Criará um pipeline que usa SQL para agregar o tráfego do site por usuário.Hi!
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
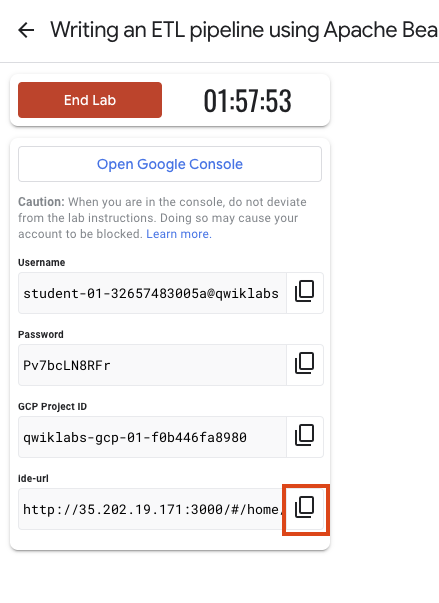
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Verifique as permissões do projeto
Antes de começar a trabalhar no Google Cloud, veja se o projeto tem as permissões corretas no Identity and Access Management (IAM).
No console do Google Cloud, em Menu de navegação (), selecione IAM e administrador > IAM.
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que está no Menu de navegação > Visão geral do Cloud > Painel.
Observação: se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
No console do Google Cloud, em Menu de navegação, clique em Visão geral do Cloud > Painel.
Copie o número do projeto, por exemplo, 729328892908.
Em Menu de navegação, clique em IAM e administrador > IAM.
Clique em Permitir acesso, logo abaixo de Visualizar por principais na parte de cima da tabela de papéis.
Substitua {project-number} pelo número do seu projeto.
Em Papel, selecione Projeto (ou Básico) > Editor.
Clique em Save.
Configurar o ambiente de desenvolvimento integrado
Neste laboratório, você vai usar principalmente a versão do ambiente de desenvolvimento integrado Theia para Web. Ela é hospedada no Google Compute Engine e contém o repositório do laboratório pré-clonado. Além disso, o Theia oferece suporte de servidor à linguagem Java e um terminal para acesso programático às APIs do Google Cloud com a ferramenta de linha de comando gcloud, similar ao Cloud Shell.
Para acessar o ambiente de desenvolvimento integrado Theia, copie e cole o link mostrado no Google Cloud Ensina em uma nova guia.
Observação: mesmo depois que o URL aparecer, talvez você precise esperar de 3 a 5 minutos para o ambiente ser totalmente provisionado. Até isso acontecer, você verá uma mensagem de erro no navegador.
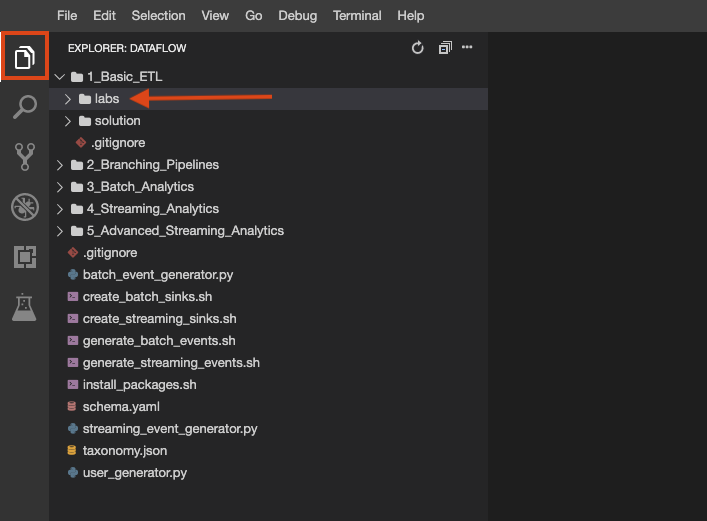
O repositório do laboratório foi clonado para seu ambiente. Cada laboratório é dividido em uma pasta labs com códigos que você vai concluir e uma pasta solution com um exemplo totalmente funcional para consulta, caso você tenha dificuldades.
