Ejecutar soluciones de problemas simples para canalizaciones.
Ver cómo funcionan las pestañas Diagnóstico y BQ.
Explorar la página de Error Reporting.
Requisitos previos
Conocimientos básicos sobre Python
Configuración y requisitos
En cada lab, recibirá un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Qwiklabs desde una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesita, puede reiniciar el lab, pero deberá hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usa otras credenciales, se generarán errores o incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Activa Google Cloud Shell
Google Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud.
Google Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
En la consola de Cloud, en la barra de herramientas superior derecha, haz clic en el botón Abrir Cloud Shell.
Haz clic en Continuar.
El aprovisionamiento y la conexión al entorno demorarán unos minutos. Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu PROJECT_ID. Por ejemplo:
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con el completado de línea de comando.
Puedes solicitar el nombre de la cuenta activa con este comando:
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
En la consola de Google Cloud, en el Menú de navegación (), selecciona IAM y administración > IAM.
Confirma que aparezca la cuenta de servicio predeterminada de Compute {número-del-proyecto}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el menú de navegación > Descripción general de Cloud > Panel.
Nota: Si la cuenta no aparece en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
En la consola de Google Cloud, en el menú de navegación, haz clic en Descripción general de Cloud > Panel.
Copia el número del proyecto (p. ej., 729328892908).
En el Menú de navegación, selecciona IAM y administración > IAM.
En la parte superior de la tabla de funciones, debajo de Ver por principales, haz clic en Otorgar acceso.
Por último, asegúrate de que la API de Dataflow esté habilitada:
gcloud services enable dataflow.googleapis.com
Tarea 2. Crea una política de alertas
En esta sección, crearás una política de alertas que se activa cuando se cumple la condición.
En el campo Buscar de la barra de título de la consola de Google Cloud, escribe Supervisión, haz clic en Buscar y, luego, en Supervisión.
En el panel de navegación izquierdo, haz clic en Alertas.
En la página Alertas, haz clic en + CREAR POLÍTICA.
Haz clic en el menú desplegable Selecciona una métrica y desmarca Activa.
a. Escribe Trabajo de Dataflow en Filtrar por nombre de recurso o métrica y haz clic en Trabajo de Dataflow > Trabajo. Selecciona Con errores y haz clic en Aplicar.
b. Establece la función Rolling windows en Sum.
c. Haz clic en Siguiente. Establece 0 como valor del umbral.
Haz clic en el botón SIGUIENTE para ir al paso Configurar notificaciones y finalizar la alerta.
En el formulario que se carga, haz clic en el menú desplegable de Canales de notificaciones y, luego, en ADMINISTRAR CANALES DE NOTIFICACIONES.
Se abrirá una ventana nueva que muestra los tipos de canales de notificaciones admitidos.
Desplázate hasta la fila que dice Correo electrónico y, luego, haz clic en AGREGAR NUEVO en el extremo derecho.
a. En Dirección de correo electrónico, ingresa tu dirección de correo electrónico personal.
Nota:
El correo electrónico de la cuenta de estudiante de Qwiklabs no funcionará, ya que es una cuenta temporal.
b. En Nombre visible, ingresa Qwiklabs Student.
c. Haz clic en Guardar. Ahora puedes cerrar esta ventana y volver a la ventana anterior Crear política de alertas.
Haz clic en el ícono de actualización a la izquierda de ADMINISTRAR CANALES DE NOTIFICACIONES.
Luego, vuelva a hacer clic en el menú desplegable Canales de notificaciones. Esta vez, deberías ver el nombre visible de la cuenta de estudiante que acabas de agregar.
Marca la casilla de verificación a la izquierda del nombre de Estudiante de Qwiklabs y haz clic en Aceptar.
Ingresa Trabajo de Dataflow con errores como el nombre de la alerta en el cuadro de texto.
Haz clic en Siguiente otra vez.
Revisa la alerta y haz clic en Crear política.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear una política de alertas
Tarea 3. Errores en el inicio de la canalización en Dataflow
Revisa el código de tu canalización a continuación:
import argparse
import logging
import argparse, logging, os
import apache_beam as beam
from apache_beam.io import WriteToText
from apache_beam.options.pipeline_options import PipelineOptions
class ReadGBK(beam.DoFn):
def process(self, e):
k, elems = e
for v in elems:
logging.info(f"the element is {v}")
yield v
def run(argv=None):
parser = argparse.ArgumentParser()
parser.add_argument(
'--output', dest='output', help='Output file to write results to.')
known_args, pipeline_args = parser.parse_known_args(argv)
read_query = """(
SELECT
version,
block_hash,
block_number
FROM
`bugquery-public-data.crypto_bitcoin.transactions`
WHERE
version = 1
LIMIT
1000000 )
UNION ALL (
SELECT
version,
block_hash,
block_number
FROM
`bigquery-public-data.crypto_bitcoin.transactions`
WHERE
version = 2
LIMIT
1000 ) ;"""
p = beam.Pipeline(options=PipelineOptions(pipeline_args))
(p
| 'Read from BigQuery' >> beam.io.ReadFromBigQuery(query=read_query, use_standard_sql=True)
| "Add Hotkey" >> beam.Map(lambda elem: (elem["version"], elem))
| "Groupby" >> beam.GroupByKey()
| 'Print' >> beam.ParDo(ReadGBK())
| 'Sink' >> WriteToText(known_args.output))
result = p.run()
if __name__ == '__main__':
logger = logging.getLogger().setLevel(logging.INFO)
run()
En Cloud Shell, abre un archivo nuevo llamado my_pipeline.py. Copia y pega el código anterior en este archivo y guárdalo con el editor de texto que prefieras (el siguiente ejemplo hace referencia a Vim):
vi my_pipeline.py
Después de pegar el código en el archivo, asegúrate de guardarlo.
Ejecuta el siguiente comando para crear un bucket de almacenamiento:
A continuación, intentarás iniciar la canalización con el siguiente comando (ten en cuenta que el comando fallará):
# Attempt to launch the pipeline
python3 my_pipeline.py \
--project=${PROJECT_ID} \
--region={{{project_0.default_region | Region}}} \
--tempLocation=gs://$PROJECT_ID/temp/ \
--runner=DataflowRunner
El comando anterior para iniciar la canalización fallará con un seguimiento de pila similar al que se muestra en la siguiente captura de pantalla:
Esta falla está en el extremo de Beam. En el código, especificamos WriteToText(known_args.output).
Debido a que no pasamos la marca --output, el código no pasó la validación de Beam, por lo que no se pudo iniciar en Dataflow. Como no llegó a Dataflow, no hay ningún ID de trabajo asociado a esta operación de inicio. Esto implica que no deberías recibir correos electrónicos de alerta en tu bandeja de entrada.
Haz clic en Revisar mi progreso para verificar el objetivo.
Errores en el inicio de la canalización en Dataflow
Tarea 4. Tabla de BigQuery no válida
En esta sección, intentarás iniciar la canalización de nuevo con la marca --output requerida. Si bien esto logra iniciar de manera correcta la canalización de Dataflow, el trabajo fallará después de unos minutos porque agregamos intencionalmente una tabla de BigQuery no válida. Esto debería activar la política de alertas y dar como resultado que se envíe un correo electrónico de alerta.
En la terminal, ejecuta el siguiente comando para iniciar la canalización:
En el campo Búsqueda de la barra de título de la consola de Google Cloud, escribe Dataflow, haz clic en Búsqueda y, luego, en Dataflow.
Haz clic en Trabajos.
Haz clic en el trabajo de Dataflow que se muestra en esa página.
Si esperas aproximadamente cuatro minutos, verás que el trabajo falla. Esto activa la política de alertas. Puedes revisar tu bandeja de entrada de correo electrónico para ver la notificación de alerta.
Debajo del gráfico de trabajo de canalización de Dataflow, verás el panel Registros. Haz clic en Mostrar. Se mostrarán las siguientes pestañas: Registros de trabajos, Registros de trabajador, Diagnóstico, Trabajos de BigQuery y Muestreo de datos.
Haz clic en la pestaña Registros de trabajos y explora las entradas de registro.
Luego, haz clic en la pestaña Registros de trabajador y explora esos registros también.
Nota:
Notarás que los registros se pueden expandir cuando haces clic en ellos.
Los registros que se repiten pueden aparecer en la pestaña Diagnóstico.
Cuando hagas clic en la pestaña Diagnóstico, verás un vínculo en el que puedes hacer clic.
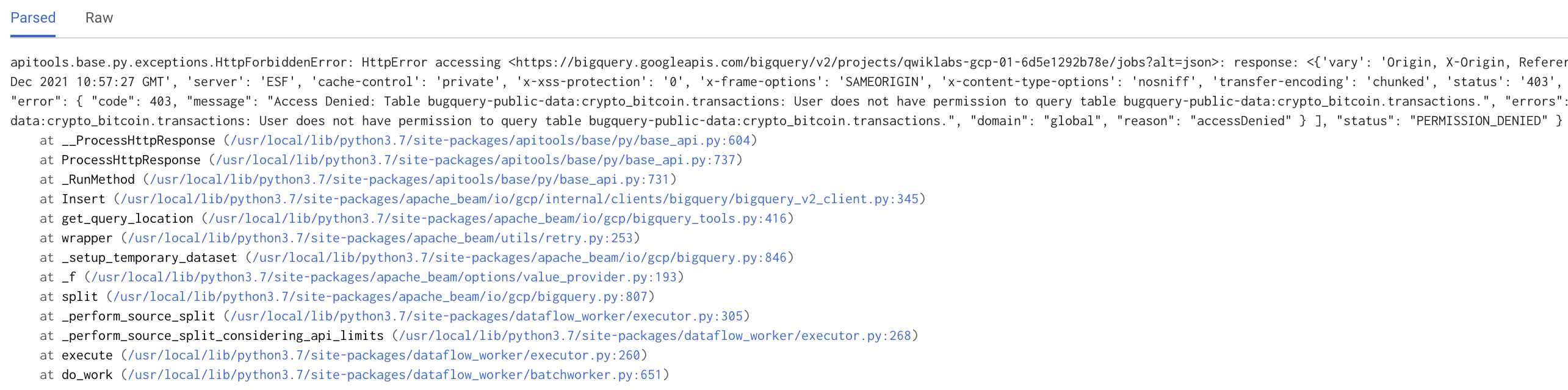
Haz clic en él para ir a la página de Error Reporting. En ella se muestra una vista expandida del error. Si observas el seguimiento de pila, verás el problema: un error tipográfico en el código de la canalización.
En el código, bigquery está mal escrito de forma intencional como bugquery, por lo que el trabajo de Dataflow falla y activa la política de alertas para enviar un correo electrónico. En la siguiente sección, corregirás el código y reiniciarás la canalización.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tabla de BigQuery no válida
Tarea 5. Demasiados registros
Con un editor de texto (como Vim o tu editor preferido), abre el archivo my_pipeline.py y corrige el código reemplazando bugquery por bigquery.
Nota:
En el código, encontrarás la palabra bugquery con un error tipográfico en la declaración SELECT como bugquery-public-data.crypto_bitcoin.transactions. Cámbiala a bigquery-public-data.crypto_bitcoin.transactions.
En la terminal, ejecuta el siguiente comando para iniciar la canalización:
La canalización tardará aproximadamente siete minutos en completarse.
En el campo Búsqueda de la barra de título de la consola de Google Cloud, escribe Dataflow, haz clic en Búsqueda y, luego, en Dataflow.
Haz clic en Trabajos. Cuando hagas clic en este nuevo trabajo, en la página del gráfico del trabajo, en el extremo derecho, deberías ver Estado del trabajo como Correcto. Si no se completó el trabajo, espera a que se complete de forma correcta.
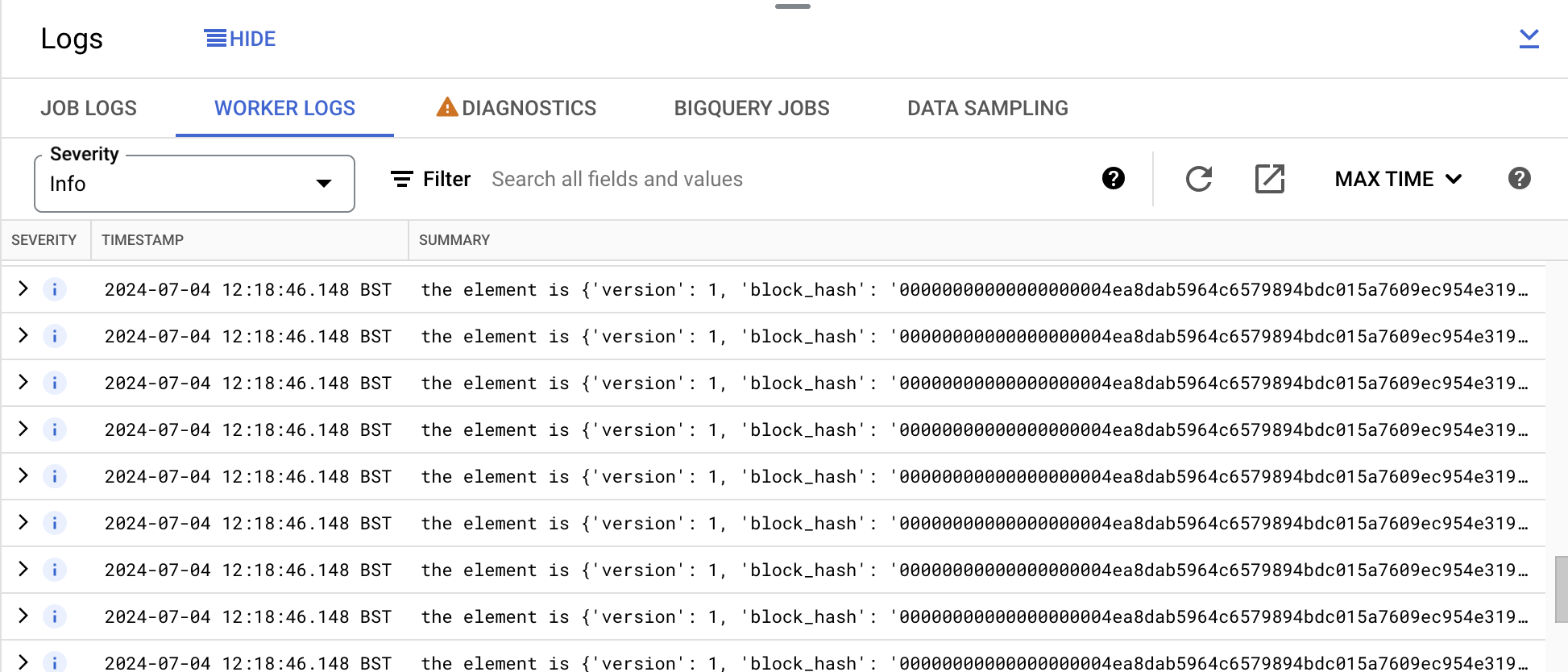
Expande la sección Registros de la parte inferior y revisa los registros en la pestaña Registros de trabajador.
En la pestaña Registros de trabajador, verás entradas de registro con el formato the element is {'version' : ....... }, como se muestra en la captura de pantalla a continuación:
Estas entradas se registran debido a la siguiente línea en el código de la canalización:
logging.info(f"the element is {v}")
Haz clic en la pestaña Diagnóstico y verás un mensaje sobre la limitación de los registros.
Haz clic en él y navega a la página de Error Reporting. El registro excesivo se genera como una estadística de trabajo, con un vínculo de documento público en el que se muestra cuál es el problema.
La solución sencilla para este problema sería quitar la línea de código de registro de tu código de canalización y volver a ejecutar la canalización de Dataflow. Cuando finalice, ya no deberías ver el mismo mensaje en la pestaña Diagnóstico.
Nota: No es necesario que vuelvas a ejecutar esta canalización para completar este lab.
Para volver a la página Trabajos de Dataflow, haz clic en el botón Atrás del navegador.
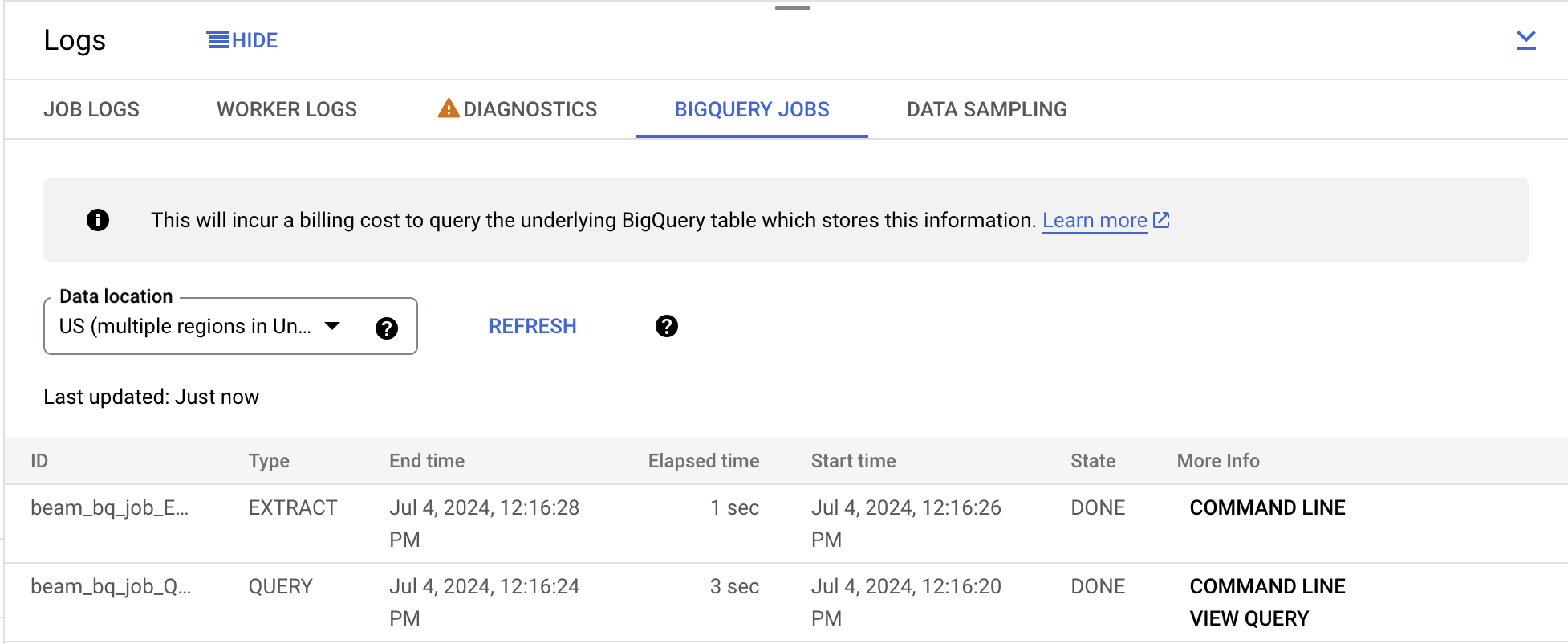
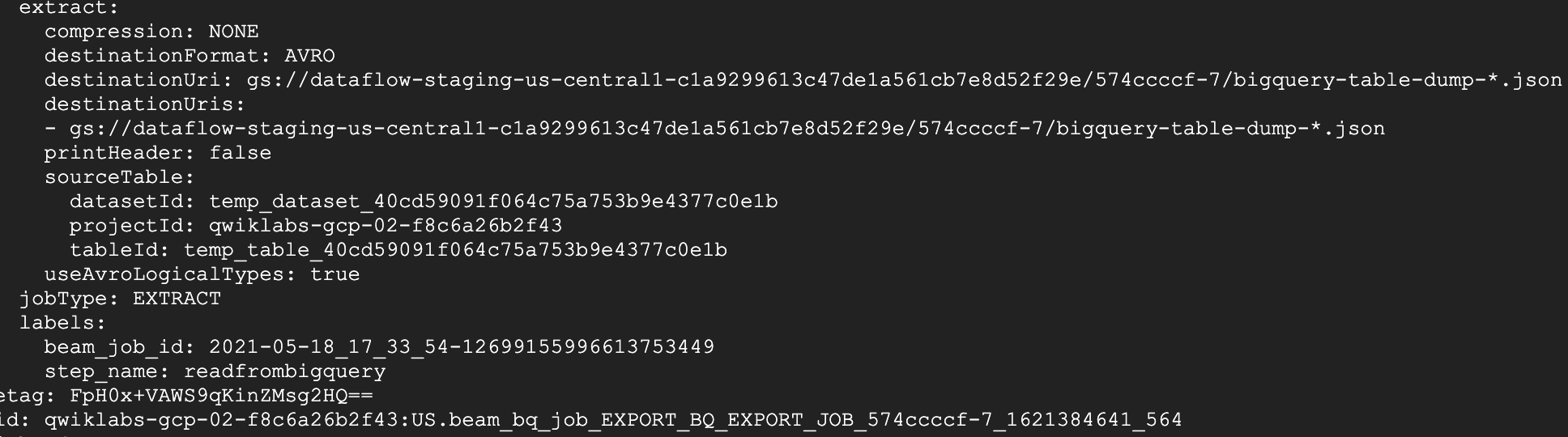
En el panel de registros expandido, haz clic en la pestaña Trabajos de BigQuery. En el menú desplegable Ubicación de los datos selecciona EE.UU. (varias regiones en Estados Unidos) y haz clic en Cargar trabajos de BigQuery. Luego, haz clic en Confirmar.
Verás dos trabajos enumerados que formaban parte de la canalización.
Haz clic en Línea de comandos en el extremo derecho del primer trabajo y, en la ventana emergente, haz clic en Ejecutar en Cloud Shell.
Esta acción pegará el comando en tu instancia de Cloud Shell. Asegúrate de ejecutar el comando.
En el resultado del comando, se muestran las ubicaciones de archivos que se usan para leer y escribir en BigQuery, su tamaño y cuánto tiempo tardó el trabajo. Si un trabajo de BigQuery falló, este es el lugar para buscar la causa de la falla.
Haz clic en Revisar mi progreso para verificar el objetivo.
Demasiados registros
Finalice su lab
Cuando haya completado el lab, haga clic en Finalizar lab. Google Cloud Skills Boost quitará los recursos que usó y limpiará la cuenta.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Neutral
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2025 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usa una ventana de navegación privada o de Incógnito para ejecutar el lab. Así
evitarás cualquier conflicto entre tu cuenta personal y la cuenta
de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
En este lab, a) configurarás el registro de tus trabajos de Dataflow y b) explorarás la página de Error Reporting.
Duración:
1 min de configuración
·
Acceso por 120 min
·
120 min para completar


 ), selecciona IAM y administración > IAM.
), selecciona IAM y administración > IAM.