Neste laboratório, vamos criar aplicativos de treinamento conteinerizados para modelos de ML no TensorFlow, PyTorch, XGBoost e Scikit-learn. Depois vamos usar essas imagens como ops em um pipeline do KubeFlow e treinar vários modelos paralelamente. Por fim, vamos configurar execuções recorrentes do pipeline do Kubeflow na IU.
Objetivos:
criar o script de treinamento;
empacotar o script de treinamento como uma imagem do Docker;
criar e enviar a imagem de treinamento para o Container Registry do Google Cloud;
criar um pipeline do Kubeflow que consulta o BigQuery para criar divisões de treinamento/validação e exportar os resultados como um arquivo CSV fragmentado no GCS;
lançar um job de treinamento da AI Platform com quatro aplicativos de treinamento conteinerizados usando os dados do CSV exportados como entrada.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual que contém ferramentas para desenvolvedores. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece aos seus recursos do Google Cloud acesso às linhas de comando. A gcloud é a ferramenta ideal para esse tipo de operação no Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
No painel de navegação do Console do Google Cloud, clique em Ativar o Cloud Shell ().
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando esses processos forem concluídos, você já vai ter uma autenticação, e o projeto estará definido com seu PROJECT_ID. Por exemplo:
Clique em Verificar meu progresso para conferir o objetivo.
Adicione a permissão de editor em uma conta de serviço do Cloud Build.
Tarefa 3: criar uma instância de Pipelines do AI Platform
No menu de navegação do console do Google Cloud (), role para baixo até AI Platform e fixe a seção para facilitar o acesso ao laboratório.
Acesse AI Platform > Pipelines.
Depois clique em Nova instância.
Clique em Configurar.
Para criar um cluster, selecione Zona como . Em seguida, marque a opção Permitir acesso às seguintes APIs do Cloud, não mude o nome e clique em Criar novo cluster.
Observação:
a criação do cluster leva de 3 a 5 minutos. Antes de continuar, espere esse processo ser concluído.
Role até a parte de baixo da página, aceite os termos do Marketplace e clique em Implantar. Você verá cada serviço do KFP implantado no seu cluster do GKE. Aguarde a implantação ser concluída antes de seguir para a próxima tarefa.
No Cloud Shell, execute este comando para configurar o acesso à linha de comando kubectl:
No Cloud Shell, execute o comando abaixo para conseguir o ENDPOINT da implantação do KFP:
kubectl describe configmap inverse-proxy-config | grep googleusercontent.com
Importante: na tarefa 6, você precisará configurar o endpoint do KFP em uma das células do Notebook. Não se esqueça de usar a saída acima como seu ENDPOINT.
Clique em Verificar meu progresso para conferir o objetivo.
Crie uma instância do AI Platform Pipelines
Tarefa 4: criar uma instância de Notebooks do Vertex AI Platform.
Uma instância de notebooks da Vertex AI Platform é usada como um workbench principal de experimentação/desenvolvimento.
No console do Cloud, abra o Menu de navegação e selecione Vertex AI > Workbench.
Clique em ATIVAR A API NOTEBOOKS caso ainda não tenha feito isso.
Na página "Workbench", clique em CRIAR NOVA.
Na caixa de diálogo Nova instância, selecione como a Região e selecione como a Zona.
Em seguida, selecione Debian 10 como o sistema operacional e Python 3 (com Intel MKL e CUDA 11.3) como o ambiente.
Mantenha os outros campos como padrão e clique em Criar.
Observação: a instância do notebook pode levar até cinco minutos para aparecer.
Observação: aguarde até que a instância esteja disponível antes de prosseguir para a próxima etapa.
Clique em Abrir o JupyterLab. Uma janela do JupyterLab será aberta em uma nova guia.
Quando o pop-up "Build recomendado" aparecer, clique em Build. Se houver uma falha nesse processo, ela poderá ser ignorada.
Clique em Verificar meu progresso para conferir o objetivo.
Crie uma instância de Notebooks do AI Platform
Tarefa 5: Clonar o repositório de exemplo na sua instância de notebooks do AI Platform
Siga estas instruções para clonar o notebook mlops-on-gcp na sua instância do JupyterLab:
No JupyterLab, clique no ícone Terminal para abrir um novo terminal.
No prompt da linha de comando, digite o código abaixo e pressione Enter.
git clone https://github.com/GoogleCloudPlatform/mlops-on-gcp
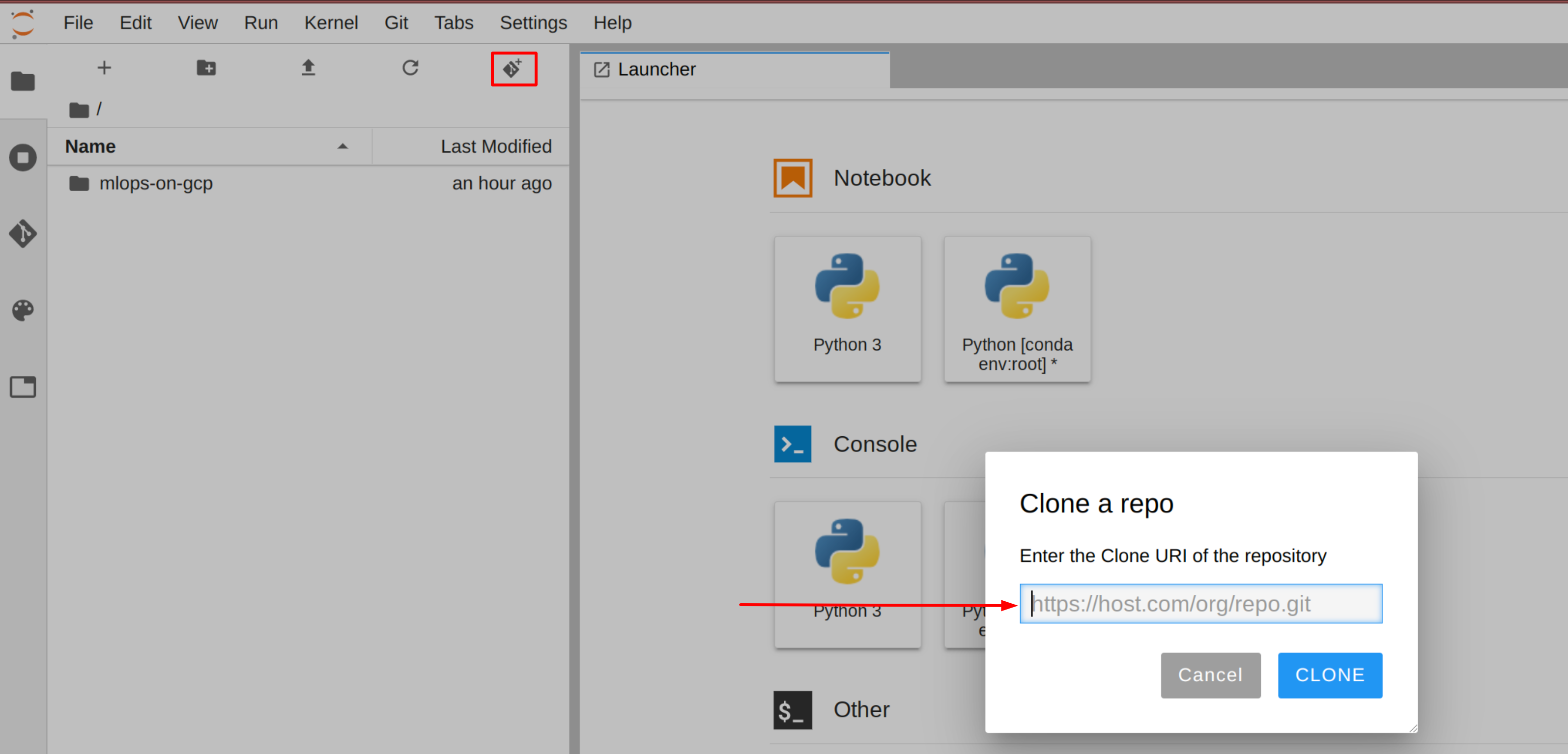
Observação: se o repositório clonado não aparecer na interface do JupyterLab, use o menu da parte de cima da tela e acesse Git > Clonar um repositório para realizar o processo (https://github.com/GoogleCloudPlatform/mlops-on-gcp) usando a UI.
Para confirmar que você clonou o repositório, clique duas vezes no diretório mlops-on-gcp e confira se o conteúdo dele aparece. Os arquivos de todos os laboratórios com notebooks do Jupyter deste curso estão nesse diretório.
Execute o comando a seguir para instalar os pacotes necessários.
pip install kfp==0.2.5 fire gcsfs requests-toolbelt==0.10.1
Tarefa 6: navegar até o notebook do laboratório
Na IU do JupyterLab, navegue até mlops-on-gcp/continuous_training/kubeflow/labs e abra multiple_frameworks_lab.ipynb.
Limpe todas as células do notebook (procure o botão "Limpar" na barra de ferramentas do notebook) e execute as células uma a uma. Observe que há um #TODO em algumas células solicitando que você escreva o código antes da execução.
Quando solicitado, volte a estas instruções para verificar seu progresso.
Se precisar de mais ajuda, confira a solução completa em mlops-on-gcp/continuous_training/kubeflow/solutions e abra multiple_frameworks_kubeflow.ipynb.
Tarefa 7: executar o job de treinamento na nuvem
Teste as tarefas concluídas: crie uma tabela e um conjunto de dados do BigQuery, gere as imagens e as envie para o Container Registry do seu projeto
Clique em Verificar meu progresso para conferir o objetivo.
Crie um conjunto de dados do BigQuery, uma tabela, as imagens e as envie para o Container Registry do seu projeto
Teste as tarefas concluídas: implantar o pipeline do KubeFlow
Clique em Verificar meu progresso para conferir o objetivo.
Implantar o pipeline do KubeFlow
Teste as tarefas concluídas: criar execuções de pipelines
Clique em Verificar meu progresso para conferir o objetivo.
Criar execuções de pipelines
Parabéns!
Neste laboratório, você aprendeu a desenvolver, empacotar como uma imagem do Docker e executar um aplicativo de treinamento no AI Platform Training.
Finalize o laboratório
Após terminar seu laboratório, clique em End Lab. O Qwiklabs removerá os recursos usados e limpará a conta para você.
Você poderá avaliar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Submit.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Support.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste laboratório, você vai criar aplicativos de treinamento conteinerizados para modelos de ML no TensorFlow, PyTorch, XGBoost e Scikit-learn. Depois vamos usar essas imagens como ops em um pipeline do KubeFlow e treinar vários modelos paralelamente. Por fim, vamos configurar execuções recorrentes do pipeline do KubeFlow na interface.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 120 minutos
·
Tempo para conclusão: 120 minutos
 ).
).
 ), role para baixo até AI Platform e fixe a seção para facilitar o acesso ao laboratório.
), role para baixo até AI Platform e fixe a seção para facilitar o acesso ao laboratório.