Dans cet atelier, vous allez apprendre à migrer du code Apache Spark vers Cloud Dataproc. Vous allez effectuer une série d'étapes pour transférer progressivement des composants de jobs vers des services Google Cloud :
Exécuter le code Spark d'origine sur Cloud Dataproc (Lift and Shift)
Remplacer HDFS par Cloud Storage (cloud natif)
Automatiser le processus pour que les jobs s'exécutent sur des clusters adaptés (optimisés pour le cloud)
Points abordés
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
Migrer des jobs Spark existants vers Cloud Dataproc
Modifier des jobs Spark afin qu'ils utilisent Cloud Storage au lieu de HDFS
Optimiser des jobs Spark pour une exécution sur des clusters adaptés
Outils utilisés
Cloud Dataproc
Apache Spark
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Qwiklabs dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à Google Cloud Console.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Activer Google Cloud Shell
Google Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud.
Google Cloud Shell vous permet d'accéder à vos ressources Google Cloud grâce à une ligne de commande.
Dans la barre d'outils située en haut à droite dans la console Cloud, cliquez sur le bouton "Ouvrir Cloud Shell".
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Par exemple :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project =
Exemple de résultat :
[core]
project = qwiklabs-gcp-44776a13dea667a6
Remarque : Pour consulter la documentation complète sur gcloud, accédez au guide de présentation de la gcloud CLI.
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
Dans la console Google Cloud, accédez au menu de navigation (), puis sélectionnez IAM et administration > IAM.
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle editor (éditeur). Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation du cloud > Tableau de bord.
Remarque : Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle editor (éditeur), procédez comme suit pour lui attribuer le rôle approprié.
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation du cloud > Tableau de bord.
Copiez le numéro du projet (par exemple, 729328892908).
Dans le menu de navigation, sélectionnez IAM et administration > IAM.
Sous Afficher par compte principal, en haut de la table des rôles, cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez :
Remplacez {project-number} par le numéro de votre projet.
Dans le champ Rôle, sélectionnez Projet (ou Basique) > Éditeur.
Cliquez sur Enregistrer.
Scénario
Vous allez transférer une charge de travail Spark vers Cloud Dataproc, puis modifier progressivement le code Spark afin d'utiliser les fonctionnalités et services natifs de Google Cloud.
Tâche 1 : Migration Lift and Shift
Migrer des jobs Spark existants vers Cloud Dataproc
Vous allez créer un cluster Cloud Dataproc, puis vous exécuterez un notebook Jupyter qui utilise le système de fichiers HDFS (Hadoop Distributed File System) local pour stocker les données source. Vous traiterez ensuite ces données exactement comme vous le feriez sur n'importe quel cluster Hadoop à l'aide de Spark. Ceci montre que pour un grand nombre de charges de travail analytiques existantes telles que les notebooks Jupyter contenant du code Spark, la migration vers un environnement Cloud Dataproc ne nécessite aucune modification.
Configurer et démarrer un cluster Cloud Dataproc
Dans la console Google Cloud, accédez au menu de navigation et, dans la section Analyse, cliquez sur Dataproc.
Cliquez sur Créer un cluster.
Cliquez sur Créer à côté de l'élément Cluster sur Compute Engine.
Dans le champ Nom du cluster, saisissez sparktodp.
Définissez la région sur et la zone sur .
Dans la section Gestion des versions, cliquez sur Modifier, puis choisissez 2.1 (Debian 11, Hadoop 3.3, Spark 3.3).
Cette version inclut Python3, dont nous avons besoin pour l'exemple de code utilisé dans cet atelier.
Cliquez sur Sélectionner.
Accédez à Composants > Passerelle des composants, puis sélectionnez Activer la passerelle des composants.
Choisissez l'option Jupyter Notebook sous Composants facultatifs.
Dans la liste de gauche, sous Configurer le cluster, cliquez sur Configurer les nœuds (facultatif).
Sous Nœud du gestionnaire, choisissez E2 pourSérie et e2-standard-2 (2 vCPU, 8 Go de mémoire) pour Type de machine, puis définissez Taille du disque principal sur 30.
Sous Nœuds de calcul, choisissez E2 pour Série et e2-standard-2 (2 vCPU, 8 Go de mémoire) pour Type de machine, puis définissez Taille du disque principal sur 30.
Cliquez sur Créer.
Le cluster devrait démarrer dans quelques minutes. Veuillez attendre que le cluster Cloud Dataproc soit entièrement déployé avant de passer à la prochaine étape.
Cloner le dépôt source associé à cet atelier
Dans Cloud Shell, vous allez cloner le dépôt Git de cet atelier, puis copier les fichiers de notebook requis dans le bucket Cloud Storage utilisé par Cloud Dataproc en tant que répertoire d'accueil pour les notebooks Jupyter.
Pour cloner le dépôt Git associé à cet atelier, saisissez la commande suivante dans Cloud Shell :
Dès que le démarrage du cluster est terminé, vous pouvez vous connecter aux interfaces Web. Cliquez sur le bouton "Actualiser" pour vérifier, car il est possible que le déploiement soit déjà terminé à ce stade.
Sur la page "Dataproc Clusters" (Clusters Dataproc), attendez la fin du démarrage du cluster, puis cliquez sur son nom pour ouvrir la page Cluster details (Détails du cluster).
Cliquez sur Web Interfaces (Interfaces Web).
Cliquez sur le lien Jupyter pour ouvrir un nouvel onglet Jupyter dans le navigateur.
La page d'accueil de Jupyter s'ouvre. Vous pouvez voir sur cette page le contenu du répertoire /notebooks/jupyter créé dans Cloud Storage, qui comprend désormais les exemples de notebook Jupyter utilisés dans cet atelier.
Sous l'onglet Fichiers, cliquez sur le dossier GCS, puis sur le nom de notebook 01_spark.ipynb pour l'ouvrir.
Cliquez sur Cellule, puis sur Tout exécuter pour exécuter toutes les cellules du notebook.
Faites défiler la page jusqu'en haut du notebook et continuez à faire défiler, car à mesure que chaque cellule est exécutée par le notebook, le résultat s'affiche en dessous.
Vous pouvez maintenant faire défiler les cellules vers le bas et suivre le traitement du code pour observer l'activité du notebook. Notez en particulier l'emplacement dans lequel les données sont enregistrées et à partir duquel elles sont traitées.
La première cellule de code récupère le fichier des données source, qui est un extrait de la KDD Cup Competition de la conférence Knowledge, Discovery, and Data (KDD) de 1999. Ces données concernent des événements de détection d'intrusion dans des systèmes informatiques.
Dans la deuxième cellule de code, les données source sont copiées dans le système de fichiers Hadoop (local) par défaut.
!hadoop fs -put kddcup* /
Dans la troisième cellule de code, la commande liste le contenu du répertoire par défaut dans le système de fichiers HDFS du cluster.
!hadoop fs -ls /
Lecture des données
Les données sont des fichiers CSV compressés avec gzip. Dans Spark, ces fichiers peuvent être lus directement à l'aide de la méthode textFile, puis analysés en fractionnant chaque ligne après chaque virgule.
Le code Python Spark commence dans la cellule In[4].
Dans cette cellule, Spark SQL est initialisé. Spark est utilisé pour lire les données source comme du texte, puis renvoie les cinq premières lignes.
Dans la cellule In [5], chaque ligne est fractionnée au niveau de la virgule ( ,), qui est utilisée comme délimiteur. Ensuite, chaque ligne est analysée à l'aide d'un schéma préparé intégré dans le code.
Dans la cellule In [6], un contexte SQL Spark est généré, et un DataFrame Spark utilisant ce contexte est créé à l'aide des données d'entrée analysées à l'étape précédente.
Sélectionnez et affichez les données de ligne à l'aide de la méthode .show() du DataFrame pour récupérer en sortie une vue récapitulant le nombre de champs sélectionnés :
SparkSQL permet également d'interroger les données analysées stockées dans le Dataframe.
La cellule In [7] contient une table temporaire (connections) enregistrée, qui est ensuite référencée dans l'instruction de requête SQL SparkSQL suivante :
df.registerTempTable("connections")
attack_stats = sqlContext.sql("""
SELECT
protocol_type,
CASE label
WHEN 'normal.' THEN 'no attack'
ELSE 'attack'
END AS state,
COUNT(*) as total_freq,
ROUND(AVG(src_bytes), 2) as mean_src_bytes,
ROUND(AVG(dst_bytes), 2) as mean_dst_bytes,
ROUND(AVG(duration), 2) as mean_duration,
SUM(num_failed_logins) as total_failed_logins,
SUM(num_compromised) as total_compromised,
SUM(num_file_creations) as total_file_creations,
SUM(su_attempted) as total_root_attempts,
SUM(num_root) as total_root_acceses
FROM connections
GROUP BY protocol_type, state
ORDER BY 3 DESC
""")
attack_stats.show()
Lorsque la requête est terminée, vous devez voir un résultat semblable à cet exemple (lequel est volontairement tronqué) :
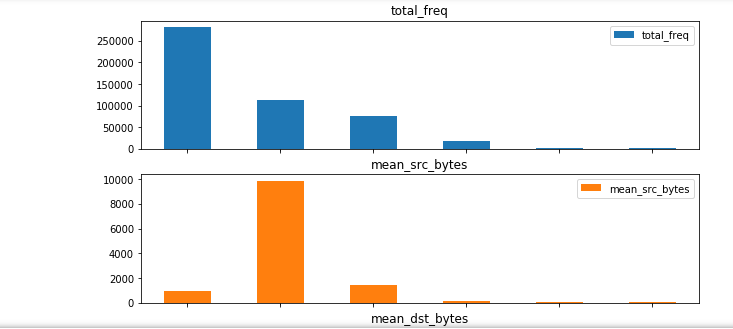
Notez que vous pouvez aussi afficher ces données sous forme de graphiques à barres.
La dernière cellule, In [8], utilise la fonction magique de Jupyter %matplotlib inline pour rediriger matplotlib afin de rendre une figure graphique intégrée dans le notebook, au lieu de seulement insérer les données dans une variable. Cette cellule affiche un graphique à barres reposant sur la requête attack_stats utilisée dans l'étape précédente.
La première partie de la sortie doit normalement ressembler au graphique suivant, une fois que toutes les cellules du notebook ont été correctement exécutées. Vous pouvez faire défiler le notebook vers le bas pour visualiser l'intégralité du graphique.
Tâche 2 : Séparation du calcul et du stockage
Modifier des jobs Spark afin qu'ils utilisent Cloud Storage au lieu de HDFS
À partir de cet exemple initial de notebook créé via une migration "Lift and Shift", vous allez maintenant créer une copie qui dissocie les exigences de stockage associées au job des exigences en termes de calcul. En l'espèce, il vous suffit de remplacer les appels de système de fichiers Hadoop par des appels Cloud Storage. Pour ce faire, substituez des références de stockage gs:// aux références de stockage hdfs:// dans le code, puis modifiez les noms de dossiers en conséquence.
Pour commencer, vous utiliserez Cloud Shell pour placer une copie des données source dans un nouveau bucket Cloud Storage.
Dans Cloud Shell, créez un bucket de stockage pour vos données source :
export PROJECT_ID=$(gcloud info --format='value(config.project)')
gcloud storage buckets create gs://$PROJECT_ID
Dans Cloud Shell, copiez les données source dans le bucket :
Assurez-vous que l'exécution de la dernière commande est terminée et que le fichier a été copié dans le nouveau bucket de stockage.
Dans le navigateur, revenez à l'onglet du notebook Jupyter 01_spark.
Cliquez sur File (Fichier), puis sélectionnez Make a Copy (Créer une copie).
Lorsque la copie s'ouvre, cliquez sur le titre 01_spark-Copy1 et renommez-le De-couple-storage.
Ouvrez l'onglet Jupyter pour 01_spark.
Cliquez sur File (Fichier), puis sur Save and checkpoint (Enregistrer et effectuer un point de contrôle) pour enregistrer le notebook.
Cliquez sur File (Fichier), puis sur Close and Halt (Fermer et interrompre) pour fermer le notebook.
Si vous êtes invité à confirmer que vous voulez fermer le notebook, cliquez sur Leave (Quitter) ou Cancel (Annuler).
Si nécessaire, retournez dans l'onglet du notebook Jupyter De-couple-storage du navigateur.
Vous n'avez plus besoin des cellules qui téléchargent et copient les données dans le système de fichiers HDFS interne du cluster. Vous allez donc commencer par les supprimer.
Pour supprimer une cellule, cliquez dessus pour la sélectionner, puis cliquez sur l'icône Cut selected cells (Couper les cellules sélectionnées) sur la barre d'outils du notebook.
Supprimez les cellules de commentaires initiaux et les trois premières cellules de code (In [1], In [2] et In [3]) afin que le notebook commence maintenant par la section Reading in Data (Lecture des données).
Vous allez maintenant modifier le code dans la première cellule (encore appelée In[4] si vous n'avez pas réexécuté le notebook) qui définit l'emplacement source du fichier de données et lit dans les données source. Cette cellule contient actuellement le code suivant :
Remplacez le contenu de la cellule In [4] par le code suivant. La seule modification effectuée ici consiste à créer une variable pour stocker un nom de bucket Cloud Storage, puis à faire pointer le data_file vers le bucket que nous avons utilisé pour stocker les données source dans Cloud Storage :
Une fois le code modifié, la première cellule ressemble à ce qui suit, votre ID de projet pour cet atelier étant utilisé comme nom du bucket :
Dans la cellule que vous venez de modifier, remplacez l'espace réservé [Your-Bucket-Name] par le nom du bucket de stockage que vous avez créé lors de la première étape de cette section. Vous avez créé ce bucket en utilisant comme nom l'ID du projet. Vous pouvez le copier ici à partir du panneau des informations de connexion de Qwiklabs, situé dans la partie gauche de cet écran. Remplacez la totalité du texte de l'espace réservé, y compris les crochets [].
Cliquez sur Cellule, puis sur Tout exécuter pour exécuter toutes les cellules du notebook.
Le résultat qui s'affiche est strictement identique à ce que vous avez pu observer lorsque le fichier a été chargé et exécuté à partir de l'espace de stockage interne du cluster. Pour transférer les fichiers de données source vers Cloud Storage, il vous suffit de remplacer la référence de votre source de stockage hdfs:// par gs://.
Tâche 3 : Déploiement de jobs Spark
Optimiser des jobs Spark pour une exécution sur des clusters adaptés
Vous allez maintenant créer un fichier Python autonome, pouvant être déployé en tant que job Cloud Dataproc, qui exécutera les mêmes fonctions que ce notebook. Pour ce faire, vous ajouterez des commandes magiques aux cellules Python dans une copie de ce notebook pour écrire le contenu des cellules dans un fichier. Vous allez également ajouter un gestionnaire de paramètres d'entrée pour définir l'emplacement du bucket de stockage lorsque le script Python est appelé afin d'améliorer la portabilité du code.
Dans le menu du notebook Jupyter De-couple-storage, cliquez sur Fichier, puis sélectionnez Créer une copie.
Lorsque la copie s'ouvre, cliquez sur De-couple-storage-Copy1 et renommez cet élément PySpark-analysis-file.
Ouvrez l'onglet du notebook Jupyter De-couple-storage.
Cliquez sur File (Fichier), puis sur Save and checkpoint (Enregistrer et effectuer un point de contrôle) pour enregistrer le notebook.
Cliquez sur File (Fichier), puis sur Close and Halt (Fermer et interrompre) pour fermer le notebook.
Si vous êtes invité à confirmer que vous voulez fermer le notebook, cliquez sur Leave (Quitter) ou Cancel (Annuler).
Si nécessaire, retournez à l'onglet du notebook Jupyter PySpark-analysis-file du navigateur.
Cliquez sur la première cellule en haut du notebook.
Cliquez sur Insert (Insérer), puis sélectionnez Insert Cell Above (Insérer la cellule au-dessus).
Collez le code d'importation de bibliothèque et de gestion de paramètres suivant dans cette nouvelle première cellule de code :
La commande magique Jupyter %%writefile spark_analysis.py crée un fichier de sortie destiné à accueillir votre script Python autonome. Vous allez ajouter une variation de cette commande aux cellules restantes pour ajouter le contenu de chaque cellule au fichier de script autonome.
Ce code importe également le module matplotlib et définit explicitement le backend de traçage par défaut via matplotlib.use('agg') afin que le code de traçage s'exécute en dehors d'un notebook Jupyter.
Pour les cellules restantes, insérez %%writefile -a spark_analysis.py au début de chaque cellule de code Python. Voici les cinq cellules intitulées In [x].
%%writefile -a spark_analysis.py
La cellule suivante doit maintenant ressembler à ceci :
Répétez cette étape en insérant %%writefile -a spark_analysis.py au début de chaque cellule de code, jusqu'à la dernière.
Dans la dernière cellule, où est tracé le graphique à barres Pandas, supprimez la commande magique %matplotlib inline.
Remarque : L'exécution de votre script échouera si vous ne supprimez pas la directive magique Jupyter intégrée matplotlib.
Assurez-vous que vous avez sélectionné la dernière cellule de code dans le notebook, puis, dans la barre de menu, cliquez sur Insert (Insérer) et sélectionnez Insert Cell Below (Insérer la cellule au-dessus).
Collez le code suivant dans la nouvelle cellule :
%%writefile -a spark_analysis.py
ax[0].get_figure().savefig('report.png');
Ajoutez une autre cellule à la fin du notebook, et collez-y le code suivant :
%%writefile -a spark_analysis.py
import google.cloud.storage as gcs
bucket = gcs.Client().get_bucket(BUCKET)
for blob in bucket.list_blobs(prefix='sparktodp/'):
blob.delete()
bucket.blob('sparktodp/report.png').upload_from_filename('report.png')
Ajoutez une nouvelle cellule à la fin du notebook, et collez-y le code suivant :
%%writefile -a spark_analysis.py
connections_by_protocol.write.format("csv").mode("overwrite").save(
"gs://{}/sparktodp/connections_by_protocol".format(BUCKET))
Automatisation des tests
Vous allez maintenant vérifier que le code PySpark s'exécute correctement en tant que fichier en appelant sa copie locale à partir du notebook, en transmettant un paramètre permettant d'identifier le bucket de stockage créé précédemment, dans lequel sont stockées les données d'entrée pour ce job. Le même bucket sera utilisé pour stocker les fichiers de données de rapport produites par ce script.
Dans le notebook PySpark-analysis-file, ajoutez une nouvelle cellule à la fin, et collez-y le code suivant :
BUCKET_list = !gcloud info --format='value(config.project)'
BUCKET=BUCKET_list[0]
print('Writing to {}'.format(BUCKET))
!/opt/conda/miniconda3/bin/python spark_analysis.py --bucket=$BUCKET
Ce code suppose que vous avez suivi les instructions précédentes et créé un bucket Cloud Storage en utilisant l'ID du projet de cet atelier en tant que nom du bucket. Si vous avez utilisé un autre nom, modifiez ce code pour définir la variable BUCKET sur le nom que vous avez utilisé.
Ajoutez une nouvelle cellule à la fin du notebook, et collez-y le code suivant :
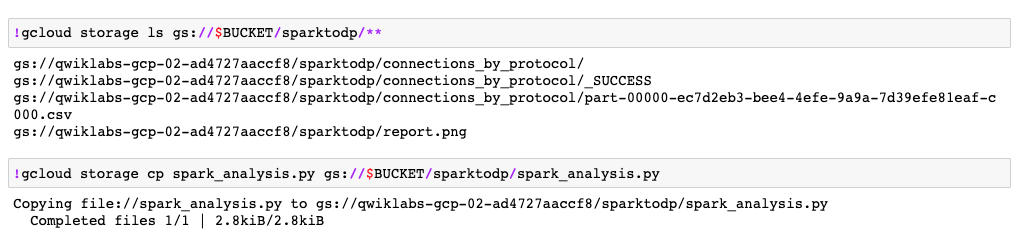
!gcloud storage ls gs://$BUCKET/sparktodp/**
Cette commande liste les fichiers de sortie du script qui ont été enregistrés dans votre bucket Cloud Storage.
Pour enregistrer une copie du fichier Python sur le stockage persistant, ajoutez une nouvelle cellule, et collez-y le code suivant :
Cliquez sur Cellule, puis sur Tout exécuter pour exécuter toutes les cellules du notebook.
Si le notebook crée et exécute correctement le fichier Python, vous devriez obtenir un résultat semblable à celui-ci pour les deux dernières cellules. Ceci indique que le script a été exécuté intégralement et que le résultat de l'exécution a été enregistré dans le bucket Cloud Storage que vous avez créé précédemment dans cet atelier.
Remarque : La cause d'erreur la plus probable à ce stade est la non-suppression de la directive matplotlib dans In [7]. Vérifiez que vous avez bien modifié toutes les cellules en respectant les instructions ci-dessus, sans omettre aucune étape.
Exécuter la tâche d'analyse à partir de Cloud Shell
Repassez sur Cloud Shell et copiez le script Python à partir de Cloud Storage de façon à pouvoir l'exécuter en tant que job Cloud Dataproc :
#!/bin/bash
gcloud dataproc jobs submit pyspark \
--cluster sparktodp \
--region {{{project_0.default_region | REGION }}} \
spark_analysis.py \
-- --bucket=$1
Appuyez sur CTRL+X, puis sur Y et sur Entrée pour quitter et enregistrer.
Rendez le script exécutable :
chmod +x submit_onejob.sh
Lancez le job d'analyse PySpark :
./submit_onejob.sh $PROJECT_ID
Dans l'onglet Cloud Console, accédez à la page Dataproc > Clusters si elle n'est pas déjà ouverte.
Cliquez sur Jobs (Tâches).
Cliquez sur nom de la tâche qui est répertoriée. Vous pouvez surveiller l'avancement sur cette page comme dans le Cloud Shell. Attendez que la tâche soit terminée.
Accédez au bucket de stockage et notez que le rapport de sortie /sparktodp/report.png comporte un horodatage mis à jour indiquant que la tâche autonome s'est effectuée correctement.
Le bucket de stockage utilisé par cette tâche pour le stockage des données d'entrée et de sortie est le bucket dont le nom correspond à l'ID de votre projet.
Accédez de nouveau à la page Dataproc > Clusters.
Sélectionnez le cluster sparktodp, puis cliquez sur Delete (Supprimer). Vous n'en avez plus besoin.
Cliquez sur CONFIRMER.
Fermez les onglets Jupyter de votre navigateur.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Cet atelier explique comment exécuter des tâches Apache Spark sur Cloud Dataproc.
Durée :
0 min de configuration
·
Accessible pendant 90 min
·
Terminé après 90 min


 ), puis sélectionnez IAM et administration > IAM.
), puis sélectionnez IAM et administration > IAM.
![gcs_bucket='[Your-Bucket-Name]'](https://cdn.qwiklabs.com/lxRwZFWWNgly1JKdY9s5JNVNwgW4rKxzYKwBIgkHlBw%3D)