Write a pipeline that uses SQL to aggregate site traffic by user.
Setup and requirements
For each lab, you get a new Google Cloud project and set of resources for a fixed time at no cost.
Sign in to Qwiklabs using an incognito window.
Note the lab's access time (for example, 1:15:00), and make sure you can finish within that time.
There is no pause feature. You can restart if needed, but you have to start at the beginning.
When ready, click Start lab.
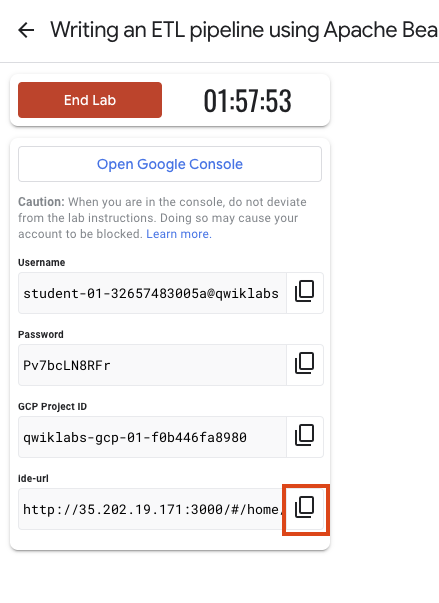
Note your lab credentials (Username and Password). You will use them to sign in to the Google Cloud Console.
Click Open Google Console.
Click Use another account and copy/paste credentials for this lab into the prompts.
If you use other credentials, you'll receive errors or incur charges.
Accept the terms and skip the recovery resource page.
Check project permissions
Before you begin your work on Google Cloud, you need to ensure that your project has the correct permissions within Identity and Access Management (IAM).
In the Google Cloud console, on the Navigation menu (), select IAM & Admin > IAM.
Confirm that the default compute Service Account {project-number}-compute@developer.gserviceaccount.com is present and has the editor role assigned. The account prefix is the project number, which you can find on Navigation menu > Cloud Overview > Dashboard.
Note: If the account is not present in IAM or does not have the editor role, follow the steps below to assign the required role.
In the Google Cloud console, on the Navigation menu, click Cloud Overview > Dashboard.
Copy the project number (e.g. 729328892908).
On the Navigation menu, select IAM & Admin > IAM.
At the top of the roles table, below View by Principals, click Grant Access.
Replace {project-number} with your project number.
For Role, select Project (or Basic) > Editor.
Click Save.
Setting up your IDE
For the purposes of this lab, you will mainly be using a Theia Web IDE hosted on Google Compute Engine. It has the lab repo pre-cloned. There is java langauge server support, as well as a terminal for programmatic access to Google Cloud APIs via the gcloud command line tool, similar to Cloud Shell.
To access your Theia IDE, copy and paste the link shown in Google Cloud Skills Boost to a new tab.
Note: You may need to wait 3-5 minutes for the environment to be fully provisioned, even after the url appears. Until then you will see an error in the browser.
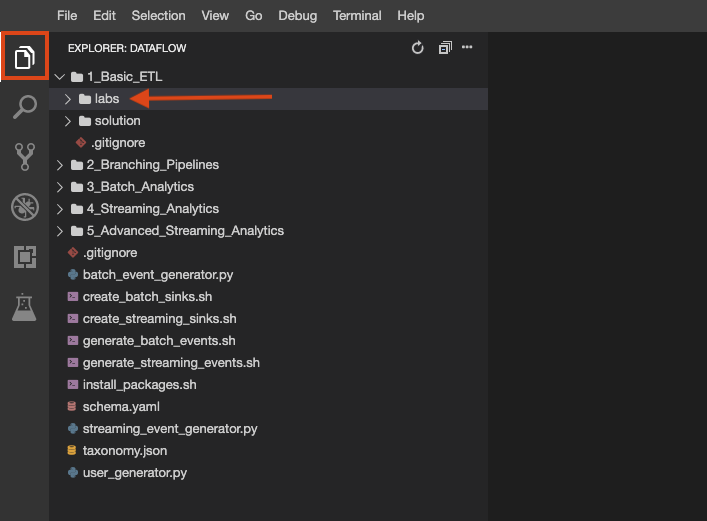
The lab repo has been cloned to your environment. Each lab is divided into a labs folder with code to be completed by you, and a solution folder with a fully workable example to reference if you get stuck.
