Questo tutorial mostra come usare le funzionalità Wrangler e Pipeline di dati in Cloud Data Fusion per pulire, trasformare ed elaborare i dati sulle corse in taxi in modo da analizzarli più in dettaglio.
Cosa imparerai
In questo lab imparerai a:
Collegare Cloud Data Fusion a un paio di origini dati
Applicare le trasformazioni di base
Unire due origini dati
Scrivere i dati in un sink
Introduzione
Spesso, i dati devono passare attraverso una serie di fasi di pre-elaborazione prima che gli analisti possano sfruttarli per raccogliere insight. Ad esempio, potrebbe essere necessario modificare i tipi di dati, rimuovere le anomalie e convertire identificatori vaghi in voci più significative. Cloud Data Fusion è un servizio per creare in modo efficace pipeline di dati ETL/ELT. Cloud Data Fusion utilizza un cluster Cloud Dataproc per eseguire tutte le trasformazioni nella pipeline.
In questo tutorial viene mostrato un esempio di come usare Cloud Data Fusion sulla base di un subset di dati sulle corse dei taxi a New York, fornito dalla Taxi and Limousine Commission (TLC) e presente su BigQuery.
Configurazione e requisiti
Per ciascun lab, riceverai un nuovo progetto Google Cloud e un insieme di risorse per un periodo di tempo limitato senza alcun costo aggiuntivo.
Accedi a Qwiklabs utilizzando una finestra di navigazione in incognito.
Tieni presente la durata dell'accesso al lab (ad esempio, 1:15:00) e assicurati di finire entro quell'intervallo di tempo.
Non è disponibile una funzionalità di pausa. Se necessario, puoi riavviare il lab ma dovrai ricominciare dall'inizio.
Quando è tutto pronto, fai clic su Inizia lab.
Annota le tue credenziali del lab (Nome utente e Password). Le userai per accedere a Google Cloud Console.
Fai clic su Apri console Google.
Fai clic su Utilizza un altro account e copia/incolla le credenziali per questo lab nei prompt.
Se utilizzi altre credenziali, compariranno errori oppure ti verranno addebitati dei costi.
Accetta i termini e salta la pagina di ripristino delle risorse.
Attiva Google Cloud Shell
Google Cloud Shell è una macchina virtuale in cui sono caricati strumenti per sviluppatori. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud.
Google Cloud Shell fornisce l'accesso da riga di comando alle risorse Google Cloud.
Nella barra degli strumenti in alto a destra della console Cloud, fai clic sul pulsante Apri Cloud Shell.
Fai clic su Continua.
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Quando la connessione è attiva, l'autenticazione è già avvenuta e il progetto è impostato sul tuo PROJECT_ID. Ad esempio:
gcloud è lo strumento a riga di comando di Google Cloud. È preinstallato su Cloud Shell e supporta il completamento.
Puoi visualizzare il nome dell'account attivo con questo comando:
Prima di iniziare il tuo lavoro su Google Cloud, devi assicurarti che il tuo progetto disponga delle autorizzazioni corrette in Identity and Access Management (IAM).
Nella console Google Cloud, nel menu di navigazione (), seleziona IAM e amministrazione > IAM.
Conferma che l'account di servizio di computing predefinito {project-number}-compute@developer.gserviceaccount.com sia presente e che abbia il ruolo di editor assegnato. Il prefisso dell'account è il numero del progetto, che puoi trovare in Menu di navigazione > Panoramica di Cloud > Dashboard
Nota: se l'account non è presente in IAM o non dispone del ruolo editor, attieniti alla procedura riportata di seguito per assegnare il ruolo richiesto.
Nel menu di navigazione della console Google Cloud, fai clic su Panoramica di Cloud > Dashboard.
Copia il numero del progetto (es. 729328892908).
Nel menu di navigazione, seleziona IAM e amministrazione > IAM.
Nella parte superiore della tabella dei ruoli, sotto Visualizza per entità, fai clic su Concedi accesso.
Per garantire che l'ambiente di apprendimento sia configurato correttamente, devi prima arrestare e riavviare l'API Cloud Data Fusion. Esegui il comando in basso in Cloud Shell. Il completamento dell'operazione richiede alcuni minuti.
gcloud services disable datafusion.googleapis.com
L'output indica che l'operazione è riuscita.
Riavvia la connessione all'API Cloud Data Fusion.
Nella console Google Cloud, inserisci API Cloud Data Fusion nella barra di ricerca in alto. Fai clic sul risultato per l'API Cloud Data Fusion.
Fai clic su Abilita nella pagina che viene caricata.
Quando l'API è stata nuovamente abilitata, la pagina verrà aggiornata e mostrerà l'opzione per disabilitare l'API, insieme ad altri dettagli su uso e rendimento dell'API.
Nel Menu di navigazione, seleziona Data Fusion.
Per creare un'istanza Cloud Data Fusion, fai clic su Crea un'istanza.
Inserisci un nome per l'istanza.
Seleziona Base per il tipo di edizione.
Nella sezione Autorizzazione, fai clic su Concedi autorizzazione.
Lascia invariati i valori predefiniti degli altri campi e fai clic su Crea.
Nota: la creazione dell'istanza può richiedere circa 15 minuti.
