écrire un pipeline qui utilise SQL pour agréger le trafic du site par utilisateur.
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Qwiklabs dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
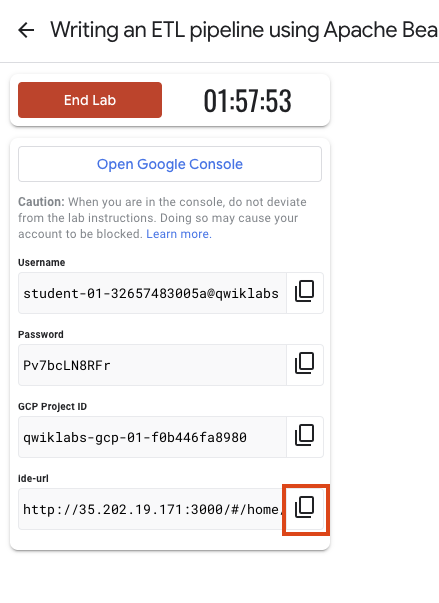
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à Google Cloud Console.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
Dans la console Google Cloud, accédez au menu de navigation (), puis sélectionnez IAM et administration > IAM.
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle editor (éditeur). Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation du cloud > Tableau de bord.
Remarque : Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle editor (éditeur), procédez comme suit pour lui attribuer le rôle approprié.
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation du cloud > Tableau de bord.
Copiez le numéro du projet (par exemple, 729328892908).
Dans le menu de navigation, sélectionnez IAM et administration > IAM.
Sous Afficher par compte principal, en haut de la table des rôles, cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez :
Remplacez {project-number} par le numéro de votre projet.
Dans le champ Rôle, sélectionnez Projet (ou Basique) > Éditeur.
Cliquez sur Enregistrer.
Configurer votre IDE
Dans cet atelier, vous utiliserez principalement un IDE Web Theia hébergé sur Google Compute Engine. Le dépôt de l'atelier y est précloné. L'IDE prend en charge les serveurs au langage Java et comprend un terminal permettant l'accès programmatique aux API Google Cloud via l'outil de ligne de commande gcloud, comme avec Cloud Shell.
Pour accéder à votre IDE Theia, copiez le lien affiché dans Google Cloud Skills Boost et collez-le dans un nouvel onglet.
Remarque : Le provisionnement complet de l'environnement peut prendre entre trois et cinq minutes, même après l'affichage de l'URL. En attendant, le navigateur indiquera une erreur.
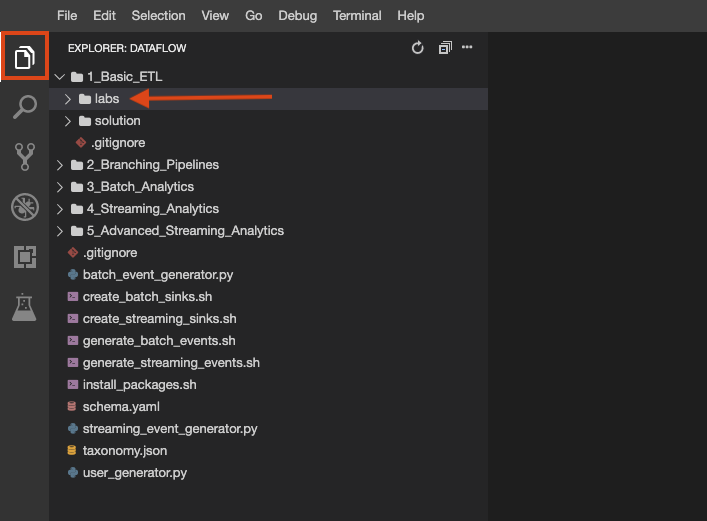
Le dépôt de l'atelier a été cloné dans votre environnement. Chaque atelier est divisé en deux dossiers : le premier, intitulé labs, contient du code que vous devez compléter, tandis que le second, nommé solution, comporte un exemple opérationnel que vous pouvez consulter si vous rencontrez des difficultés.
