

![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)
![gcs_bucket='[Your-Bucket-Name]'](https://cdn.qwiklabs.com/lxRwZFWWNgly1JKdY9s5JNVNwgW4rKxzYKwBIgkHlBw%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
このラボでは、Apache Spark のコードを Cloud Dataproc に移行する方法を学びます。一連のステップに従って段階的に、ジョブの各コンポーネントを Google Cloud のサービスに移行します。
このラボでは、次の方法について学びます。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。既存の Spark ワークロードを Cloud Dataproc に移行した後、Google Cloud のネイティブ機能とサービスを使用するように、Spark コードを段階的に変更します。
新しい Cloud Dataproc クラスタを作成した後、インポートした Jupyter ノートブックを実行します。このノートブックでは、クラスタのデフォルトのローカル Hadoop 分散ファイル システム(HDFS)を使用してソースデータを格納し、Spark を使用する Hadoop クラスタの場合と同様に、そのデータを処理します。これにより、Spark コードが含まれる Jupyter ノートブックなど、既存の分析ワークロードの多くが、Cloud Dataproc 環境に移行しても変更の必要がないことを確認することができます。
Google Cloud コンソールのナビゲーション メニューで、[分析] セクションの [Dataproc] をクリックします。
[CREATE CLUSTER] をクリックします。
[Compute Engine 上のクラスタ] の [作成] をクリックします。
[クラスタ名] に「sparktodp」と入力します。
リージョンを [
[バージョニング] セクションで、[変更] をクリックし、[2.1 (Debian 11, Hadoop 3.3, Spark 3.3)] を選択します。
このバージョンには、このラボで使用するサンプルコードで必要となる Python3 が含まれています。
[選択] をクリックします。
[コンポーネント] > [コンポーネント ゲートウェイ] セクションで、[コンポーネント ゲートウェイを有効にする] を選択します。
[オプション コンポーネント] で [Jupyter Notebook] を選択します。
左側のリストの [クラスタの設定] の下の [ノードの構成(省略可)] をクリックします。
[マネージャー ノード] で、[シリーズ] を [E2] に、[マシンタイプ] を [e2-standard-2(2 vCPU、8 GB メモリ)] に変更し、[プライマリ ディスク サイズ] を [30] に設定します。
[ワーカーノード] で、[シリーズ] を [E2]、[マシンタイプ] を [e2-standard-2(2 vCPU、8 GB メモリ)] に変更し、[プライマリ ディスク サイズ] を [30] に設定します。
[作成] をクリックします。
クラスタは数分で起動します。Cloud Dataproc クラスタが完全にデプロイされるまで待ってから次のステップに進んでください。
Cloud Shell で、ラボ用に Git リポジトリのクローンを作成し、Cloud Dataproc によって Jupyter ノートブックのホーム ディレクトリとして使用される Cloud Storage バケットに、必要なノートブック ファイルをコピーします。
クラスタが完全に起動したら、すぐにウェブ インターフェースに接続できます。更新ボタンをクリックして、このステージに至るまでに完全にデプロイされたかどうかを確認します。
Dataproc の [クラスタ] ページで、クラスタの起動が完了するまで待ち、該当するクラスタの名前をクリックして [クラスタの詳細] ページを開きます。
[ウェブ インターフェース] をクリックします。
Jupyter のリンクをクリックして、ブラウザに新しい Jupyter のタブを開きます。
Jupyter のホームページが開きます。このページには Cloud Storage の /notebooks/jupyter ディレクトリの内容が表示され、このラボで使用するサンプルの Jupyter ノートブックが含まれるようになったことがわかります。
[Files] タブで、GCS フォルダをクリックした後、01_spark.ipynb ノートブックをクリックして開きます。
[Cell]、[Run All] を順にクリックして、ノートブック内のすべてのセルを実行します。
ノートブックの一番上まで戻ります。各セルの実行が完了したら、その下に結果が出力されることを確認します。
一連のセルの処理に伴い、順を追って各セルのコードを確認することで、ノートブックによって行われていることを把握できます。特に、データがどこで保存され、どこから処理されるかに注意するようにしてください。
データは、gzip で圧縮された CSV ファイルです。Spark ではこれらのデータを textFile メソッドを使用して直接読み取り、各行をカンマで区切ることで解析できます。
Python Spark コードはセル In[4] から始まります。
In [5] では、各行が「,」という文字で区切られ、コード内に準備されたインライン スキーマを使用して解析されます。セル In [6] では、Spark SQL コンテキストが作成され、そのコンテキストを使用する Spark データフレームが、前のステージの解析済み入力データを使用して作成されます。
.show() メソッド(選択されたフィールドの数を要約したビューを出力する)を使用して選択および表示できます。.show() メソッドによって、次のような出力テーブルが生成されます。
SparkSQL を使用して、データフレームに格納された解析済みデータのクエリを実行することもできます。
In [7] では、一時テーブル(connections)が登録されます。これはその後、後続の SparkSQL SQL クエリ ステートメント内で参照されます。クエリが終了すると、この例(簡略化したもの)のような出力が表示されます。
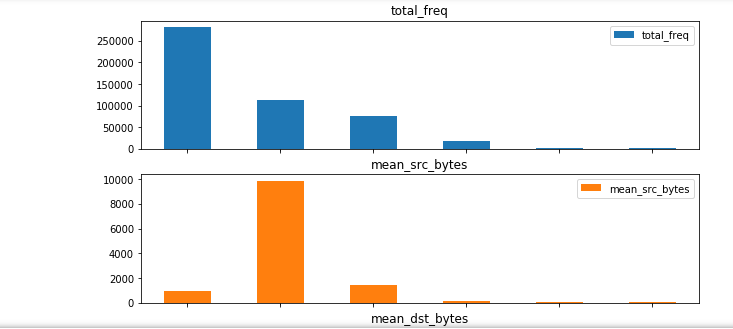
このデータは棒グラフを使用して表示することもできます。
In [8] では、単にデータを変数にダンプするのではなく、%matplotlib inline Jupyter マジック関数を使用して matplotlib をリダイレクトし、ノートブックにインラインで視覚的なグラフをレンダリングしています。このセルには、前のステップの attack_stats クエリを使用した棒グラフが表示されます。ノートブックのすべてのセルが正常に実行されると、出力の最初の部分は、次のグラフのようになります。ノートブックを下までスクロールすれば、出力グラフ全体を参照できます。
元の「リフト&シフト」のサンプル ノートブックからコピーを作成し、ジョブのストレージ要件をコンピューティング要件から切り離します。このケースでは、Hadoop ファイル システム呼び出しを Cloud Storage 呼び出しに置き換えることのみが必要となります。具体的には、コード内の hdfs:// ストレージ参照を gs:// 参照に置き換え、必要に応じてフォルダ名を修正します。
最初に、Cloud Shell を使用して、新しい Cloud Storage バケットにソースデータのコピーを配置します。
最後のコマンドが完了し、新しいストレージ バケットにファイルがコピーされていることを確認します。
ブラウザの Jupyter Notebook の 01_spark のタブに戻ります。
[File] をクリックした後、[Make a Copy] を選択します。
コピーが開いたら、01_spark-Copy1 というタイトルをクリックし、名前を De-couple-storage に変更します。
Jupyter の 01_spark のタブを開きます。
[File]、[Save and Checkpoint] の順にクリックして、ノートブックを保存します。
[File]、[Close and Halt] の順にクリックして、ノートブックをシャットダウンします。
De-couple-storage のタブに戻ります。データをダウンロードしてクラスタの内部的な HDFS ファイル システムにコピーするセルは必要なくなったため、最初にこれらのセルを削除します。
セルを削除するには、該当するセル内をクリックして選択した後、ノートブックのツールバーの cut selected cells アイコン(はさみ)をクリックします。
In [1]、In [2]、In [3])を削除します。これにより、ノートブックの先頭は [Reading in data] になります。次に、最初のセル(ノートブックを再実行していない場合はまだ In[4] という名前です)のコードを変更します。このセルではデータファイルのソースの場所を定義し、ソースデータを読み込みます。現在、セルには次のコードが含まれています。
In [4] の内容を次のコードに置き換えます。ここで加える変更は 1 つだけです。Cloud Storage バケット名を格納する変数を作成した後、data_file が、Cloud Storage にソースデータを格納するために使用していたバケットをポイントするようにします。コードを置き換えると、最初のセルは次のようになります。バケット名は実際のラボ プロジェクト ID になります。
先ほど更新したセルで、プレースホルダ [Your-Bucket-Name] を、このセクションの最初のステップで作成したストレージ バケットの名前に置き換えます。このバケットは、プロジェクト ID を名前にして作成しました。プロジェクト ID はこちらの画面の左側にある、Qwiklabs ラボのログイン情報パネルからコピーできます。すべてのプレースホルダ テキストを、角かっこ [] も含めて置き換えます。
[Cell]、[Run All] を順にクリックして、ノートブック内のすべてのセルを実行します。
表示される出力は、内部クラスタ ストレージからファイルがロードされ、実行されたときとまったく同一になります。ストレージ ソース参照のポイント先を hdfs:// から gs:// に変更するだけで、ソースデータのファイルを Cloud Storage に移動できます。
次に、このノートブックと同じ機能を実行し、Cloud Dataproc ジョブとしてデプロイできるスタンドアロンの Python ファイルを作成します。そのためには、このノートブックのコピーの Python セルに、セルの内容をファイルに書き出すマジック コマンドを追加します。また、Python スクリプトが呼び出されたときにストレージ バケットの場所を設定する入力パラメータ ハンドラも追加することで、コードのポータビリティを高めます。
Jupyter Notebook メニューの De-couple-storage で、[File] をクリックして [Make a Copy] を選択します。
コピーが開いたら、De-couple-storage-Copy1 をクリックし、名前を PySpark-analysis-file に変更します。
Jupyter の De-couple-storage のタブを開きます。
[File]、[Save and Checkpoint] の順にクリックして、ノートブックを保存します。
[File]、[Close and Halt] の順にクリックして、ノートブックをシャットダウンします。
必要に応じて、ブラウザの Jupyter Notebook の PySpark-analysis-file のタブに戻ります。
ノートブック上部の最初のセルをクリックします。
[Insert] をクリックし、[Insert Cell Above] を選択します。
次のライブラリ インポートとパラメータ処理コードを新しい最初のコードセルに貼り付けます。
%%writefile spark_analysis.py という Jupyter マジック コマンドによって、スタンドアロンの Python スクリプトを含む新しい出力ファイルが作成されます。残りの各セルには、このマジック コマンド(「-a」付き)を追加し、各セルの内容をこのスタンドアロンのスクリプト ファイルに追加します。
さらに、このコードでは、matplotlib モジュールをインポートし、matplotlib.use('agg') を介して明示的にデフォルトのプロット バックエンドを設定します。これにより、プロットコードが Jupyter ノートブックの外部で実行されるようになります。
%%writefile -a spark_analysis.py を挿入します。これらは In [x] というラベルの付いた 5 つのセルです。たとえば、次のセルは、以下のようになります。
このステップを繰り返して、最後まで、各コードセルの先頭に %%writefile -a spark_analysis.py を挿入します。
最後のセル(Pandas 棒グラフがプロットされる)から、%matplotlib inline マジック コマンドを削除します。
ノートブックの最後のコードセルを選択した状態で、メニューバーで [Insert] をクリックし、[Insert Cell Below] を選択します。
新しいセルに次のコードを貼り付けます。
ここでは、ノートブック内からローカルコピーを呼び出し、このジョブの入力データを格納するストレージ バケット(作成済み)を識別するためのパラメータを受け渡すことによって、PySpark コードがファイルとして正常に実行されるかどうかをテストします。このバケットは、スクリプトによって生成されたレポートデータ ファイルを格納するためにも使用されます。
PySpark-analysis-file ノートブックの末尾に、新しいセルを追加して、次の内容を貼り付けます。このコードは、ここまでに示した手順のとおり、ストレージ バケット名としてラボのプロジェクト ID を使用して Cloud Storage バケットを作成していることを前提としています。別の名前を使用した場合は、BUCKET 変数に該当する名前に設定するように、このコードを変更します。
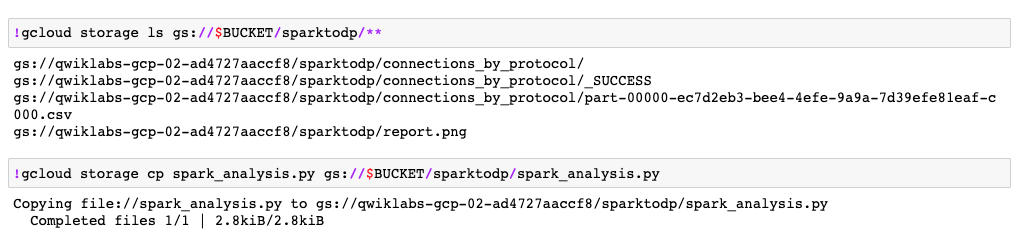
Cloud Storage バケットに保存されているスクリプト出力ファイルが一覧表示されます。
正常に Python ファイルが作成されて実行された場合は、最後の 2 つのセルについて、次のような出力が表示されます。これは、スクリプトの実行が完了し、このラボで前に作成した Cloud Storage バケットに、出力が保存されたことを示します。
Ctrl+X キー、Y キー、Enter キーの順に押して保存して終了します。
スクリプトを実行可能にします。
Cloud コンソールのタブで、[Dataproc] > [クラスタ] ページを開きます(まだ開いていない場合)。
[ジョブ] をクリックします。
リストされているジョブの名前をクリックします。進行状況は、ここでも、Cloud Shell からでも確認することができます。ジョブが正常に完了するまで待ちます。
ストレージ バケットに移動し、出力レポート /sparktodp/report.png のタイムスタンプが更新されている、つまり、スタンドアロンのジョブが正常に完了したことを確認します。
このジョブによって入出力のデータ ストレージとして使用されたストレージ バケットは、プロジェクト ID が名前として使用されているものとなります。
[Dataproc] > [クラスタ] ページに戻ります。
sparktodp クラスタを選択し、[削除] をクリックします(この後は必要ないため)。
[削除] をクリックします。
ブラウザの Jupyter のタブをすべて閉じます。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2020 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください