![[プロジェクト情報]、[API]、[リソース]、[お支払い] などのタイルが表示されたプロジェクト ダッシュボード](https://cdn.qwiklabs.com/dxfeoOcn1ObyC0BYyoqqqSi4rO%2FeMdbWPFjoK6C0YYk%3D)



始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
この演習では、アプリケーションからログエントリを生成し、Cloud Logging でログをフィルタし分析して、BigQuery ログシンクにログをエクスポートします。
このラボでは、次のタスクを行う方法について学びます。
テスト アプリケーションの設定とデプロイを行う。
テスト アプリケーションによって生成されたログエントリを確認する。
ログベースの指標を作成して使用する。
アプリケーション ログを BigQuery にエクスポートする。
このタスクでは、Qwiklabs を使用してラボの初期化手順を行います。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
最初のログイン手順を完了すると、プロジェクト ダッシュボードが表示されます。
Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
ロギング、ログのエクスポート、Error Reporting をテストするために、前の演習で使用した HelloLoggingNodeJS アプリケーションを Cloud Run にデプロイします。
後のステップで使用するので、Cloud Build、Compute Engine、Cloud Run の各 API を有効にします。
API を有効にしたら、https://github.com/haggman/HelloLoggingNodeJS.git リポジトリのクローンを作成します。
このリポジトリには、テストに使用される基本的な Node.js アプリケーションが含まれています。
HelloLoggingNodeJS フォルダに移動し、Cloud Shell エディタで index.js を開きます。
「サードパーティの Cookie が無効になっているためコードエディタを読み込めなかった」という内容のエラーが表示された場合は、[新しいウィンドウで開く] をクリックし、新しいタブに切り替えます。
少し時間をかけてコードをよく読みます。このコードが講義モジュール内のコード例の一部であることに気付いたでしょうか。
これによって Google Error Reporting ライブラリとデバッグ ライブラリが読み込まれる点に注意してください。
下にスクロールすると、ログ、エラー、エラーログを生成するいくつかのメソッドがあります。
特に /random-error に注目してください。このメソッドによって約 1,000 リクエストごとにエラーが生成されます。次のステップで、これを 20 リクエストに変更し、エラーの表示頻度を上げます。
捕捉されない例外を増やすために /random-error を 1,000 分の 1 から 20 分の 1 に変更します。Cloud Shell エディタで index.js を開きます。
index.js ファイルで、125~135 行目を以下の行に置き換えます。
エディタで rebuildService.sh ファイルも確認します。このファイルでは Cloud Build を使用して Docker コンテナを作成し、そのコンテナを使用して Cloud Run アプリケーションを作成(または更新)します。Cloud Run サービスでは匿名アクセスがサポートされており、ステージと部門に関する 2 つのラベルが付きます。また、1 つの実行インスタンスに対して許可される同時接続数は最大で 5 つのみです。
Cloud Shell ウィンドウに戻ります。Cloud Shell が表示されない場合、[ターミナルを開く] をクリックします。
ファイルを実行することにより、コンテナを作成して Cloud Run アプリケーションを開始します。
完了までに 1~2 分かかります。
Cloud Shell に表示される最後のメッセージに新しいサービスへの URL が含まれています。そのリンクをクリックし、新しいタブでアプリケーションをテストします。シンプルな「Hello World!」というレスポンスが返されます。
Cloud Shell ターミナル ウィンドウで新しい URL 環境変数を作成し、その値をアプリケーションへの URL に設定します。
値をエコーして、変数が正しく作成されたかどうかをテストします。
bash の while ループを使用して、アプリケーションの random-error ルートで負荷を生成します。主に「今回は成功した」という内容のメッセージが表示され始めるのを確認します。表示されない場合は、アプリケーションが実行されており、URL プロパティが正しく設定されていることをもう一度確認します。
アプリケーションが Cloud Run にデプロイされたので、URL に応じて、シンプルにログを作成するか、Winston を介してログを作成するか、エラーレポートを生成することができます。それらのログを数分かけて確認します。
Google Cloud コンソールの [ナビゲーション メニュー](
[クエリを表示] を有効にし、デフォルトでクエリが表示される場合は、それを消去します。
[リソース] プルダウン メニューを使用して [Cloud Run のリビジョン] > [hello-logging] Cloud Run サービスを選択します。選択した内容は適用しないとそのリソースで実際にフィルタされないので、忘れずに適用してください。
[クエリを実行] をクリックします。
多くの場合は、成功を示す 200 のメッセージしか見当たりません。エラーはどうすれば見つけられるでしょうか?1 つは 200 のレスポンスをすべて除外し、残ったものを確認する方法です。
完璧な方法ではありませんが、エラーに関連付けられたログメッセージと、発生しているエラーから生成されたスタック トレースが見つかります。
ログ フィールドを使用し、[重大度] が [エラー] のメッセージのみを表示するフィルタを適用します。エラーが発生したときのレスポンスが表示されています。
いずれかのエントリを開いて確認します。500 エラーが含まれているログファイルをメモしておきます。完了したら、エラーの重大度フィルタをクリアします。
開発者が最も興味を持つと思われるスタック トレースを確認するには、ログ フィールドを使用して run.googleapis.com/stderr 標準エラーログを対象とするフィルタを適用します。
例外が表示されますが、それぞれどこから開始しているのでしょうか?
スタック トレースを含む stderr ログと 500 ステータス エラーを含むリクエストログの両方を確認してみましょう。
クエリビルダー] をクリックして、[ログ名] を選択します。少し時間をかけて、表示されたログを確認します。クライアント リクエストにエラーを返しているレスポンスと、その後に stderr に送信されたスタック トレースが確認できます。
先ほどは Cloud Run サービスのログファイルを確認し、エラーエントリを調べました。しかし、エラーに関連するとは限らないカスタム ロギングを行っているとして、それに基づくカスタム指標を作成したい場合は、どうすればよいでしょうか?ここでは、/score ルートを呼び出すようにループを変更し、得られるスコアから指標を作成します。
このタスクでは、次のことを実行します。
/score エンドポイントで負荷を生成する。
負荷によって生成されたログを確認する。
コードを微調整してメッセージをより使いやすい形式にする。
新しいログベースの指標を作成する。
Cloud Shell に切り替えるか、再度開きます。
Ctrl+C を使用してテストループから抜けます。
/score ルートを呼び出すように while ループを変更し、ループを再開します。新しいメッセージにランダムスコアが表示されていることを確認します。
Google Cloud コンソール に切り替え、[ロギング] > [ログ エクスプローラ] ページを再度開きます。
既存のクエリをすべてクリアし、[リソース] を使用して [Cloud Run のリビジョン] > [hello-logging] ログを表示します。
[適用] をクリックします。
[クエリを実行] を選択します。
ステータス コードが 200 のエントリはすべて、この最新のテスト実行によって生成されたものであるはずです。そうでない場合は、[現在の位置に移動] をクリックしてログビューを更新します。
ステータス コードが 200 のエントリのうち、いずれかを開きます。 /score リクエストのエントリかどうかを見分けるには、どうすればよいでしょうか?ログエントリにスコアが表示されないのはなぜでしょうか?
ログ フィールド エクスプローラを使用して run.googleapis.com/stdout ログを対象にフィルタを適用します。
これで、コード自体によって表示されたすべてのメッセージが確認できるはずです。このエントリのスコアを表示する指標は、なぜ作成しにくいのでしょうか?
メッセージは非構造化テキストではなく、構造化 JSON として生成した方が便利です。そうすれば、ログベースの指標に含まれるスコアだけに簡単にアクセスし、抽出できます。
Cloud Shell ターミナル ウィンドウで、Ctrl+C を使用して while テストループから抜けます。
Cloud Shell エディタで index.js ファイルを開き、/score ルートのコードを見つけます(90 行目辺り)。
/score ルートを以下のコードに置き換えます。
メッセージの内容が output オブジェクトのプロパティになっている点と、表示されるメッセージが文字列化された JSON オブジェクトになっている点に注目してください。
コードを変更したので、Cloud Shell でアプリケーションをローカルに開始して、エラーが発生しないことを確認します。
Cloud Shell ターミナル ウィンドウで依存関係をインストールし、アプリケーションを開始します。現在地が HelloLoggingNodeJS フォルダ内になるようにします。
「Hello world listening on port 8080 message」と表示されたら、Ctrl+C を使用してアプリケーションを停止し、次のステップに進みます。エラーが表示された場合は、それを修正してアプリケーションが開始するのを確認してから先に進みます。
rebuildService.sh を再実行することにより、アプリケーションの再ビルドと再デプロイを行います。
アプリケーションの再ビルドと再デプロイが完了するまで待ってから、テストループを再開します。
スコア メッセージが再度表示されるのを確認します。
まだエントリには hello-logging の Cloud Run stdout ログを表示するようフィルタを適用しておく必要があります。
いずれかのエントリを開いて新しい形式を調べます。
指標タイプ: Distribution
ログ指標の名前: score_averages
単位: 1
フィールド名: jsonPayload.score
種類: Linear
開始値: 0
バケット数: 20
バケット幅: 5
[指標を作成] をクリックします。
[ナビゲーション メニュー](
[+CREATE DASHBOARD] をクリックします。
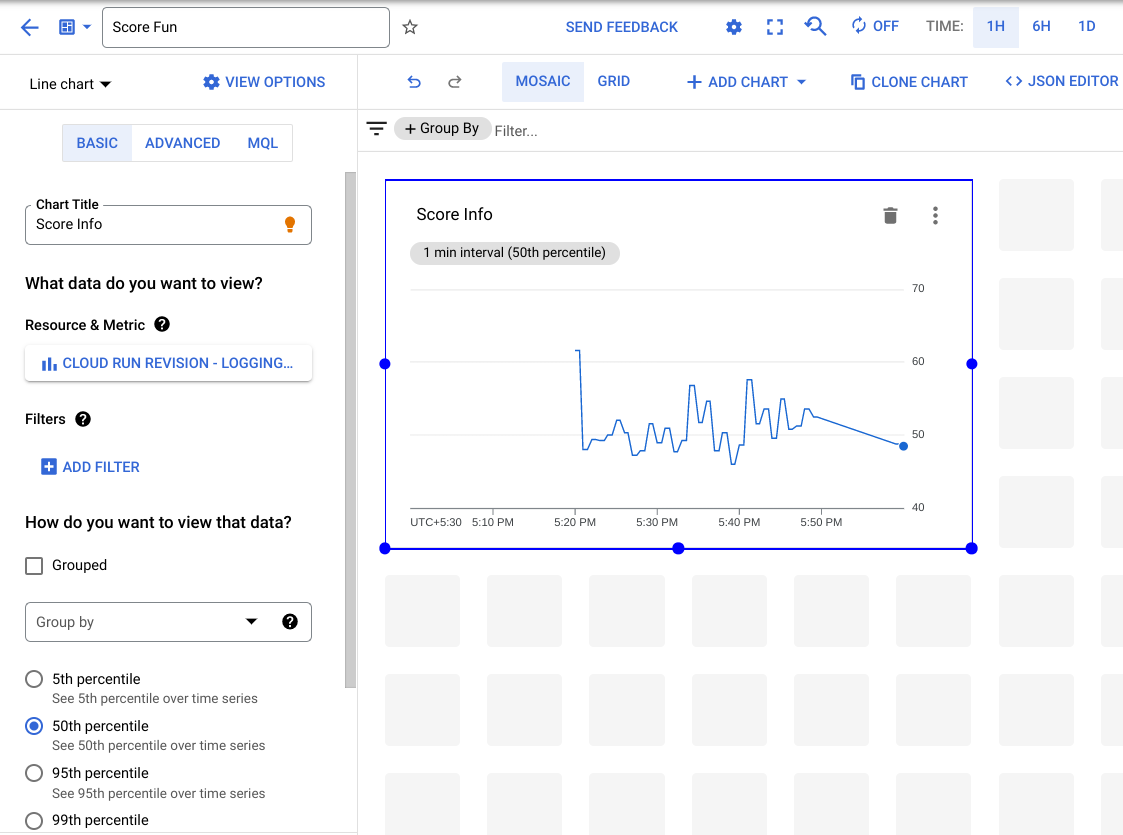
[New Dashboard Name] に「Score Fun」と入力します。
[Line] グラフをクリックします。
[Chart Title] を「Score Info」にします。
[Resource & Metric] セクションで [Cloud Run のリビジョン] > [ログベースの指標] から [logging/user/score_averages] を選択します。
[適用] をクリックします。
整列指定子はデフォルトで [50 パーセンタイル] に設定されています。そうでない場合は、[50 パーセンタイル](中央値)に設定します。
ログを BigQuery にエクスポートすると、より長期間にわたって保存できるだけでなく、SQL と BigQuery を活用して分析を行うこともできます。このタスクでは、Cloud Run ログの BigQuery へのエクスポートを設定し、それを使用して random-error アプリケーション ルートによって生成されたエラー メッセージを見つけます。
このタスクでは、次のことを実行します。
BigQuery へのログのエクスポートを設定する。
while ループによってアプリケーションに負荷が送信されている Cloud Shell ウィンドウに切り替え、Ctrl+C を使用してループから抜けます。
random-error ルートに負荷を再度送信するよう while を変更します。ループを再実行します。
Google Cloud コンソールの [ナビゲーション メニュー] を使用して [ロギング] > [ログ エクスプローラー] の順に移動します。
既存のクエリをすべて削除し、[リソース] を [Cloud Run のリビジョン] > [hello-logging] にしてクエリ フィルタリングを行います。
[適用] をクリックします。
1~2 個のエントリを開いて、それらが /random-error リクエストに関連していることを確認します。
[その他の操作] > [シンクの作成] でシンクを作成します。
[シンク名] を「hello-logging-sink」に設定します。
[次へ] をクリックします。
シンクサービスを [BigQuery データセット] に設定します。
[BigQuery データセット] で [新しい BigQuery データセットを作成する] を選択します。
データセット ID を hello_logging_logs と名付けます。
[データセットを作成] をクリックします。
[次へ] をクリックします。
[シンクに含めるログの選択] で、[次へ] をクリックします。
[シンクを作成] をクリックします。シンクを作成するときは、新しい BigQuery データセットへの書き込みに使用するサービス アカウントがどのように作成されるかに注意してください。
[ナビゲーション メニュー] を使用して [BigQuery] に切り替えます。
[エクスプローラ] セクションでプロジェクト ノードを展開し、hello_logging_logs データセットを展開します。
requests テーブルをクリックします。
クエリ ウィンドウの下にあるタブ形式のダイアログで、[プレビュー] タブをクリックしてこのログの情報を確認します。これにはリクエストに関する全般的な情報が含まれています。どのような URL が、いつ、どこからリクエストされたのかというような情報です。
[スキーマ] タブをクリックし、生成されたテーブルのスキーマを少し時間をかけて調べます。resource や httpRequest のような列にはネストや繰り返しのデータ構造が使用されている点に注意してください。
stderr テーブルを選択します。 標準出力と標準エラーは通常、シンプルなログメッセージとエラーに関連するメッセージを識別する目的でアプリケーションによって使用されます。Node.js アプリケーションでは、捕捉されていない例外やエラー関連の情報が標準エラーにダンプされます。
もう一度テーブル内のデータをプレビューします。リクエスト コールスタックのさまざまな部分に影響するものとして、ランダムなエラーが表示されています。ReferenceError を含む textPayload があるエントリは、それ自体が実際のエラーです。
[スキーマ] タブをクリックし、テーブルの実際の構造を調べます。やはり標準フィールド、ネストされたフィールド、繰り返しフィールドが混在しているのがわかります。
クエリを作成および実行し、先頭に ReferenceError がある textPayloads のみを抽出します。
[クエリ] ボタンをクリックしてクエリを開始します。
textPayload を抽出するように SELECT を変更します。
where 句を追加します。
[project-id] は自分の GCP プロジェクトの ID、[date] はテーブル名に指定した日付に置き換えてください。
再度実行し、表示されている数値を確認します。
[project-id] は自分の GCP プロジェクトの ID、[date] はテーブル名に指定した日付に置き換えてください。
ReferenceError% リクエスト数と比較するクエリを作成します。[project-id] は自分の GCP プロジェクトの ID、[date] はテーブル名に指定した日付に置き換えてください。
エラーの割合は 1/1,000 程度ですか?
この演習では、テスト アプリケーションを使用してログを生成し、それらのログのデータを使用してログベースの指標を作成し、ログを BigQuery にエクスポートしました。これで完了となります。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2020 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください