



准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Examine GKE application SQL queries using SQL Insights.
/ 25
Enable SQLCommenter on a GKE application.
/ 25
Redeploy the gMemegen application.
/ 25
Take actions to tune and optimise the database to enhance performance.
/ 25
在本实验中,您将使用 SQL Insights 分析 Cloud SQL 数据库性能。您将修改现有的 Google Kubernetes Engine (GKE) 应用,使用 SQLcommenter 库为应用查询添加注释,这将有助于您在应用中确定查询的来源。
您必须创建或配置为每项任务指定的服务和资源,并且必须遵循所提供的详细说明,才能成功完成每项任务。
在本实验中,您将学习如何执行以下任务:
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。左侧是“实验详细信息”窗格,其中包含以下各项:
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:将这些标签页安排在不同的窗口中,并排显示。
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
您也可以在“实验详细信息”窗格中找到“用户名”。
点击下一步。
复制下面的密码,然后将其粘贴到欢迎对话框中。
您也可以在“实验详细信息”窗格中找到“密码”。
点击下一步。
继续在后续页面中点击以完成相应操作:
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
点击 Google Cloud 控制台顶部的激活 Cloud Shell 
在弹出的窗口中执行以下操作:
如果您连接成功,即表示您已通过身份验证,且项目 ID 会被设为您的 Project_ID
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
输出:
输出:
gcloud 的完整文档,请参阅 gcloud CLI 概览指南。
您必须启用本实验所需的 API。您将在后续任务中构建容器并将其推送到 Artifact Registry,因此您必须先启用 Artifact Registry API。
.kube 文件夹中创建一个 config 文件。在浏览器中,转到负载均衡器的入站 IP 地址。
您可以使用以下命令在 Cloud Shell 中创建指向负载均衡器外部 IP 地址的可点击链接:
在此任务中,您将检查由 gMemegen 应用生成的查询。您需要通过该应用制作表情包,并在该应用的近期和随机页面中查看这些表情包,从而产生一些流量。
若要完成此任务,您必须对 Cloud SQL 数据库启用 SQL Insights。
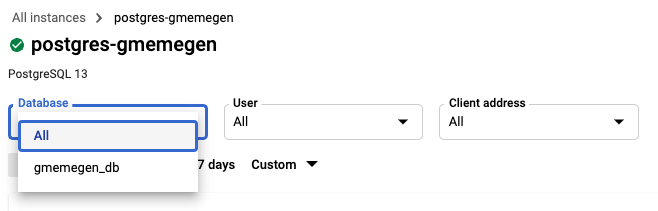
在 Cloud 控制台中,依次点击数据库 > SQL,然后选择 postgres-gmemegen 实例。
在主实例菜单中,选择查询数据分析。
点击启用按钮。
在主实例 > 查询数据分析页面的热门查询和标记中,选择标记标签页。
点击存储应用标记
在此步骤中,您将使用 gMemegen 应用制作至少四个新的表情包,并查看这些表情包。这样做是为了对应用进行测试,生成一些样本数据,并利用所有可用路由。
在 gMemegen 应用标签页中,前往主页并选择一张图片。
在新建表情包页面中,在顶部和底部文本框中输入文本。您可以制作您想到的任何表情包。
点击提交按钮。您将看到界面上显示了新的表情包。
使用浏览器的返回按钮返回。
点击近期菜单项,查看您最近创作的表情包。
点击已排序菜单项,查看按顶部文本的字母顺序排序的表情包。
点击随机菜单项,随机查看一个表情包。关闭浏览器中的随机标签页。
点击主页菜单项返回主页,您可以在这里创建新的表情包。
重复执行上述 1 到 8 点,直到制作出至少 4 个新的表情包。
在主实例菜单中,转到查询数据分析。
打开数据库字段中的下拉菜单,然后选择 gmemegen_db。如果未在列表中看到 gmemegen_db,请刷新页面。gmemegen_db 可能需要一段时间才能在列表中显示。您可以通过在 gMemegen 应用中执行更多操作来产生更多数据库流量,从而加速这一过程。
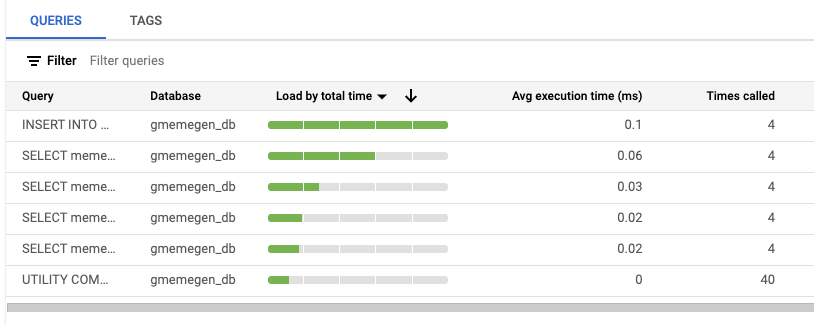
热门查询和标记部分,请注意,由 gMemegen 应用生成的查询列在查询标签页中。SQL Insights 无法区分查询的来源,因为这些查询没有标记。有一个名为 SQLcommenter 的数据库开发者工具,可以通过向应用查询附加注释来提供帮助,这些注释将在此视图中填充标记。这对于开发者和测试人员跟踪应用查询的来源、协助调试和优化非常有用。
您应该记下当前时间,以便比较在应用代码中加入 SQLcommenter 库前后 SQL Insights 的结果。
点击“检查我的进度”以验证是否完成了以下目标:
在此任务中,您将修改 gMemegen 应用,使其包含 SQLcommenter 库代码;这些代码将为应用查询添加注释,提高其在 SQL Insights 中的实用性。
在此步骤中,您将修改 gMemegen 应用的 main.py Python 应用代码,以启用 SQLcommenter。代码已经包含了这些更改,只需取消注释即可,这只需一个简单的 sed 命令即可实现。您还将重建该应用,并将新的映像存储在 Artifact Registry 中。
若要启用 SQLcommenter,您需要在 gmemegen/app/main.py Python 文件中移除以下代码块的注释,以便配置该应用,使其使用 SQLcommenter 为查询添加标记。
在此步骤中,您将构建经过修改的应用代码,并将映像推送到 Artifact Registry,标记为版本 2。
如果系统要求您确认,请输入 Y。
创建制品库:
构建新映像并将其推送到 Artifact Registry:
构建和推送过程需要几分钟才能完成。完成后,输出内容应表明构建成功,如下所示。
输出:
点击“检查我的进度”以验证是否完成了以下目标:
在此任务中,您将重新部署修改后的 gMemegen 应用。然后,您就可以使用 SQL Insights 对两版应用的查询进行比较。
在 Cloud Shell 中,运行以下命令,使用您的项目 ID、Cloud SQL 连接名称和区域更新部署 YAML:
在 Cloud Shell 中,运行以下命令来重新部署应用:
在 Cloud Shell 中,重新部署负载均衡器,选择应用的 2.0 版本:
在 Cloud Shell 中,运行以下命令来检查部署是否成功:
输出:
现在,您已运行新部署的 gMemegen 应用。
点击“检查我的进度”以验证是否完成了以下目标:
在此任务中,您将返回 SQL Insights,以查看更新版应用的数据库活动,包括 SQLcommenter。您首先需要使用新版应用制作一些表情包,以便生成更多数据库活动。
在此步骤中,您将使用在任务 3 中部署的新版应用制作新的表情包。请注意,在菜单栏中,该应用的名称旁边会显示 (SQLcommenter),这表明它是新应用。
在此步骤中,您将查看来自新部署应用的查询,请注意由 SQLcommenter 插入的标记。
在 Cloud 控制台标签页中,依次选择主实例 > 查询数据分析页面,然后选择热门查询和标记中的标记标签页。
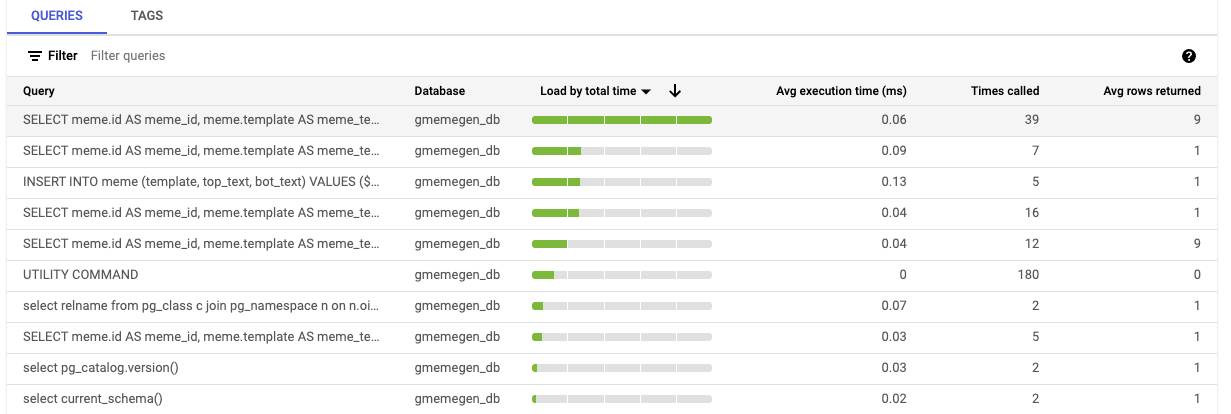
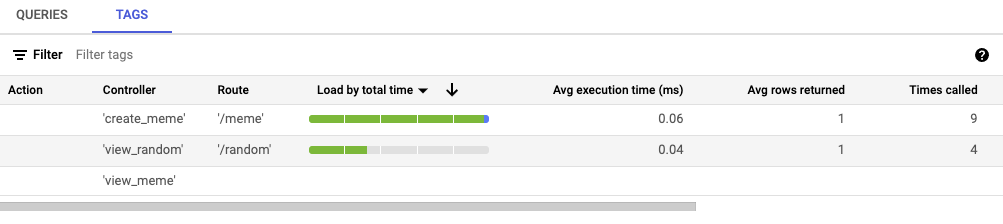
点击负载(按总时长)列名称。这应该会刷新已标记查询的列表,显示由 SQLcommenter 标记的所有近期查询。
请注意,控制器、路由、数据库驱动程序和框架标记现已填充。
如果您无法在标记标签页中看到此查询,请刷新网页,点击标记标签页,然后再次点击负载(按总时长)列名称。
在此步骤中,您将分析应用查询的性能,以识别运行缓慢的查询。
热门查询和标记。点击标记标签页。
在路由列中选择带有 /sorted 的标记。
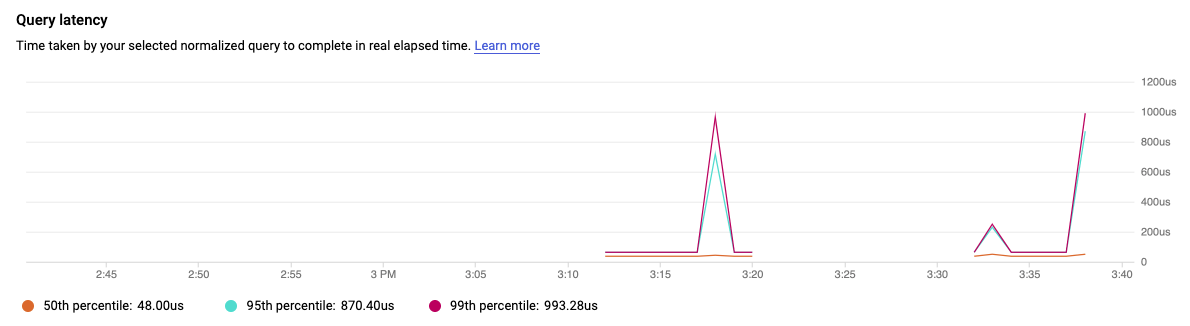
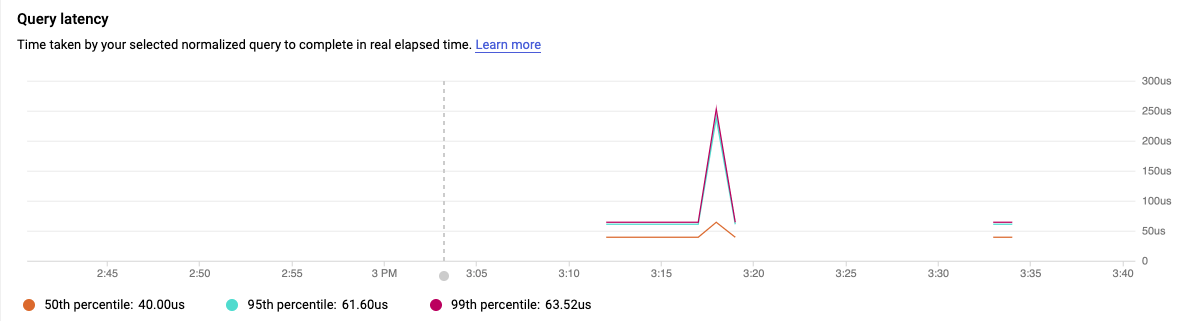
它应该具有最高的负载(用绿色指示条表示),但由于实验中的数据量相对较小,情况可能并非如此。实验中的查询延迟时间图表可能只会显示少量数据点,但通过其他数据,您可以查看延迟时间较长(P95 和 P99)的查询的值。
使用浏览器中的返回按钮返回热门查询和标记视图。或者,您也可以使用查询数据分析页面顶部的面包屑导航,选择 postgres-gmemegen 实例。
选择路由列中的 /recent 标记,该标记的负载和延迟应该稍低一些。同样,在您的实验中,这将仅显示可能与 /sorted 路由没有太大差异的数据点结果。
这些查询返回的行数大致相同。它们的性能为何不同?答案在于,meme.id 字段是 meme 表的主键,因此已编入索引;而 meme.top_text 字段未编入索引,因此运行时间较长。
gmemegen_db 数据库非常小,只包含您在本实验期间通过界面生成的那几行,因此这两种路由在性能上的差异可能并不明显,甚至难以察觉。在生产环境中,用于对已编入索引以及未编入索引的字段进行排序的查询,其性能差异肯定会很明显。在此任务中,您将修改 gmemegen_db 数据库,以修复在上一个任务中发现的运行缓慢的查询。
在此步骤中,您将向数据库列添加索引,以提高性能。
在 Cloud 控制台中,前往主实例 > 概览页面,在连接到此实例部分,点击打开 Cloud Shell。Cloud Shell 控制台中将自动填充一条命令。运行这条命令。
在系统提示时,输入密码 supersecret!。
在 psql 中的 postgres=> 提示符处,运行以下命令:
系统会再次提示您输入密码。输入 supersecret!。
在 psql 中的 gmemegen_db=> 提示符处,运行以下命令:
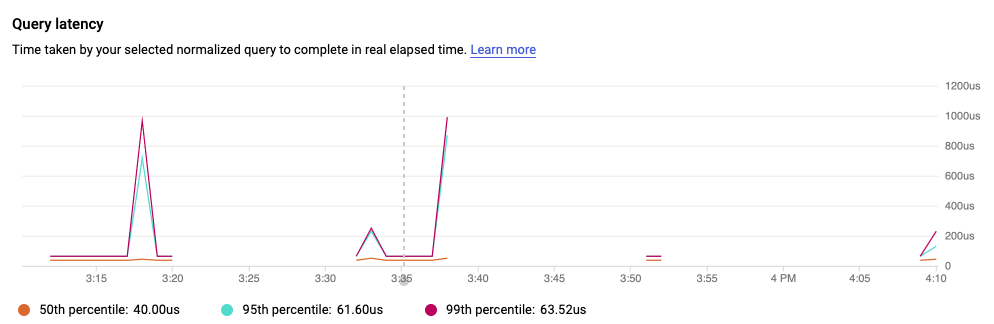
目前,我们已为排序的列添加索引;在此步骤中,您将检查运行缓慢的查询的性能。
在 Cloud 控制台中,前往主实例 > 查询数据分析页面,在热门查询和标记下的标记标签页上,再次选择 /sorted 标记。
向下滚动到查询延迟时间图表,请注意,延迟时间现在应该减少了。
点击“检查我的进度”以验证是否完成了以下目标:
您已完成本实验。
本自学实验是在 Cloud SQL 上管理 PostgreSQL 数据库挑战任务的组成部分。一项挑战任务就是一系列相关的实验,学习时按部就班地完成这些实验即可。完成挑战任务即可赢得一枚徽章,以表彰您取得的成就。您可以公开展示徽章,还可以在您的在线简历或社交媒体账号中加入指向徽章的链接。欢迎注册参加此挑战任务,完成后就能立即获得相应的积分。请参阅 Google Cloud Skills Boost 目录,查看所有可参加的挑战任务。
上次更新手册的时间:2024 年 7 月 4 日
上次测试实验的时间:2024 年 7 月 4 日
版权所有 2025 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验