Ce tutoriel explique comment réaliser des analyses plus approfondies à l'aide des fonctionnalités Wrangler et Data pipelines de Cloud Data Fusion. Nous les utiliserons ici pour nettoyer, transformer et traiter des données sur des courses de taxis.
Objectifs
Au cours de cet atelier, vous allez :
Connecter Cloud Data Fusion à plusieurs sources de données
Appliquer des transformations de base
Effectuer une jointure de deux sources de données
Écrire des données dans un récepteur
Introduction
Les données doivent parfois passer par plusieurs étapes de prétraitement avant que les analystes puissent en tirer des insights. Il peut être nécessaire d'ajuster les types de données, de supprimer des anomalies ou de remplacer des identifiants peu précis par des noms plus explicites. Cloud Data Fusion est un service qui permet de créer efficacement des pipelines de données ETL/ELT. Cloud Data Fusion effectue toutes les transformations du pipeline à l'aide du cluster Cloud Dataproc.
Dans ce tutoriel, vous allez vous familiariser avec Cloud Data Fusion grâce à un sous-ensemble de données BigQuery sur les courses des taxis TLC de New York.
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Qwiklabs dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à Google Cloud Console.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Activer Google Cloud Shell
Google Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud.
Google Cloud Shell vous permet d'accéder à vos ressources Google Cloud grâce à une ligne de commande.
Dans la barre d'outils située en haut à droite dans la console Cloud, cliquez sur le bouton "Ouvrir Cloud Shell".
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Par exemple :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project =
Exemple de résultat :
[core]
project = qwiklabs-gcp-44776a13dea667a6
Remarque : Pour consulter la documentation complète sur gcloud, accédez au guide de présentation de la gcloud CLI.
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
Dans la console Google Cloud, accédez au menu de navigation (), puis sélectionnez IAM et administration > IAM.
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle editor (éditeur). Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation du cloud > Tableau de bord.
Remarque : Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle editor (éditeur), procédez comme suit pour lui attribuer le rôle approprié.
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation du cloud > Tableau de bord.
Copiez le numéro du projet (par exemple, 729328892908).
Dans le menu de navigation, sélectionnez IAM et administration > IAM.
Sous Afficher par compte principal, en haut de la table des rôles, cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez :
Remplacez {project-number} par le numéro de votre projet.
Dans le champ Rôle, sélectionnez Projet (ou Basique) > Éditeur.
Cliquez sur Enregistrer.
Tâche 1 : Créer une instance Cloud Data Fusion
Les instructions complètes pour créer une instance Cloud Data Fusion sont disponibles dans le guide Créer une instance Cloud Data Fusion. Les étapes essentielles sont les suivantes :
Pour vous assurer que l'environnement d'entraînement est bien configuré, vous devez d'abord arrêter, puis redémarrer l'API Cloud Data Fusion. Exécutez la commande suivante dans Cloud Shell. Cette opération prend quelques minutes.
gcloud services disable datafusion.googleapis.com
Le résultat indique que l'opération a bien été exécutée.
Redémarrez ensuite la connexion à l'API Cloud Data Fusion.
Dans la console Google Cloud, saisissez API Cloud Data Fusion dans la barre de recherche en haut de l'écran. Cliquez sur le résultat qui s'affiche.
Sur la page qui apparaît, cliquez sur Activer.
Une fois l'API réactivée, la page s'actualise et affiche l'option permettant de désactiver l'API, ainsi que d'autres informations sur l'utilisation et les performances de l'API.
Dans le menu de navigation, sélectionnez Data Fusion.
Pour créer une instance Cloud Data Fusion, cliquez sur Créer une instance.
Saisissez le nom de l'instance.
Sélectionnez le type d'édition Basic.
Dans la section Autorisation, cliquez sur Accorder l'autorisation.
Conservez les valeurs par défaut de tous les autres champs, puis cliquez sur Créer.
Remarque : La création de l'instance peut prendre une quinzaine de minutes.
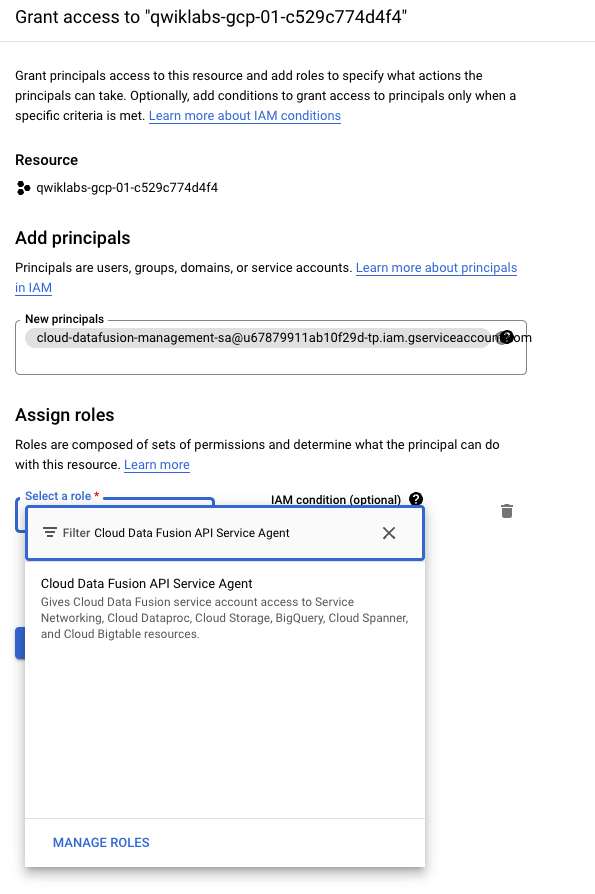
Après avoir créé l'instance, vous devez accorder au compte de service qui lui est associé les autorisations sur votre projet. Pour accéder à la page des informations sur l'instance, cliquez sur son nom.
Copiez le compte de service dans votre presse-papiers.
Dans la console GCP, accédez à IAM et administration > IAM.
Sur la page "Autorisations IAM", cliquez sur + Accorder l'accès, ajoutez le compte de service que vous avez copié précédemment en tant que nouveau compte principal et attribuez-lui le rôle Agent de service de l'API Cloud Data Fusion.
Cliquez sur Enregistrer.
Tâche 2 : Charger les données
Une fois que l'instance Cloud Data Fusion est opérationnelle, vous pouvez commencer à utiliser Cloud Data Fusion. Certaines étapes sont toutefois nécessaires avant que Cloud Data Fusion ingère des données.
Dans cet exemple, Cloud Data Fusion va lire les données d'un bucket de stockage. Dans la console Cloud Shell, exécutez les commandes suivantes pour créer un bucket et y copier les données pertinentes :
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
gcloud storage cp gs://cloud-training/OCBL017/ny-taxi-2018-sample.csv gs://$BUCKET
Remarque : Le nom du bucket créé correspond à l'ID du projet.
Dans la ligne de commande, exécutez la commande suivante pour créer un bucket qui servira à stocker temporairement les éléments que Cloud Data Fusion va créer :
gcloud storage buckets create gs://$BUCKET-temp
Remarque : Le nom du bucket créé correspond à l'ID du projet suivi de "-temp".
Sur la page des instances Data Fusion ou sur la page des détails d'une instance, cliquez sur le lien Afficher l'instance. Cliquez sur Nom d'utilisateur. Si vous êtes invité à découvrir le service, cliquez sur Non, merci. L'UI Cloud Data Fusion s'ouvre.
Remarque : Vous devrez peut-être actualiser la page de l'interface utilisateur Cloud Data Fusion pour qu'elle se charge rapidement.
Wrangler est un outil interactif, qui vous permet de visualiser les effets des transformations sur un petit sous-ensemble de vos données avant de répartir des jobs de traitement parallèle volumineux sur l'ensemble de données complet. Dans l'interface utilisateur Cloud Data Fusion, sélectionnez Wrangler. Sur le côté gauche, vous pouvez voir un panneau dans lequel figurent les connexions préconfigurées avec vos données, y compris la connexion Cloud Storage.
Sous GCS, sélectionnez Cloud Storage Default (Option Cloud Storage par défaut).
Cliquez sur le bucket associé à votre projet.
Sélectionnez ny-taxi-2018-sample.csv. Les données sont chargées dans l'écran Wrangler sous forme de lignes et de colonnes.
Dans la fenêtre Parsing Options (Options d'analyse), définissez Use First Row as Header (Utiliser la première ligne pour l'en-tête) sur True. Les données sont divisées en plusieurs colonnes.
Cliquez sur Confirm (Confirmer).
Tâche 3 : Nettoyer les données
Vous allez maintenant effectuer des transformations pour analyser et nettoyer les données concernant les taxis.
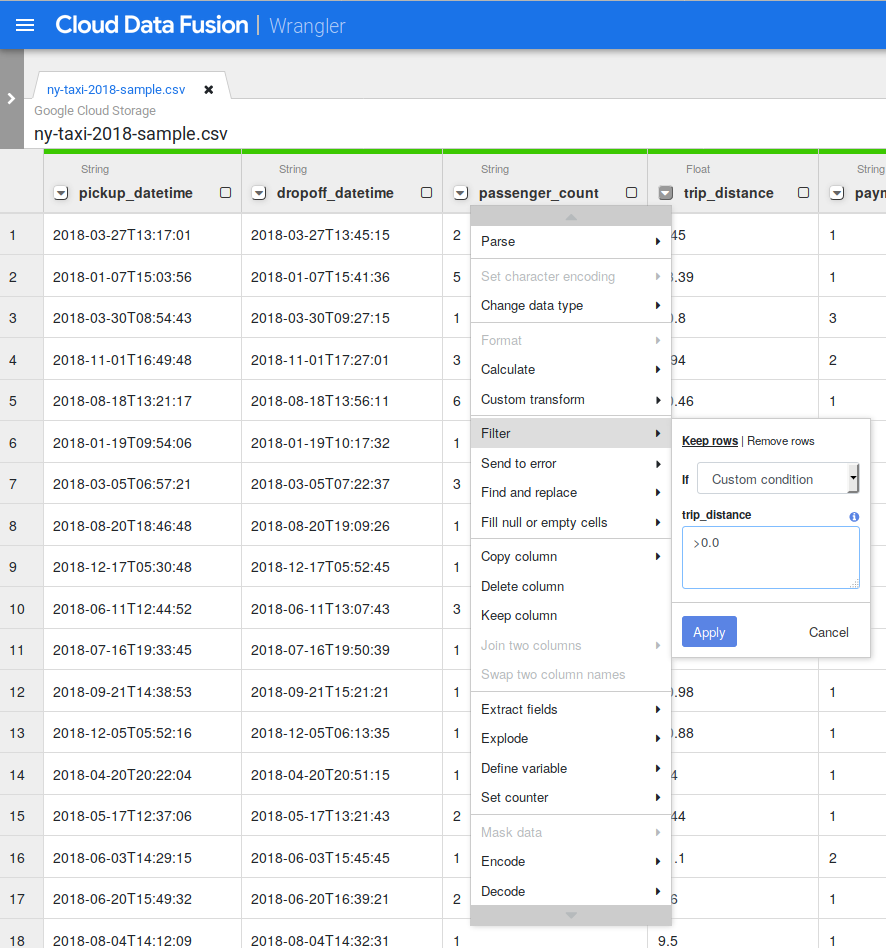
Cliquez sur la flèche vers le bas à côté de la colonne trip_distance (distance du trajet). Sélectionnez ensuite Change data type (Modifier le type de données) et cliquez sur Float (Nombre à virgule flottante). Répétez la procédure pour la colonne total_amount (montant total).
Cliquez sur la flèche vers le bas à côté de la colonne pickup_location_id (ID du lieu de départ). Sélectionnez ensuite Change data type (Modifier le type de données) et cliquez sur String (Chaîne).
Si vous examinez attentivement les données, il se peut que vous constatiez certaines anomalies, par exemple des distances négatives. Pour éliminer ces valeurs négatives, filtrez-les dans Wrangler. Cliquez sur la flèche vers le bas à côté de la colonne trip_distance, puis sélectionnez Filter (Filtrer). Cliquez sur Custom condition (Condition personnalisée) et saisissez >0.0.
Cliquez sur Apply (Appliquer).
Tâche 4 : Créer le pipeline
Vous avez effectué un nettoyage basique des données et des transformations sur un sous-ensemble de celles-ci. Vous pouvez maintenant créer un pipeline de traitement par lot pour exécuter des transformations sur toutes vos données.
Cloud Data Fusion traduit votre pipeline créé visuellement en un programme Apache Spark ou MapReduce qui exécute des transformations sur un cluster éphémère Cloud Dataproc en parallèle. Cela vous permet de réaliser facilement des transformations complexes sur de grandes quantités de données de manière fiable et évolutive, sans avoir à gérer l'infrastructure ni la technologie.
En haut à droite de l'interface utilisateur Google Cloud Data Fusion, cliquez sur Create a Pipeline (Créer un pipeline).
