Neste tutorial, você vai aprender a usar os recursos Wrangler e pipeline de dados no Cloud Data Fusion para limpar, transformar e processar dados de corridas de táxi e realizar análises mais detalhadas.
Conteúdo do laboratório
Neste laboratório, você vai aprender a:
conectar o Cloud Data Fusion a algumas fontes de dados;
aplicar transformações básicas;
mesclar duas fontes de dados;
gravar os dados em um coletor.
Introdução
Muitas vezes, é preciso realizar algumas etapas de pré-processamento para que analistas possam usar os dados e gerar insights, como ajustar os tipos de dados, remover anomalias e converter identificadores vagos em entradas mais significativas. O Cloud Data Fusion é um serviço para a criação eficiente de pipelines de dados de ETL/ELT. O Cloud Data Fusion usa clusters do Cloud Dataproc para fazer todas as transformações no pipeline.
Para mostrar como o Cloud Data Fusion funciona, usaremos neste tutorial uma parte do conjunto de dados de corridas de táxi TLC de Nova York no BigQuery.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Ative o Google Cloud Shell
O Google Cloud Shell é uma máquina virtual com ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud.
O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
No console do Cloud, clique no botão "Abrir o Cloud Shell" na barra de ferramentas superior direita.
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando você estiver conectado, já estará autenticado, e o projeto estará definido com seu PROJECT_ID. Exemplo:
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
Para listar o nome da conta ativa, use este comando:
Antes de começar a trabalhar no Google Cloud, veja se o projeto tem as permissões corretas no Identity and Access Management (IAM).
No console do Google Cloud, em Menu de navegação (), selecione IAM e administrador > IAM.
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que está no Menu de navegação > Visão geral do Cloud > Painel.
Observação: se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
No console do Google Cloud, em Menu de navegação, clique em Visão geral do Cloud > Painel.
Copie o número do projeto, por exemplo, 729328892908.
Em Menu de navegação, clique em IAM e administrador > IAM.
Clique em Permitir acesso, logo abaixo de Visualizar por principais na parte de cima da tabela de papéis.
Substitua {project-number} pelo número do seu projeto.
Em Papel, selecione Projeto (ou Básico) > Editor.
Clique em Save.
Tarefa 1: Como criar uma instância do Cloud Data Fusion
Confira as instruções detalhadas sobre como criar uma instância do Cloud Data Fusion neste guia. Estas são as etapas essenciais:
Para garantir que o ambiente do treinamento seja configurado corretamente, interrompa o funcionamento da API Data Fusion. Execute o comando abaixo no Cloud Shell. Essa operação leva alguns minutos.
gcloud services disable datafusion.googleapis.com
A saída vai mostrar uma mensagem de que a operação foi concluída com sucesso.
Agora reconecte a API Data Fusion.
No Console do Google Cloud, digite API Data Fusion do Cloud na barra de pesquisa. Clique no resultado retornado para API Data Fusion.
Na página da API, clique em Ativar.
Quando a API estiver ativada outra vez, a página vai ser atualizada para mostrar a opção "Desativar" e outros detalhes sobre o uso e o desempenho da API.
No Menu de navegação, selecione Data Fusion.
Para criar uma instância do Cloud Data Fusion, clique em Criar uma instância.
Digite um nome para a instância.
Selecione Basic para o tipo da edição.
Na seção Autorização, clique em Conceder permissão.
Mantenha as configurações padrão dos outros campos e clique em Criar.
Observação: a criação da instância demora cerca de 15 minutos.
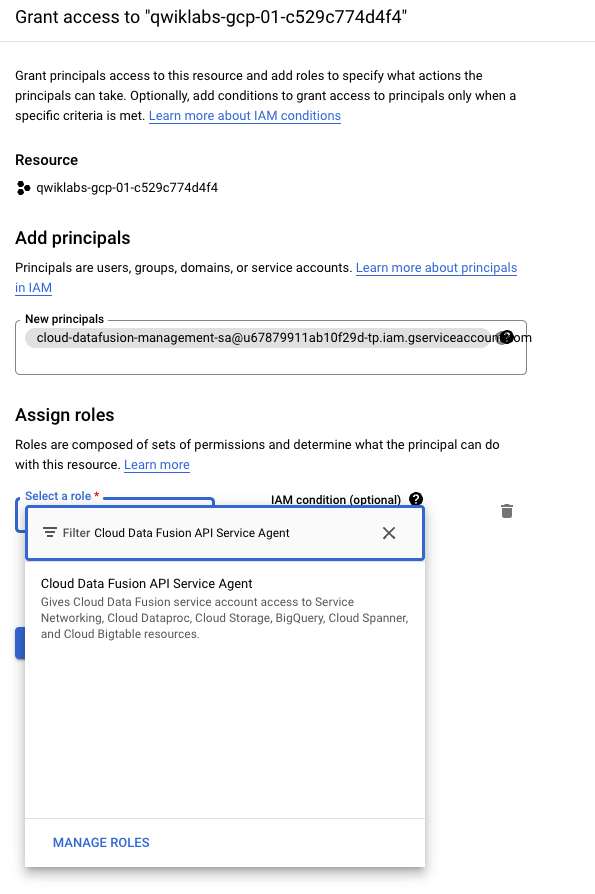
Quando a instância estiver pronta, dê permissão para a conta de serviço associada acessar seu projeto. Clique no nome da instância para abrir a página com os detalhes dela.
Copie a conta de serviço para a área de transferência.
No Console do GCP, acesse IAM e administrador > IAM.
Na página "Permissões do IAM", clique em Conceder acesso e adicione a conta de serviço que você copiou como um novo principal. Depois, atribua à conta o papel Agente de serviço da API Data Fusion.
Clique em Salvar.
Tarefa 2: Como carregar os dados
Você vai poder usar o Cloud Data Fusion assim que a instância ficar pronta, mas precisa concluir algumas etapas antes de iniciar a ingestão dos dados.
Neste exemplo, o Cloud Data Fusion lê os dados que estão em um bucket de armazenamento. No console do Cloud Shell, execute os seguintes comandos para criar um bucket e copiar os dados relevantes para ele:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
gcloud storage cp gs://cloud-training/OCBL017/ny-taxi-2018-sample.csv gs://$BUCKET
Observação: o nome do bucket criado é o ID do projeto.
Na linha de comando, execute o comando abaixo para criar o bucket que vai armazenar temporariamente os itens criados pelo Cloud Data Fusion:
gcloud storage buckets create gs://$BUCKET-temp
Observação: o nome do bucket criado é o id do projeto seguido por "-temp".
Clique no link Visualizar instância na página das instâncias do Data Fusion ou na página de detalhes da instância. Clique em nome de usuário. Se o serviço oferecer um tour, clique em Agora não. Agora você está usando a interface do Cloud Data Fusion.
Observação: talvez seja necessário recarregar ou atualizar as páginas de UI do Cloud Fusion para acessar a página da instância.
O Wrangler é uma ferramenta visual e interativa que você pode usar para visualizar os efeitos das transformações em um pequeno subconjunto de dados, antes de aplicá-las a jobs grandes com processamento em paralelo no conjunto de dados inteiro. Na IU do Cloud Data Fusion, selecione Wrangler. O painel à esquerda mostra as conexões pré-configuradas para os dados, inclusive a conexão do Cloud Storage.
No GCS, selecione bucket padrão do Cloud Storage.
Clique no bucket que corresponde ao nome do seu projeto.
Selecione ny-taxi-2018-sample.csv. Os dados são carregados na tela do Wrangler, no formato de linhas e colunas.
Na janela Opções de análise, configure Usar a primeira linha como cabeçalho como verdadeiro. Os dados serão divididos em várias colunas.
Clique em Confirmar.
Tarefa 3: Como organizar os dados
Agora vamos fazer algumas transformações para analisar e organizar os dados das corridas de táxi.
Clique na seta para baixo ao lado da coluna trip_distance, selecione Mudar tipo de dados e clique em Ponto flutuante. Repita para a coluna total_amount.
Clique na seta para baixo ao lado da coluna pickup_location_id, selecione Mudar tipo de dados e clique em String.
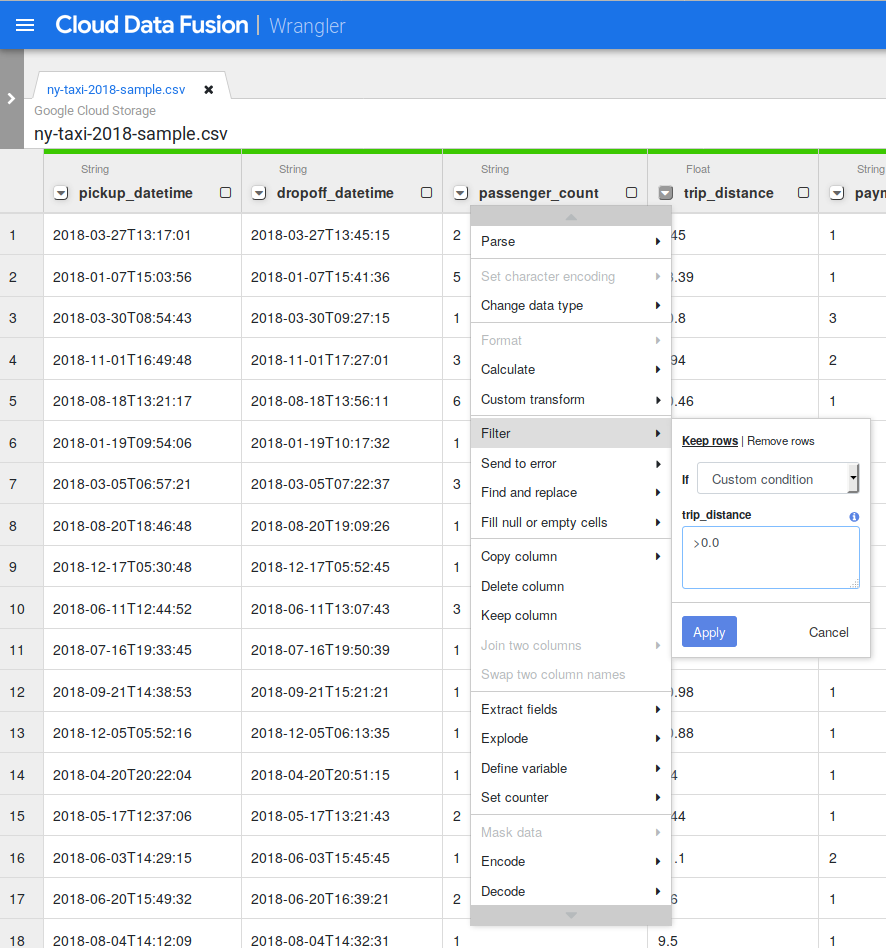
Se você analisar os dados com atenção, talvez encontre anomalias, como valores negativos para as distâncias das viagens. Use o Wrangler para filtrar esses valores. Clique na seta para baixo ao lado da coluna trip_distance e selecione Filtrar. Clique em Condição personalizada e digite >0.0
Clique em Aplicar.
Tarefa 4: Como criar o pipeline
Você fez a limpeza de dados básica e executou transformações em uma parte dos dados. Agora já pode criar um pipeline em lote para executar transformações no conjunto de dados inteiro.
O Cloud Data Fusion traduz seu pipeline criado visualmente em um programa do Apache Spark ou do MapReduce, que executa em paralelo transformações em um cluster temporário do Cloud Dataproc. Isso permite executar transformações complexas com facilidade em grandes quantidades de dados e de modo escalonável e confiável, sem ter que lidar com infraestruturas e tecnologias.
Na parte de cima à direita da IU do Google Cloud Fusion, clique em Criar pipeline.
Na caixa de diálogo que aparece, selecione Pipeline em lote.
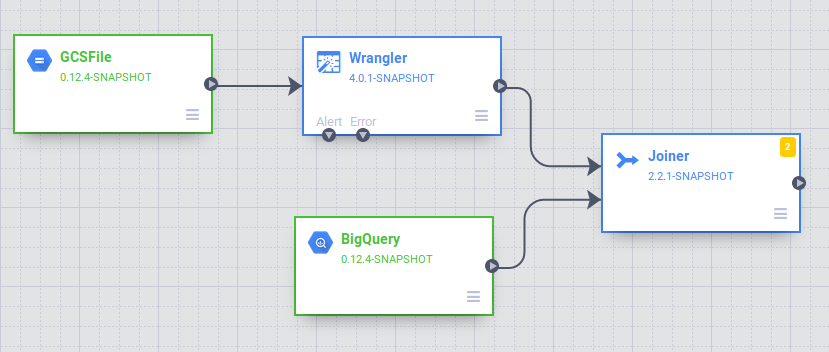
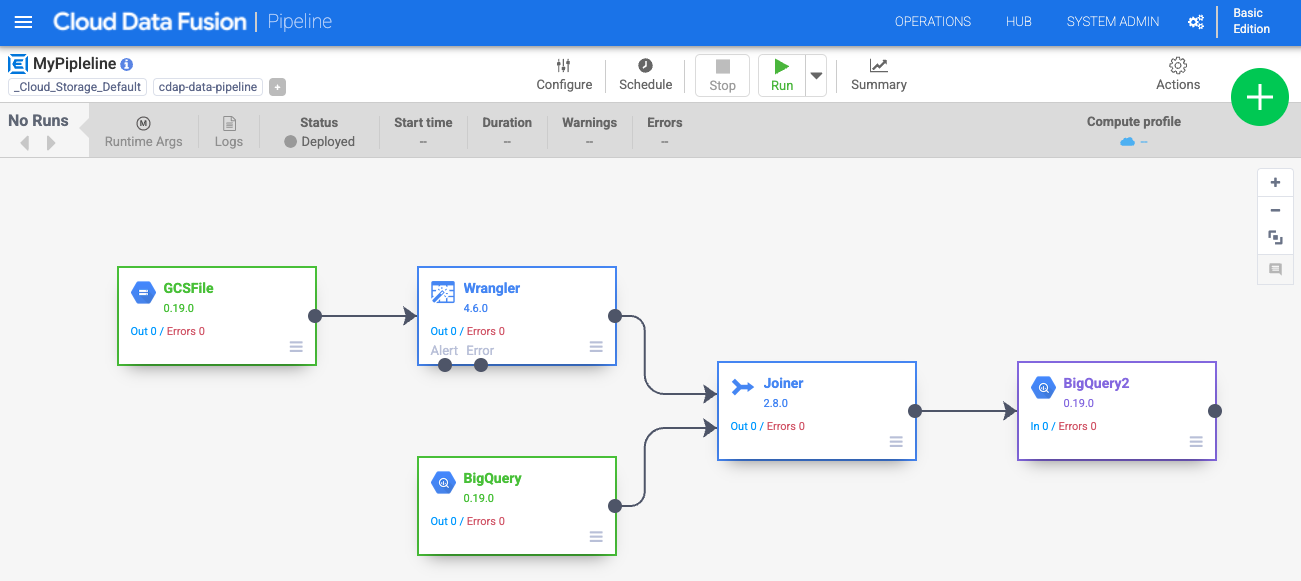
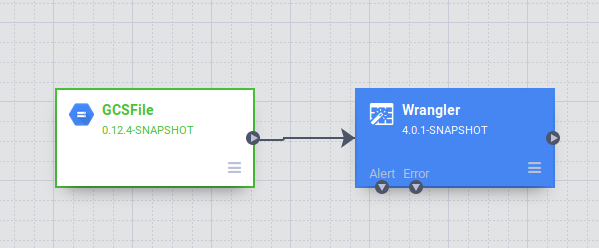
Na interface do Data pipelines, você verá um nó de origem do GCSFile conectado a um nó do Wrangler. O nó do Wrangler contém todas as transformações que você aplicou à visualização do Wrangler capturadas como gramática diretiva. Passe o cursor sobre o nó do Wrangler e selecione Propriedades.
.
Para aplicar mais transformações nesta etapa, clique no botão Wrangle. Exclua a coluna extra clicando no ícone de lixeira vermelho ao lado dela. Clique em Validar no canto de cima à direita para verificar se há erros. Para fechar o Wrangler, clique no X na parte de cima à direita.
Tarefa 5: Como adicionar uma fonte de dados
Os dados das corridas de táxi contêm colunas com valores que não são informações óbvias para um analista, como pickup_location_id. Você vai adicionar ao pipeline uma fonte de dados que associa os valores da coluna pickup_location_id aos nomes dos lugares correspondentes. Essas informações de referência serão armazenadas em uma tabela do BigQuery.
Na seção "Explorer" da IU do BigQuery, clique nos três pontos ao lado do ID do projeto do GCP, que começa com qwiklabs.
No menu que aparece, clique em Criar conjunto de dados.
No campo ID do conjunto de dados, digite trips.
Clique em Criar conjunto de dados.
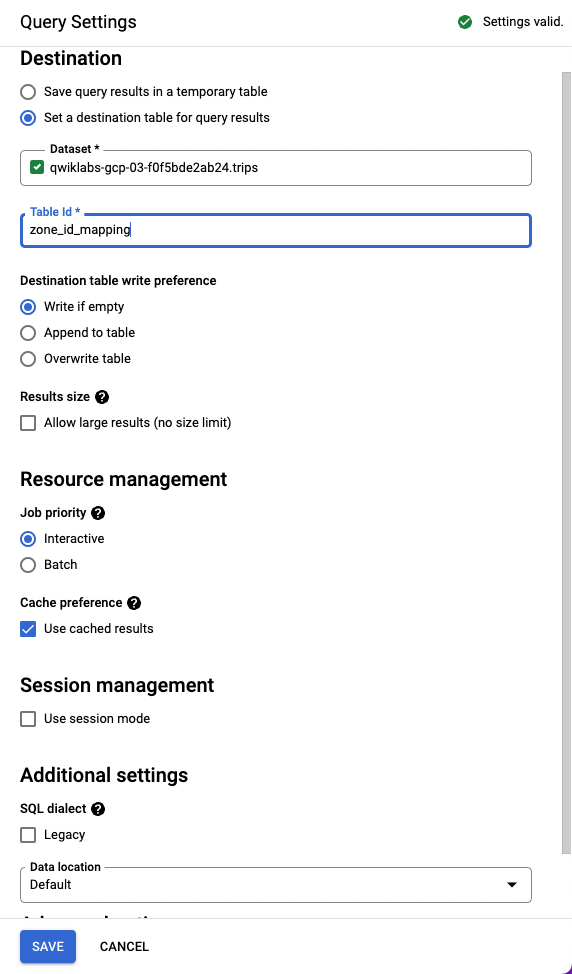
Para criar a tabela nesse novo conjunto de dados, selecione Mais > Configurações de consulta. Assim, a tabela pode ser acessada no Cloud Data Fusion.
Selecione a opção Definir uma tabela de destino para os resultados da consulta. Em Conjunto de dados, insira trips e selecione uma das opções do menu suspenso. Em ID da tabela, selecione zone_id_mapping. Clique em Salvar.
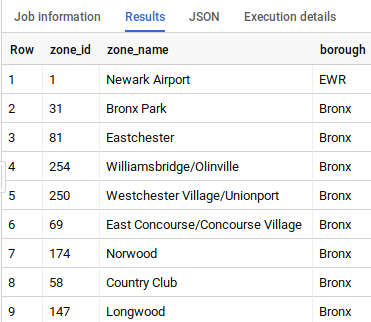
Digite a consulta a seguir no Editor de consultas e clique em Executar:
SELECT
zone_id,
zone_name,
borough
FROM
`bigquery-public-data.new_york_taxi_trips.taxi_zone_geom`
Esta tabela relaciona os valores de zone_id com os nomes das zonas e os municípios correspondentes.
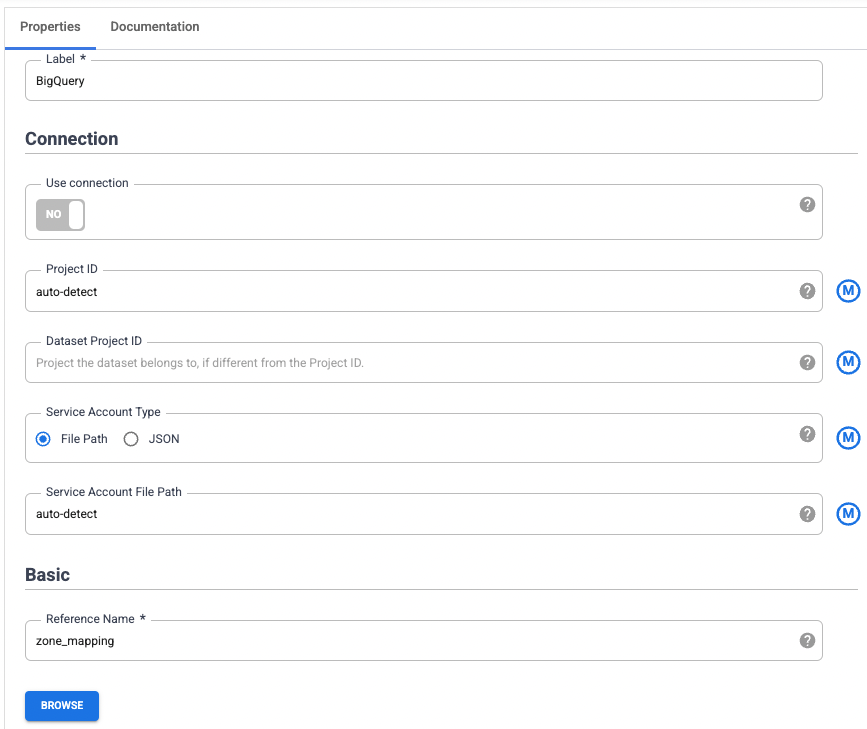
Agora você vai adicionar uma origem ao pipeline para acessar esta tabela do BigQuery. Volte para a guia em que o Cloud Data Fusion está aberto. Na paleta de plug-ins à esquerda, selecione BigQuery na seção Origem. Um nó de origem do BigQuery aparece na tela com os outros dois nós.
Passe o cursor sobre o nó de origem do BigQuery e clique em Propriedades.
Para definir o Nome da referência, digite zone_mapping, que é usado para identificar valores dessa fonte de dados.
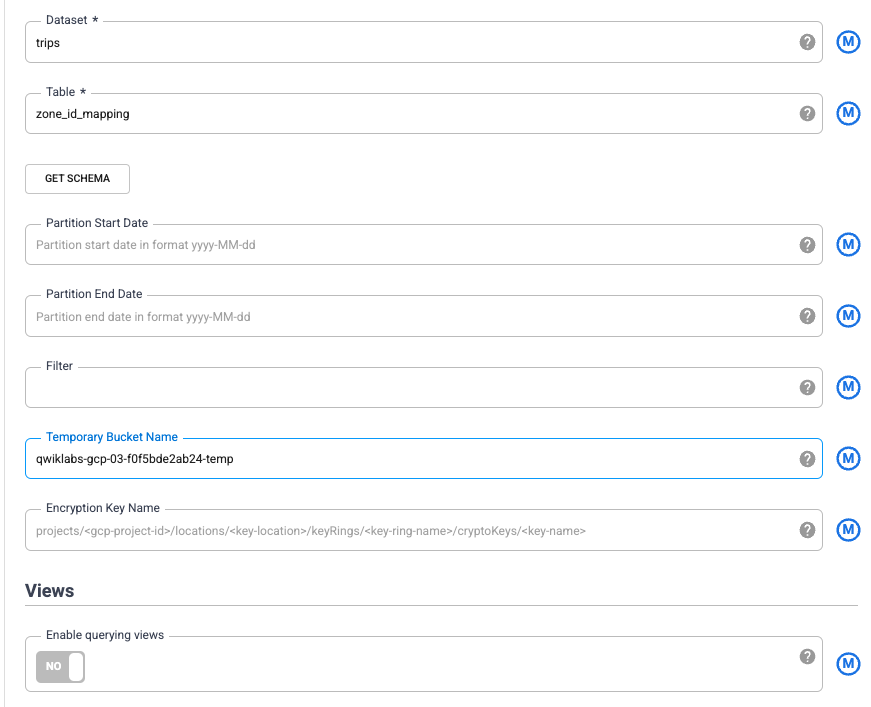
Os campos Conjunto de dados e Tabela correspondem ao conjunto de dados e à tabela que você acabou de configurar no BigQuery: trips e zone_id_mapping. Em Nome do bucket temporário, digite o nome do projeto seguido de "--temp", que corresponde ao bucket que você criou na tarefa 2.
Para preencher o esquema dessa tabela no BigQuery, clique em Ver esquema. Os campos vão aparecer à direita do assistente.
Clique em Validar no canto de cima à direita para verificar se há erros. Para fechar a janela com as propriedades do BigQuery, clique no X na parte de cima à direita.
Tarefa 6: Como mesclar duas fontes de dados
Agora você já pode mesclar as duas fontes de dados (das corridas de táxi e com os nomes das zonas) para gerar uma saída mais significativa.
Na seção Analytics na paleta de plug-ins, escolha a opção Joiner. Um nó de Joiner aparece na tela.
Para conectar o nó do Wrangler e o nó do BigQuery ao nó do Joiner: arraste uma seta de conexão > na borda direita do nó de origem e solte no nó de destino.
Para configurar o nó do Joiner, que é semelhante à sintaxe usada com JOIN no SQL:
Clique em Propriedades no Joiner.
Mantenha o rótulo definido como Joiner.
Altere o Tipo de mesclagem para Interna.
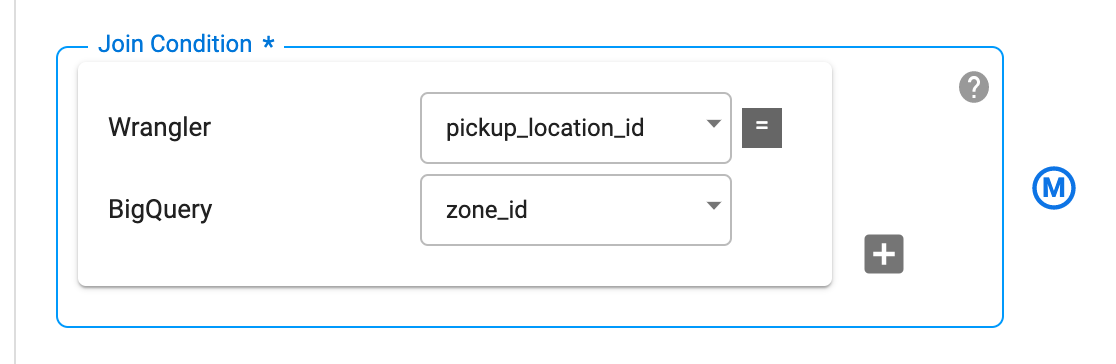
Defina a condição em Condição de mesclagem para mesclar a coluna pickup_location_id no nó do Wrangler com a coluna zone_id no nó do BigQuery.
Para gerar o esquema da mesclagem, clique em Gerar esquema.
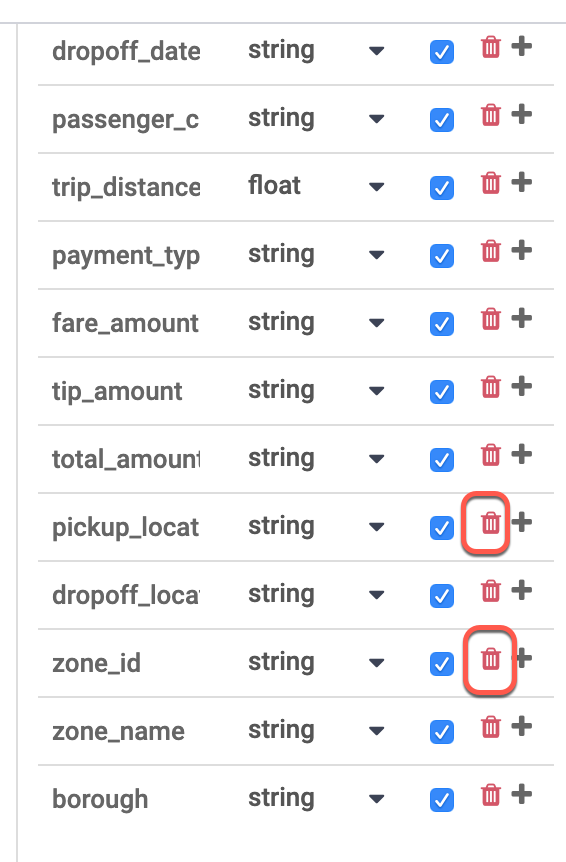
Na tabela Esquema de saída à direita, remova os campos zone_id e pickup_location_id usando o ícone de lixeira vermelho.
Clique em Validar no canto de cima à direita para verificar se há erros. Para fechar a janela, clique no X na parte de cima à direita.
Tarefa 7: Como armazenar o resultado no BigQuery
Você vai armazenar o resultado do pipeline em uma tabela do BigQuery. O local onde os dados serão armazenados é chamado de coletor.
Na seção Coletor da paleta de plug-ins, escolha BigQuery.
Conecte o nó do Joiner ao nó do BigQuery. Arraste uma seta de conexão > da extremidade direita do nó de origem e solte no nó de destino.
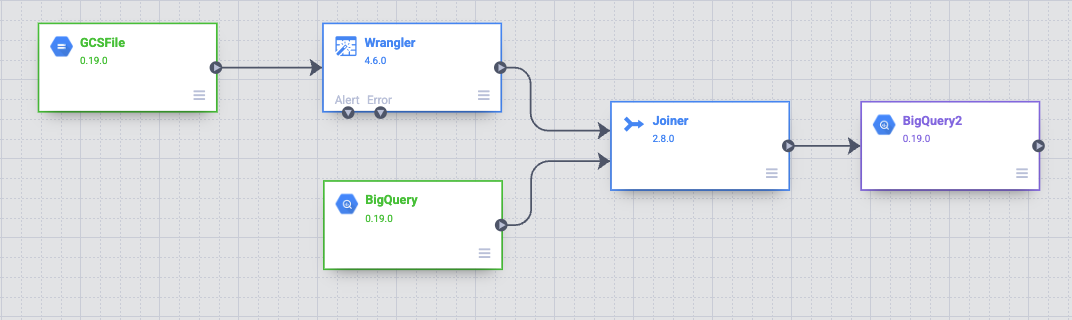
Abra o nó do BigQuery2 passando o cursor sobre ele e clicando em Propriedades. Configure o nó de acordo com a imagem abaixo. A configuração é parecida com a da origem atual do BigQuery. Digite bq_insert no campo Nome de referência, trips no campo Conjunto de dados e o nome do seu projeto seguido de "-temp" no campo Nome do bucket temporário. Os dados serão armazenados em uma nova tabela que será usada para executar o pipeline. No campo Tabela, insira trips_pickup_name.
Clique em Validar no canto de cima à direita para verificar se há erros. Para fechar a janela, clique no X na parte de cima à direita.
Tarefa 8: Como implantar e executar o pipeline
Você acaba de criar seu primeiro pipeline, que já pode ser implantado e executado.
No canto superior esquerdo da interface do Data Fusion, dê um nome para o pipeline e clique em Salvar.
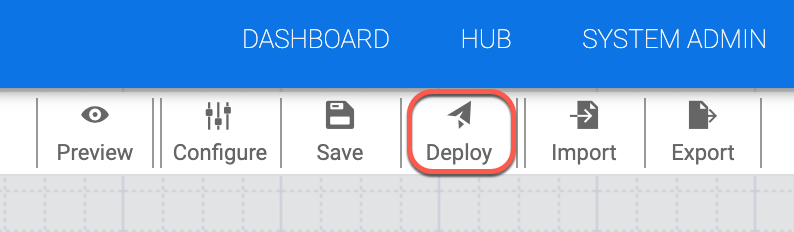
Agora implante o pipeline. Na parte de cima à direita da página, clique em Implantar.
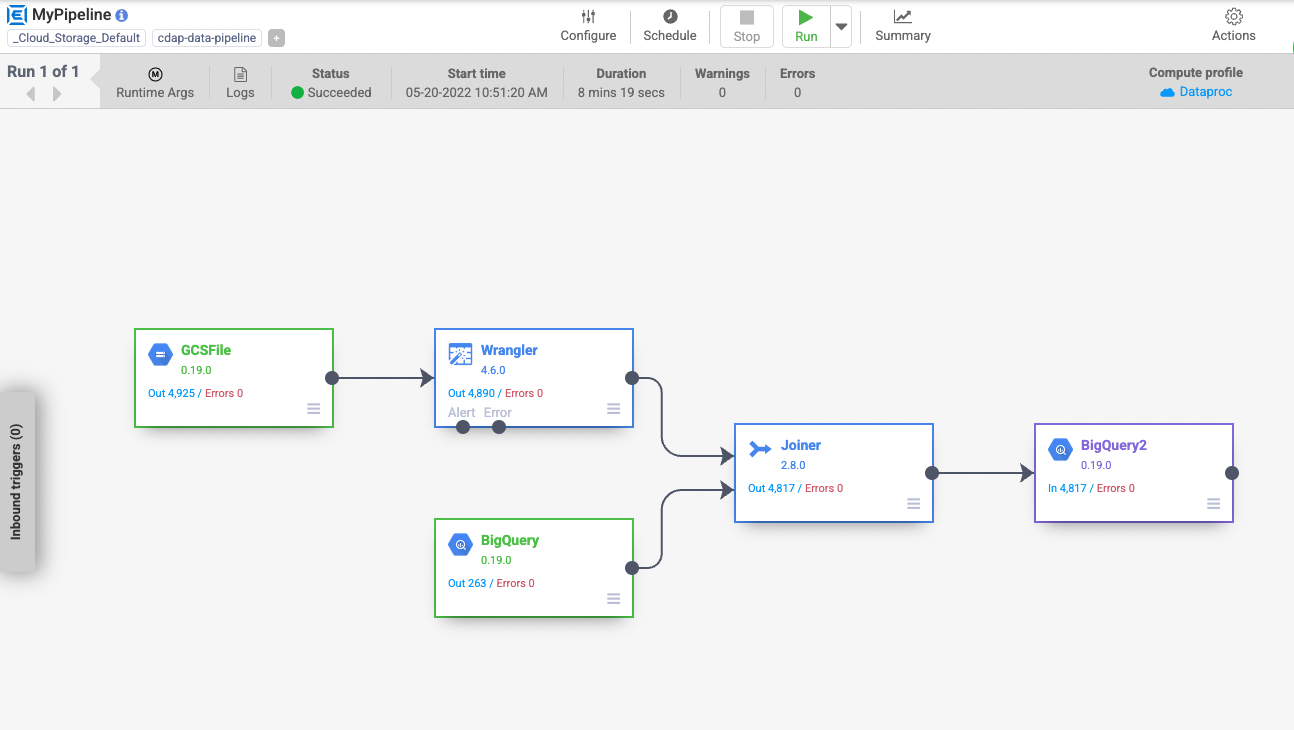
Na próxima tela, clique em Executar para iniciar o processamento dos dados.
Quando você executa um pipeline, o Cloud Data Fusion provisiona um cluster temporário do Cloud Dataproc, executa o pipeline e destrói o cluster. Isso pode levar alguns minutos. Veja que o status do pipeline muda de Provisionamento para Iniciando e de Iniciando para Em execução e, por fim, para Concluído nesse período.
Observação: a transição do pipeline pode levar de 10 a 15 minutos.
Tarefa 9: Como ver os resultados
Para ver os resultados depois da execução do pipeline:
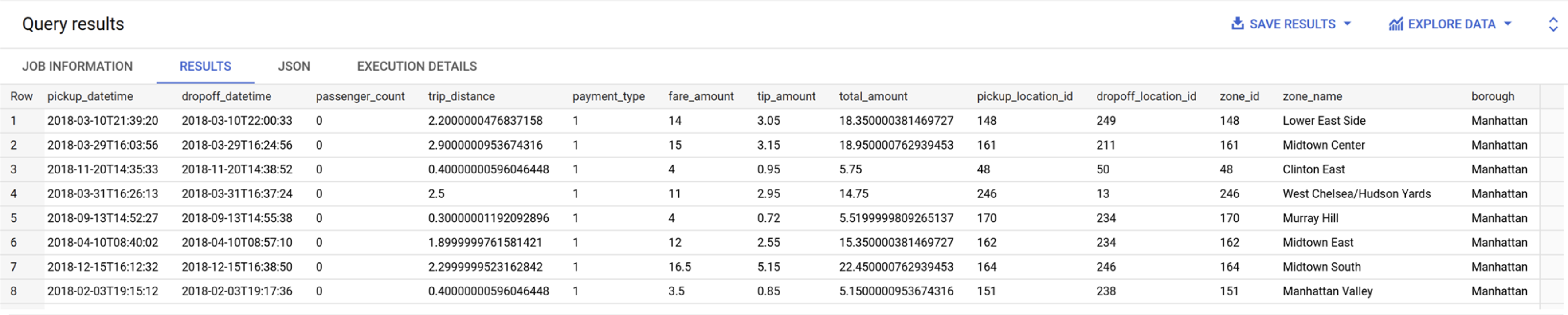
Volte para a guia em que o BigQuery está aberto. Execute a consulta abaixo para conferir os valores da tabela trips_pickup_name:
SELECT
*
FROM
`trips.trips_pickup_name`
RESULTADOS DO BIGQUERY
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste tutorial, você vai aprender a usar os recursos Wrangler e pipeline de dados no Cloud Data Fusion para limpar, transformar e processar dados de corridas de táxi e realizar análises mais detalhadas.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 150 minutos
·
Tempo para conclusão: 150 minutos


 ), selecione IAM e administrador > IAM.
), selecione IAM e administrador > IAM.
 .
.