Los flujos de trabajo son un tema recurrente en las estadísticas de datos. Implican transferir, transformar y analizar datos para descubrir la información significativa que contienen. En Google Cloud, la herramienta destinada a alojar flujos de trabajo es Cloud Composer, que es una versión alojada de Apache Airflow, la popular herramienta de código abierto para flujos de trabajo.
En este lab, usarás la consola de Google Cloud para configurar un entorno de Cloud Composer. Luego, utilizarás Cloud Composer para preparar un flujo de trabajo simple que verifique la existencia de un archivo de datos, cree un clúster de Cloud Dataproc, ejecute un trabajo de conteo de palabras de Apache Hadoop en el clúster de Cloud Dataproc y borre este clúster más adelante.
Actividades
Usar la consola de Google Cloud para crear el entorno de Cloud Composer
Ver y ejecutar el DAG (grafo acíclico dirigido) en la interfaz web de Airflow
Ver los resultados del trabajo de conteo de palabras en Storage
Configuración y requisitos
Configuración del lab
En cada lab, recibirá un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Qwiklabs desde una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesita, puede reiniciar el lab, pero deberá hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usa otras credenciales, se generarán errores o incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Active Cloud Shell
Cloud Shell es una máquina virtual que contiene herramientas de desarrollo y un directorio principal persistente de 5 GB. Se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a sus recursos de Google Cloud. gcloud es la herramienta de línea de comandos de Google Cloud, la cual está preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
En el panel de navegación de Google Cloud Console, haga clic en Activar Cloud Shell ().
Haga clic en Continuar.
El aprovisionamiento y la conexión al entorno tardan solo unos momentos. Una vez que se conecte, también estará autenticado, y el proyecto estará configurado con su PROJECT_ID. Por ejemplo:
Comandos de muestra
Si desea ver el nombre de cuenta activa, use este comando:
Si desea ver el ID del proyecto, use este comando:
gcloud config list project
(Resultado)
[core]
project = <project_ID>
(Resultado de ejemplo)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Verifica los permisos del proyecto
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
En el Menú de navegación () de la consola de Google Cloud, haga clic en IAM y administración > IAM.
Confirma que aparezca la cuenta de servicio predeterminada de Compute {project-number}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el menú de navegación > Descripción general de Cloud.
Si no aparece la cuenta en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
En la consola de Google Cloud, en el menú de navegación, haz clic en Descripción general de Cloud.
En la tarjeta Información del proyecto, copia el Número de proyecto.
En el menú de navegación, haz clic en IAM y administración > IAM.
En la parte superior de la página IAM, haga clic en Agregar.
Reemplaza {project-number} por el número de tu proyecto.
En Seleccionar un rol, elige Básico (o Proyecto) > Editor.
Haz clic en Guardar.
Tarea 1: Asegúrate de que la API de Kubernetes Engine esté habilitada correctamente
Para garantizar el acceso a las APIs necesarias, reinicia la conexión a la API de Kubernetes Engine.
En la consola de Google Cloud, busca y registra el Número de proyecto en el cuadro Información del proyecto.
En la consola, ingresa API de Kubernetes Engine en la barra de búsqueda superior. Haz clic en el resultado de la API de Kubernetes Engine.
Haz clic en Administrar.
Haz clic en Inhabilitar API.
Si se te solicita confirmar, haz clic en Inhabilitar.
De nuevo, cuando aparezca el mensaje Do you want to disable Kubernetes Engine API and its dependent APIs?, haz clic en Inhabilitar.
Haz clic en Habilitar.
Cuando se haya habilitado de nuevo la API, se mostrará en la página la opción para inhabilitarla.
Tarea 2. Asegúrate de que la API de Cloud Composer esté habilitada correctamente
Reinicia la conexión a la API de Cloud Composer. En el paso anterior, el reinicio de la API de Kubernetes Engine provocó que se inhabilitara la API de Cloud Composer.
En la consola de Google Cloud, ingresa API de Cloud Composer en la barra de búsqueda superior. Haz clic en el resultado de la API de Cloud Composer.
Haz clic en Habilitar.
Cuando se haya habilitado de nuevo la API, se mostrará en la página la opción para inhabilitarla.
Tarea 3: Crea el entorno de Cloud Composer
En esta sección, crearás un entorno de Cloud Composer.
Nota: Antes de continuar, comprueba que realizaste las tareas anteriores para garantizar que las APIs necesarias estén habilitadas correctamente. De lo contrario, la creación del entorno de Cloud Composer fallará.
En el campo Buscar de la barra de título de la consola de Google Cloud, escribe cloud composer y, luego, haz clic en Composer.
Haz clic en Crear entorno y selecciona Composer 3.
Establece lo siguiente para el entorno:
Propiedad
Valor
Nombre
highcpu
Ubicación
Versión de la imagen
composer-3-airflow-n.n.n-build.n (Nota: Selecciona la imagen con el número más alto que esté disponible)
Deja el resto de la configuración con sus valores predeterminados.
En Recursos del entorno, selecciona Pequeño.
Haz clic en Crear.
El proceso de creación del entorno se completa cuando, en la página de Entornos de la consola de Google Cloud, la marca de verificación verde aparece a la izquierda del nombre del entorno.
El entorno puede tardar entre 10 y 20 minutos en completar el proceso de configuración. Continúa con el lab mientras se inicia.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear el entorno de Cloud Composer.
Crea un bucket de Cloud Storage
Crea un bucket de Cloud Storage en tu proyecto. Este bucket se usará como resultado del trabajo de Hadoop obtenido de Dataproc.
Ve al Menú de navegación > Cloud Storage > Buckets y, luego, haz clic en + Crear.
Asígnale un nombre universalmente único al bucket y, luego, haz clic en Crear. Si aparece el mensaje Se impedirá el acceso público, haz clic en Confirmar.
Recuerda el nombre del bucket de Cloud Storage, ya que lo usarás como una variable de Airflow más adelante en el lab.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear un bucket de Cloud Storage
Tarea 4: Airflow y conceptos básicos
Mientras esperas a que se cree tu entorno de Composer, repasa algunos términos que se usan con Airflow.
Airflow es una plataforma para crear, programar y supervisar flujos de trabajo de manera programática.
Utiliza Airflow para crear flujos de trabajo como grafos acíclicos dirigidos (DAG) de tareas. El programador de Airflow ejecuta tus tareas en un array de trabajadores mientras sigue las dependencias especificadas.
Conceptos básicos
DAG: Un grafo acíclico dirigido es una colección de todas las tareas que quieres ejecutar, organizadas para que reflejen sus relaciones y dependencias.
Operador: Es la descripción de una sola tarea; suele ser atómico. Por ejemplo, BashOperator se usa para ejecutar comandos Bash.
Tarea: Es una instancia con parámetros de un operador; un nodo en el DAG.
Instancia de tarea: Es la ejecución específica de una tarea, caracterizada como un DAG, una tarea y un momento determinado. Tiene un estado indicativo: running, success, failed, skipped, …
Ahora, analicemos el flujo de trabajo que utilizarás. Los flujos de trabajo de Cloud Composer constan de DAG (grafos acíclicos dirigidos). Los DAG se definen en archivos estándar de Python ubicados en la carpeta DAG_FOLDER de Airflow. Este, a su vez, ejecutará el código en cada archivo para compilar dinámicamente los objetos DAG. Puedes tener tantos DAG como desees, pues cada uno describe un número arbitrario de tareas. En general, cada DAG debe corresponder a un único flujo de trabajo lógico.
A continuación, se encuentra el código de flujo de trabajo hadoop_tutorial.py, también denominado DAG:
"""Example Airflow DAG that creates a Cloud Dataproc cluster, runs the Hadoop
wordcount example, and deletes the cluster.
This DAG relies on three Airflow variables
https://airflow.apache.org/concepts.html#variables
* gcp_project - Google Cloud Project to use for the Cloud Dataproc cluster.
* gce_zone - Google Compute Engine zone where Cloud Dataproc cluster should be
created.
* gcs_bucket - Google Cloud Storage bucket to used as output for the Hadoop jobs from Dataproc.
See https://cloud.google.com/storage/docs/creating-buckets for creating a
bucket.
"""
import datetime
import os
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
# Output file for Cloud Dataproc job.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Path to Hadoop wordcount example available on every Dataproc cluster.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Arguments to pass to Cloud Dataproc job.
wordcount_args = ['wordcount', 'gs://pub/shakespeare/rose.txt', output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
'start_date': yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
'email_on_failure': False,
'email_on_retry': False,
# If a task fails, retry it once after waiting at least 5 minutes
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
with models.DAG(
'composer_sample_quickstart',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
# Create a Cloud Dataproc cluster.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
# Give the cluster a unique name by appending the date scheduled.
# See https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
region=models.Variable.get('gce_region'),
zone=models.Variable.get('gce_zone'),
image_version='2.0',
master_machine_type='n1-standard-2',
worker_machine_type='n1-standard-2')
# Run the Hadoop wordcount example installed on the Cloud Dataproc cluster
# master node.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
region=models.Variable.get('gce_region'),
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
# Delete Cloud Dataproc cluster.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
region=models.Variable.get('gce_region'),
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Setting trigger_rule to ALL_DONE causes the cluster to be deleted
# even if the Dataproc job fails.
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
Para organizar las tres tareas del flujo de trabajo, el DAG importa los siguientes operadores:
DataprocClusterCreateOperator: Crea un clúster de Cloud Dataproc.
DataProcHadoopOperator: Envía un trabajo de conteo de palabras de Hadoop y escribe los resultados en un bucket de Cloud Storage.
DataprocClusterDeleteOperator: Borra el clúster para no generar cargos continuos de Compute Engine.
Las tareas se ejecutan de forma secuencial, lo que puedes ver en esta sección del archivo:
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
El nombre del DAG es quickstart y se ejecuta una vez al día.
with models.DAG(
'composer_sample_quickstart',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
Dado que la start_date que se pasa a default_dag_args está establecida como yesterday, Cloud Composer programa el flujo de trabajo para que comience inmediatamente después de subir el DAG.
Tarea 6: Consulta información del entorno
Vuelve a Composer para comprobar el estado de tu entorno.
Cuando termine de crearse el entorno, haz clic en el nombre (highcpu) para ver los detalles.
En la pestaña Configuración del entorno, verás información como la URL de la IU web de Airflow, el clúster de GKE y un vínculo a la carpeta de los DAG, que está almacenada en tu bucket.
Nota: Cloud Composer solo programa los flujos de trabajo en la carpeta /dags.
Tarea 7. Usa la IU de Airflow
Realiza lo siguiente para acceder a la interfaz web de Airflow por medio de la consola de Google Cloud:
Regrese a la página Entornos.
En la columna Webserver de Airflow del entorno, haz clic en Airflow.
Haz clic en tus credenciales del lab.
La interfaz web de Airflow se abrirá en una nueva ventana del navegador.
Tarea 8: Configura variables de Airflow
Las variables de Airflow son un concepto específico de Airflow que difiere de las variables de entorno.
En la interfaz de Airflow, selecciona Administrador > Variables en la barra de menú.
Haz clic en el ícono + para agregar un registro nuevo.
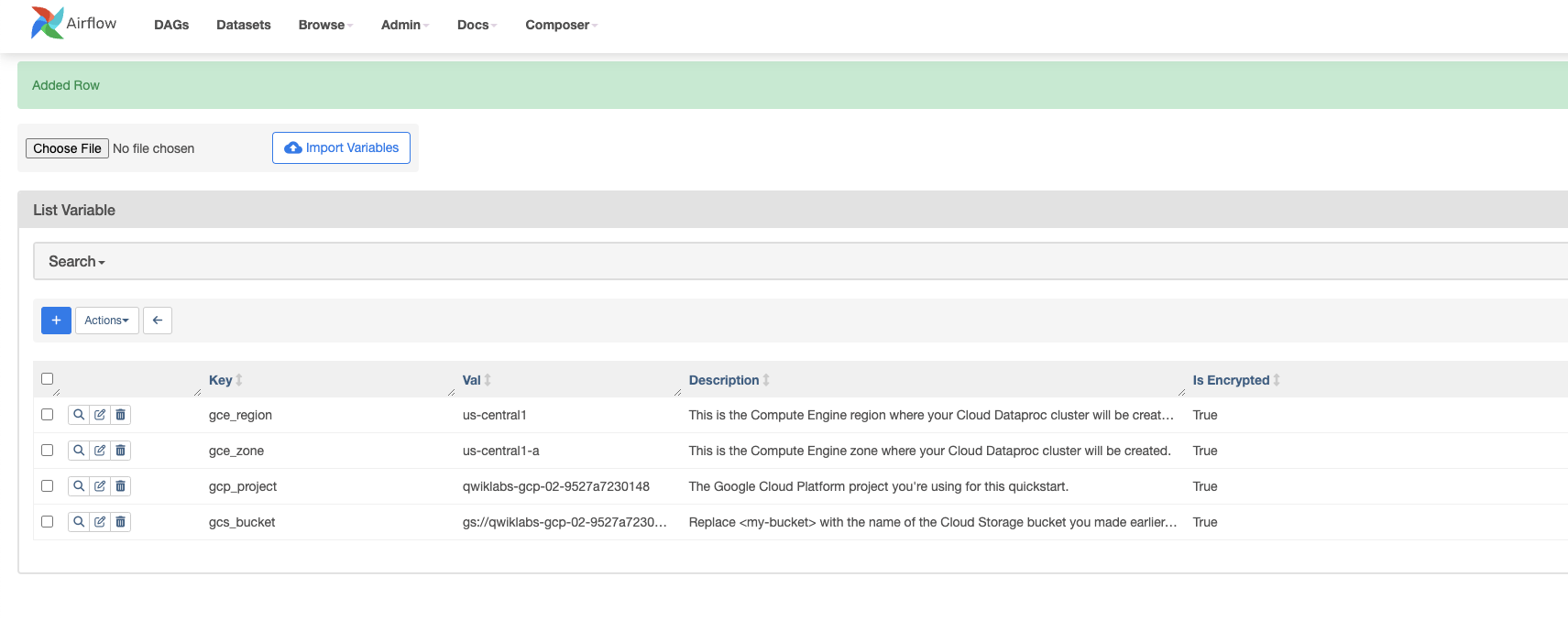
Crea las siguientes variables de Airflow: gcp_project, gcs_bucket y gce_zone:
Clave
Val
Detalles
gcp_project
El proyecto de Google Cloud Platform que estás usando en este lab.
gcs_bucket
gs://<my-bucket>
Reemplaza <my-bucket> por el nombre del bucket de Cloud Storage que creaste anteriormente. Este bucket almacena el resultado de los trabajos de Hadoop que se obtienen de Dataproc.
gce_zone
Esta es la zona de Compute Engine en la que se creará tu clúster de Cloud Dataproc.
gce_region
Esta es la región de Compute Engine en la que se creará tu clúster de Cloud Dataproc.
Haz clic en Guardar. Después de agregar la primera variable, repite el mismo proceso para la segunda y la tercera. Cuando termines, la tabla Variables debería verse de esta forma:
Tarea 9: Sube el DAG a Cloud Storage
Sigue estos pasos para subir el DAG:
En Cloud Shell, ejecuta el comando que se menciona a continuación para subir una copia del archivo hadoop_tutorial.py al bucket de Cloud Storage que se generó automáticamente cuando creaste el entorno.
Reemplaza <DAGs_folder_path> en el siguiente comando por la ruta a la carpeta de los DAG:
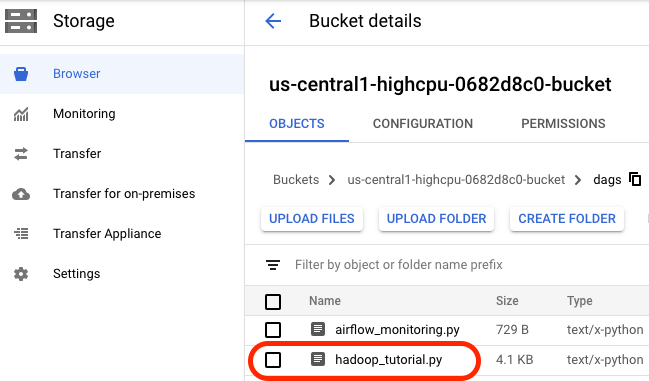
Cuando el archivo se haya subido correctamente al directorio de DAG, abre la carpeta dags en el bucket y verás el archivo en la pestaña Objetos de los detalles del bucket.
Cuando se agrega un archivo DAG a la carpeta de los DAG, Cloud Composer agrega el DAG a Airflow y lo programa automáticamente. Los cambios en el DAG tardan de 3 a 5 minutos.
Puede ver el estado de la tarea del DAG composer_hadoop_tutorial en la interfaz web de Airflow.
Haz clic en Revisar mi progreso para verificar el objetivo.
Subir el DAG a Cloud Storage
Explora las ejecuciones del DAG
Cuando subas tu archivo DAG a la carpeta dags en Cloud Storage, Cloud Composer lo analizará. Si no se encuentran errores, el nombre del flujo de trabajo aparecerá en la lista del DAG y el flujo de trabajo se pondrá en cola para ejecutarse de inmediato.
Asegúrate de estar en la pestaña de DAG, en la interfaz web de Airflow. Este proceso tardará varios minutos en completarse. Actualiza la página para asegurarte de ver la información más reciente.
Asegúrate de estar en la pestaña de DAG, en la interfaz web de Airflow. Este proceso tardará varios minutos en completarse. Actualiza la página para asegurarte de ver la información más reciente.
En Airflow, haz clic en composer_hadoop_tutorial para abrir la página de detalles del DAG. En ella, se incluyen varias representaciones de las tareas y dependencias del flujo de trabajo.
En la barra de herramientas, haz clic en Gráfico. Desplaza el mouse sobre el gráfico de cada tarea para ver su estado. Ten en cuenta que el borde de cada tarea también indica el estado (borde verde: running; rojo: failed; etcétera).
Haz clic en el vínculo “Actualizar” para asegurarte de ver la información más reciente. Los bordes de los procesos cambian de color a medida que se actualizan los estados.
Nota: Si tu clúster de Dataproc ya existe, puedes volver a ejecutar el flujo de trabajo para alcanzar el estado “success” haciendo clic en el gráfico “create_dataproc_cluster” y, luego, en Borrar para restablecer las tres tareas y, por último, en Aceptar para confirmar.
Una vez que el estado de create_dataproc_cluster cambie a “running”, dirígete al menú de navegación > Dataproc y, luego, haz clic en lo siguiente:
Clústeres para supervisar la creación y eliminación de clústeres. El clúster que el flujo de trabajo creó es efímero: solo existe a la par del flujo de trabajo y se borra como parte de la última tarea de este.
Trabajos para supervisar el trabajo de conteo de palabras de Apache Hadoop. Haz clic en el ID del trabajo para ver el resultado del registro de trabajos.
Cuando Dataproc alcance el estado “Running”, vuelve a Airflow y haz clic en Refresh para ver que el clúster esté completo.
Cuando el proceso run_dataproc_hadoop esté completo, ve al menú de navegación > Cloud Storage > Buckets y haz clic en el nombre de tu bucket para ver los resultados del conteo de palabras en la carpeta wordcount.
Cuando se completen todos los pasos en el DAG, cada uno tendrá un borde verde oscuro. Además, se borrará el clúster de Dataproc que creó.
¡Felicitaciones!
Ejecutaste correctamente un flujo de trabajo de Cloud Composer.
Cuando haya completado su lab, haga clic en Finalizar lab. Qwiklabs quitará los recursos que usó y limpiará la cuenta por usted.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Neutral
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2020 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usa una ventana de navegación privada o de Incógnito para ejecutar el lab. Así
evitarás cualquier conflicto entre tu cuenta personal y la cuenta
de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
En este lab, crearás un entorno de Cloud Composer mediante la consola de Google Cloud. Luego, usarás la interfaz web de Airflow para ejecutar un flujo de trabajo que verifique un archivo de datos, cree y ejecute un trabajo de recuento de palabras de Apache Hadoop en un clúster de Dataproc y borre el clúster.
Duración:
0 min de configuración
·
Acceso por 90 min
·
90 min para completar
 ).
).
 ) de la consola de Google Cloud, haga clic en IAM y administración > IAM.
) de la consola de Google Cloud, haga clic en IAM y administración > IAM.