Descripción general
En este lab, configurarás una canalización de integración continua/implementación
continua (CI/CD) para procesar datos implementando métodos
de CI/CD con productos administrados en Google Cloud. Los científicos y
los ingenieros de datos pueden adaptar las metodologías de las prácticas de CI/CD para garantizar la
alta calidad, la capacidad de mantenimiento y la adaptabilidad de los procesos de datos y
los flujos de trabajo. A continuación, se incluyen los métodos que puedes aplicar:
- Control de versión del código fuente
- Compilación, prueba e implementación automática de apps
- Aislamiento del entorno y separación de la producción
- Procedimientos replicables para la configuración del entorno
Arquitectura de implementación
En este lab, usarás los siguientes productos de Google Cloud:
- Usarás Cloud Build cuando crees una canalización de CI/CD para compilar, implementar y probar un flujo de trabajo de procesamiento de datos y el procesamiento de datos en sí.
Cloud Build es un servicio administrado que ejecuta la compilación en Google Cloud. Una compilación es una serie de pasos de compilación en la que cada paso se ejecuta en un contenedor de Docker.
- Usarás Cloud Composer
para definir y ejecutar los pasos del flujo de trabajo, como el inicio del procesamiento
de datos, la prueba y la verificación de los resultados. Cloud Composer es un servicio administrado de
Apache Airflow
que ofrece un entorno en el que puedes crear, programar, supervisar
y administrar flujos de trabajo complejos, como el flujo de trabajo de procesamiento de datos de este
lab.
- Usarás Dataflow para ejecutar el ejemplo WordCount de Apache Beam como un proceso de datos de muestra.
Configuración y requisitos
En cada lab, recibirás un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
-
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá una ventana emergente para que selecciones tu forma de pago.
A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón Abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debes usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordena las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta.
-
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}}
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}}
También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud.
Nota: Usar tu propia cuenta de Google Cloud para este lab podría generar cargos adicionales.
-
Haga clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.
Nota: Para ver un menú con una lista de productos y servicios de Google Cloud, haz clic en el menú de navegación que se encuentra en la parte superior izquierda o escribe el nombre del servicio o producto en el campo Búsqueda.

Activa Google Cloud Shell
Google Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud.
Google Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
-
En la consola de Cloud, en la barra de herramientas superior derecha, haz clic en el botón Abrir Cloud Shell.

-
Haz clic en Continuar.
El aprovisionamiento y la conexión al entorno demorarán unos minutos. Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu PROJECT_ID. Por ejemplo:

gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con el completado de línea de comando.
- Puedes solicitar el nombre de la cuenta activa con este comando:
gcloud auth list
Resultado:
Credentialed accounts:
- @.com (active)
Resultado de ejemplo:
Credentialed accounts:
- google1623327_student@qwiklabs.net
- Puedes solicitar el ID del proyecto con este comando:
gcloud config list project
Resultado:
[core]
project =
Resultado de ejemplo:
[core]
project = qwiklabs-gcp-44776a13dea667a6
Nota:
La documentación completa de gcloud está disponible en la
guía de descripción general de gcloud CLI
.
La canalización de CI/CD
En un nivel alto, la canalización de IC/EC consta de los pasos siguientes:
- Cloud Build empaqueta la muestra de WordCount en un Archivo Java (JAR) de ejecución automática con el compilador de Maven.
El compilador de Maven es un contenedor con Maven instalado. Cuando se configura un paso de compilación para usar el compilador de Maven, este ejecuta las tareas.
- Cloud Build sube el archivo JAR a Cloud Storage.
- Cloud Build ejecuta pruebas de unidades en el código del flujo de trabajo de procesamiento de datos
y, luego, implementa el código del flujo de trabajo en Cloud Composer.
- Cloud Composer reconoce el archivo JAR y ejecuta el trabajo de procesamiento de datos en Dataflow.
En el siguiente diagrama, se muestra una vista detallada de los pasos de la canalización de CI/CD.
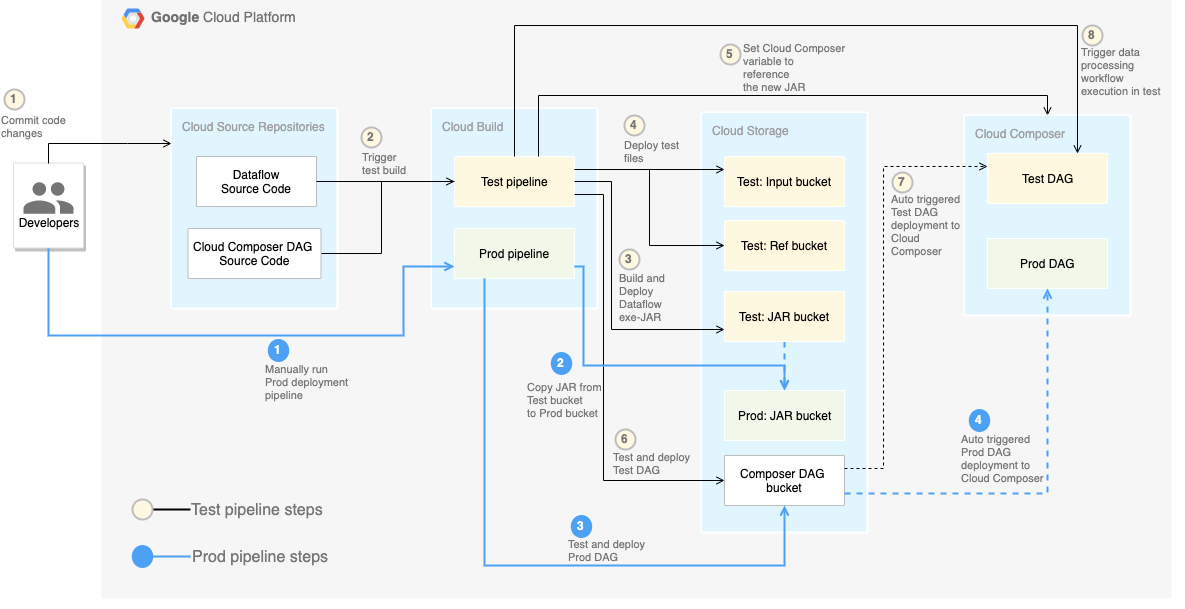
En este lab, las implementaciones en los entornos de prueba y producción
se separan en dos canalizaciones de Cloud Build diferentes: una de prueba y una
de producción.
En el diagrama anterior, la canalización de prueba consta de los siguientes pasos:
- Un desarrollador confirma los cambios de código en Cloud Source Repositories.
- Los cambios de código activan una compilación de prueba en Cloud Build.
- Cloud Build compila el archivo JAR de ejecución automática y lo implementa en el bucket de JAR de prueba en Cloud Storage.
- Cloud Build implementa los archivos de prueba en los buckets de archivos de prueba en Cloud Storage.
- Cloud Build establece la variable en Cloud Composer para hacer referencia al archivo JAR recién implementado.
- Cloud Build prueba el flujo de trabajo de procesamiento de datos
grafo acíclico dirigido
(DAG) y lo implementa en el bucket de Cloud Composer en
Cloud Storage.
- El archivo DAG de flujo de trabajo se implementa en Cloud Composer.
- Cloud Build activa el flujo de trabajo de procesamiento de datos recién
implementado para su ejecución.
Para separar por completo los entornos, necesitas varios entornos de Cloud Composer creados en proyectos diferentes, que están separados de forma predeterminada. Esta separación ayuda a proteger el entorno de producción. Este
método no se analiza en este lab. Si quieres obtener más información para acceder a los recursos en varios proyectos de Google Cloud, consulta Configura los permisos de la cuenta de servicio.
El flujo de trabajo de procesamiento de datos
Las instrucciones que indican cómo Cloud Composer ejecuta el flujo de trabajo
de procesamiento de datos se definen en un
grafo acíclico dirigido
(DAG) escrito en Python. En el DAG, todos los pasos del flujo de trabajo de procesamiento de datos se definen junto con las dependencias entre ellos.
La canalización de CI/CD implementa de forma automática la definición de DAG de Cloud Source Repositories en Cloud Composer en cada compilación. Este proceso garantiza que Cloud Composer siempre esté actualizado con la última definición del flujo de trabajo sin necesidad de intervención humana.
En la definición de DAG para el entorno de prueba, se define un paso de prueba de extremo a extremo, además del flujo de trabajo de procesamiento de datos. El paso de prueba ayuda a garantizar que el
flujo de trabajo de procesamiento de datos se ejecute de forma correcta.
El flujo de trabajo de procesamiento de datos se ilustra en el siguiente diagrama.
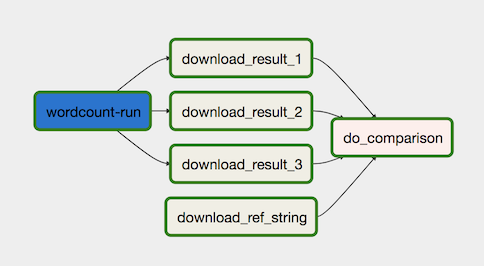
El flujo de trabajo de procesamiento de datos consta de los pasos siguientes:
-
Ejecuta el proceso de datos de WordCount en Dataflow.
-
Descarga los archivos de salida del proceso WordCount. El proceso WordCount genera tres archivos:
download_result_1download_result_2download_result_3
-
Descarga el archivo de referencia, llamado download_ref_string.
-
Verifica el resultado con el archivo de referencia. Esta prueba de integración agrupa los tres resultados y compara todos los resultados con el archivo de referencia.
El uso de un framework de organización de tareas como Cloud Composer para administrar el flujo de trabajo de procesamiento de datos ayuda a disminuir la complejidad del código del flujo de trabajo.
Las pruebas
Además de la prueba de integración que verifica el flujo de trabajo de procesamiento de datos
de extremo a extremo, hay dos pruebas de unidades en este lab. Las pruebas de unidades son
pruebas automáticas en el código de procesamiento de datos y el código del flujo de trabajo
de procesamiento de datos. La prueba en el código de procesamiento de datos se escribe en Java y se ejecuta de forma automática durante el proceso de compilación de Maven. La prueba en el código del flujo de trabajo de procesamiento de datos se escribe en Python y se ejecuta como un paso de compilación independiente.
Código de muestra
El código de muestra está en dos carpetas:
-
La carpeta env-setup contiene secuencias de comandos de shell para la configuración inicial
del entorno de Google Cloud.
-
La carpeta source-code contiene código que se desarrolla a lo largo del tiempo,
debe controlarse a través del código fuente y activa procesos automáticos de compilación
y prueba. Esta carpeta contiene las siguientes subcarpetas:
- La carpeta
data-processing-code contiene el código fuente del proceso de
Apache Beam.
- La carpeta
workflow-dag contiene las definiciones de DAG del compositor
correspondiente a los flujos de trabajo de procesamiento de datos con los pasos para diseñar, implementar
y probar el proceso de Dataflow.
- La carpeta
build-pipeline contiene dos opciones de configuración de Cloud Build:
una destinada a la canalización de prueba y otra a la
canalización de producción. Esta carpeta también contiene una secuencia de comandos de compatibilidad para las canalizaciones.
A los fines de este lab, los archivos de código fuente para el procesamiento de datos y
el flujo de trabajo de DAG se encuentran en diferentes carpetas en el mismo repositorio de código fuente.
En un entorno de producción, los archivos de código fuente suelen estar en sus propios
repositorios de código fuente y los administran equipos diferentes.
Tarea 1. Configura tu entorno
En este instructivo, ejecutarás todos los comandos en
Cloud Shell.
Cloud Shell aparece como una ventana en la parte inferior de la consola de Google Cloud.
-
En la consola de Cloud, abre Cloud Shell.
-
Clona el repositorio de código de muestra:
git clone https://github.com/GoogleCloudPlatform/ci-cd-for-data-processing-workflow.git
-
Navega al directorio que contenga los archivos de muestra de este lab:
cd ~/ci-cd-for-data-processing-workflow/env-setup
-
Actualiza la región en el archivo set_env.sh con el comando sed.
sed -i "s/us-central1-a/{{{project_0.default_zone|Zone}}}/g" set_env.sh
sed -i "s/us-central1/{{{project_0.default_region|Region}}}/g" set_env.sh
-
Ejecuta una secuencia de comandos para establecer variables de entorno:
source set_env.sh
La secuencia de comandos establece las siguientes variables de entorno:
- El ID del proyecto de Google Cloud
- La región y la zona
- El nombre de los buckets de Cloud Storage que usan la canalización de compilación y el flujo de trabajo de procesamiento de datos
Debido a que las variables de entorno no se conservan entre sesiones, si la
sesión de Cloud Shell se cierra o se desconecta mientras trabajas en el lab, deberás restablecer
las variables de entorno.
-
Agrega la opción de registro al archivo yaml:
echo -e "\noptions:\n logging: CLOUD_LOGGING_ONLY" >> ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline/build_deploy_test.yaml
-
Actualiza la secuencia de comandos de la canalización:
sed -i 's/project=project/project_id=project/' ~/ci-cd-for-data-processing-workflow/source-code/workflow-dag/data-pipeline-test.py
Tarea 2. Crea el entorno de Cloud Composer
Asegúrate de que la API de Cloud Composer esté habilitada correctamente
Para garantizar el acceso a las APIs necesarias, reinicia la conexión a la API de Cloud Composer.
-
En la consola de Google Cloud, en la barra de búsqueda superior, ingresa API de Cloud Composer. Luego, haz clic en el resultado de la API de Cloud Composer.
-
Haz clic en Administrar.
-
Haz clic en Inhabilitar API.
Si se te solicita confirmar, haz clic en Inhabilitar.
- Haz clic en Habilitar.
Cuando se haya habilitado de nuevo la API, se mostrará en la página la opción para inhabilitarla.
Crea un entorno de Cloud Composer
-
En Cloud Shell, ejecuta el siguiente comando para crear un entorno de Cloud Composer:
gcloud composer environments create $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--image-version composer-3-airflow-2
Nota: Por lo general, el comando tarda unos 15 minutos en completar la creación del entorno de Cloud Composer. Espera a que Composer esté listo antes de continuar.
Cuando el comando se complete, puedes verificarlo en Google Cloud.
-
Ejecuta una secuencia de comandos para configurar las variables en el entorno de Cloud Composer. Las variables se necesitan en los DAG de procesamiento de datos.
cd ~/ci-cd-for-data-processing-workflow/env-setup
chmod +x set_composer_variables.sh
./set_composer_variables.sh
La secuencia de comandos establece las siguientes variables de entorno:
- El ID del proyecto de Google Cloud
- La región y la zona
- El nombre de los buckets de Cloud Storage que usan la canalización de compilación y el flujo de trabajo de procesamiento de datos
Extrae las propiedades del entorno de Cloud Composer
Cloud Composer usa un bucket de Cloud Storage para almacenar los DAG.
Si mueves un archivo de definición de DAG al bucket, se activará Cloud Composer para leer los archivos de forma automática. Creaste el bucket de Cloud Storage para Cloud Composer cuando creaste el entorno de Cloud Composer.
En el procedimiento siguiente, debes extraer la URL de los buckets y, luego, configurar la canalización de CI/CD para implementar definiciones de DAG en el bucket de Cloud Storage de forma automática.
-
En Cloud Shell, exporta la URL del bucket como una variable de entorno:
export COMPOSER_DAG_BUCKET=$(gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.dagGcsPrefix)")
-
Exporta el nombre de la cuenta de servicio que usa Cloud Composer para tener acceso a los buckets de Cloud Storage:
export COMPOSER_SERVICE_ACCOUNT=$(gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.nodeConfig.serviceAccount)")
Tarea 3. Crea los buckets de Cloud Storage
En esta sección, crearás un conjunto de buckets de Cloud Storage para almacenar los siguientes
elementos:
- Los artefactos de los pasos intermedios del proceso de compilación
- Los archivos de entrada y salida para el flujo de trabajo de procesamiento de datos
- La ubicación de etapa de pruebas para que los trabajos de Dataflow almacenen los archivos binarios
Para crear los depósitos de Cloud Storage, completa el siguiente paso:
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear los buckets de Cloud Storage
Tarea 4. Envía el código fuente a Cloud Source Repositories
En este lab, tienes una base de código fuente que debes poner en el
control de versiones. En el siguiente paso, se muestra cómo se desarrolla y se cambia una base de código con el tiempo. Cada vez que se envían cambios al repositorio, se activa la canalización para compilar, implementar y probar.
-
En Cloud Shell, envía la carpeta source-code a
Cloud Source Repositories:
gcloud source repos create $SOURCE_CODE_REPO
cp -r ~/ci-cd-for-data-processing-workflow/source-code ~/$SOURCE_CODE_REPO
cd ~/$SOURCE_CODE_REPO
git config --global credential.'https://source.developers.google.com'.helper gcloud.sh
git config --global user.email $(gcloud config list --format 'value(core.account)')
git config --global user.name $(gcloud config list --format 'value(core.account)')
git init
git remote add google \
https://source.developers.google.com/p/$GCP_PROJECT_ID/r/$SOURCE_CODE_REPO
git add .
git commit -m 'initial commit'
git push google master
Estos son comandos estándar para inicializar Git en un directorio nuevo y enviar el contenido a un repositorio remoto.
Haz clic en Revisar mi progreso para verificar el objetivo.
Enviar el código fuente a Cloud Source Repositories
Tarea 5. Crea canalizaciones de Cloud Build
En esta sección, crearás las canalizaciones de compilación con las que se compila, implementa y prueba
el flujo de trabajo de procesamiento de datos.
Crea la canalización de compilación y prueba
Los pasos de canalización de compilación y prueba se configuran en el archivo de configuración YAML.
En este lab, usarás
imágenes de compiladores
ya compiladas para git, maven, gsutil y gcloud para ejecutar las tareas en cada paso de la compilación.
Usa las sustituciones de la variable de configuración para definir la configuración del entorno en el momento de la compilación. La ubicación del repositorio de código fuente se define mediante sustituciones de variables, al igual que las ubicaciones de los buckets de Cloud Storage. La compilación necesita esta información para implementar el
archivo JAR, los archivos de prueba y la definición de DAG.
-
En Cloud Shell, envía el archivo de configuración de canalización de compilación
para crear la canalización en Cloud Build:
cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline
gcloud builds submit --config=build_deploy_test.yaml --substitutions=\
REPO_NAME=$SOURCE_CODE_REPO,\
_DATAFLOW_JAR_BUCKET=$DATAFLOW_JAR_BUCKET_TEST,\
_COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_TEST,\
_COMPOSER_REF_BUCKET=$REF_BUCKET_TEST,\
_COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\
_COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\
_COMPOSER_REGION=$COMPOSER_REGION,\
_COMPOSER_DAG_NAME_TEST=$COMPOSER_DAG_NAME_TEST
Este comando le indica a Cloud Build que ejecute una compilación con los siguientes pasos:
-
Compilación e implementación del archivo JAR de ejecución automática de WordCount
- Consultar el código fuente
- Compilar el código fuente de WordCount Beam en un archivo JAR de ejecución automática
- Almacenar el archivo JAR en Cloud Storage, donde Cloud Composer
lo puede captar para ejecutar el trabajo de procesamiento de
WordCount
-
Implementación y configuración del flujo de trabajo de procesamiento de datos en Cloud Composer
- Ejecutar la prueba de unidades en el código de operador personalizado que usa el DAG del flujo de trabajo
- Implementar el archivo de entrada de prueba y el archivo de referencia de prueba en
Cloud Storage. El archivo de entrada de prueba es la entrada para el trabajo de procesamiento de WordCount. El archivo de referencia de prueba se usa como referencia para verificar el resultado del trabajo de procesamiento de WordCount
- Configurar las variables de Cloud Composer para que apunten al archivo JAR recién compilado
- Implementar la definición de DAG del flujo de trabajo en el entorno de Cloud Composer
-
Ejecutar el flujo de trabajo de procesamiento de datos en el entorno de prueba para activar el
flujo de trabajo de procesamiento de pruebas
Verifica la compilación y la canalización de prueba
Después de enviar el archivo de compilación, verifica los pasos de compilación.
-
En la consola de Cloud, ve a la página Historial de compilaciones para ver una lista de todas las compilaciones anteriores y en ejecución.
-
Haz clic en la compilación que ahora esté en ejecución.
-
En la página Detalles de compilación, verifica que los pasos de compilación coincidan con los pasos descritos antes.
En la página Detalles de compilación, el campo Estado de la compilación muestra el mensaje
Se realizó correctamente la compilación cuando esta finaliza.
Nota:
Si la compilación falla, vuelve a ejecutarla una vez más.
-
En Cloud Shell, verifica que el archivo JAR de muestra de WordCount se haya copiado
en el bucket correcto:
gsutil ls gs://$DATAFLOW_JAR_BUCKET_TEST/dataflow_deployment*.jar
El resultado es similar a este:
gs://…-composer-dataflow-source-test/dataflow_deployment_e88be61e-50a6-4aa0-beac-38d75871757e.jar
-
Obtén la URL de tu interfaz web de Cloud Composer. Toma nota
de la URL porque la usarás en el siguiente paso.
gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.airflowUri)"
-
Usa la URL del paso anterior para ir a la IU de Cloud Composer y verificar la ejecución exitosa del DAG. También puedes hacer clic en el vínculo de Airflow Webserver desde la página Composer. Si en la columna Ejecuciones de Dag (DAG Runs) no
se muestra información, espera unos minutos y vuelve a cargar la página.
-
Para verificar que el
test_word_count del DAG del flujo de trabajo de procesamiento de datos se implemente y esté en modo de ejecución, mantén el cursor
sobre el círculo verde claro bajo Ejecuciones de DAG y verifica que diga
En ejecución.
-
Para ver el flujo de trabajo del procesamiento de datos en ejecución como un gráfico, haz clic
en el círculo verde claro y, luego, en la página Ejecuciones de DAG, haz clic en ID
de DAG: test_word_count.
-
Vuelve a cargar la página Vista de gráfico para actualizar el estado de la ejecución de DAG actual. Por lo general, el flujo de trabajo toma entre tres y cinco minutos en completarse. Para verificar que la ejecución de DAG finalice de manera correcta, mantén el cursor sobre cada tarea de modo que puedas verificar que el cuadro de información indique Estado: finalizado. La última tarea, llamada do_comparison, es la
prueba de integración que verifica el resultado del proceso con el archivo de
referencia.
Nota: Si ves que el estado aparece con errores, ignora el problema de la tarea do_comparison o publish_test_complete en el DAG test_word_count.
Si la ejecución del DAG falla, activa otra ejecución siguiendo estos pasos:
- En la página DAG, en la fila
test_word_count, haz clic en Activar DAG. 
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear canalizaciones de Cloud Build
Crea la canalización de producción
Cuando el flujo de trabajo de procesamiento de pruebas se ejecute de forma correcta, podrás cambiar la versión actual del flujo de trabajo a producción. Existen varias formas de implementar el flujo de trabajo en producción:
- De forma manual
- De forma automática cuando todas las pruebas se aprueban en los entornos de prueba o de etapa de pruebas
- De forma automática mediante un trabajo programado
Los métodos automáticos no se analizan en este lab. Para obtener más
información, consulta
Ingeniería de lanzamiento.
En este lab, realizarás una implementación manual en producción ejecutando la
compilación de implementación de producción de Cloud Build. La compilación de la implementación de producción sigue estos pasos:
- Se copia el archivo JAR de WordCount del bucket de prueba en el bucket de producción.
- Se configuran las variables de Cloud Composer para que el flujo de trabajo de producción apunte al archivo JAR recién cambiado.
- Se implementa la definición de DAG del flujo de trabajo de producción en el entorno de Cloud Composer y se ejecuta el flujo de trabajo.
Con las sustituciones de variables, se define el nombre del último archivo JAR que se implementa en producción con los buckets de Cloud Storage que usa el flujo de trabajo de procesamiento de producción. Para crear la canalización de Cloud Build que implementa el flujo de trabajo de producción de Airflow, completa los siguientes pasos:
-
En Cloud Shell, imprime la variable de Cloud Composer
para el nombre de archivo JAR y así poder leer el nombre del archivo JAR más reciente:
export DATAFLOW_JAR_FILE_LATEST=$(gcloud composer environments run $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION variables \
-- \
get dataflow_jar_file_test | grep -i '.jar')
-
Usa el archivo de configuración de la canalización de compilación, deploy_prod.yaml, para
crear la canalización en Cloud Build:
cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline
gcloud builds submit --config=deploy_prod.yaml --substitutions=\
REPO_NAME=$SOURCE_CODE_REPO,\
_DATAFLOW_JAR_BUCKET_TEST=$DATAFLOW_JAR_BUCKET_TEST,\
_DATAFLOW_JAR_FILE_LATEST=$DATAFLOW_JAR_FILE_LATEST,\
_DATAFLOW_JAR_BUCKET_PROD=$DATAFLOW_JAR_BUCKET_PROD,\
_COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_PROD,\
_COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\
_COMPOSER_REGION=$COMPOSER_REGION,\
_COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\
_COMPOSER_DAG_NAME_PROD=$COMPOSER_DAG_NAME_PROD
Verifica el flujo de trabajo de procesamiento de datos que creó la canalización de producción
-
Obtén la URL de la IU de Cloud Composer:
gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION \
--format="get(config.airflowUri)"
-
Para verificar que el DAG del flujo de trabajo de procesamiento de datos de producción esté implementado,
visita la URL que recuperaste en el paso anterior y verifica que el DAG
prod_word_count esté en la lista correspondiente.
-
En la página DAG, en la fila prod_word_count, haz clic en Activar DAG.
-
Vuelve a cargar la página para actualizar el estado de ejecución del DAG. Para verificar que el DAG del flujo de trabajo de procesamiento de datos de producción esté implementado y en modo de ejecución, mantén el cursor sobre el círculo verde claro bajo Ejecuciones de DAG (DAG Runs) y verifica que indique En ejecución.
-
Después de que la ejecución se realice con éxito, mantén el cursor sobre el círculo verde oscuro debajo de la columna Ejecuciones de DAG y verifica que indique Finalizado.
-
En Cloud Shell, enumera los archivos de resultados en el bucket de Cloud Storage:
gsutil ls gs://$RESULT_BUCKET_PROD
El resultado es similar a este:
gs://…-composer-result-prod/output-00000-of-00003
gs://…-composer-result-prod/output-00001-of-00003
gs://…-composer-result-prod/output-00002-of-00003
Nota: Por lo general, la ejecución del trabajo de flujo de datos de producción se
activa a través de eventos, como el almacenamiento de archivos en buckets, o se programa para ejecutarse de forma periódica. Es importante que el trabajo de implementación garantice que el flujo de trabajo de datos de producción no se ejecute antes de la implementación.
En un entorno de producción, puedes usar los DAG de los comandos de la CLI de Airflow para recuperar el estado de una ejecución de DAG.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crear la canalización de producción
Tarea 6: Configura un activador de compilación
Configura un activador de Cloud Build que active una compilación nueva cuando los cambios se envíen a la rama principal del repositorio de código fuente.
-
En Cloud Shell, ejecuta el siguiente comando y obtén todas las variables de sustitución necesarias para la compilación. Toma nota de estos valores, porque los necesitará en un paso posterior.
echo "_DATAFLOW_JAR_BUCKET : ${DATAFLOW_JAR_BUCKET_TEST}
_COMPOSER_INPUT_BUCKET : ${INPUT_BUCKET_TEST}
_COMPOSER_REF_BUCKET : ${REF_BUCKET_TEST}
_COMPOSER_DAG_BUCKET : ${COMPOSER_DAG_BUCKET}
_COMPOSER_ENV_NAME : ${COMPOSER_ENV_NAME}
_COMPOSER_REGION : ${COMPOSER_REGION}
_COMPOSER_DAG_NAME_TEST : ${COMPOSER_DAG_NAME_TEST}"
-
En la consola de Cloud, ve a la página Activadores de compilación: Página Activadores de compilación.
-
Haz clic en Crear activador.
-
Para establecer la configuración del activador, sigue estos pasos:
- En el campo Nombre, ingresa
Trigger build in test environment.
- En Evento, haz clic en Enviar a una rama.
- Selecciona el repositorio como
data-pipeline-source (Cloud Source Repositories).
- Selecciona el campo Rama como
^master$.
- En Configuración, haz clic en Archivo
de configuración de Cloud Build (YAML o JSON).
- En el campo Ubicación del archivo de configuración de Cloud Build, ingresa
build-pipeline/build_deploy_test.yaml.
-
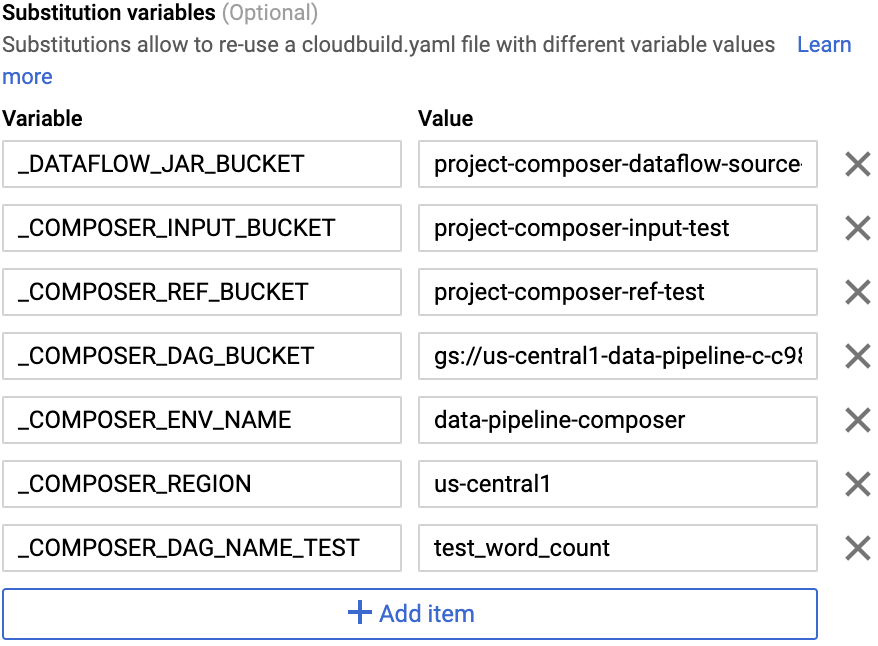
En el campo Avanzado, reemplaza las
variables por los valores del entorno que obtuviste en el paso
anterior. Agrega lo siguiente una por vez y haz clic en + AGREGAR VARIABLE para cada
par nombre-valor.
-
_DATAFLOW_JAR_BUCKET
-
_COMPOSER_INPUT_BUCKET
-
_COMPOSER_REF_BUCKET
-
_COMPOSER_DAG_BUCKET
-
_COMPOSER_ENV_NAME
-
_COMPOSER_REGION
-
_COMPOSER_DAG_NAME_TEST
-
En Cuenta de servicio, selecciona xxxxxxx-compute@developer.gserviceaccount.com.
-
Haz clic en Crear.
Haz clic en Revisar mi progreso para verificar el objetivo.
Configurar un activador de compilación
Prueba el activador
Para probar el activador, agrega una palabra nueva al archivo de entrada de prueba y realiza el ajuste correspondiente en el archivo de referencia de prueba. Verifica que la canalización de compilación se active mediante un envío de confirmación a Cloud Source Repositories y que el flujo de trabajo de procesamiento de datos se ejecute de forma correcta con los archivos de prueba actualizados.
-
En Cloud Shell, agrega una palabra de prueba al final del archivo de prueba:
echo "testword" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/input.txt
-
Actualiza el archivo de referencia de resultados de prueba, ref.txt, para que coincida con los cambios
realizados en el archivo de entrada de prueba:
echo "testword: 1" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/ref.txt
-
Confirma y envía cambios a Cloud Source Repositories:
cd ~/$SOURCE_CODE_REPO
git add .
git commit -m 'change in test files'
git push google master
-
En la consola de Cloud, ve a la página Historial: Página Historial.
-
Para verificar que una compilación nueva se active a través del envío anterior a la rama principal, en la compilación que está ahora en ejecución, la columna Activador dirá Enviar a rama principal.
-
En Cloud Shell, obtén la URL de la interfaz web de Cloud Composer:
gcloud composer environments describe $COMPOSER_ENV_NAME \
--location $COMPOSER_REGION --format="get(config.airflowUri)"
-
Una vez finalizada la compilación, ve a la URL del comando anterior para
verificar que el DAG test_word_count se esté ejecutando.
Espera hasta que finalice la ejecución del DAG, que se indica cuando el círculo verde claro en la columna Ejecuciones de DAG desaparece. Por lo general, el proceso demora entre tres y cinco minutos.
Nota: Ignora el problema de la tarea do_comparison en el DAG test_word_count.
-
En Cloud Shell, descarga los archivos de resultados de la prueba:
mkdir ~/result-download
cd ~/result-download
gsutil cp gs://$RESULT_BUCKET_TEST/output* .
-
Verifica que la palabra agregada recientemente esté en uno de los archivos de resultados:
grep testword output*
El resultado es similar a este:
output-00000-of-00003:testword: 1
Haz clic en Revisar mi progreso para verificar el objetivo.
Probar el activador
¡Felicitaciones!
Finalice su lab
Cuando haya completado el lab, haga clic en Finalizar lab. Google Cloud Skills Boost quitará los recursos que usó y limpiará la cuenta.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
- 1 estrella = Muy insatisfecho
- 2 estrellas = Insatisfecho
- 3 estrellas = Neutral
- 4 estrellas = Satisfecho
- 5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2020 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.