Visão geral
Neste laboratório, vamos configurar um pipeline de integração/implantação
contínuas (CI/CD) para processar dados utilizando métodos de CI/CD
com produtos gerenciados no Google Cloud. Os cientistas e engenheiros
de dados podem adaptar as metodologias das práticas de CI/CD para garantir
a alta qualidade, facilidade de manutenção e de adaptação dos processos de dados e
fluxos de trabalho. É possível aplicar
os seguintes métodos:
- Controle de versão do código-fonte
- Desenvolvimento, teste e implantação automáticos de apps
- Isolamento de ambiente e separação da produção
- Replicação de procedimentos para configuração de ambiente
Arquitetura de implantação
Neste laboratório, você usará os seguintes produtos do Google Cloud:
- O Cloud Build
para desenvolver um pipeline de CI/CD e criar, implantar e testar
o processamento de dados e o fluxo de trabalho dele.
O Cloud Build é um serviço gerenciado que executa seu build no Google Cloud. Um build é uma série de etapas de compilação em que cada uma é executada
em um contêiner do Docker.
- O Cloud Composer
para definir e executar as etapas do fluxo de trabalho, como iniciar o processamento de dados, testar e verificar os resultados. O Cloud Composer é um serviço gerenciado do
Apache Airflow
que oferece um ambiente onde é possível criar, programar, monitorar
e gerenciar fluxos de trabalho complexos, como o de processamento de dados mostrado neste
laboratório.
- O Dataflow
para executar o exemplo
WordCount (em inglês)
do Apache Beam como um processo de dados de amostra.
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento.
No painel Detalhes do laboratório à esquerda, você vai encontrar o seguinte:
- O botão Abrir console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Nome de usuário"}}}
Você também encontra o Nome de usuário no painel Detalhes do laboratório.
-
Clique em Seguinte.
-
Copie a Senha abaixo e cole na caixa de diálogo de boas-vindas.
{{{user_0.password | "Senha"}}}
Você também encontra a Senha no painel Detalhes do laboratório.
-
Clique em Seguinte.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar uma lista de produtos e serviços do Google Cloud, clique no Menu de navegação no canto superior esquerdo ou digite o nome do serviço ou produto no campo Pesquisar.

Ative o Google Cloud Shell
O Google Cloud Shell é uma máquina virtual com ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud.
O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
-
No console do Cloud, clique no botão "Abrir o Cloud Shell" na barra de ferramentas superior direita.

-
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando você estiver conectado, já estará autenticado, e o projeto estará definido com seu PROJECT_ID. Exemplo:

A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- Para listar o nome da conta ativa, use este comando:
gcloud auth list
Saída:
Credentialed accounts:
- @.com (active)
Exemplo de saída:
Credentialed accounts:
- google1623327_student@qwiklabs.net
- Para listar o ID do projeto, use este comando:
gcloud config list project
Saída:
[core]
project =
Exemplo de saída:
[core]
project = qwiklabs-gcp-44776a13dea667a6
Observação:
a documentação completa da gcloud está disponível no
guia com informações gerais sobre a gcloud CLI
.
Pipeline de CI/CD
De modo geral, o pipeline de CI/CD consiste nas seguintes etapas:
- O Cloud Build empacota a amostra WordCount em um arquivo Java Archive (JAR) de execução automática usando o Maven Builder (em inglês),
que é um contêiner com o Maven instalado. Quando uma etapa de compilação é configurada para usar o Maven Builder, o Maven executa as tarefas.
- O Cloud Build carrega o arquivo JAR no Cloud Storage.
- O Cloud Build executa testes de unidade no código do fluxo de trabalho de processamento de dados e implanta esse código no Cloud Composer.
- O Cloud Composer coleta o arquivo JAR e executa o job de processamento de dados no Dataflow.
Confira no diagrama a seguir as etapas do pipeline de CI/CD em detalhes.
