Les workflows sont une notion courante dans l'analyse de données ; ils impliquent l'ingestion, la transformation et l'analyse de données pour déduire les informations significatives. Dans Google Cloud, l'hébergement des workflows s'effectue dans Cloud Composer, version hébergée d'Apache Airflow, l'outil de workflow Open Source communément utilisé.
Dans cet atelier, vous allez configurer un environnement Cloud Composer à l'aide de la console Google Cloud. Vous allez ensuite utiliser Cloud Composer pour mettre en place un workflow simple qui vérifie l'existence d'un fichier de données, crée un cluster Cloud Dataproc, exécute un job de décompte de mots Apache Hadoop sur le cluster Cloud Dataproc, puis supprime ce cluster.
Objectifs de l'atelier
Créer un environnement Cloud Composer à l'aide de la console Google Cloud
Afficher et exécuter le graphe orienté acyclique (DAG, Directed Acyclic Graph) dans l'interface Web Airflow
Afficher les résultats du job de décompte dans l'espace de stockage
Préparation
Mettre en place l'atelier
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Qwiklabs dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à Google Cloud Console.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Activer Google Cloud Shell
Google Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud.
Google Cloud Shell vous permet d'accéder à vos ressources Google Cloud grâce à une ligne de commande.
Dans la barre d'outils située en haut à droite dans la console Cloud, cliquez sur le bouton "Ouvrir Cloud Shell".
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Par exemple :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project =
Exemple de résultat :
[core]
project = qwiklabs-gcp-44776a13dea667a6
Remarque : Pour consulter la documentation complète sur gcloud, accédez au guide de présentation de la gcloud CLI.
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
Dans la console Google Cloud, accédez au menu de navigation (), puis sélectionnez IAM et administration > IAM.
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle editor (éditeur). Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation du cloud > Tableau de bord.
Remarque : Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle editor (éditeur), procédez comme suit pour lui attribuer le rôle approprié.
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation du cloud > Tableau de bord.
Copiez le numéro du projet (par exemple, 729328892908).
Dans le menu de navigation, sélectionnez IAM et administration > IAM.
Sous Afficher par compte principal, en haut de la table des rôles, cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez :
Dans cette section, vous allez créer un environnement Cloud Composer.
Remarque : Avant de poursuivre, assurez-vous d'avoir bien effectué les étapes précédentes de sorte que les API requises soient activées. Si ce n'est pas le cas, veuillez effectuer ces étapes. Sinon, la création de l'environnement Cloud Composer échouera.
Dans la barre de titre de la console Google Cloud, saisissez Composer dans le champ de recherche, puis cliquez sur Composer dans la section "Produits et pages".
Cliquez sur Créer un environnement et sélectionnez Composer 3. Définissez les éléments suivants pour votre environnement :
Propriété
Valeur
Nom
highcpu
Emplacement
Version de l'image
composer-3-airflow-n.n.n-build.n (Remarque : sélectionnez la dernière version disponible de l'image)
Sous Ressources de l'environnement, sélectionnez Petit.
Conservez les valeurs par défaut de tous les autres paramètres.
Cliquez sur Créer.
La création de l'environnement est terminée lorsqu'une coche verte apparaît à gauche du nom de l'environnement sur la page "Environnements" de la console.
La procédure de configuration de l'environnement peut prendre entre 15 et 30 minutes. Poursuivez l'atelier en attendant.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer un environnement Cloud Composer
Créer un bucket Cloud Storage
Créez un bucket Cloud Storage dans votre projet. Ce bucket servira de sortie pour le job Hadoop fourni par Dataproc.
Accédez au menu de navigation > Cloud Storage > Buckets, puis cliquez sur + Créer.
Attribuez à votre bucket un nom unique universel, tel que l'ID de votre projet (), puis cliquez sur Créer. Si le message L'accès public sera bloqué s'affiche, cliquez sur Confirmer.
Notez bien le nom du bucket Cloud Storage, car vous l'utiliserez comme variable Airflow plus tard dans l'atelier.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer un bucket Cloud Storage
Tâche 3 : Airflow et concepts fondamentaux
En attendant la création de votre environnement Composer, découvrez quelques-uns des termes associés à Airflow.
Airflow est une plate-forme qui permet de créer, de planifier et de surveiller vos workflows de manière programmatique.
Avec Airflow, vous pouvez créer des workflows en tant que graphes de tâches orientés acycliques. Le programmeur Airflow exécute vos tâches sur un tableau de nœuds de calcul tout en suivant les dépendances spécifiées.
Un graphe orienté acyclique (DAG, Directed Acyclic Graph) est une collection regroupant toutes les tâches à exécuter et organisée de manière à refléter leurs relations et leurs dépendances.
Exécution spécifique d'une tâche caractérisée par un DAG, une tâche et un moment précis. Elle est affectée d'un état indicatif : running (exécution en cours), success (réussite), failed (échec), skipped (ignorée)...
Étudions maintenant le workflow que vous allez utiliser. Les workflows Cloud Composer sont constitués de DAG (graphes orientés acycliques). Les DAG sont définis dans des fichiers Python standards placés dans le dossier DAG_FOLDER d'Airflow. Airflow exécute le code de chaque fichier pour créer dynamiquement les objets DAG. Vous pouvez avoir autant de DAG que vous voulez, chacun décrivant un nombre arbitraire de tâches. En général, un DAG correspond à un workflow logique unique.
Le code du workflow hadoop_tutorial.py, que nous appellerons également le "DAG", est reproduit ci-dessous :
"""Example Airflow DAG that creates a Cloud Dataproc cluster, runs the Hadoop
wordcount example, and deletes the cluster.
This DAG relies on three Airflow variables
https://airflow.apache.org/concepts.html#variables
* gcp_project - Google Cloud Project to use for the Cloud Dataproc cluster.
* gce_zone - Google Compute Engine zone where Cloud Dataproc cluster should be
created.
* gce_region - Google Compute Engine region where Cloud Dataproc cluster should be
created.
* gcs_bucket - Google Cloud Storage bucket to used as output for the Hadoop jobs from Dataproc.
See https://cloud.google.com/storage/docs/creating-buckets for creating a
bucket.
"""
import datetime
import os
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
# Output file for Cloud Dataproc job.
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Path to Hadoop wordcount example available on every Dataproc cluster.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Arguments to pass to Cloud Dataproc job.
wordcount_args = ['wordcount', 'gs://pub/shakespeare/rose.txt', output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
'start_date': yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
'email_on_failure': False,
'email_on_retry': False,
# If a task fails, retry it once after waiting at least 5 minutes
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
# Create a Cloud Dataproc cluster.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
# Give the cluster a unique name by appending the date scheduled.
# See https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
region=models.Variable.get('gce_region'),
zone=models.Variable.get('gce_zone'),
image_version='2.0',
master_machine_type='e2-standard-2',
worker_machine_type='e2-standard-2')
# Run the Hadoop wordcount example installed on the Cloud Dataproc cluster
# master node.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
region=models.Variable.get('gce_region'),
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
# Delete Cloud Dataproc cluster.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
region=models.Variable.get('gce_region'),
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Setting trigger_rule to ALL_DONE causes the cluster to be deleted
# even if the Dataproc job fails.
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
Pour orchestrer les trois tâches de workflow, le DAG importe les opérateurs suivants :
DataprocClusterCreateOperator : crée un cluster Cloud Dataproc.
DataProcHadoopOperator : soumet un job de décompte de mots Hadoop et code le résultat dans un bucket Cloud Storage.
DataprocClusterDeleteOperator : supprime le cluster pour éviter que des frais Compute Engine ne continuent d'être facturés.
Les tâches sont exécutées de manière séquentielle, comme vous pouvez le voir dans cette section du fichier :
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
Ce DAG nommé composer_hadoop_tutorial s'exécute une fois par jour :
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
La valeur start_date transmise à default_dag_args étant définie sur yesterday, Cloud Composer planifie le démarrage du workflow immédiatement après l'importation du DAG.
Tâche 5 : Afficher les informations concernant l'environnement
Retournez à Composer pour vérifier l'état de votre environnement.
Une fois l'environnement créé, cliquez sur son nom (highcpu) pour en afficher les détails.
L'onglet Configuration de l'environnement contient des informations telles que l'URL de l'interface utilisateur Web d'Airflow, le cluster GKE et un lien vers le dossier des DAG, stocké dans votre bucket.
Remarque : Cloud Composer planifie uniquement les workflows dans le dossier /dags.
Pour accéder à l'interface Web d'Airflow à partir de la console :
Retournez à la page Environnements.
Dans la colonne Serveur Web Airflow associée à l'environnement, cliquez sur Airflow.
Cliquez sur les identifiants qui vous ont été attribués pour cet atelier.
L'interface Web d'Airflow s'ouvre dans une nouvelle fenêtre du navigateur.
Tâche 7 : Définir les variables Airflow
Les variables Airflow sont un concept spécifique à Airflow et sont différentes des variables d'environnement.
Dans la barre de menu de l'interface d'Airflow, sélectionnez Admin > Variables (Administration > Variables).
Cliquez sur l'icône + pour ajouter un enregistrement.
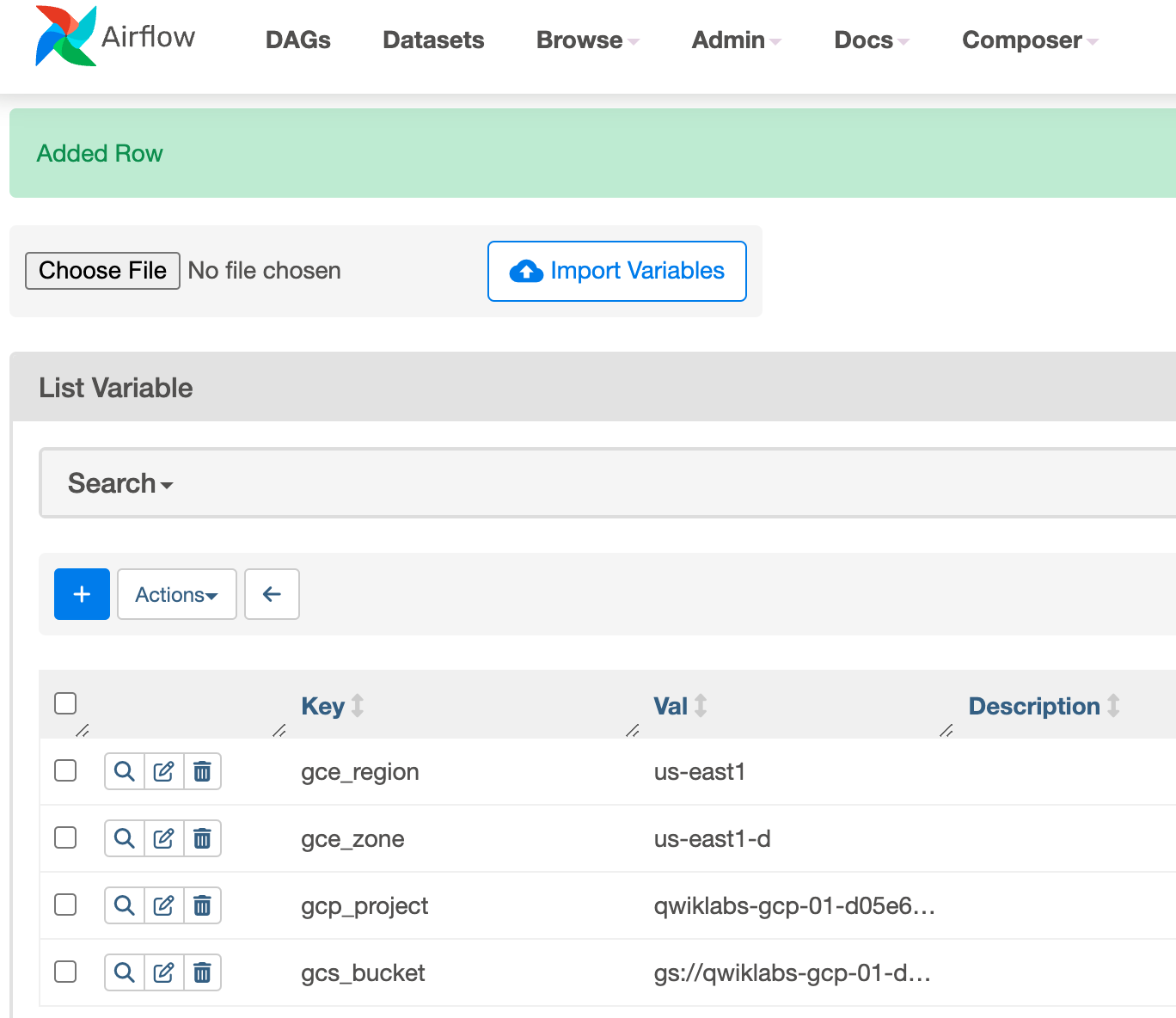
Créez les variables Airflow suivantes : gcp_project, gcs_bucket, gce_zone et gce_region. Cliquez sur Save (Enregistrer) après avoir créé chaque variable.
Clé
Valeur
Détails
gcp_project
Le projet Google Cloud Platform que vous utilisez dans cet atelier.
gcs_bucket
gs://<my-bucket>
Remplacez <my-bucket> par le nom du bucket Cloud Storage que vous avez créé précédemment. Ce bucket stocke le résultat des jobs Hadoop exécutées sur Dataproc.
gce_zone
Il s'agit de la zone Compute Engine dans laquelle votre cluster Cloud Dataproc sera créé.
gce_region
Il s'agit de la région Compute Engine dans laquelle votre cluster Cloud Dataproc sera créé.
Cliquez sur Enregistrer. Après avoir ajouté la première variable, répétez la même procédure pour la deuxième et la troisième variable. La table des variables doit se présenter comme suit lorsque vous avez terminé :
Tâche 8 : Importer le DAG dans Cloud Storage
Pour importer le DAG :
Dans Cloud Shell, exécutez la commande ci-dessous pour importer une copie du fichier hadoop_tutorial.py dans le bucket Cloud Storage qui a été créé automatiquement lors de la création de l'environnement.
Dans la commande suivante, remplacez <DAGs_folder_path> par le chemin d'accès au dossier des DAG :
Pour obtenir le chemin d'accès, accédez à Composer.
Cliquez sur l'environnement que vous avez créé précédemment, puis sur l'onglet Configuration de l'environnement pour afficher les informations de l'environnement.
Recherchez le dossier DAGs et copiez son chemin d'accès.
La commande modifiée permettant d'importer le fichier doit ressembler à la suivante :
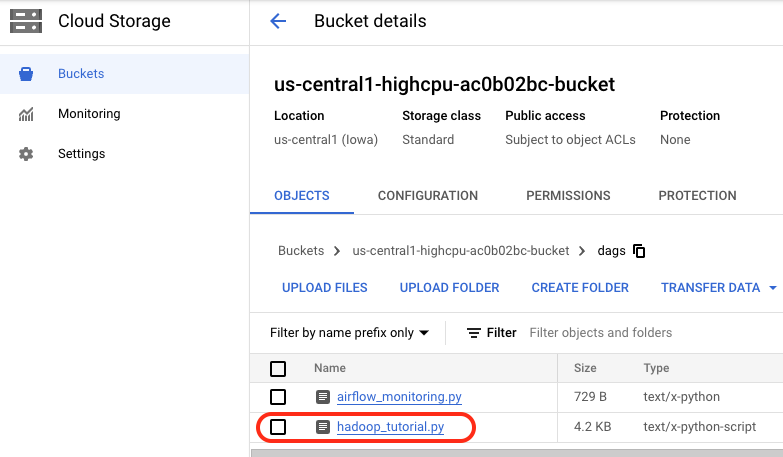
Une fois le fichier importé dans le répertoire des DAG, ouvrez le dossier dags dans le bucket. Le fichier apparaît dans l'onglet Objets de la page "Informations sur le bucket".
Lorsqu'un fichier DAG est ajouté au dossier des DAG, Cloud Composer ajoute le DAG à Airflow et le programme automatiquement. Les modifications sont appliquées au DAG après trois à cinq minutes.
L'état de la tâche du DAG composer_hadoop_tutorial s'affiche dans l'interface Web d'Airflow.
Remarque : Vous pouvez ignorer les messages qui s'affichent dans l'interface, comme The scheduler does not appear to be running (Le programmeur ne semble pas être en cours d'exécution). L'interface Web d'Airflow s'actualise à mesure que le DAG est importé.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Importer le DAG dans Cloud Storage
Explorer les exécutions du DAG
Lorsque vous importez le fichier DAG dans le dossier dags de Cloud Storage, il est analysé par Cloud Composer. Si aucune erreur n'est détectée, le nom du workflow apparaît dans la liste des DAG, et le workflow est placé en file d'attente en vue d'une exécution immédiate.
Assurez-vous que l'onglet des DAG de l'interface Web Airflow est actif. Ce processus peut prendre plusieurs minutes. Actualisez le navigateur pour afficher les informations les plus récentes.
Dans Airflow, cliquez sur composer_hadoop_tutorial pour ouvrir la page d'informations du DAG. Cette page comprend plusieurs représentations des tâches et des dépendances du workflow.
Dans la barre d'outils, cliquez sur Graph (Graphique). Passez la souris sur le graphique de chaque tâche pour afficher l'état de celle-ci. Notez que la bordure autour de chaque tâche indique également son état (bordure verte = exécution en cours, rouge = échec, etc.).
Cliquez sur le lien "Refresh" (Actualiser) pour afficher les informations les plus récentes. En fonction de l'état d'évolution des processus, la couleur des bordures change.
Remarque : Si votre cluster Dataproc existe déjà, vous pouvez de nouveau exécuter le workflow pour atteindre l'état de réussite. Pour ce faire, cliquez sur le graphique "create_dataproc_cluster", choisissez Clear (Effacer) pour réinitialiser les trois tâches, puis cliquez sur OK pour confirmer.
Lorsque create_dataproc_cluster passe à l'état "running" (en cours d'exécution), accédez au menu de navigation > Dataproc, puis cliquez sur les éléments suivants :
Clusters pour surveiller la création et la suppression des clusters. Le cluster créé par le workflow est éphémère : il est supprimé lors de la dernière tâche de ce workflow.
Jobs pour surveiller le job de décompte de mots Apache Hadoop. Cliquez sur l'ID de job pour afficher la sortie du journal associée au job.
Une fois que Dataproc passe à l'état "Running" (Exécution en cours), retournez à Airflow, puis cliquez sur Refresh (Actualiser) pour vérifier que le cluster est créé.
Une fois le processus run_dataproc_hadoop terminé, accédez au menu de navigation, sélectionnez Cloud Storage > Buckets, puis cliquez sur le nom de votre bucket pour afficher les résultats du décompte de mots dans le dossier wordcount.
Une fois toutes les étapes terminées dans le DAG, chacune présente une bordure vert foncé. De plus, le cluster Dataproc qui a été créé est désormais supprimé.
Félicitations !
Vous avez réussi à exécuter un workflow Cloud Composer.
Pour afficher la valeur d'une variable, exécutez les variables de la sous-commande CLI Airflow avec l'argument get ou utilisez l'interface Web Airflow.
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez créer un environnement Cloud Composer à l'aide de la console GCP. Dans l'interface Web Airflow, vous allez ensuite mettre en place un workflow qui vérifie l'existence d'un fichier de données, crée et exécute un job de décompte de mots Apache Hadoop sur un cluster Dataproc, puis supprime ce cluster.
Durée :
0 min de configuration
·
Accessible pendant 90 min
·
Terminé après 90 min


 ), puis sélectionnez IAM et administration > IAM.
), puis sélectionnez IAM et administration > IAM.