Neste laboratório, veremos como migrar o código do Apache Spark para o Cloud Dataproc. Você vai seguir uma sequência de etapas e mover cada vez mais componentes do job para os serviços do Google Cloud:
Executar o código original do Spark no Cloud Dataproc (migração lift-and-shift)
Substituir o HDFS pelo Cloud Storage (nativo da nuvem)
Automatizar tudo para execução em clusters específicos dos jobs (otimizados para a nuvem)
Conteúdo do laboratório
Neste laboratório, você vai aprender a:
Migrar jobs do Spark para o Cloud Dataproc
Modificar jobs do Spark para usar o Cloud Storage em vez do HDFS
Otimizar jobs do Spark para executar em clusters específicos
Vamos usar
Cloud Dataproc
Apache Spark
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Ative o Google Cloud Shell
O Google Cloud Shell é uma máquina virtual com ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud.
O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
No console do Cloud, clique no botão "Abrir o Cloud Shell" na barra de ferramentas superior direita.
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando você estiver conectado, já estará autenticado, e o projeto estará definido com seu PROJECT_ID. Exemplo:
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
Para listar o nome da conta ativa, use este comando:
Antes de começar a trabalhar no Google Cloud, veja se o projeto tem as permissões corretas no Identity and Access Management (IAM).
No console do Google Cloud, em Menu de navegação (), selecione IAM e administrador > IAM.
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que está no Menu de navegação > Visão geral do Cloud > Painel.
Observação: se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
No console do Google Cloud, em Menu de navegação, clique em Visão geral do Cloud > Painel.
Copie o número do projeto, por exemplo, 729328892908.
Em Menu de navegação, clique em IAM e administrador > IAM.
Clique em Permitir acesso, logo abaixo de Visualizar por principais na parte de cima da tabela de papéis.
Substitua {project-number} pelo número do seu projeto.
Em Papel, selecione Projeto (ou Básico) > Editor.
Clique em Save.
Cenário
Você está migrando uma carga de trabalho do Spark para o Cloud Dataproc e modificando o código aos poucos para aproveitar os recursos e serviços nativos do Google Cloud.
Tarefa 1: realizar migração lift-and-shift
Migre jobs do Spark para o Cloud Dataproc
Você criará um cluster do Cloud Dataproc. Depois, executará um notebook do Jupyter importado que usa o Sistema de Arquivos Distribuído do Hadoop (HDFS, na sigla em inglês) padrão do cluster para armazenar os dados de origem. Por fim, você processará esses dados como faria em qualquer cluster do Hadoop, usando o Spark. A atividade demonstra que é possível migrar muitas cargas de trabalho de análise que contêm código do Spark, como os notebooks do Jupyter, para um ambiente do Cloud Dataproc sem alterações.
Configure e inicie um cluster do Cloud Dataproc
Na seção Analytics do menu de navegação do console do Google Cloud, clique em Dataproc.
Selecione Criar cluster.
Clique em Criar para o item Cluster no Compute Engine.
Digite sparktodp em Nome do cluster.
Defina a região como e a zona como .
Na seção Controle de versões, clique em Alterar e selecione 2.1 (Debian 11, Hadoop 3.3, Spark 3.3).
Essa versão inclui Python3, necessário para o exemplo de código usado no laboratório.
Clique em Selecionar.
Na seção Componentes > Gateway do componente, escolha Ativar gateway de componente.
Em Componentes opcionais, selecione Notebook do Jupyter.
Na lista Configurar cluster à esquerda, clique em Configurar nós (opcional).
Em Nó do administrador, altere Série para E2 e Tipo de máquina para e2-standard-2 (2 vCPUs, 8 GB de memória) e defina o Tamanho do disco principal como 30.
Em Nós de trabalho, altere Série para E2 e Tipo de máquina para e2-standard-2 (2 vCPUs, 8 GB de memória) e defina o Tamanho do disco principal para 30.
Clique em Criar.