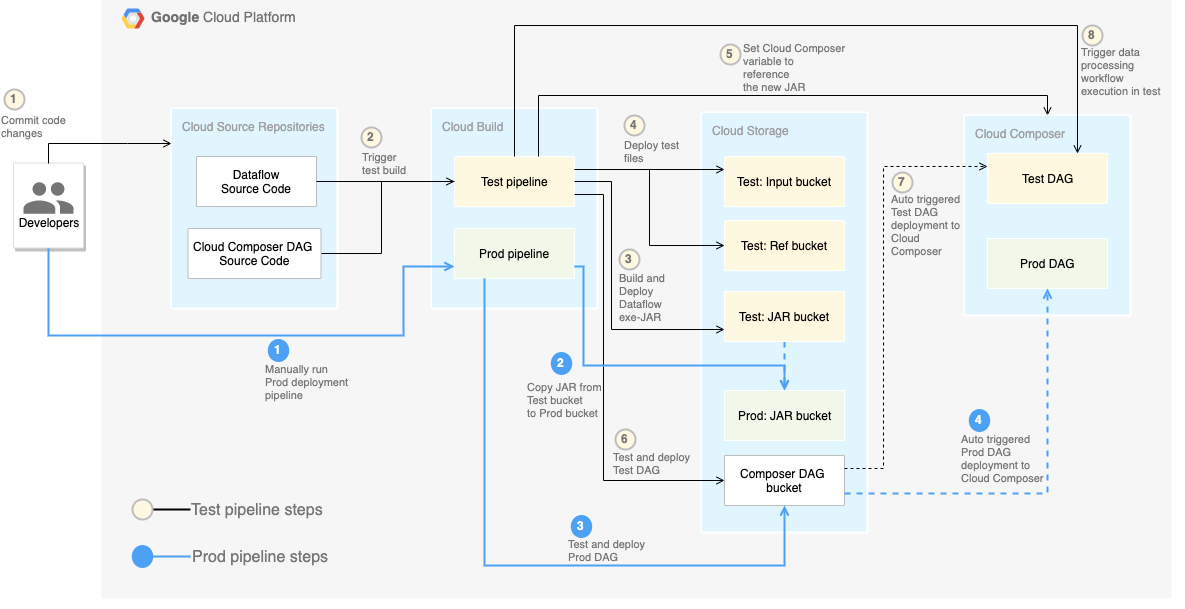
Neste laboratório, as implantações nos ambientes de teste e produção são
separadas em dois pipelines diferentes do Cloud Build, um de teste e
outro de produção.
No diagrama anterior, o pipeline de teste consiste nas seguintes etapas:
- Um desenvolvedor confirma as alterações de código no Cloud Source Repositories.
- As alterações acionam uma compilação de teste no Cloud Build.
- O Cloud Build cria o arquivo JAR autoexecutável e o implanta no bucket do JAR de teste no Cloud Storage.
- O Cloud Build implanta os arquivos de teste nos buckets do arquivo de teste no Cloud Storage.
- O Cloud Build define a variável no Cloud Composer para fazer referência ao arquivo JAR recém-implantado.
- O Cloud Build testa o fluxo de trabalho
Gráfico acíclico dirigido (DAG, na sigla em inglês)
de processamento de dados e faz a implantação no bucket do Cloud Composer no
Cloud Storage.
- O arquivo DAG do fluxo de trabalho é implantado no Cloud Composer.
- O Cloud Build aciona a execução do fluxo de trabalho de processamento de dados
recém-implantado.
Se você quiser separar completamente os ambientes, precisará criar vários ambientes
do Cloud Composer em diferentes projetos, que são separados um do outro
por padrão. Essa separação ajuda a proteger seu ambiente de produção. No entanto, esse procedimento não faz parte do escopo deste laboratório. Para mais informações de como acessar recursos em vários projetos do Google Cloud, consulte Como definir permissões de conta de serviço.
Fluxo de trabalho de processamento de dados
As instruções de como o Cloud Composer executa o fluxo de trabalho de
processamento de dados são definidas em um
Gráfico acíclico dirigido (DAG, na sigla em inglês) escrito em Python. No DAG, todas as etapas do fluxo
são indicadas juntamente com as dependências entre elas.
O pipeline de CI/CD implanta automaticamente a definição do DAG do Cloud Source Repositories para o Cloud Composer em cada compilação. Esse processo garante que o Cloud Composer esteja sempre atualizado com as instruções mais recentes de fluxo de trabalho, sem precisar de intervenção humana.
Além do fluxo de trabalho de processamento de dados, a definição do DAG para o ambiente de teste também contém instruções da etapa completa de teste, que ajuda a garantir a execução correta do processamento de dados.
O fluxo de trabalho de processamento de dados está ilustrado no diagrama a seguir.
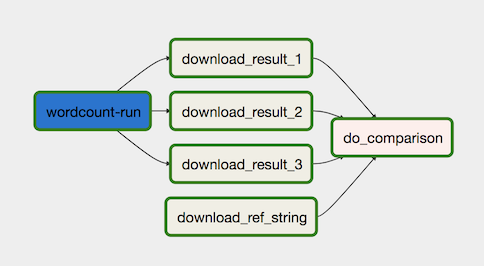
O fluxo de trabalho de processamento de dados consiste nas seguintes etapas:
-
Executar o processo de dados WordCount no Dataflow.
-
Fazer o download dos arquivos de saída do processo WordCount, que gera
três arquivos:
download_result_1download_result_2download_result_3
-
Faça o download do arquivo de referência, chamado download_ref_string.
-
Verifique o resultado em relação ao arquivo de referência. Esse teste de integração agrega as três saídas e compara os resultados com o arquivo de referência.
Usar uma estrutura de orquestração de tarefas, como o Cloud Composer, para gerenciar o fluxo de trabalho de processamento de dados ajuda a reduzir a complexidade do código do fluxo.
Testes
Além do teste de integração que verifica todo o fluxo de trabalho de processamento de dados, este laboratório inclui dois testes de unidade. Os testes de unidade são
testes automáticos no código de processamento de dados e do fluxo de trabalho de processamento
de dados. O teste no código de processamento de dados é escrito em Java e executado automaticamente durante o processo de compilação do Maven. O teste no código do fluxo de trabalho
de processamento de dados é escrito em Python e executado como uma etapa de compilação independente.
Código de amostra
Você encontrará o código de amostra em duas pastas:
-
A pasta env-setup contém scripts de shell para a configuração inicial do
ambiente do Google Cloud.
-
A pasta source-code contém um código desenvolvido ao longo do tempo,
tem fontes controladas e aciona processos automáticos de compilação e
teste. Ela inclui as seguintes subpastas:
- A pasta
data-processing-code contém o código-fonte do processo
do Apache Beam.
- A pasta
workflow-dag contém as definições do DAG do Composer
para os fluxos de trabalho de processamento de dados, com etapas de desenvolvimento, implementação
e teste do processo do Dataflow.
- A pasta
build-pipeline contém duas configurações
do Cloud Build, uma para o pipeline de teste e outra para o
pipeline de produção. Ela também inclui um script de suporte para os
pipelines.
Neste laboratório, os arquivos de código-fonte para o processamento de dados e
para o fluxo de trabalho do DAG estão em pastas diferentes no mesmo repositório.
Em um ambiente de produção, os arquivos de código-fonte geralmente ficam nos respectivos
repositórios e são gerenciados por equipes diferentes.
Tarefa 1: configurar o ambiente
Neste laboratório, todos os comandos serão executados no
Cloud Shell.
O Cloud Shell aparece como uma janela na parte de baixo do console do Google Cloud.
-
No console do Cloud, abra o Cloud Shell.
-
Clone o repositório do exemplo de código:
git clone https://github.com/GoogleCloudPlatform/ci-cd-for-data-processing-workflow.git
-
Acesse o diretório que contém os arquivos de amostra deste laboratório:
cd ~/ci-cd-for-data-processing-workflow/env-setup
-
Atualize a região no arquivo set_env.sh usando o comando sed.
sed -i "s/us-central1-a/{{{project_0.default_zone|Zone}}}/g" set_env.sh
sed -i "s/us-central1/{{{project_0.default_region|Region}}}/g" set_env.sh
-
Execute um script para definir as variáveis de ambiente:
source set_env.sh
O script define as seguintes variáveis de ambiente:
- ID do seu projeto do Google Cloud
- Sua região e zona
- O nome dos buckets do Cloud Storage usados pelo pipeline
de compilação e pelo fluxo de trabalho de processamento de dados.
As variáveis de ambiente não são armazenadas entre sessões. Portanto, se a
sessão do Cloud Shell for encerrada ou
desconectada enquanto você estiver trabalhando no laboratório, será necessário redefinir
as variáveis.
-
Adicione a opção de geração de registros ao arquivo yaml:
echo -e "\noptions:\n logging: CLOUD_LOGGING_ONLY" >> ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline/build_deploy_test.yaml
-
Atualize o script do pipeline:
sed -i 's/project=project/project_id=project/' ~/ci-cd-for-data-processing-workflow/source-code/workflow-dag/data-pipeline-test.py
Tarefa 2: criar o ambiente do Cloud Composer
Verificar se a API Cloud Composer foi ativada
Para garantir o acesso às APIs necessárias, reinicie a conexão com a API Cloud Composer.
-
No console do Google Cloud, digite API Cloud Composer na barra de pesquisa da parte de cima da página e clique no resultado API Cloud Composer.
-
Selecione Gerenciar.
-
Clique em Desativar API.
Se for necessário confirmar, clique em Desativar.
- Selecione Ativar.
A opção para desativar a API aparece quando ela é ativada novamente.
Criar um ambiente do Cloud Composer
-
No Cloud Shell, execute o seguinte comando para criar um ambiente do Cloud Composer:
gcloud composer environments create $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--image-version composer-3-airflow-2
Observação: o comando leva aproximadamente 15 minutos para criar o ambiente do Cloud Composer. Aguarde o Composer ficar pronto antes de continuar.
Quando o processo for concluído, você vai encontrar o ambiente no Google Cloud.
-
Execute um script para definir as variáveis no ambiente do
Cloud Composer. Elas são necessárias para os DAGs de processamento de dados.
cd ~/ci-cd-for-data-processing-workflow/env-setup
chmod +x set_composer_variables.sh
./set_composer_variables.sh
O script define as seguintes variáveis de ambiente:
- ID do seu projeto do Google Cloud
- Sua região e zona
- O nome dos buckets do Cloud Storage usados pelo pipeline
de compilação e pelo fluxo de trabalho de processamento de dados.
Extrair as propriedades do ambiente do Cloud Composer
O Cloud Composer usa um bucket do Cloud Storage para armazenar os DAGs.
Quando você move um arquivo de definição do DAG para o bucket, o Cloud Composer lê automaticamente os arquivos. O bucket do Cloud Storage para o Cloud Composer foi criado junto com o ambiente do Cloud Composer.
Siga o procedimento a seguir para extrair o URL dos buckets e configure o pipeline de CI/CD para implantar automaticamente as definições do DAG no bucket do Cloud Storage.
-
No Cloud Shell, exporte o URL do bucket como uma variável de
ambiente:
export COMPOSER_DAG_BUCKET=$(gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.dagGcsPrefix)")
-
Exporte o nome da conta de serviço que o Cloud Composer usa
para ter acesso aos buckets do Cloud Storage:
export COMPOSER_SERVICE_ACCOUNT=$(gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.nodeConfig.serviceAccount)")
Tarefa 3: criar os buckets do Cloud Storage
Nesta seção, você cria um conjunto de buckets do Cloud Storage para armazenar
o seguinte:
- Artefatos das etapas intermediárias do processo de compilação
- Arquivos de entrada e saída do fluxo de trabalho de processamento de dados
- Local de preparo dos jobs do Dataflow para armazenar os arquivos binários
Para criar os buckets do Cloud Storage, faça o seguinte:
Clique em Verificar meu progresso para conferir o objetivo.
Criar os buckets do Cloud Storage
Tarefa 4: enviar o código-fonte para o Cloud Source Repositories
Neste laboratório, você usará uma base de código-fonte no
controle de versão. A etapa a seguir mostra como uma base de código é desenvolvida e
alterada ao longo do tempo. Sempre que as alterações são enviadas ao repositório, o pipeline de compilação, implantação e teste é acionado.
-
No Cloud Shell, envie a pasta source-code para
o Cloud Source Repositories:
gcloud source repos create $SOURCE_CODE_REPO
cp -r ~/ci-cd-for-data-processing-workflow/source-code ~/$SOURCE_CODE_REPO
cd ~/$SOURCE_CODE_REPO
git config --global credential.'https://source.developers.google.com'.helper gcloud.sh
git config --global user.email $(gcloud config list --format 'value(core.account)')
git config --global user.name $(gcloud config list --format 'value(core.account)')
git init
git remote add google \
https://source.developers.google.com/p/$GCP_PROJECT_ID/r/$SOURCE_CODE_REPO
git add .
git commit -m 'initial commit'
git push google master
Esses são os comandos padrão para inicializar o Git em um novo diretório e
enviar o conteúdo para um repositório remoto.
Clique em Verificar meu progresso para conferir o objetivo.
Enviar o código-fonte para o Cloud Source Repositories
Tarefa 5: criar pipelines do Cloud Build
Nesta seção, serão criados os pipelines do build que geram, implantam e testam
o fluxo de trabalho de processamento de dados.
Criar o pipeline de build e teste
As etapas do pipeline de compilação e teste são definidas no
arquivo de configuração YAML.
Neste laboratório, você usará as
imagens pré-criadas do builder
para git, maven, gsutil e gcloud para executar as tarefas em cada etapa da criação.
As
substituições
de variáveis de configuração serão usadas para definir as configurações do ambiente no momento da compilação. Os locais do repositório do código-fonte e dos buckets do Cloud Storage serão definidos pelas substituições. A compilação precisa dessas informações para implantar o arquivo JAR, os arquivos de teste e a definição do DAG.
-
No Cloud Shell, envie o arquivo de configuração do pipeline de compilação para
criar o pipeline no Cloud Build:
cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline
gcloud builds submit --config=build_deploy_test.yaml --substitutions=\
REPO_NAME=$SOURCE_CODE_REPO,\
_DATAFLOW_JAR_BUCKET=$DATAFLOW_JAR_BUCKET_TEST,\
_COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_TEST,\
_COMPOSER_REF_BUCKET=$REF_BUCKET_TEST,\
_COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\
_COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\
_COMPOSER_REGION=$COMPOSER_REGION,\
_COMPOSER_DAG_NAME_TEST=$COMPOSER_DAG_NAME_TEST
Este comando instrui o Cloud Build a executar uma compilação seguindo
as etapas abaixo:
-
Crie e implante o arquivo JAR autoexecutável do WordCount.
- Confira o código-fonte.
- Compile o código-fonte do WordCount Beam em um arquivo JAR autoexecutável.
- Armazene o arquivo JAR no Cloud Storage onde ele pode ser selecionado pelo Cloud Composer para executar o job de processamento do WordCount.
-
Implante e configure o fluxo de trabalho de processamento de dados no Cloud Composer.
- Execute o teste de unidade no código de operador personalizado usado pelo DAG do fluxo de trabalho.
- Implante o arquivo de entrada e o arquivo de referência de teste no Cloud Storage. O arquivo de entrada de teste é a entrada para o job de processamento do WordCount. O arquivo de referência de teste é usado como uma referência para verificar a saída do job de processamento do WordCount.
- Defina as variáveis do Cloud Composer para apontar para o arquivo JAR recém-criado.
- Implante a definição do DAG do fluxo de trabalho no ambiente do Cloud Composer.
-
Execute o fluxo de trabalho de processamento de dados no ambiente de teste para acionar o fluxo de trabalho de processamento de teste.
Verificar o pipeline de compilação e teste
Depois de enviar o arquivo de build, verifique as etapas.
-
No Console do Cloud, acesse a página Histórico da compilação para ver
uma lista de todas as compilações anteriores e atuais.
-
Clique na versão que está sendo executada.
-
Na página Detalhes do build, confira se as etapas de build correspondem às
que você verificou antes.
Na página Detalhes do build, o campo Status
mostra Build successful quando a criação é concluída.
Observação:
em caso de falha, execute o build novamente.
-
No Cloud Shell, verifique se o arquivo JAR de amostra do WordCount foi
copiado para o bucket correto:
gsutil ls gs://$DATAFLOW_JAR_BUCKET_TEST/dataflow_deployment*.jar
A saída será assim:
gs://…-composer-dataflow-source-test/dataflow_deployment_e88be61e-50a6-4aa0-beac-38d75871757e.jar
-
Copie o URL da sua interface da Web do Cloud Composer e anote-o porque
ele será usado na próxima etapa.
gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.airflowUri)"
-
Use o URL da etapa anterior para acessar a IU do Cloud Composer
e verificar se o DAG foi executado corretamente. Você também pode clicar no link Airflow Webserver na página do Composer. Se a coluna Execuções DAG não
exibir informações, aguarde alguns minutos e atualize a página.
-
Para verificar se o test_word_count do DAG do fluxo de trabalho de
processamento de dados foi implantado e está em execução, mantenha o cursor
no círculo verde claro abaixo de Execuções DAG e verifique se ele
exibe Em execução.
-
Para acessar o fluxo de trabalho de processamento de dados em execução como um gráfico, clique
no círculo verde claro e, na página Execuções DAG, clique no ID do
DAG test_word_count.
-
Atualize a página Visualização de gráfico para ver o estado
da execução mais recente do DAG. Geralmente, leva de três a cinco minutos para o fluxo de trabalho ser concluído. Para verificar se a execução do DAG foi concluída com êxito,
mantenha o ponteiro sobre cada tarefa para confirmar se a dica mostra
Estado: sucesso. A última tarefa, denominada do_comparison, é o
teste de integração que compara a saída do processo e o arquivo de
referência.
Observação: ignore o problema da tarefa do_comparison ou publish_test_complete no DAG test_word_count se o status de uma delas for "Falha".
Se a execução do DAG falhar, acione outra execução dele seguindo as etapas abaixo:
- Na página DAGs, na linha
test_word_count, clique em DAG de gatilho. 
Clique em Verificar meu progresso para conferir o objetivo.
Criar pipelines do Cloud Build
Criar o pipeline de produção
Quando o fluxo de trabalho de processamento de teste é executado com êxito, é possível enviar a versão atual do fluxo de trabalho para a produção. Existem várias maneiras de implantar o fluxo de trabalho na produção:
- Manualmente
- Com acionamento automático quando todos os testes passam nos ambientes de teste ou de preparo
- Com acionamento automático por um job programado
As abordagens automáticas não estão no escopo deste laboratório. Para mais
informações, consulte
Engenharia de versões.
Neste laboratório, você fará uma implantação manual na produção executando o
build de implantação na produção do Cloud Build. Isso acontecerá
em três etapas:
- Copie o arquivo JAR do WordCount do bucket de teste para o bucket de produção.
- Defina as variáveis do Cloud Composer do fluxo de trabalho de produção para apontar para o arquivo JAR recém-enviado.
- Implante a definição do DAG do fluxo de trabalho de produção no ambiente do Cloud Composer e execute o fluxo.
As substituições variáveis definem o nome do arquivo JAR mais recente que é implantado na produção com os buckets do Cloud Storage usados pelo fluxo de trabalho de processamento de produção. Para criar o pipeline do Cloud Build que implanta o fluxo de trabalho do Airflow na produção, faça o seguinte:
-
No Cloud Shell, leia o nome do arquivo JAR mais recente
imprimindo a variável do Cloud Composer para o nome de arquivo JAR:
export DATAFLOW_JAR_FILE_LATEST=$(gcloud composer environments run $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION variables \
-- \
get dataflow_jar_file_test | grep -i '.jar')
-
Use o arquivo de configuração do pipeline de build, deploy_prod.yaml, para
criar o pipeline no Cloud Build:
cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline
gcloud builds submit --config=deploy_prod.yaml --substitutions=\
REPO_NAME=$SOURCE_CODE_REPO,\
_DATAFLOW_JAR_BUCKET_TEST=$DATAFLOW_JAR_BUCKET_TEST,\
_DATAFLOW_JAR_FILE_LATEST=$DATAFLOW_JAR_FILE_LATEST,\
_DATAFLOW_JAR_BUCKET_PROD=$DATAFLOW_JAR_BUCKET_PROD,\
_COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_PROD,\
_COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\
_COMPOSER_REGION=$COMPOSER_REGION,\
_COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\
_COMPOSER_DAG_NAME_PROD=$COMPOSER_DAG_NAME_PROD
Verificar o fluxo de trabalho de processamento de dados criado pelo pipeline de produção
-
Copie o URL da sua interface do Cloud Composer:
gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.airflowUri)"
-
Para verificar se o DAG do fluxo de trabalho de processamento de dados de produção está implantado,
acesse o URL da etapa anterior e verifique se o DAG
prod_word_count está na lista.
-
Na página DAGs, na linha prod_word_count, clique em Acionar DAG.
-
Recarregue a página para atualizar o status de execução do DAG. Para verificar se o DAG
do fluxo de trabalho de processamento de dados de produção foi implantado e está no modo de execução, mantenha o
cursor sobre o círculo verde-claro abaixo de Execuções DAG e confira se aparece
Em execução.
-
Após a conclusão da execução, mantenha o cursor sobre o círculo verde-escuro abaixo da coluna Execuções DAG
e confira se aparece Sucesso.
-
No Cloud Shell, liste os arquivos de resultados no bucket do
Cloud Storage:
gsutil ls gs://$RESULT_BUCKET_PROD
A resposta será semelhante a esta:
gs://…-composer-result-prod/output-00000-of-00003
gs://…-composer-result-prod/output-00001-of-00003
gs://…-composer-result-prod/output-00002-of-00003
Observação: normalmente, a execução do job de fluxo de trabalho dos dados de produção é
acionada por eventos, como ao armazenar arquivos em buckets, ou programada para execução frequente. O job de implantação precisa garantir que o fluxo de trabalho dos dados de produção não esteja sendo executado antes da implantação.
Em um ambiente de produção, use DAGs dos comandos da CLI do Airflow para recuperar o status da execução de um DAG.
Clique em Verificar meu progresso para conferir o objetivo.
Criar o pipeline de produção
Tarefa 6: configurar um gatilho de build
É preciso configurar um
gatilho do Cloud Build
que aciona uma nova compilação quando as alterações são enviadas para a ramificação mestre
do repositório de origem.
-
No Cloud Shell, execute o seguinte comando para visualizar todas as variáveis de substituição necessárias para a compilação. Anote esses valores, porque
eles serão necessários em uma etapa posterior.
echo "_DATAFLOW_JAR_BUCKET : ${DATAFLOW_JAR_BUCKET_TEST}
_COMPOSER_INPUT_BUCKET : ${INPUT_BUCKET_TEST}
_COMPOSER_REF_BUCKET : ${REF_BUCKET_TEST}
_COMPOSER_DAG_BUCKET : ${COMPOSER_DAG_BUCKET}
_COMPOSER_ENV_NAME : ${COMPOSER_ENV_NAME}
_COMPOSER_REGION : ${COMPOSER_REGION}
_COMPOSER_DAG_NAME_TEST : ${COMPOSER_DAG_NAME_TEST}"
-
No console do Cloud, acesse a página Gatilhos de build: página "Gatilhos de build".
-
Clique em Criar gatilho.
-
Para definir as configurações do gatilho, siga estas etapas:
- No campo Nome, digite
Trigger build in test environment.
- Em Evento, clique em Enviar para uma ramificação.
- Em Repositório, selecione
data-pipeline-source (Cloud Source Repositories).
- No campo Ramificação, selecione
^master$.
- Em Configuração, clique em Arquivo de configuração
do Cloud Build (yaml ou json).
- No campo Local do arquivo de configuração do Cloud Build, digite
build-pipeline/build_deploy_test.yaml.
-
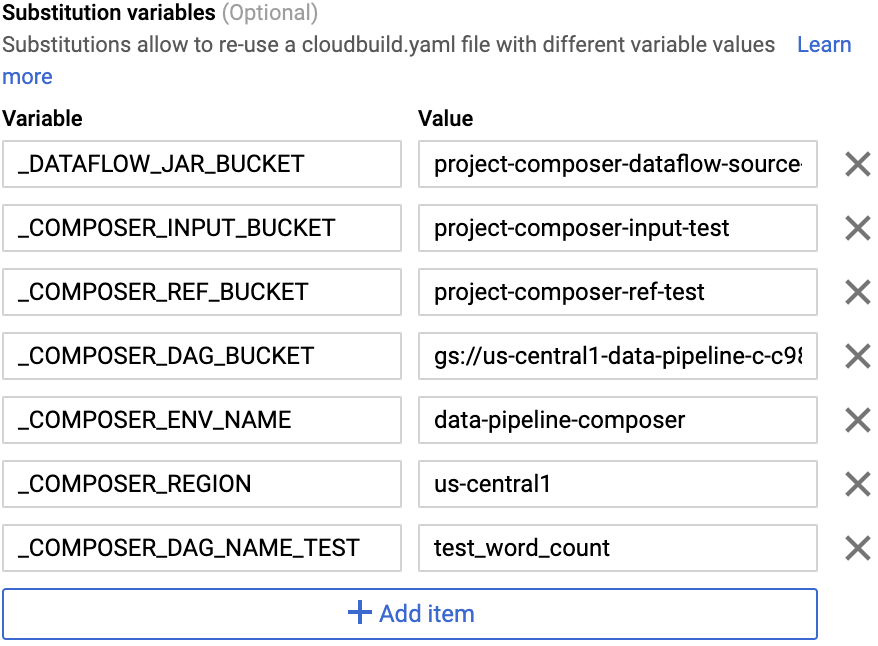
No Campo avançado, substitua as
variáveis pelos valores do ambiente que você recebeu na etapa
anterior. Adicione os itens abaixo um por vez e clique em + ADICIONAR VARIÁVEL para cada
par de nome-valor:
-
_DATAFLOW_JAR_BUCKET
-
_COMPOSER_INPUT_BUCKET
-
_COMPOSER_REF_BUCKET
-
_COMPOSER_DAG_BUCKET
-
_COMPOSER_ENV_NAME
-
_COMPOSER_REGION
-
_COMPOSER_DAG_NAME_TEST
-
Em Conta de serviço, selecione xxxxxxx-compute@developer.gserviceaccount.com.
-
Clique em Criar.
Clique em Verificar meu progresso para conferir o objetivo.
Como configurar um gatilho de compilação
Testar o gatilho
Para testar o acionador, é preciso adicionar uma nova palavra ao arquivo de entrada de teste e fazer o ajuste correspondente no arquivo de referência de teste. Depois, verifique se o pipeline de compilação é acionado por um envio de confirmação para o Cloud Source Repositories e se o fluxo de trabalho de processamento de dados é executado corretamente com os arquivos de teste atualizados.
-
No Cloud Shell, adicione uma palavra de teste ao fim do arquivo:
echo "testword" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/input.txt
-
Atualize o arquivo de referência do resultado do teste, ref.txt, para corresponder às alterações
feitas no arquivo de entrada:
echo "testword: 1" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/ref.txt
-
Confirme e envie as alterações ao Cloud Source Repositories:
cd ~/$SOURCE_CODE_REPO
git add .
git commit -m 'change in test files'
git push google master
-
No console do Cloud, acesse a página Histórico: página "Histórico".
-
Para verificar se um novo build é acionado pelo envio anterior para a ramificação
mestre, confirme se a coluna Acionador mostra Enviar para ramificação mestre
no build em execução.
-
No Cloud Shell, copie o URL da interface da Web do
Cloud Composer:
gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION --format="get(config.airflowUri)"
-
Após a conclusão da compilação, acesse o URL do comando anterior para
verificar se o DAG test_word_count está em execução.
Aguarde até que a execução do DAG seja concluída, o que é indicado quando o círculo verde claro desaparece da coluna Execuções do DAG. Geralmente,
o processo leva de três a cinco minutos.
Observação: ignore o problema da tarefa do_comparison no DAG test_word_count.
-
No Cloud Shell, faça o download dos arquivos de resultados do teste:
mkdir ~/result-download
cd ~/result-download
gsutil cp gs://$RESULT_BUCKET_TEST/output* .
-
Verifique se a palavra recém-adicionada está em um dos arquivos de resultado:
grep testword output*
A saída será assim:
output-00000-of-00003:testword: 1
Clique em Verificar meu progresso para conferir o objetivo.
Testar o gatilho
Parabéns
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
- 1 estrela = muito insatisfeito
- 2 estrelas = insatisfeito
- 3 estrelas = neutro
- 4 estrelas = satisfeito
- 5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.