Dans cet atelier, vous utiliserez Dataflow pour recueillir des événements de trafic à partir de données de capteurs de trafic simulées, disponibles dans Google Cloud Pub/Sub. Vous les traiterez ensuite de manière à obtenir une moyenne exploitable, puis vous stockerez les données brutes dans BigQuery en vue de les analyser. Vous apprendrez à démarrer un pipeline Dataflow, à le surveiller et, enfin, à l'optimiser.
Remarque : Au moment de la rédaction de ce document, les pipelines de traitement par flux ne sont pas disponibles dans le SDK Dataflow pour Python. Les ateliers liés aux flux de données sont donc rédigés en Java.
Objectifs
Dans cet atelier, vous allez effectuer les tâches suivantes :
Lancer Dataflow et exécuter un job Dataflow
Comprendre le parcours qu'empruntent les éléments de données au fil des transformations d'un pipeline Dataflow
Connecter Dataflow à Pub/Sub et à BigQuery
Observer et comprendre la manière dont l'autoscaling de Dataflow ajuste les ressources de calcul pour traiter les données entrées de manière optimale
Savoir où rechercher les données de journalisation créées par Dataflow
Découvrir les métriques, et créer des alertes et des tableaux de bord avec Cloud Monitoring
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
Connectez-vous à Qwiklabs dans une fenêtre de navigation privée.
Vérifiez le temps imparti pour l'atelier (par exemple : 01:15:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Notez vos identifiants pour l'atelier (Nom d'utilisateur et Mot de passe). Ils vous serviront à vous connecter à Google Cloud Console.
Cliquez sur Ouvrir la console Google.
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
Dans la console Google Cloud, accédez au menu de navigation (), puis sélectionnez IAM et administration > IAM.
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle editor (éditeur). Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation du cloud > Tableau de bord.
Remarque : Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle editor (éditeur), procédez comme suit pour lui attribuer le rôle approprié.
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation du cloud > Tableau de bord.
Copiez le numéro du projet (par exemple, 729328892908).
Dans le menu de navigation, sélectionnez IAM et administration > IAM.
Sous Afficher par compte principal, en haut de la table des rôles, cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez :
Remplacez {project-number} par le numéro de votre projet.
Dans le champ Rôle, sélectionnez Projet (ou Basique) > Éditeur.
Cliquez sur Enregistrer.
Tâche 1 : Préparation
Vous allez exécuter un simulateur de capteurs depuis la VM d'entraînement. Au cours de l'atelier 1, vous avez configuré manuellement les composants de Pub/Sub. Cette fois, nous avons automatisé un certain nombre de processus.
Ouvrir le terminal SSH et se connecter à la VM d'entraînement
Dans la console, accédez au menu de navigation (), puis cliquez sur Compute Engine > Instances de VM.
Repérez la ligne comportant l'instance nommée training-vm.
Tout à droite de la page, sous Connecter, cliquez sur SSH pour ouvrir une fenêtre de terminal.
Dans cet atelier, vous allez saisir les commandes CLI dans l'instance training-vm.
Vérifier que l'initialisation est terminée
L'instance training-vm installe des logiciels en arrière-plan.
Pour vérifier si la configuration est terminée, examinez le contenu du nouveau répertoire :
ls /training
La configuration est terminée lorsque votre commande de liste ("ls") génère le résultat suivant. Si la liste complète ne s'affiche pas, attendez quelques minutes, puis réessayez.
Remarque : L'exécution de l'ensemble des actions en arrière-plan peut prendre deux à trois minutes.
Télécharger le dépôt de code
Maintenant, vous allez actualiser le dépôt de code que vous utiliserez dans cet atelier :
Dans le terminal SSH de l'instance training-vm, saisissez le script suivant :
source /training/project_env.sh
Ce script définit les variables d'environnement DEVSHELL_PROJECT_ID et BUCKET.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Télécharger un dépôt de code
Tâche 2 : Créer un ensemble de données BigQuery et un bucket Cloud Storage
Le pipeline Dataflow sera créé ultérieurement et écrit dans une table de l'ensemble de données BigQuery.
Ouvrir la console BigQuery
Dans Google Cloud Console, sélectionnez le menu de navigation > BigQuery :
Le message Welcome to BigQuery in the Cloud Console (Bienvenue sur BigQuery dans Cloud Console) s'affiche. Il contient un lien vers le guide de démarrage rapide et répertorie les mises à jour de l'interface utilisateur.
Cliquez sur Done (OK).
Créer un ensemble de données BigQuery
Pour créer un ensemble de données, cliquez sur l'icône Afficher les actions à côté de votre ID de projet, puis sélectionnez Créer un ensemble de données.
Ensuite, saisissez demos pour l'ID de l'ensemble de données et conservez la valeur par défaut de toutes les autres options. Enfin, cliquez sur Créer un ensemble de données.
Vérifier le bucket Cloud Storage
Vous devez normalement disposer d'un bucket dont le nom est identique à l'ID du projet.
Dans la console, accédez au menu de navigation (), puis cliquez sur Cloud Storage > Buckets.
Examinez les valeurs suivantes :
Propriété
Valeur
(saisissez une valeur ou sélectionnez une option)
Nom
Classe de stockage par défaut
Régional
Emplacement
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer un ensemble de données BigQuery
Tâche 3 : Simuler les données de capteurs de trafic dans Pub/Sub
Dans le terminal SSH de l'instance training-vm, lancez le simulateur de capteurs. Le script lit des échantillons de données à partir d'un fichier CSV et les publie sur Pub/Sub :
/training/sensor_magic.sh
Cette commande enverra une heure de données en une minute. Laissez le script s'exécuter dans le terminal que vous avez ouvert.
Ouvrir un deuxième terminal SSH et le connecter à la VM d'entraînement
En haut à droite du terminal SSH de l'instance training-vm, cliquez sur le bouton en forme de roue dentée () et sélectionnez Nouvelle connexion à l'instance "training-vm" dans le menu déroulant. Une nouvelle fenêtre de terminal s'ouvre.
La nouvelle session de terminal ne dispose pas des variables d'environnement requises. Exécutez la commande suivante pour les définir.
Dans le terminal SSH de la nouvelle instance training-vm, saisissez la commande suivante :
source /training/project_env.sh
Cliquez sur Vérifier ma progression pour valider l'objectif.
Simuler les données de capteurs de trafic dans Pub/Sub
Tâche 4 : Lancer le pipeline Dataflow
Vérifier que l'API Google Cloud Dataflow est activée pour ce projet
Pour vérifier que les API sont activées et que les autorisations appropriées sont définies, exécutez le bloc de code suivant dans Cloud Shell.
Le script doit comprendre trois arguments : project id, bucket name et classname
Vous pouvez également utiliser l'argument facultatif options. Nous l'aborderons plus loin dans cet atelier.
project id
bucket name
classname
<fichier java exécutant les agrégations>
options
<options>
Pour l'argument classname, vous pouvez choisir parmi quatre fichiers Java. Chacun d'entre eux lit les données de trafic depuis Pub/Sub et exécute des agrégations/calculs différents.
Accédez au répertoire Java. Repérez le fichier source AverageSpeeds.java.
cd ~/training-data-analyst/courses/streaming/process/sandiego/src/main/java/com/google/cloud/training/dataanalyst/sandiego
cat AverageSpeeds.java
Que fait le script ?
Pour poursuivre, fermez le fichier. Vous aurez besoin de vous reporter à ce code source lorsque vous exécuterez l'application. Ouvrez un nouvel onglet de navigateur pour afficher le fichier AverageSpeeds.java sur GitHub afin de pouvoir y accéder facilement.
Pour afficher le code source sur GitHub, copiez l'URL suivante et collez-la dans un onglet de navigateur :
Ne fermez pas cet onglet. Vous aurez besoin de reconsulter le code source plus tard.
Revenez au terminal SSH de l'instance training-vm. Exécutez les commandes suivantes pour que le pipeline Dataflow lise les données depuis Pub/Sub et les écrive dans BigQuery :
cd ~/training-data-analyst/courses/streaming/process/sandiego
export REGION={{{project_0.startup_script.gcp_region|Lab GCP Region}}}
./run_oncloud.sh $DEVSHELL_PROJECT_ID $BUCKET AverageSpeeds
Ce script utilise Maven pour construire un pipeline de flux de données Dataflow avec Java.
Exemple d'exécution réussie :
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 45.542 s
[INFO] Finished at: 2018-06-08T16:51:30+00:00
[INFO] Final Memory: 56M/216M
[INFO] ------------------------------------------------------------------------
Tâche 5 : Explorer le pipeline
Ce pipeline Dataflow lit les messages d'un sujet Pub/Sub, analyse le JSON du message d'entrée, génère un résultat principal et écrit dans BigQuery.
Dans le navigateur, revenez à l'onglet de la console. Dans le menu de navigation (), cliquez sur Dataflow, puis sur votre job pour suivre son avancement.
Exemple :
Remarque : Si le job Dataflow échoue, exécutez de nouveau la commande ./run_oncloud.sh $DEVSHELL_PROJECT_ID $BUCKET AverageSpeeds.
Une fois que le pipeline est en cours d'exécution, accédez au menu de navigation () et cliquez sur Pub/Sub > Sujets.
Examinez la ligne Nom du sujet du sujet sandiego.
Revenez au menu de navigation () et cliquez sur Dataflow, puis sur votre job.
Comparez le code contenu dans l'onglet du navigateur GitHub, dans le fichier AverageSpeeds.java et dans le graphique du pipeline affiché sur la page de votre job Dataflow.
Recherchez l'étape GetMessages du pipeline dans le graphique, puis le code correspondant dans le fichier AverageSpeeds.java. C'est cette étape qui lit les données depuis le sujet Pub/Sub. Elle crée une collection de chaînes correspondant aux messages Pub/Sub qui ont été lus.
Voyez-vous l'abonnement créé ?
Comment le code extrait-il les messages de Pub/Sub ?
Trouvez l'étape de pipeline Time Window (Fenêtre temporelle) dans le graphique et dans le code. Cette étape sert à créer une fenêtre de la durée spécifiée dans les paramètres du pipeline (dans ce cas-ci, une fenêtre glissante). Celle-ci accumule les données de trafic de l'étape précédente jusqu'à ce qu'elle se termine, puis les transmet aux étapes suivantes en vue d'autres transformations.
Quel est l'intervalle de la fenêtre ?
À quelle fréquence une nouvelle période est-elle créée ?
Recherchez les étapes BySensor et AvgBySensor du pipeline dans le graphique, puis l'extrait de code correspondant dans le fichier AverageSpeeds.java. L'étape BySensor effectue un regroupement de tous les événements de la fenêtre par ID de capteur, tandis que l'étape AvgBySensor calcule ensuite la vitesse moyenne de chaque regroupement.
Recherchez l'étape ToBQRow du pipeline dans le graphique et dans le code. Cette étape crée simplement une "ligne" contenant la moyenne calculée à partir de l'étape précédente et les informations sur les voies.
Remarque : Dans la pratique, l'étape ToBQRow vous permet d'effectuer d'autres actions. Par exemple, elle peut comparer la moyenne calculée avec un seuil prédéfini et consigner les résultats dans Cloud Logging.
Trouvez BigQueryIO.Write à la fois dans le graphique de pipeline et dans le code source. Cette étape reproduit la ligne du pipeline dans une table BigQuery. Dans la mesure où nous avons choisi la disposition d'écriture WriteDisposition.WRITE_APPEND, de nouveaux enregistrements seront ajoutés à la table.
Revenez à l'interface utilisateur Web BigQuery. Actualisez votre navigateur.
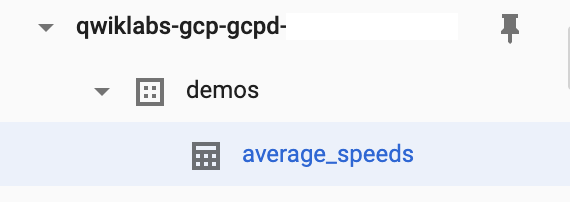
Recherchez le nom de votre projet et l'ensemble de données "demos" que vous avez créé. La petite flèche qui s'affiche à gauche du nom de l'ensemble de données demos doit maintenant être active. Cliquez dessus pour afficher la table average_speeds.
La table average_speeds peut mettre quelques minutes à s'afficher dans BigQuery.
Exemple :
Cliquez sur Vérifier ma progression pour valider l'objectif.
Lancer le pipeline Dataflow
Tâche 6 : Déterminer les débits
Lors des opérations de surveillance et d'amélioration des pipelines Dataflow, une activité courante consiste à déterminer le nombre d'éléments traités par le pipeline chaque seconde, le retard du système et le nombre d'éléments de données traités jusqu'à l'instant présent. Dans cette activité, vous apprendrez où trouver les informations sur les éléments traités et les durées dans Cloud Console.
Dans le navigateur, revenez à l'onglet de la console. Dans le menu de navigation (), cliquez sur Dataflow, puis sur votre job pour suivre son avancement (le nom du pipeline contient votre nom d'utilisateur).
Sélectionnez le nœud de pipeline GetMessages dans le graphique et observez les métriques d'étape sur la droite.
● La métrique Retard du système est importante pour les pipelines de flux de données. Elle correspond à la durée qui s'écoule entre le moment où les éléments "arrivent" en entrée de l'étape de transformation et celui où ils sont traités.
● La métrique Éléments ajoutés située sous les collections de sortie indique le nombre d'éléments de données ayant quitté cette étape. (Pour l'étape Read PubSub Msg du pipeline, elle représente également le nombre de messages Pub/Sub lus depuis le sujet par le connecteur d'E/S Pub/Sub.)
Sélectionnez le nœud Time Window (Fenêtre temporelle) dans le graphique. Observez la correspondance entre la métrique "Éléments ajoutés" sous les collections d'entrée de l'étape Time Window et la métrique "Éléments ajoutés" sous les collections de sortie de l'étape précédente GetMessages.
Tâche 7 : Examiner le résultat BigQuery
Revenez à l'interface utilisateur Web de BigQuery.
Remarque : Il est possible que les flux de données et les tables n'apparaissent pas immédiatement, et que la fonctionnalité d'aperçu ne soit pas disponible pour les données figurant encore dans la mémoire tampon du flux de données. Dans ce cas, si vous cliquez sur Aperçu, le message suivant s'affiche : "This table has records in the streaming buffer that may not be visible in the preview" (Cette table contient des enregistrements qui sont dans la mémoire tampon du flux et qui risquent de ne pas être visibles dans l'aperçu). Vous pouvez quand même exécuter des requêtes pour afficher les données.
Dans la fenêtre Éditeur de requête, saisissez (ou copiez-collez) la requête suivante. Utilisez la requête suivante pour observer le résultat du job Dataflow. Cliquez sur Exécuter :
SELECT *
FROM `demos.average_speeds`
ORDER BY timestamp DESC
LIMIT 100
Pour obtenir la dernière mise à jour de la table, exécutez la requête SQL suivante :
SELECT
MAX(timestamp)
FROM
`demos.average_speeds`
Utilisez ensuite la fonction temporelle de BigQuery pour référencer l'état de la table à un moment précis.
La requête ci-dessous renvoie un sous-ensemble de lignes de la table average_speeds, telle qu'elle se présentait 10 minutes avant.
Si la table n'existait pas au moment précis demandé, le message d'erreur suivant s'affiche :
Invalid snapshot time 1633691170651 for Table PROJECT:DATASET.TABLE__
Dans ce cas, réduisez la plage temporelle en diminuant le nombre de minutes :
SELECT *
FROM `demos.average_speeds`
FOR SYSTEM_TIME AS OF TIMESTAMP_SUB(CURRENT_TIMESTAMP, INTERVAL 10 MINUTE)
ORDER BY timestamp DESC
LIMIT 100
Tâche 8 : Observer et comprendre l'autoscaling
Observez comment Dataflow adapte le nombre de nœuds de calcul pour traiter les messages Pub/Sub entrants en attente.
Dans le navigateur, revenez à l'onglet de la console. Dans le menu de navigation (), cliquez sur Dataflow, puis sur votre job de pipeline.
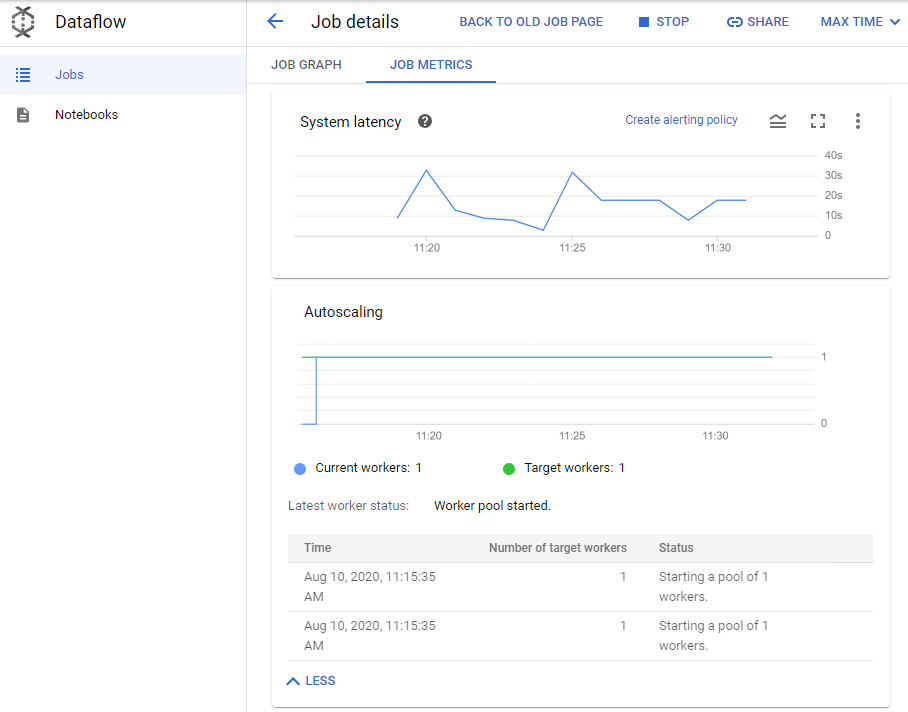
Examinez le panneau Métriques de job sur la droite, puis consultez la section Autoscaling. Combien de nœuds de calcul sont actuellement utilisés afin de traiter les messages du sujet Pub/Sub ?
Cliquez sur Afficher davantage d'historique et vérifiez combien de nœuds de calcul ont été utilisés à différents moments de l'exécution du pipeline.
Les données provenant d'un simulateur de capteurs de trafic démarré au début de l'atelier créent des centaines de messages par seconde dans le sujet Pub/Sub. Dataflow augmente le nombre de nœuds de calcul en conséquence afin de maintenir le retard du système du pipeline à un niveau optimal.
Cliquez sur Afficher davantage d'historique. Dans le pool de nœuds de calcul, vous pouvez voir les modifications qu'a apportées Dataflow au nombre de nœuds de calcul. Remarquez la présence de la colonne État, qui indique le motif de la modification.
Tâche 9 : Actualiser le script de simulation des données de capteurs
Remarque : L'environnement de l'atelier de formation présente des limites de quota. Si le script de simulation des données de capteurs s'exécute trop longtemps, il dépassera la limite de quota, ce qui entraînera la suspension des identifiants de la session.
Revenez au terminal SSH de l'instance training-vm où s'exécute le script des données de capteurs.
Si vous voyez des messages qui indiquent INFO : Publication en cours, cela signifie que le script est toujours en cours d'exécution. Appuyez sur CTRL+C pour l'arrêter. Exécutez ensuite la commande ci-dessous pour redémarrer le script :
cd ~/training-data-analyst/courses/streaming/publish
./send_sensor_data.py --speedFactor=60 --project $DEVSHELL_PROJECT_ID
Les étapes 3 à 8 indiquées ci-après ne sont nécessaires que si vous ne parvenez pas à arrêter le script en appuyant sur CTRL+C. Si le script a dépassé la limite de quota, des messages d'erreur s'affichent plusieurs fois, indiquant qu'il est "impossible d'actualiser les identifiants", et la combinaison CTRL+C ne fonctionne pas. Dans ce cas, fermez simplement le terminal SSH et suivez les étapes 3 à 8 ci-dessous.
Ouvrez un nouveau terminal SSH. La nouvelle session dispose alors d'un nouveau quota.
Dans la console, accédez au menu de navigation (), puis cliquez sur Compute Engine > Instances de VM.
Repérez la ligne comportant l'instance nommée training-vm.
Tout à droite de la page, sous Connecter, cliquez sur SSH pour ouvrir une nouvelle fenêtre de terminal.
Dans le terminal SSH de training-vm, saisissez la commande suivante pour créer des variables d'environnement :
source /training/project_env.sh
Exécutez les commandes suivantes pour démarrer un nouveau simulateur de capteurs :
cd ~/training-data-analyst/courses/streaming/publish
./send_sensor_data.py --speedFactor=60 --project $DEVSHELL_PROJECT_ID
Tâche 10 : Intégration de Cloud Monitoring
L'intégration de Cloud Monitoring à Dataflow permet aux utilisateurs d'accéder à des métriques de jobs Dataflow telles que le retard du système (pour les jobs de traitement par flux), l'état du job (échec, succès), le nombre d'éléments et les compteurs utilisateur dans Cloud Monitoring.
Fonctionnalités d'intégration de Cloud Monitoring
Explorez les métriques Dataflow : parcourez les métriques des pipelines Dataflow disponibles et visualisez-les dans des graphiques.
Voici quelques métriques Dataflow courantes.
Métriques
Fonctionnalités
État du job
État du job (échec, succès), fourni sous forme d'énumération toutes les 30 secondes et lors des mises à jour.
Temps écoulé
Durée du job (en secondes), fournie toutes les 30 secondes.
Retard du système
Retard maximal sur l'ensemble du pipeline, exprimé en secondes.
Current vCPU count (Nombre actuel de processeurs virtuels)
Nombre actuel de processeurs virtuels utilisés par le job, mis à jour en cas de modification de la valeur.
Estimated byte count (Estimation du nombre d'octets)
Nombre d'octets traités par PCollection
Présentez les métriques Dataflow dans des graphiques au sein de tableaux de bord Monitoring : créez des tableaux de bord et des séries temporelles graphiques à partir de métriques Dataflow.
Configurez des alertes : définissez des seuils sur des métriques au niveau d'un job ou d'un groupe de ressources, et recevez une alerte lorsque les valeurs spécifiées sont atteintes. Les alertes Monitoring peuvent vous avertir en fonction de différentes conditions, comme un retard trop important du système de traitement par flux ou l'échec de certains jobs.
Surveillez des métriques définies par l'utilisateur : en plus de ses métriques propres, Dataflow expose des métriques définies par l'utilisateur (SDK Aggregators) sous forme de compteurs Monitoring personnalisés dans l'interface utilisateur de Monitoring pour créer des graphiques et des alertes. Tout agrégateur défini dans un pipeline Dataflow est transmis à Monitoring sous forme de métrique personnalisée. Dataflow définit une nouvelle métrique personnalisée pour le compte de l'utilisateur et fournit à Monitoring des mises à jour incrémentielles toutes les 30 secondes environ.
Tâche 11 : Explorer les métriques
Cloud Monitoring est un service distinct de Google Cloud. Vous devrez donc procéder à quelques étapes de configuration afin d'initialiser le service pour votre compte d'atelier.
Créer un espace de travail Surveillance
Vous allez maintenant configurer un espace de travail Surveillance lié à votre projet GCP Qwiklabs. Suivez les étapes ci-dessous pour créer un compte avec un essai gratuit de Surveillance.