Click on the File Explorer button to look:
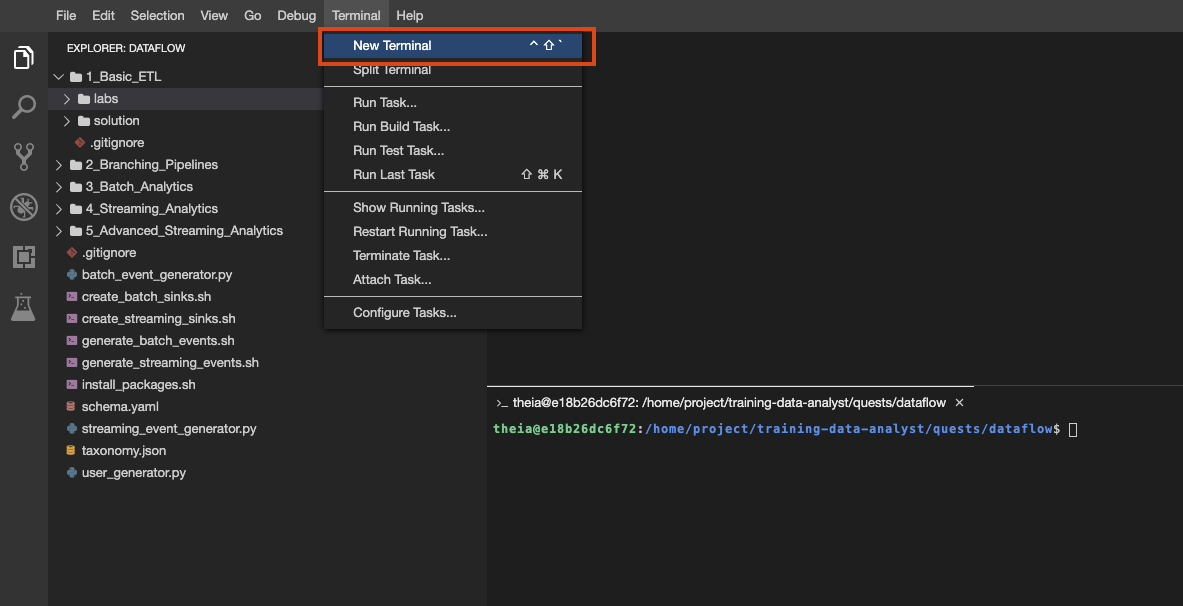
You can also create multiple terminals in this environment, just as you would with cloud shell:
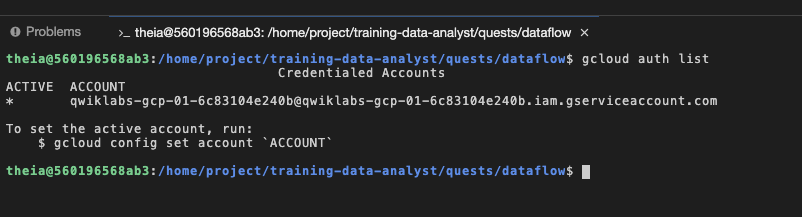
You can see with by running gcloud auth list on the terminal that you're logged in as a provided service account, which has the exact same permissions are your lab user account:
If at any point your environment stops working, you can try resetting the VM hosting your IDE from the GCE console like this:
Aggregating site traffic by user with SQL
In this lab, you rewrite your previous BatchUserTraffic pipeline so that it performs the following:
Reads the day’s traffic from a file in Cloud Storage.
Converts each event into a CommonLog object.
Uses SQL instead of Java transforms to sum the number of hits for each unique user ID and perform additional aggregations.
Writes the resulting data to BigQuery.
Has an additional branch that writes the raw data to BigQuery for later analysis.
Task 1. Prepare environment
As in the prior labs, the first step is to generate data for the pipeline to process. You will open the lab environment and generate the data as before:
Open the appropriate lab
Create a new terminal in your IDE environment, if you haven't already, and copy and paste the following command:
# Change directory into the lab
cd 4_SQL_Batch_Analytics/labs
# Download dependencies
mvn clean dependency:resolve
export BASE_DIR=$(pwd)
Set up the data environment:
# Create GCS buckets and BQ dataset
cd $BASE_DIR/../..
source create_batch_sinks.sh
# Generate event dataflow
source generate_batch_events.sh
# Change to the directory containing the practice version of the code
cd $BASE_DIR
Ensure that the Data Catalog APIs is enabled:
gcloud services enable datacatalog.googleapis.com
Click Check my progress to verify the objective.
Set up the data environment
Task 2. Add SQL dependencies to the pipeline
Open up BatchUserTrafficSQLPipeline.java in your IDE, which can be found in 4_SQL_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.
This pipeline already contains the necessary code to accept command-line options for the input path and one output table name, as well as code to read in events from Google Cloud Storage, parse those events, and write results to BigQuery. However, some important parts are missing.
As in the previous lab, the next step in the pipeline is to aggregate the events by each unique user_id and count pageviews for each. This time, however, you will perform the aggregation using SQL using SqlTransform instead of Java-based transforms.
Before you implement this, you will need to add a SQL dependency to your pipeline.
To complete this task, open up the pom.xml file for this pipeline located at 4_SQL_Batch_Analytics/labs/ and add the following dependency:
The SqlTransform.query(queryString) method is the only API to create a PTransform from a string representation of the SQL query. You can apply this PTransform either to a single PCollection or a PCollectionTuple that holds multiple PCollections (more on PColllectionTuples later).
When it is being applied to a single PCollection, it can be referenced via the table name PCOLLECTION in the query:
The resulting output is a Row object with associated schema that can be further mutated in SQL Transforms or other Java PTransforms, or stored in a sink.
To complete this task, add a SQLTransform to your pipeline, supplying a SQL string to aggregate the number of hits by user_id and naming this 'pageviews'.
You can also perform additional aggregations if you wish. For reference, this was the PTransform previously used:
If you get stuck, reference the solution for hints.
Implement a branch to store raw data
You want to store all the raw results in BigQuery for further SQL aggregations later in the UI.
To complete this task, reconfigure your pipeline with a branch that writes out the raw CommonLog objects directly to BigQuery, to a table name referenced by a command line option rawTableName.
You can do this as before by terminating the first branch of the pipeline with a semicolon and starting each branch with logs.apply();. Don't forget to add this new command line to the Pipeline options along with inputPath and aggregateTableName. Remember also to change the type hint on BigQueryIO.<Object>write().
Navigate to Navigation Menu > Dataflow to see the status of your pipeline.
Once your pipeline has finished, go to the BigQuery UI to query the two resulting tables. Make sure that logs.raw exists and has data populated, as you will need that later in the lab.
Click Check my progress to verify the objective.
Aggregating site traffic by user with SQL
End your lab
When you have completed your lab, click End Lab. Google Cloud Skills Boost removes the resources you’ve used and cleans the account for you.
You will be given an opportunity to rate the lab experience. Select the applicable number of stars, type a comment, and then click Submit.
The number of stars indicates the following:
1 star = Very dissatisfied
2 stars = Dissatisfied
3 stars = Neutral
4 stars = Satisfied
5 stars = Very satisfied
You can close the dialog box if you don't want to provide feedback.
For feedback, suggestions, or corrections, please use the Support tab.
Copyright 2022 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.
Moduły tworzą projekt Google Cloud i zasoby na określony czas.
Moduły mają ograniczenie czasowe i nie mają funkcji wstrzymywania. Jeśli zakończysz moduł, musisz go zacząć od początku.
Aby rozpocząć, w lewym górnym rogu ekranu kliknij Rozpocznij moduł.
Użyj przeglądania prywatnego
Skopiuj podaną nazwę użytkownika i hasło do modułu.
Kliknij Otwórz konsolę w trybie prywatnym.
Zaloguj się w konsoli
Zaloguj się z użyciem danych logowania do modułu. Użycie innych danych logowania może spowodować błędy lub naliczanie opłat.
Zaakceptuj warunki i pomiń stronę zasobów przywracania.
Nie klikaj Zakończ moduł, chyba że właśnie został przez Ciebie zakończony lub chcesz go uruchomić ponownie, ponieważ spowoduje to usunięcie wyników i projektu.
Ta treść jest obecnie niedostępna
Kiedy dostępność się zmieni, wyślemy Ci e-maila z powiadomieniem
Świetnie
Kiedy dostępność się zmieni, skontaktujemy się z Tobą e-mailem
Jeden moduł, a potem drugi
Potwierdź, aby zakończyć wszystkie istniejące moduły i rozpocząć ten
Aby uruchomić moduł, użyj przeglądania prywatnego
Uruchom ten moduł w oknie incognito lub przeglądania prywatnego. Dzięki temu unikniesz konfliktu między swoim kontem osobistym a kontem do nauki, co mogłoby spowodować naliczanie dodatkowych opłat na koncie osobistym.
In this lab you add SQL statements to the previously written Beam pipeline that aggregates site traffic by user and by minute. You also execute a Beam SQL job from the BigQuery UI.
Czas trwania:
Konfiguracja: 2 min
·
Dostęp na 120 min
·
Ukończono w 120 min
 ), select IAM & Admin > IAM.
), select IAM & Admin > IAM.