Vai executar a solução de problemas simples para pipelines.
Vai entender como as guias Diagnóstico e BQ funcionam.
Vai explorar a página Error Reporting.
Pré-requisitos
Conhecimento básico de Python.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Ative o Google Cloud Shell
O Google Cloud Shell é uma máquina virtual com ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud.
O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
No console do Cloud, clique no botão "Abrir o Cloud Shell" na barra de ferramentas superior direita.
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando você estiver conectado, já estará autenticado, e o projeto estará definido com seu PROJECT_ID. Exemplo:
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
Para listar o nome da conta ativa, use este comando:
Antes de começar a trabalhar no Google Cloud, veja se o projeto tem as permissões corretas no Identity and Access Management (IAM).
No console do Google Cloud, em Menu de navegação (), selecione IAM e administrador > IAM.
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que está no Menu de navegação > Visão geral do Cloud > Painel.
Observação: se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
No console do Google Cloud, em Menu de navegação, clique em Visão geral do Cloud > Painel.
Copie o número do projeto, por exemplo, 729328892908.
Em Menu de navegação, clique em IAM e administrador > IAM.
Clique em Permitir acesso, logo abaixo de Visualizar por principais na parte de cima da tabela de papéis.
Por fim, verifique se a API Dataflow está ativada:
gcloud services enable dataflow.googleapis.com
Tarefa 2. Criar política de alertas
Nesta seção, você vai criar uma política de alertas que será acionada quando a condição for atendida.
Na barra de título do console do Google Cloud, no campo Pesquisar, digite Monitoring, clique em Pesquisar e depois em Monitoring.
No painel de navegação à esquerda, clique em Alertas.
Na página Alertas, clique em + CRIAR POLÍTICA.
Clique no menu suspenso Selecionar uma métrica e desmarque a opção Ativa.
a. Digite Job do Dataflow em "Filtrar por nome do recurso e da métrica" e clique em Job do Dataflow > Job. Selecione Com falha e clique em Aplicar.
b. Defina a Função de janelas móveis como Soma.
c. Clique em Próxima. Defina 0 como o Valor do limite.
Clique no botão PRÓXIMA para acessar a etapa Configurar notificações e finalizar alerta.
No formulário que abrir, clique no menu suspenso Canais de notificação e depois em GERENCIAR CANAIS DE NOTIFICAÇÃO.
Isso abre uma nova janela que lista os tipos de canal de notificação compatíveis.
Role para baixo até a linha E-mail e clique em ADICIONAR NOVO à direita.
a. Em Endereço de e-mail, digite seu e-mail pessoal.
Observação:
o e-mail da conta de estudante do Qwiklabs não vai funcionar porque é uma conta temporária.
b. Em Nome de exibição, digite Estudante do Qwiklabs.
c. Clique em Salvar. Feche esta janela e volte à anterior, Criar política de alertas.
Clique no ícone de atualização à esquerda de GERENCIAR CANAIS DE NOTIFICAÇÃO.
Clique novamente no menu suspenso Canais de notificação. Desta vez, você verá o nome de exibição da conta de estudante que acabou de adicionar.
Marque a caixa de seleção à esquerda do nome Estudante do Qwiklabs e clique em OK.
Insira Job do Dataflow com falha como o Nome do alerta na caixa de texto.
Clique em Próxima novamente.
Analise o alerta e clique em Criar política.
Clique em Verificar meu progresso para conferir o objetivo.
Criar política de alertas
Tarefa 3. Falha ao iniciar o pipeline no Dataflow
Revise o código do seu pipeline abaixo:
import argparse
import logging
import argparse, logging, os
import apache_beam as beam
from apache_beam.io import WriteToText
from apache_beam.options.pipeline_options import PipelineOptions
class ReadGBK(beam.DoFn):
def process(self, e):
k, elems = e
for v in elems:
logging.info(f"the element is {v}")
yield v
def run(argv=None):
parser = argparse.ArgumentParser()
parser.add_argument(
'--output', dest='output', help='Output file to write results to.')
known_args, pipeline_args = parser.parse_known_args(argv)
read_query = """(
SELECT
version,
block_hash,
block_number
FROM
`bugquery-public-data.crypto_bitcoin.transactions`
WHERE
version = 1
LIMIT
1000000 )
UNION ALL (
SELECT
version,
block_hash,
block_number
FROM
`bigquery-public-data.crypto_bitcoin.transactions`
WHERE
version = 2
LIMIT
1000 ) ;"""
p = beam.Pipeline(options=PipelineOptions(pipeline_args))
(p
| 'Read from BigQuery' >> beam.io.ReadFromBigQuery(query=read_query, use_standard_sql=True)
| "Add Hotkey" >> beam.Map(lambda elem: (elem["version"], elem))
| "Groupby" >> beam.GroupByKey()
| 'Print' >> beam.ParDo(ReadGBK())
| 'Sink' >> WriteToText(known_args.output))
result = p.run()
if __name__ == '__main__':
logger = logging.getLogger().setLevel(logging.INFO)
run()
No Cloud Shell, abra um arquivo novo chamado my_pipeline.py. Copie e cole o código acima nesse arquivo e o salve usando o editor de texto que preferir. O exemplo abaixo se refere ao Vim:
vi my_pipeline.py
Cole o código no arquivo e salve.
Execute o comando abaixo para criar um bucket de armazenamento:
Em seguida, tente iniciar o pipeline com o comando abaixo. Observe que o comando vai falhar:
# Tentativa de iniciar o pipeline
python3 my_pipeline.py \
--project=${PROJECT_ID} \
--region={{{project_0.default_region | Region}}} \
--tempLocation=gs://$PROJECT_ID/temp/ \
--runner=DataflowRunner
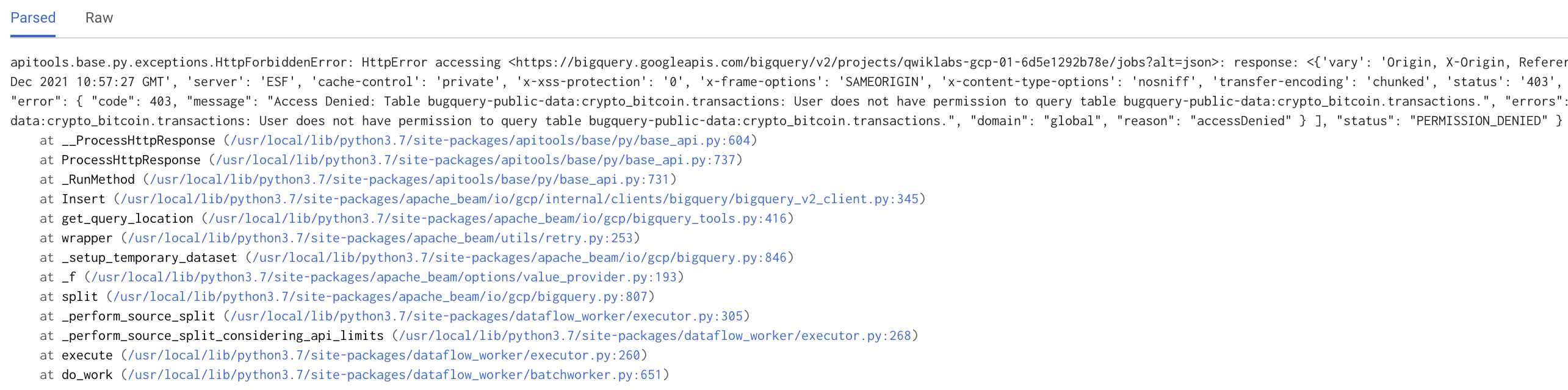
O comando acima para iniciar o pipeline falhará com um stack trace semelhante ao mostrado na captura de tela abaixo:
Essa falha está na parte do Beam. No código, especificamos WriteToText(known_args.output).
Como não especificamos a flag --output, o código não passou na validação do Beam e não pôde ser iniciado no Dataflow. Como isso não chegou ao Dataflow, nenhum ID de job está associado a essa operação de inicialização. Isso significa que você não receberá nenhum e-mail de alerta na sua caixa de entrada.
Clique em Verificar meu progresso para conferir o objetivo.
Falha ao iniciar o pipeline no Dataflow
Tarefa 4. Tabela do BigQuery inválida
Nesta seção, você tentará iniciar o pipeline novamente com a flag --output necessária. Esse procedimento permite iniciar o pipeline do Dataflow, mas o job falhará após alguns minutos porque uma tabela do BigQuery inválida foi adicionada intencionalmente. Isso aciona a política de alertas e envia um e-mail de alerta.
No terminal, execute o comando abaixo para iniciar o pipeline:
Na barra de título do console do Google Cloud, no campo Pesquisar, digite Dataflow, clique em Pesquisar e depois em Dataflow.
Clique em Jobs.
Clique no job do Dataflow listado nessa página.
Se você aguardar cerca de quatro minutos, verá que o job falhará. Isso aciona a política de alertas, e é possível acessar a caixa de entrada para ver o e-mail de alerta.
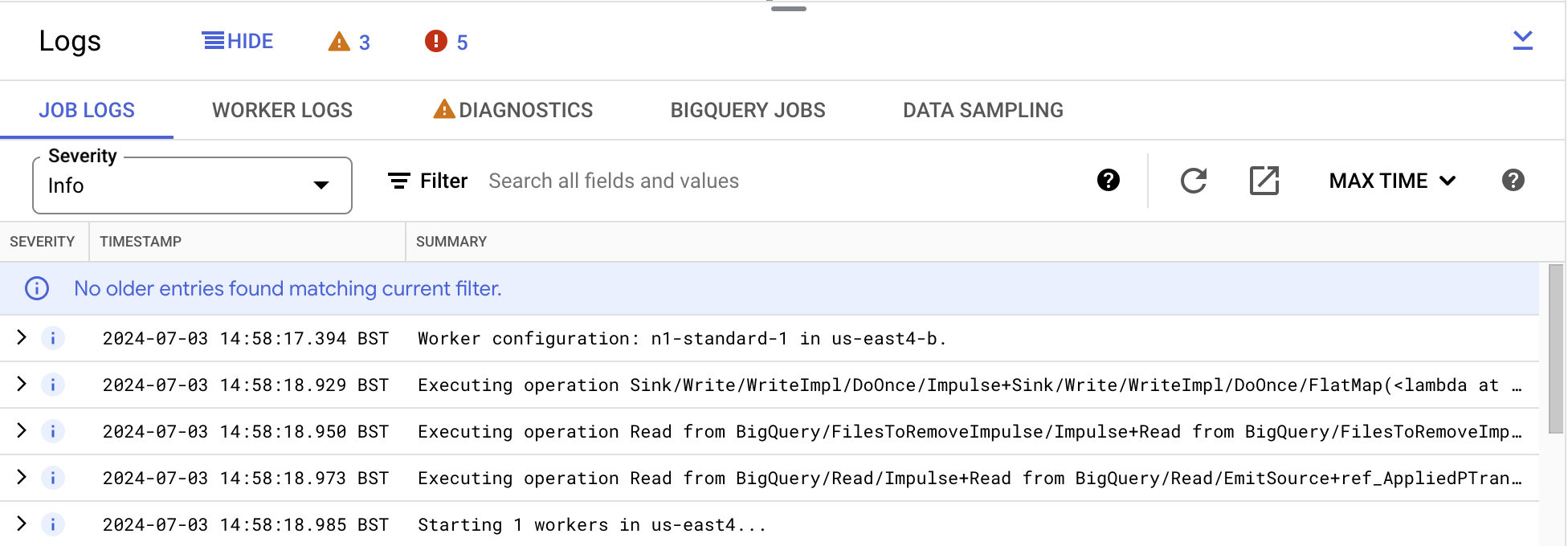
Abaixo do gráfico do job do pipeline do Dataflow, confira o painel Registros. Clique em Mostrar. As seguintes guias vão aparecer: Registros de jobs, Registros de workers, Diagnóstico, Jobs do BigQuery e Amostragem de dados.
Clique na guia Registros de jobs e analise as entradas de registro.
Em seguida, clique na guia Registros de workers para analisar esses registros.
Observação:
você vai notar que os registros podem ser expandidos quando se clica neles.
Os registros repetidos podem aparecer na guia Diagnóstico.
Ao clicar na guia Diagnóstico, você verá um link clicável.
Clique nele para acessar a página "Error Reporting". Isso nos mostra uma visualização expandida do erro. Observando o stack trace, você vai identificar o problema: um erro de digitação no código do pipeline.
No código, bigquery foi intencionalmente escrito de maneira incorreta como bugquery. Isso causa uma falha no job do Dataflow, aciona a política de alertas e envia um e-mail. Na próxima seção, você corrigirá o código e reiniciará o pipeline.
Clique em Verificar meu progresso para conferir o objetivo.
Tabela do BigQuery inválida
Tarefa 5. Geração de registros em excesso
Em um editor de texto (como o Vim, por exemplo), abra o arquivo my_pipeline.py e corrija o código substituindo bugquery por bigquery.
Observação:
no código, você encontra a palavra bugquery com erro de ortografia na instrução SELECT como bugquery-public-data.crypto_bitcoin.transactions. Corrija como bigquery-public-data.crypto_bitcoin.transactions.
No terminal, execute o comando abaixo para iniciar o pipeline:
O pipeline levará cerca de sete minutos para concluir a operação.
Na barra de título do console do Google Cloud, no campo Pesquisar, digite Dataflow, clique em Pesquisar e depois em Dataflow.
Clique em Jobs. Ao clicar nesse novo job, na página do gráfico do job à direita, o Status do job vai aparecer como succeeded. Se o job não foi concluído, aguarde a conclusão.
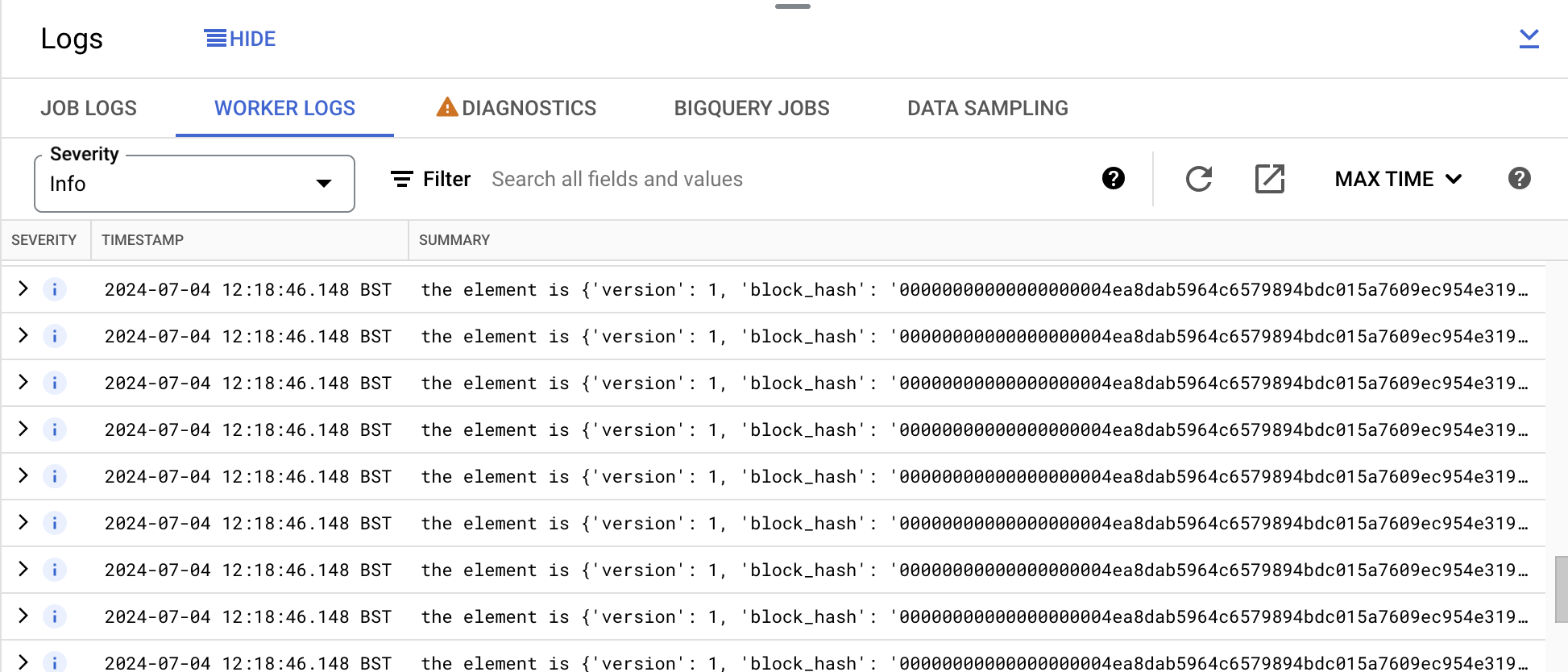
Expanda os Registros na parte inferior e revise os registros na guia Registros de workers.
Na guia Registros de workers, serão exibidas as entradas de registro com o formato the element is {'version' : ....... }, conforme mostrado na captura de tela abaixo:
Essas entradas estão sendo registradas por causa da seguinte linha no código do pipeline:
logging.info(f"the element is {v}")
Clique na guia Diagnóstico para exibir uma mensagem sobre a limitação de registros.
Clique nela e acesse a página Error Reporting. O excesso de registros é gerado como um insight do job, com um link de documento público que mostra qual é o problema.
A correção simples para esse problema seria remover a linha de geração de registros do código do pipeline e executar novamente o pipeline do Dataflow. Após a conclusão, a mesma mensagem não será mais exibida na guia Diagnóstico.
Observação: não é preciso executar novamente esse pipeline para concluir este laboratório.
Volte para a página "Jobs do Dataflow" clicando no botão "Voltar" do navegador.
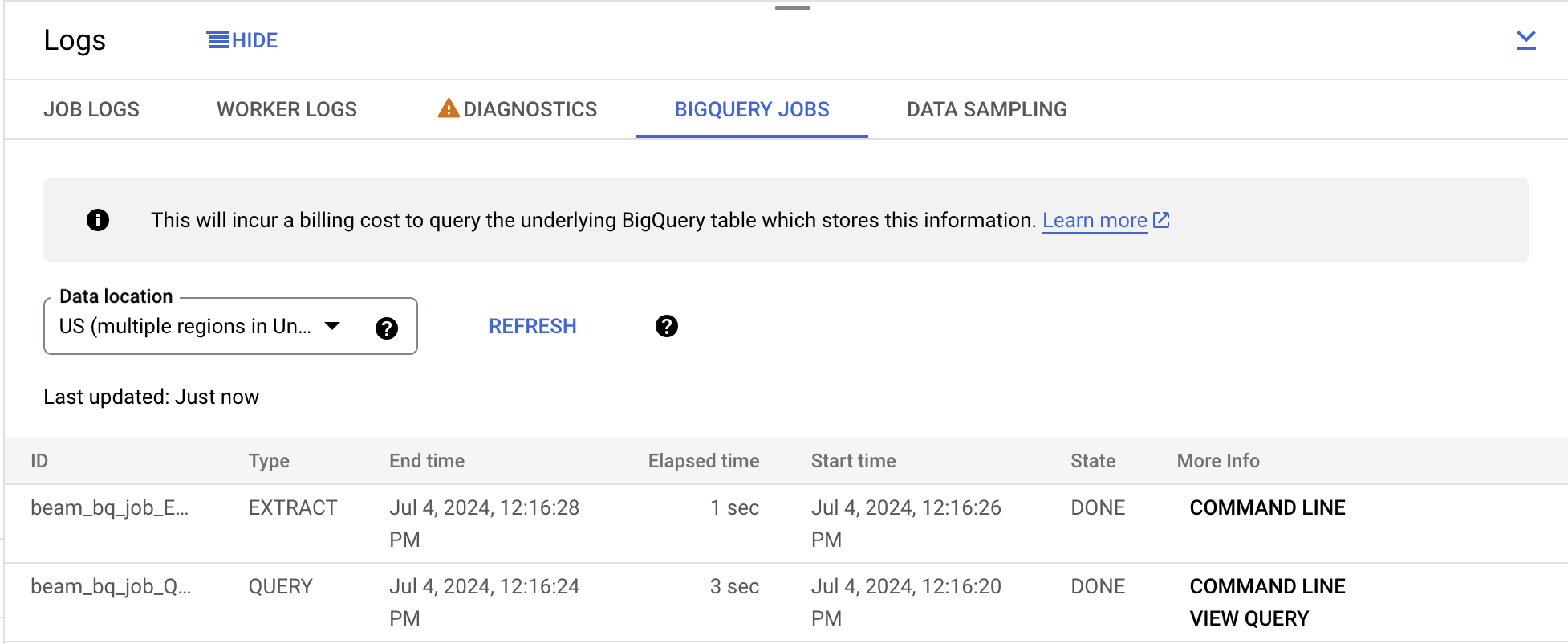
No painel de registros expandidos, clique na guia Jobs do BigQuery. No menu suspenso Local dos dados, selecione "us" (várias regiões nos Estados Unidos) e clique em Carregar jobs do BigQuery. Depois clique em Confirmar.
Serão exibidos dois jobs listados que faziam parte do pipeline.
Clique em Linha de comando à direita do primeiro job e, no pop-up, clique em Executar no Cloud Shell.
Isso vai colar o comando no Cloud Shell. Execute o comando.
O resultado do comando mostra os locais dos arquivos usados para ler/gravar no BigQuery, o tamanho deles e quanto tempo o job levou. Se um job do BigQuery falhar, esse será o lugar para procurar a causa da falha.
Clique em Verificar meu progresso para conferir o objetivo.
Geração de registros em excesso
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2025 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste laboratório, você vai: a) configurar a geração de registros dos jobs do Dataflow e b) explorar a página "Error Reporting"
Duração:
Configuração: 1 minutos
·
Tempo de acesso: 120 minutos
·
Tempo para conclusão: 120 minutos


 ), selecione IAM e administrador > IAM.
), selecione IAM e administrador > IAM.