Dans la boîte de dialogue qui s'affiche, sélectionnez Batch pipeline (Pipeline de traitement par lot).
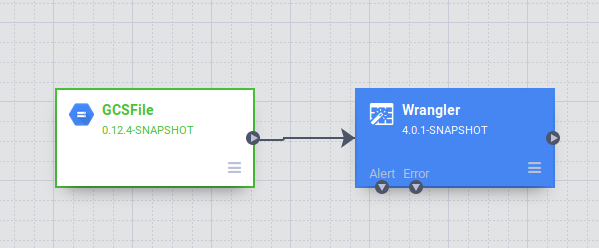
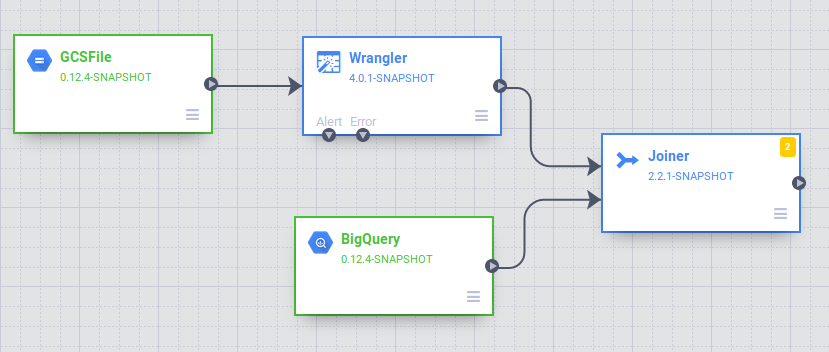
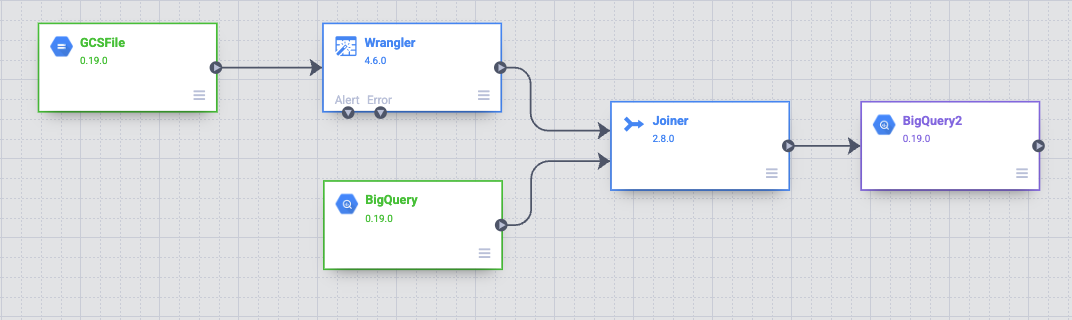
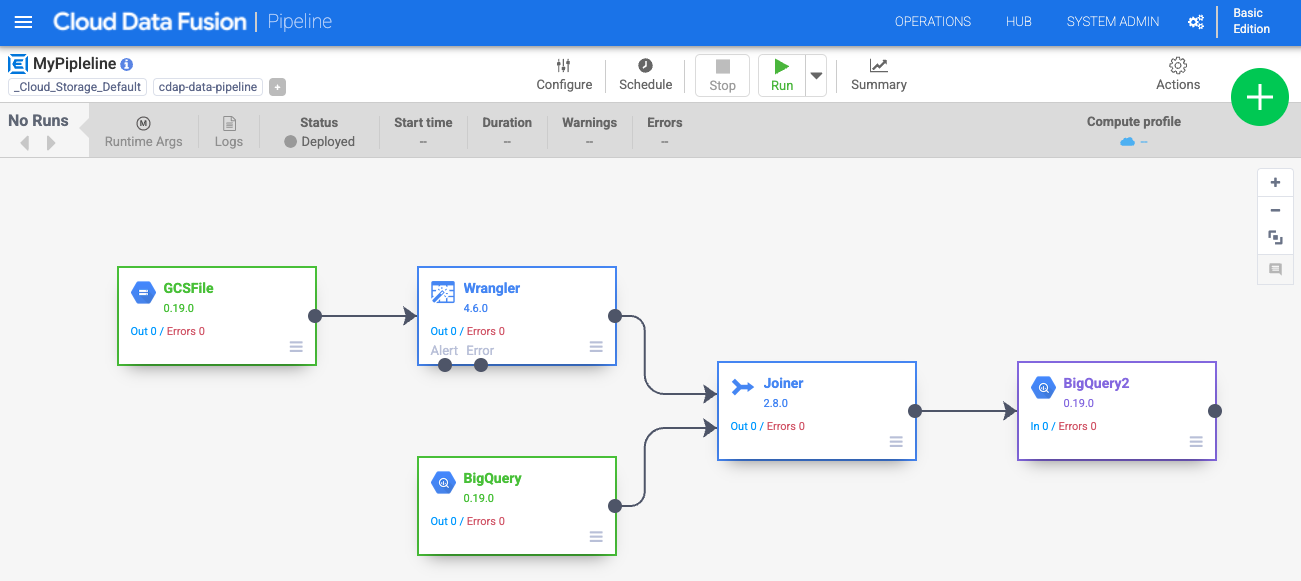
Dans l'interface utilisateur Data pipelines, un nœud source GCSFile connecté à un nœud Wrangler s'affiche. Le nœud Wrangler contient toutes les transformations que vous avez appliquées dans la vue Wrangler sous forme de grammaire directive. Pointez sur le nœud Wrangler et sélectionnez Propriétés.
À ce stade, vous pouvez appliquer d'autres transformations en cliquant sur le bouton Wrangle. Supprimez la colonne extra en cliquant sur l'icône de la poubelle rouge à côté de son nom. Cliquez sur Valider en haut à droite pour détecter d'éventuelles erreurs. Pour fermer l'outil Wrangler, cliquez sur le bouton X en haut à droite.
Tâche 5 : Ajouter une source de données
Les données concernant les taxis contiennent plusieurs colonnes qui peuvent être a priori difficiles à déchiffrer par un analyste, comme la colonne pickup_location_id. Vous allez ajouter une source de données au pipeline qui mappe la colonne pickup_location_id à un nom de lieu pertinent. Les informations de mappage seront stockées dans une table BigQuery.
Dans la section "Explorateur" de l'interface utilisateur BigQuery, cliquez sur les trois points situés à côté de votre ID de projet GCP (il commence par Qwiklabs).
Dans le menu qui s'affiche, cliquez sur Créer un ensemble de données.
Dans le champ ID de l'ensemble de données, saisissez trips.
Cliquez sur Créer un ensemble de données.
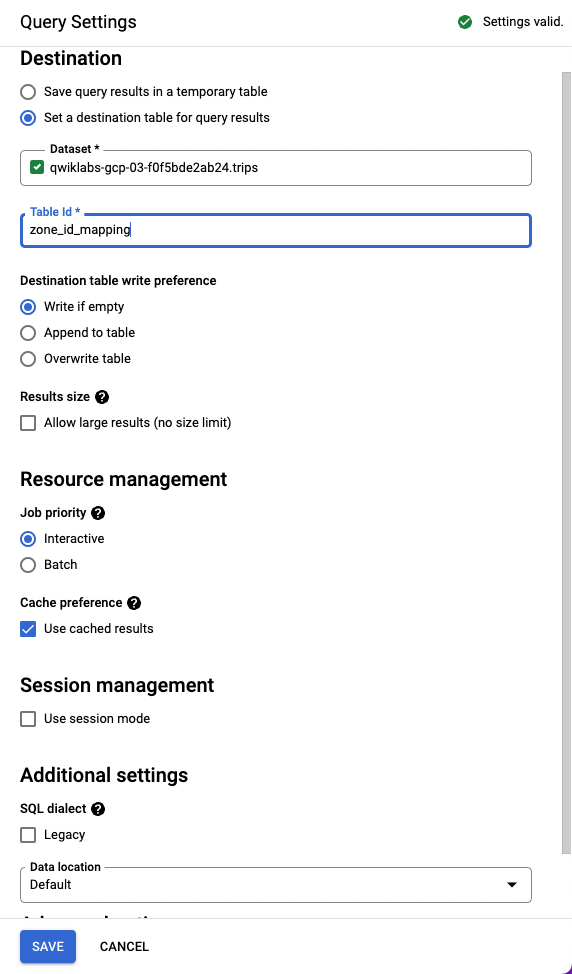
Pour créer la table souhaitée dans le nouvel ensemble de données, accédez à Plus > Paramètres de requête. Cette procédure vous permettra d'accéder à votre table depuis Cloud Data Fusion.
Sélectionnez l'option Définir une table de destination pour les résultats de la requête. Pour Ensemble de données, saisissez trips et sélectionnez-le dans le menu déroulant. Dans ID de la table, saisissez zone_id_mapping. Cliquez sur Enregistrer.
Saisissez la requête suivante dans l'éditeur de requête, puis cliquez sur Exécuter :
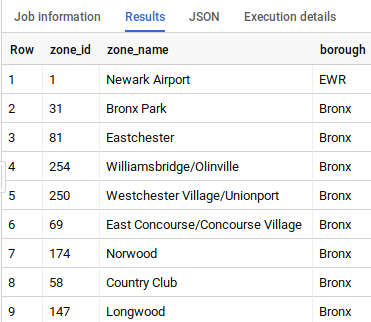
SELECT
zone_id,
zone_name,
borough
FROM
`bigquery-public-data.new_york_taxi_trips.taxi_zone_geom`
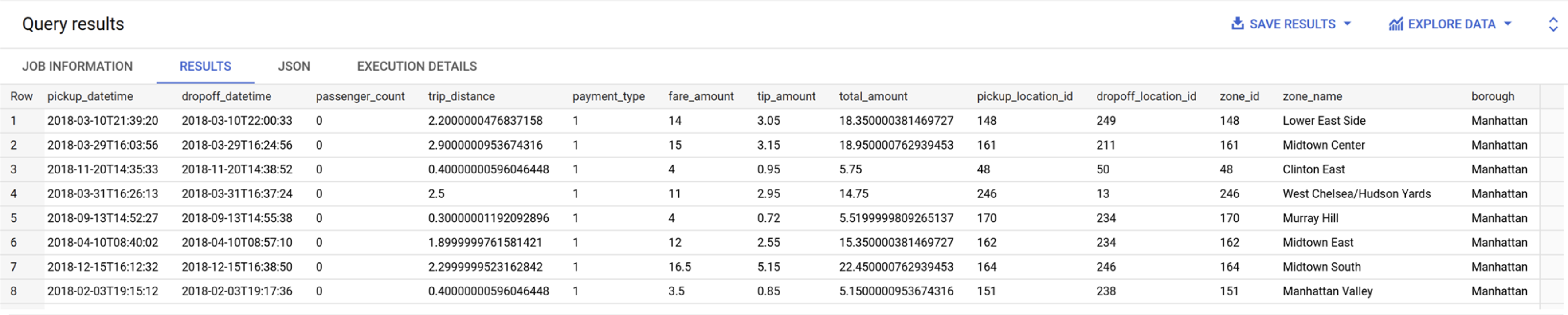
Vous constatez que cette table contient les mappages entre zone_id et le nom et arrondissement de la zone.
Vous allez maintenant ajouter une source à votre pipeline pour accéder à cette table BigQuery. Revenez à l'onglet dans lequel Cloud Data Fusion est ouvert. Dans la palette de plug-ins située à gauche, sélectionnez BigQuery dans la section Source. Un nœud source BigQuery apparaît sur le canevas avec les deux autres nœuds.
