Présentation
Au cours de cet atelier, vous allez :
- Écrire des tests unitaires pour les
DoFn et les PTransform à l'aide des outils de test d'Apache Beam
- Effectuer un test d'intégration du pipeline
- Utiliser la classe
TestStream pour tester le comportement de fenêtrage d'un pipeline de traitement en flux continu.
Le test de votre pipeline constitue une étape particulièrement importante dans le développement d'une solution de traitement de données efficace. Du fait de la nature indirecte du modèle Beam, déboguer des échecs d'exécution peut s'avérer complexe.
Dans cet atelier, nous allons voir comment effectuer des tests unitaires en local avec les outils du package testing du SDK Beam, à l'aide de DirectRunner.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Remarque : Lisez ces instructions.
Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique Qwiklabs vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Des identifiants temporaires vous sont fournis pour vous permettre de vous connecter à Google Cloud le temps de l'atelier.
Conditions requises
Pour réaliser cet atelier, vous devez :
- avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- disposer de suffisamment de temps pour effectuer l'atelier en une fois.
Remarque : Si vous possédez déjà votre propre compte ou projet Google Cloud, veillez à ne pas l'utiliser pour réaliser cet atelier.
Remarque : Si vous utilisez un Pixelbook, veuillez exécuter cet atelier dans une fenêtre de navigation privée.
Démarrer votre atelier et vous connecter à la console
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous verrez un panneau contenant les identifiants temporaires à utiliser pour cet atelier.

-
Copiez le nom d'utilisateur, puis cliquez sur Ouvrir la console Google.
L'atelier lance les ressources, puis la page Sélectionner un compte dans un nouvel onglet.
Remarque : Ouvrez les onglets dans des fenêtres distinctes, placées côte à côte.
-
Sur la page "Sélectionner un compte", cliquez sur Utiliser un autre compte. La page de connexion s'affiche.

-
Collez le nom d'utilisateur que vous avez copié dans le panneau "Détails de connexion". Copiez et collez ensuite le mot de passe.
Remarque : Vous devez utiliser les identifiants fournis dans le panneau "Détails de connexion", et non vos identifiants Google Cloud Skills Boost. Si vous possédez un compte Google Cloud, ne vous en servez pas pour cet atelier (vous éviterez ainsi que des frais vous soient facturés).
- Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas aux essais offerts.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Vous pouvez afficher le menu qui contient la liste des produits et services Google Cloud en cliquant sur le menu de navigation en haut à gauche.

Dans cet atelier, vous allez exécuter toutes les commandes dans un terminal à partir du notebook de votre instance.
-
Dans le menu de navigation ( ) de la console Google Cloud, sélectionnez Vertex AI.
) de la console Google Cloud, sélectionnez Vertex AI.
-
Cliquez sur Activer toutes les API recommandées.
-
Dans le menu de navigation, cliquez sur Workbench.
En haut de la page "Workbench", vérifiez que vous vous trouvez dans la vue Instances.
-
Cliquez sur  Créer.
Créer.
-
Configurez l'instance :
-
Nom : lab-workbench
-
Région : définissez la région sur
-
Zone : définissez la zone sur
-
Options avancées (facultatif) : si nécessaire, cliquez sur "Options avancées" pour une personnalisation plus avancée (par exemple, type de machine, taille du disque).

- Cliquez sur Créer.
La création de l'instance prend quelques minutes. Une coche verte apparaît à côté de son nom quand elle est prête.
- Cliquez sur Ouvrir JupyterLab à côté du nom de l'instance pour lancer l'interface JupyterLab. Un nouvel onglet s'ouvre alors dans votre navigateur.

- Vous cliquerez ensuite sur Terminal. Le terminal qui s'affiche vous permettra d'exécuter toutes les commandes de cet atelier.
Télécharger le dépôt de code
Maintenant, vous allez télécharger le dépôt de code que vous utiliserez dans cet atelier.
- Dans le terminal que vous venez d'ouvrir, saisissez le code suivant :
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
cd /home/jupyter/training-data-analyst/quests/dataflow_python/
-
Dans le panneau de gauche de votre environnement de notebook, dans l'explorateur de fichiers, vous pouvez noter que le dépôt training-data-analyst a été ajouté.
-
Accédez au dépôt cloné /training-data-analyst/quests/dataflow_python/. Chaque atelier correspond à un dossier, divisé en deux sous-dossiers : le premier, intitulé lab, contient du code que vous devez compléter, tandis que le second, nommé solution, comporte un exemple concret que vous pouvez mettre en œuvre si vous rencontrez des difficultés.
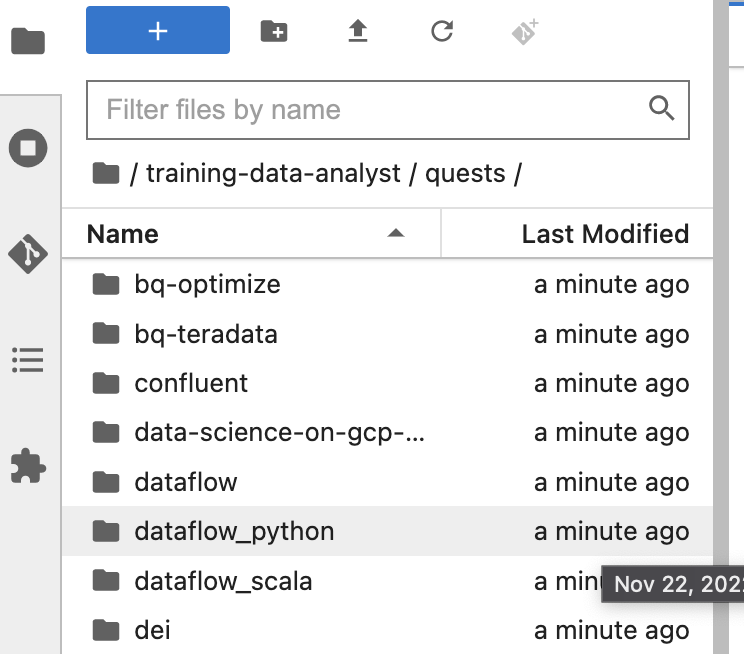
Remarque : Si vous souhaitez ouvrir un fichier pour le modifier, il vous suffit de le trouver et de cliquer dessus. Une fois ce fichier ouvert, vous pourrez y ajouter ou modifier le code.
Le code de l'atelier est réparti dans deux dossiers : 8a_Batch_Testing_Pipeline/lab et 8b_Stream_Testing_Pipeline/lab. Si vous rencontrez des difficultés, vous trouverez la solution dans les dossiers solution correspondants.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer une instance de notebook et cloner le dépôt du cours
Partie 1 de l'atelier : Effectuer des tests unitaires pour les DoFn et les PTransform
Tâche 1 : Préparer l'environnement
Dans cette partie de l'atelier, nous allons effectuer des tests unitaires sur les DoFn et les PTransform d'un pipeline par lot qui calcule des statistiques à partir de données de capteurs météorologiques. Pour tester les transformations que vous avez créées, vous pouvez utiliser ce modèle et ces transformations fournis par Beam :
- Créez un objet
TestPipeline.
- Créez des données d'entrée de test et utilisez la transformation
Create pour créer une PCollection de vos données d'entrée.
- Appliquez votre transformation à la
PCollection d'entrée et enregistrez la PCollection qui en résulte.
- Utilisez la méthode
assert_that du module testing.util et ses autres méthodes pour vérifier que le résultat de PCollection contient les éléments attendus.
TestPipeline est une classe spéciale incluse dans le SDK Beam, qui permet de tester vos transformations et la logique de votre pipeline. Pour les tests, utilisez TestPipeline au lieu de Pipeline lorsque vous créez l'objet de pipeline. La transformation Create prend une collection d'objets en mémoire (un itérable Java) et crée une PCollection à partir de cette collection. L'objectif est de disposer d'un petit ensemble de données d'entrée de test, pour lesquelles nous connaissons le résultat attendu de PCollection, à partir de nos PTransforms.
with TestPipeline() as p:
INPUTS = [fake_input_1, fake_input_2]
test_output = p | beam.Create(INPUTS) | # Transforms to be tested
Enfin, nous voulons vérifier que le résultat de PCollection correspond à celui attendu. Nous utilisons la méthode assert_that pour vérifier cela. Par exemple, nous pouvons utiliser la méthode equal_to pour vérifier que le résultat de PCollection contient les bons éléments :
assert_that(test_output, equal_to(EXPECTED_OUTPUTS))
Comme dans les ateliers précédents, la première étape consiste à générer des données que le pipeline pourra traiter. Vous allez ouvrir l'environnement de l'atelier et générer les données comme précédemment :
Ouvrir l'atelier approprié
- Dans le terminal de votre IDE, exécutez les commandes suivantes pour accéder au répertoire que vous allez utiliser pour cet atelier :
# Change directory into the lab
cd 8a_Batch_Testing_Pipeline/lab
export BASE_DIR=$(pwd)
Configurer l'environnement virtuel et les dépendances
Avant de pouvoir modifier le code du pipeline, assurez-vous d'avoir installé les dépendances nécessaires.
- Exécutez la commande suivante pour créer un environnement virtuel pour votre travail dans cet atelier :
sudo apt-get install -y python3-venv
# Create and activate virtual environment
python3 -m venv df-env
source df-env/bin/activate
- Installez ensuite les packages dont vous aurez besoin pour exécuter votre pipeline :
python3 -m pip install -q --upgrade pip setuptools wheel
python3 -m pip install apache-beam[gcp]
- Vérifiez que l'API Dataflow est activée :
gcloud services enable dataflow.googleapis.com
- Enfin, créez un bucket de stockage :
export PROJECT_ID=$(gcloud config get-value project)
gcloud storage buckets create gs://$PROJECT_ID --location=US
Cliquez sur Vérifier ma progression pour valider l'objectif.
Préparer l'environnement
Tâche 2 : Explorer le code du pipeline principal
-
Dans l'explorateur de fichiers, accédez à 8a_Batch_Testing_Pipeline/lab. Ce répertoire contient deux fichiers : weather_statistics_pipeline.py, qui contient le code principal de notre pipeline, et weather_statistics_pipeline_test.py, qui contient le code de test.
-
Ouvrez d'abord le fichier 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline.py.
Nous allons examiner brièvement le code de notre pipeline avant de travailler sur nos tests unitaires. Nous voyons d'abord la classe WeatherRecord (à partir de la ligne 6). Il s'agit d'une sous-classe de typing.NamedTuple. Nous pouvons donc utiliser des transformations compatibles avec les schémas pour travailler avec des objets de cette classe. Nous allons également définir des collections en mémoire d'objets de cette classe pour nos tests ultérieurs.
class WeatherRecord(typing.NamedTuple):
loc_id: str
lat: float
lng: float
date: str
low_temp: float
high_temp: float
precip: float
- Faites défiler la page jusqu'à la ligne 17, où nous commençons à définir nos
DoFn et PTransform.
Les concepts de ce pipeline ont pour la plupart été abordés dans les ateliers précédents, mais veillez à explorer plus en détail les éléments suivants :
- Les
DoFn ConvertCsvToWeatherRecord (à partir de la ligne 17) et ConvertTempUnits (à partir de la ligne 27). Nous effectuerons des tests unitaires sur ces DoFn ultérieurement.
- La
PTransform ComputeStatistics (à partir de la ligne 41). Il s'agit d'un exemple de transformation composite que nous pourrons tester de la même manière qu'une DoFn.
- La
PTransform WeatherStatsTransform (à partir de la ligne 55). Cette PTransform contient la logique de traitement de l'ensemble de notre pipeline (moins les transformations de source et de récepteur), ce qui nous permet d'effectuer un petit test d'intégration de pipeline sur des données synthétiques créées par une transformation Create.
Remarque : Si vous remarquez une erreur logique dans le code de traitement, ne la corrigez pas tout de suite. Nous verrons plus tard comment repérer l'erreur grâce aux tests.
Tâche 3 : Ajouter des dépendances pour les tests
- Ouvrez maintenant le fichier 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline_test.py dans l'explorateur de fichiers.
Nous devons ajouter quelques dépendances pour les tests. Nous allons utiliser les utilitaires de test inclus dans Apache Beam et le package unittest de Python.
- Pour réaliser cette tâche, ajoutez les instructions d'importation suivantes en haut du fichier weather_statistics_pipeline_test.py, là où vous y êtes invité :
from apache_beam.testing.test_pipeline import TestPipeline
from apache_beam.testing.util import BeamAssertException
from apache_beam.testing.util import assert_that, equal_to
Si vous rencontrez des difficultés, vous pouvez consulter les solutions.
Tâche 4 : Écrire le premier test unitaire DoFn dans Apache Beam
Notez que le fichier 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline_test.py contient le code de nos tests unitaires DoFn et PTransform. La majeure partie du code est actuellement commentée, mais nous allons annuler la mise en commentaire au fur et à mesure.
Avant d'explorer notre code Beam, notez que nous avons défini une méthode main personnalisée pour gérer l'exécution de nos tests et écrire le résultat des tests dans un fichier texte. De cette façon, nous disposons d'un enregistrement des tests auxquels nous pouvons nous référer une fois la session de terminal actuelle terminée. Vous pouvez également gérer cela à l'aide du module logging, par exemple.
def main(out = sys.stderr, verbosity = 2):
loader = unittest.TestLoader()
suite = loader.loadTestsFromModule(sys.modules[__name__])
unittest.TextTestRunner(out, verbosity = verbosity).run(suite)
# Testing code omitted
if __name__ == '__main__':
with open('testing.out', 'w') as f:
main(f)
- Nous allons commencer par examiner un test unitaire
DoFn pour notre DoFn ConvertCsvToWeatherRecord (à partir de la ligne 43). Nous créons d'abord une classe pour tester notre pipeline et créons un objet TestPipeline :
class ConvertToWeatherRecordTest(unittest.TestCase):
def test_convert_to_csv(self):
with TestPipeline() as p:
...
- Examinons à présent le code (incomplet) de notre premier test :
LINES = ['x,0.0,0.0,2/2/2021,1.0,2.0,0.1']
EXPECTED_OUTPUT = [WeatherRecord('x', 0.0, 0.0, '2/2/2021', 1.0, 2.0, 0.1)]
input_lines = p | # TASK 4: Create PCollection from LINES
output = input_lines | beam.ParDo(ConvertCsvToWeatherRecord())
# TASK 4: Write assert_that statement
Nous créons une seule entrée de test (LINES) représentant une ligne d'un fichier CSV (le format d'entrée attendu pour notre pipeline) et la plaçons dans une liste. Nous définissons également le résultat attendu (EXPECTED_OUTPUT) sous la forme d'une liste de WeatherRecords.
Il manque quelques éléments dans le reste du code du test.
-
Pour effectuer cette tâche, commencez par ajouter la transformation Create pour convertir LINES en PCollection.
-
Ensuite, incluez une instruction assert_that utilisant la méthode equal_to pour comparer output avec EXPECTED_OUTPUT.
Si vous rencontrez des difficultés, vous pouvez vous reporter aux tests commentés ultérieurs ou aux solutions.
Tâche 5 : Exécuter le premier test unitaire DoFn
- Revenez dans votre terminal et exécutez la commande suivante :
python3 weather_statistics_pipeline_test.py
cat testing.out
Les résultats des tests seront écrits dans le fichier testing.out. Nous pouvons afficher le contenu de ce fichier en exécutant la commande cat testing.out dans notre terminal. Si vous avez correctement effectué la tâche précédente, le contenu du fichier testing.out doit être le suivant (le temps écoulé peut varier) :
test_convert_to_csv (__main__.ConvertToWeatherRecordTest) ... ok
----------------------------------------------------------------------
Ran 1 test in 0.918s
OK
Remarque : Le test ci-dessus aurait pu être exécuté à l'aide de la commande "python3 -m unittest test_script.py". Nous avons exécuté le script Python directement pour accéder à la méthode principale, mais l'approche mentionnée ici est plus courante dans la pratique.
Tâche 6 : Exécuter le deuxième test unitaire DoFn et déboguer le pipeline
- Revenez à 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline_test.py et annulez la mise en commentaire du code du deuxième test unitaire (autour des lignes 33 à 50). Pour ce faire, sélectionnez le code et appuyez sur Ctrl + / (ou Cmd + / sur macOS). Le code est présenté ci-dessous à titre de référence :
class ConvertTempUnitsTest(unittest.TestCase):
def test_convert_temp_units(self):
with TestPipeline() as p:
RECORDS = [WeatherRecord('x', 0.0, 0.0, '2/2/2021', 1.0, 2.0, 0.1),
WeatherRecord('y', 0.0, 0.0, '2/2/2021', -3.0, -1.0, 0.3)]
EXPECTED_RECORDS = [WeatherRecord('x', 0.0, 0.0, '2/2/2021', 33.8, 35.6, 0.1),
WeatherRecord('y', 0.0, 0.0, '2/2/2021', 26.6, 30.2, 0.3)]
input_records = p | beam.Create(RECORDS)
output = input_records | beam.ParDo(ConvertTempUnits())
assert_that(output, equal_to(EXPECTED_RECORDS))
Ce test permet de s'assurer que la fonction DoFn ConvertTempUnits() fonctionne comme prévu. Enregistrez le fichier weather_statistics_pipeline_test.py et revenez au terminal.
- Exécutez les commandes suivantes pour lancer les tests et afficher le résultat :
rm testing.out
python3 weather_statistics_pipeline_test.py
cat testing.out
Cette fois, le test échoue. Si nous parcourons le résultat, nous pouvons trouver les informations suivantes sur l'échec du test :
test_compute_statistics (__main__.ComputeStatsTest) ... ok
test_convert_temp_units (__main__.ConvertTempUnitsTest) ... ERROR
...
apache_beam.testing.util.BeamAssertException: Failed assert: [WeatherRecord(loc_id='x', lat=0.0, lng=0.0, date='2/2/2021', low_temp=33.8, high_temp=35.6, precip=0.1), WeatherRecord(loc_id='y', lat=0.0, lng=0.0, date='2/2/2021', low_temp=26.6, high_temp=30.2, precip=0.3)] == [WeatherRecord(loc_id='x', lat=0.0, lng=0.0, date='2/2/2021', low_temp=32.8, high_temp=34.6, precip=0.1), WeatherRecord(loc_id='y', lat=0.0, lng=0.0, date='2/2/2021', low_temp=25.6, high_temp=29.2, precip=0.3)], unexpected elements [WeatherRecord(loc_id='x', lat=0.0, lng=0.0, date='2/2/2021', low_temp=32.8, high_temp=34.6, precip=0.1), WeatherRecord(loc_id='y', lat=0.0, lng=0.0, date='2/2/2021', low_temp=25.6, high_temp=29.2, precip=0.3)], missing elements [WeatherRecord(loc_id='x', lat=0.0, lng=0.0, date='2/2/2021', low_temp=33.8, high_temp=35.6, precip=0.1), WeatherRecord(loc_id='y', lat=0.0, lng=0.0, date='2/2/2021', low_temp=26.6, high_temp=30.2, precip=0.3)] [while running 'assert_that/Match']
En examinant de plus près l'exception BeamAssertException, nous pouvons voir que les valeurs de low_temp et high_temp sont incorrectes. La logique de traitement de la DoFn ConvertTempUnits est incorrecte.
- Revenez à 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline.py et faites défiler la page jusqu'à la définition de
ConvertTempUnits (vers la ligne 32). Pour effectuer cette tâche, identifiez l'erreur dans la logique de traitement DoFn et réexécutez les commandes suivantes pour vérifier que le test réussit :
rm testing.out
python3 weather_statistics_pipeline_test.py
cat testing.out
Pour rappel, voici la formule de conversion des degrés Celsius en degrés Fahrenheit :
temp_f = temp_c * 1.8 + 32.0
Si vous rencontrez des difficultés, vous pouvez consulter les solutions.
Tâche 7 : Exécuter un test unitaire de PTransform et tester le pipeline de bout en bout
- Revenez au fichier 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline_test.py et annulez la mise en commentaire des deux derniers tests (à partir de la ligne 53 environ).
Le premier test que nous venons de passer en code teste la PTransform composite ComputeStatistics. Une version tronquée du code est présentée ci-dessous à titre de référence :
def test_compute_statistics(self):
with TestPipeline() as p:
INPUT_RECORDS = # Test input omitted here
EXPECTED_STATS = # Expected output omitted here
inputs = p | beam.Create(INPUT_RECORDS)
output = inputs | ComputeStatistics()
assert_that(output, equal_to(EXPECTED_STATS))
Vous remarquerez que cela ressemble beaucoup aux tests unitaires DoFn que nous avons effectués précédemment. La seule différence réelle (en dehors des entrées et résultats de test) est que nous appliquons la PTransform plutôt que beam.ParDo(DoFn()).
Le dernier test concerne le pipeline de bout en bout. Dans le code du pipeline (weather_statistics_pipeline.py), l'intégralité du pipeline de bout en bout, à l'exception de la source et du récepteur, a été incluse dans une seule PTransform WeatherStatsTransform. Pour tester le pipeline de bout en bout, nous pouvons répéter une opération semblable à celle que nous avons effectuée ci-dessus, mais en utilisant cette PTransform.
- Revenez à votre terminal et exécutez la commande suivante pour exécuter les tests une nouvelle fois :
rm testing.out
python3 weather_statistics_pipeline_test.py
cat testing.out
Si vous avez correctement effectué les tâches précédentes, vous devriez voir ce qui suit dans le terminal une fois les tests terminés :
test_compute_statistics (__main__.ComputeStatsTest) ... ok
test_convert_temp_units (__main__.ConvertTempUnitsTest) ... ok
test_convert_to_csv (__main__.ConvertToWeatherRecordTest) ... ok
test_weather_stats_transform (__main__.WeatherStatsTransformTest) ... ok
----------------------------------------------------------------------
Ran 4 tests in 2.295s
OK
- Copiez maintenant le fichier
testing.out dans le bucket de stockage :
export PROJECT_ID=$(gcloud config get-value project)
gcloud storage cp testing.out gs://$PROJECT_ID/8a_Batch_Testing_Pipeline/
Cliquez sur Vérifier ma progression pour valider l'objectif.
Effectuer des tests unitaires pour les DoFn et les PTransform
Partie 2 de l'atelier : Tester la logique de traitement par flux avec TestStream
Dans cette partie de l'atelier, nous allons effectuer des tests unitaires pour un pipeline de traitement par flux qui calcule le nombre de courses de taxi par fenêtre. Pour tester les transformations que vous avez créées, vous pouvez utiliser ce modèle et ces transformations fournis par Beam :
- Créez un objet
TestPipeline.
- Utilisez la classe
TestStream pour générer un flux de données. Cela inclut la génération d'une série d'événements, l'avancement de la watermark et l'avancement du temps de traitement.
- Utilisez la méthode
assert_that du module testing.util et ses autres méthodes pour vérifier que le résultat de PCollection contient les éléments attendus.
Lorsqu'un pipeline qui lit à partir d'un TestStream est exécuté, la lecture attend que toutes les conséquences de chaque événement soient terminées avant de passer à l'événement suivant, y compris lorsque le temps de traitement avance et que les déclencheurs appropriés se déclenchent. TestStream permet d'observer et de tester l'effet du déclenchement et de la tolérance au retard sur un pipeline. Cela inclut la logique concernant les déclencheurs tardifs et les données perdues en raison de leur retard.
Tâche 1 : Explorer le code du pipeline principal
- Dans l'explorateur de fichiers, accédez à 8b_Stream_Testing_Pipeline/lab.
Ce répertoire contient deux fichiers : taxi_streaming_pipeline.py, qui contient le code principal de notre pipeline, et taxi_streaming_pipeline_test.py, qui contient notre code de test.
- Ouvrez d'abord le fichier 8b_Stream_Testing_Pipeline/lab/taxi_streaming_pipeline.py.
Nous allons examiner brièvement le code de notre pipeline avant de travailler sur nos tests unitaires. Nous voyons d'abord la classe TaxiRide (à partir de la ligne 6). Il s'agit d'une sous-classe de typing.NamedTuple. Nous pouvons donc utiliser des transformations compatibles avec les schémas pour travailler avec des objets de cette classe. Nous allons également définir des collections en mémoire d'objets de cette classe pour nos tests ultérieurs.
class TaxiRide(typing.NamedTuple):
ride_id: str
point_idx: int
latitude: float
longitude: float
timestamp: str
meter_reading: float
meter_increment: float
ride_status: str
passenger_count: int
Vient ensuite le code principal de notre pipeline. Les concepts de ce pipeline ont pour la plupart été abordés dans les ateliers précédents, mais veillez à explorer plus en détail les éléments suivants :
- Le
DoFn JsonToTaxiRide (à partir de la ligne 22) utilisé pour convertir les messages Pub/Sub entrants en objets de la classe TaxiRide.
- La
PTransform TaxiCountTransform (à partir de la ligne 36). Cette PTransform contient la logique principale de comptage et de fenêtrage du pipeline. Nos tests porteront sur cette PTransform.
Le résultat de TaxiCountTransform doit être un décompte de toutes les courses de taxi enregistrées par fenêtre. Cependant, nous aurons plusieurs événements par trajet (prise en charge, dépose, etc.). Nous allons filtrer les données sur la propriété ride_status pour nous assurer que chaque course n'est comptabilisée qu'une seule fois. Pour cela, nous ne conservons que les éléments dont la valeur de ride_status est "pickup" :
... | "FilterForPickups" >> beam.Filter(lambda x : x.ride_status == 'pickup')
Voici la logique de fenêtrage utilisée dans notre pipeline :
... | "WindowByMinute" >> beam.WindowInto(beam.window.FixedWindows(60),
trigger=AfterWatermark(late=AfterCount(1)),
allowed_lateness=60,
accumulation_mode=AccumulationMode.ACCUMULATING)
Nous allons créer des fenêtres fixes d'une durée de 60 secondes. Nous n'avons pas de déclencheur anticipé, mais nous émettrons les résultats une fois que le wartermark aura dépassé la fin de la fenêtre. Nous incluons les déclenchements tardifs avec chaque nouvel élément entrant, mais uniquement avec une tolérance de retard de 60 secondes. Enfin, nous allons accumuler l'état dans des fenêtres jusqu'à ce que le délai de retard autorisé soit dépassé.
Tâche 2 : Explorer l'utilisation de TestStream et exécuter le premier test
- Ouvrez maintenant 8b_Stream_Testing_Pipeline/lab/taxi_streaming_pipeline_test.py.
Le premier objectif sera de comprendre l'utilisation de TestStream dans notre code de test. Rappelez-vous que la classe TestStream nous permet de simuler un flux de messages en temps réel tout en contrôlant la progression du temps de traitement et la watermark. Le code du premier test (à partir de la ligne 66) est inclus ci-dessous :
test_stream = TestStream().advance_watermark_to(0).add_elements([
TimestampedValue(base_json_pickup, 0),
TimestampedValue(base_json_pickup, 0),
TimestampedValue(base_json_enroute, 0),
TimestampedValue(base_json_pickup, 60)
]).advance_watermark_to(60).advance_processing_time(60).add_elements([
TimestampedValue(base_json_pickup, 120)
]).advance_watermark_to_infinity()
- Nous créons un objet
TestStream, puis nous transmettons le message JSON sous forme de chaîne (nommée base_json_pickup ou base_json_enroute, selon l'état de la course). Que fait le TestStream ci-dessus ?
Le flux TestStream effectue les tâches suivantes :
- Définissez la watermark initiale sur l'heure
0 (tous les codes temporels sont en secondes).
- Ajoutez trois éléments au flux à l'aide de la méthode
add_elements avec un code temporel d'événement de 0. Deux de ces événements seront comptabilisés (ride_status = "pickup"), mais pas l'autre.
- Ajoutez un autre événement "pickup", mais avec un code temporel d'événement de
60.
- Avancez la watermark et le temps de traitement à
60 pour déclencher la première fenêtre.
- Ajoutez un autre événement "pickup" (prise en charge), mais avec un code temporel d'événement de
120.
- Avancez la watermark jusqu'à "infini". Cela signifie que toutes les fenêtres seront désormais fermées et que toutes les nouvelles données dépasseront la limite de retard autorisée.
- Le reste du code du premier test est semblable à l'exemple de traitement par lot précédent, mais nous utilisons désormais
TestStream au lieu de la transformation Create :
taxi_counts = (p | test_stream
| TaxiCountTransform()
)
EXPECTED_WINDOW_COUNTS = {IntervalWindow(0,60): [3],
IntervalWindow(60,120): [1],
IntervalWindow(120,180): [1]}
assert_that(taxi_counts, equal_to_per_window(EXPECTED_WINDOW_COUNTS),
reify_windows=True)
Dans le code ci-dessus, nous définissons le résultat de PCollection (taxi_counts) en créant le TestStream et en appliquant la PTransform TaxiCountTransform. Nous utilisons la classe InvervalWindow pour définir les fenêtres que nous souhaitons vérifier, puis nous utilisons assert_that avec la méthode equal_to_per_window pour vérifier les résultats par fenêtre.
- Enregistrez le fichier, revenez à votre terminal et exécutez les commandes suivantes pour vous déplacer vers le bon répertoire :
# Change directory into the lab
cd $BASE_DIR/../../8b_Stream_Testing_Pipeline/lab
export BASE_DIR=$(pwd)
- Exécutez maintenant le test ci-dessus et affichez le résultat en exécutant les commandes suivantes :
python3 taxi_streaming_pipeline_test.py
cat testing.out
Le résultat suivant doit s'afficher après le test (le temps écoulé peut varier) :
test_windowing_behavior (__main__.TaxiWindowingTest) ... ok
----------------------------------------------------------------------
Ran 1 test in 1.113s
OK
Tâche 3 : Créer TestStream pour tester la gestion des données tardives
Dans cette tâche, vous allez écrire du code pour un TestStream afin de tester la logique de gestion des données tardives.
- Revenez à 8b_Stream_Testing_Pipeline/lab/taxi_streaming_pipeline_test.py et faites défiler jusqu'au moment où la méthode
test_late_data_behavior est mise en commentaire (vers la ligne 60). Annulez la mise en commentaire du code pour ce test, car nous allons l'exécuter.
class TaxiLateDataTest(unittest.TestCase):
def test_late_data_behavior(self):
options = PipelineOptions()
options.view_as(StandardOptions).streaming = True
with TestPipeline(options=options) as p:
base_json_pickup = "{\"ride_id\":\"x\",\"point_idx\":1,\"latitude\":0.0,\"longitude\":0.0," \
"\"timestamp\":\"00:00:00\",\"meter_reading\":1.0,\"meter_increment\":0.1," \
"\"ride_status\":\"pickup\",\"passenger_count\":1}"
test_stream = # TÂCHE 3 : Créer un objet TestStream
EXPECTED_RESULTS = {IntervalWindow(0,60): [2,3]} #On Time and Late Result
taxi_counts = (p | test_stream
| TaxiCountTransform()
)
assert_that(taxi_counts, equal_to(EXPECTED_RESULTS))
Notez que EXPECTED_RESULTS contient deux résultats pour IntervalWindow(0,60). Ils représentent les résultats des déclencheurs exécutés à temps et en retard pour cette fenêtre.
Le code du test est complet, à l'exception de la création de TestStream.
-
Pour effectuer cette tâche, créez un objet TestStream qui effectue les tâches suivantes :
- Fait avancer la watermark à
0 (tous les codes temporels sont en secondes).
- Ajoute deux
TimestampedValues avec la valeur base_json_pickup et le code temporel 0.
- Avance la watermark et le temps de traitement à
60.
- Ajoute une autre
TimestampedValue avec la valeur base_json_pickup et le code temporel 0.
- Avance la watermark et le temps de traitement à
300.
- Ajoute une autre
TimestampedValue avec la valeur base_json_pickup et le code temporel 0.
- Fait avancer la watermark à l'infini.
Cela crée un TestStream avec quatre éléments appartenant à notre première fenêtre. Les deux premiers éléments sont à l'heure, le troisième est en retard (mais dans les limites autorisées), et le dernier est en retard au-delà des limites autorisées. Comme nous accumulons les fenêtres déclenchées, le premier déclencheur doit compter deux événements et le dernier déclencheur doit compter trois événements. Le quatrième événement ne doit pas être inclus.
Si vous rencontrez des difficultés, vous pouvez consulter les solutions.
Tâche 4 : Exécuter un test pour la gestion des données tardives
- Revenez à votre terminal et exécutez la commande suivante pour exécuter les tests une nouvelle fois :
rm testing.out
python3 taxi_streaming_pipeline_test.py
cat testing.out
Si vous avez correctement effectué les tâches précédentes, vous devriez voir ce qui suit dans le terminal une fois les tests terminés :
test_late_data_behavior (__main__.TaxiLateDataTest) ... ok
test_windowing_behavior (__main__.TaxiWindowingTest) ... ok
----------------------------------------------------------------------
Ran 2 tests in 2.225s
OK
- Copiez maintenant le fichier
testing.out dans le bucket de stockage :
export PROJECT_ID=$(gcloud config get-value project)
gcloud storage cp testing.out gs://$PROJECT_ID/8b_Stream_Testing_Pipeline/
Cliquez sur Vérifier ma progression pour valider l'objectif.
Tester la logique de traitement par flux avec TestStream
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
- 1 étoile = très insatisfait(e)
- 2 étoiles = insatisfait(e)
- 3 étoiles = ni insatisfait(e), ni satisfait(e)
- 4 étoiles = satisfait(e)
- 5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2025 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms de société et de produit peuvent être des marques des sociétés auxquelles ils sont associés.