Descripción general
En este lab, aprenderás a hacer lo siguiente:
- Escribir pruebas de unidades para
DoFn y PTransform mediante las herramientas de prueba de Apache Beam
- Realizar una prueba de integración de la canalización
- Utilizar la clase
TestStream para probar el comportamiento del sistema de ventanas en una canalización de transmisión
La prueba de tu canalización es un paso importante en el desarrollo de una solución de procesamiento de datos efectiva. Debido a la naturaleza indirecta del modelo de Beam, la depuración de ejecuciones con errores puede convertirse en una tarea importante.
En este lab, aprenderemos a realizar pruebas de unidades de forma local con herramientas del paquete de pruebas del SDK de Beam usando DirectRunner.
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Nota: Lee estas instrucciones.
Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
En este lab práctico de Qwiklabs, se te proporcionarán credenciales temporales nuevas para acceder a Google Cloud y realizar las actividades en un entorno de nube real, no en uno de simulación o demostración.
Requisitos
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab
Nota: Si ya tienes un proyecto o una cuenta personal de Google Cloud, no los uses para el lab.
Nota: Si usas una Pixelbook, abre una ventana de incógnito para ejecutar el lab.
Cómo iniciar tu lab y acceder a la consola
-
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá una ventana emergente para que selecciones tu forma de pago.
A la izquierda, verás un panel con las credenciales temporales que debes usar para este lab.

-
Copia el nombre de usuario y, luego, haz clic en Abrir la consola de Google.
El lab inicia los recursos y abre otra pestaña que muestra la página Elige una cuenta.
Sugerencia: Abre las pestañas en ventanas separadas, una junto a la otra.
-
En la página Elige una cuenta, haz clic en Usar otra cuenta. Se abrirá la página de acceso.

-
Pega el nombre de usuario que copiaste del panel Detalles de la conexión. Luego, copia y pega la contraseña.
Nota: Debes usar las credenciales del panel Detalles de la conexión. No uses tus credenciales de Google Cloud Skills Boost. Si tienes una cuenta propia de Google Cloud, no la utilices para este lab para no incurrir en cargos.
- Haz clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Cloud en esta pestaña.
Nota: Para ver el menú con una lista de los productos y servicios de Google Cloud, haz clic en el menú de navegación que se encuentra en la parte superior izquierda de la pantalla.

En este lab, ejecutarás todos los comandos en una terminal de tu notebook de instancia.
-
En el menú de navegación ( ) de la consola de Google Cloud, selecciona Vertex AI.
) de la consola de Google Cloud, selecciona Vertex AI.
-
Haz clic en Habilitar todas las APIs recomendadas.
-
En el menú de navegación, haz clic en Workbench.
En la parte superior de la página de Workbench, asegúrate de estar en la vista Instancias.
-
Haz clic en  Crear nueva.
Crear nueva.
-
Configura la instancia:
-
Nombre: lab-workbench
-
Región: Configura la región como
-
Zona: Establece la zona en
-
Opciones avanzadas (opcional): Si es necesario, haz clic en "Opciones avanzadas" para realizar personalizaciones adicionales (p. ej., tipo de máquina, tamaño del disco).

- Haz clic en Crear.
La instancia tardará algunos minutos en crearse. Se mostrará una marca de verificación verde junto a su nombre cuando esté lista.
- Haz clic en ABRIR JUPYTERLAB junto al nombre de la instancia para iniciar la interfaz de JupyterLab. Se abrirá una pestaña nueva en el navegador.

- Haz clic en Terminal. Esto abrirá una terminal en la que podrá ejecutar todos los comandos del lab.
Descarga el repositorio de código
A continuación, descargarás un repositorio de código que usarás en este lab.
- En la terminal que acabas de abrir, ingresa lo siguiente:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
cd /home/jupyter/training-data-analyst/quests/dataflow_python/
-
En el panel izquierdo de tu entorno de notebook, en el navegador de archivos, verás que se agregó el repo training-data-analyst.
-
Navega al repo clonado /training-data-analyst/quests/dataflow_python/. Verás una carpeta para cada lab. Cada una de ellas se divide en una subcarpeta lab con un código que debes completar y una subcarpeta solution con un ejemplo viable que puedes consultar como referencia si no sabes cómo continuar.
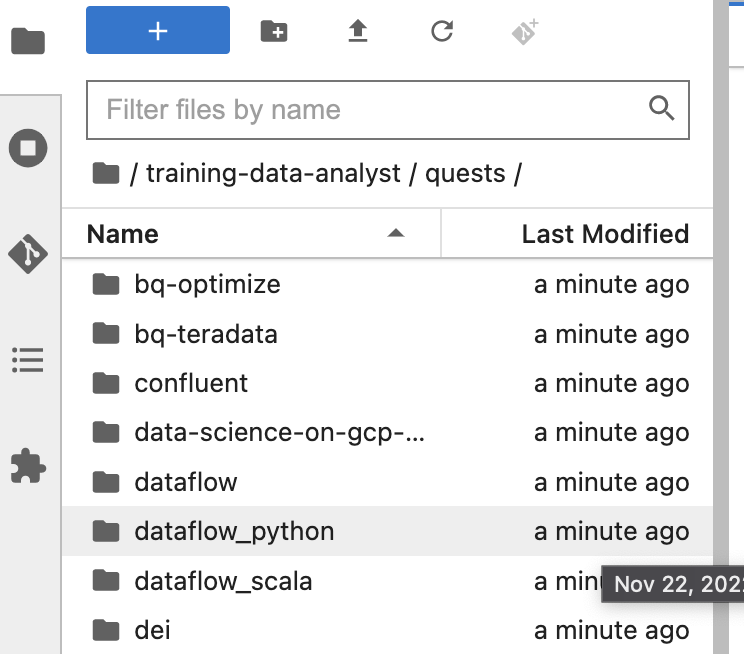
Nota: Para abrir un archivo y editarlo, simplemente debes navegar al archivo y hacer clic en él. Se abrirá el archivo, en el que puedes agregar o modificar código.
El código del lab se divide en dos carpetas: 8a_Batch_Testing_Pipeline/lab y 8b_Stream_Testing_Pipeline/lab. Si en algún momento tienes problemas, puedes consultar la solución en las carpetas solution correspondientes.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear una instancia de notebook y clonar el repo del curso.
Parte 1 del lab: Realiza pruebas de unidades para DoFn y PTransform
Tarea 1. Prepara el entorno
En esta parte del lab, realizaremos pruebas de unidades en DoFn y PTransform para obtener estadísticas de procesamiento de una canalización por lotes a partir de sensores meteorológicos. Para probar las transformaciones que tú creaste, puedes usar el siguiente patrón y las transformaciones que proporciona Beam:
- Crea una
TestPipeline.
- Crea algunos datos de entrada de prueba y usa la transformación
Create para crear una PCollection de tus datos de entrada.
- Aplica tu transformación a la
PCollection de entrada y guarda la PCollection resultante.
- Usa el método
Assert_that del módulo testing.util, junto con los demás disponibles, para verificar que la PCollection de salida contenga los elementos previstos.
TestPipeline es una clase especial incluida en el SDK de Beam específicamente para probar tus transformaciones y la lógica de tu canalización. Cuando realices pruebas, usa TestPipeline en lugar de Pipeline para crear el objeto de canalización. La transformación Create toma una colección de objetos en la memoria (un iterable de Java) y crea una PCollection a partir de aquella. El objetivo es tener un pequeño conjunto de datos de entrada de prueba (de los cuales conozcamos la PCollection de salida esperada) a partir de nuestras PTransforms.
with TestPipeline() as p:
INPUTS = [fake_input_1, fake_input_2]
test_output = p | beam.Create(INPUTS) | # Transforms to be tested
Por último, debemos comprobar que la PCollection de salida coincida con la salida que se espera. Para ello, usamos el método assert_that. Por ejemplo, podemos usar el método equal_to para verificar que la PCollection de salida tenga los elementos correctos:
assert_that(test_output, equal_to(EXPECTED_OUTPUTS))
Al igual que en los labs anteriores, el primer paso es generar datos para que la canalización los procese. Abre el entorno del lab y genera los datos como lo hiciste anteriormente:
Abre el lab adecuado
- En la terminal del IDE, ejecuta los siguientes comandos para cambiar al directorio que usarás en este lab:
# Change directory into the lab
cd 8a_Batch_Testing_Pipeline/lab
export BASE_DIR=$(pwd)
Configura el entorno virtual y las dependencias
Antes de comenzar a editar el código de la canalización en sí, debes asegurarte de haber instalado las dependencias necesarias.
- Ejecuta el siguiente comando para crear un entorno virtual para tu trabajo en este lab:
sudo apt-get install -y python3-venv
# Create and activate virtual environment
python3 -m venv df-env
source df-env/bin/activate
- Luego, instala los paquetes que necesitarás para ejecutar tu canalización:
python3 -m pip install -q --upgrade pip setuptools wheel
python3 -m pip install apache-beam[gcp]
- Asegúrate de que la API de Dataflow esté habilitada:
gcloud services enable dataflow.googleapis.com
- Por último, crea un bucket de almacenamiento:
export PROJECT_ID=$(gcloud config get-value project)
gcloud storage buckets create gs://$PROJECT_ID --location=US
Haz clic en Revisar mi progreso para verificar el objetivo.
Preparar el entorno
Tarea 2. Explora el código de canalización principal
-
En el explorador de archivos, dirígete a 8a_Batch_Testing_Pipeline/lab. Este directorio contiene dos archivos: weather_statistics_pipeline.py, que incluye el código de canalización principal, y weather_statistics_pipeline_test.py, que incluye el código de prueba.
-
En primer lugar, abre 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline.py.
Exploraremos brevemente el código de nuestra canalización antes de trabajar con las pruebas de unidades. Primero, vemos la clase WeatherRecord (a partir de la línea 6). Esta es una subclase de typing.NamedTuple, por lo que podemos usar transformaciones adaptadas al esquema para trabajar con objetos de esta clase. Más adelante, definiremos las colecciones de objetos de esta clase en la memoria para nuestras pruebas.
class WeatherRecord(typing.NamedTuple):
loc_id: str
lat: float
lng: float
date: str
low_temp: float
high_temp: float
precip: float
- Ahora, desplázate hacia abajo hasta la línea en la que comenzaremos a definir
DoFn y PTransform (línea 17).
Si bien la mayoría de los conceptos de esta canalización se abordaron en labs anteriores, asegúrate de explorar con mayor detalle los que se indican a continuación:
- Las
DoFn ConvertCsvToWeatherRecord (a partir de la línea 17) y ConvertTempUnits (a partir de la línea 27). Realizaremos pruebas de unidades en estas DoFn más adelante.
- La
PTransform ComputeStatistics (a partir de la línea 41). Este es un ejemplo de una transformación compuesta que podremos probar de la misma manera que una DoFn.
- La
PTransform WeatherStatsTransform (a partir de la línea 55). Esta PTransform contiene la lógica de procesamiento de toda nuestra canalización (menos las transformaciones de origen y receptor) para que podamos realizar una prueba de integración de canalización pequeña con datos sintéticos creados con una transformación Create.
Nota: Si observas un error lógico en el código de procesamiento, no lo corrijas todavía. Más adelante, veremos cómo usar pruebas para identificarlo.
Tarea 3: Agrega dependencias para las pruebas
- Ahora, abre 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline_test.py en tu explorador de archivos.
Debemos agregar algunas dependencias para las pruebas. Aprovecharemos las utilidades de prueba incluidas en Apache Beam y el paquete unittest en Python.
- Para completar esta tarea, agrega las siguientes sentencias de importación cuando se te solicite en la parte superior de weather_statistics_pipeline_test.py:
from apache_beam.testing.test_pipeline import TestPipeline
from apache_beam.testing.util import BeamAssertException
from apache_beam.testing.util import assert_that, equal_to
Si tienes problemas, puedes consultar las soluciones.
Tarea 4. Escribe la primera prueba de unidades de DoFn en Apache Beam
Observa que el archivo 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline_test.py contiene el código de nuestras pruebas de unidades de DoFn y PTransform. Por ahora, el código está generalmente marcado como comentado, pero quitaremos el comentario a medida que avancemos.
Antes de explorar el código de Beam, ten en cuenta que definimos un método main personalizado para administrar la ejecución de nuestras pruebas y escribir el resultado de estas en un archivo de texto. De esta forma, tendremos un registro de las pruebas que podremos consultar después de que finalice la sesión de la terminal actual. Esto también se puede administrar con el módulo logging, por ejemplo.
def main(out = sys.stderr, verbosity = 2):
loader = unittest.TestLoader()
suite = loader.loadTestsFromModule(sys.modules[__name__])
unittest.TextTestRunner(out, verbosity = verbosity).run(suite)
# Testing code omitted
if __name__ == '__main__':
with open('testing.out', 'w') as f:
main(f)
- Comenzaremos explorando una prueba de unidades de
DoFn para nuestra ConvertCsvToWeatherRecord DoFn (a partir de la línea 43). Primero, crearemos una clase para probar nuestra canalización y crearemos un objeto TestPipeline:
class ConvertToWeatherRecordTest(unittest.TestCase):
def test_convert_to_csv(self):
with TestPipeline() as p:
...
- Ahora, observa el código (incompleto) de nuestra primera prueba:
LINES = ['x,0.0,0.0,2/2/2021,1.0,2.0,0.1']
EXPECTED_OUTPUT = [WeatherRecord('x', 0.0, 0.0, '2/2/2021', 1.0, 2.0, 0.1)]
input_lines = p | # TASK 4: Create PCollection from LINES
output = input_lines | beam.ParDo(ConvertCsvToWeatherRecord())
# TASK 4: Write assert_that statement
Crearemos una entrada de prueba única (LINES), que represente una línea de un archivo CSV (el formato de entrada esperado para nuestra canalización), y la colocaremos en una lista. También definiremos el resultado esperado (EXPECTED_OUTPUT) como una lista de WeatherRecords.
Hay partes que faltan en el resto del código para la prueba.
-
Para completar esta tarea, primero agrega la transformación Create y convierte LINES en una PCollection.
-
Luego, incluye una sentencia assert_that con el método equal_to para comparar output con EXPECTED_OUTPUT.
Si tienes problemas, puedes consultar las pruebas con comentarios más recientes o las soluciones.
Tarea 5: Ejecuta la primera prueba de unidades de DoFn
- Regresa a la terminal y ejecuta el siguiente comando:
python3 weather_statistics_pipeline_test.py
cat testing.out
El resultado de las pruebas se escribirá en el archivo testing.out. Podemos ver el contenido de este archivo ejecutando cat testing.out en nuestra terminal. Si la tarea anterior se completó correctamente, el contenido del archivo testing.out debería ser el siguiente (el tiempo transcurrido podría variar):
test_convert_to_csv (__main__.ConvertToWeatherRecordTest) ... ok
----------------------------------------------------------------------
Ran 1 test in 0.918s
OK
Nota: La prueba anterior se podría haber ejecutado con el comando "python3 -m unittest test_script.py". Ejecutamos la secuencia de comandos de Python directamente para acceder al método principal, pero el enfoque que se menciona aquí suele ser más común en la práctica.
Tarea 6: Ejecuta la segunda prueba de unidades de DoFn y la canalización de depuración
- Regresa a 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline_test.py y quita el comentario del código de la segunda prueba de unidades (de la línea 33 a la línea 50). Para ello, destaca el código y presiona Ctrl + / (o Cmd + / en MacOS). A continuación, se muestra el código a modo de referencia:
class ConvertTempUnitsTest(unittest.TestCase):
def test_convert_temp_units(self):
with TestPipeline() as p:
RECORDS = [WeatherRecord('x', 0.0, 0.0, '2/2/2021', 1.0, 2.0, 0.1),
WeatherRecord('y', 0.0, 0.0, '2/2/2021', -3.0, -1.0, 0.3)]
EXPECTED_RECORDS = [WeatherRecord('x', 0.0, 0.0, '2/2/2021', 33.8, 35.6, 0.1),
WeatherRecord('y', 0.0, 0.0, '2/2/2021', 26.6, 30.2, 0.3)]
input_records = p | beam.Create(RECORDS)
output = input_records | beam.ParDo(ConvertTempUnits())
assert_that(output, equal_to(EXPECTED_RECORDS))
Esta prueba garantiza que la DoFn ConvertTempUnits() funcione según lo previsto. Guarda weather_statistics_pipeline_test.py y regresa a tu terminal.
- Ejecuta los siguientes comandos para realizar las pruebas y ver el resultado:
rm testing.out
python3 weather_statistics_pipeline_test.py
cat testing.out
La prueba falló esta vez. Si nos desplazamos por el resultado, encontraremos la siguiente información sobre la prueba con errores:
test_compute_statistics (__main__.ComputeStatsTest) ... ok
test_convert_temp_units (__main__.ConvertTempUnitsTest) ... ERROR
...
apache_beam.testing.util.BeamAssertException: Failed assert: [WeatherRecord(loc_id='x', lat=0.0, lng=0.0, date='2/2/2021', low_temp=33.8, high_temp=35.6, precip=0.1), WeatherRecord(loc_id='y', lat=0.0, lng=0.0, date='2/2/2021', low_temp=26.6, high_temp=30.2, precip=0.3)] == [WeatherRecord(loc_id='x', lat=0.0, lng=0.0, date='2/2/2021', low_temp=32.8, high_temp=34.6, precip=0.1), WeatherRecord(loc_id='y', lat=0.0, lng=0.0, date='2/2/2021', low_temp=25.6, high_temp=29.2, precip=0.3)], unexpected elements [WeatherRecord(loc_id='x', lat=0.0, lng=0.0, date='2/2/2021', low_temp=32.8, high_temp=34.6, precip=0.1), WeatherRecord(loc_id='y', lat=0.0, lng=0.0, date='2/2/2021', low_temp=25.6, high_temp=29.2, precip=0.3)], missing elements [WeatherRecord(loc_id='x', lat=0.0, lng=0.0, date='2/2/2021', low_temp=33.8, high_temp=35.6, precip=0.1), WeatherRecord(loc_id='y', lat=0.0, lng=0.0, date='2/2/2021', low_temp=26.6, high_temp=30.2, precip=0.3)] [while running 'assert_that/Match']
Si analizamos con más detalle la BeamAssertException, observamos que los valores de low_temp y high_temp son incorrectos. Hay un error en la lógica de procesamiento de la DoFn ConvertTempUnits.
- Regresa a 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline.py y desplázate hacia abajo hasta la definición de
ConvertTempUnits (cerca de la línea 32). Para completar esta tarea, busca el error en la lógica de procesamiento de DoFn y vuelve a ejecutar los siguientes comandos para confirmar que la prueba ahora se realice correctamente:
rm testing.out
python3 weather_statistics_pipeline_test.py
cat testing.out
A modo de recordatorio, esta es la fórmula para convertir grados Celsius en grados Farenheit:
temp_f = temp_c * 1.8 + 32.0
Si tienes problemas, puedes consultar las soluciones.
Tarea 7: Ejecuta la prueba de unidades de PTransform y prueba la canalización de extremo a extremo
- Regresa a 8a_Batch_Testing_Pipeline/lab/weather_statistics_pipeline_test.py y quita los comentarios del código de las dos últimas pruebas (a partir de la línea 53).
La primera prueba, a la que acabamos de quitar el comentario, corresponde a la prueba de la PTransform compuesta ComputeStatistics. A modo de referencia, este es un código con formato truncado:
def test_compute_statistics(self):
with TestPipeline() as p:
INPUT_RECORDS = # Test input omitted here
EXPECTED_STATS = # Expected output omitted here
inputs = p | beam.Create(INPUT_RECORDS)
output = inputs | ComputeStatistics()
assert_that(output, equal_to(EXPECTED_STATS))
Ten en cuenta que esto es muy similar a las pruebas de unidades de DoFn que realizamos anteriormente. La única diferencia real (aparte de las entradas y las salidas diferentes de las pruebas) es que aplicamos PTransform en lugar de beam.ParDo(DoFn()).
La prueba final es para la canalización de extremo a extremo. En el código de canalización (weather_statistics_pipeline.py), se incluyó toda la canalización de extremo a extremo (menos la fuente y el receptor) en una sola PTransform WeatherStatsTransform. Para probar la canalización de extremo a extremo, podemos repetir lo que hicimos anteriormente, pero con PTransform.
- Ahora, regresa a tu terminal y ejecuta el siguiente comando para ejecutar las pruebas una vez más:
rm testing.out
python3 weather_statistics_pipeline_test.py
cat testing.out
Si completaste correctamente las tareas anteriores, deberías ver lo siguiente en la terminal una vez que finalice la prueba:
test_compute_statistics (__main__.ComputeStatsTest) ... ok
test_convert_temp_units (__main__.ConvertTempUnitsTest) ... ok
test_convert_to_csv (__main__.ConvertToWeatherRecordTest) ... ok
test_weather_stats_transform (__main__.WeatherStatsTransformTest) ... ok
----------------------------------------------------------------------
Ran 4 tests in 2.295s
OK
- Ahora, copia y pega el archivo
testing.out en el bucket de almacenamiento:
export PROJECT_ID=$(gcloud config get-value project)
gcloud storage cp testing.out gs://$PROJECT_ID/8a_Batch_Testing_Pipeline/
Haz clic en Revisar mi progreso para verificar el objetivo.
Realizar pruebas de unidades para DoFn y PTransform
Parte 2 del lab: Prueba la lógica de procesamiento de transmisión con TestStream
En esta parte del lab, realizaremos pruebas de unidades para una canalización de transmisión que procesa recuentos de los recorridos de un taxi mediante un sistema de ventanas. Para probar las transformaciones que tú creaste, puedes usar el siguiente patrón y las transformaciones que proporciona Beam:
- Crea una
TestPipeline.
- Usa la clase
TestStream para generar datos de transmisión. Esto incluye generar una serie de eventos y avanzar la marca de agua y el tiempo de procesamiento.
- Usa el método
Assert_that del módulo testing.util, junto con los demás disponibles, para verificar que la PCollection de salida contenga los elementos previstos.
Cuando se ejecuta una canalización que lee de TestStream, la operación de lectura espera a que se completen todas las consecuencias de cada evento antes de pasar al siguiente, incluso cuando se avanza el tiempo de procesamiento y se accionan los activadores correspondientes. TestStream permite que el efecto de la activación y el retraso permitido se observen y prueben en una canalización. Esto incluye la lógica en torno a los activadores tardíos y los datos descartados debido a un retraso.
Tarea 1: Explora el código de canalización principal
- Navega a 8b_Stream_Testing_Pipeline/lab en el explorador de archivos.
Este directorio contiene dos archivos: taxi_streaming_pipeline.py, que incluye el código de canalización principal, y taxi_streaming_pipeline_test.py, que incluye el código de prueba.
- Primero, abre 8b_Stream_Testing_Pipeline/lab/taxi_streaming_pipeline.py.
Exploraremos brevemente el código de nuestra canalización antes de trabajar con las pruebas de unidades. Primero, vemos la clase TaxiRide (a partir de la línea 6). Esta es una subclase de typing.NamedTuple, por lo que podemos usar transformaciones adaptadas al esquema para trabajar con objetos de esta clase. Más adelante, definiremos las colecciones de objetos de esta clase en la memoria para nuestras pruebas.
class TaxiRide(typing.NamedTuple):
ride_id: str
point_idx: int
latitude: float
longitude: float
timestamp: str
meter_reading: float
meter_increment: float
ride_status: str
passenger_count: int
Luego, se encuentra el código principal de nuestra canalización. Si bien la mayoría de los conceptos de esta canalización se abordaron en labs anteriores, asegúrate de explorar con mayor detalle los que se indican a continuación:
- La
DoFn JsonToTaxiRide (a partir de la línea 22) usada para convertir los mensajes entrantes de Pub/Sub en objetos de la clase TaxiRide.
- La
PTransform TaxiCountTransform (a partir de la línea 36). Esta PTransform contiene la lógica principal de recuento y sistema de ventanas de la canalización. Nuestras pruebas se enfocarán en esta PTransform.
El resultado de la TaxiCountTransform debería ser un recuento de todos los recorridos registrados de taxi por ventana. Sin embargo, tendremos múltiples eventos por recorrido (partida, destino, etcétera). Filtraremos por la propiedad ride_status para garantizar que contemos cada recorrido solo una vez. Para ello, solo mantendremos los elementos cuyo ride_status sea igual a “pickup”:
... | "FilterForPickups" >> beam.Filter(lambda x : x.ride_status == 'pickup')
Si lo analizamos un poco más en detalle, verás que se utilizó la siguiente lógica de renderización en ventanas en nuestra canalización:
... | "WindowByMinute" >> beam.WindowInto(beam.window.FixedWindows(60),
trigger=AfterWatermark(late=AfterCount(1)),
allowed_lateness=60,
accumulation_mode=AccumulationMode.ACCUMULATING)
Estableceremos grupos de ventanas fijas de 60 segundos de duración. No contamos con un activador anticipado, por lo que emitiremos los resultados después de que la marca de agua pase el final de la ventana. Incluiremos activaciones tardías con cada elemento nuevo que ingrese, pero con un retraso permitido de solo 60 segundos. Por último, acumularemos el estado en ventanas hasta que haya pasado el retraso permitido.
Tarea 2. Explora el uso de TestStream y ejecuta la primera prueba
- En primer lugar, abre 8b_Stream_Testing_Pipeline/lab/taxi_streaming_pipeline_test.py.
El primer objetivo será comprender el uso de TestStream en nuestro código de prueba. Recuerda que la clase TestStream nos permite simular un flujo de mensajes en tiempo real y controlar el progreso del tiempo de procesamiento y la marca de agua. Este es el código de la primera prueba (a partir de la línea 66):
test_stream = TestStream().advance_watermark_to(0).add_elements([
TimestampedValue(base_json_pickup, 0),
TimestampedValue(base_json_pickup, 0),
TimestampedValue(base_json_enroute, 0),
TimestampedValue(base_json_pickup, 60)
]).advance_watermark_to(60).advance_processing_time(60).add_elements([
TimestampedValue(base_json_pickup, 120)
]).advance_watermark_to_infinity()
- Crearemos un nuevo objeto
TestStream y, luego, pasaremos el mensaje JSON como una cadena denominada base_json_pickup o base_json_enroute, según el estado del recorrido. ¿Qué hace el TestStream anterior?
El TestStream realiza las siguientes tareas:
- Se establece la marca de agua de tiempo como
0 (todas las marcas de tiempo son en segundos).
- Agregar tres elementos al flujo a través del método
add_elements con una marca de tiempo de evento de 0 Contar solo dos de estos eventos (ride_status = "pickup")
- Agregar otro evento de “pickup”, pero con una marca de tiempo de evento correspondiente a
60
- Avanzar la marca de agua y el tiempo de procesamiento a
60 para activar la primera ventana
- Agregar otro evento de “pickup”, pero con una marca de tiempo de evento correspondiente a
120
- Avanzar la marca de agua al “infinito”. Esto hará que todas las ventanas se cierren y permitirá que los datos nuevos superen el retraso permitido
- El resto del código de la primera prueba es similar al ejemplo por lotes anterior, pero ahora usamos
TestStream en lugar de la transformación Create:
taxi_counts = (p | test_stream
| TaxiCountTransform()
)
EXPECTED_WINDOW_COUNTS = {IntervalWindow(0,60): [3],
IntervalWindow(60,120): [1],
IntervalWindow(120,180): [1]}
assert_that(taxi_counts, equal_to_per_window(EXPECTED_WINDOW_COUNTS),
reify_windows=True)
En el código anterior, definimos nuestra PCollection de salida (taxi_counts) creando el TestStream y aplicando la PTransform TaxiCountTransform. Usamos la clase IntervalWindow para definir las ventanas que queremos verificar y, luego, usamos assert_that con el método equal_to_per_window para verificar los resultados por ventana.
- Guarda el archivo, regresa a la terminal y ejecuta los siguientes comandos para reubicar al directorio correcto:
# Change directory into the lab
cd $BASE_DIR/../../8b_Stream_Testing_Pipeline/lab
export BASE_DIR=$(pwd)
- Ahora, ejecuta la prueba anterior y los siguientes comandos para ver el resultado:
python3 taxi_streaming_pipeline_test.py
cat testing.out
Deberías ver el siguiente resultado después de la prueba (aunque el tiempo transcurrido puede variar):
test_windowing_behavior (__main__.TaxiWindowingTest) ... ok
----------------------------------------------------------------------
Ran 1 test in 1.113s
OK
Tarea 3: Crea TestStream para probar el manejo de datos tardíos
En esta tarea, escribirás código para un TestStream para probar la lógica de la prueba relacionada con el manejo de los datos tardíos.
- Regresa a 8b_Stream_Testing_Pipeline/lab/taxi_streaming_pipeline_test.py y desplázate hacia abajo hasta donde se marcó el método
test_late_data_Behavior como comentario (línea 60). Quita el comentario del código de esta prueba, ya que completaremos el código para esta tarea.
class TaxiLateDataTest(unittest.TestCase):
def test_late_data_behavior(self):
options = PipelineOptions()
options.view_as(StandardOptions).streaming = True
with TestPipeline(options=options) as p:
base_json_pickup = "{\"ride_id\":\"x\",\"point_idx\":1,\"latitude\":0.0,\"longitude\":0.0," \
"\"timestamp\":\"00:00:00\",\"meter_reading\":1.0,\"meter_increment\":0.1," \
"\"ride_status\":\"pickup\",\"passenger_count\":1}"
test_stream = # TASK 3: Create TestStream Object
EXPECTED_RESULTS = {IntervalWindow(0,60): [2,3]} #On Time and Late Result
taxi_counts = (p | test_stream
| TaxiCountTransform()
)
assert_that(taxi_counts, equal_to(EXPECTED_RESULTS))
Ten en cuenta que EXPECTED_RESULTS contiene dos resultados para IntervalWindow(0,60). Estos representan los resultados de los activadores puntuales y tardíos de esta ventana.
El código de la prueba se completará fuera de la creación de TestStream.
-
Para completar esta tarea, crea un objeto TestStream que realice las siguientes tareas:
- Avanzar la marca de agua a
0 (todas las marcas de tiempo están en segundos)
- Agregar dos
TimestampedValues con el valor base_json_pickup y la marca de tiempo 0
- Avanzar la marca de agua y el tiempo de procesamiento a
60
- Agregar otro
TimestampedValue con el valor base_json_pickup y la marca de tiempo 0
- Avanzar la marca de agua y el tiempo de procesamiento a
300
- Agregar otro
TimestampedValue con el valor base_json_pickup y la marca de tiempo 0
- Avanzar la marca de agua al infinito
Se creará un TestStream con cuatro elementos que pertenecen a la primera ventana. Los primeros dos elementos son puntuales, el segundo está retrasado (pero dentro del retraso permitido) y el último está retrasado y supera el retraso permitido. Debido a que acumulamos paneles activados, el primer activador debe contar dos eventos, mientras que el activador final debe contar tres. No se debe incluir el cuarto evento.
Si tienes problemas, puedes consultar las soluciones.
Tarea 4: Ejecuta pruebas para el manejo de datos tardíos
- Ahora, regresa a tu terminal y ejecuta el siguiente comando para ejecutar las pruebas una vez más:
rm testing.out
python3 taxi_streaming_pipeline_test.py
cat testing.out
Si completaste correctamente las tareas anteriores, deberías ver lo siguiente en la terminal una vez que finalice la prueba:
test_late_data_behavior (__main__.TaxiLateDataTest) ... ok
test_windowing_behavior (__main__.TaxiWindowingTest) ... ok
----------------------------------------------------------------------
Ran 2 tests in 2.225s
OK
- Ahora, copia y pega el archivo
testing.out en el bucket de almacenamiento:
export PROJECT_ID=$(gcloud config get-value project)
gcloud storage cp testing.out gs://$PROJECT_ID/8b_Stream_Testing_Pipeline/
Haz clic en Revisar mi progreso para verificar el objetivo.
Prueba la lógica de procesamiento de transmisión con TestStream
Finalice su lab
Cuando haya completado el lab, haga clic en Finalizar lab. Google Cloud Skills Boost quitará los recursos que usó y limpiará la cuenta.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
- 1 estrella = Muy insatisfecho
- 2 estrellas = Insatisfecho
- 3 estrellas = Neutral
- 4 estrellas = Satisfecho
- 5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2025 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.