GSP965

Ringkasan
Pipelines membantu Anda mengotomatiskan dan mereproduksi alur kerja ML Anda. Vertex AI mengintegrasikan penawaran ML di Google Cloud ke dalam pengalaman pengembangan yang lancar. Sebelumnya, model yang dilatih dengan AutoML dan model kustom dapat diakses melalui layanan terpisah. Vertex AI menggabungkan kedua model ini menjadi satu API, beserta produk baru lainnya. Vertex AI juga menyertakan berbagai produk MLOps, seperti Vertex AI Pipelines. Di lab ini, Anda akan mempelajari cara membuat dan menjalankan pipeline ML dengan Vertex AI Pipelines.
Mengapa harus menggunakan pipeline ML?
Sebelum memulai, Anda perlu memahami terlebih dahulu alasan pentingnya menggunakan pipeline. Bayangkan Anda sedang membuat alur kerja ML yang mencakup pemrosesan data, pelatihan model, penyesuaian hyperparameter, evaluasi, dan deployment model. Setiap langkah ini mungkin memiliki dependensi berbeda, yang mungkin menyulitkan jika Anda memperlakukan keseluruhan alur kerja sebagai monolit. Saat mulai menskalakan proses ML, Anda mungkin ingin berbagi alur kerja ML Anda dengan anggota lain di tim Anda sehingga mereka dapat menjalankannya dan memberikan kontribusi kode. Tanpa proses yang andal dan dapat direproduksi, berbagi alur kerja ML bisa menjadi sulit. Dengan pipeline, setiap langkah dalam proses ML Anda berlangsung dalam container-nya sendiri. Hal ini memungkinkan Anda mengembangkan langkah-langkah secara independen serta memantau input dan output dari setiap langkah dengan cara yang dapat direproduksi. Anda juga dapat menjadwalkan atau memicu jalannya pipeline berdasarkan peristiwa lain di lingkungan Cloud Anda, seperti saat data pelatihan baru tersedia.
Tujuan
Di lab ini, Anda akan mempelajari cara:
- Menggunakan Kubeflow Pipelines SDK untuk membangun pipeline ML yang skalabel
- Membuat dan menjalankan pipeline intro 3 langkah yang membutuhkan input teks
- Membuat dan menjalankan pipeline yang melatih, mengevaluasi, dan men-deploy model klasifikasi AutoML
- Menggunakan komponen bawaan untuk berinteraksi dengan layanan Vertex AI, yang disediakan melalui library google_cloud_pipeline_components
- Menjadwalkan tugas pipeline dengan Cloud Scheduler
Penyiapan dan persyaratan
Sebelum mengklik tombol Start Lab
Baca petunjuk ini. Lab memiliki timer dan Anda tidak dapat menjedanya. Timer yang dimulai saat Anda mengklik Start Lab akan menampilkan durasi ketersediaan resource Google Cloud untuk Anda.
Lab interaktif ini dapat Anda gunakan untuk melakukan aktivitas lab di lingkungan cloud sungguhan, bukan di lingkungan demo atau simulasi. Untuk mengakses lab ini, Anda akan diberi kredensial baru yang bersifat sementara dan dapat digunakan untuk login serta mengakses Google Cloud selama durasi lab.
Untuk menyelesaikan lab ini, Anda memerlukan:
- Akses ke browser internet standar (disarankan browser Chrome).
Catatan: Gunakan jendela Samaran (direkomendasikan) atau browser pribadi untuk menjalankan lab ini. Hal ini akan mencegah konflik antara akun pribadi Anda dan akun siswa yang dapat menyebabkan tagihan ekstra pada akun pribadi Anda.
- Waktu untuk menyelesaikan lab. Ingat, setelah dimulai, lab tidak dapat dijeda.
Catatan: Hanya gunakan akun siswa untuk lab ini. Jika Anda menggunakan akun Google Cloud yang berbeda, Anda mungkin akan dikenai tagihan ke akun tersebut.
Cara memulai lab dan login ke Google Cloud Console
-
Klik tombol Start Lab. Jika Anda perlu membayar lab, dialog akan terbuka untuk memilih metode pembayaran.
Di sebelah kiri ada panel Lab Details yang berisi hal-hal berikut:
- Tombol Open Google Cloud console
- Waktu tersisa
- Kredensial sementara yang harus Anda gunakan untuk lab ini
- Informasi lain, jika diperlukan, untuk menyelesaikan lab ini
-
Klik Open Google Cloud console (atau klik kanan dan pilih Open Link in Incognito Window jika Anda menjalankan browser Chrome).
Lab akan menjalankan resource, lalu membuka tab lain yang menampilkan halaman Sign in.
Tips: Atur tab di jendela terpisah secara berdampingan.
Catatan: Jika Anda melihat dialog Choose an account, klik Use Another Account.
-
Jika perlu, salin Username di bawah dan tempel ke dialog Sign in.
{{{user_0.username | "Username"}}}
Anda juga dapat menemukan Username di panel Lab Details.
-
Klik Next.
-
Salin Password di bawah dan tempel ke dialog Welcome.
{{{user_0.password | "Password"}}}
Anda juga dapat menemukan Password di panel Lab Details.
-
Klik Next.
Penting: Anda harus menggunakan kredensial yang diberikan lab. Jangan menggunakan kredensial akun Google Cloud Anda.
Catatan: Menggunakan akun Google Cloud sendiri untuk lab ini dapat dikenai biaya tambahan.
-
Klik halaman berikutnya:
- Setujui persyaratan dan ketentuan.
- Jangan tambahkan opsi pemulihan atau autentikasi 2 langkah (karena ini akun sementara).
- Jangan mendaftar uji coba gratis.
Setelah beberapa saat, Konsol Google Cloud akan terbuka di tab ini.
Catatan: Untuk mengakses produk dan layanan Google Cloud, klik Navigation menu atau ketik nama layanan atau produk di kolom Search.

Tugas 1. Membuka notebook di Vertex AI Workbench
-
Di Konsol Google Cloud, pada Navigation menu ( ), klik Vertex AI > Workbench.
), klik Vertex AI > Workbench.
-
Cari instance lalu klik tombol Open JupyterLab.
Antarmuka JupyterLab untuk instance Workbench Anda akan terbuka di tab browser baru.
Catatan: Jika Anda tidak melihat notebook di JupyterLab, ikuti langkah tambahan berikut untuk mereset instance:
1. Tutup tab browser untuk JupyterLab, lalu kembali ke halaman beranda Workbench.
2. Pilih kotak centang di samping nama instance, lalu klik Reset.
3. Setelah tombol Open JupyterLab diaktifkan kembali, tunggu satu menit, lalu klik Open JupyterLab.
Tugas 2. Penyiapan Vertex AI Pipelines
Ada beberapa library tambahan yang perlu Anda instal agar dapat menggunakan Vertex AI Pipelines:
-
Kubeflow Pipelines: Ini adalah SDK yang digunakan untuk membangun pipeline. Vertex AI Pipelines dapat menjalankan pipeline yang dibangun dengan Kubeflow Pipelines atau TFX.
-
Google Cloud Pipeline Components: Library ini menyediakan komponen bawaan yang memudahkan interaksi dengan layanan Vertex AI dari langkah-langkah pipeline Anda.
Langkah 1: Membuat notebook Python dan menginstal library
- Klik ikon Python 3 untuk meluncurkan notebook Python baru.
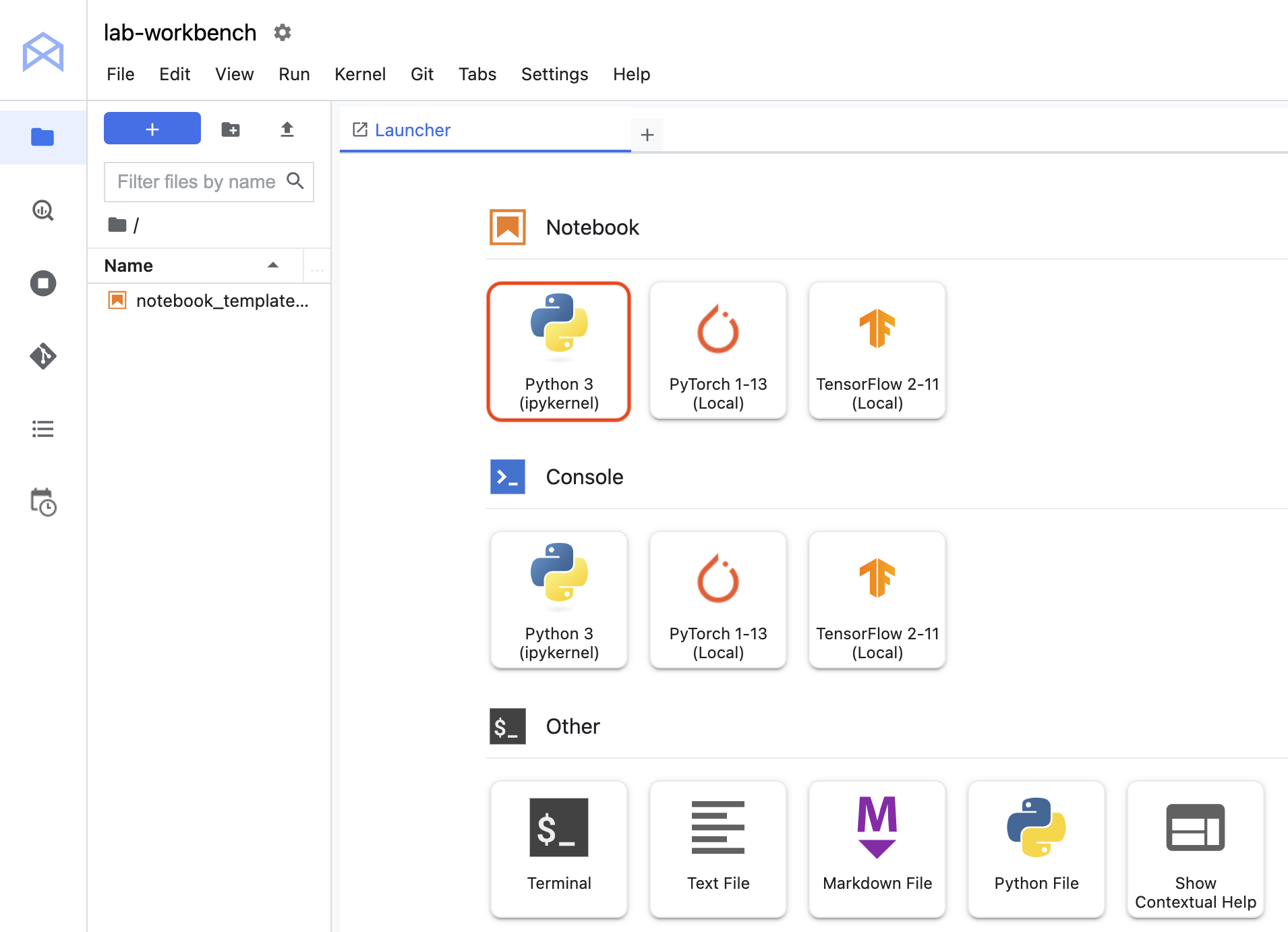
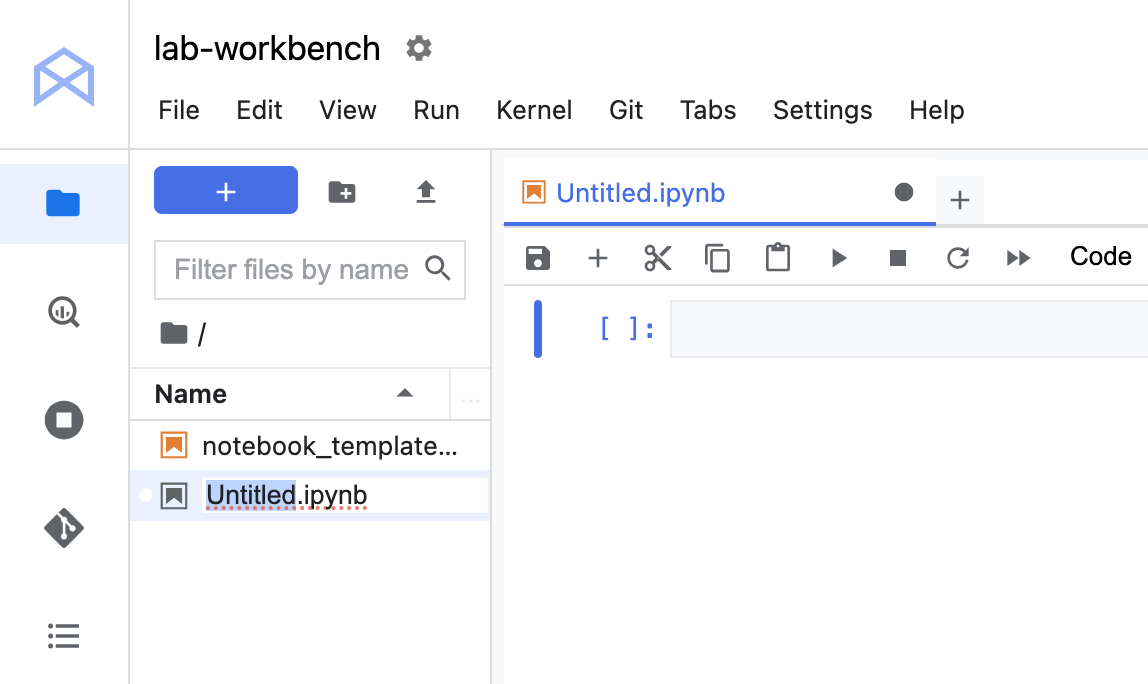
- Klik kanan file
Untitled.ipynb di panel menu dan pilih Rename Notebook untuk memberinya nama yang bermakna.
- Untuk menginstal kedua layanan yang diperlukan untuk lab ini, tetapkan terlebih dahulu flag pengguna di sel notebook:
USER_FLAG = "--user"
- Kemudian jalankan kode berikut dari notebook Anda:
%pip install $USER_FLAG google-cloud-aiplatform==1.59.0
%pip install $USER_FLAG kfp google-cloud-pipeline-components==0.1.1 --upgrade
%pip uninstall -y shapely pygeos geopandas
%pip install shapely==1.8.5.post1 pygeos==0.12.0 geopandas>=0.12.2
%pip install google-cloud-pipeline-components
Catatan: Anda akan melihat peringatan dan error terkait versi, yang aman untuk Anda abaikan.
- Setelah menginstal paket ini, Anda perlu memulai ulang kernel:
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
- Terakhir, pastikan Anda telah menginstal paket dengan benar. Versi KFP SDK harus >=1.6:
!python3 -c "import kfp; print('KFP SDK version: {}'.format(kfp.__version__))"
!python3 -c "import google_cloud_pipeline_components; print('google_cloud_pipeline_components version: {}'.format(google_cloud_pipeline_components.__version__))"
Langkah 2: Menetapkan project ID dan bucket Anda
Di sepanjang lab ini, Anda akan mereferensikan Project ID Cloud dan bucket yang telah Anda buat sebelumnya. Selanjutnya, Anda akan membuat variabel untuk keduanya.
- Jika tidak mengetahui project ID Anda, Anda bisa mendapatkannya dengan menjalankan kode berikut:
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
- Lalu buat variabel untuk menyimpan nama bucket Anda.
BUCKET_NAME="gs://" + PROJECT_ID + "-labconfig-bucket"
Langkah 3: Mengimpor library
- Tambahkan kode berikut untuk mengimpor library yang akan Anda gunakan di sepanjang lab ini:
from typing import NamedTuple
import kfp
from kfp import dsl
from kfp.v2 import compiler
from kfp.v2.dsl import (Artifact, Dataset, Input, InputPath, Model, Output,
OutputPath, ClassificationMetrics, Metrics, component)
from kfp.v2.google.client import AIPlatformClient
from google.cloud import aiplatform
from google_cloud_pipeline_components import aiplatform as gcc_aip
Langkah 4: Menentukan variabel konstan
- Hal terakhir yang perlu Anda lakukan sebelum membangun pipeline adalah menentukan beberapa variabel konstan.
PIPELINE_ROOT adalah jalur Cloud Storage tempat artefak yang dibuat oleh pipeline Anda akan ditulis. Anda menggunakan sebagai region di sini, tetapi jika Anda menggunakan region lain saat membuat bucket, update variabel REGION pada kode di bawah ini:
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
REGION="{{{ project_0.default_region | Placeholder value. }}}"
PIPELINE_ROOT = f"{BUCKET_NAME}/pipeline_root/"
PIPELINE_ROOT
Setelah menjalankan kode di atas, Anda akan melihat direktori root untuk pipeline Anda ditampilkan. Ini adalah lokasi Cloud Storage tempat artefak dari pipeline Anda akan ditulis. Direktori root tersebut akan ditampilkan dalam format gs://<bucket_name>/pipeline_root/.
Tugas 3. Membuat pipeline pertama Anda
-
Buat pipeline pendek menggunakan KFP SDK. Pipeline ini tidak melakukan apa pun yang berkaitan dengan ML (jangan khawatir, Anda akan mempelajarinya nanti!), tujuan latihan ini adalah untuk mengajarkan:
- Cara membuat komponen kustom di KFP SDK
- Cara menjalankan dan memantau pipeline di Vertex AI Pipelines
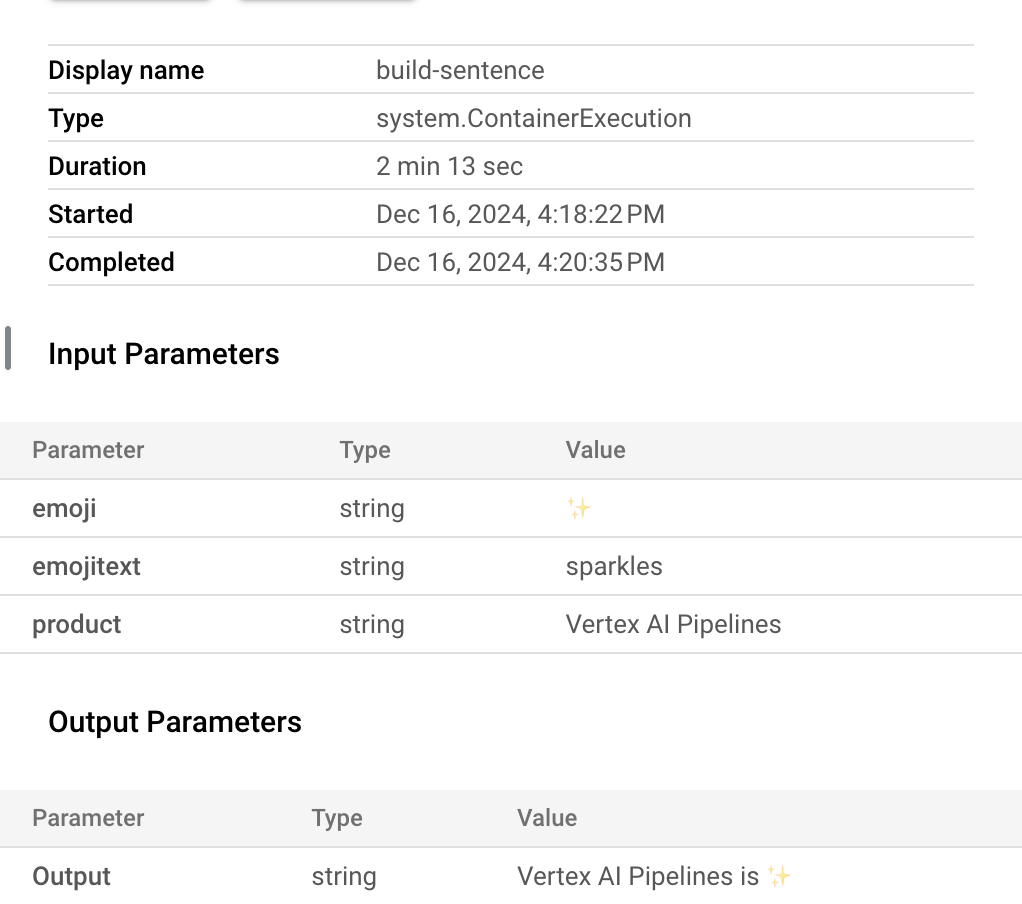
Anda akan membuat pipeline yang menampilkan suatu kalimat menggunakan dua output: nama produk dan deskripsi emoji. Pipeline ini akan mencakup tiga komponen:
-
product_name: Komponen ini akan menggunakan nama produk sebagai input, dan menampilkan string tersebut sebagai output.
-
emoji: Komponen ini akan menggunakan deskripsi teks suatu emoji dan mengonversinya menjadi emoji. Misalnya, kode teks untuk ✨ adalah "sparkles". Komponen ini menggunakan library emoji untuk menunjukkan cara mengelola dependensi eksternal di pipeline Anda.
-
build_sentence: Komponen terakhir ini akan memakai output dari dua komponen sebelumnya untuk membuat kalimat yang menggunakan emoji. Misalnya, output yang dihasilkan mungkin berbunyi "Vertex AI Pipelines is ✨".
Langkah 1: Membuat komponen berdasarkan fungsi Python
Dengan menggunakan KFP SDK, Anda dapat membuat komponen berdasarkan fungsi Python. Pertama, buat komponen product_name, yang mengambil suatu string sebagai input lalu menampilkan string tersebut.
- Tambahkan kode berikut ke notebook Anda:
@component(base_image="python:3.9", output_component_file="first-component.yaml")
def product_name(text: str) -> str:
return text
Pelajari sintaksis lebih lanjut di sini:
- Dekorator
@component mengompilasi fungsi ini ke komponen saat pipeline dijalankan. Anda akan menggunakannya setiap kali Anda menulis komponen kustom.
- Parameter
base_image menentukan image container yang akan digunakan komponen ini.
- Parameter
output_component_file bersifat opsional, dan menentukan file yaml tempat komponen yang dikompilasi akan ditulis. Setelah menjalankan sel, Anda akan melihat file tersebut ditulis ke instance notebook Anda. Jika Anda ingin membagikan komponen ini kepada seseorang, Anda dapat mengirimi orang tersebut file yaml yang dihasilkan, dan kemudian dia dapat memuatnya dengan kode berikut:
product_name_component = kfp.components.load_component_from_file('./first-component.yaml')
-> str setelah definisi fungsi menentukan jenis output untuk komponen ini.
Langkah 2: Membuat dua komponen tambahan
- Untuk menyelesaikan pipeline, buat dua komponen tambahan. Komponen pertama menggunakan string sebagai input, lalu mengonversi string ini menjadi emoji yang sesuai, jika ada. Komponen pertama ini menampilkan tuple dengan teks input yang diteruskan, dan emoji yang dihasilkan:
@component(base_image="python:3.9", output_component_file="second-component.yaml", packages_to_install=["emoji"])
def emoji(
text: str,
) -> NamedTuple(
"Outputs",
[
("emoji_text", str), # Return parameters
("emoji", str),
],
):
import emoji
emoji_text = text
emoji_str = emoji.emojize(':' + emoji_text + ':', language='alias')
print("output one: {}; output_two: {}".format(emoji_text, emoji_str))
return (emoji_text, emoji_str)
Komponen ini sedikit lebih rumit daripada komponen sebelumnya. Berikut adalah perbedaannya:
- Parameter
packages_to_install memberi tahu komponen semua dependensi library eksternal untuk container ini. Dalam hal ini, Anda menggunakan library yang bernama emoji.
- Komponen ini menampilkan
NamedTuple yang disebut Outputs. Perhatikan bahwa setiap string dalam tuple ini memiliki kunci: emoji_text dan emoji. Anda akan menggunakan kedua kunci ini di komponen selanjutnya untuk mengakses output.
- Komponen terakhir dalam pipeline ini akan menggunakan output dari dua komponen pertama dan menggabungkannya untuk menampilkan string:
@component(base_image="python:3.9", output_component_file="third-component.yaml")
def build_sentence(
product: str,
emoji: str,
emojitext: str
) -> str:
print("We completed the pipeline, hooray!")
end_str = product + " is "
if len(emoji) > 0:
end_str += emoji
else:
end_str += emojitext
return(end_str)
Anda mungkin penasaran: bagaimana komponen ini tahu cara menggunakan output dari langkah sebelumnya yang Anda tentukan?
Pertanyaan bagus! Anda akan menggabungkan semuanya pada langkah selanjutnya.
Langkah 3: Menggabungkan komponen ke dalam pipeline
Definisi komponen yang ditentukan di atas membuat fungsi factory yang dapat digunakan dalam definisi pipeline untuk membuat langkah-langkah.
-
Untuk menyiapkan pipeline, gunakan dekorator @dsl.pipeline, beri nama dan deskripsi pada pipeline, lalu beri jalur root tempat artefak pipeline Anda akan ditulis. Artefak adalah semua file output yang dihasilkan oleh pipeline Anda. Pipeline intro ini tidak menghasilkan artefak apa pun, tetapi pipeline Anda yang selanjutnya akan menghasilkannya.
-
Pada blok kode selanjutnya, Anda akan menentukan fungsi intro_pipeline. Di sinilah tempat Anda menentukan input untuk langkah-langkah pipeline awal dan bagaimana setiap langkah tersebut saling berhubungan satu sama lain:
-
product_task menggunakan nama produk sebagai input. Di sini, Anda akan meneruskan "Vertex AI Pipelines", tetapi Anda dapat mengubahnya menjadi apa pun sesuai keinginan.
-
emoji_task menggunakan kode teks untuk emoji sebagai input. Anda juga dapat mengubahnya menjadi apa pun sesuai keinginan Anda. Misalnya, "party_face" merujuk pada emoji 🥳. Perlu diperhatikan bahwa, karena komponen ini dan komponen product_task tidak memiliki langkah untuk memasukkan input ke dalamnya, Anda perlu secara manual menetapkan input komponen ini saat menentukan pipeline.
- Langkah terakhir di pipeline -
consumer_task memiliki tiga parameter input:
- Output
product_task. Karena langkah ini hanya menghasilkan satu output, Anda dapat mereferensikannya melalui product_task.output.
- Output
emoji pada langkah emoji_task. Lihat komponen emoji yang ditentukan di atas tempat Anda menamai parameter output.
- Demikian pula,
emoji_text menamai output dari komponen emoji. Jika pipeline Anda meneruskan teks yang tidak terkait dengan emoji, pipeline akan menggunakan teks ini untuk menyusun kalimat.
@dsl.pipeline(
name="hello-world",
description="An intro pipeline",
pipeline_root=PIPELINE_ROOT,
)
# You can change the `text` and `emoji_str` parameters here to update the pipeline output
def intro_pipeline(text: str = "Vertex AI Pipelines", emoji_str: str = "sparkles"):
product_task = product_name(text)
emoji_task = emoji(emoji_str)
consumer_task = build_sentence(
product_task.output,
emoji_task.outputs["emoji"],
emoji_task.outputs["emoji_text"],
)
Langkah 4: Mengompilasi dan menjalankan pipeline
- Setelah menentukan pipeline, Anda siap untuk mengompilasinya. Kode berikut akan menghasilkan file JSON yang akan Anda gunakan untuk menjalankan pipeline:
compiler.Compiler().compile(
pipeline_func=intro_pipeline, package_path="intro_pipeline_job.json"
)
- Selanjutnya, buat instance klien API:
api_client = AIPlatformClient(
project_id=PROJECT_ID,
region=REGION,
)
- Terakhir, jalankan pipeline:
response = api_client.create_run_from_job_spec(
job_spec_path="intro_pipeline_job.json",
# pipeline_root=PIPELINE_ROOT # this argument is necessary if you did not specify PIPELINE_ROOT as part of the pipeline definition.
)
Menjalankan pipeline akan menghasilkan link untuk melihat proses pipeline di konsol Anda. Begitu selesai, tindakan tersebut akan terlihat seperti ini:
- Pipeline ini akan memerlukan waktu 5—6 menit untuk dijalankan. Begitu selesai, Anda dapat mengklik komponen
build-sentence untuk melihat output akhir:
Setelah memahami cara kerja KFP SDK dan Vertex AI Pipelines, Anda siap membangun pipeline yang membuat dan men-deploy model ML menggunakan layanan Vertex AI lainnya.
Klik Periksa progres saya untuk memverifikasi tujuan.
Memastikan pipeline emoji Anda telah selesai
Tugas 4. Membuat pipeline ML end-to-end
Waktunya membangun pipeline ML pertama Anda. Di pipeline ini, Anda akan menggunakan set data Dry Bean UCI Machine Learning, dari: KOKLU, M. and OZKAN, I.A., (2020), "Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques."In Computers and Electronics in Agriculture, 174, 105507. DOI.
Catatan: Perlu waktu lebih dari 2 jam untuk menyelesaikan pipeline ini. Jadi, Anda tidak perlu menunggu sampai pipeline selesai untuk menyelesaikan lab ini. Ikuti langkah-langkah hingga tugas pipeline Anda dimulai.
Dry Bean adalah set data tabulasi, dan di pipeline Anda akan menggunakan set data ini untuk melatih, mengevaluasi, dan men-deploy model AutoML yang mengklasifikasi bean ke dalam salah satu dari 7 jenis berdasarkan karakteristiknya.
Pipeline ini akan:
- Membuat Set data di Vertex AI
- Melatih model klasifikasi tabulasi dengan AutoML
- Mendapatkan metrik evaluasi pada model ini
- Memutuskan apakah akan men-deploy model menggunakan logika kondisional di Vertex AI Pipelines atau tidak berdasarkan metrik evaluasi
- Men-deploy model ke endpoint menggunakan Vertex AI Prediction
Tiap langkah yang diuraikan akan menjadi komponen. Sebagian besar langkah-langkah pipeline akan menggunakan komponen bawaan untuk layanan Vertex AI melalui library google_cloud_pipeline_components yang Anda impor sebelumnya di lab ini.
Di bagian ini, kita akan menentukan satu komponen kustom terlebih dahulu. Kemudian, kita akan menentukan langkah pipeline hingga akhir menggunakan komponen bawaan. Komponen bawaan memudahkan akses ke layanan Vertex AI, seperti pelatihan model dan deployment.
Sebagian besar waktu untuk langkah ini adalah untuk bagian pelatihan AutoML pipeline ini, yang akan memerlukan waktu sekitar satu jam.
Langkah 1: Komponen kustom untuk evaluasi model
Komponen kustom yang akan Anda tentukan akan digunakan di akhir pipeline begitu pelatihan model selesai. Komponen ini akan melakukan beberapa hal berikut:
- Mendapatkan metrik evaluasi dari model klasifikasi AutoML yang dilatih
- Mengurai metrik dan merender metrik tersebut di UI Vertex AI Pipelines
- Membandingkan metrik terhadap nilai minimum untuk menentukan apakah model perlu di-deploy atau tidak
Sebelum menentukan komponen, pahami parameter input dan output-nya. Sebagai input, pipeline ini menggunakan beberapa metadata di project Cloud Anda, model terlatih yang dihasilkan (Anda akan menentukan komponen ini nanti), metrik evaluasi model, dan thresholds_dict_str.
thresholds_dict_str akan Anda tentukan saat Anda menjalankan pipeline. Dalam hal model klasifikasi ini, Anda akan menggunakan nilai area di bawah kurva KOP untuk menentukan apakah Anda perlu men-deploy model. Misalnya, jika Anda meneruskan 0,95, artinya Anda hanya ingin pipeline Anda men-deploy model jika metrik ini di atas 95%.
Komponen evaluasi menampilkan string yang menunjukkan apakah model perlu di-deploy atau tidak.
- Tambahkan kode berikut di sel notebook untuk membuat komponen kustom ini:
@component(
base_image="gcr.io/deeplearning-platform-release/tf2-cpu.2-3:latest",
output_component_file="tables_eval_component.yaml", # Optional: you can use this to load the component later
packages_to_install=["google-cloud-aiplatform"],
)
def classif_model_eval_metrics(
project: str,
location: str, # "region",
api_endpoint: str, # "region-aiplatform.googleapis.com",
thresholds_dict_str: str,
model: Input[Model],
metrics: Output[Metrics],
metricsc: Output[ClassificationMetrics],
) -> NamedTuple("Outputs", [("dep_decision", str)]): # Return parameter.
"""This function renders evaluation metrics for an AutoML Tabular classification model.
It retrieves the classification model evaluation generated by the AutoML Tabular training
process, does some parsing, and uses that info to render the ROC curve and confusion matrix
for the model. It also uses given metrics threshold information and compares that to the
evaluation results to determine whether the model is sufficiently accurate to deploy.
"""
import json
import logging
from google.cloud import aiplatform
# Fetch model eval info
def get_eval_info(client, model_name):
from google.protobuf.json_format import MessageToDict
response = client.list_model_evaluations(parent=model_name)
metrics_list = []
metrics_string_list = []
for evaluation in response:
print("model_evaluation")
print(" name:", evaluation.name)
print(" metrics_schema_uri:", evaluation.metrics_schema_uri)
metrics = MessageToDict(evaluation._pb.metrics)
for metric in metrics.keys():
logging.info("metric: %s, value: %s", metric, metrics[metric])
metrics_str = json.dumps(metrics)
metrics_list.append(metrics)
metrics_string_list.append(metrics_str)
return (
evaluation.name,
metrics_list,
metrics_string_list,
)
# Use the given metrics threshold(s) to determine whether the model is
# accurate enough to deploy.
def classification_thresholds_check(metrics_dict, thresholds_dict):
for k, v in thresholds_dict.items():
logging.info("k {}, v {}".format(k, v))
if k in ["auRoc", "auPrc"]: # higher is better
if metrics_dict[k] < v: # if under threshold, don't deploy
logging.info(
"{} < {}; returning False".format(metrics_dict[k], v)
)
return False
logging.info("threshold checks passed.")
return True
def log_metrics(metrics_list, metricsc):
test_confusion_matrix = metrics_list[0]["confusionMatrix"]
logging.info("rows: %s", test_confusion_matrix["rows"])
# log the ROC curve
fpr = []
tpr = []
thresholds = []
for item in metrics_list[0]["confidenceMetrics"]:
fpr.append(item.get("falsePositiveRate", 0.0))
tpr.append(item.get("recall", 0.0))
thresholds.append(item.get("confidenceThreshold", 0.0))
print(f"fpr: {fpr}")
print(f"tpr: {tpr}")
print(f"thresholds: {thresholds}")
metricsc.log_roc_curve(fpr, tpr, thresholds)
# log the confusion matrix
annotations = []
for item in test_confusion_matrix["annotationSpecs"]:
annotations.append(item["displayName"])
logging.info("confusion matrix annotations: %s", annotations)
metricsc.log_confusion_matrix(
annotations,
test_confusion_matrix["rows"],
)
# log textual metrics info as well
for metric in metrics_list[0].keys():
if metric != "confidenceMetrics":
val_string = json.dumps(metrics_list[0][metric])
metrics.log_metric(metric, val_string)
# metrics.metadata["model_type"] = "AutoML Tabular classification"
logging.getLogger().setLevel(logging.INFO)
aiplatform.init(project=project)
# extract the model resource name from the input Model Artifact
model_resource_path = model.uri.replace("aiplatform://v1/", "")
logging.info("model path: %s", model_resource_path)
client_options = {"api_endpoint": api_endpoint}
# Initialize client that will be used to create and send requests.
client = aiplatform.gapic.ModelServiceClient(client_options=client_options)
eval_name, metrics_list, metrics_str_list = get_eval_info(
client, model_resource_path
)
logging.info("got evaluation name: %s", eval_name)
logging.info("got metrics list: %s", metrics_list)
log_metrics(metrics_list, metricsc)
thresholds_dict = json.loads(thresholds_dict_str)
deploy = classification_thresholds_check(metrics_list[0], thresholds_dict)
if deploy:
dep_decision = "true"
else:
dep_decision = "false"
logging.info("deployment decision is %s", dep_decision)
return (dep_decision,)
Langkah 2: Menambahkan komponen bawaan Google Cloud
Di langkah ini Anda akan menentukan komponen pipeline lainnya dan melihat kecocokan komponen antara satu sama lain.
- Pertama, tentukan nama tampilan untuk proses pipeline menggunakan stempel waktu:
import time
DISPLAY_NAME = 'automl-beans{}'.format(str(int(time.time())))
print(DISPLAY_NAME)
- Lalu salin kode berikut ke sel notebook baru:
@kfp.dsl.pipeline(name="automl-tab-beans-training-v2",
pipeline_root=PIPELINE_ROOT)
def pipeline(
bq_source: str = "bq://aju-dev-demos.beans.beans1",
display_name: str = DISPLAY_NAME,
project: str = PROJECT_ID,
gcp_region: str = "{{{ project_0.default_region | Placeholder value. }}}",
api_endpoint: str = "{{{ project_0.default_region | Placeholder value. }}}-aiplatform.googleapis.com",
thresholds_dict_str: str = '{"auRoc": 0.95}',
):
dataset_create_op = gcc_aip.TabularDatasetCreateOp(
project=project, display_name=display_name, bq_source=bq_source
)
training_op = gcc_aip.AutoMLTabularTrainingJobRunOp(
project=project,
display_name=display_name,
optimization_prediction_type="classification",
budget_milli_node_hours=1000,
column_transformations=[
{"numeric": {"column_name": "Area"}},
{"numeric": {"column_name": "Perimeter"}},
{"numeric": {"column_name": "MajorAxisLength"}},
{"numeric": {"column_name": "MinorAxisLength"}},
{"numeric": {"column_name": "AspectRation"}},
{"numeric": {"column_name": "Eccentricity"}},
{"numeric": {"column_name": "ConvexArea"}},
{"numeric": {"column_name": "EquivDiameter"}},
{"numeric": {"column_name": "Extent"}},
{"numeric": {"column_name": "Solidity"}},
{"numeric": {"column_name": "roundness"}},
{"numeric": {"column_name": "Compactness"}},
{"numeric": {"column_name": "ShapeFactor1"}},
{"numeric": {"column_name": "ShapeFactor2"}},
{"numeric": {"column_name": "ShapeFactor3"}},
{"numeric": {"column_name": "ShapeFactor4"}},
{"categorical": {"column_name": "Class"}},
],
dataset=dataset_create_op.outputs["dataset"],
target_column="Class",
)
model_eval_task = classif_model_eval_metrics(
project,
gcp_region,
api_endpoint,
thresholds_dict_str,
training_op.outputs["model"],
)
with dsl.Condition(
model_eval_task.outputs["dep_decision"] == "true",
name="deploy_decision",
):
deploy_op = gcc_aip.ModelDeployOp( # noqa: F841
model=training_op.outputs["model"],
project=project,
machine_type="e2-standard-4",
)
Yang terjadi dalam kode ini:
- Pertama, seperti pada pipeline sebelumnya, Anda menentukan parameter input yang digunakan oleh pipeline ini. Anda perlu menentukannya secara manual karena parameter input ini tidak bergantung pada output dari langkah-langkah lainnya di pipeline.
- Pipeline yang tersisa menggunakan beberapa komponen bawaan untuk berinteraksi dengan layanan Vertex AI:
-
TabularDatasetCreateOp membuat set data tabulasi di Vertex AI dengan sumber set data di Cloud Storage atau BigQuery. Di pipeline ini, Anda meneruskan data melalui URL Tabel BigQuery.
-
AutoMLTabularTrainingJobRunOp memulai tugas pelatihan AutoML untuk set data tabulasi. Anda meneruskan beberapa parameter konfigurasi ke komponen ini, termasuk jenis model (dalam hal ini, klasifikasi), beberapa data di kolom, durasi waktu menjalankan pelatihan, dan pointer ke set data tabulasi. Perhatikan bahwa untuk meneruskan set data tersebut ke komponen ini, Anda perlu menyediakan output dari komponen sebelumnya melalui dataset_create_op.outputs["dataset"] .
-
ModelDeployOp men-deploy model tertentu ke endpoint di Vertex AI. Tersedia opsi konfigurasi tambahan, tetapi di sini Anda akan menyediakan model, project, dan jenis mesin endpoint yang ingin Anda deploy. Anda akan meneruskan model dengan mengakses output dari langkah pelatihan di pipeline Anda.
- Pipeline ini juga memanfaatkan logika kondisional, yakni fitur Vertex AI Pipelines yang memungkinkan Anda menentukan kondisi, beserta berbagai cabang berdasarkan hasil dari kondisi tersebut. Ingat bahwa saat Anda menentukan pipeline, Anda meneruskan parameter
thresholds_dict_str. Ini adalah nilai minimum akurasi yang Anda gunakan untuk menentukan apakah Anda perlu men-deploy model Anda ke endpoint atau tidak. Untuk mengimplementasikan hal ini, manfaatkan class Condition dari KFP SDK. Kondisi yang diteruskan adalah output komponen evaluasi kustom yang Anda tentukan sebelumnya di lab ini. Jika kondisi ini benar, pipeline akan terus menjalankan komponen deploy_op. Jika akurasi tidak mencapai nilai minimum yang ditetapkan, pipeline akan berhenti di sini dan tidak akan men-deploy model.
Langkah 3: Mengompilasi dan menjalankan pipeline ML end-to-end
- Setelah menentukan semua pipeline, waktunya untuk mengompilasinya:
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="tab_classif_pipeline.json"
)
- Selanjutnya, mulai proses pipeline:
response = api_client.create_run_from_job_spec(
"tab_classif_pipeline.json", pipeline_root=PIPELINE_ROOT,
parameter_values={"project": PROJECT_ID,"display_name": DISPLAY_NAME}
)
- Klik link yang ditampilkan setelah menjalankan sel di atas untuk melihat pipeline Anda di konsol. Pipeline ini akan memerlukan waktu satu jam lebih untuk dijalankan. Sebagian besar waktu tersebut dihabiskan pada langkah pelatihan AutoML. Pipeline yang sudah selesai akan tampak seperti berikut:
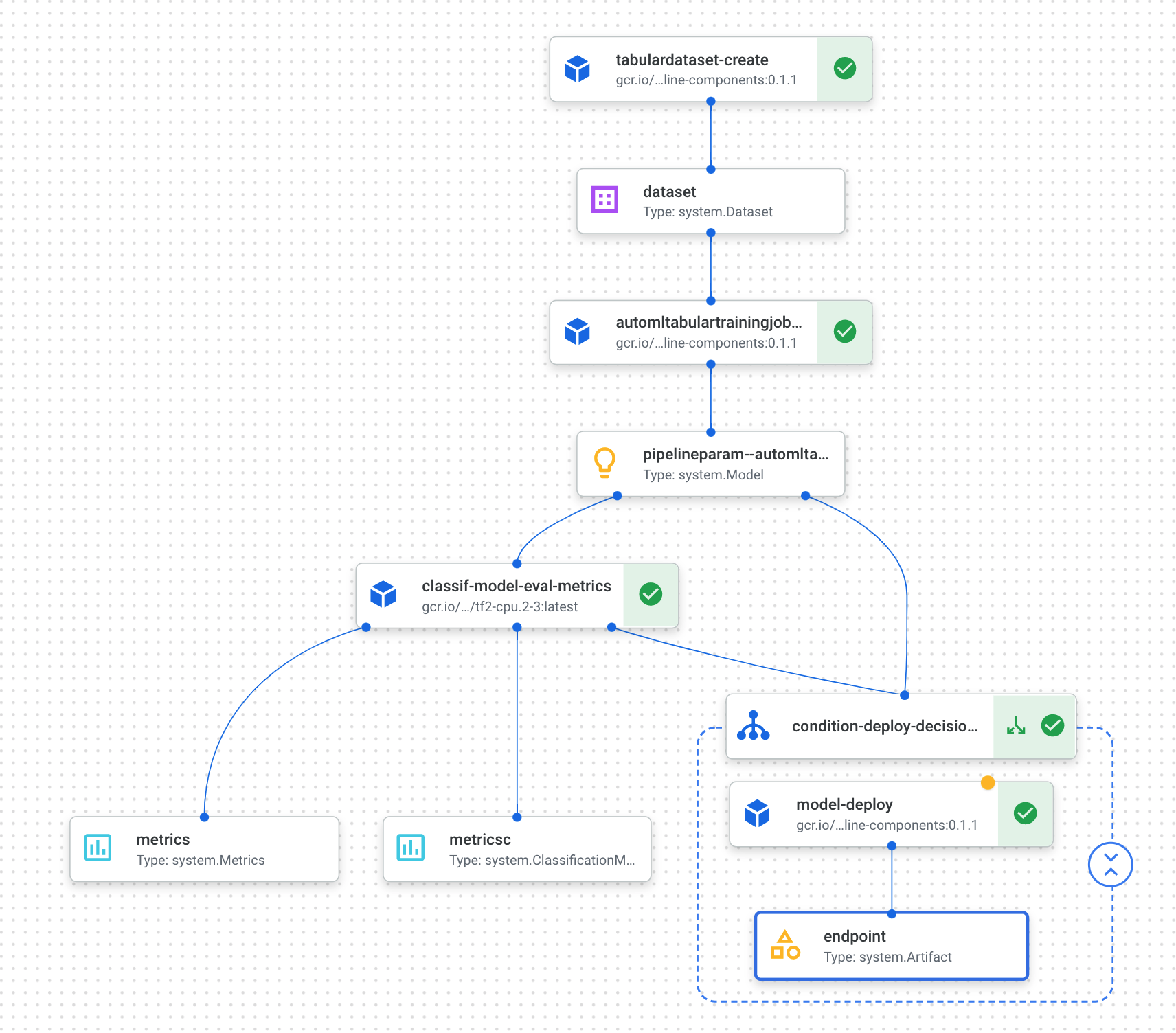
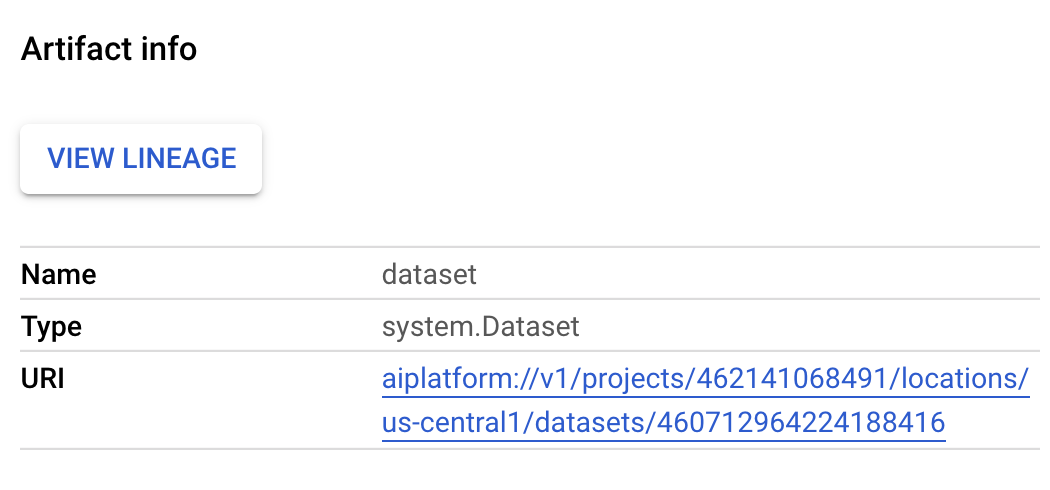
- Jika Anda menekan tombol "Expand artifacts" di atas, Anda dapat melihat detail untuk berbagai artefak yang dibuat dari pipeline Anda. Misalnya, jika Anda mengklik artefak
dataset, Anda akan melihat detail pada set data Vertex AI yang telah dibuat. Anda dapat mengklik link di sini guna membuka halaman untuk set data tersebut:
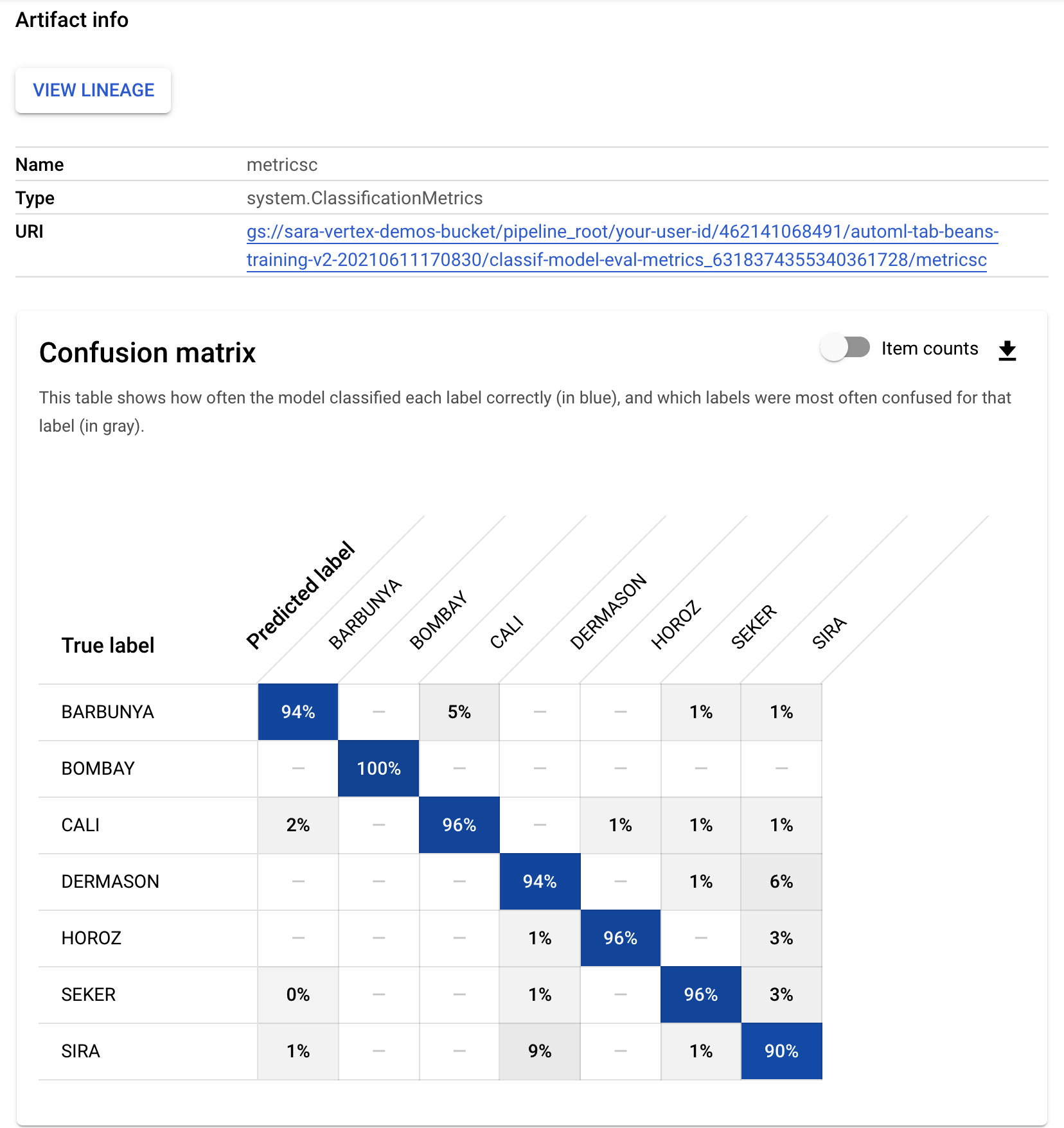
- Demikian pula, untuk melihat visualisasi metrik yang dihasilkan dari komponen evaluasi kustom, klik artefak bernama metricsc. Di bagian kanan dasbor, Anda dapat melihat matriks konfusi untuk model ini:
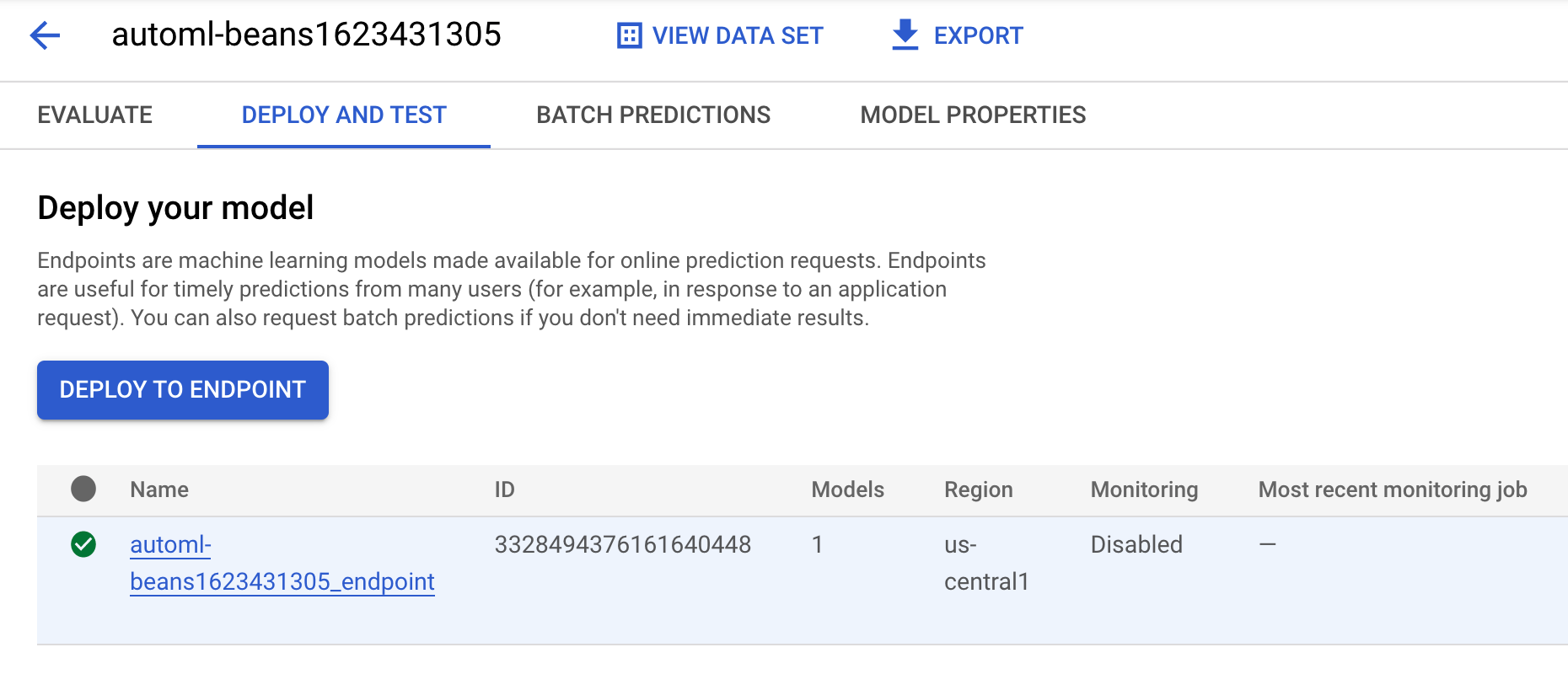
- Untuk melihat model dan endpoint yang dibuat dari proses pipeline ini, buka bagian model dan klik model bernama
automl-beans. Di bagian tersebut, Anda akan melihat model ini di-deploy ke endpoint:
-
Anda juga dapat mengakses halaman ini dengan mengklik artefak endpoint di grafik pipeline Anda.
-
Selain melihat grafik pipeline di konsol, Anda juga dapat menggunakan Vertex AI Pipelines untuk melakukan Pelacakan Silsilah.
-
Pelacakan silsilah berarti melacak artefak yang dibuat di seluruh pipeline Anda. Hal ini dapat membantu Anda memahami lokasi artefak dibuat dan cara artefak digunakan di seluruh alur kerja ML. Misalnya, guna melihat pelacakan silsilah untuk set data yang dibuat di pipeline ini, klik artefak set data, lalu View Lineage:
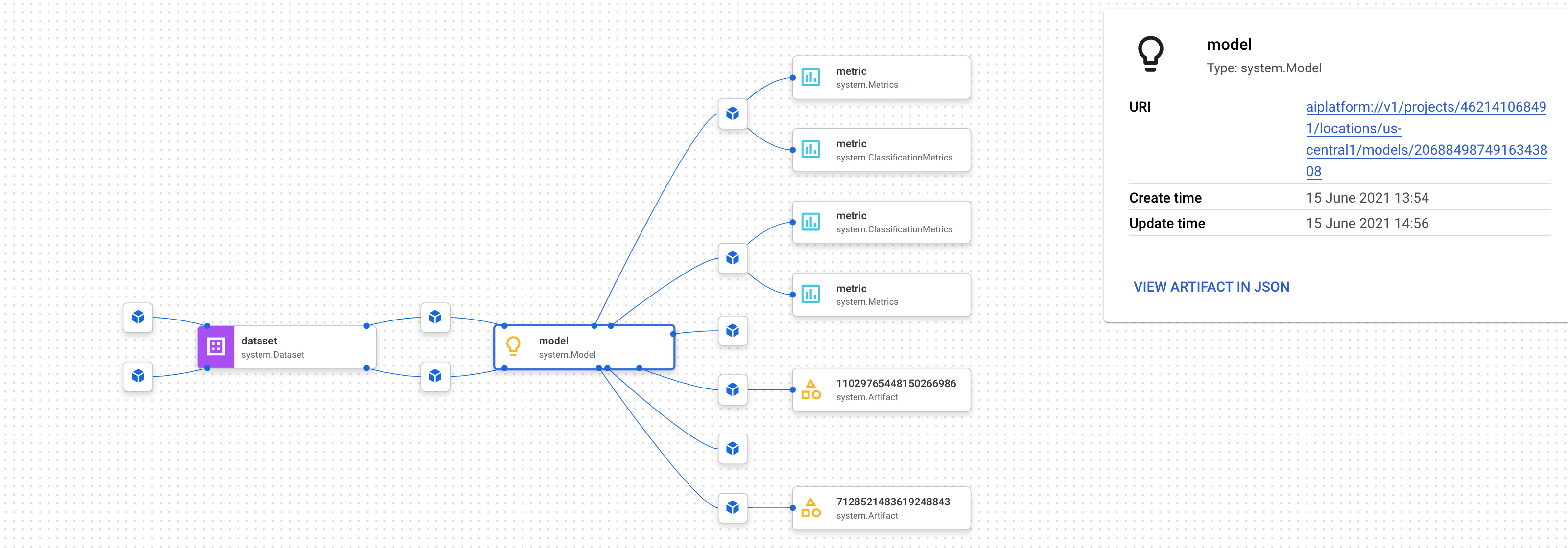
Semua tempat yang menggunakan artefak ini akan ditampilkan:
Catatan: Tunggu hingga tugas pelatihan di pipeline Anda dimulai, lalu periksa progres Anda di bawah. Tugas pelatihan akan membutuhkan waktu lebih banyak daripada waktu yang dialokasikan untuk lab ini, tetapi Anda akan diberi poin penuh jika berhasil mengirimkan tugas pelatihan.
Klik Periksa progres saya untuk memverifikasi tujuan.
Memastikan apakah tugas pelatihan pipeline ML end-to-end Anda telah dimulai
Langkah 4: Membandingkan metrik di seluruh proses pipeline (Opsional)
- Jika Anda menjalankan pipeline ini beberapa kali, Anda mungkin ingin membandingkan metrik diseluruh proses. Anda dapat menggunakan metode
aiplatform.get_pipeline_df() untuk mengakses metadata pipeline yang dijalankan. Di sini, kita akan mendapatkan metadata untuk semua proses pipeline dan memuatnya ke dalam DataFrame Pandas:
pipeline_df = aiplatform.get_pipeline_df(pipeline="automl-tab-beans-training-v2")
small_pipeline_df = pipeline_df.head(2)
small_pipeline_df
Anda telah belajar cara membangun, menjalankan, dan mendapatkan metadata untuk pipeline ML end-to-end di Vertex AI Pipelines.
Selamat!
Di lab ini, Anda telah membuat dan menjalankan pipeline emoji. Anda juga telah mempelajari cara membangun, menjalankan, dan mendapatkan metadata untuk pipeline ML end-to-end di Vertex AI Pipelines.
Langkah berikutnya/pelajari lebih lanjut
Cobalah skenario yang sama di Project Google Cloud Anda sendiri menggunakan Codelab Developer Relations.
Sertifikasi dan pelatihan Google Cloud
...membantu Anda mengoptimalkan teknologi Google Cloud. Kelas kami mencakup keterampilan teknis dan praktik terbaik untuk membantu Anda memahami dengan cepat dan melanjutkan proses pembelajaran. Kami menawarkan pelatihan tingkat dasar hingga lanjutan dengan opsi on demand, live, dan virtual untuk menyesuaikan dengan jadwal Anda yang sibuk. Sertifikasi membantu Anda memvalidasi dan membuktikan keterampilan serta keahlian Anda dalam teknologi Google Cloud.
Manual Terakhir Diperbarui pada 03 Januari 2025
Lab Terakhir Diuji pada 03 Januari 2025
Hak cipta 2025 Google LLC. Semua hak dilindungi undang-undang. Google dan logo Google adalah merek dagang dari Google LLC. Semua nama perusahaan dan produk lain mungkin adalah merek dagang masing-masing perusahaan yang bersangkutan.