O cluster vai levar uns minutos para iniciar. Espere a implantação do Cloud Dataproc ser concluída e prossiga para a próxima etapa.
Clone o repositório de origem do laboratório
No Cloud Shell, você clona o repositório Git do laboratório e copia os arquivos necessários para o bucket do Cloud Storage que o Cloud Dataproc usa como diretório inicial dos notebooks do Jupyter.
Para clonar o repositório do Git do laboratório, digite o seguinte comando no Cloud Shell:
Você já pode acessar as interfaces da Web assim que o cluster terminar de iniciar. Clique no botão "Atualizar" para verificar se a implantação já terminou.
Na página "Clusters" do Dataproc, aguarde até que seu cluster termine de iniciar e clique no nome dele para abrir a página Detalhes do cluster.
Clique em Interfaces da Web.
Clique no link Jupyter para abrir uma nova guia do Jupyter no navegador.
A página inicial do Jupyter será aberta. Nela, é possível conferir o conteúdo do diretório /notebooks/jupyter no Cloud Storage, que inclui os exemplos de notebooks do Jupyter usados no laboratório.
Na guia Files, clique na pasta GCS e depois no notebook 01_spark.ipynb para abrir.
Clique em Cell e depois em Run All para executar todas as células no notebook.
Use Page Up para voltar ao começo do notebook. Acompanhe a execução de cada célula e as respostas que aparecem abaixo delas.
Você pode navegar pelas células e examinar o código que está sendo processado, para ver o que o notebook está fazendo. Preste atenção especialmente ao local em que os dados são salvos e processados.
A primeira célula de código recupera o arquivo de dados de origem, que é um trecho da competição KDD Cup da conferência Knowledge, Discovery, and Data (KDD) de 1999. Os dados são relacionados a eventos de detecção de intrusões de computador.
Na segunda célula de código, os dados de origem são copiados para o sistema de arquivos padrão do Hadoop (local).
!hadoop fs -put kddcup* /
Na terceira célula de código, o comando lista o conteúdo do diretório padrão do sistema de arquivos HDFS do cluster.
!hadoop fs -ls /
Leitura dos dados
Os dados são arquivos CSV no formato gzip. No Spark, podemos ler esses arquivos diretamente usando o método textFile e dividir cada linha com vírgulas para fazer a análise.
O código em Python do Spark começa na célula In[4].
O código desta célula inicializa o Spark SQL, usa o Spark para ler os dados de origem como texto e retorna as cinco primeiras linhas.
Na célula In [6], um contexto do Spark SQL é criado, e um DataFrame do Spark que usa esse contexto é gerado a partir dos dados de entrada analisados na etapa anterior.
Os dados das linhas podem ser selecionados e expostos com o método .show() do DataFrame para gerar um resumo da contagem dos campos selecionados:
O SparkSQL também pode ser usado para consultar os dados analisados armazenados no DataFrame.
Na célula In [7], é registrada uma tabela temporária (connections) que é referenciada na consulta SQL subsequente do SparkSQL:
df.registerTempTable("connections")
attack_stats = sqlContext.sql("""
SELECT
protocol_type,
CASE label
WHEN 'normal.' THEN 'no attack'
ELSE 'attack'
END AS state,
COUNT(*) as total_freq,
ROUND(AVG(src_bytes), 2) as mean_src_bytes,
ROUND(AVG(dst_bytes), 2) as mean_dst_bytes,
ROUND(AVG(duration), 2) as mean_duration,
SUM(num_failed_logins) as total_failed_logins,
SUM(num_compromised) as total_compromised,
SUM(num_file_creations) as total_file_creations,
SUM(su_attempted) as total_root_attempts,
SUM(num_root) as total_root_acceses
FROM connections
GROUP BY protocol_type, state
ORDER BY 3 DESC
""")
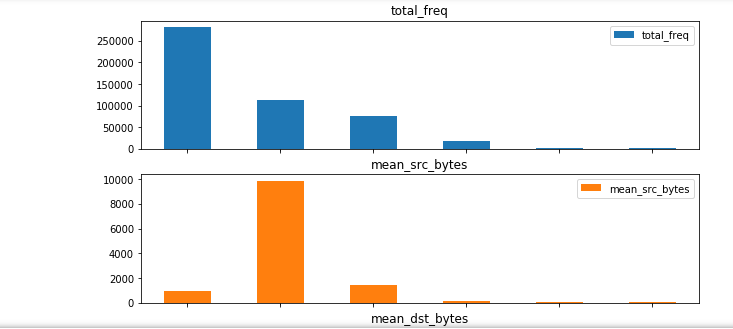
attack_stats.show()
Quando a consulta terminar, você vai receber uma resposta semelhante a este exemplo truncado:
Também é possível usar gráficos de barras para mostrar esses dados visualmente.
O código da última célula, In [8], usa a função mágica do Jupyter %matplotlib inline para redirecionar matplotlib para renderizar uma figura inline no notebook, em vez de apenas jogar os dados em uma variável. Essa célula exibe o gráfico de barras usando a consulta attack_stats da etapa anterior.
Depois que todas as células no notebook forem executadas, a primeira parte da saída será semelhante ao gráfico abaixo. Role para baixo no seu notebook para conferir o gráfico completo.
Tarefa 2: separar computação e armazenamento
Modifique jobs do Spark para usar o Cloud Storage em vez do HDFS
Usando este exemplo de notebook de "migração lift-and-shift" original, você vai criar uma cópia que separa os requisitos de armazenamento e de computação do job. Nesse caso, basta substituir as chamadas ao sistema de arquivos do Hadoop por chamadas ao Cloud Storage. Para isso, troque as referências a hdfs:// por referências a gs:// no código e faça as mudanças necessárias nos nomes das pastas.
Comece usando o Cloud Shell para colocar uma cópia dos dados de origem em um novo bucket do Cloud Storage.
No Cloud Shell, crie um novo bucket de armazenamento para os dados de origem:
export PROJECT_ID=$(gcloud info --format='value(config.project)')
gcloud storage buckets create gs://$PROJECT_ID
No Cloud Shell, copie os dados de origem para o bucket:
Espere o comando anterior ser concluído e o arquivo ser copiado para o novo bucket.
Volte à guia do notebook do Jupyter 01_spark no navegador.
Clique em File e em Make a Copy.
Quando a cópia abrir, clique no título 01_spark-Copy1 e altere o nome para De-couple-storage.
Abra a guia do Jupyter do notebook 01_spark.
Clique em File e em Save and checkpoint para salvar o notebook.
Clique em File e em Close and Halt para fechar o notebook.
Se for solicitado, clique em Leave ou em Cancel para confirmar.
Volte à guia do notebook do Jupyter De-couple-storage no navegador, se necessário.
Você não precisa mais das células que fazem o download e a cópia dos dados para o sistema de arquivos HDFS interno do cluster, então remova essas células.
Para excluir uma célula, clique nela e depois clique no ícone cut selected cells (símbolo de tesoura) na barra de ferramentas do notebook.
Exclua as células de comentário iniciais e as três primeiras células de código ( In [1], In [2] e In [3]) para que o notebook comece com a seção Reading in Data.
Agora você vai alterar o código da primeira célula, que define o local de origem do arquivo de dados e insere os dados de origem. Ela ainda se chama In[4], a menos que você tenha executado o notebook novamente. A célula atualmente contém este código:
Substitua o conteúdo da célula In [4] pelo código abaixo. A única alteração aqui é criar a variável para armazenar o nome de um bucket do Cloud Storage e apontar data_file para o bucket que usamos para armazenar os dados de origem.
Depois que você substituir o código, a primeira célula vai ficar semelhante à imagem abaixo, e o ID do seu projeto do laboratório será o nome do bucket:
Na célula atualizada, substitua o marcador de posição [Your-Bucket-Name] pelo nome do bucket de armazenamento que você criou na primeira etapa desta seção. Esse bucket foi criado com o ID do projeto como nome. O ID é mostrado no painel de informações de login do laboratório, no lado esquerdo. Substitua todo o texto do marcador de posição, inclusive os colchetes [].
Clique em Cell e depois em Run All para executar todas as células no notebook.
Você vai receber a mesma resposta de quando o arquivo foi carregado e executado no armazenamento interno do cluster. Para mover os arquivos de dados de origem para o Cloud Storage, basta alterar a referência à origem do armazenamento de hdfs:// para gs://.
Tarefa 3: implantar jobs do Spark
Otimize jobs do Spark para executar em clusters específicos
Agora você vai criar um arquivo Python independente para implantação como um job do Cloud Dataproc. Ele terá as mesmas funções deste notebook. Para isso, você adiciona comandos mágicos às células do Python em uma cópia deste notebook para gravar o conteúdo das células em um arquivo. Além disso, você adiciona um manipulador de parâmetros de entrada para definir o local do bucket de armazenamento quando o script em Python é chamado. Isso facilita a portabilidade do código.
No menu De-couple-storage do notebook do Jupyter, clique em File e depois em Make a copy.
Quando a cópia abrir, clique em De-couple-storage-Copy1 e altere o nome para PySpark-analysis-file.
Abra a guia do Jupyter De-couple-storage.
Clique em File e em Save and checkpoint para salvar o notebook.
Clique em File e em Close and Halt para fechar o notebook.
Se for solicitado, clique em Leave ou em Cancel para confirmar.
Volte à guia do notebook do Jupyter PySpark-analysis-file no navegador, se necessário.
Clique na primeira célula na parte superior do notebook.
Clique em Insert e selecione Insert Cell Above.
Cole o código abaixo na primeira célula de código nova. Ele importa a biblioteca e faz a manipulação dos parâmetros.
O comando mágico do Jupyter %%writefile spark_analysis.py cria um novo arquivo de resposta para conter o script independente do Python. Você adiciona uma variação dele às demais células para anexar o conteúdo de cada uma ao arquivo de script.
O código também importa o módulo matplotlib e define explicitamente o back-end de plotagem padrão por meio de matplotlib.use('agg'), para que o código de plotagem seja executado fora de um notebook do Jupyter.
No início das demais células de código Python, digite %%writefile -a spark_analysis.py. Elas são as cinco células com o rótulo In [x].
%%writefile -a spark_analysis.py
Por exemplo, o código da célula seguinte deve ficar como o indicado abaixo:
Repita a etapa digitando %%writefile -a spark_analysis.py no início de cada célula de código até chegar ao final.
Na última célula, onde um gráfico de barras do Pandas é plotado, remova o comando mágico %matplotlib inline.
Observação: se você não remover a diretiva mágica matplotlib inline do Jupyter, a execução do seu script vai falhar.
Selecione a última célula de código no notebook e, na barra de menus, clique em Insert e em Insert Cell Below.
Cole o código na célula nova:
%%writefile -a spark_analysis.py
ax[0].get_figure().savefig('report.png');
Adicione outra célula ao final do notebook e cole este código:
%%writefile -a spark_analysis.py
import google.cloud.storage as gcs
bucket = gcs.Client().get_bucket(BUCKET)
for blob in bucket.list_blobs(prefix='sparktodp/'):
blob.delete()
bucket.blob('sparktodp/report.png').upload_from_filename('report.png')
Adicione uma célula ao final do notebook e cole este código:
%%writefile -a spark_analysis.py
connections_by_protocol.write.format("csv").mode("overwrite").save(
"gs://{}/sparktodp/connections_by_protocol".format(BUCKET))
Automação de teste
Agora, você vai testar o código PySpark para confirmar que ele é executado corretamente em um arquivo. Chame a cópia local no notebook e passe um parâmetro para identificar o bucket de armazenamento que você criou, que contém os dados de entrada do job. O mesmo bucket será usado para armazenar os arquivos de dados de relatórios produzidos pelo script.
No notebook PySpark-analysis-file, adicione uma célula ao final e cole este código:
BUCKET_list = !gcloud info --format='value(config.project)'
BUCKET=BUCKET_list[0]
print('Writing to {}'.format(BUCKET))
!/opt/conda/miniconda3/bin/python spark_analysis.py --bucket=$BUCKET
Esse código só vai funcionar se você tiver seguido as instruções anteriores e criado um bucket do Cloud Storage usando o ID do seu projeto como o nome. Se você tiver usado outro nome, modifique a variável BUCKET com o nome que você usou.
Adicione uma célula ao final do notebook e cole este código:
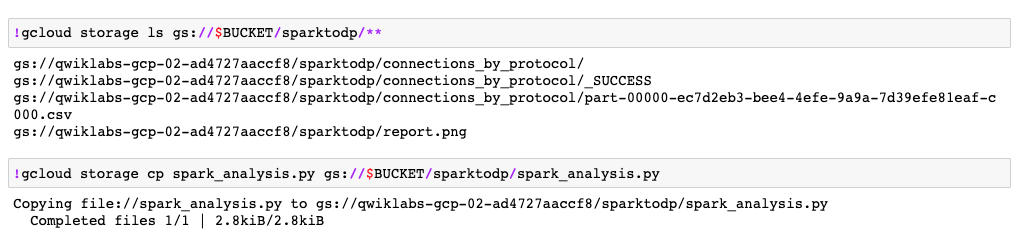
!gcloud storage ls gs://$BUCKET/sparktodp/**
Esse comando mostra os arquivos de saída do script que foram salvos no seu bucket do Cloud Storage.
Para salvar uma cópia do arquivo em Python no armazenamento permanente, adicione uma célula e cole este código:
Clique em Cell e depois em Run All para executar todas as células no notebook.
Se o notebook criar e executar um arquivo Python corretamente, você verá uma resposta semelhante à imagem abaixo nas duas últimas células. Isso indica que o script foi executado até o fim e salvou a resposta no bucket do Cloud Storage criado no laboratório.
Observação: a maior causa de erros nessa etapa é a não remoção da diretiva matplotlib em In [7]. Verifique novamente se você modificou todas as células segundo as instruções acima e não pulou nenhuma etapa.
Execute o job de análise no Cloud Shell
Volte ao Cloud Shell e copie o script Python do Cloud Storage para executá-lo como um job do Cloud Dataproc:
#!/bin/bash
gcloud dataproc jobs submit pyspark \
--cluster sparktodp \
--region {{{project_0.default_region | REGION }}} \
spark_analysis.py \
-- --bucket=$1
Pressione CTRL+X, depois Y e Enter para sair e salvar.
Torne o script executável:
chmod +x submit_onejob.sh
Inicie o job de análise do PySpark:
./submit_onejob.sh $PROJECT_ID
Na guia do console do Cloud, acesse Dataproc > Clusters se você ainda não tiver feito isso.
Clique em Jobs.
Clique no nome do job que aparece na lista. Você pode monitorar o progresso aqui ou no Cloud Shell. Aguarde a conclusão do job.
Acesse seu bucket de armazenamento. O relatório gerado, /sparktodp/report.png, terá um carimbo de data/hora atualizado, indicando que o job independente foi realizado.
O bucket que o job usa para gravar dados é o que tem o ID do projeto como nome.
Acesse novamente Dataproc > Clusters.
Selecione o cluster sparktodp e clique em Excluir. Você não precisa mais dele.
Clique em CONFIRMAR.
Feche as guias do Jupyter no seu navegador.
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste laboratório, você verá como executar jobs do Apache Spark no Cloud Dataproc.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 90 minutos
·
Tempo para conclusão: 90 minutos


 ), selecione IAM e administrador > IAM.
), selecione IAM e administrador > IAM.
![gcs_bucket='[Your-Bucket-Name]'](https://cdn.qwiklabs.com/lxRwZFWWNgly1JKdY9s5JNVNwgW4rKxzYKwBIgkHlBw%3D)