Neste laboratório, você vai usar o Dataflow para coletar eventos de tráfego de dados simulados do sensor de tráfego (disponíveis no Google Cloud Pub/Sub), processá-los em uma média utilizável e armazenar os dados brutos no BigQuery para análise posterior. Você vai aprender a iniciar um pipeline do Dataflow, monitorá-lo e, por último, otimizá-lo.
Observação: na criação deste módulo, os pipelines de streaming não estavam disponíveis no SDK do Dataflow para Python. Por isso, os laboratórios de streaming estão escritos em Java.
Objetivos
Neste laboratório, você vai executar as seguintes tarefas:
Iniciar o Dataflow e gerar um job
Entender como os elementos de dados passam pelas transformações de um pipeline do Dataflow
Conectar o Dataflow ao Pub/Sub e ao BigQuery
Observar e compreender como o escalonamento automático do Dataflow ajusta os recursos de computação para processar os dados de entrada de maneira ideal
Saber onde encontrar informações de registro criadas pelo Dataflow
Analisar métricas e criar alertas e painéis com o Cloud Monitoring
Configuração
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Verifique as permissões do projeto
Antes de começar a trabalhar no Google Cloud, veja se o projeto tem as permissões corretas no Identity and Access Management (IAM).
No console do Google Cloud, em Menu de navegação (), selecione IAM e administrador > IAM.
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que está no Menu de navegação > Visão geral do Cloud > Painel.
Observação: se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
No console do Google Cloud, em Menu de navegação, clique em Visão geral do Cloud > Painel.
Copie o número do projeto, por exemplo, 729328892908.
Em Menu de navegação, clique em IAM e administrador > IAM.
Clique em Permitir acesso, logo abaixo de Visualizar por principais na parte de cima da tabela de papéis.
Substitua {project-number} pelo número do seu projeto.
Em Papel, selecione Projeto (ou Básico) > Editor.
Clique em Save.
Tarefa 1: preparação
Você vai executar um simulador de sensor na VM de treinamento. No laboratório 1, é necessário configurar manualmente os componentes do Pub/Sub. Neste laboratório, muitos processos são automatizados.
Abra o terminal SSH e acesse a VM de treinamento
No console, acesse o menu de navegação () e clique em Compute Engine > Instâncias de VM.
Encontre a linha com a instância chamada training-vm.
À direita, na coluna Conectar, clique em SSH para abrir uma janela de terminal.
Neste laboratório, você adicionará comandos da CLI em training-vm.
Verifique se a inicialização foi concluída
A instância training-vm está instalando alguns softwares em segundo plano.
Para confirmar que as instalações foram concluídas, verifique o conteúdo do novo diretório:
ls /training
Se a resposta ao comando de lista (Is) for parecida com a imagem abaixo, a configuração estará pronta. Caso a lista não esteja completa, espere alguns minutos e tente de novo.
Observação: pode levar de 2 a 3 minutos para todas as ações em segundo plano serem concluídas.
Faça o download do repositório do código
Em seguida, atualize o repositório do código para usar neste laboratório:
No terminal SSH de training-vm, digite o seguinte:
source /training/project_env.sh
Esse script define as variáveis de ambiente DEVSHELL_PROJECT_ID e BUCKET.
Clique em Verificar meu progresso para conferir o objetivo.
Fazer o download de um repositório de código
Tarefa 2: criar um conjunto de dados do BigQuery e um bucket do Cloud Storage
O pipeline do Dataflow será criado e gravado depois em uma tabela no conjunto de dados do BigQuery.
Abra o BigQuery no Console do Cloud
No Console do Google Cloud, selecione o menu de navegação > BigQuery:
Você vai ver a caixa de mensagem Olá! Este é o BigQuery no Console do Cloud. Ela tem um link para o guia de início rápido e lista as atualizações da interface.
Clique em Concluído.
Criar um conjunto de dados do BigQuery
Para criar um conjunto de dados, clique no ícone Ver ações ao lado do ID do projeto e selecione Criar conjunto de dados.
Nomeie o ID do conjunto de dados como demos, não mexa nas outras opções e clique em Criar conjunto de dados.
Verifique o bucket do Cloud Storage
Já deve haver um bucket com o mesmo nome do ID do projeto.
No console, acesse o Menu de navegação () e clique em Cloud Storage > Buckets.
Atente-se aos seguintes valores:
Propriedade
Valor
(digite o valor ou selecione a opção conforme especificado)
Nome
Classe de armazenamento padrão
Regional
Local
Clique em Verificar meu progresso para conferir o objetivo.
Criar um conjunto de dados do BigQuery
Tarefa 3: simular os dados do sensor de tráfego no Pub/Sub
No terminal SSH da training_vm, inicie o simulador do sensor. O script lê os dados de amostra de um arquivo csv e os publica no Pub/Sub:
/training/sensor_magic.sh
Esse comando enviará 1 hora de dados em 1 minuto. Deixe o script executando no terminal atual.
Abra um segundo terminal SSH e conecte-se à VM de treinamento
No canto superior direito do terminal SSH de training-vm, clique no botão em forma de engrenagem () e selecione Nova conexão para training-vm no menu suspenso. Uma nova janela de terminal será aberta.
A nova sessão do terminal não terá as variáveis de ambiente necessárias. Execute o comando a seguir para configurá-las.
No novo terminal SSH de training-vm, digite o seguinte:
source /training/project_env.sh
Clique em Verificar meu progresso para conferir o objetivo.
Simular os dados do sensor de tráfego no Pub/Sub
Tarefa 4: iniciar o pipeline do Dataflow
Verifique se a API Google Cloud Dataflow está ativada para o projeto
Para garantir que as APIs e permissões sejam definidas adequadamente, execute o bloco de código abaixo no Cloud Shell.
O script requer três argumentos: project id, bucket name, classname.
O quarto argumento opcional é o options. Vamos abordar o argumento options neste laboratório.
project id
bucket name
classname
<arquivo java que executa agregações>
options
<opções>
Você pode escolher um dos quatro arquivos Java para classname. Cada um lê os dados de tráfego do Pub/Sub e executa diferentes agregações/cálculos.
Acesse o diretório Java. Identifique o arquivo de origem AverageSpeeds.java.
cd ~/training-data-analyst/courses/streaming/process/sandiego/src/main/java/com/google/cloud/training/dataanalyst/sandiego
cat AverageSpeeds.java
O que o script faz?
Feche o arquivo para continuar. Recomendamos consultar esse código-fonte ao executar o aplicativo. Para facilitar o acesso, abra uma nova guia no navegador e confira o arquivo AverageSpeeds.java no GitHub.
Copie e cole o URL abaixo em uma nova guia do navegador para conferir o código-fonte no GitHub:
Deixe a nova guia aberta. Você precisará consultar o código-fonte em outra etapa deste laboratório.
Volte ao terminal SSH de training-vm. Execute os comandos abaixo para o pipeline Dataflow ler do PubSub e gravar no BigQuery:
cd ~/training-data-analyst/courses/streaming/process/sandiego
export REGION={{{project_0.startup_script.gcp_region|Lab GCP Region}}}
./run_oncloud.sh $DEVSHELL_PROJECT_ID $BUCKET AverageSpeeds
Esse script usa maven para criar um pipeline de streaming do Dataflow em Java.
Exemplo de conclusão:
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 45.542 s
[INFO] Finished at: 2018-06-08T16:51:30+00:00
[INFO] Final Memory: 56M/216M
[INFO] ------------------------------------------------------------------------
Tarefa 5: analisar o pipeline
O pipeline do Dataflow lê mensagens de um tópico do Pub/Sub, analisa o JSON da mensagem de entrada, gera uma resposta principal e grava no BigQuery.
Volte para a guia do console no navegador. No Menu de navegação (), clique em Dataflow e no job para monitorar o progresso.
Exemplo:
Observação: se o job do Dataflow falhar, execute o comando ./run_oncloud.sh $DEVSHELL_PROJECT_ID $BUCKET AverageSpeeds outra vez.
Quando o pipeline estiver em execução, clique no Menu de navegação () e em Pub/Sub > Tópicos.
Observe a linha Nome do tópico no tópico sandiego.
Volte ao Menu de navegação () e clique em Dataflow e no job.
Compare o código na guia do navegador do GitHub, AverageSpeeds.java, com o gráfico do pipeline na página do seu job do Dataflow.
Encontre a etapa do pipeline GetMessages no gráfico e o código correspondente no arquivo AverageSpeeds.java. Essa é a etapa do pipeline que faz a leitura do tópico do Pub/Sub. Isso cria uma coleção de Strings, que corresponde às mensagens do Pub/Sub que foram lidas.
Você vê a assinatura criada?
Como o código recupera mensagens do Pub/Sub?
Encontre a etapa do pipeline Time Window no gráfico e no código. Nessa etapa do pipeline, criamos uma janela com uma duração especificada nos parâmetros do pipeline (janela deslizante, neste caso). Essa janela acumulará os dados de tráfego da etapa anterior até o fim da janela, e os passará para as próximas etapas de transformações adicionais.
Qual é o intervalo da janela?
Com que frequência uma nova janela é criada?
Encontre as etapas BySensor e AvgBySensor do pipeline no gráfico. Em seguida, localize o snippet de código correspondente no arquivo AverageSpeeds.java. BySensor agrupa todos os eventos da janela por ID de sensor. Já AvgBySensor calcula a velocidade média de cada agrupamento.
Encontre a etapa do pipeline ToBQRow no gráfico e no código. Essa etapa apenas cria uma "linha" com a média calculada na etapa anterior com as informações de faixa.
Observação: é possível realizar outras ações na etapa ToBQRow. Por exemplo, é possível comparar a média calculada com o limite predefinido e registrar os resultados no Cloud Logging.
Encontre BigQueryIO.Write no gráfico do pipeline e no código-fonte. Essa etapa grava a linha do pipeline em uma tabela do BigQuery. Como escolhemos a disposição de gravação WriteDisposition.WRITE_APPEND, novos registros serão anexados à tabela.
Volte para a guia da IU da Web do BigQuery. Atualize o navegador.
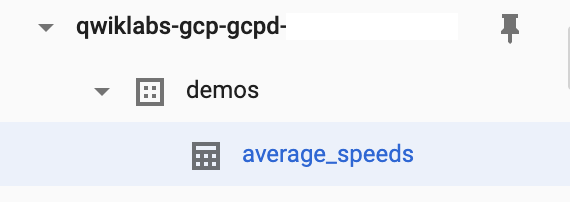
Localize o nome do seu projeto e o conjunto de dados de demonstrações que você criou. Agora a pequena seta à esquerda do nome do conjunto de dados demos está ativa. Quando você clicar nessa seta, verá a tabela average_speeds.
A tabela average_speeds pode demorar alguns minutos para aparecer no BigQuery.
Exemplo:
Clique em Verificar meu progresso para conferir o objetivo.
Iniciar o pipeline do Dataflow
Tarefa 6: definir taxas de capacidade de processamento
Uma atividade comum no monitoramento e aprimoramento de pipelines do Dataflow é descobrir quantos elementos o pipeline processa por segundo, qual é o intervalo do sistema e quantos elementos de dados foram processados até um determinado momento. Nesta atividade, você vai aprender a encontrar informações sobre tempo e elementos processados no Cloud Console.
Volte para a guia do Console no navegador. No Menu de navegação (), clique em Dataflow e no job para monitorar o progresso. Seu nome de usuário vai estar no nome do pipeline.
Selecione o nó GetMessages do pipeline no gráfico e veja as métricas da etapa à direita.
A métrica Intervalo do sistema (System Lag) é importante para os pipelines de streaming. Ela representa o tempo total de espera do processamento dos elementos de dados desde o momento em que eles "chegam" à entrada da etapa de transformação.
A métrica Elementos adicionados (Elements Added) nas coleções de saída informa quantos elementos de dados saíram dessa etapa. Na etapa Ler mensagem do Pub/Sub do pipeline, ela também representa o número de mensagens do Pub/Sub lidas no tópico pelo conector de E/S do Pub/Sub.
Selecione o nó Time Window no gráfico. Observe como a métrica "Elementos adicionados" nas coleções de entrada da etapa Janela de tempo e nas coleções de saída da etapa anterior GetMessages correspondem.
Tarefa 7: revisar a saída do BigQuery
Volte à interface da Web do BigQuery.
Observação: é possível que as tabelas e os dados de streaming não sejam exibidos imediatamente e o recurso "Visualização" não esteja disponível para os dados que ainda estão no buffer de streaming. Se você clicar em Visualização, a mensagem "Esta tabela tem registros no buffer de streaming que talvez não apareçam na visualização" vai aparecer. Você pode continuar executando consultas para ver os dados.
Na janela Editor de consultas digite (ou copie e cole) a consulta a seguir. Ela pode ser usada para observar a saída do job do Dataflow. Clique em Executar:
SELECT *
FROM `demos.average_speeds`
ORDER BY timestamp DESC
LIMIT 100
Encontre a última atualização da tabela executando este SQL:
SELECT
MAX(timestamp)
FROM
`demos.average_speeds`
Em seguida, use o recurso de viagem no tempo do BigQuery para consultar o estado da tabela em um momento anterior.
A consulta a seguir retornará um subconjunto de linhas da tabela average_speeds de 10 minutos atrás.
Se a consulta solicitar linhas, mas a tabela não existir no momento consultado, a seguinte mensagem de erro será exibida:
Invalid snapshot time 1633691170651 for Table PROJECT:DATASET.TABLE__
Caso isso aconteça, reduza o escopo da viagem no tempo diminuindo o valor dos minutos:
SELECT *
FROM `demos.average_speeds`
FOR SYSTEM_TIME AS OF TIMESTAMP_SUB(CURRENT_TIMESTAMP, INTERVAL 10 MINUTE)
ORDER BY timestamp DESC
LIMIT 100
Tarefa 8: conhecer e entender o escalonamento automático
Saiba como o Dataflow escalona o número de workers para processar o backlog das mensagens de entrada do Pub/Sub.
Volte para a guia do Console no navegador. No Menu de navegação (), clique em Dataflow e no job do pipeline.
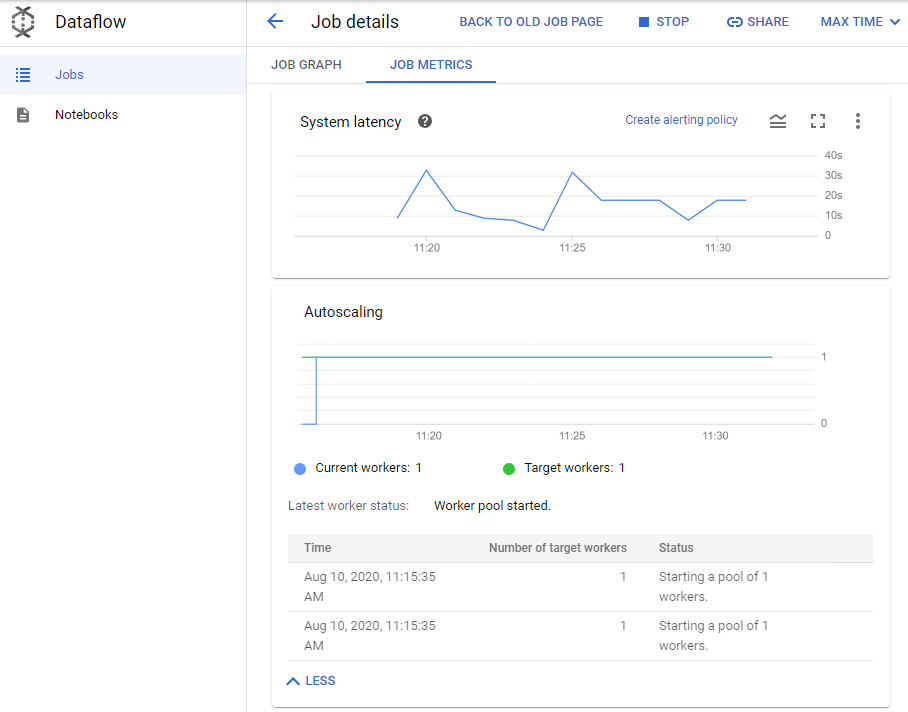
Acesse o painel Métricas do job à direita e revise a seção Escalonamento automático. Quantos workers estão sendo usados no momento para processar mensagens no tópico do Pub/Sub?
Clique em Mais históricos e verifique quantos workers foram usados em vários momentos durante a execução do pipeline.
Os dados do simulador do sensor de tráfego iniciado no começo do laboratório criam centenas de mensagens por segundo no tópico do Pub/Sub. O Dataflow aumentará o número de workers para manter os intervalos do sistema do pipeline em níveis ideais.
Clique em Mais históricos. Em Pool de workers, você pode ver como o Dataflow alterou o número de workers. Observe a coluna Status, que explica o motivo da alteração.
Tarefa 9: atualizar o script de simulação de dados do sensor
Observação: o ambiente do laboratório de treinamento tem limites de cota. Se a execução do script de simulação de dados do sensor levar muito tempo, ela vai ultrapassar o limite da cota, suspendendo as credenciais da sessão.
Volte ao terminal SSH de training_vm em que o script de dados do sensor está em execução.
Se a mensagem INFO: Publishing aparecer, significa que o script ainda está em execução. Pressione CTRL+C para interrompê-lo. Em seguida, execute este comando para reiniciar o script:
cd ~/training-data-analyst/courses/streaming/publish
./send_sensor_data.py --speedFactor=60 --project $DEVSHELL_PROJECT_ID
As etapas 3 a 8 só são necessárias se você não conseguir interromper o script com CTRL+C. Se o script tiver atingido o limite da cota, você vai receber repetidamente uma mensagem de erro dizendo que "não foi possível atualizar as credenciais", e pressionar CTRL+C não vai funcionar. Neste caso, feche o terminal SSH e siga as etapas 3 a 8 abaixo.
Abra um novo terminal SSH. A nova sessão terá a cota renovada.
No console, acesse o menu de navegação () e clique em Compute Engine > Instâncias de VM.
Encontre a linha com a instância chamada training-vm.
À direita, na coluna Conectar, clique em SSH para abrir uma nova janela de terminal.
No terminal SSH de training_vm, digite o seguinte para criar variáveis de ambiente:
source /training/project_env.sh
Use estes comandos para iniciar um novo simulador do sensor:
cd ~/training-data-analyst/courses/streaming/publish
./send_sensor_data.py --speedFactor=60 --project $DEVSHELL_PROJECT_ID
Tarefa 10: integração com o Cloud Monitoring
Com o Cloud Monitoring integrado ao Dataflow, os usuários podem acessar métricas do job do Dataflow no Cloud Monitoring, como "Intervalos do Sistema" (para jobs de streaming), "Status do Job" (não concluído ou concluído), "Quantidade de Elementos" e "Contadores de Usuários".
Atributos de integração do Cloud Monitoring
Conheça as métricas do Dataflow: navegue pelas métricas de pipeline disponíveis no Dataflow e veja os gráficos.
Algumas métricas comuns do Dataflow
Métrica
Atributo
Status do job
Status do job (Failed, Successful), reportado como um enum a cada 30 segundos e na atualização.
Tempo decorrido
Tempo decorrido do job, medido em segundos e reportado a cada 30 segundos.
Intervalo do sistema
Intervalo máximo em todo o pipeline, reportado em segundos.
Número atual de vCPUs
O número atual de CPUs virtuais usadas pelo job e atualizado com a mudança do valor.
Número de bytes estimados
Número de bytes processados por PCollection.
Gráfico com métricas do Dataflow nos painéis do Cloud Monitoring: crie painéis e gráficos de séries temporais com as métricas do Dataflow.
Configuração de alertas: defina limites para as métricas no job ou no grupo de recursos e receba alertas quando os valores especificados forem atingidos. Os alertas do Cloud Monitoring notificam várias condições, como atrasos no sistema de streaming ou jobs com falha.
Monitoramento de métricas definidas pelo usuário: além das métricas do próprio Dataflow, ele também mostra as métricas definidas pelo usuário (agregadores de SDK) como contagens personalizadas na interface do Cloud Monitoring que são disponibilizadas para a criação de gráficos e alertas. Qualquer agregador definido em um pipeline do Dataflow será reportado para o Cloud Monitoring como uma métrica personalizada. O Dataflow vai definir uma nova métrica personalizada em nome do usuário e reportar atualizações incrementais para o Cloud Monitoring a cada 30 segundos.
Tarefa 11: conhecer as métricas
O Cloud Monitoring é um serviço separado no Google Cloud. Por isso, você terá que fazer algumas configurações antes de inicializar o serviço para sua conta de laboratório.
Criar um espaço de trabalho do Monitoring
Agora você vai configurar um espaço de trabalho no Monitoring vinculado ao seu projeto no Google Cloud. Siga estas etapas para criar uma conta com acesso a um teste sem custo do Monitoring.
No console do Cloud, clique em Menu de navegação > Monitoring.
Aguarde o provisionamento do espaço de trabalho.
Quando o painel do Monitoring for aberto, o espaço de trabalho estará pronto.
No painel à esquerda, clique em Metrics Explorer.
Em Metrics Explorer, na opção Recurso e métrica clique em Selecionar uma métrica.
Selecione Dataflow Job > Job. Será exibida uma lista de métricas disponíveis relacionadas ao Dataflow. Selecione Atraso na marca-d'água dos dados e clique em Aplicar.
O Cloud Monitoring cria um gráfico no lado direito da página.
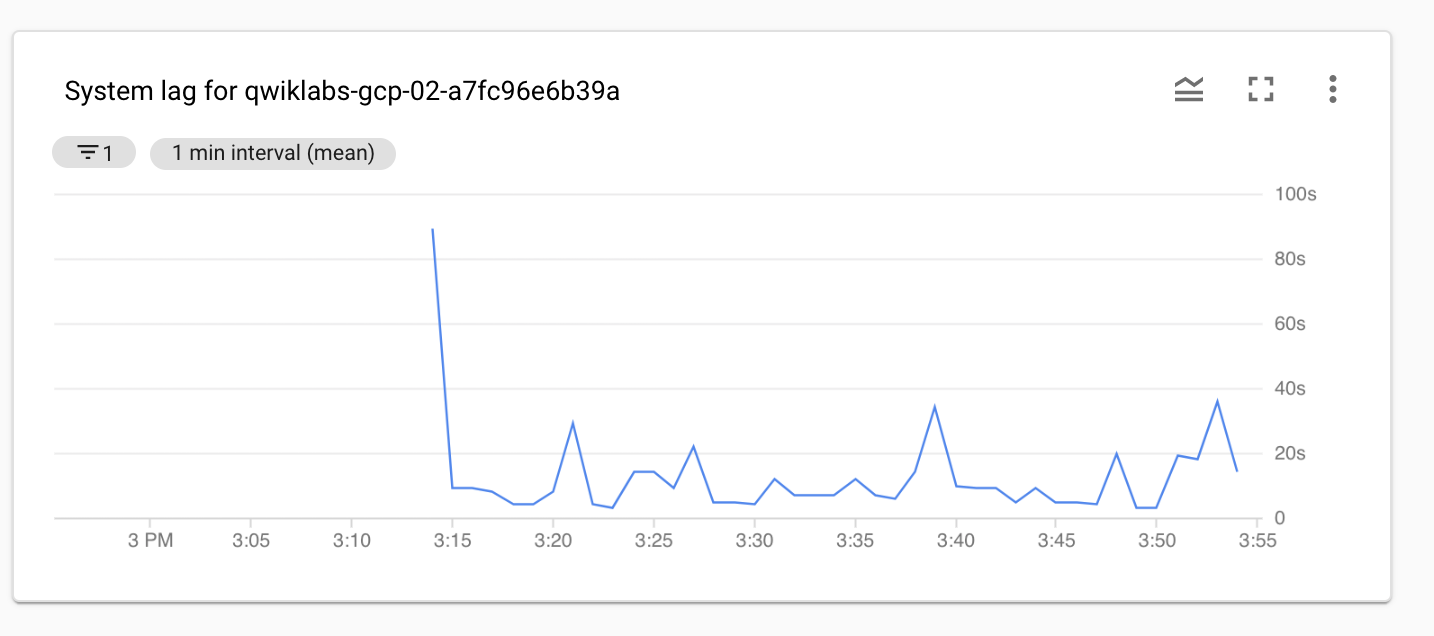
Em "Métrica", clique em Redefinir para remover a métrica do Intervalo na marca-d'água dos dados. Selecione uma nova métrica Intervalo do sistema.
Observação: as métricas fornecidas pelo Dataflow ao Cloud Monitoring são listadas na documentação de métricas do Google Cloud. É possível pesquisar o Dataflow na página. As métricas que você viu são indicadores úteis do desempenho do pipeline.
Atraso na marca d'água dos dados: a idade (tempo desde o carimbo de data/hora do evento) do item de dados mais recente que foi totalmente processado pelo pipeline.
Atraso no sistema: a duração máxima atual que um item de dados aguardou o processamento, em segundos.
Tarefa 12: criar alertas
Para receber uma notificação quando uma certa métrica ultrapassar o limite definido (por exemplo, quando o "Atraso do Sistema" do pipeline de streaming do laboratório ultrapassar o valor predefinido), use os mecanismos de alerta do Cloud Monitoring.
Crie um alerta
No Cloud Monitoring, clique em Alertas.
Clique em + Criar política.
Clique no menu suspenso Selecionar uma métrica. Desative a opção Mostrar apenas métricas e recursos ativos.
Digite Job do Dataflow em "Filtrar por nome do recurso e da métrica" e clique em Job do Dataflow > Job. Selecione Atraso do sistema e clique em Aplicar.
Clique em Configurar gatilho.
Defina a Posição do limite como Acima do limite, o Valor do limite como 5 e defina Opções avançadas > Teste a janela de novo, como 1 min. Clique em Próxima.
Adicione uma notificação
Clique na seta suspensa ao lado dos Canais de notificação e depois em Gerenciar canais de notificação.
A página Canais de notificação será aberta em uma nova guia.
Role a página para baixo e clique em Adicionar novo em E-mail.
Na caixa de diálogo Criar canal de e-mail, defina o nome de usuário do Qwiklabs no campo Endereço de e-mail e um Nome de exibição.
Observação: se usar seu próprio endereço de e-mail, você vai receber alertas até que todos os recursos do projeto sejam excluídos.
Clique em Salvar.
Volte para a guia Criar política de alertas anterior.
Clique de novo em Canais de notificação e depois no ícone de atualização para acessar o nome de exibição mencionado na etapa anterior.
Agora selecione o Nome de exibição e clique em OK.
Defina o Nome do alerta como MyAlertPolicy.
Clique em Próxima.
Analise o alerta e clique em Criar política.
Acesse os eventos
Na guia do Cloud Monitoring, clique em Alertas > Políticas.
Cada vez que um alerta é acionado por uma condição de limite de métrica, um incidente e um evento correspondente são criados no Cloud Monitoring. Se você especificar um mecanismo de notificação no alerta, como e-mail, SMS, pager etc., também receberá uma notificação.
Clique em Verificar meu progresso para conferir o objetivo.
Criar um alerta
Tarefa 13: configurar painéis
É fácil criar painéis com os gráficos mais relevantes relacionados ao Dataflow usando os painéis do Cloud Monitoring.
No painel à esquerda, clique em Painéis.
Clique em + Criar painel.
Na caixa Nome do painel novo, digite Meu painel.
Clique em Adicionar widget e depois em Gráfico de linhas.
Clique na caixa de menu suspenso em Recurso e métrica.
Selecione Job do Dataflow > Job > Atraso do sistema e clique em Aplicar.
No painel Filtros, clique em + Adicionar filtro.
Selecione project_id no campo Label, depois selecione ou digite no campo Value.
Clique em Aplicar.
Exemplo:
Se você quiser, será possível adicionar gráficos ao painel, como taxas de publicação do Pub/Sub no tópico, ou um backlog de assinatura, que é um sinal para o escalonador automático do Dataflow.
Finalize o laboratório
Clique em Terminar o laboratório após a conclusão. O Google Cloud Ensina remove os recursos usados e limpa a conta por você.
Você vai poder avaliar sua experiência no laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
1 estrela = muito insatisfeito
2 estrelas = insatisfeito
3 estrelas = neutro
4 estrelas = satisfeito
5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Processamento de dados de streaming: pipelines de dados de streaming
Duração:
Configuração: 1 minutos
·
Tempo de acesso: 90 minutos
·
Tempo para conclusão: 90 minutos
 ), selecione IAM e administrador > IAM.
), selecione IAM e administrador > IAM.

 ) e selecione Nova conexão para training-vm no menu suspenso. Uma nova janela de terminal será aberta.
) e selecione Nova conexão para training-vm no menu suspenso. Uma nova janela de terminal será aberta.