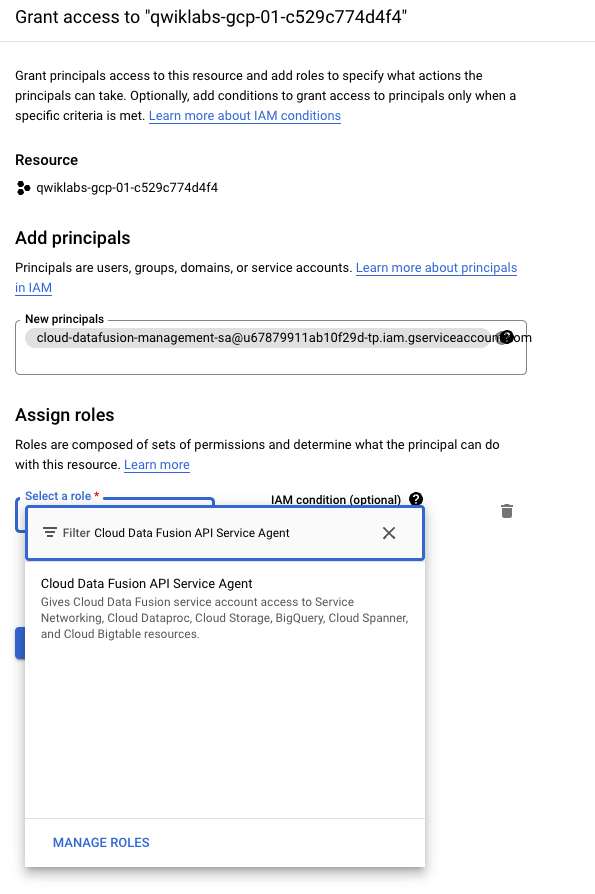
Una volta creata l'istanza, è necessario un ulteriore passaggio per concedere al service account associato le autorizzazioni per l'istanza nel progetto. Vai alla pagina dei dettagli dell'istanza facendo clic sul nome dell'istanza.
Copia il service account negli appunti.
Nella console Google Cloud, vai a IAM e amministrazione > IAM.
Nella pagina Autorizzazioni IAM, fai clic su +Concedi accesso, aggiungi il service account che hai copiato in precedenza come nuova entità e concedi il ruolo Cloud Data Fusion API Service Agent.
Fai clic su Salva.
Attività 2: carica i dati
Quando l'istanza Cloud Data Fusion è attiva e in esecuzione, puoi iniziare a utilizzare Cloud Data Fusion. Tuttavia, prima che Cloud Data Fusion possa iniziare ad importare i dati, devi eseguire alcuni passaggi preliminari.
In questo esempio, Cloud Data Fusion leggerà i dati da un bucket di archiviazione. Nella console di Cloud Shell esegui i comandi riportati di seguito per creare un nuovo bucket, poi copia i dati pertinenti al suo interno:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
gcloud storage cp gs://cloud-training/OCBL017/ny-taxi-2018-sample.csv gs://$BUCKET
Nota: il nome del bucket creato corrisponde all'ID del progetto.
Nella riga di comando, esegui il comando seguente per generare un bucket per gli elementi di archiviazione temporanei che Cloud Data Fusion creerà:
gcloud storage buckets create gs://$BUCKET-temp
Nota: il nome del bucket creato corrisponde all'ID del progetto, seguito da "-temp".
Fai clic sul link Visualizza istanza nella pagina delle istanze di Data Fusion o in quella dei dettagli di un'istanza. Fai clic su nome utente. Se ti viene chiesto di fare un tour del servizio, fai clic su No, grazie. A questo punto dovresti essere nella UI di Cloud Data Fusion.
Nota: potresti dover ricaricare o aggiornare le pagine della UI di Cloud Fusion per consentire il caricamento rapido della pagina.
Wrangler è uno strumento visivo interattivo che ti consente di vedere gli effetti delle trasformazioni su un piccolo subset di dati prima di eseguire grandi job di elaborazione parallela sull'intero set di dati. Scegli Wrangler nella UI di Cloud Data Fusion. A sinistra c'è un riquadro con le connessioni preconfigurate ai tuoi dati, inclusa quella a Cloud Storage.
In GCS, seleziona Bucket Cloud Storage predefinito.
Fai clic sul bucket corrispondente al nome del tuo progetto.
Seleziona ny-taxi-2018-sample.csv. I dati vengono caricati nella schermata Wrangler in formato riga/colonna.
Nella finestra Parsing Options (Opzioni di analisi), imposta Use First Row as Header (Usa la prima riga per l'intestazione) su True. I dati vengono suddivisi in più colonne.
Fai clic su Conferma.
Attività 3: pulisci i dati
Ora devi eseguire alcune trasformazioni per analizzare e pulire i dati sui taxi.
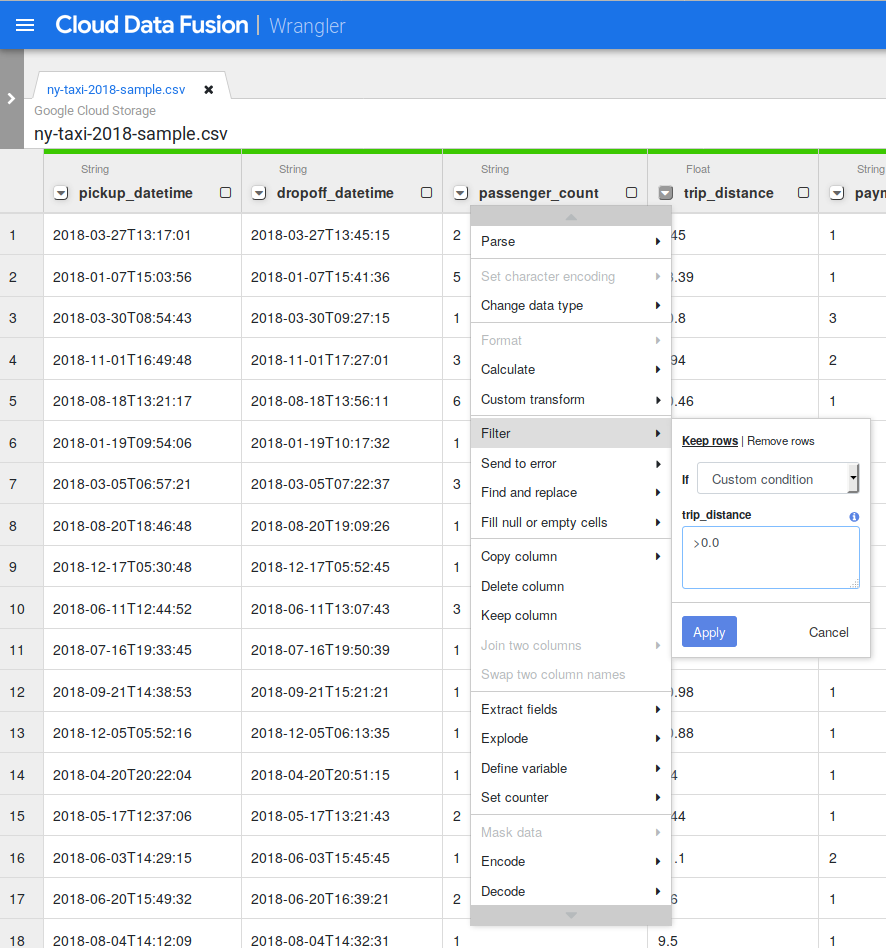
Fai clic sulla Freccia giù accanto alla colonna trip_distance, seleziona Cambia tipo di dati e fai clic su In virgola mobile. Ripeti questa operazione per la colonna total_amount.
Fai clic sulla Freccia giù accanto alla colonna pickup_location_id, seleziona Cambia tipo di dati e fai clic su Stringa.
Se guardi attentamente i dati, potresti trovare alcune anomalie, ad esempio distanze delle corse con valori negativi. Per evitarli, escludili in Wrangler. Fai clic sulla Freccia giù accanto alla colonna trip_distance e seleziona Filtro. Fai clic sulla Condizione personalizzata "if" e inserisci >0.0
Fai clic su Applica.
Attività 4: crea la pipeline
Hai completato la pulizia dei dati di base e hai eseguito alcune trasformazioni su un subset di dati. Ora puoi creare una pipeline batch per eseguire trasformazioni su tutti i tuoi dati.
Cloud Data Fusion converte la pipeline creata visivamente in un programma Apache Spark o MapReduce che esegue trasformazioni su un cluster Cloud Dataproc temporaneo in parallelo. Ciò consente di eseguire facilmente trasformazioni complesse su grandi quantità di dati in modo scalabile e affidabile, senza troppe complicazioni in termini di infrastruttura e tecnologia.
Nell'angolo superiore destro della UI di Google Cloud Fusion, fai clic su Crea una pipeline.
Nella finestra di dialogo visualizzata, seleziona Pipeline batch.
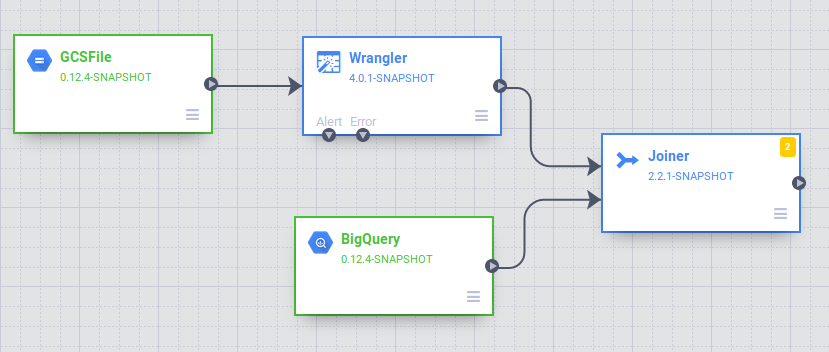
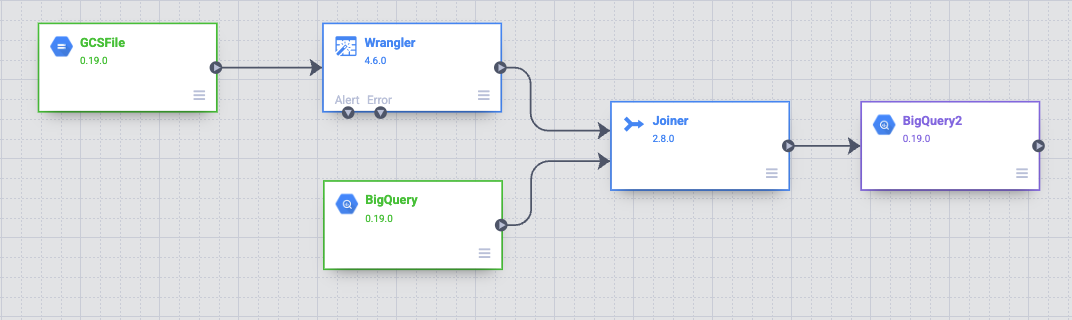
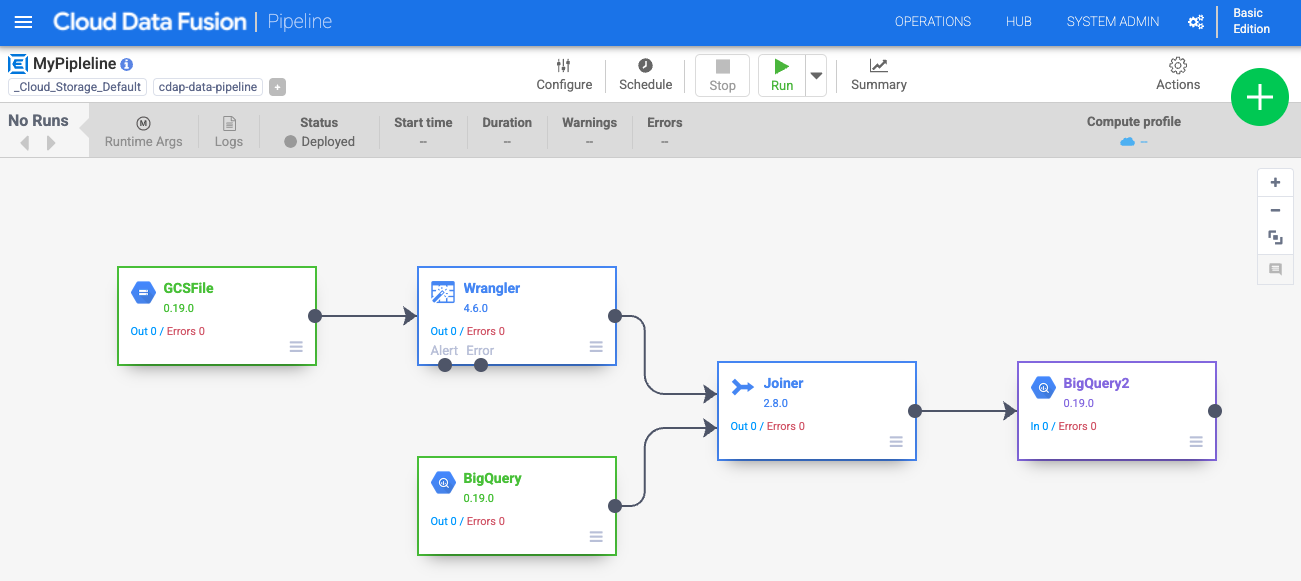
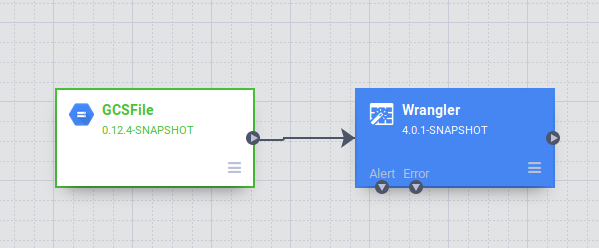
Nella UI di Data Pipelines, vedrai un nodo di origine GCSFile connesso a un nodo Wrangler. Il nodo Wrangler contiene tutte le trasformazioni che hai applicato nella vista Wrangler acquisite come grammatica di direttive. Passa il mouse sopra il nodo Wrangler e seleziona Proprietà.
.
In questa fase puoi applicare altre trasformazioni facendo clic sul pulsante Wrangle. Elimina la colonna extra premendo l'icona rossa del cestino accanto al nome della colonna. Fai clic su Convalida nell'angolo in alto a destra per verificare se esistono errori. Per chiudere lo strumento Wrangler, fai clic sul pulsante X nell'angolo in alto a destra.
Attività 5: aggiungi un'origine dati
I dati sui taxi contengono varie colonne (ad esempio pickup_location_id) che non sono immediatamente chiare per gli analisti. Devi aggiungere un'origine dati alla pipeline che mappa la colonna pickup_location_id a un nome di località pertinente. Le informazioni di mappatura vengono archiviate in una tabella BigQuery.
Apri la UI di BigQuery nella console Cloud in una scheda a parte. Fai clic su Fine nella pagina "Ti diamo il benvenuto in BigQuery nella console Cloud".
Nella sezione Explorer della UI di BigQuery, fai clic sui tre puntini accanto all'ID del progetto Google Cloud (inizia con qwiklabs).
Nel menu visualizzato, fai clic su Crea set di dati.
Nel campo ID set di dati, digita trips.
Fai clic su Crea set di dati.
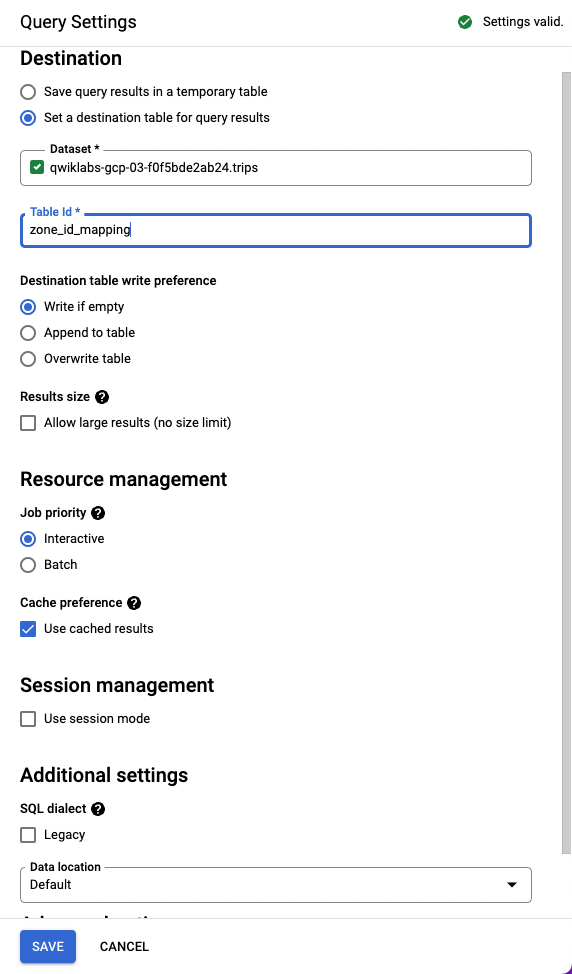
Per creare la tabella desiderata nel nuovo set di dati creato, vai ad Altro > Impostazioni query. Questa procedura ti permette di accedere alla tabella da Cloud Data Fusion.
Seleziona Imposta una tabella di destinazione per i risultati della query. Per Set di dati, inserisci trips ed effettua una selezione dal menu a discesa. Per ID tabella, inserisci zone_id_mapping. Fai clic su Salva.
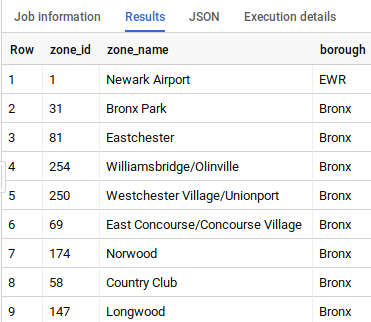
Inserisci la seguente query nell'editor e poi fai clic su Esegui:
SELECT
zone_id,
zone_name,
borough
FROM
`bigquery-public-data.new_york_taxi_trips.taxi_zone_geom`
Puoi vedere che questa tabella contiene la mappatura da zone_id al rispettivo nome e quartiere.
Adesso devi aggiungere un'origine nella pipeline per accedere a questa tabella BigQuery. Torna alla scheda in cui hai aperto Cloud Data Fusion e, dalla tavolozza Plug-in a sinistra, seleziona BigQuery nella sezione Origine. Nel canvas viene visualizzato un nodo di origine BigQuery insieme agli altri due nodi.
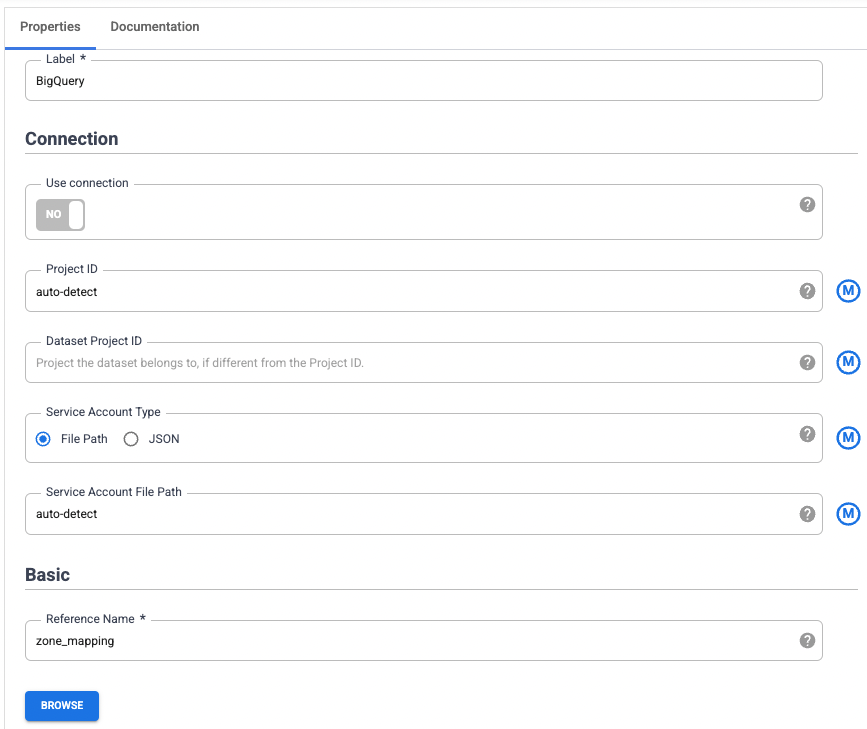
Passa il mouse sopra il nuovo nodo di origine BigQuery e fai clic su Proprietà.
Per configurare il Nome di riferimento, inserisci zone_mapping, utilizzato per identificare questa origine dati per scopi di derivazione.
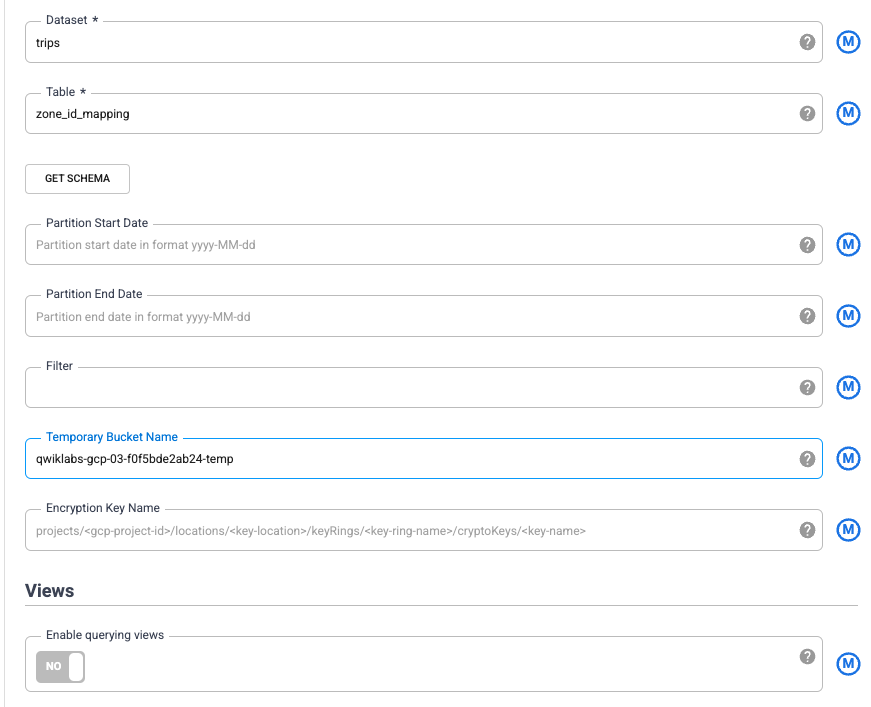
Le configurazioni del Set di dati e della Tabella BigQuery corrispondono al set di dati e alla tabella che hai configurato in BigQuery in precedenza: trips e zone_id_mapping. Per Nome bucket temporaneo, inserisci il nome del progetto seguito da "-temp", che corrisponde al bucket che hai creato nell'attività 2.
Per compilare lo schema di questa tabella da BigQuery, fai clic su Ottieni schema. I campi vengono visualizzati sul lato destro della procedura guidata.
Fai clic su Convalida nell'angolo in alto a destra per verificare se esistono errori. Per chiudere la finestra Proprietà di BigQuery, fai clic sul pulsante X nell'angolo in alto a destra.
Attività 6: unisci due origini
Ora puoi unire le due origini dati, ovvero i dati sulle corse dei taxi e i nomi delle zone, per generare risultati più significativi.
Nella sezione Analisi della tavolozza Plug-in, scegli Joiner. Nel canvas compare un nodo Joiner.
Collega il nodo Wrangler e il nodo BigQuery al nodo Joiner: trascina una freccia di connessione > sul bordo destro del nodo di origine e rilasciala sul nodo di destinazione.
Per configurare il nodo Joiner, simile a una sintassi di JOIN SQL:
Fai clic su Proprietà per il nodo Joiner.
Lascia invariata l'etichetta Joiner.
Cambia Join Type (Tipo di join) in Inner (Interno).
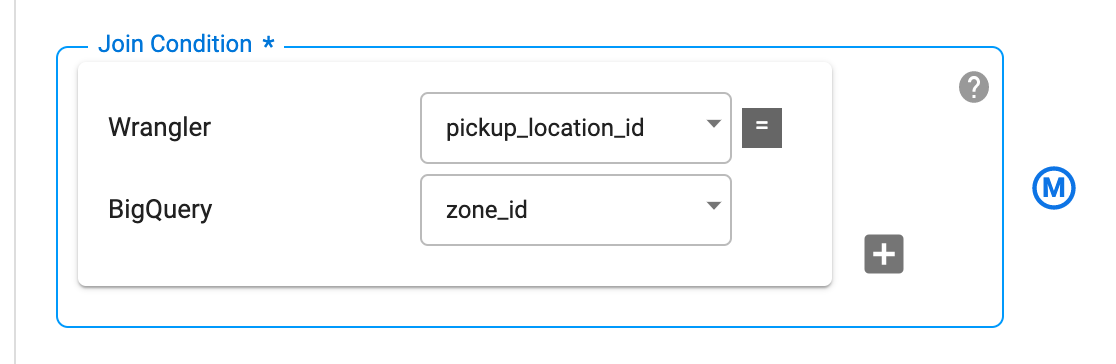
Imposta la Condizione di join in modo da unire la colonna pickup_location_id nel nodo Wrangler con la colonna zone_id nel nodo BigQuery.
Per generare lo schema dall'unione che risulta, fai clic su Ottieni schema.
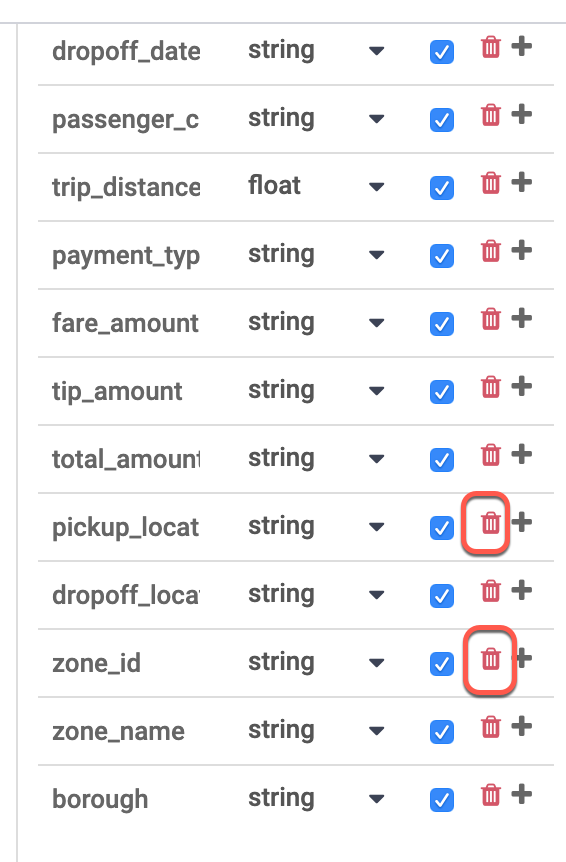
Nella tabella Output Schema (Schema di output) a destra, rimuovi i campi zone_id e pickup_location_id facendo clic sull'icona rossa del cestino.
Fai clic su Convalida nell'angolo in alto a destra per verificare se esistono errori. Per chiudere la finestra, fai clic sul pulsante X nell'angolo in alto a destra.
Attività 7: archivia l'output in BigQuery
Adesso devi archiviare i risultati della pipeline in una tabella BigQuery. I dati verranno archiviati in un sink.
Nella sezione Sink della tavolozza Plug-in, scegli BigQuery.
Collega il nodo Joiner al nodo BigQuery. Trascina una freccia di connessione > sul bordo destro del nodo di origine e rilasciala sul nodo di destinazione.
Passa il mouse sopra il nodo BigQuery2 per aprirlo e fai clic su Proprietà. Ora devi configurare il nodo come descritto di seguito. Userai una configurazione simile a quella dell'origine BigQuery esistente. Specifica bq_insert per il campo Nome di riferimento, poi usa trips per il Set di dati e il nome del tuo progetto seguito da "-temp" come Nome bucket temporaneo. Scriverai in una nuova tabella che verrà creata per l'esecuzione di questa pipeline. Nel campo Tabella, inserisci trips_pickup_name.
Fai clic su Convalida nell'angolo in alto a destra per verificare se esistono errori. Per chiudere la finestra, fai clic sul pulsante X nell'angolo in alto a destra.
Attività 8: esegui il deployment della pipeline ed eseguila
A questo punto hai creato la tua prima pipeline. Ora puoi eseguirne il deployment ed eseguirla.
Assegna un nome alla pipeline nell'angolo in alto a sinistra della UI di Data Fusion e fai clic su Salva.
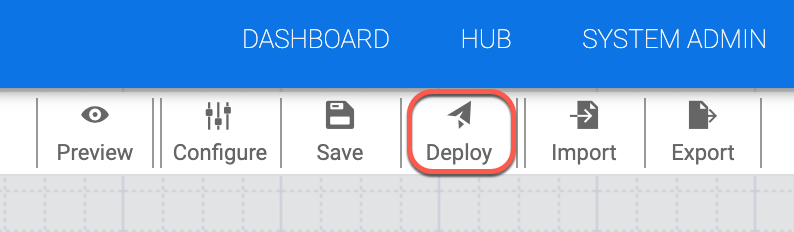
Ora devi eseguire il deployment della pipeline. Nell'angolo in alto a destra della pagina, fai clic su Esegui il deployment.
Nella schermata successiva, fai clic su Esegui per avviare l'elaborazione dei dati.
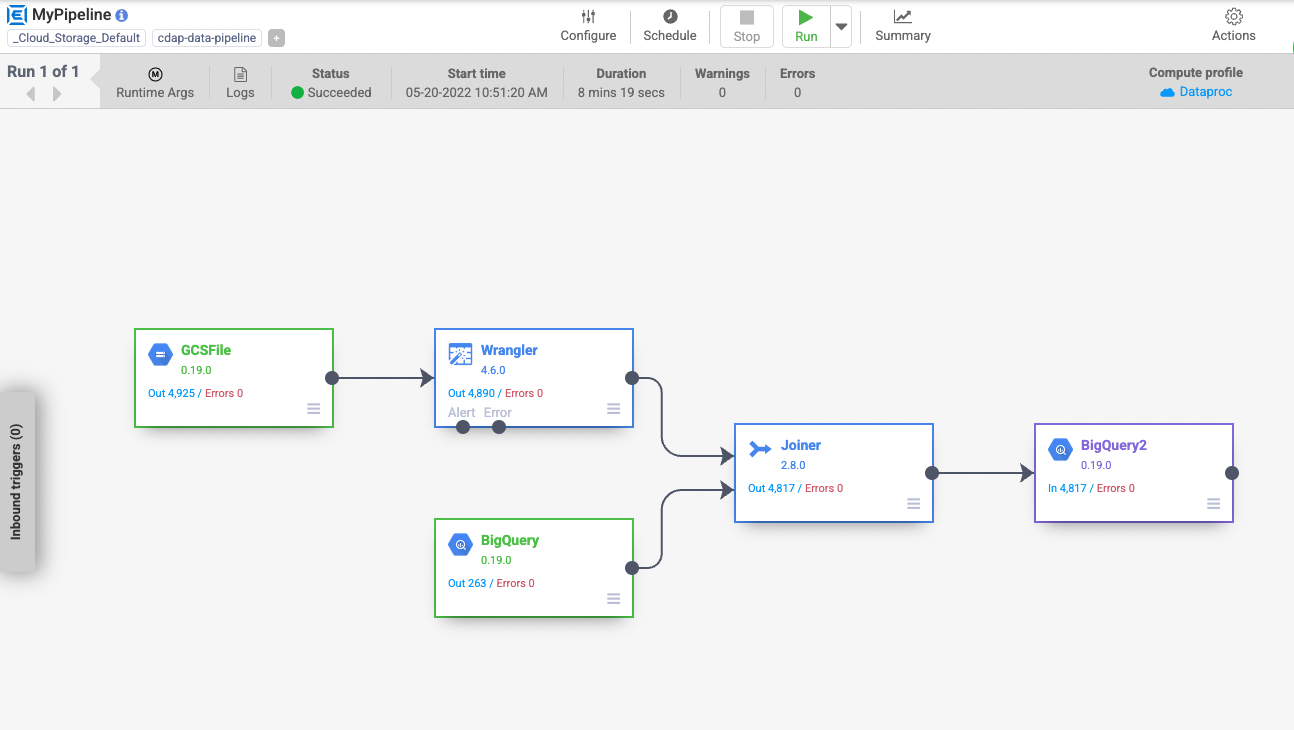
Quando esegui una pipeline, Cloud Data Fusion esegue il provisioning di un cluster Cloud Dataproc temporaneo, esegue la pipeline e poi rimuove il cluster. L'operazione potrebbe richiedere alcuni minuti. In questo periodo puoi osservare il passaggio dello stato della pipeline da In fase di provisioning a In fase di avvio e da In fase di avvio a In esecuzione e poi a Operazione.