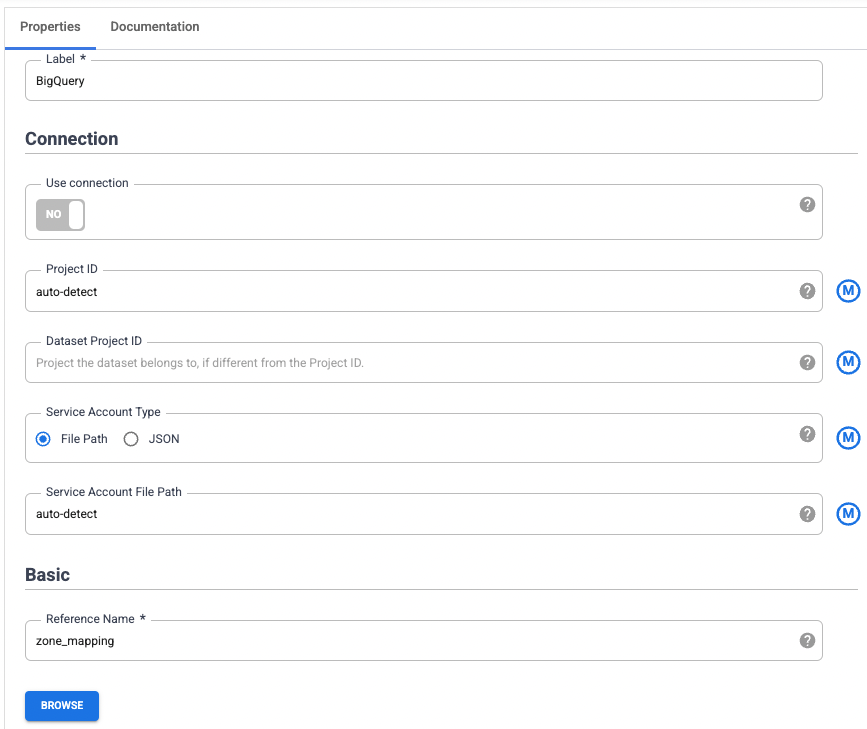
Pointez sur le nouveau nœud source BigQuery et cliquez sur Propriétés.
Dans Nom de la référence, saisissez zone_mapping, qui permet d'identifier cette source de données à des fins de traçabilité.
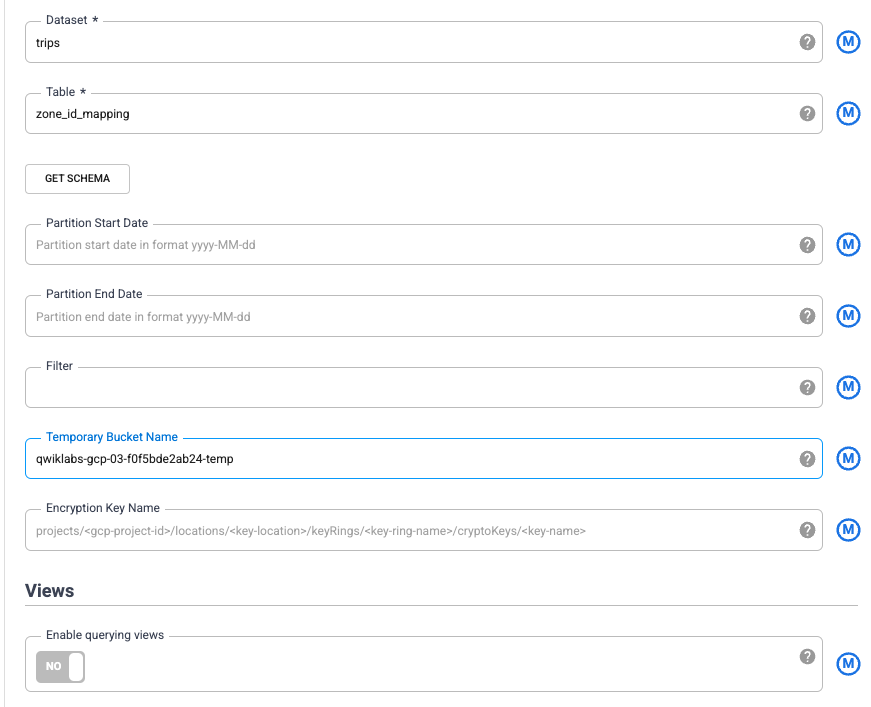
Les valeurs des champs Ensemble de données et Table de BigQuery correspondent à celles que vous avez définies dans BigQuery un peu plus tôt : trips et zone_id_mapping. Dans le champ Nom de bucket temporaire, saisissez le nom de votre projet suivi de "-temp", ce qui correspond au bucket créé à la tâche 2.
Pour renseigner le schéma de cette table à partir de BigQuery, cliquez sur Obtenir un schéma. Les champs s'affichent à droite de l'assistant.
Cliquez sur Valider en haut à droite pour détecter d'éventuelles erreurs. Pour fermer la fenêtre des propriétés de BigQuery, cliquez sur le bouton X en haut à droite.
Tâche 6 : Effectuer la jointure de deux sources
Vous pouvez maintenant effectuer la jointure des deux sources de données, c'est-à-dire les données des trajets de taxis et les noms des zones, pour générer des résultats plus pertinents.
Sous la section Analytics (Analyse) de la palette de plug-ins, sélectionnez Joiner. Un nœud Joiner apparaît sur le canevas.
Pour connecter le nœud Wrangler et le nœud BigQuery au nœud Joiner, faites glisser une flèche de connexion > depuis le bord droit du nœud source jusqu'au nœud de destination.
Pour configurer le nœud Joiner, qui est identique à une syntaxe SQL JOIN :
Cliquez sur Properties (Propriétés) de Joiner.
Conservez l'étiquette Joiner.
Sélectionnez Inner (Interne) comme valeur dans le champ Join Type (Type de jointure).
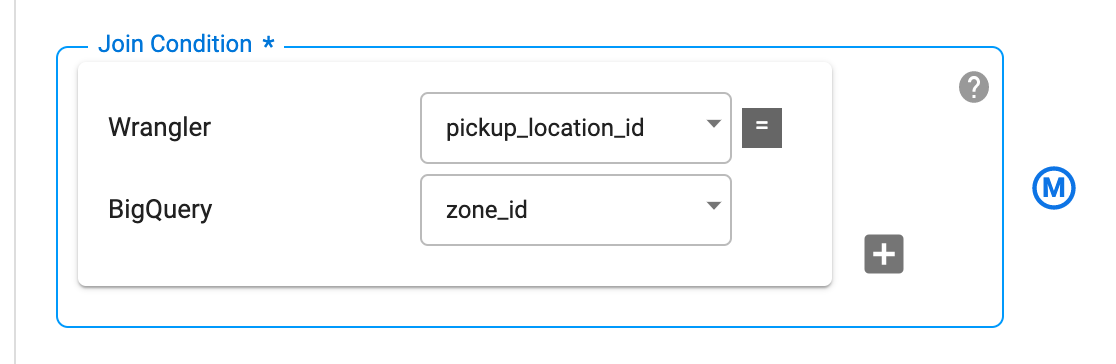
Dans Condition de jointure, effectuez la jointure entre la colonne pickup_location_id du nœud Wrangler et la colonne zone_id du nœud BigQuery.
Pour générer le schéma de la jointure qui en résulte, cliquez sur Obtenir un schéma.
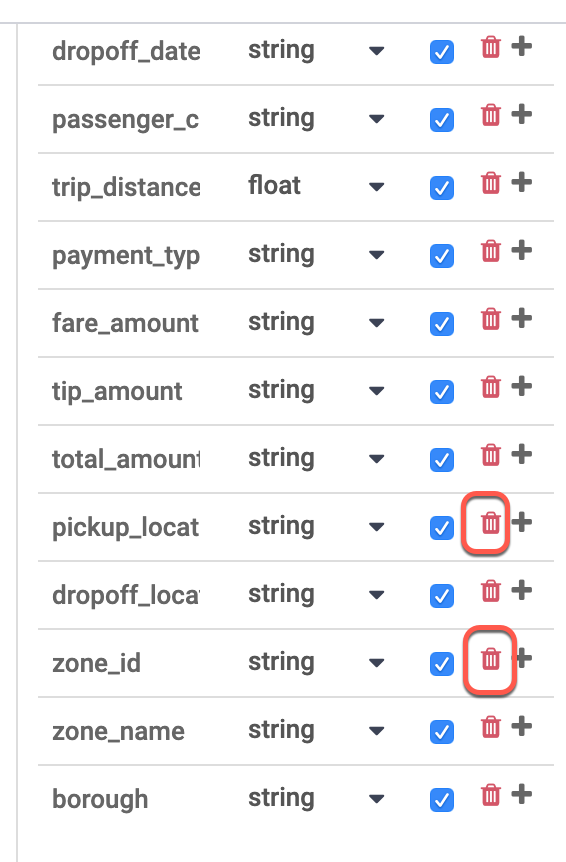
Dans la table Output Schema (Schéma de sortie) à droite, supprimez les champs zone_id et pickup_location_id en cliquant sur l'icône rouge de la corbeille.
Cliquez sur Valider en haut à droite pour détecter d'éventuelles erreurs. Pour fermer la fenêtre, cliquez sur le bouton X en haut à droite.
Tâche 7 : Stocker le résultat dans BigQuery
Vous allez stocker le résultat du pipeline dans une table BigQuery. L'emplacement de stockage de vos données s'appelle un récepteur.
Dans la section Sink (Récepteur) de la palette de plug-ins, sélectionnez BigQuery.
Connectez le nœud Joiner au nœud BigQuery. Faites glisser une flèche de connexion > sur le bord droit du nœud source et déposez-la sur le nœud de destination.
Ouvrez le nœud BigQuery2 en pointant sur lui, puis cliquez sur Propriétés. Vous allez ensuite configurer le nœud comme suit. Vous allez utiliser une configuration semblable à la source BigQuery actuelle. Saisissez bq_insert dans le champ Nom de la référence, trips dans le champ Ensemble de données et le nom de votre projet suivi de "-temp" dans le champ Nom de bucket temporaire. Vous allez écrire dans une nouvelle table créée pour l'exécution de ce pipeline. Dans le champ Table, saisissez trips_pickup_name.
Cliquez sur Valider en haut à droite pour détecter d'éventuelles erreurs. Pour fermer la fenêtre, cliquez sur le bouton X en haut à droite.
Tâche 8 : Déployer et exécuter le pipeline
À ce stade, vous avez créé votre premier pipeline. Vous pouvez désormais le déployer et l'exécuter.
En haut à gauche de l'interface utilisateur Data Fusion, donnez un nom à votre pipeline, puis cliquez sur Enregistrer.
Vous allez maintenant déployer le pipeline. En haut à droite de la page, cliquez sur Déployer.
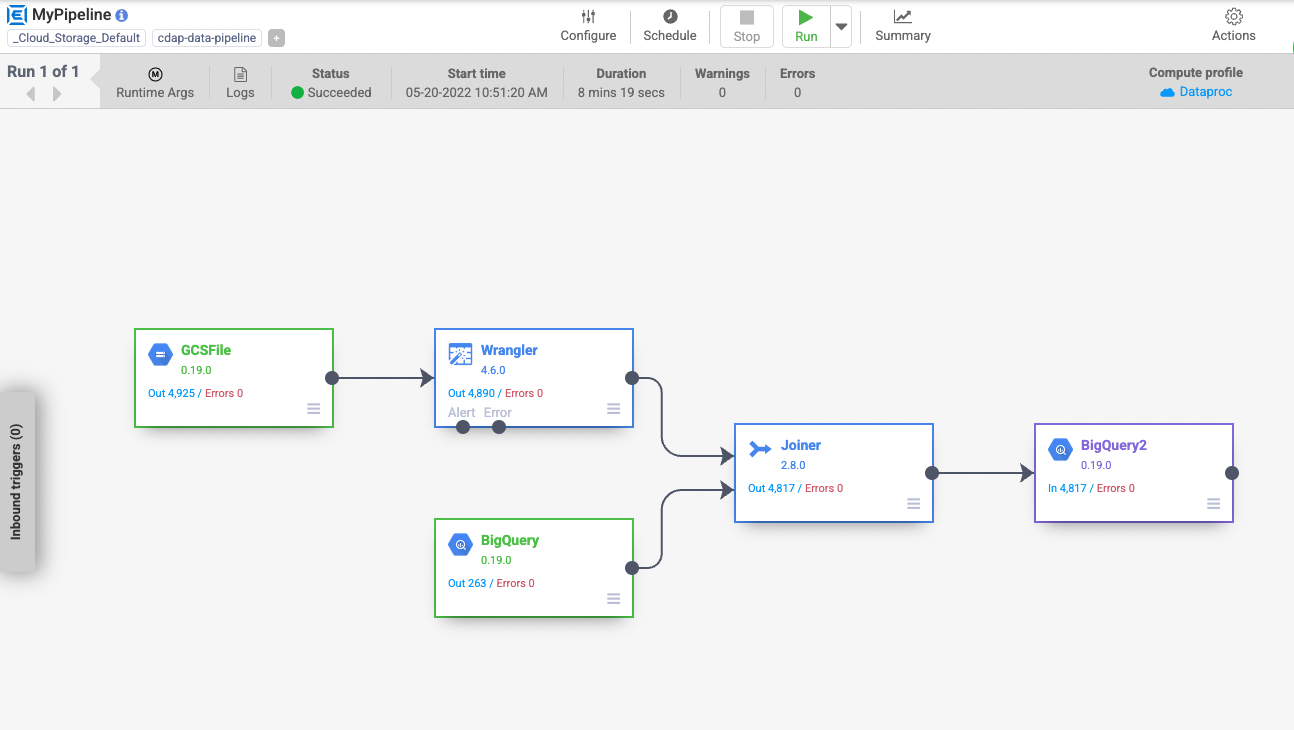
Sur l'écran suivant, cliquez sur Exécuter pour lancer le traitement des données.
Lorsque vous exécutez un pipeline, Cloud Data Fusion provisionne un cluster éphémère Cloud Dataproc, exécute le pipeline, puis supprime le cluster. L'opération peut prendre quelques minutes. Pendant ce laps de temps, vous pouvez observer l'état de transition du pipeline qui passe de Provisionnement à Démarrage et de Démarrage à Exécution, puis Réussie.
Remarque : La transition du pipeline peut prendre 10 à 15 minutes.
Tâche 9 : Afficher les résultats
Pour afficher les résultats une fois le pipeline exécuté :
Revenez à l'onglet dans lequel BigQuery est ouvert. Exécutez la requête ci-dessous pour afficher les valeurs de la table trips_pickup_name :
SELECT
*
FROM
`trips.trips_pickup_name`
RÉSULTATS DANS BIGQUERY
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Ce tutoriel explique comment réaliser des analyses plus approfondies à l'aide des fonctionnalités Wrangler et Data pipelines de Cloud Data Fusion. Nous les utiliserons ici pour nettoyer, transformer et traiter des données sur des courses de taxis.
Durée :
0 min de configuration
·
Accessible pendant 150 min
·
Terminé après 150 min


 ), puis sélectionnez IAM et administration > IAM.
), puis sélectionnez IAM et administration > IAM.