Présentation
Dans cet atelier, vous allez configurer un pipeline d'intégration/de déploiement continu (CI/CD) pour traiter des données en appliquant des méthodes CI/CD avec des produits gérés sur Google Cloud. Les data scientists et les ingénieurs peuvent adapter les méthodologies mises en œuvre dans les pratiques CI/CD pour garantir la haute qualité, la facilité de gestion et l'adaptabilité des processus de données et des workflows. Vous pouvez appliquer les méthodes suivantes :
- Contrôle des versions du code source
- Création, test et déploiement automatiques d'applications
- Isolation et séparation des environnements de développement et de test de l'environnement de production
- Procédures reproductibles pour la configuration des environnements
Architecture de déploiement
Dans ce guide, vous allez utiliser les produits Google Cloud suivants :
-
Cloud Build, pour développer un pipeline CI/CD afin de créer, déployer et tester un workflow de traitement des données, et effectuer le traitement des données.
Cloud Build est un service géré qui exécute votre build sur Google Cloud sous la forme d'une série d'étapes de compilation où chaque étape est exécutée dans un conteneur Docker.
-
Cloud Composer, pour définir et exécuter les étapes du workflow, telles que le démarrage du traitement des données, les tests et la vérification des résultats. Cloud Composer est un service géré basé sur Apache Airflow qui offre un environnement dans lequel vous pouvez créer, planifier, surveiller et gérer des workflows complexes, tels que le workflow de traitement des données développé dans cet atelier.
-
Dataflow pour exécuter l'exemple Apache Beam WordCount comme exemple de traitement des données.
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google Cloud
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour afficher un menu contenant la liste des produits et services Google Cloud, cliquez sur le menu de navigation en haut à gauche, ou saisissez le nom du service ou du produit dans le champ Recherche.

Activer Google Cloud Shell
Google Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud.
Google Cloud Shell vous permet d'accéder à vos ressources Google Cloud grâce à une ligne de commande.
-
Dans la barre d'outils située en haut à droite dans la console Cloud, cliquez sur le bouton "Ouvrir Cloud Shell".

-
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Par exemple :

gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
gcloud auth list
Résultat :
Credentialed accounts:
- @.com (active)
Exemple de résultat :
Credentialed accounts:
- google1623327_student@qwiklabs.net
- Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project =
Exemple de résultat :
[core]
project = qwiklabs-gcp-44776a13dea667a6
Remarque : Pour consulter la documentation complète sur gcloud, accédez au guide de présentation de la gcloud CLI.
Le pipeline CI/CD
De manière générale, le pipeline CI/CD comprend les étapes suivantes :
- Cloud Build crée un package de l'exemple WordCount dans un fichier JAR (Java Archive) autoexécutable à l'aide du compilateur Maven.
Le compilateur Maven est un conteneur dans lequel Maven est installé. Lorsqu'une étape de compilation est configurée pour utiliser le compilateur Maven, Maven exécute les tâches.
- Cloud Build importe le fichier JAR dans Cloud Storage.
- Cloud Build exécute des tests unitaires sur le code du workflow de traitement des données et déploie le code du workflow dans Cloud Composer.
- Cloud Composer récupère le fichier JAR et exécute le job de traitement des données sur Dataflow.
Le schéma suivant présente une vue détaillée des étapes du pipeline CI/CD.
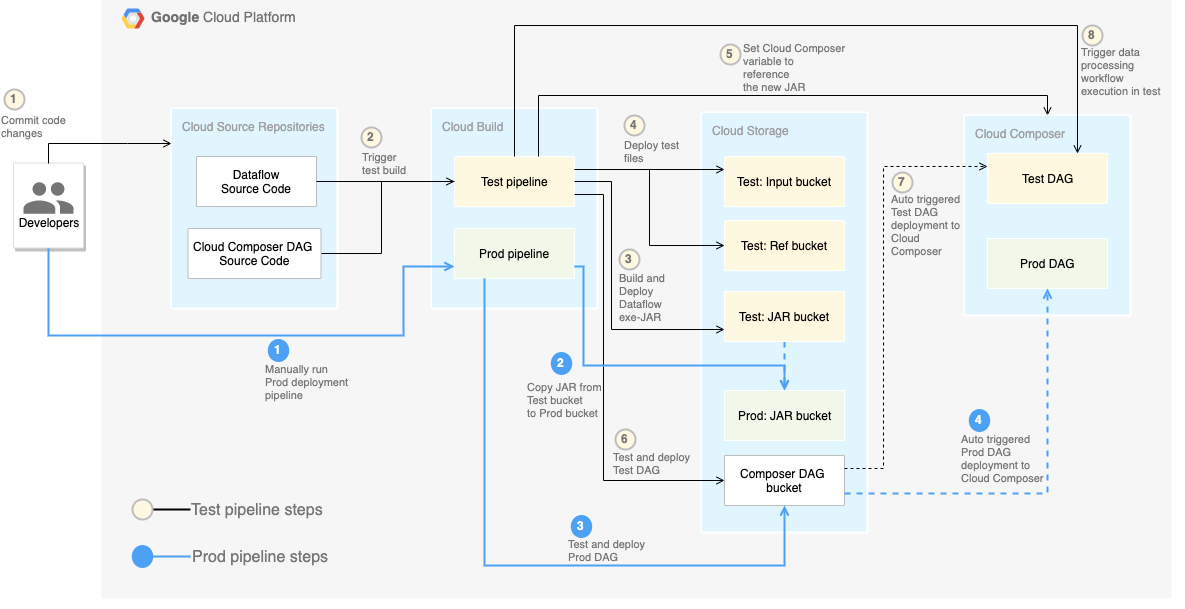
Dans cet atelier, les déploiements dans les environnements de test et de production sont séparés en deux pipelines Cloud Build différents : un pipeline de test et un pipeline de production.
Dans le schéma précédent, le pipeline de test comprend les étapes suivantes :
- Un développeur valide les modifications de code dans Cloud Source Repositories.
- Les modifications de code déclenchent une version de build dans Cloud Build.
- Cloud Build crée le fichier JAR auto-exécutable et le déploie dans le bucket JAR de test sur Cloud Storage.
- Cloud Build déploie les fichiers de test dans les buckets de fichiers de test sur Cloud Storage.
- Cloud Build définit dans Cloud Composer la variable utilisée pour référencer le fichier JAR qui vient d'être déployé.
- Cloud Build teste le graphe orienté acyclique (DAG, Directed Acyclic Graph) du workflow de traitement des données et le déploie dans le bucket Cloud Composer sur Cloud Storage.
- Le fichier DAG du workflow est déployé dans Cloud Composer.
- Cloud Build déclenche l'exécution du workflow de traitement des données qui vient d'être déployé.
Pour séparer complètement les deux environnements, vous devez créer plusieurs environnements Cloud Composer dans différents projets, séparés par défaut les uns des autres. Cette séparation permet de sécuriser votre environnement de production. Cette approche n'entre pas dans le cadre de cet atelier. Pour en savoir plus sur l'accès aux ressources réparties dans plusieurs projets Google Cloud, consultez la page Définir des autorisations de compte de service.
Le workflow de traitement des données
Les instructions relatives à l'exécution du workflow de traitement des données par Cloud Composer sont indiquées dans un graphe orienté acyclique (DAG) écrit en Python. Le DAG définit toutes les étapes du workflow de traitement des données, ainsi que les dépendances entre elles.
Le pipeline CI/CD déploie automatiquement la définition du DAG à partir de Cloud Source Repositories dans Cloud Composer, lors de chaque compilation. Ce processus assure que Cloud Composer est constamment à jour avec la dernière définition du workflow sans qu'aucune intervention humaine ne soit requise.
En plus du workflow de traitement des données, la définition du DAG pour l'environnement de test comprend une étape de test de bout en bout. Cette étape de test permet de vérifier que le workflow de traitement des données s'exécute correctement.
Le workflow de traitement des données est illustré dans le schéma suivant.
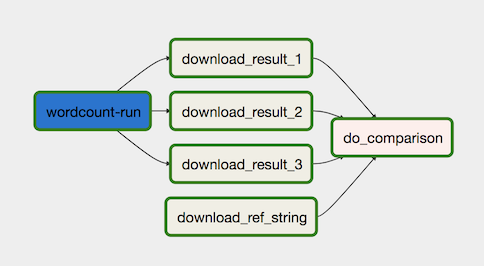
Le workflow de traitement des données comprend les étapes suivantes :
-
Exécution du processus de données WordCount dans Dataflow.
-
Téléchargement des trois fichiers de sortie générés par le processus WordCount :
download_result_1download_result_2download_result_3
-
Téléchargez le fichier de référence, appelé download_ref_string
-
Vérifiez les résultats par rapport au fichier de référence. Ce test d'intégration agrège les trois résultats et compare les résultats agrégés au fichier de référence.
L'utilisation d'un framework d'orchestration de tâches, tel que Cloud Composer, pour gérer le workflow de traitement des données permet de réduire la complexité du code du workflow.
Les tests
En plus du test d'intégration qui vérifie le workflow de traitement des données de bout en bout, cet atelier comporte deux tests unitaires. Les tests unitaires sont des tests automatiques qui sont exécutés sur le code de traitement des données et sur le code du workflow de traitement des données. Le test sur le code de traitement des données est écrit en Java et s'exécute automatiquement lors du processus de compilation Maven. Le test sur le code du workflow de traitement des données est écrit en Python et s'exécute en tant qu'étape de compilation indépendante.
Exemple de code
L'exemple de code se trouve dans deux dossiers :
-
Le dossier env-setup contient des scripts shell pour la configuration initiale de l'environnement Google Cloud.
-
Le dossier source-code contient du code développé dans le temps, qui doit être contrôlé par la source et déclenche des processus automatiques de compilation et de test. Ce dossier contient les sous-dossiers suivants :
- Le dossier
data-processing-code contient le code source du processus Apache Beam.
- Le dossier
workflow-dag contient les définitions DAG de Composer pour les workflows de traitement des données, ainsi que les étapes de création, de mise en œuvre et de test du processus Dataflow.
- Le dossier
build-pipeline contient deux configurations Cloud Build : l'une pour le pipeline de test et l'autre pour le pipeline de production. Ce dossier contient également un script d'assistance pour les pipelines.
Pour les besoins de cet atelier, les fichiers de code source pour le traitement des données et pour le workflow DAG se trouvent dans des dossiers différents du même dépôt de code source.
Dans un environnement de production, les fichiers de code source se trouvent généralement dans leurs propres dépôts de code source, et sont gérés par des équipes différentes.
Tâche 1 : Configurer votre environnement
Dans cet atelier, vous allez exécuter toutes les commandes dans Cloud Shell.
Cloud Shell apparaît sous la forme d'une fenêtre en bas de la console Google Cloud.
-
Dans la console Cloud, ouvrez Cloud Shell :
-
Clonez l'exemple de dépôt de code :
git clone https://github.com/GoogleCloudPlatform/ci-cd-for-data-processing-workflow.git
-
Accédez au répertoire qui contient les exemples de fichiers de l'atelier :
cd ~/ci-cd-for-data-processing-workflow/env-setup
-
Mettez à jour la région dans le fichier set_env.sh à l'aide de la commande sed.
sed -i "s/us-central1-a/{{{project_0.default_zone|Zone}}}/g" set_env.sh
sed -i "s/us-central1/{{{project_0.default_region|Region}}}/g" set_env.sh
-
Exécutez un script pour définir les variables d'environnement :
source set_env.sh
Le script définit les variables d'environnement suivantes :
- L'ID de votre projet Google Cloud
- Votre région et votre zone
- Le nom des buckets Cloud Storage utilisés par le pipeline de compilation et le workflow de traitement des données
Les variables d'environnement ne sont pas conservées entre les sessions. Par conséquent, si votre session Cloud Shell se ferme ou se déconnecte pendant le déroulement de l'atelier, vous devrez reconfigurer les variables d'environnement.
-
Ajoutez l'option de journalisation au fichier YAML :
echo -e "\noptions:\n logging: CLOUD_LOGGING_ONLY" >> ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline/build_deploy_test.yaml
-
Mettez à jour le script de pipeline :
sed -i 's/project=project/project_id=project/' ~/ci-cd-for-data-processing-workflow/source-code/workflow-dag/data-pipeline-test.py
Tâche 2 : Créer l'environnement Cloud Composer
Vérifier que l'API Cloud Composer est activée
Pour vous assurer que vous avez bien accès aux API requises, redémarrez la connexion à l'API Cloud Composer.
-
Dans la console Google Cloud, saisissez API Cloud Composer dans la barre de recherche en haut de l'écran, puis cliquez sur le résultat API Cloud Composer.
-
Cliquez sur Gérer.
-
Cliquez sur Désactiver l'API.
Si vous êtes invité à confirmer votre choix, cliquez sur Désactiver.
- Cliquez sur Activer.
Une fois l'API réactivée, l'option permettant de la désactiver s'affiche sur la page.
Créer un environnement Cloud Composer
-
Dans Cloud Shell, exécutez la commande suivante pour créer un environnement Cloud Composer :
gcloud composer environments create $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--image-version composer-3-airflow-2
Remarque : La création de l'environnement Cloud Composer prend généralement 15 minutes environ. Veuillez attendre que Composer soit prêt avant de continuer.
Une fois la commande exécutée, vous pouvez la vérifier dans Google Cloud.
-
Exécutez un script pour définir les variables de l'environnement Cloud Composer. Les variables sont requises pour les DAG de traitement des données.
cd ~/ci-cd-for-data-processing-workflow/env-setup
chmod +x set_composer_variables.sh
./set_composer_variables.sh
Le script définit les variables d'environnement suivantes :
- L'ID de votre projet Google Cloud
- Votre région et votre zone
- Le nom des buckets Cloud Storage utilisés par le pipeline de compilation et le workflow de traitement des données
Extraire les propriétés de l'environnement Cloud Composer
Cloud Composer utilise un bucket Cloud Storage pour stocker les DAG.
Le déplacement d'un fichier de définition de DAG vers ce bucket déclenche la lecture automatique des fichiers par Cloud Composer. Vous avez généré le bucket Cloud Storage pour Cloud Composer lorsque vous avez créé l'environnement Cloud Composer.
Dans la procédure suivante, vous allez extraire l'URL des buckets, puis configurer votre pipeline CI/CD pour déployer automatiquement les définitions de DAG dans le bucket Cloud Storage.
-
Dans Cloud Shell, exportez l'URL du bucket en tant que variable d'environnement :
export COMPOSER_DAG_BUCKET=$(gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.dagGcsPrefix)")
-
Exportez le nom du compte de service utilisé par Cloud Composer pour accéder aux buckets Cloud Storage :
export COMPOSER_SERVICE_ACCOUNT=$(gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.nodeConfig.serviceAccount)")
Tâche 3 : Créer les buckets Cloud Storage
Dans cette section, vous allez créer un ensemble de buckets Cloud Storage pour y stocker les éléments suivants :
- Artefacts des étapes intermédiaires du processus de compilation
- Fichiers d’entrée et de sortie du workflow de traitement des données
- Emplacement de préproduction des jobs Dataflow dans lequel stocker leurs fichiers binaires
Pour créer les buckets Cloud Storage, procédez comme suit :
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer les buckets Cloud Storage
Tâche 4 : Transférer le code source vers Cloud Source Repositories
Dans cet atelier, vous disposez d'un code base source que vous devez intégrer au contrôle des versions. L'étape suivante montre comment un code base est développé et évolue dans le temps. Chaque fois que des modifications sont transmises dans le dépôt, le pipeline à créer, déployer et tester est déclenché.
-
Dans Cloud Shell, transférez le dossier source-code dans Cloud Source Repositories :
gcloud source repos create $SOURCE_CODE_REPO
cp -r ~/ci-cd-for-data-processing-workflow/source-code ~/$SOURCE_CODE_REPO
cd ~/$SOURCE_CODE_REPO
git config --global credential.'https://source.developers.google.com'.helper gcloud.sh
git config --global user.email $(gcloud config list --format 'value(core.account)')
git config --global user.name $(gcloud config list --format 'value(core.account)')
git init
git remote add google \
https://source.developers.google.com/p/$GCP_PROJECT_ID/r/$SOURCE_CODE_REPO
git add .
git commit -m 'initial commit'
git push google master
Ces commandes standards permettent d'initialiser Git dans un nouveau répertoire et de transférer le contenu vers un dépôt distant.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Transférer le code source vers Cloud Source Repositories
Tâche 5 : Créer des pipelines Cloud Build
Dans cette section, vous allez créer les pipelines de compilation qui créent, déploient et testent le workflow de traitement des données.
Créer le pipeline de compilation et de test
Les étapes du pipeline de compilation et de test sont configurées dans le fichier de configuration YAML.
Dans cet atelier, vous allez utiliser des images de compilateur précompilées pour git, maven, gsutilet gcloud afin d'exécuter les tâches de chaque étape de compilation.
Vous allez utiliser des substitutions de variables de configuration pour définir les paramètres d'environnement au moment de la compilation. L'emplacement du dépôt contenant le code source est défini par les substitutions de variables, ainsi que par l'emplacement des buckets Cloud Storage. La compilation a besoin de ces informations pour déployer le fichier JAR, les fichiers de test et la définition du DAG.
-
Dans Cloud Shell, envoyez le fichier de configuration du pipeline de compilation pour créer le pipeline dans Cloud Build :
cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline
gcloud builds submit --config=build_deploy_test.yaml --substitutions=\
REPO_NAME=$SOURCE_CODE_REPO,\
_DATAFLOW_JAR_BUCKET=$DATAFLOW_JAR_BUCKET_TEST,\
_COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_TEST,\
_COMPOSER_REF_BUCKET=$REF_BUCKET_TEST,\
_COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\
_COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\
_COMPOSER_REGION=$COMPOSER_REGION,\
_COMPOSER_DAG_NAME_TEST=$COMPOSER_DAG_NAME_TEST
Cette commande indique à Cloud Build d’exécuter une compilation selon la procédure suivante :
-
Créer et déployer le fichier JAR WordCount auto-exécutable.
- Vérifier le code source.
- Compiler le code source Beam WordCount dans un fichier JAR auto-exécutable.
- Stocker le fichier JAR sur Cloud Storage où il peut être sélectionné par Cloud Composer pour exécuter le job de traitement WordCount.
-
Déployer et configurer le workflow de traitement des données sur Cloud Composer.
- Exécuter le test unitaire sur le code opérateur personnalisé utilisé par le DAG du workflow.
- Déployer le fichier d'entrée du test et le fichier de référence du test sur Cloud Storage. Le fichier d'entrée du test contient les données d'entrée du job de traitement WordCount. Le fichier de référence du test sert de référence pour vérifier le résultat du job de traitement WordCount.
- Définir les variables Cloud Composer de sorte qu'elles pointent vers le fichier JAR qui vient d'être créé.
- Déployer la définition du DAG du workflow dans l'environnement Cloud Composer.
-
Exécuter le workflow de traitement des données dans l'environnement de test pour déclencher le workflow de traitement de test.
Vérifier le pipeline de compilation et de test
Après avoir envoyé le fichier de compilation, vérifiez les étapes de compilation.
-
Dans Cloud Console, accédez à la page Historique de compilation pour afficher la liste de toutes les compilations précédentes et en cours d'exécution.
-
Cliquez sur la version en cours d'exécution.
-
Sur la page Informations sur le build, vérifiez que les étapes de compilation correspondent aux étapes décrites précédemment.
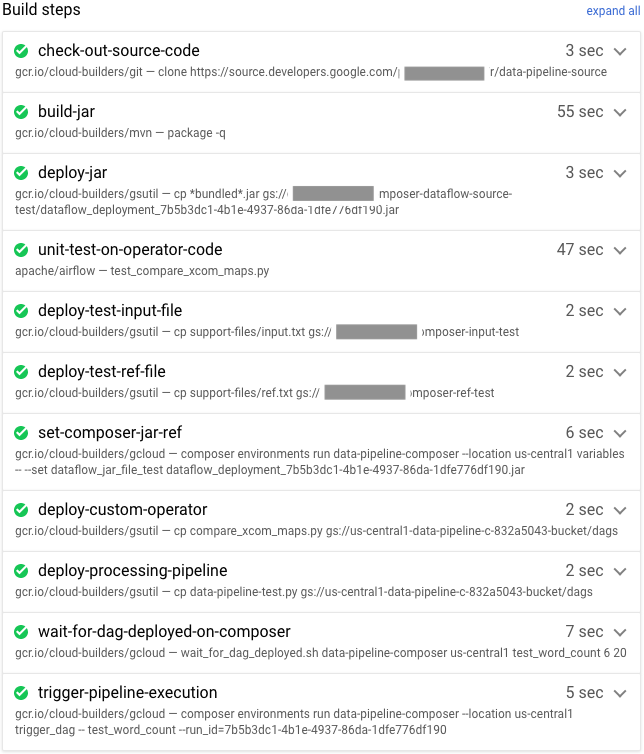
Sur la page Informations sur le build, le champ État du build indique Build successful (Build réussi) lorsque la compilation est terminée.
Remarque :
Si la compilation échoue, exécutez-la à nouveau.
-
Dans Cloud Shell, vérifiez que le fichier JAR de l'exemple WordCount a bien été copié dans le bucket approprié :
gsutil ls gs://$DATAFLOW_JAR_BUCKET_TEST/dataflow_deployment*.jar
Le résultat ressemble à ce qui suit :
gs://…-composer-dataflow-source-test/dataflow_deployment_e88be61e-50a6-4aa0-beac-38d75871757e.jar
-
Obtenez l'URL de votre interface Web Cloud Composer. Notez-la car elle sera utilisée à l'étape suivante.
gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.airflowUri)"
-
Utilisez l'URL de l'étape précédente pour accéder à l'interface utilisateur de Cloud Composer afin de vérifier que le DAG s'est correctement exécuté. Vous pouvez également cliquer sur le lien Serveur Web Airflow sur la page Composer. Si la colonne DAG Runs (Exécutions DAG) n’affiche aucune information, attendez quelques minutes, puis actualisez la page.
-
Pour vérifier que le DAG du workflow de traitement des données test_word_count est déployé et en cours d'exécution, maintenez le pointeur sur le cercle vert clair situé en dessous de DAG Runs (Exécutions du DAG) et vérifiez qu'il affiche Running (En cours d'exécution).
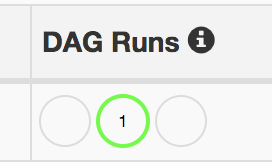
-
Pour afficher le workflow de traitement des données sous forme de graphique, cliquez sur le cercle vert clair, puis sur la page DAG Runs (Exécutions du DAG), et cliquez sur Dag Id: test_word_count (Id de Dag: test_word_count).
-
Actualisez la page Graph View (Vue graphique) pour mettre à jour l'état d'exécution du DAG en cours. L'exécution du workflow prend généralement entre trois et cinq minutes. Pour vous assurer que l'exécution du DAG s'effectue avec succès, maintenez le pointeur sur chaque tâche pour vérifier que l'info-bulle indique State: success (État : Opération réussie). La dernière tâche, appelée do_comparison, est le test d'intégration qui compare le résultat du processus au fichier de référence.
Remarque : Ignorez le problème lié à la tâche do_comparison ou publish_test_complete dans le DAG test_word_count si l'état de l'une de ces tâches est "Échec".
Si l'exécution du DAG échoue, déclenchez-en une autre en procédant comme suit :
- Sur la page des DAG, dans la ligne
test_word_count, cliquez sur Déclencher le DAG. 
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer des pipelines Cloud Build
Créer le pipeline de production
Lorsque le workflow de traitement de test s'exécute avec succès, vous pouvez faire passer la version actuelle du workflow en production. Il existe plusieurs manières de déployer le workflow en production :
- Manuellement
- Par déclenchement automatique lorsque tous les tests sont concluants dans les environnements de test ou de préproduction
- Par déclenchement automatique provoqué par un job planifié
Les méthodes automatiques n'entrent pas dans le cadre de cet atelier. Pour plus d'informations, consultez l'article consacré à l'Ingénierie des versions.
Dans cet atelier, vous allez effectuer un déploiement manuel en production en exécutant la version de déploiement de production Cloud Build. La version de déploiement de production suit les étapes ci-dessous :
- Copier le fichier JAR WordCount à partir du bucket de test dans le bucket de production.
- Définir les variables Cloud Composer du workflow de production pour pointer vers le fichier JAR récemment passé en production.
- Déployer la définition du DAG du workflow de production dans l'environnement Cloud Composer et exécuter le workflow.
Les substitutions de variables définissent le nom du dernier fichier JAR déployé en production avec les buckets Cloud Storage utilisés par le workflow de traitement de production. Pour créer le pipeline Cloud Build qui déploie le workflow Airflow de production, procédez comme suit :
-
Dans Cloud Shell, lisez le nom du dernier fichier JAR en imprimant la variable Cloud Composer correspondant au nom du fichier JAR :
export DATAFLOW_JAR_FILE_LATEST=$(gcloud composer environments run $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION variables \
-- \
get dataflow_jar_file_test | grep -i '.jar')
-
Utilisez le fichier de configuration du pipeline de compilation, deploy_prod.yaml, pour créer le pipeline dans Cloud Build :
cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline
gcloud builds submit --config=deploy_prod.yaml --substitutions=\
REPO_NAME=$SOURCE_CODE_REPO,\
_DATAFLOW_JAR_BUCKET_TEST=$DATAFLOW_JAR_BUCKET_TEST,\
_DATAFLOW_JAR_FILE_LATEST=$DATAFLOW_JAR_FILE_LATEST,\
_DATAFLOW_JAR_BUCKET_PROD=$DATAFLOW_JAR_BUCKET_PROD,\
_COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_PROD,\
_COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\
_COMPOSER_REGION=$COMPOSER_REGION,\
_COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\
_COMPOSER_DAG_NAME_PROD=$COMPOSER_DAG_NAME_PROD
Vérifier le workflow de traitement des données créé par le pipeline de production
-
Obtenez l'URL de votre interface utilisateur Cloud Composer :
gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.airflowUri)"
-
Pour vérifier que le DAG du workflow de traitement des données en production est déployé, accédez à l'URL que vous avez récupérée à l'étape précédente et vérifiez que le DAG prod_word_count figure dans la liste des DAG.
-
Sur la page des DAG, dans la ligne prod_word_count, cliquez sur Déclencher le DAG.
-
Actualisez la page pour mettre à jour l'état d'exécution du DAG. Pour vérifier que le DAG du workflow de traitement des données en production est déployé et en cours d'exécution, maintenez le pointeur sur le cercle vert clair situé en dessous de Exécutions DAG et vérifiez qu'il affiche l'état En cours d'exécution.
-
Une fois l'exécution réussie, maintenez le pointeur sur le cercle vert foncé situé sous la colonne Exécutions DAG et vérifiez qu'il affiche l'état Opération réussie.
-
Dans Cloud Shell, répertoriez les fichiers de résultats dans le bucket Cloud Storage :
gsutil ls gs://$RESULT_BUCKET_PROD
Le résultat ressemble à ce qui suit :
gs://…-composer-result-prod/output-00000-of-00003
gs://…-composer-result-prod/output-00001-of-00003
gs://…-composer-result-prod/output-00002-of-00003
Remarque : L'exécution des jobs de workflow de données en production est généralement déclenchée par des événements, tels que le stockage de fichiers dans des buckets. Elle peut également être planifiée de façon régulière. Il est important que le job de déploiement vérifie que le workflow de données en production n'est pas en cours d'exécution avant le déploiement.
Dans un environnement de production, vous pouvez utiliser dags avec l'une des commandes CLI Airflow, pour récupérer l'état d'exécution d'un DAG.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer le pipeline de production
Tâche 6 : Configurer un déclencheur de compilation
Vous allez configurer un déclencheur Cloud Build qui déclenche une nouvelle compilation lorsque les modifications sont envoyées dans la branche principale du dépôt source.
-
Dans Cloud Shell, exécutez la commande suivante pour obtenir toutes les variables de substitution nécessaires à la compilation. Notez ces valeurs car vous en aurez besoin ultérieurement.
echo "_DATAFLOW_JAR_BUCKET : ${DATAFLOW_JAR_BUCKET_TEST}
_COMPOSER_INPUT_BUCKET : ${INPUT_BUCKET_TEST}
_COMPOSER_REF_BUCKET : ${REF_BUCKET_TEST}
_COMPOSER_DAG_BUCKET : ${COMPOSER_DAG_BUCKET}
_COMPOSER_ENV_NAME : ${COMPOSER_ENV_NAME}
_COMPOSER_REGION : ${COMPOSER_REGION}
_COMPOSER_DAG_NAME_TEST : ${COMPOSER_DAG_NAME_TEST}"
-
Dans la console Cloud, accédez à la page Déclencheurs de compilation : Page "Déclencheurs de compilation".
-
Cliquez sur Créer un déclencheur.
-
Pour configurer les paramètres du déclencheur, procédez comme suit :
- Dans le champ Nom, saisissez
Trigger build in test environment.
- Pour Événement, cliquez sur Déployer sur une branche.
- Sélectionnez le dépôt
data-pipeline-source (Cloud Source Repositories).
- Sélectionnez
^master$ pour le champ Branche et saisissez.
- Dans le champ Configuration, cliquez sur Fichier de configuration Cloud Build (YAML ou JSON).
- Dans le champ Emplacement du fichier de configuration Cloud Build, saisissez
build-pipeline/build_deploy_test.yaml.
-
Dans le champ Avancé, remplacez les variables par les valeurs correspondant à votre environnement, que vous avez obtenues à l'étape précédente. Ajoutez les éléments suivants un à un, puis cliquez sur +AJOUTER UNE VARIABLE pour chaque paire nom-valeur.
-
_DATAFLOW_JAR_BUCKET
-
_COMPOSER_INPUT_BUCKET
-
_COMPOSER_REF_BUCKET
-
_COMPOSER_DAG_BUCKET
-
_COMPOSER_ENV_NAME
-
_COMPOSER_REGION
-
_COMPOSER_DAG_NAME_TEST
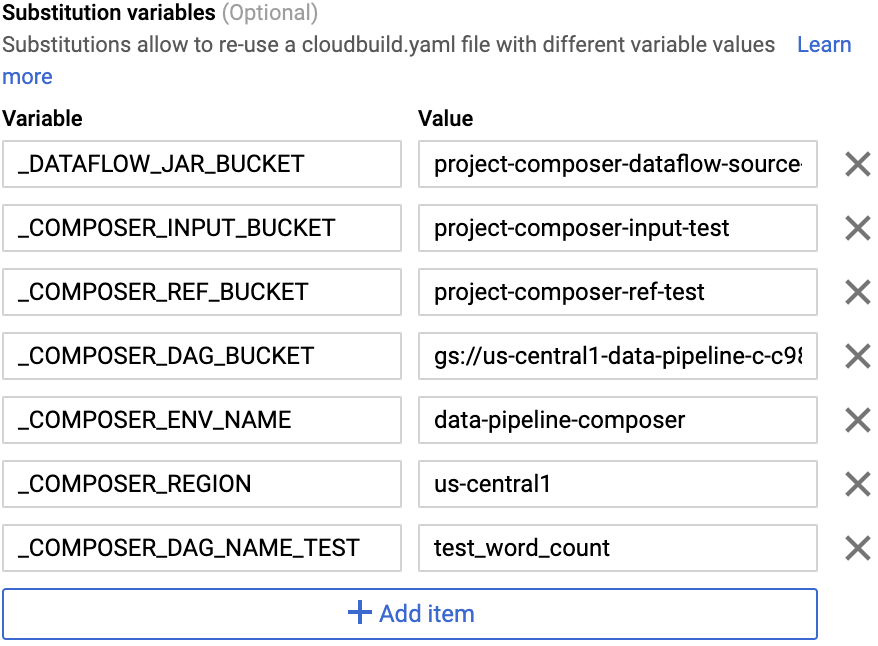
-
Dans le champ Compte de service, sélectionnez xxxxxxx-compute@developer.gserviceaccount.com.
-
Cliquez sur Créer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Configurer un déclencheur de compilation
Tester le déclencheur
Pour tester le déclencheur, vous devez ajouter un mot dans le fichier d'entrée de test et apporter la modification correspondante dans le fichier de référence de test. Vous allez vérifier que le pipeline de compilation est déclenché par l'envoi d'un commit dans Cloud Source Repositories et que le workflow de traitement des données s'exécute correctement avec les fichiers de test mis à jour.
-
Dans Cloud Shell, ajoutez un mot test à la fin du fichier de test :
echo "testword" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/input.txt
-
Mettez à jour le fichier de référence des résultats de test, ref.txt, en fonction des modifications apportées au fichier d'entrée de test :
echo "testword: 1" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/ref.txt
-
Validez les modifications et déployez-les sur Cloud Source Repositories.
cd ~/$SOURCE_CODE_REPO
git add .
git commit -m 'change in test files'
git push google master
-
Dans la console Cloud, accédez à la page Historique : page "Historique".
-
Pour confirmer qu'une nouvelle compilation est déclenchée par l'envoi précédent dans la branche principale, la colonne Déclencheur de la compilation en cours d'exécution indique Push to master branch (Envoi vers la branche principale).
-
Dans Cloud Shell, obtenez l'URL de votre interface Web Cloud Composer :
gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION --format="get(config.airflowUri)"
-
Une fois la compilation terminée, accédez à l'URL utilisée dans la commande précédente pour vérifier que le DAG test_word_count est en cours d'exécution.
Attendez la fin de l'exécution du DAG. Elle est signalée par la disparition du cercle vert clair de la colonne DAG runs (Exécutions du DAG). Cela prend généralement entre trois et cinq minutes.
Remarque : Ignorez le problème lié à la tâche do_comparison dans le DAG test_word_count.
-
Dans Cloud Shell, téléchargez les fichiers de résultats du test :
mkdir ~/result-download
cd ~/result-download
gsutil cp gs://$RESULT_BUCKET_TEST/output* .
-
Vérifiez que le mot que vous venez d'ajouter figure dans l'un des fichiers de résultats :
grep testword output*
Le résultat ressemble à ce qui suit :
output-00000-of-00003:testword: 1
Cliquez sur Vérifier ma progression pour valider l'objectif.
Tester le déclencheur
Félicitations
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
- 1 étoile = très insatisfait(e)
- 2 étoiles = insatisfait(e)
- 3 étoiles = ni insatisfait(e), ni satisfait(e)
- 4 étoiles = satisfait(e)
- 5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.