![[データセットの作成] ページ。[データセット ID]、データ ロケーションの各欄が入力されており、テーブルの有効期限がなしに設定されている。](https://cdn.qwiklabs.com/e8L4jEZB8huExxJGFmhKl07oTgeEFs2PEOOL7LDBr2U%3D)


始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create a training dataset
/ 5
Improving the model through feature engineering
/ 5
Make predictions
/ 5
Examine model weights
/ 5
BigQuery は、Google が提供する低コスト、NoOps のフルマネージド分析データベースです。BigQuery では、インフラストラクチャを所有して管理したりデータベース管理者を置いたりすることなく、テラバイト単位の大規模なデータでクエリを実行できます。また、SQL が採用されており、従量課金制というメリットもあります。そのため、ユーザーは有用な情報を得るためのデータの分析に専念することができます。
BigQuery の機能である BigQuery 機械学習を使用すれば、データア ナリストは最小限のコーディングで機械学習モデルの作成、トレーニング、評価、予測が可能になります。
このラボでは、ロンドンの自転車データセットを使用して、レンタル時間を予測する回帰モデルを BigQuery ML で構築します。耐久性の高い通勤用自転車と、スピードは出るものの壊れやすいロードバイクの 2 種類の自転車の在庫を持つ自転車レンタル会社を営んでいるとします。自転車レンタル時間が長時間になる可能性がある場合は、ロードバイクの在庫が必要ですが、短時間になる可能性がある場合は、通勤用自転車の在庫が必要です。したがって、自転車の適切な在庫を保持するシステムを構築するには、自転車レンタル時間を予測する必要があります。
このラボでは、次のタスクの実行方法について学びます。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
Qwiklabs にシークレット ウィンドウでログインします。
ラボのアクセス時間(例: 1:15:00)に注意し、時間内に完了できるようにしてください。
一時停止機能はありません。必要な場合はやり直せますが、最初からになります。
準備ができたら、[ラボを開始] をクリックします。
ラボの認証情報(ユーザー名とパスワード)をメモしておきます。この情報は、Google Cloud Console にログインする際に使用します。
[Google Console を開く] をクリックします。
[別のアカウントを使用] をクリックし、このラボの認証情報をコピーしてプロンプトに貼り付けます。
他の認証情報を使用すると、エラーが発生したり、料金の請求が発生したりします。
利用規約に同意し、再設定用のリソースページをスキップします。
ML の問題を解決するために行う最初のステップは、ML モデルの策定、つまり、モデルの特徴量とラベルを決めることです。最初のモデルの目標は、自転車レンタルの履歴データセットに基づいてレンタル時間を予測することであるため、ラベルはレンタル時間になります。
自転車がレンタルされるステーション、曜日、時刻に応じてレンタル時間が異なると考える場合は、これらを特徴量とすることができます。ただし、これらの特徴量を使用してモデルを作成する前に、こうした要素がラベルに影響を与えることを確認することをおすすめします。
機械学習モデルのための特徴量を見つけ出すことを、特徴量エンジニアリングと呼びます。特徴量エンジニアリングは、多くの場合、正確な ML モデルを構築するうえで特に重要な部分であり、使用するアルゴリズムの決定やハイパーパラメータの調整よりも大きな影響を与える可能性があります。優れた特徴量エンジニアリングのためには、データとドメインに関する深い理解が必要です。多くの場合、それは仮説テストのプロセスです。つまり、ある特徴量を思いついたら、それがうまく機能するか(ラベルとの間に相互情報量があるか)を確認してから、モデルに追加します。機能しない場合は、別の特徴量を検討します。
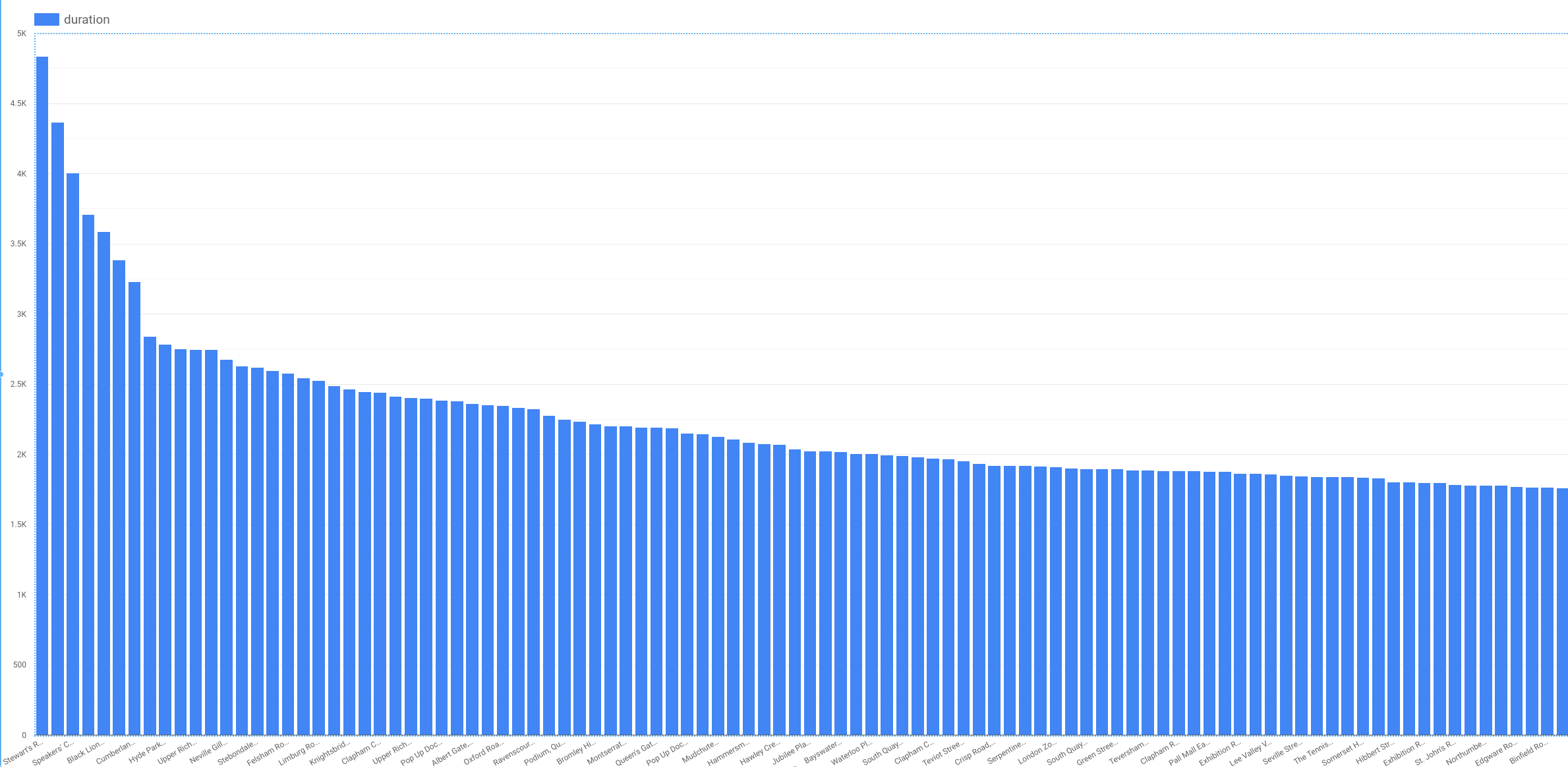
レンタル時間がステーションごとに異なるかどうかを確認するには、データポータルで次のクエリの結果を可視化します。
[グラフ] タブで [縦棒グラフ] を選択します。
右側のメニューの [データ] タブで、次のように設定します。
次のようなプロットになります。
いくつかのステーションに長いレンタル時間(3,000 秒以上)が関連付けられていることがわかります。しかし、大部分のステーションでのレンタル時間は、比較的狭い範囲内です。ロンドンのすべてのステーションに狭い範囲内のレンタル時間が関連していることから、レンタルが開始されたステーションは特徴量として適切ではありません。しかしこの問題においては、グラフが示すように、start_station_name が重要です。
自転車がレンタルされた時点には、どこに返却されるかは予測できないため、end_station_name は特徴量として使用できません。将来のイベントを予測する機械学習モデルを作成する際は、予測を行う時点で未知の列を使用しないように注意する必要があります。この時間と因果関係の条件により、使用できる特徴量が制限されます。
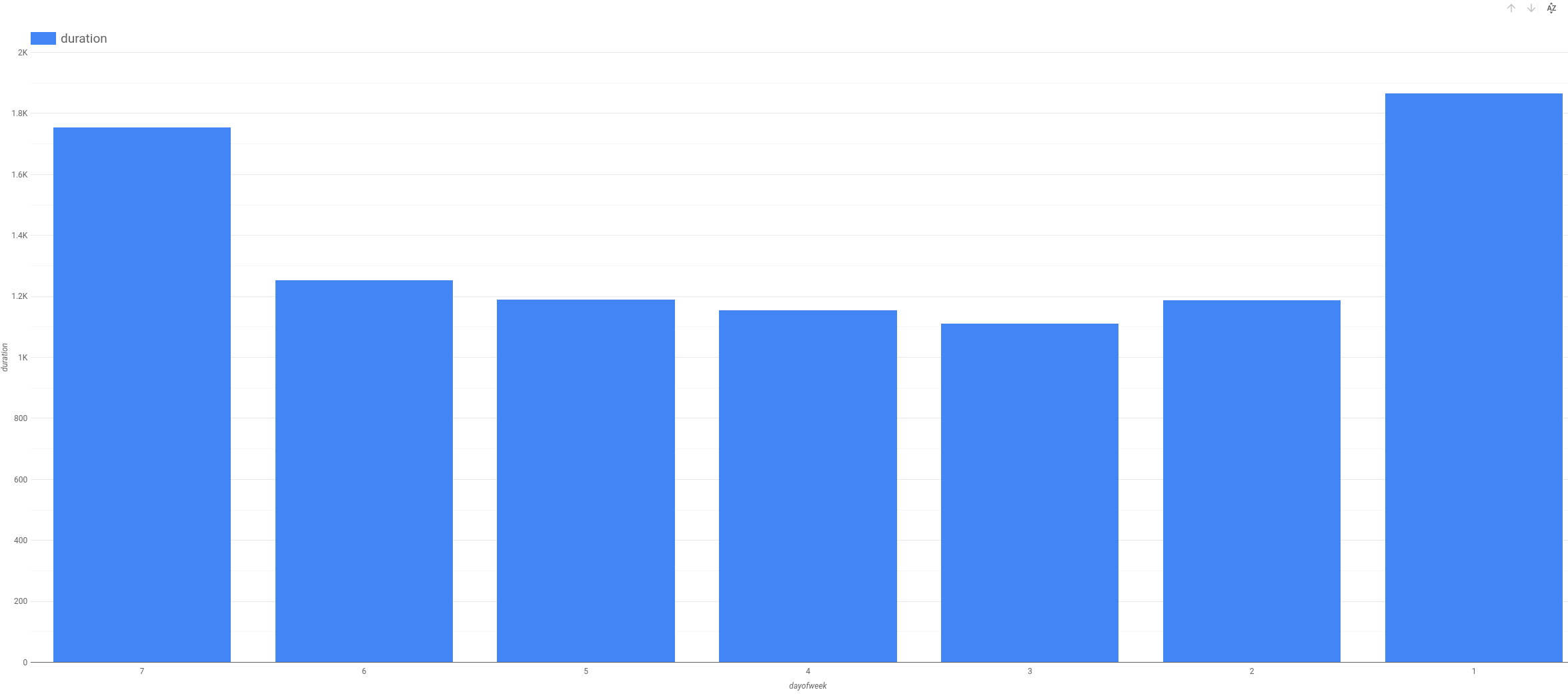
次の特徴量の候補についても、プロセスは同様です。dayofweek(または、同様に hourofday)が重要かどうかを確認できます。
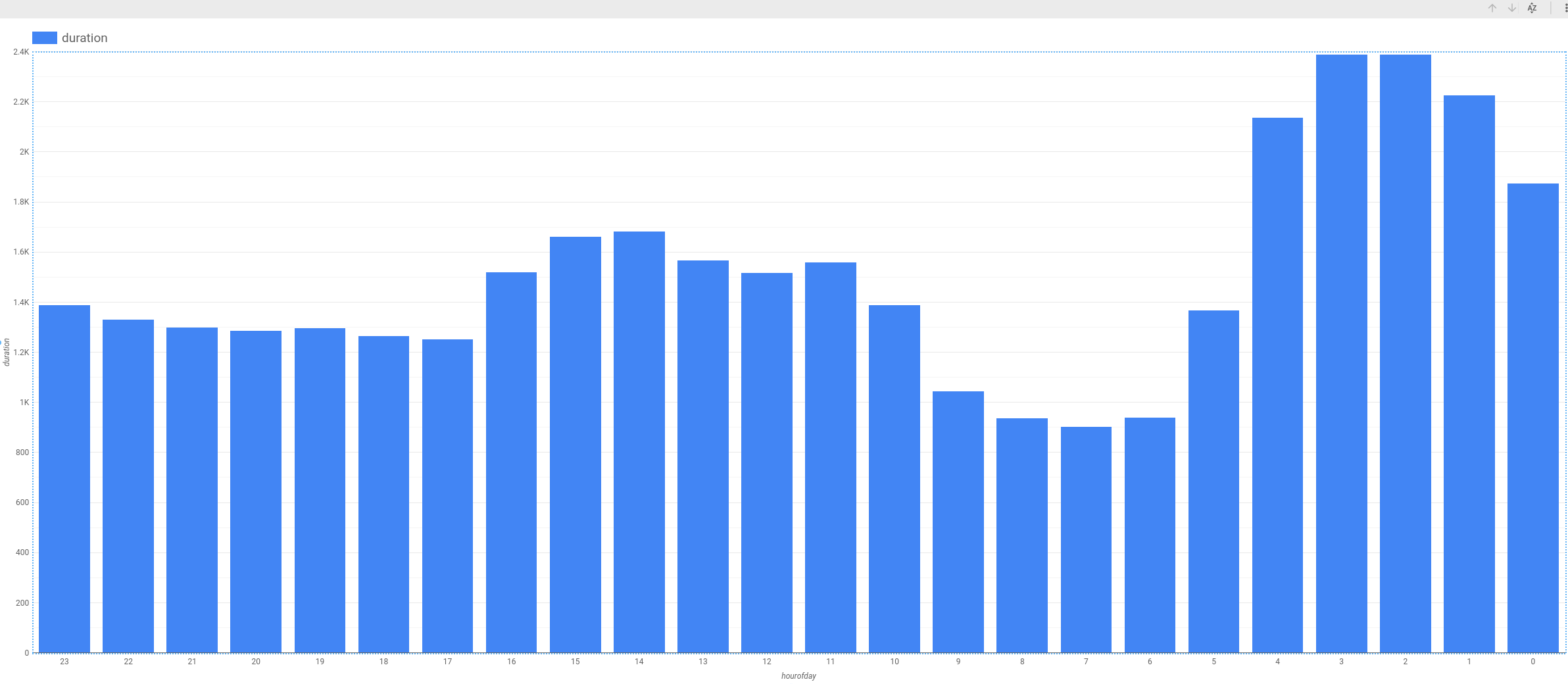
時刻については、次のように可視化されます。
曜日によっても時刻によっても、レンタル時間が異なることがわかります。平日よりも週末(1 日目と 7 日目)の方が、レンタル時間が長いようです。同様に、早朝と午後の半ばにレンタル時間が長くなります。したがって、dayofweek と hourofday は両方とも特徴量の候補として適切です。
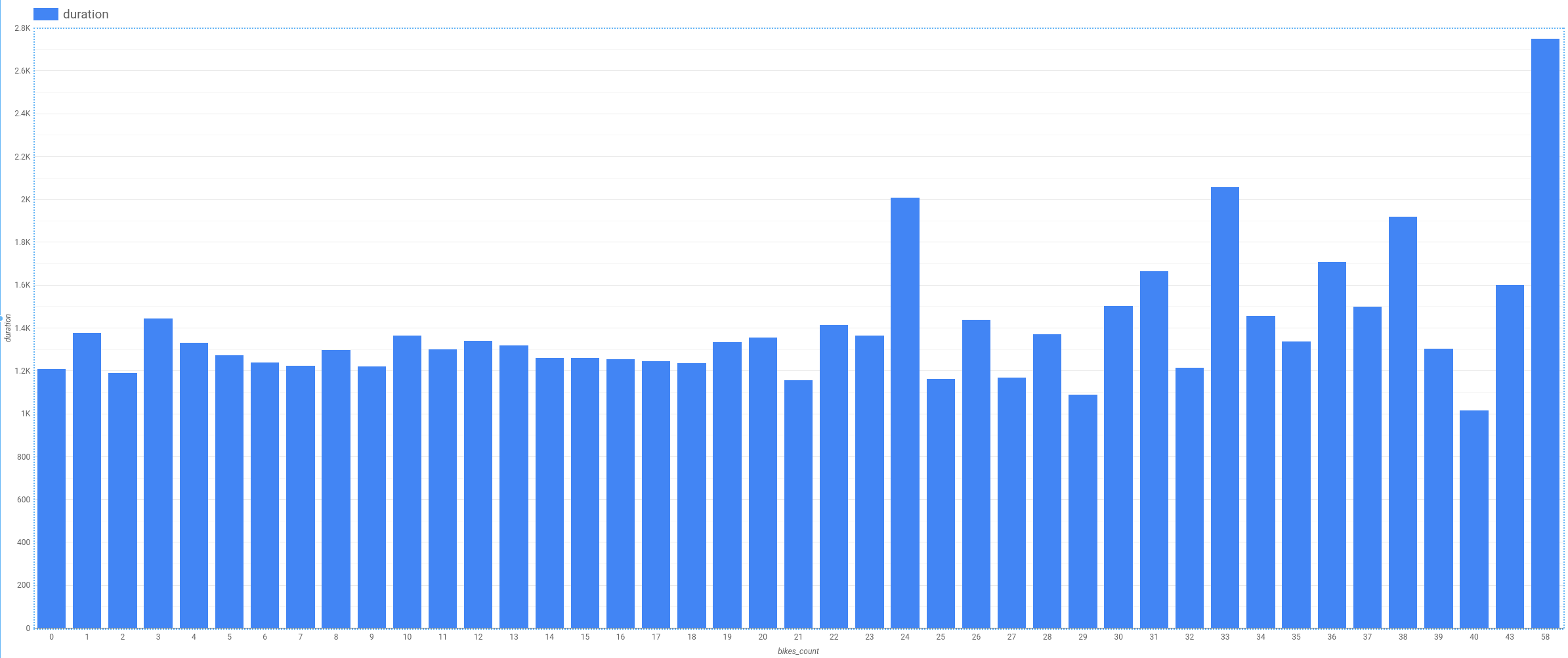
その他の特徴量の候補としてステーションの自転車台数があります。自転車をレンタルしたステーションの自転車台数が少ない場合、自転車をより長時間借りたままにしておくと仮定します。
関係には目に見える傾向がなく有用な情報を示していない(時刻などと比較して)ことがわかります。これは、自転車台数が特徴量の候補として適切ではないことを示しています。
自転車データセットと、さまざまな列とラベル列との関係の調査結果に基づき、選択した特徴量とラベルを抽出することによってトレーニング データセットを準備できます。
特徴量列は数値(INT64、FLOAT64 など)またはカテゴリ(STRING)のいずれかである必要があります。特徴量が数値であるものの、カテゴリとして扱う必要がある場合は、その数値を文字列に型変換する必要があります。整数である dayofweek と hourofday 列(それぞれ 1~7 と 0~23 の範囲)を文字列に型変換しているのはこのためです。
データを準備する際に計算コストが高い変換や結合が行われる場合は、テスト中に同じ作業を繰り返さなくても済むように、準備したトレーニング データをテーブルとして保存しておくことをおすすめします。変換は簡単でも、クエリ自体の実行時間が長い場合は、クエリをビューとして保存しておくと、繰り返し作業を回避できます。
ここで扱うクエリはシンプルで短いため、保存は行いません(煩雑さを避けるため)。
bike_model というデータセットを BigQuery で作成します。ML モデルをトレーニングしてデータセット bike_model に保存するために、CREATE TABLE と同様に動作する CREATE MODEL を呼び出します。予測を行おうとしているラベルが数値であるため、これは回帰問題です。このため、OPTIONS では linear_reg をモデルタイプとして選択するのが最適です。
モデルのトレーニングには 2~3 分かかります。
平均絶対誤差は 1,025 秒(約 17 分)です。つまり、自転車レンタル時間を、約 17 分の平均誤差で予測可能であると期待できます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
見つけた特徴量を別の方法で表すことができます。たとえば、レンタルの dayofweek と duration の関係を調べた際に、平日よりも週末のほうがレンタル時間が長いことがわかりました。したがって、dayofweek の未加工の値を特徴量として扱う代わりに、複数の dayofweek の値を統合して weekday カテゴリに統合することで、この分析情報を使用できます。
このモデルの平均絶対誤差は、元のモデルの 1,025 秒より小さい 966 秒になり、モデルを改良することができました。
hourofday と duration の関係に基づいて、変数を (-inf,5)、[5,10)、[10,17)、[17,inf) の 4 つのビンにバケット化してみましょう。
このモデルの平均絶対誤差は、weekday-weekend モデルの 966 秒より小さい 904 秒になり、モデルをさらに改良することができました。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ここまで作成してきたモデルには、いくつかのデータ変換が含まれています。トレーニング時に行われた一連の変換が BigQuery で記憶され、予測時に自動的に適用されると便利でしょう。そこで、TRANSFORM 句を使用してみます。
この場合、作成したモデルには、duration を予測するための start_station_name と start_date が必要です。変換が保存され、指定された元データに対して実行されて、モデルに入力する特徴量が作成されます。前処理関数をすべて TRANSFORM 句内に配置する主な利点は、モデルのクライアントがどのような前処理が実行されたかを知る必要がないということです。
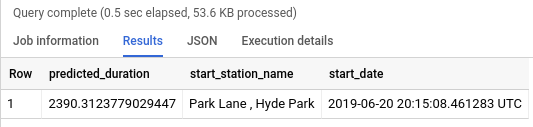
TRANSFORM 句に使用した次のクエリを実行して、BigQuery ML モデルを構築します。TRANSFORM 句を配置して、Park Lane での現時点からのレンタル時間を予測する次のクエリを入力します(結果はそれぞれ異なります)。[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
線形回帰モデルでは、入力に重みが組み合わされた合計として出力が予測されます。多くの場合、本番環境でモデルの重みを使用する必要があります。
次のクエリを使用して、モデルの重みを調べます(またはエクスポートします)。
数値特徴量には単一の重みが課せられ、カテゴリ特徴量には存在する可能性のある値ごとの重みが課せられます。たとえば、特徴量 dayofweek には次の重みがあります。
つまり、平日の場合、予測レンタル時間全体に対するこの特徴量の割り当ては 1,709 秒です(最適なパフォーマンスを提供する重みは一意ではありません。そのため、異なる値が得られる場合があります)。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ラボでの学習が完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Qwiklabs から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバック、ご提案、修正が必要な箇所については、[サポート] タブからお知らせください。
Copyright 2020 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください