Escribir una canalización que use SQL para agregar el tráfico del sitio por usuario
Configuración y requisitos
En cada lab, recibirá un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Qwiklabs desde una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesita, puede reiniciar el lab, pero deberá hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
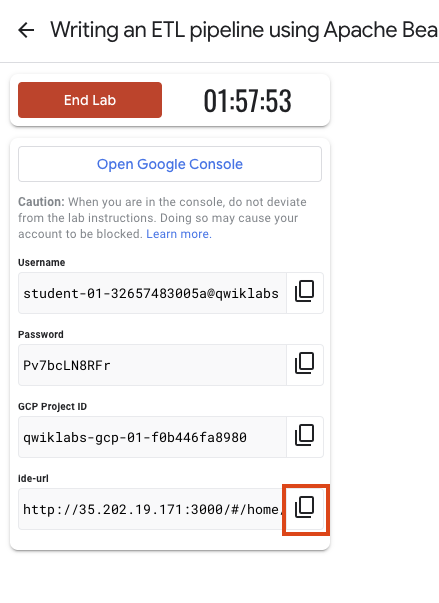
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usa otras credenciales, se generarán errores o incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Verifica los permisos del proyecto
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
En la consola de Google Cloud, en el Menú de navegación (), selecciona IAM y administración > IAM.
Confirma que aparezca la cuenta de servicio predeterminada de Compute {número-del-proyecto}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el menú de navegación > Descripción general de Cloud > Panel.
Nota: Si la cuenta no aparece en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
En la consola de Google Cloud, en el menú de navegación, haz clic en Descripción general de Cloud > Panel.
Copia el número del proyecto (p. ej., 729328892908).
En el Menú de navegación, selecciona IAM y administración > IAM.
En la parte superior de la tabla de funciones, debajo de Ver por principales, haz clic en Otorgar acceso.
Reemplaza {número-del-proyecto} por el número de tu proyecto.
En Rol, selecciona Proyecto (o Básico) > Editor.
Haz clic en Guardar.
Configura tu IDE
Para los fines de este lab, usará principalmente un IDE web de Theia alojado en Google Compute Engine. El IDE tiene el repositorio de labs clonado previamente. Se ofrece compatibilidad con servidores de lenguaje Java y una terminal para el acceso programático a las APIs de Google Cloud con la herramienta de línea de comandos de gcloud, similar a Cloud Shell.
Para acceder al IDE de Theia, copia y pega en una pestaña nueva el vínculo que se muestra en Google Cloud Skills Boost.
Nota: Es posible que debas esperar entre 3 y 5 minutos para que se aprovisione por completo el entorno, incluso después de que aparezca la URL. Hasta ese momento, se mostrará un error en el navegador.
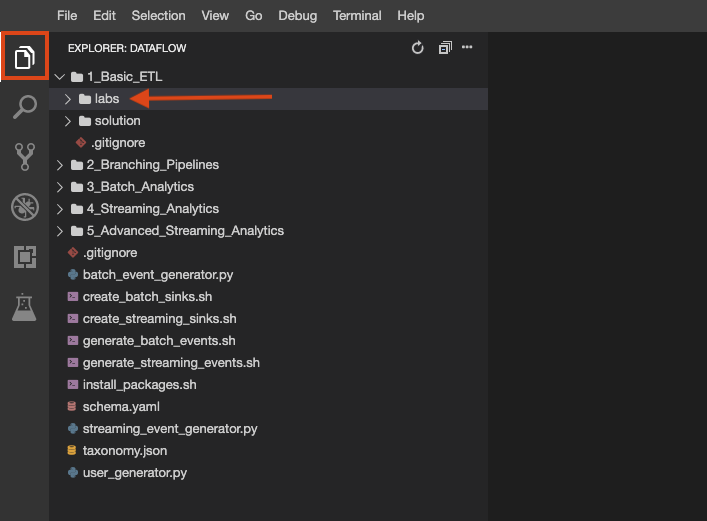
El repositorio del lab se clonó en tu entorno. Cada lab se divide en una carpeta labs con un código que debes completar y una carpeta solution con un ejemplo viable que puedes consultar como referencia si no sabes cómo continuar.
Haz clic en el botón File Explorer para ver lo siguiente:
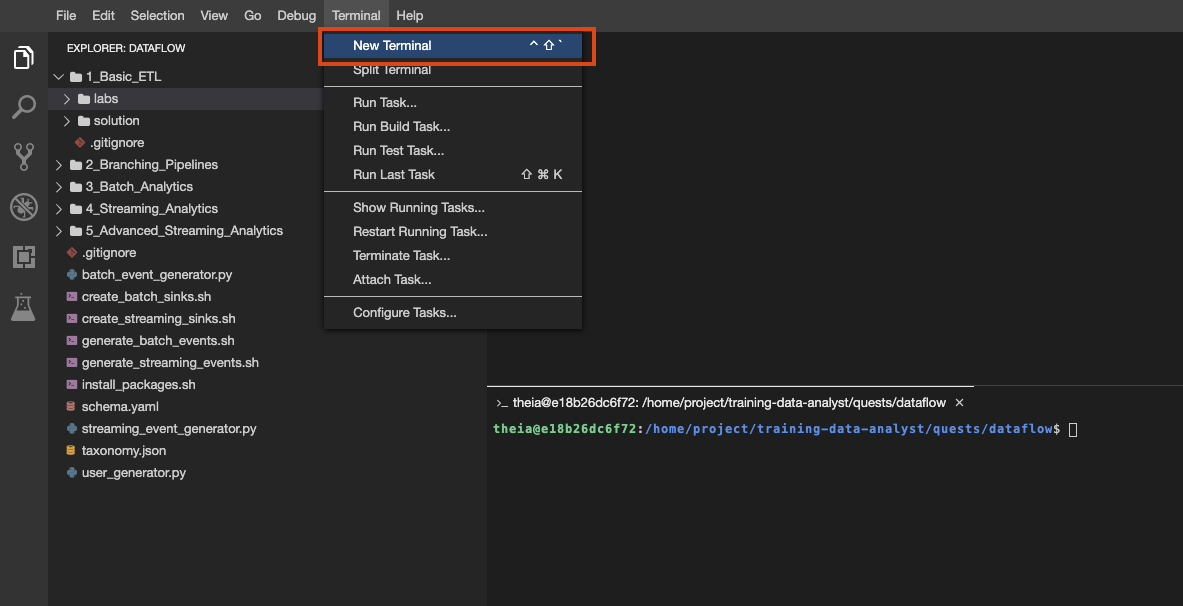
También puedes crear varias terminales en este entorno, como lo harías con Cloud Shell:
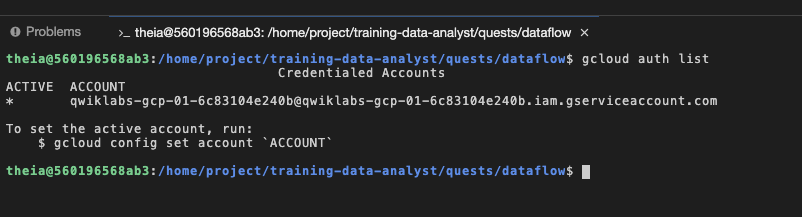
Para verificarlo, ejecuta gcloud auth list en la terminal con la que accediste como cuenta de servicio proporcionada, que tiene exactamente los mismos permisos que tu cuenta de usuario del lab:
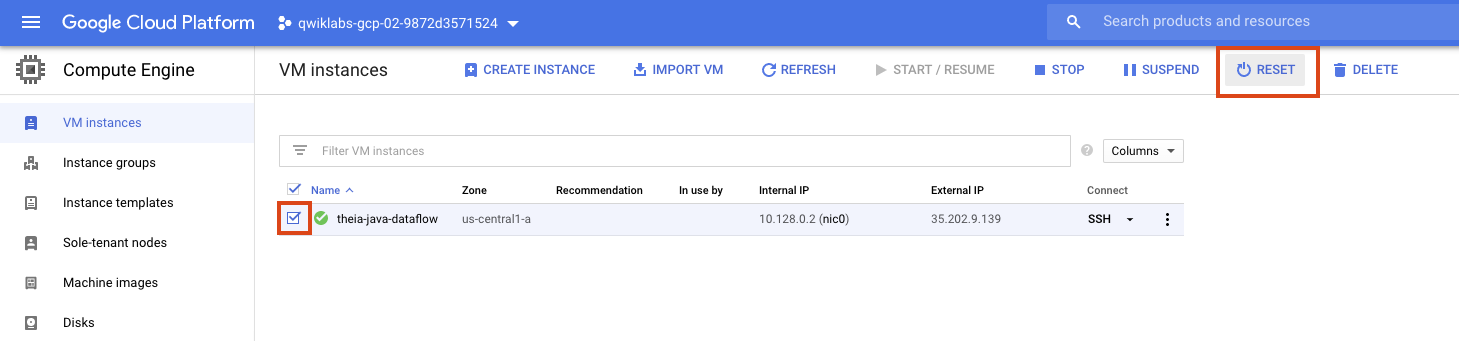
Si en algún momento tu entorno deja de funcionar, intenta restablecer la VM en la que se aloja el IDE desde la consola de GCE de la siguiente manera:
Agrega tráfico del sitio por usuario con SQL
En este lab, reescribirás tu canalización anterior de BatchUserTraffic para que realice las siguientes acciones:
Lea el tráfico del día desde un archivo de Cloud Storage
Convierta cada evento en un objeto CommonLog
Use SQL en lugar de transformaciones de Java para sumar la cantidad de hits para cada ID de usuario único y realizar agregaciones adicionales
Escriba los datos resultantes en BigQuery
Tenga una rama adicional que escriba los datos sin procesar en BigQuery para su análisis posterior
Tarea 1: Prepara el entorno
Al igual que en los labs anteriores, el primer paso es generar datos para que la canalización los procese. Abre el entorno del lab y genera los datos como lo hiciste anteriormente:
Abre el lab adecuado
Si aún no lo has hecho, crea una terminal nueva en tu IDE y, luego, copia y pega el siguiente comando:
# Change directory into the lab
cd 4_SQL_Batch_Analytics/labs
# Download dependencies
mvn clean dependency:resolve
export BASE_DIR=$(pwd)
Configura el entorno de datos:
# Create GCS buckets and BQ dataset
cd $BASE_DIR/../..
source create_batch_sinks.sh
# Generate event dataflow
source generate_batch_events.sh
# Change to the directory containing the practice version of the code
cd $BASE_DIR
Asegúrate de que estén habilitadas las APIs de Data Catalog:
gcloud services enable datacatalog.googleapis.com
Haz clic en Revisar mi progreso para verificar el objetivo.
Configurar el entorno de datos
Tarea 2: Agrega dependencias de SQL a la canalización
Abre BatchUserTrafficSQLPipeline.java en tu IDE, que se puede encontrar en 4_SQL_Batch_Analytics/labs/src/main/java/com/mypackage/pipeline.
Esta canalización ya contiene el código necesario para aceptar las opciones de la línea de comandos de la ruta de entrada y un nombre de una tabla de salida, así como el código para leer los eventos de Google Cloud Storage, analizarlos y escribir resultados en BigQuery. Sin embargo, faltan algunas partes importantes.
Al igual que en el lab anterior, el siguiente paso de la canalización es agregar los eventos según cada user_id único y contar las páginas vistas de cada uno. Sin embargo, esta vez realizarás la agregación con SQL. Para ello, usarás SqlTransform en lugar de las transformaciones basadas en Java.
Antes de implementar esto, deberás agregar una dependencia de SQL a tu canalización.
Para completar esta tarea, abre el archivo pom.xml de la canalización, ubicado en 4_SQL_Batch_Analytics/labs/, y agrega la siguiente dependencia:
El método SqlTransform.query(queryString) es la única API para crear una PTransform a partir de una representación de cadena de la consulta en SQL. Puedes aplicar esta PTransform a una sola PCollection o a una PCollectionTuple que contenga varias PCollections (más adelante obtendrás más información sobre PColllectionTuples).
Cuando se aplica a una sola PCollection, puede revisarse a través del nombre de tabla PCOLLECTION de la consulta:
El resultado es un objeto Row con un esquema asociado que puede mutarse aún más en las Transformaciones de SQL o en otras PTransform de Java, o bien almacenarse en un receptor.
Para completar esta tarea, agrega una SQLTransform a tu canalización y proporciona una cadena de SQL para agregar la cantidad de hits por user_id y asignarle el nombre “pageviews”.
Si lo deseas, también puedes realizar agregaciones adicionales. A modo de referencia, esta era la PTransform que se usaba anteriormente:
Si no sabes cómo hacerlo, consulta la solución aquí para ver sugerencias.
Implementa una rama para almacenar datos sin procesar
Es recomendable que almacenes todos los resultados sin procesar en BigQuery para realizar agregaciones de SQL adicionales más adelante en la IU.
Para completar esta tarea, vuelve a configurar tu canalización con una rama que escriba los objetos CommonLog sin procesar directamente en BigQuery, en un nombre de tabla al que haga referencia una opción de la línea de comandos rawTableName.
Para ello, finaliza la primera rama de la canalización con un punto y coma y, luego, inicia cada rama con logs.apply();. No olvides agregar esta nueva línea de comandos a las opciones de canalización junto con inputPath y aggregateTableName. Recuerda también que debes cambiar el tipo de sugerencia en BigQueryIO.<Object>write().
Ve a Menú de navegación > Dataflow para ver el estado de tu canalización.
Una vez que esta haya finalizado, ve a la IU de BigQuery para consultar las dos tablas resultantes. Asegúrate de que logs.raw exista y que se hayan propagado los datos, ya que lo necesitarás más adelante en el lab.
Haz clic en Revisar mi progreso para verificar el objetivo.
Agregar tráfico del sitio por usuario con SQL
Finalice su lab
Cuando haya completado el lab, haga clic en Finalizar lab. Google Cloud Skills Boost quitará los recursos que usó y limpiará la cuenta.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Neutral
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2020 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usa una ventana de navegación privada o de Incógnito para ejecutar el lab. Así
evitarás cualquier conflicto entre tu cuenta personal y la cuenta
de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
En este lab, agregarás instrucciones de SQL a la canalización de Beam escrita anteriormente que agrega el tráfico del sitio por usuario y por minuto. También ejecutarás un trabajo de Beam SQL desde la IU de BigQuery.
Duración:
2 min de configuración
·
Acceso por 120 min
·
120 min para completar
 ), selecciona IAM y administración > IAM.
), selecciona IAM y administración > IAM.