

![複数のデータ行がそれぞれの行のステータスとともに表示されている [ビルドステップ] ページ](https://cdn.qwiklabs.com/j3Zu8L7ugvhc2%2Fln1Yg%2FN1vh7yGCPE40RJ1hvG1vl1g%3D)
![[DAG Runs] の処理ステータスは「1」。](https://cdn.qwiklabs.com/9pL0VTTq5arbw9T1%2Fhwn4d%2BaxNYy4t9jcb5F3dOEhTY%3D)
![変数とそれぞれの値が表示された [置換変数] ページ](https://cdn.qwiklabs.com/YImAQh3Laz4taFwXNQmej28KkmTtUUUPbHtyBXwVRBY%3D)
始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Creating the Cloud Storage buckets
/ 10
Pushing the source code to Cloud Source Repositories
/ 10
Creating Cloud Build pipelines
/ 10
Create the production pipeline
/ 10
Configuring a build trigger
/ 10
Test the trigger
/ 10
このラボでは、Google Cloud のマネージド プロダクトを使用して継続的インテグレーション / 継続的デプロイ(CI / CD)の手法を実装し、データ処理用の CI / CD パイプラインを設定します。データ サイエンティストやエンジニアは、CI / CD の方法論を応用して、品質、保守性、適応性に優れたデータ処理とワークフローを実現できます。適用できる手法は次のとおりです。
このラボでは、次の Google Cloud プロダクトを使用します。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] パネルでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] パネルでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
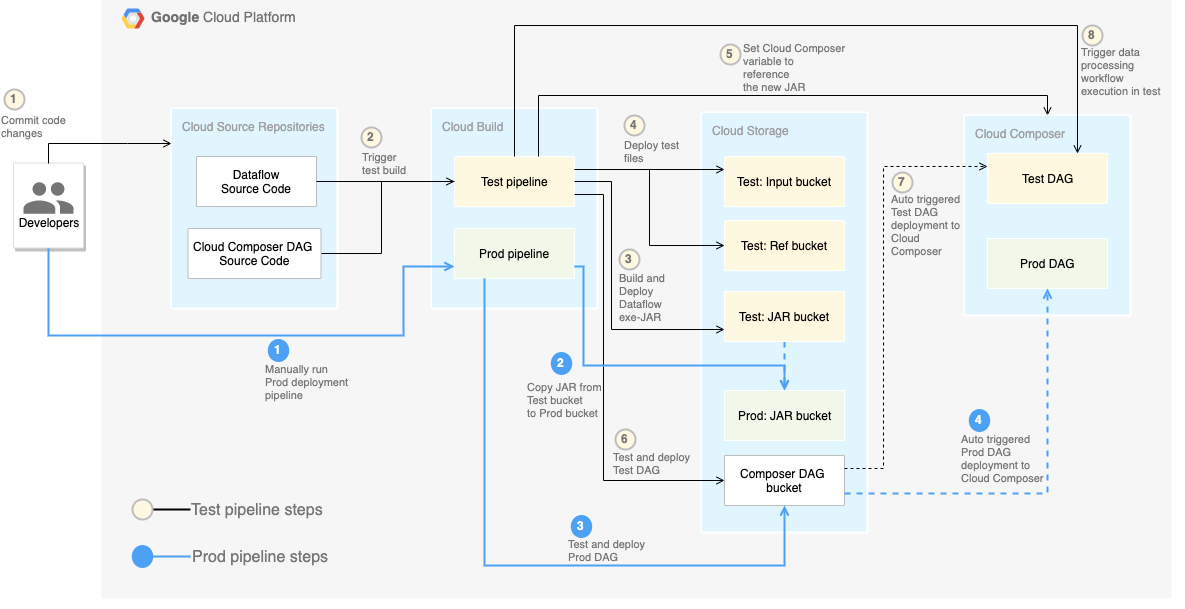
大まかに言えば、CI / CD パイプラインは次のステップで構成されます。
次の図に、CI / CD パイプライン ステップの詳細を示します。
このラボでは、テスト環境と本番環境へのデプロイが 2 つの異なる Cloud Build パイプライン(テスト パイプラインと本番環境パイプライン)に分かれています。
上の図では、テスト パイプラインは以下のステップで構成されています。
環境を完全に分離するには、異なるプロジェクト内に作成された複数の Cloud Composer 環境が必要です。このようにして作成された環境はデフォルトで分離され、本番環境を保護するのに役立ちます。ただし、このアプローチは本ラボの対象範囲外です。複数の Google Cloud プロジェクトのリソースにアクセスする方法の詳細については、サービス アカウント権限の設定をご覧ください。
Cloud Composer がデータ処理ワークフローを実行する手順は、Python で書かれた有向非巡回グラフ(DAG)で定義されます。DAG では、データ処理ワークフローのすべてのステップが、それぞれの依存関係とともに定義されます。
CI / CD パイプラインは毎回のビルドの中で、DAG 定義を Cloud Source Repositories から Cloud Composer に自動的にデプロイします。このプロセスにより、Cloud Composer のワークフロー定義は人の手を介さなくても常に最新の状態に保たれます。
テスト環境用の DAG 定義では、データ処理ワークフローに加えてエンドツーエンドのテストステップが定義されています。テストステップは、データ処理ワークフローが正しく実行されることを確認するのに役立ちます。
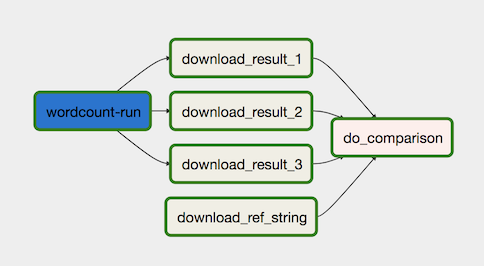
次の図に、データ処理ワークフローを示します。
データ処理ワークフローは次のステップで構成されます。
Dataflow で WordCount データ処理を実行します。
WordCount プロセスの出力ファイルをダウンロードします。WordCount プロセスは次の 3 つのファイルを出力します。
download_result_1download_result_2download_result_3download_ref_string という名前の参照ファイルをダウンロードします。
この参照ファイルと照らし合わせて結果を検証します。この統合テストでは、3 つの結果すべてを集計して、集計結果を参照ファイルと比較します。
Cloud Composer などのタスク オーケストレーション フレームワークを使用してデータ処理ワークフローを管理すると、ワークフローのコードの複雑さを軽減できます。
このラボには、データ処理ワークフローをエンドツーエンドで検証する統合テストのほかに、2 つの単体テストがあります。それは、データ処理コードとデータ処理ワークフロー コードの自動テストです。データ処理コードのテストは Java で記述されていて、Maven ビルドプロセス中に自動的に実行されます。データ処理ワークフロー コードのテストは Python で記述されていて、独立したビルドステップとして実行されます。
サンプルコードは次の 2 つのフォルダにあります。
env-setup フォルダには、Google Cloud 環境の初期設定用シェル スクリプトが含まれています。
source-code フォルダには、時間の経過に伴って継続的に開発され、ソース管理が必要なコードが含まれています。このコードによってビルドとテストの自動的なプロセスがトリガーされます。このフォルダには次のサブフォルダが含まれます。
data-processing-code フォルダには、Apache Beam プロセスのソースコードが含まれています。workflow-dag フォルダには、データ処理ワークフローの Composer DAG 定義が含まれています。この DAG 定義には、Dataflow プロセスを設計、実装、テストするステップが記述されています。build-pipeline フォルダには 2 つの Cloud Build 構成が含まれています。1 つはテスト パイプライン用の構成であり、もう 1 つは本番環境パイプライン用の構成です。このフォルダには、これらのパイプラインのサポート スクリプトも含まれています。このラボの目的上、データ処理用と DAG ワークフロー用のソースコード ファイルは、同じソースコード リポジトリ内の別のフォルダに格納されています。本番環境では、通常これらのソースコード ファイルは個別のソースコード リポジトリに格納され、別のチームによって管理されます。
このラボでは、すべてのコマンドを Cloud Shell で実行します。Cloud Shell は、Google Cloud コンソールの下部にウィンドウとして表示されます。
Cloud コンソールで Cloud Shell を開きます。
サンプルコード リポジトリのクローンを作成します。
このラボのサンプル ファイルが含まれているディレクトリに移動します。
sed コマンドを使用して、set_env.sh ファイル内のリージョンを更新します。
スクリプトを実行して環境変数を設定します。
このスクリプトでは次の環境変数を設定します。
環境変数はセッション間で保持されないため、ラボを進めている間に Cloud Shell セッションがシャットダウンまたは切断された場合は、環境変数を再設定する必要があります。
yaml ファイルにロギング オプションを追加します。
パイプライン スクリプトを更新します。
必要な API にアクセスできることを確認するには、Cloud Composer API への接続を再起動します。
Google Cloud コンソール上部の検索バーに「Cloud Composer API」と入力し、検索結果の「Cloud Composer API」をクリックします。
[管理] をクリックします。
[API を無効にする] をクリックします。
確認を求められたら、[無効にする] をクリックします。
API が再度有効になると、ページに無効にするオプションが表示されます。
Cloud Shell で次のコマンドを実行して Cloud Composer 環境を作成します。
コマンドが完了したら、Google Cloud で確認します。
スクリプトを実行して、Cloud Composer 環境の変数を設定します。これらの変数はデータ処理 DAG で必要になります。
このスクリプトでは次の環境変数を設定します。
Cloud Composer は、Cloud Storage バケットを使用して DAG を保存します。DAG 定義ファイルをバケットに移動すると、Cloud Composer の読み取りがトリガーされ、自動的にファイルが読み取られます。Cloud Composer 環境を作成したときに、Cloud Composer 用の Cloud Storage バケットを作成しました。次の手順では、バケットの URL を抽出してから、DAG 定義を Cloud Storage バケットに自動的にデプロイするように CI / CD パイプラインを構成します。
Cloud Shell で、バケットの URL を環境変数としてエクスポートします。
Cloud Storage バケットにアクセスできるようにするために、Cloud Composer が使用するサービス アカウントの名前をエクスポートします。
このセクションでは、次のデータを保存する一連の Cloud Storage バケットを作成します。
Cloud Storage バケットを作成するには、以下の手順を実施します。
Cloud Shell で Cloud Storage バケットを作成し、Cloud Composer サービス アカウントにデータ処理ワークフローを実行する権限を付与します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このラボでは、バージョン管理に組み込む必要があるソースコード ベースを 1 つ作成します。次の手順は、コードベースが開発され、時間の経過とともに変更されていく様子を表しています。変更がリポジトリに push されるたびに、ビルド、デプロイ、テストのパイプラインがトリガーされます。
Cloud Shell で、source-code フォルダを Cloud Source Repositories に push します。
これらは、新しいディレクトリで Git を初期化し、コンテンツをリモート リポジトリに push する際の標準的なコマンドです。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このセクションでは、データ処理ワークフローをビルド、デプロイ、テストするビルド パイプラインを作成します。
ビルドとテストのパイプライン ステップは YAML 構成ファイルで構成します。このラボでは、事前ビルド済みの git、maven、gsutil、gcloud のビルダー イメージを使用して、各ビルドステップのタスクを実行します。ビルド時に環境設定を定義するには、構成変数の置換を使用します。ソースコード リポジトリの場所は、変数の置換と Cloud Storage バケットの場所によって定義されます。JAR ファイル、テストファイル、DAG 定義をデプロイするときに、この情報が必要になります。
Cloud Shell で、ビルド パイプラインの構成ファイルを送信して Cloud Build 内にパイプラインを作成します。
このコマンドは、次の手順でビルドを実行するように Cloud Build に指示するものです。
WordCount の自己実行型 JAR ファイルをビルドしてデプロイします。
データ処理ワークフローを Cloud Composer にデプロイして設定します。
テスト環境でデータ処理ワークフローを実行し、テスト処理ワークフローをトリガーします。
ビルドファイルを送信したら、ビルドステップを検証します。
Cloud コンソールで [ビルド履歴] ページに移動し、過去および現在実行中のすべてのビルドのリストを表示します。
現在実行中のビルドをクリックします。
[ビルドの詳細] ページで、そのビルドステップが上記のステップと一致していることを確認します。
ビルドが完了すると、[ビルドの詳細] ページの [ステータス] フィールドに「Build successful」と表示されます。
Cloud Shell で、WordCount のサンプル JAR ファイルが正しいバケットにコピーされたことを確認します。
出力は次のようになります。
Cloud Composer のウェブ インターフェースの URL を取得します。次の手順で使用するために、この URL をメモしておきます。
前の手順の URL を使用して Cloud Composer UI に移動し、DAG が正しく実行されたことを確認します。Composer のページで [Airflow ウェブサーバー] リンクをクリックして移動することもできます。[DAG Runs] 列に情報が表示されない場合は、数分待ってからページを再読み込みしてください。
データ処理ワークフロー DAG test_word_count がデプロイされて実行モードになっていることを確認するには、[DAG Runs] の下の薄い緑色の円にポインタを置き、「実行中」と表示されることを確認します。
実行中のデータ処理ワークフローをグラフとして表示するには、薄い緑色の円をクリックし、[Dag Runs] ページで [Dag Id: test_word_count] をクリックします。
現在の DAG の実行ステータスを更新するには、[グラフ表示] ページを再読み込みします。ワークフローが完了するまでに、通常 3〜5 分かかります。DAG の実行が正常に終了したことを確認するには、ポインタを各タスクの上に置き、ツールチップに「State: success」と表示されることを確認します。最後のタスク do_comparison は、プロセスの出力を参照ファイルと照らし合わせて検証する統合テストです。
test_word_count DAG の do_comparison タスクまたは publish_test_complete タスクのいずれかのステータスが Failed になっている場合、これらのタスクの問題は無視してください。DAG の実行に失敗した場合は、以下の手順を使用して別の DAG 実行をトリガーしてください。
test_word_count 行で、[DAG をトリガー] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
テスト処理ワークフローが正常に実行されたら、現在のバージョンのワークフローを本番環境に昇格させることができます。ワークフローを本番環境にデプロイするには、いくつかの方法があります。
自動アプローチはこのラボの対象範囲外です。詳細については、リリース エンジニアリングをご覧ください。
このラボでは、Cloud Build の本番環境用デプロイメント ビルドを実行して本番環境に手動でデプロイします。本番環境用デプロイメント ビルドは次の手順で実行します。
変数置換によって、本番環境にデプロイされる最新の JAR ファイルの名前が定義されます。本番環境の処理ワークフローで使用される Cloud Storage バケットに置換されます。本番環境用の Airflow ワークフローをデプロイする Cloud Build パイプラインを作成するには、以下の手順を実行します。
Cloud Shell で、最新の JAR ファイル名の Cloud Composer 変数を出力して、その JAR ファイルのファイル名を読み取ります。
ビルド パイプラインの構成ファイル deploy_prod.yaml, を使用して Cloud Build 内にパイプラインを作成します。
Cloud Composer UI の URL を取得します。
本番環境用データ処理ワークフロー DAG がデプロイされていることを確認するには、前の手順で取得した URL に移動し、prod_word_count DAG が DAG リストに含まれていることを確認します。
[DAGs] ページの prod_word_count 行で、[DAG をトリガー] をクリックします。
DAG の実行ステータスを更新するには、ページを再読み込みします。本番環境用データ処理ワークフロー DAG がデプロイされ実行モードになっていることを確認するには、[DAG Runs] の下の薄い緑色の円にポインタを置き、「実行中」と表示されることを確認します。
実行が完了したら、[DAG Runs] 列の下の濃い緑色の円にポインタを置き、「成功」と表示されることを確認します。
Cloud Shell で、Cloud Storage バケットの結果ファイルを一覧表示します。
出力は次のようになります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ソース リポジトリのマスター ブランチに変更が push されたときに新しいビルドをトリガーする Cloud Build トリガーを設定します。
Cloud Shell で次のコマンドを実行して、ビルドに必要なすべての置換変数を取得します。後の手順で必要になるため、この値をすべてメモしておきます。
Cloud コンソールで、[ビルドトリガー] ページに移動します([ビルドトリガー] ページ)。
[トリガーを作成] をクリックします。
トリガー設定を構成するには、以下の手順を実施します。
Trigger build in test environment」と入力します。data-pipeline-source (Cloud Source Repositories) には [リポジトリ] を選択します。^master$ を選択します。build-pipeline/build_deploy_test.yaml」と入力します。[詳細設定] フィールドで、変数を前のステップで環境から取得した値に置き換えます。次の値を一度に 1 つずつ追加して、名前と値のペアごとに [+ 変数を追加] をクリックします。
_DATAFLOW_JAR_BUCKET
_COMPOSER_INPUT_BUCKET
_COMPOSER_REF_BUCKET
_COMPOSER_DAG_BUCKET
_COMPOSER_ENV_NAME
_COMPOSER_REGION
_COMPOSER_DAG_NAME_TEST
[サービス アカウント] で、[xxxxxxx-compute@developer.gserviceaccount.com] を選択します。
[作成] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
トリガーをテストするには、テスト入力ファイルに新しい単語を追加し、それに合わせてテスト参照ファイルも調整します。Cloud Source Repositories への commit push によってビルド パイプラインがトリガーされ、更新されたテストファイルを使用してデータ処理ワークフローが正しく実行されることを確認します。
Cloud Shell で、テストファイルの末尾にテスト用の単語を追加します。
テスト入力ファイルで行った変更に合わせて、テスト結果の参照ファイル ref.txt を更新します。
変更を commit して Cloud Source Repositories に push します。
Cloud コンソールで、[履歴] ページに移動します([履歴] ページ)。
マスター ブランチへの以前の push によって新しいビルドがトリガーされたことを確認するには、現在実行中のビルドで [トリガー] 列に [マスター ブランチへの push] と表示されていることを確認します。
Cloud Shell で、Cloud Composer のウェブ インターフェースの URL を取得します。
ビルドが完了したら、前のコマンドで取得した URL に移動し、test_word_count DAG が実行されていることを確認します。
DAG の実行が完了するまで待ちます。完了すると、[DAG runs] 列の薄い緑色の円が消えます。プロセスが完了するまでに通常 3~5 分かかります。
test_word_count DAG の do_comparison タスクの問題は無視してください。
Cloud Shell でテスト結果ファイルをダウンロードします。
新しく追加した単語が結果ファイルのいずれかに含まれていることを確認します。
出力は次のようになります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2020 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。


このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします
ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください