![Compute Engine のデフォルトのサービス アカウント名と編集者のステータスがハイライト表示された [権限] タブページ](https://cdn.qwiklabs.com/1nytD9OUuNUV9undyjUWeOS7LJmekReBDmkUjveCjcU%3D)
![[ターミナル] メニューでハイライト表示されている [新しいターミナル] オプション](https://cdn.qwiklabs.com/o3Hxy07QcEZ%2FwAucqGRJPFyRJWB0negMcYJph7S%2FDh4%3D)
![[VM インスタンス] ページで、リセットボタンと VM インスタンス名の両方がハイライト表示されている](https://cdn.qwiklabs.com/jDH1qGTOJ%2B1Hy2nxOPm1DPmO1JgUCjOmBvwycVWgqEk%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Setup the data environment
/ 40
Aggregating Site Traffic by User with SQL
/ 60
このラボの内容:
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
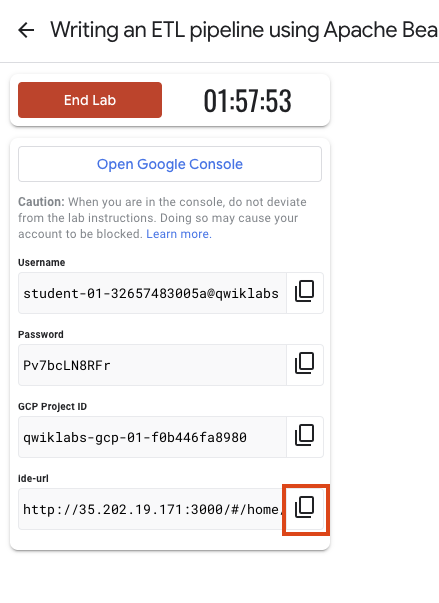
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
Google Cloud で作業を開始する前に、Identity and Access Management(IAM)内で適切な権限がプロジェクトに付与されていることを確認する必要があります。
Google Cloud コンソールのナビゲーション メニュー(
Compute Engine のデフォルトのサービス アカウント {project-number}-compute@developer.gserviceaccount.com が存在し、編集者のロールが割り当てられていることを確認します。アカウントの接頭辞はプロジェクト番号で、ナビゲーション メニュー > [Cloud の概要] > [ダッシュボード] から確認できます。
編集者のロールがない場合は、以下の手順に沿って必要なロールを割り当てます。729328892908)をコピーします。{project-number} はプロジェクト番号に置き換えてください。このラボでは、Google Compute Engine でホストされる Theia Web IDE を主に使用します。これには、事前にクローンが作成されたラボリポジトリが含まれます。Java 言語サーバーがサポートされているとともに、Cloud Shell に似た仕組みで、gcloud コマンドライン ツールを通じて Google Cloud API へのプログラムによるアクセスが可能なターミナルも使用できます。
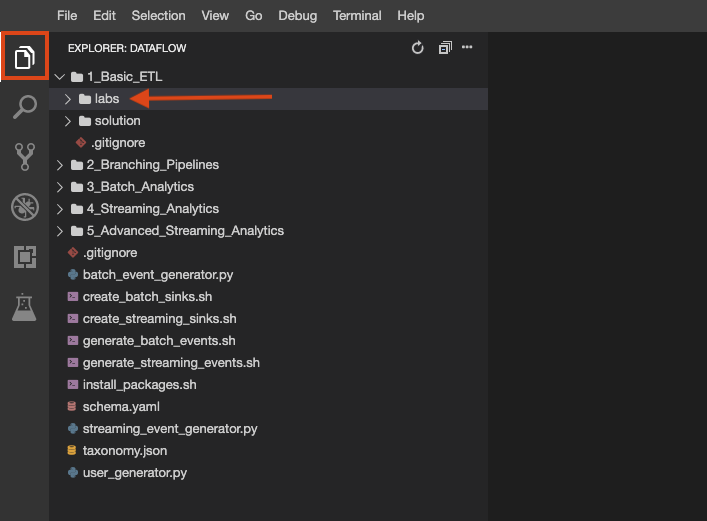
ラボリポジトリのクローンが環境に作成されました。各ラボは、完成させるコードが格納される labs フォルダと、ヒントが必要な場合に完全に機能するサンプルを参照できる solution フォルダに分けられています。
ファイル エクスプローラ ボタンをクリックして確認します。Cloud Shell で行うように、この環境で複数のターミナルを作成することも可能です。
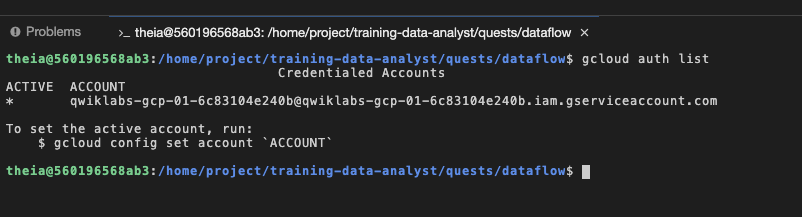
提供されたサービス アカウント(ラボのユーザー アカウントとまったく同じ権限がある)でログインしたターミナルで gcloud auth list を実行すれば、以下を確認できます。
環境が機能しなくなった場合は、IDE をホストしている VM を GCE コンソールから次のようにリセットしてみてください。
このラボでは、以下を実行するように以前の BatchUserTraffic パイプラインを書き換えます。
CommonLog オブジェクトに変換する。以前のラボと同様に、最初のステップはパイプラインで処理するデータを生成することです。ラボ環境を開いて、以前と同じようにデータを生成します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
BatchUserTrafficSQLPipeline.java を開きます。これは 4_SQL_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline にあります。このパイプラインには、入力パスと 1 つの出力テーブル名のコマンドライン オプションを受け取るために必要なコードと、Google Cloud Storage からイベントを読み取り、それらのイベントを解析して、結果を BigQuery に書き込むコードがすでに含まれています。ただし、いくつかの重要な部分が欠けています。
以前のラボと同様に、パイプラインの次のステップでは、一意の user_id 別にイベントを集計し、それぞれのページビューをカウントします。ただし、今回は、Java ベースの変換ではなく SqlTransform を使用して、SQL で集計を実行します。
これを実装する前に、SQL 依存関係をパイプラインに追加する必要があります。
4_SQL_Batch_Analytics/labs/ にあるこのパイプラインの pom.xml ファイルを開いて、次の依存関係を追加します。BatchUserTrafficSQLPipeline.java で、次の import がファイルの先頭にあることを確認します。Beam SQL は Apache Calcite 言語で実装できます。
SqlTransform.query(queryString) メソッドは、SQL クエリの文字列表現から PTransform を作成する唯一の API です。この PTransform は、単一の PCollection か、複数の PCollection を保持する 1 つの PCollectionTuple のいずれかに適用できます(PCollectionTuple については後で詳しく説明します)。
この PTransform は、単一の PCollection に適用されている場合、クエリ内の PCOLLECTION という名前のテーブルを介して参照できます。
結果として得られる出力は関連スキーマを含む Row オブジェクトであり、SQL Transform または他の Java PTransform でさらに変更することやシンクに保存することができます。
SQLTransform をパイプラインに追加し、user_id 別にヒット数を集計する SQL 文字列を設定して「pageviews」という名前を付けます。また、必要に応じて追加の集計を実行することもできます。ちなみに、これは以前に使用した PTransform です。
役に立つ SQL 集計関数がいくつかあります。
ヒントが必要な場合は、こちらのソリューションをご覧ください。
後から UI で SQL 集計を行うために、生の結果をすべて BigQuery に保存したい場合があります。
CommonLog オブジェクトを直接 BigQuery に書き出すブランチを使用して、パイプラインを再構成します。書き込み先は、コマンドライン オプション rawTableName で参照されるテーブル名です。これを行うには、以前と同様に、パイプラインの最初のブランチをセミコロンで終了し、各ブランチを logs.apply(); で開始します。この新しいコマンドラインを、inputPath および aggregateTableName とともにパイプライン オプションに追加することを忘れないでください。また、BigQueryIO.<Object>write() の型ヒントも必ず変更してください。
[ナビゲーション メニュー] > [Dataflow] に移動して、パイプラインのステータスを確認します。
パイプラインが終了したら、BigQuery UI に移動して、結果として得られる 2 つのテーブルに対してクエリを実行します。logs.raw が存在し、データが入力されていることを確認してください。これは後ほどラボで必要になります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2020 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください