Dataflow を使用したサーバーレス データ分析: シンプルな Dataflow パイプライン(Java)
ラボ
1時間 30分
universal_currency_alt
クレジット: 5
show_chart
上級
info
このラボでは、学習をサポートする AI ツールが組み込まれている場合があります。
概要
このラボでは、Dataflow プロジェクトを開き、パイプライン フィルタリングを使用し、パイプラインをローカルとクラウド上で実行します。
目標
このラボでは、単純な Dataflow パイプラインを記述し、ローカルとクラウド上の両方で実行する方法を学習します。
- Maven を使用して Java Dataflow プロジェクトをセットアップする
- Java でシンプルなパイプラインを記述する
- ローカルマシンでクエリを実行する
- クラウドでクエリを実行する
設定と要件
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
-
Qwiklabs にシークレット ウィンドウでログインします。
-
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
-
準備ができたら、[ラボを開始] をクリックします。
-
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
-
[Google Console を開く] をクリックします。
-
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
-
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud Shell の有効化
Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
-
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。

-
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。

gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
- 次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
gcloud auth list
出力:
Credentialed accounts:
- @.com (active)
出力例:
Credentialed accounts:
- google1623327_student@qwiklabs.net
- 次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
gcloud config list project
出力:
[core]
project =
出力例:
[core]
project = qwiklabs-gcp-44776a13dea667a6
注:
gcloud ドキュメントの全文については、
gcloud CLI の概要ガイド
をご覧ください。
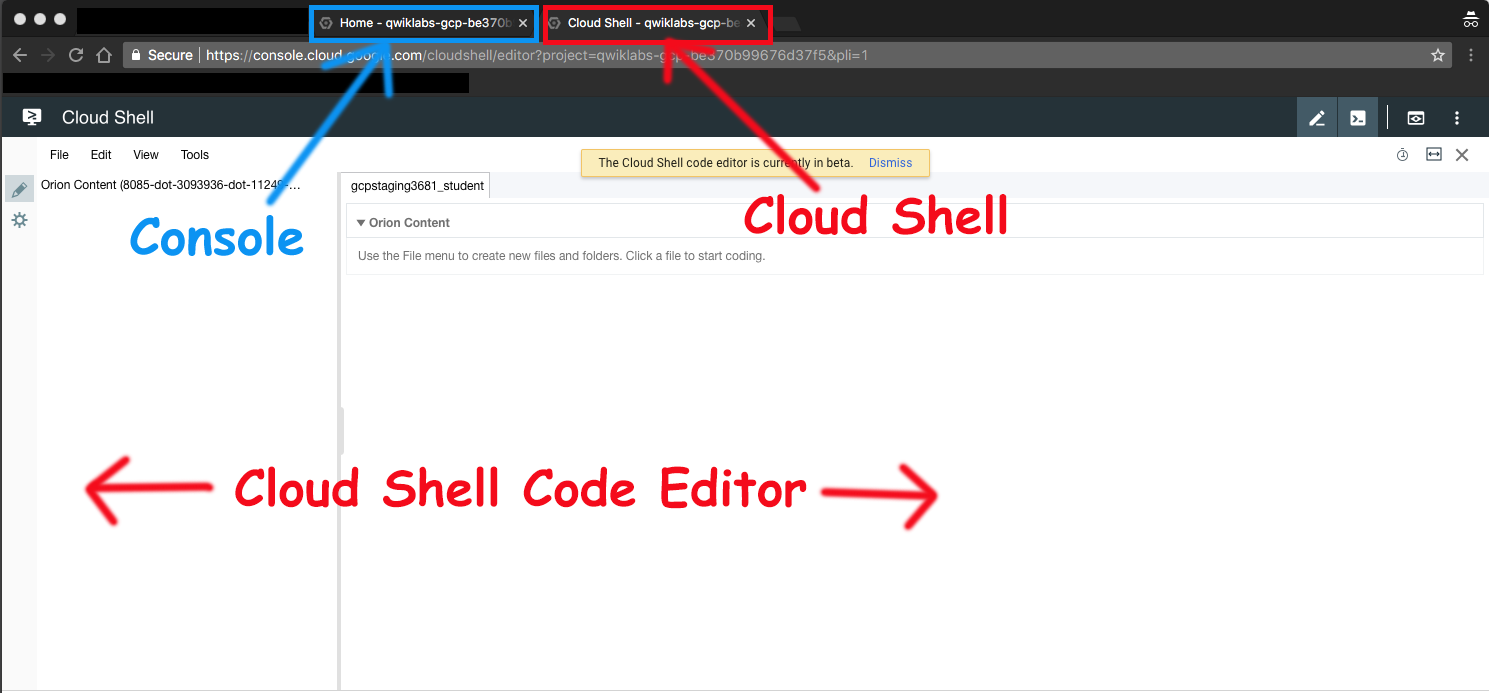
Google Cloud Shell コードエディタを起動する
Google Cloud Shell コードエディタを使用すると、Cloud Shell インスタンス内でディレクトリやファイルを簡単に作成および編集できます。
- Google Cloud Shell をアクティブにしたら、[エディタを開く] をクリックして Cloud Shell コードエディタを開きます。
![[エディタを開く] ボタン](https://cdn.qwiklabs.com/hZYBOz6ymTpCcrjxYiyPK2gVdwvdXxHVm77O5rBeFfs%3D)
これで次の 3 つのインターフェースを利用できるようになりました。
- Cloud Shell コードエディタ
- コンソール(タブをクリックして表示)。タブをクリックすれば、コンソールと Cloud Shell を切り替えることができます。
- Cloud Shell コマンドライン(コンソールの [ターミナルを開く] をクリックして表示)。
プロジェクトの権限を確認する
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
-
Google Cloud コンソールのナビゲーション メニュー( )で、[IAM と管理] > [IAM] を選択します。
)で、[IAM と管理] > [IAM] を選択します。
-
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)
注: アカウントが IAM に存在しない場合やアカウントに編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。
- Google Cloud コンソールのナビゲーション メニューで、[Cloud の概要] > [ダッシュボード] をクリックします。
- プロジェクト番号(例:
729328892908)をコピーします。
-
ナビゲーション メニューで、[IAM と管理] > [IAM] を選択します。
- ロールの表の上部で、[プリンシパル別に表示] の下にある [アクセス権を付与] をクリックします。
- [新しいプリンシパル] に次のように入力します。
{project-number}-compute@developer.gserviceaccount.com
-
{project-number} はプロジェクト番号に置き換えてください。
- [ロール] で、[Project](または [基本])> [編集者] を選択します。
- [保存] をクリックします。
タスク 1. 準備
バケットを確認してラボコードをダウンロードする
このラボを正常に実行するには、特定の手順を完了する必要があります。
-
Cloud Storage バケットがあることを確認する(ラボ環境の開始時に自動的に 1 つ作成されています)。
-
Google Cloud コンソールのタイトルバーで、[Cloud Shell をアクティブにする] をクリックします。プロンプトが表示されたら、[続行] をクリックします。次のコマンドを使用して、ラボコードを含む github リポジトリのクローンを作成します。
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
- Cloud Shell で次のコマンドを入力し、2 つの環境変数を作成します。環境変数の名前は「BUCKET」と「REGION」にします。echo コマンドを使用して、環境変数がそれぞれ存在することを確認します。
BUCKET="{{{project_0.project_id|Project ID}}}-bucket"
echo $BUCKET
REGION="{{{project_0.default_region|Region}}}"
echo $REGION
Dataflow API が有効になっていることを確認します。
- Cloud Shell で次のコマンドを実行して、Dataflow API がプロジェクト内でクリーンに有効化されるようにします。
gcloud services disable dataflow.googleapis.com --force
gcloud services enable dataflow.googleapis.com
タスク 2. 新しい Dataflow プロジェクトを作成する
このラボの目標は、Dataflow プロジェクトの構造を理解し、Dataflow パイプラインを実行する方法を学習することです。強力なビルドツール Maven を使用して、新しい Dataflow プロジェクトを作成します。
- Cloud Shell のブラウザタブに戻ります。Cloud Shell でこのラボのディレクトリに移動します。
cd ~/training-data-analyst/courses/data_analysis/lab2
- 次の Maven コマンドをコピーして貼り付けます。
mvn archetype:generate \
-DarchetypeArtifactId=google-cloud-dataflow-java-archetypes-starter \
-DarchetypeGroupId=com.google.cloud.dataflow \
-DgroupId=com.example.pipelinesrus.newidea \
-DartifactId=newidea \
-Dversion="[1.0.0,2.0.0]" \
-DinteractiveMode=false
- どのようなディレクトリが作成されましたか。
- src ディレクトリ内にどのようなパッケージが作成されましたか。
- ラボコードの作成に使用された Maven コマンドを調べます。
cat ~/training-data-analyst/courses/data_analysis/lab2/create_mvn.sh
- どのようなディレクトリが作成されますか。
- src ディレクトリ内にどのようなパッケージが作成されますか。
タスク 3. パイプラインのフィルタリング
-
Cloud Shell コードエディタで、ディレクトリ /training-data-analyst/courses/data_analysis/lab2 に移動します。
-
次に、パス javahelp/src/main/java/com/google/cloud/training/dataanalyst/javahelp/ を選択して、ファイル Grep.java を表示します。
または、nano エディタでファイルを表示することもできます。コードは変更しないでください。
cd ~/training-data-analyst/courses/data_analysis/lab2/javahelp/src/main/java/com/google/cloud/training/dataanalyst/javahelp/
nano Grep.java
ファイル Grep.java に関する次の質問に答えてください。
- 読み込まれているファイルは何ですか。
- 検索キーワードは何ですか。
- どこに出力されますか。
このパイプラインには 3 つの apply ステートメントがあります。
- 1 つ目の apply() では何が行われますか。
- 2 つ目の apply() では何が行われますか。
- 入力元はどこですか。
- この入力値に対し何が行われますか。
- 出力に書き込まれる内容は何ですか。
- 出力先はどこですか。
- 3 つ目の apply() では何が行われますか。
タスク 4. ローカルでパイプラインを実行する
- Cloud Shell で次の Maven コマンドを貼り付けます。
cd ~/training-data-analyst/courses/data_analysis/lab2
export PATH=/usr/lib/jvm/java-8-openjdk-amd64/bin/:$PATH
cd ~/training-data-analyst/courses/data_analysis/lab2/javahelp
mvn compile -e exec:java \
-Dexec.mainClass=com.google.cloud.training.dataanalyst.javahelp.Grep
- 出力ファイルは
output.txt です。出力サイズが大きければ、output-00000-of-00001 といった名前が付いた複数のファイルにシャーディングされます。必要に応じて、ファイルの時刻から目的のファイルを見つけます。
ls -al /tmp
- 出力ファイルを確認します。
cat /tmp/output*
出力内容に問題がないかを確認します。
タスク 5. パイプラインをクラウド上で実行する
- いくつかの Java ファイルをクラウドにコピーします。
gcloud storage cp ../javahelp/src/main/java/com/google/cloud/training/dataanalyst/javahelp/*.java gs://$BUCKET/javahelp
-
Cloud Shell コードエディタでディレクトリ /training-data-analyst/courses/data_analysis/lab2/javahelp/src/main/java/com/google/cloud/training/dataanalyst/javahelp に移動します。
-
ファイル Grep.java で Dataflow パイプラインを編集します。
cd ~/training-data-analyst/courses/data_analysis/lab2/javahelp/src/main/java/com/google/cloud/training/dataanalyst/javahelp
- 入力変数と出力変数をバケット名に置き換えます。変数を次のように置き換えます。
String input = "gs://{{{project_0.project_id|Project ID}}}-bucket/javahelp/*.java";
String outputPrefix = "gs://{{{project_0.project_id|Project ID}}}-bucket/javahelp/output";
注: ソースコードにすでに存在している input と outputPrefix の文字列を必ず変更してください(同じ名前の変数が 2 つできてしまうため、最初の文字列を削除せずに、上の行全体をコピーして貼り付けることは避けてください)。
編集前の行の例:
String input = "src/main/java/com/google/cloud/training/dataanalyst/javahelp/*.java";
String outputPrefix = "/tmp/output";
</ql-code-block output>
プロジェクトのバケット名を含む編集後の行の例:
String input = "gs://qwiklabs-gcp-your-value-bucket/javahelp/*.java";
</ql-code-block output>
String outputPrefix = "gs://qwiklabs-gcp-your-value-bucket/javahelp/output";
</ql-code-block output>
5. この Dataflow ジョブをクラウドに送信するスクリプトを調べます。
cd ~/training-data-analyst/courses/data_analysis/lab2/javahelp
cat run_oncloud1.sh
この Maven コマンドとローカルで実行するコマンドの違いは何ですか。
- Dataflow ジョブをクラウドに送信します。
bash run_oncloud1.sh $DEVSHELL_PROJECT_ID $BUCKET Grep $REGION
これは小さなジョブなので、クラウドで実行するほうがローカルで実行する場合よりもかなり長く(2~3 分ほど)時間がかかります。
コマンドラインの完了例:
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 01:50 min
[INFO] Finished at: 2018-02-06T15:11:23-05:00
[INFO] Final Memory: 39M/206M
[INFO] ------------------------------------------------------------------------
- コンソールのブラウザタブに戻り、ナビゲーション メニュー()で [Dataflow] をクリックし、進行状況をモニタリングするジョブをクリックします。
例:
![グラフビューを表示する [ジョブグラフ] タブ](https://cdn.qwiklabs.com/YfFzXLRnWOIRH0u7ft9ilWV%2FJtSJ3XGbG99a9HTT%2F2w%3D)
-
ジョブ ステータスが [完了] に変わるまで待ちます。この時点で Cloud Shell にコマンドライン プロンプトが表示されます。
注: Dataflow ジョブが初めて失敗した場合は、前のコマンドを再実行し、新しい Dataflow ジョブをクラウドに送信します。
-
Cloud Storage バケットで出力を調べます。ナビゲーション メニュー()で [Cloud Storage] > [バケット] をクリックして、該当するバケットをクリックします。
-
javahelp ディレクトリをクリックします。このジョブによってファイル output.txt が作成されます。ファイルのサイズが大きければ、output-0000x-of-000y といった名前が付いた複数のファイルにシャーディングされます。最新のファイルは、名前または [最終更新日] フィールドで特定できます。これらを表示するにはファイルをクリックします。
または、Cloud Shell でファイルをダウンロードして表示することもできます。
gcloud storage cp gs://$BUCKET/javahelp/output* .
cat output*
ラボを終了する
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
- 星 1 つ = 非常に不満
- 星 2 つ = 不満
- 星 3 つ = どちらともいえない
- 星 4 つ = 満足
- 星 5 つ = 非常に満足
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2020 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。