Cliquez sur le bouton Explorateur de fichiers pour y accéder :
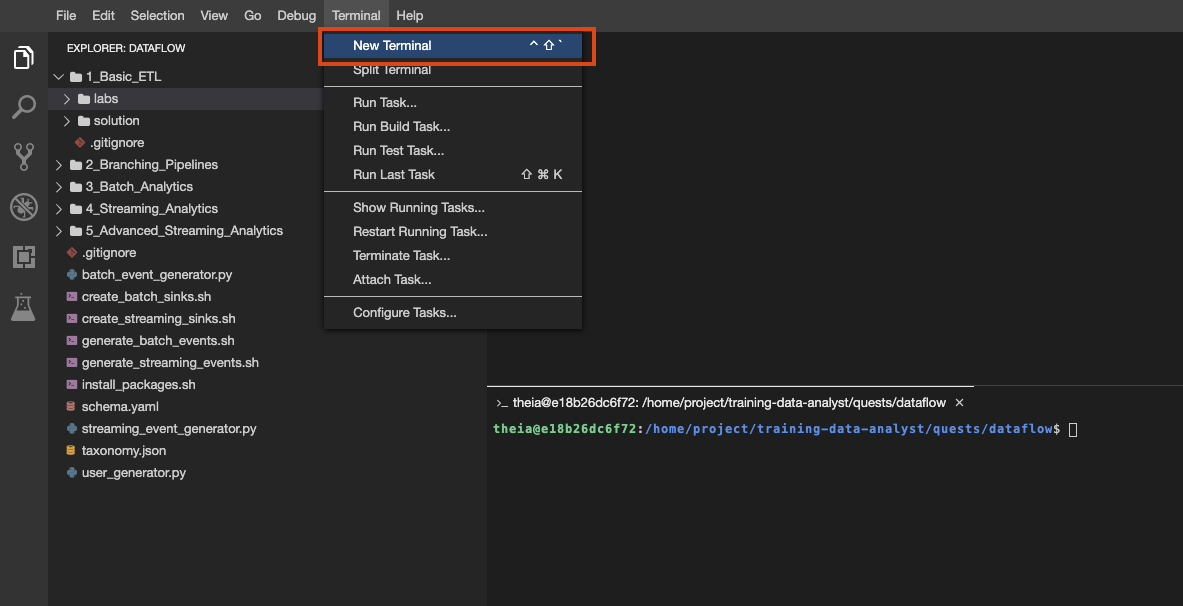
Vous pouvez également créer plusieurs terminaux dans cet environnement, comme vous le feriez avec Cloud Shell :
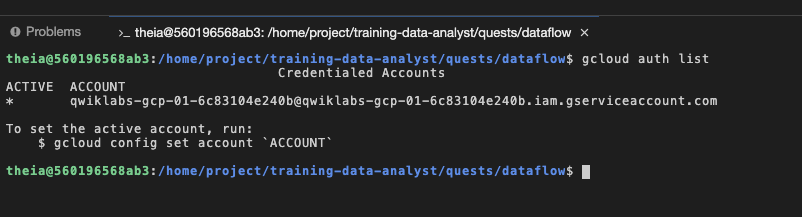
Vous pouvez exécuter la commande gcloud auth list dans le terminal pour vérifier que vous êtes connecté avec un compte de service fourni et que vous disposez donc des mêmes autorisations qu'avec votre compte utilisateur pour l'atelier :
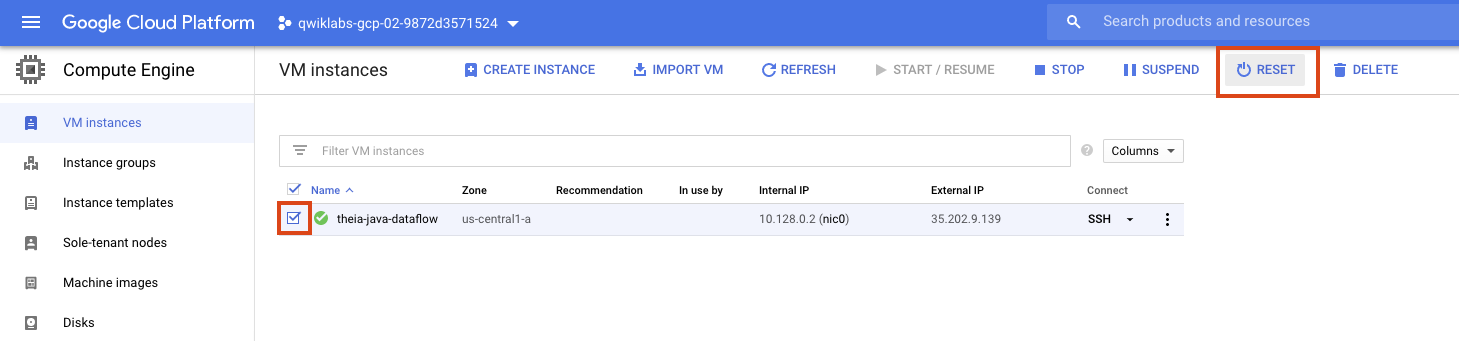
Si votre environnement cesse de fonctionner, vous pouvez essayer de réinitialiser la VM hébergeant votre IDE depuis la console GCE. Pour cela, procédez comme suit :
Agrégation du trafic sur le site par utilisateur avec SQL
Dans cet atelier, vous allez réécrire le pipeline BatchUserTraffic que vous avez créé précédemment pour qu'il effectue les opérations suivantes :
Lire le trafic de la journée à partir d'un fichier dans Cloud Storage
Convertir chaque événement en objet CommonLog
Utiliser SQL au lieu de transformations Java pour additionner le nombre d'accès pour chaque ID utilisateur unique et effectuer des agrégations supplémentaires
Écrire les données obtenues dans BigQuery
Écrire les données brutes dans BigQuery avec une branche supplémentaire pour les analyser ultérieurement
Tâche 1 : préparer l'environnement
Comme dans les ateliers précédents, la première étape consiste à générer les données que le pipeline va traiter. Vous allez ouvrir l'environnement de l'atelier et générer les données comme précédemment :
Ouvrir l'atelier approprié
Si ce n'est pas déjà fait, créez un terminal dans votre environnement IDE, puis copiez et collez la commande suivante :
# Change directory into the lab
cd 4_SQL_Batch_Analytics/labs
# Download dependencies
mvn clean dependency:resolve
export BASE_DIR=$(pwd)
Configurez l'environnement de données :
# Create GCS buckets and BQ dataset
cd $BASE_DIR/../..
source create_batch_sinks.sh
# Generate event dataflow
source generate_batch_events.sh
# Change to the directory containing the practice version of the code
cd $BASE_DIR
Vérifiez que l'API Data Catalog est activée :
gcloud services enable datacatalog.googleapis.com
Cliquez sur Vérifier ma progression pour valider l'objectif.
Configurer l'environnement de données
Tâche 2 : ajouter des dépendances SQL au pipeline
Ouvrez BatchUserTrafficSQLPipeline.java dans votre IDE. Ce fichier se trouve dans 4_SQL_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.
Ce pipeline contient déjà le code nécessaire pour accepter des options de ligne de commande (chemin d'entrée, nom de table de sortie) ainsi que le code permettant de lire les événements depuis Google Cloud Storage, de les analyser et d'écrire les résultats dans BigQuery. Cependant, il manque des éléments importants.
Comme dans l'atelier précédent, l'étape suivante du pipeline consiste à agréger les événements par user_id unique et à compter les pages vues pour chaque utilisateur. Cette fois, vous allez en revanche effectuer l'agrégation à l'aide de SQL avec SqlTransform au lieu de transformations basées sur Java.
Avant d'implémenter cette fonctionnalité, vous devez ajouter une dépendance SQL à votre pipeline.
Pour effectuer cette tâche, ouvrez le fichier pom.xml de ce pipeline situé dans 4_SQL_Batch_Analytics/labs/ et ajoutez la dépendance suivante :
La méthode SqlTransform.query(queryString) est la seule API permettant de créer une PTransform à partir d'une représentation sous forme de chaîne de la requête SQL. Vous pouvez appliquer cette PTransform à une seule PCollection ou à une PCollectionTuple contenant plusieurs PCollections (nous aborderons les PCollectionTuples plus loin).
Lorsqu'elle est appliquée à une seule PCollection, elle peut être référencée via le nom de table PCOLLECTION dans la requête :
Le résultat est un objet Row avec un schéma associé qui peut être modifié avec des transformations SQL ou d'autres PTransforms Java, ou stocké dans un récepteur.
Pour effectuer cette tâche, ajoutez une transformation SQLTransform à votre pipeline. Fournissez une chaîne SQL pour agréger le nombre d'accès par user_id et nommez cette colonne "pageviews".
Vous pouvez également effectuer d'autres agrégations si vous le souhaitez. Pour rappel, voici la PTransform utilisée précédemment :
Si vous rencontrez des difficultés, consultez la solution pour obtenir des indices.
Implémenter une branche pour stocker les données brutes
Vous souhaitez stocker tous les résultats bruts dans BigQuery pour effectuer des agrégations SQL ultérieurement dans l'UI.
Pour effectuer cette tâche, vous devez reconfigurer votre pipeline avec une branche qui écrit les objets CommonLog bruts directement dans BigQuery, dans une table dont le nom est référencé par l'option de ligne de commande rawTableName.
Pour cela, terminez encore la première branche du pipeline par un point-virgule et commencez chaque branche par logs.apply();. N'oubliez pas d'ajouter cette nouvelle ligne de commande aux options du pipeline, ainsi que inputPath et aggregateTableName. N'oubliez pas non plus de modifier l'indication de type en indiquant BigQueryIO.<Object>write().
Accédez au menu de navigation > Dataflow pour afficher l'état de votre pipeline.
Une fois votre pipeline terminé, accédez à l'UI BigQuery pour interroger les deux tables résultantes. Assurez-vous que le fichier logs.raw existe et qu'il contient des données, car vous en aurez besoin plus tard dans l'atelier.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Agrégation du trafic sur le site par utilisateur avec SQL
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Dans cet atelier, vous allez ajouter des instructions SQL au pipeline Beam écrit précédemment, qui agrège le trafic du site par utilisateur et par minute. Vous allez aussi exécuter un job Beam SQL depuis l'UI de BigQuery.
Durée :
2 min de configuration
·
Accessible pendant 120 min
·
Terminé après 120 min
 ), puis sélectionnez IAM et administration > IAM.
), puis sélectionnez IAM et administration > IAM.