In questo lab userai Dataflow per raccogliere eventi del traffico ottenuti da dati dei sensori per il traffico simulati resi disponibili mediante PubSub di Google Cloud, li elaborerai in una media processabile e archivierai i dati non elaborati in BigQuery per analisi successive. Imparerai ad avviare una pipeline di Dataflow, monitorarla e infine ottimizzarla.
Nota: al momento della stesura del presente documento, le pipeline di flussi non sono disponibili nell'SDK per Python di Dataflow. I lab sui flussi sono pertanto scritti in Java.
Obiettivi
In questo lab, imparerai a:
Lanciare Dataflow ed eseguire un job Dataflow
Comprendere come avviene il flusso degli elementi dei dati attraverso le trasformazioni di una pipeline Dataflow
Collegare Dataflow a Pub/Sub e BigQuery
Osservare e comprendere in che modo la scalabilità automatica di Dataflow regola le risorse di computing per elaborare dati di input in modo ottimale
Trovare le informazioni di logging create da Dataflow
Esplorare le metriche e creare avvisi e dashboard con Cloud Monitoring
Configurazione
Per ciascun lab, riceverai un nuovo progetto Google Cloud e un insieme di risorse per un periodo di tempo limitato senza alcun costo aggiuntivo.
Accedi a Qwiklabs utilizzando una finestra di navigazione in incognito.
Tieni presente la durata dell'accesso al lab (ad esempio, 1:15:00) e assicurati di finire entro quell'intervallo di tempo.
Non è disponibile una funzionalità di pausa. Se necessario, puoi riavviare il lab ma dovrai ricominciare dall'inizio.
Quando è tutto pronto, fai clic su Inizia lab.
Annota le tue credenziali del lab (Nome utente e Password). Le userai per accedere a Google Cloud Console.
Fai clic su Apri console Google.
Fai clic su Utilizza un altro account e copia/incolla le credenziali per questo lab nei prompt.
Se utilizzi altre credenziali, compariranno errori oppure ti verranno addebitati dei costi.
Accetta i termini e salta la pagina di ripristino delle risorse.
Verifica le autorizzazioni del progetto
Prima di iniziare il tuo lavoro su Google Cloud, devi assicurarti che il tuo progetto disponga delle autorizzazioni corrette in Identity and Access Management (IAM).
Nella console Google Cloud, nel menu di navigazione (), seleziona IAM e amministrazione > IAM.
Conferma che l'account di servizio di computing predefinito {project-number}-compute@developer.gserviceaccount.com sia presente e che abbia il ruolo di editor assegnato. Il prefisso dell'account è il numero del progetto, che puoi trovare in Menu di navigazione > Panoramica di Cloud > Dashboard
Nota: se l'account non è presente in IAM o non dispone del ruolo editor, attieniti alla procedura riportata di seguito per assegnare il ruolo richiesto.
Nel menu di navigazione della console Google Cloud, fai clic su Panoramica di Cloud > Dashboard.
Copia il numero del progetto (es. 729328892908).
Nel menu di navigazione, seleziona IAM e amministrazione > IAM.
Nella parte superiore della tabella dei ruoli, sotto Visualizza per entità, fai clic su Concedi accesso.
Sostituisci {project-number} con il numero del tuo progetto.
Come Ruolo, seleziona Progetto (o Base) > Editor.
Fai clic su Salva.
Attività 1: preparazione
Eseguirai un simulatore dei sensori dalla VM di addestramento. Nel primo lab hai configurato manualmente i componenti Pub/Sub. In questo lab molti di questi processi sono automatizzati.
Apri il terminale SSH e connettiti alla VM di addestramento
In Cloud Console, nel menu di navigazione (), fai clic su Compute Engine > Istanze VM.
Trova la riga con l'istanza denominata training-vm.
Sulla destra, sotto Connetti, fai clic su SSH per aprire una finestra del terminale.
In questo lab inserirai i comandi dell'interfaccia a riga di comando nell'istanza training-vm.
Verifica che l'inizializzazione sia completa
L'istanza training-vm installa del software in background.
Verifica che la configurazione sia completa controllando il contenuto della nuova directory:
ls /training
La configurazione è completa quando il risultato dell'elenco dell'output comando (ls) corrisponde all'immagine seguente. Se non viene visualizzato l'elenco completo, aspetta qualche minuto e riprova.
Nota: il completamento di tutte le operazioni in background potrebbe richiedere da due a tre minuti.
Scarica il repository di codice
A seguire, aggiornerai il repository di codice da utilizzare in questo lab:
Nel terminale SSH di training-vm, inserisci quanto segue:
source /training/project_env.sh
Questo script imposta le variabili DEVSHELL_PROJECT_ID e BUCKET.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Scarica un repository di codice
Attività 2: crea un set di dati BigQuery e un bucket Cloud Storage
La pipeline Dataflow verrà creata in un secondo momento e verrà scritta in una tabella nel set di dati BigQuery.
Apri la console di BigQuery
Nella console Google Cloud, seleziona Menu di navigazione > BigQuery.
Si aprirà la finestra con il messaggio Ti diamo il benvenuto in BigQuery nella console Cloud. Questa finestra fornisce un link alla guida rapida ed elenca gli aggiornamenti dell'interfaccia utente.
Fai clic su Fine.
Crea un set di dati BigQuery
Per creare un set di dati, fai clic sull'icona Visualizza azioni accanto al tuo ID progetto e seleziona Crea set di dati.
Dopodiché, assegna al tuo ID set di dati il nome demos e lascia i valori predefiniti in tutte le altre opzioni, quindi fai clic su Crea set di dati.
Verifica il bucket Cloud Storage
Dovrebbe già esistere un bucket che ha lo stesso nome dell'ID progetto.
Nel menu di navigazione () della console, fai clic su Cloud Storage > Bucket.
Osserva i seguenti valori:
Proprietà
Valore
(digita il valore o seleziona l'opzione come specificato)
Nome
Classe di archiviazione predefinita
A livello di regione
Località
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Crea un set di dati BigQuery
Attività 3: simula i dati dei sensori per il traffico in Pub/Sub
Avvia il simulatore dei sensori nel terminale SSH di training-vm. Lo script legge i dati di esempio da un file CSV e li pubblica in Pub/Sub:
/training/sensor_magic.sh
Questo comando invierà un'ora di dati in un minuto. Lascia in esecuzione lo script in questo terminale.
Apri un secondo terminale SSH e connettilo alla VM di addestramento
Nell'angolo in alto a destra del terminale SSH di training-vm, fai clic sul pulsante a forma di ingranaggio () e seleziona Nuova connessione a training-vm dal menu a discesa. Si aprirà una nuova finestra del terminale.
La nuova sessione del terminale non disporrà delle variabili di ambiente necessarie. Esegui il seguente comando per impostarle.
Nel nuovo terminale SSH di training-vm, inserisci quanto segue:
source /training/project_env.sh
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Simula i dati dei sensori per il traffico in Pub/Sub
Attività 4: lancia la pipeline Dataflow
Verifica che l'API Dataflow di Google Cloud sia abilitata per questo progetto
Esegui il seguente blocco di codice in Cloud Shell per assicurarti che siano state impostate le API e le autorizzazioni corrette.
Lo script richiede tre argomenti: ID progetto, nome bucket e nome classe
Un quarto argomento facoltativo è opzioni. Parleremo dell'argomento opzioni più avanti in questo lab.
ID progetto
nome bucket
nome classe
<java file that runs aggregations>
opzioni
<options>
Puoi scegliere tra quattro file Java per il nome classe. Ciascuno legge i dati sul traffico da Pub/Sub ed esegue diversi calcoli e aggregazioni.
Vai alla directory Java. Identifica il file sorgente AverageSpeeds.java.
cd ~/training-data-analyst/courses/streaming/process/sandiego/src/main/java/com/google/cloud/training/dataanalyst/sandiego
cat AverageSpeeds.java
Che cosa fa lo script?
Chiudi il file per continuare. Ti consigliamo di fare riferimento a questo codice sorgente quando esegui l'applicazione. Per accedere facilmente, aprirai una nuova scheda del browser e visualizzerai il file AverageSpeeds.java su GitHub.
Copia e incolla il seguente URL in una scheda del browser per vedere il codice sorgente su GitHub:
Lascia questa scheda del browser aperta. In un passaggio più avanti nel lab farai nuovamente riferimento al codice sorgente.
Torna al terminale SSH di training-vm. Esegui i seguenti comandi per fare in modo che la pipeline Dataflow legga da PubSub e trascriva in BigQuery:
cd ~/training-data-analyst/courses/streaming/process/sandiego
export REGION={{{project_0.startup_script.gcp_region|Lab GCP Region}}}
./run_oncloud.sh $DEVSHELL_PROJECT_ID $BUCKET AverageSpeeds
Lo script utilizza Maven per creare una pipeline di flussi Dataflow in Java.
Esempio di conclusione corretta:
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 45.542 s
[INFO] Finished at: 2018-06-08T16:51:30+00:00
[INFO] Final Memory: 56M/216M
[INFO] ------------------------------------------------------------------------
Attività 5: esplora la pipeline
Questa pipeline Dataflow legge i messaggi da un argomento Pub/Sub, analizza il file JSON del messaggio di input, produce un output principale e scrive a BigQuery.
Torna alla scheda del browser di Cloud Console. Nel menu di navigazione (), fai clic su Dataflow e poi sul tuo job per monitorare l'avanzamento.
Esempio:
Nota: se il job Dataflow ha esito negativo, esegui di nuovo il comando ./run_oncloud.sh $DEVSHELL_PROJECT_ID $BUCKET AverageSpeeds.
Quando la pipeline è in esecuzione, fai clic su Menu di navigazione () > Pub/Sub > Argomenti.
Esamina la riga Nome argomento e individua l'argomento sandiego.
Trona al Menu di navigazione (), fai clic su Dataflow e poi sul job.
Confronta il codice nella scheda del browser di GitHub AverageSpeeds.java con il grafico della pipeline sulla pagina del job Dataflow.
Trova il passaggio della pipeline GetMessages nel grafico, quindi individua il codice corrispondente nel file AverageSpeeds.java. Si tratta del passaggio della pipeline che legge i dati dall'argomento Pub/Sub. Crea una raccolta di stringhe che corrisponde ai messaggi Pub/Sub letti.
Visualizzi la sottoscrizione creata?
In che modo il codice esegue il pull dei messaggi da Pub/Sub?
Trova il passaggio della pipeline Time Window nel grafico e nel codice. In questo passaggio della pipeline creiamo una finestra di una durata specificata nei parametri della pipeline (in questo caso, una finestra scorrevole). Questa finestra accumulerà i dati sul traffico dal passaggio precedente fino al termine della finestra e li trasmetterà ai passaggi successivi per ulteriori trasformazioni.
Qual è l'intervallo della finestra?
Quanto spesso viene creata una nuova finestra?
Trova i passaggi della pipeline BySensor e AvgBySensor nel grafico, quindi individua lo snippet di codice corrispondente nel file AverageSpeeds.java. Il passaggio BySensor raggruppa tutti gli eventi nella finestra in base all'ID del sensore, dopodiché il passaggio AvgBySensor elaborerà la velocità media per ogni raggruppamento.
Trova il passaggio della pipeline ToBQRow nel grafico e nel codice. Questo passaggio crea una "riga" con la media calcolata dal passaggio precedente e le informazioni relative alle corsie.
Nota: nella pratica, altre azioni possono essere intraprese nel passaggio ToBQRow. Ad esempio, si potrebbe confrontare la media calcolata con una soglia predefinita e registrare i risultati del confronto in Cloud Logging.
Trova BigQueryIO.Write sia nel grafico della pipeline sia nel codice sorgente. Questo passaggio trascrive la riga dalla pipeline a una tabella BigQuery. Poiché abbiamo scelto l'istruzione di scrittura WriteDisposition.WRITE_APPEND, i nuovi record verranno aggiunti alla tabella.
Torna alla scheda della UI web di BigQuery. Aggiorna il browser.
Trova il nome del progetto e i set di dati di demos che hai creato. La piccola freccia a sinistra del nome del set di dati demos ora dovrebbe essere attiva e se ci fai clic sopra verrà visualizzata la tabella average_speeds.
Affinché la tabella average_speeds venga visualizzata in BigQuery, saranno necessari diversi minuti.
Esempio:
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Lancia la pipeline Dataflow
Attività 6: stabilisci il tasso di velocità effettiva
Un'attività comune durante il monitoraggio e il miglioramento delle pipeline Dataflow è cercare di stabilire quanti elementi al secondo elabora la pipeline, qual è il ritardo di sistema e quanti elementi di dati sono stati elaborati finora. In questa attività imparerai dove si possono trovare le informazioni sugli elementi elaborati e sui tempi nella console Cloud.
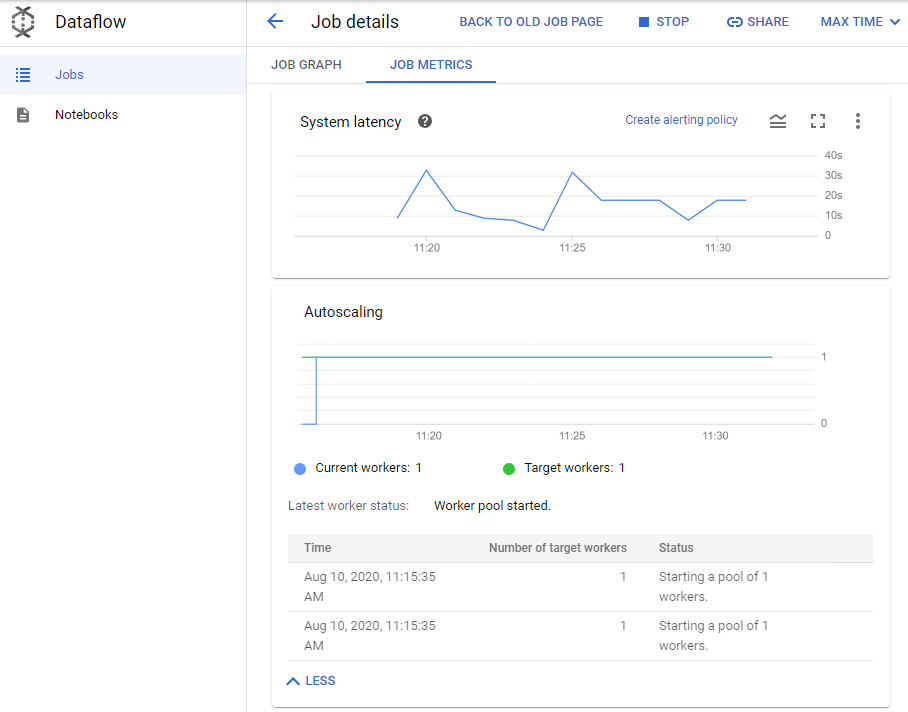
Torna alla scheda del browser di Cloud Console. Nel menu di navigazione (), fai clic su Dataflow e poi sul tuo job per monitorare l'avanzamento (il nome della pipeline corrisponderà al tuo nome utente).
Seleziona il nodo della pipeline GetMessages nel grafico e osserva le metriche del passaggio a destra.
Ritardo sistema è una metrica importante per le pipeline di flusso. Rappresenta la quantità di tempo che gli elementi dei dati impiegano per essere elaborati da quando vengono trasmessi nell'input del passaggio della trasformazione.
La metrica Elementi aggiunti nelle raccolte di output indica quanti elementi di dati hanno superato questo passaggio (per il passaggio Read PubSub Msg della pipeline rappresenta anche il numero di messaggi Pub/Sub letti dall'argomento mediante il connettore IO Pub/Sub).
Seleziona il nodo Time Window nel grafico. Osserva in che modo la metrica Elementi aggiunti in Raccolte di input del passaggio Time Window corrisponde alla metrica Elementi aggiunti in Raccolte di output del passaggio precedente GetMessages.
Attività 7: rivedi l'output BigQuery
Torna alla UI web di BigQuery.
Nota: i flussi di dati e tabelle potrebbero non essere mostrati immediatamente e la funzionalità Anteprima potrebbe non essere disponibile per i dati ancora presenti nel buffer dei flussi. Se fai clic su Anteprima vedrai il messaggio "This table has records in the streaming buffer that may not be visible in the preview" (Nel buffer dei flussi di questa tabella sono presenti record che potrebbero non essere visibili nell'anteprima). Puoi comunque eseguire query per visualizzare i dati.
Nella finestra Editor di query, digita (o copia e incolla) la query riportata di seguito. Usa la seguente query per osservare l'output dal job Dataflow. Fai clic su Esegui:
SELECT *
FROM `demos.average_speeds`
ORDER BY timestamp DESC
LIMIT 100
Trova l'ultimo aggiornamento alla tabella eseguendo il seguente SQL:
SELECT
MAX(timestamp)
FROM
`demos.average_speeds`
Dopodiché, usa la funzionalità di spostamento cronologico di BigQuery per consultare lo stato della tabella in un momento precedente.
La seguente query restituirà un sottoinsieme di righe dalla tabella average_speeds di 10 minuti prima.
Se la query richiede righe ma la tabella non esisteva al momento specificato, riceverai il seguente messaggio di errore:
Invalid snapshot time 1633691170651 for Table PROJECT:DATASET.TABLE__
Se si verifica questo errore, riduci l'ambito dello spostamento cronologico riducendo il valore dei minuti:
SELECT *
FROM `demos.average_speeds`
FOR SYSTEM_TIME AS OF TIMESTAMP_SUB(CURRENT_TIMESTAMP, INTERVAL 10 MINUTE)
ORDER BY timestamp DESC
LIMIT 100
Attività 8: osserva e comprendi la scalabilità automatica
Osserva in che modo Dataflow scala il numero di worker per elaborare il backlog dei messaggi Pub/Sub in arrivo.
Torna alla scheda del browser di Cloud Console. Nel Menu di navigazione (), fai clic su Dataflow e poi sul job della pipeline.
Esamina il riquadro Metriche del job a destra e osserva la sezione Scalabilità automatica. Al momento quanti worker sono in uso per elaborare i messaggi nell'argomento Pub/Sub?
Fai clic su Altra cronologia e rivedi quanti worker sono stati usati in diversi momenti durante l'esecuzione della pipeline.
I dati provenienti dal simulatore dei sensori per il traffico avviati all'inizio del lab creano centinaia di messaggi al secondo nell'argomento Pub/Sub. Questo fa sì che Dataflow aumenti il numero di worker per mantenere il ritardo di sistema della pipeline a livelli ottimali.
Fai clic su Altra cronologia. Nel Pool di worker, puoi vedere le modifiche apportate da Dataflow al numero di worker. Nota che nella colonna Stato viene spiegato il motivo della modifica.
Attività 9: aggiorna lo script della simulazione dei dati dei sensori
Nota: l'ambiente di addestramento del lab presenta limiti di quota. Se lo script della simulazione dei dati dei sensori viene eseguito troppo a lungo, supererà il limite di quota causando la sospensione delle credenziali della sessione.
Torna al terminale SSH di training-vm dove è in esecuzione lo script dei dati dei sensori.
Se visualizzi il messaggio INFO: Publishing, significa che lo script è ancora in esecuzione. Premi Ctrl + C per interromperlo. Dopodiché emetti il comando per avviare nuovamente lo script:
cd ~/training-data-analyst/courses/streaming/publish
./send_sensor_data.py --speedFactor=60 --project $DEVSHELL_PROJECT_ID
I seguenti passaggi 3-8 sono necessari solo se non riesci a usare Ctrl + C per interrompere lo script. Se lo script ha superato il limite di quota, ripetuti messaggi di errore ti informeranno che non è stato possibile aggiornare le credenziali e Ctrl + C non funzionerà. In questo caso, devi solo chiudere il terminale SSH e seguire i passaggi 3-8 indicati qui sotto.
Apri un nuovo terminale SSH. La nuova sessione avrà una quota rinnovata.
In Cloud Console, nel menu di navigazione (), fai clic su Compute Engine > Istanze VM.
Trova la riga con l'istanza denominata training-vm.
Sulla destra, in Connetti, fai clic su SSH per aprire una nuova finestra del terminale.
Nel terminale SSH di training-vm, inserisci quanto segue per creare le variabili di ambiente:
source /training/project_env.sh
Usa i seguenti comandi per avviare un nuovo simulatore dei sensori:
cd ~/training-data-analyst/courses/streaming/publish
./send_sensor_data.py --speedFactor=60 --project $DEVSHELL_PROJECT_ID
Attività 10: integrazione di Cloud Monitoring
L'integrazione di Cloud Monitoring con Dataflow consente agli utenti di accedere a metriche del job Dataflow come Ritardo sistema (per i job di flussi), Stato job (Non riuscito, Riuscito), Conteggi elementi e Contatori utenti dall'interno di Cloud Monitoring.
Funzionalità di integrazione di Cloud Monitoring
Esplora le metriche di Dataflow: sfoglia le metriche disponibili della pipeline Dataflow e visualizzale sotto forma di grafico.
Alcune metriche di Dataflow comuni.
Metriche
Funzionalità
Stato job
Stato job (Non riuscito, Riuscito), riportato come enum ogni 30 secondi e durante gli aggiornamenti.
Tempo trascorso
Tempo trascorso del job (misurato in secondi), riportato ogni 30 secondi.
Ritardo sistema
Massimo ritardo nell'intera pipeline, riportato in secondi.
Conteggio vCPU attuale
Il numero delle CPU virtuali usate attualmente dal job e aggiornate quando viene modificato un valore.
Conteggio byte previsti
Numero di byte elaborati per PCollection.
Organizza le metriche di Dataflow in grafici nelle dashboard di Monitoring: crea dashboard e serie temporali di grafici delle metriche di Dataflow.
Configura avvisi: stabilisci soglie per le metriche a livello di gruppo di risorse o di job e crea avvisi per quando queste metriche raggiungono valori specifici. Gli avvisi di Monitoring notificano una gamma di condizioni come un lungo ritardo di sistema nel flusso o job non riusciti.
Monitora le metriche definite dall'utente: oltre alle sue metriche, Dataflow offre metriche definite dagli utenti (aggregatori di SDK) come contatori personalizzati di Monitoring nell'UI di Monitoring, disponibili per la creazione di grafici e avvisi. Qualsiasi aggregatore definito in una pipeline Dataflow verrà trasmesso a Monitoring in forma di metrica personalizzata. Dataflow definirà una nuova metrica personalizzata per conto dell'utente e trasmetterà aggiornamenti incrementali a Monitoring approssimativamente ogni 30 secondi.
Attività 11: esplora le metriche
Cloud Monitoring è un servizio separato in Google Cloud, quindi avrai bisogno di seguire una procedura di configurazione per inizializzare il servizio per il tuo account del lab.
Crea un'area di lavoro di Monitoring
Ora configurerai un'area di lavoro di Monitoring associata al tuo progetto GCP di Qwiklabs. I passaggi seguenti servono a creare un nuovo account che dispone di una prova gratuita di Monitoring.
Nella console di Google Cloud Platform, fai clic su Menu di navigazione > Monitoring.
Attendi che venga eseguito il provisioning dell'area di lavoro.
Quando la dashboard di Monitoring si apre, l'area di lavoro sarà pronta.
Nel riquadro a sinistra fai clic su Esplora metriche.
In Esplora metriche, nella sezione Risorsa e metrica, fai clic su Seleziona una metrica.
Seleziona Job Dataflow > Job. Dovresti visualizzare un elenco di metriche disponibili correlate a Dataflow. Seleziona Ritardo della filigrana dei dati e fai clic su Applica.
Cloud Monitoring disegnerà un grafico sul lato destro della pagina.
Sotto alla metrica, fai clic su Reimposta per rimuovere la metrica Ritardo della filigrana dei dati. Seleziona una nuova metrica di Dataflow Ritardo sistema.
Nota: le metriche offerte da Dataflow per Monitoring sono elencate nella documentazione delle metriche di Google Cloud. Cerca Dataflow sulla pagina. Le metriche che hai visualizzato sono indicatori utili delle prestazioni della pipeline.
Ritardo della filigrana dei dati: la durata (il tempo trascorso dal timestamp dell'evento) dell'elemento più recente dei dati che è stato interamente elaborato dalla pipeline.
Ritardo sistema: l'attuale tempo massimo per il quale un elemento dei dati ha atteso l'elaborazione, espresso in secondi.
Attività 12: crea avvisi
Se vuoi ricevere una notifica quando una determinata metrica supera una soglia specifica (ad esempio, quando Ritardo sistema della pipeline di flusso del nostro lab supera un certo valore predefinito), puoi usare i meccanismi di avviso di Monitoring.
Crea un avviso
In Cloud Monitoring, fai clic su Avvisi.
Fai clic su + Crea criterio.
Fai clic sul menu a discesa Seleziona una metrica. Disattiva Mostra solo risorse e metriche attive.
Digita Job Dataflow nel filtro per nome risorsa e metrica e fai clic su Job Dataflow > Job. Seleziona Ritardo sistema e fai clic su Applica.
Fai clic su Configura trigger.
Imposta Posizione soglia su Above threshold, Valore soglia su 5 e Opzioni avanzate > Finestra di ripetizione test su 1 min. Fai clic su Avanti.
Aggiungi una notifica
Fai clic sulla freccia menu a discesa accanto a Canali di notifica, quindi fai clic su Gestisci canali di notifica.
Una pagina Canali di notifica verrà aperta in una nuova scheda.
Scorri la pagina verso il basso e fai clic su Aggiungi nuovo per Email.
Nella finestra di dialogo Crea canale email, inserisci il nome utente che usi per il lab nel campo Indirizzo email e un Nome visualizzato.
Nota: se inserisci il tuo indirizzo email, potresti ricevere avvisi finché tutte le risorse del progetto non saranno state eliminate.
Fai clic su Salva.
Torna alla scheda Crea criterio di avviso precedente.
Fai di nuovo clic su Canali di notifica, quindi fai clic sull'icona Aggiorna per recuperare il nome visualizzato indicato nel passaggio precedente.
A questo punto, seleziona il Nome visualizzato e fai clic su Ok.
Imposta Nome avviso su MyAlertPolicy.
Tocca Avanti.
Rivedi l'avviso e fai clic su Crea criterio.
Visualizza gli eventi
Nella scheda Cloud Monitoring, fai clic su Avvisi > Criteri.
Ogni volta che una condizione di soglia metrica attiva un avviso, in Monitoring vengono creati un evento e un incidente corrispondenti. Se nell'avviso hai specificato un meccanismo di notifica (email, SMS, cercapersone e così via), riceverai anche una notifica.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Crea un avviso
Attività 13: configura dashboard
Puoi creare facilmente dashboard con i grafici correlati a Dataflow più pertinenti con Dashboard di Cloud Monitoring.
Nel riquadro di sinistra, fai clic su Dashboard.
Fai clic su + Crea dashboard.
In Nuovo nome della dashboard, digita Dashboard personale.
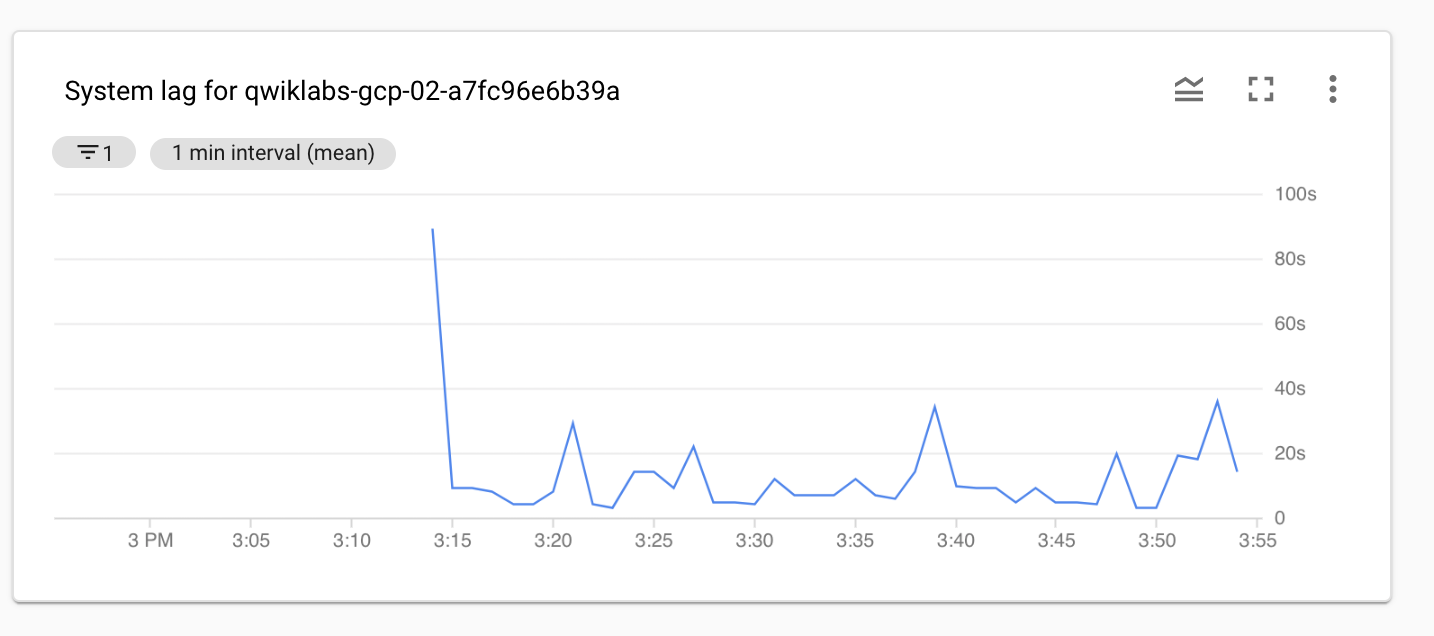
Fai clic su Aggiungi widget, quindi su Grafico a linee.
Fai clic sulla casella a discesa in Risorsa e metrica.
Seleziona Job Dataflow > Job > Ritardo sistema e fai clic su Applica.
Nel riquadro Filtri, fai clic su + Aggiungi filtro.
Seleziona project_id nel campo Etichetta, quindi seleziona o digita il tuo nel campo Valore.
Fai clic su Applica.
Esempio:
Se vuoi puoi aggiungere altri grafici alla dashboard, ad esempio i tassi di pubblicazione di Pub/Sub sull'argomento o il backlog di sottoscrizione (che è un indicatore per la scalabilità automatica di Dataflow).
Termina il lab
Una volta completato il lab, fai clic su Termina lab. Google Cloud Skills Boost rimuove le risorse che hai utilizzato ed esegue la pulizia dell'account.
Avrai la possibilità di inserire una valutazione in merito alla tua esperienza. Seleziona il numero di stelle applicabile, inserisci un commento, quindi fai clic su Invia.
Il numero di stelle corrisponde alle seguenti valutazioni:
1 stella = molto insoddisfatto
2 stelle = insoddisfatto
3 stelle = esperienza neutra
4 stelle = soddisfatto
5 stelle = molto soddisfatto
Se non vuoi lasciare un feedback, chiudi la finestra di dialogo.
Per feedback, suggerimenti o correzioni, utilizza la scheda Assistenza.
Copyright 2020 Google LLC Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.
I lab creano un progetto e risorse Google Cloud per un periodo di tempo prestabilito
I lab hanno un limite di tempo e non possono essere messi in pausa. Se termini il lab, dovrai ricominciare dall'inizio.
In alto a sinistra dello schermo, fai clic su Inizia il lab per iniziare
Utilizza la navigazione privata
Copia il nome utente e la password forniti per il lab
Fai clic su Apri console in modalità privata
Accedi alla console
Accedi utilizzando le tue credenziali del lab. L'utilizzo di altre credenziali potrebbe causare errori oppure l'addebito di costi.
Accetta i termini e salta la pagina di ripristino delle risorse
Non fare clic su Termina lab a meno che tu non abbia terminato il lab o non voglia riavviarlo, perché il tuo lavoro verrà eliminato e il progetto verrà rimosso
Questi contenuti non sono al momento disponibili
Ti invieremo una notifica via email quando sarà disponibile
Bene.
Ti contatteremo via email non appena sarà disponibile
Un lab alla volta
Conferma per terminare tutti i lab esistenti e iniziare questo
Utilizza la navigazione privata per eseguire il lab
Utilizza una finestra del browser in incognito o privata per eseguire questo lab. In questo modo eviterai eventuali conflitti tra il tuo account personale e l'account Studente, che potrebbero causare addebiti aggiuntivi sul tuo account personale.
Elaborazione dei dati in modalità flusso: pipeline di dati in modalità flusso
Durata:
Configurazione in 1 m
·
Accesso da 90 m
·
Completamento in 90 m
 ), seleziona IAM e amministrazione > IAM.
), seleziona IAM e amministrazione > IAM.

 ) e seleziona Nuova connessione a training-vm dal menu a discesa. Si aprirà una nuova finestra del terminale.
) e seleziona Nuova connessione a training-vm dal menu a discesa. Si aprirà una nuova finestra del terminale.