Clique no botão File Explorer para conferir:
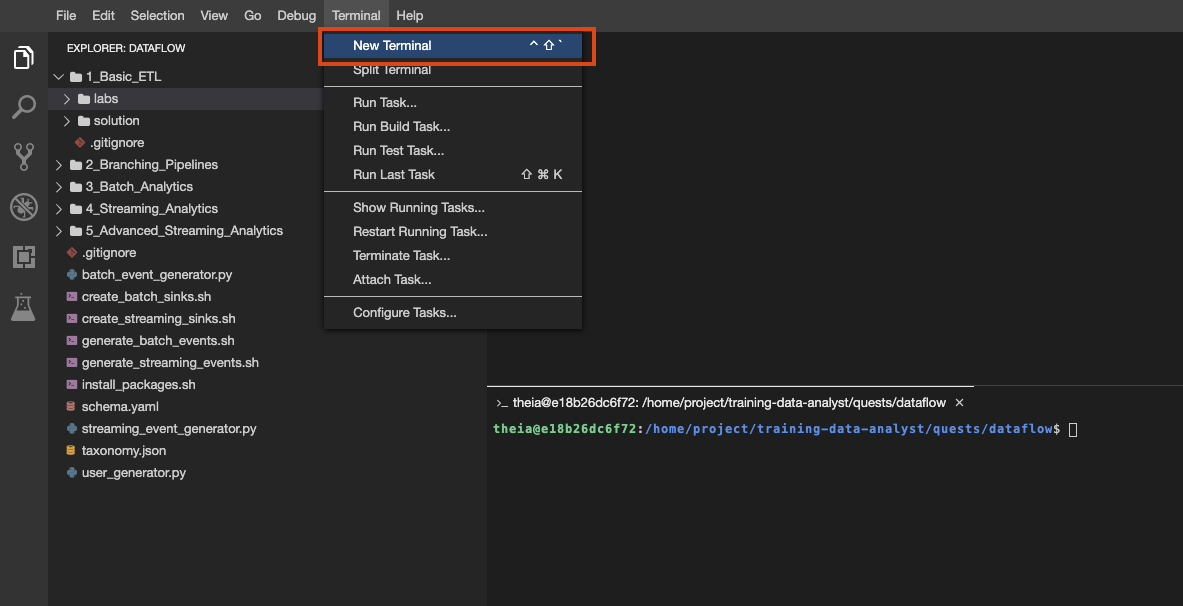
Também é possível criar vários terminais nesse ambiente, como você faria com o Cloud Shell:
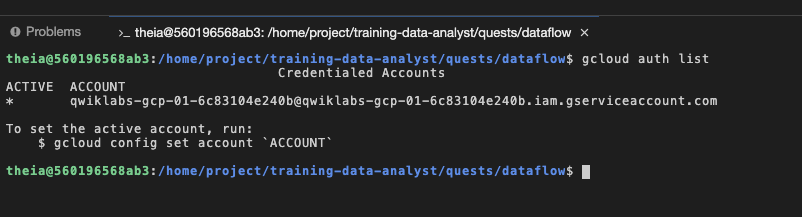
Outra forma de visualizar é executando gcloud auth list no terminal em que você fez login com uma conta de serviço fornecida. Ela tem as mesmas permissões que a sua conta de usuário do laboratório:
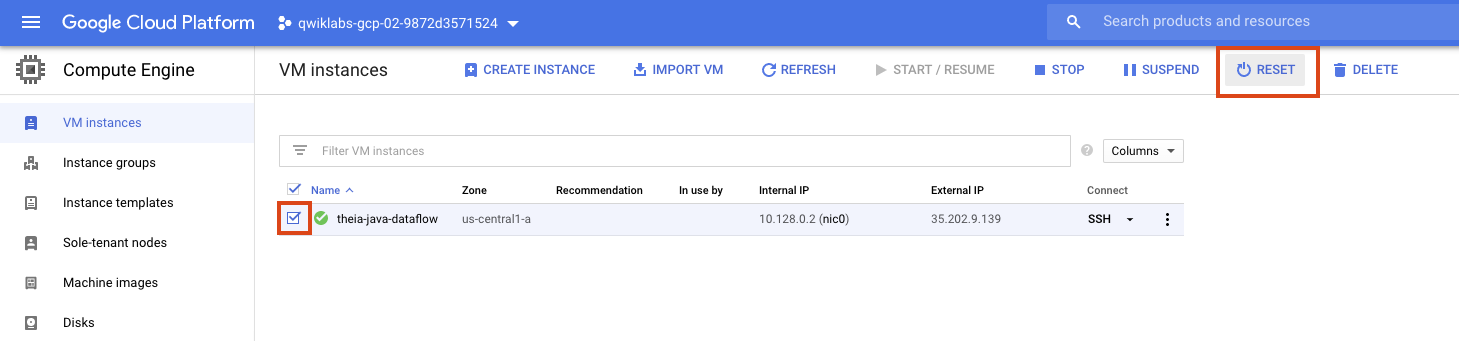
Se em algum momento o ambiente parar de funcionar, redefina a VM que hospeda o ambiente de desenvolvimento integrado no Console do GCE, conforme este exemplo:
Agregar o tráfego do site por usuário com SQL
Neste laboratório, você vai recriar o pipeline BatchUserTraffic anterior para que ele faça o seguinte:
Leia o tráfego do dia de um arquivo no Cloud Storage.
Converta cada evento em um objeto CommonLog.
Use SQL em vez de transformações Java para somar o número de hits para cada ID de usuário único e realize agregações adicionais.
Grave os dados resultantes no BigQuery.
Tenha uma outra ramificação que grava os dados brutos no BigQuery para análise posterior.
Tarefa 1: preparar o ambiente
Assim como nos laboratórios anteriores, a primeira coisa a se fazer é gerar os dados que o pipeline vai tratar. Abra o ambiente do laboratório e gere os dados como antes:
Abra o laboratório apropriado
Crie um novo terminal no ambiente de desenvolvimento integrado, caso ainda não tenha feito isso. Depois, copie e cole este comando:
# Change directory into the lab
cd 4_SQL_Batch_Analytics/labs
# Download dependencies
mvn clean dependency:resolve
export BASE_DIR=$(pwd)
Configure o ambiente de dados:
# Create GCS buckets and BQ dataset
cd $BASE_DIR/../..
source create_batch_sinks.sh
# Generate event dataflow
source generate_batch_events.sh
# Change to the directory containing the practice version of the code
cd $BASE_DIR
Verifique se as APIs do Data Catalog estão ativadas:
gcloud services enable datacatalog.googleapis.com
Clique em Verificar meu progresso para conferir o objetivo.
Configure o ambiente de dados
Tarefa 2: adicionar dependências do SQL ao pipeline
Abra BatchUserTrafficSQLPipeline.java no ambiente de desenvolvimento integrado, que fica em 4_SQL_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.
O pipeline já contém o código necessário para aceitar as opções de linha de comando do caminho de entrada e um nome de tabela de saída, bem como o código para ler eventos no Google Cloud Storage, analisar esses eventos e gravar os resultados no BigQuery. No entanto, algumas partes importantes estão ausentes.
Como no laboratório anterior, a próxima etapa no pipeline é agregar os eventos de cada user_id exclusivo e contar visualizações de página de cada um. No entanto, desta vez você fará a agregação usando a transformação SqlTransform de SQL, em vez de transformações baseadas em Java.
Antes de implementar, é preciso adicionar uma dependência de SQL ao pipeline.
Para concluir essa tarefa, abra o arquivo pom.xml referente a esse pipeline, localizado em 4_SQL_Batch_Analytics/labs/, e adicione a seguinte dependência:
O método SqlTransform.query(queryString) é a única API que cria uma PTransform usando uma representação de string da consulta SQL. É possível aplicar essa PTransform a uma única PCollection ou a uma PCollectionTuple que contenha várias PCollections (mais informações sobre PColllectionTuples posteriormente).
Quando aplicada a uma única PCollection, ela pode ser referenciada pelo nome da tabela PCOLLECTION na consulta:
A saída resultante é um objeto Row com esquema associado que pode ser modificado ainda mais em transformações SQL ou outas PTransform do Java ou armazenados em um coletor.
Para concluir esta tarefa, adicione um SQLTransform ao pipeline, fornecendo uma string SQL para agregar o número de hits por user_id e nomeando como "visualizações de página".
Também é possível realizar outras agregações se você quiser. Para referência, esta foi a PTransform usada anteriormente:
Se você não souber o que fazer, consulte a solução para encontrar dicas.
Implemente uma ramificação para armazenar dados brutos
Você quer armazenar todos os resultados brutos no BigQuery para agregações de SQL posteriores na interface.
Para concluir esta tarefa, reconfigure o pipeline, com uma ramificação que grave os objetos brutos CommonLog diretamente no BigQuery, em um nome de tabela referenciado por uma opção de linha de comando rawTableName.
Para isso, encerre a primeira ramificação do pipeline com um ponto e vírgula e inicie cada ramificação com logs.apply();. Não se esqueça de adicionar essa nova linha de comando às opções de pipeline com inputPath e aggregateTableName. Lembre-se também de mudar a dica de tipo no BigQueryIO.<Object>write().
Acesse Menu de navegação > Dataflow para ver o status do pipeline.
Quando o pipeline terminar, acesse a IU do BigQuery para consultar as duas tabelas resultantes. Verifique se logs.raw existe e tem dados preenchidos, porque você precisará deles mais adiante no laboratório.
Clique em Verificar meu progresso para conferir o objetivo.
Agregar o tráfego do site por usuário com SQL
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste laboratório, você adicionará instruções SQL ao pipeline do Beam gravado anteriormente que agrega o tráfego do site por usuário e por minuto. Além disso, executará um job de SQL do Beam na IU do BigQuery.
Duração:
Configuração: 2 minutos
·
Tempo de acesso: 120 minutos
·
Tempo para conclusão: 120 minutos
 ), selecione IAM e administrador > IAM.
), selecione IAM e administrador > IAM.