Nota: il completamento della transizione della pipeline potrebbe richiedere 10-15 minuti.
Attività 9: visualizza i risultati
Per visualizzare i risultati dopo l'esecuzione della pipeline:
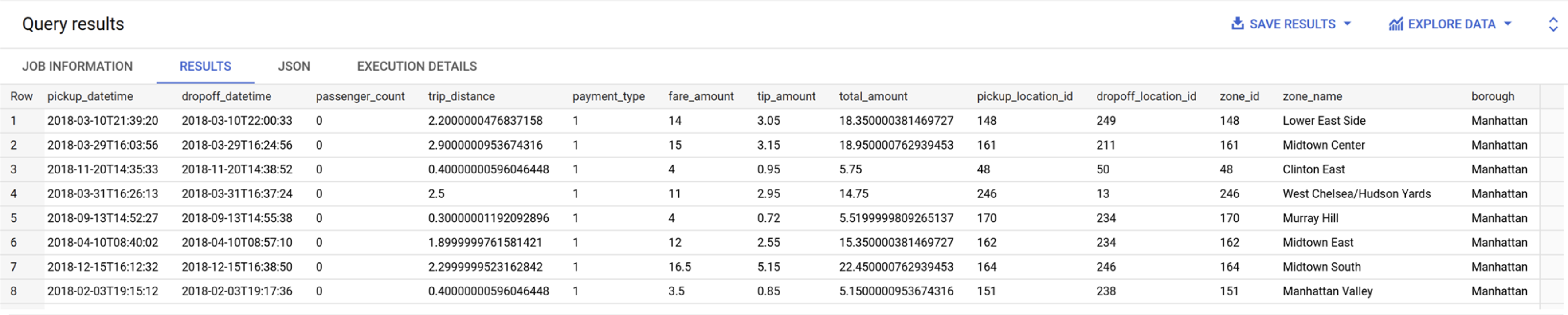
Torna alla scheda in cui hai aperto BigQuery. Esegui la query in basso per vedere i valori nella tabella trips_pickup_name:
SELECT
*
FROM
`trips.trips_pickup_name`
BQ RESULTS
Termina il lab
Una volta completato il lab, fai clic su Termina lab. Google Cloud Skills Boost rimuove le risorse che hai utilizzato ed esegue la pulizia dell'account.
Avrai la possibilità di inserire una valutazione in merito alla tua esperienza. Seleziona il numero di stelle applicabile, inserisci un commento, quindi fai clic su Invia.
Il numero di stelle corrisponde alle seguenti valutazioni:
1 stella = molto insoddisfatto
2 stelle = insoddisfatto
3 stelle = esperienza neutra
4 stelle = soddisfatto
5 stelle = molto soddisfatto
Se non vuoi lasciare un feedback, chiudi la finestra di dialogo.
Per feedback, suggerimenti o correzioni, utilizza la scheda Assistenza.
Copyright 2020 Google LLC Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.
I lab creano un progetto e risorse Google Cloud per un periodo di tempo prestabilito
I lab hanno un limite di tempo e non possono essere messi in pausa. Se termini il lab, dovrai ricominciare dall'inizio.
In alto a sinistra dello schermo, fai clic su Inizia il lab per iniziare
Utilizza la navigazione privata
Copia il nome utente e la password forniti per il lab
Fai clic su Apri console in modalità privata
Accedi alla console
Accedi utilizzando le tue credenziali del lab. L'utilizzo di altre credenziali potrebbe causare errori oppure l'addebito di costi.
Accetta i termini e salta la pagina di ripristino delle risorse
Non fare clic su Termina lab a meno che tu non abbia terminato il lab o non voglia riavviarlo, perché il tuo lavoro verrà eliminato e il progetto verrà rimosso
Questi contenuti non sono al momento disponibili
Ti invieremo una notifica via email quando sarà disponibile
Bene.
Ti contatteremo via email non appena sarà disponibile
Un lab alla volta
Conferma per terminare tutti i lab esistenti e iniziare questo
Utilizza la navigazione privata per eseguire il lab
Utilizza una finestra del browser in incognito o privata per eseguire questo lab. In questo modo eviterai eventuali conflitti tra il tuo account personale e l'account Studente, che potrebbero causare addebiti aggiuntivi sul tuo account personale.
Questo tutorial mostra come usare le funzionalità Wrangler e Pipeline di dati in Cloud Data Fusion per pulire, trasformare ed elaborare i dati sulle corse in taxi in modo da analizzarli più in dettaglio.
Durata:
Configurazione in 0 m
·
Accesso da 150 m
·
Completamento in 150 m


 ), seleziona IAM e amministrazione > IAM.
), seleziona IAM e amministrazione > IAM.
 .
.