Dans la console Google Cloud Platform, cliquez sur le menu de navigation > Monitoring (Surveillance).
Attendez que votre espace de travail soit provisionné.
Votre espace de travail est prêt dès que le tableau de bord Surveillance s'ouvre.
Dans le panneau de gauche, cliquez sur Explorateur de métriques.
Une fois dans l'explorateur de métriques, sous Ressource et métrique, cliquez sur Sélectionner une métrique.
Cliquez sur Job Dataflow > Job pour afficher la liste des métriques disponibles associées à Dataflow. Sélectionnez Data watermark lag(Retard de la marque de données) et cliquez sur Appliquer.
Cloud Monitoring trace un graphique sur le côté droit de la page.
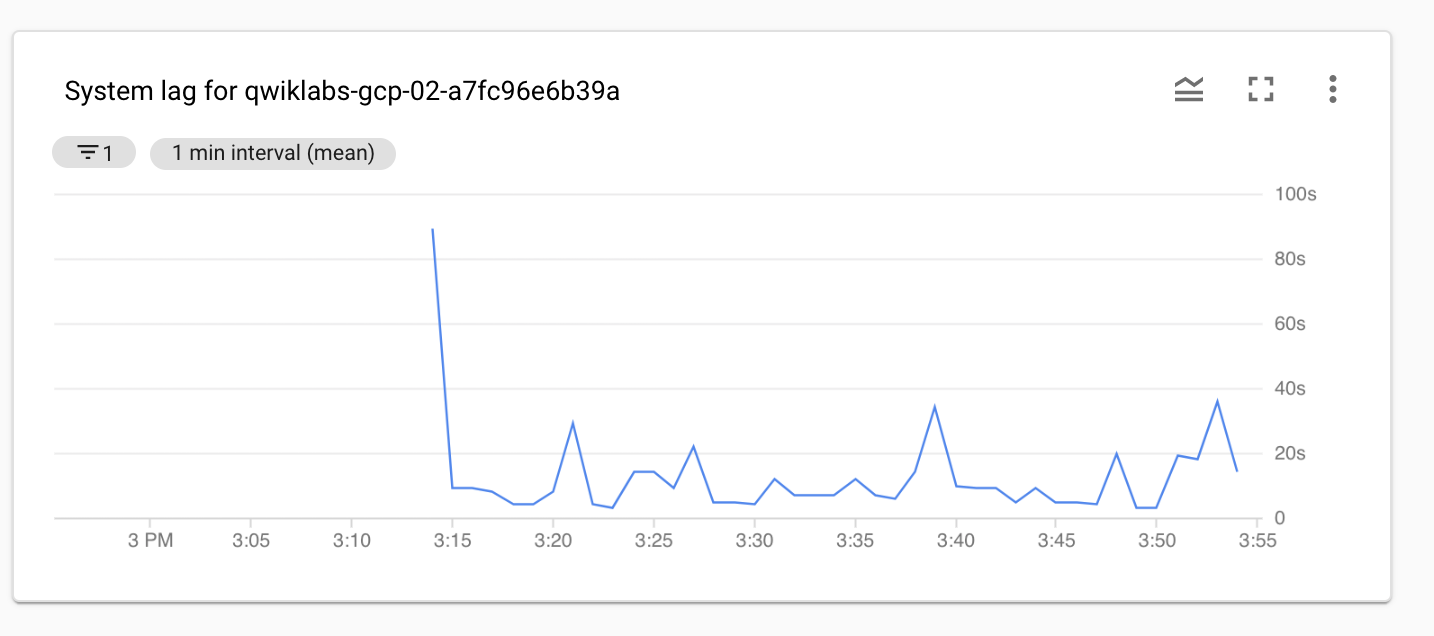
Sous "Métrique", cliquez sur Réinitialiser pour supprimer la métrique Data watermark lag (Retard de la marque de données). Sélectionnez à présent la métrique Retard du système.
Remarque : Les métriques que Dataflow fournit à Monitoring sont listées dans la documentation sur les métriques Google Cloud. Recherchez-les sur la page qui concerne Dataflow. Les métriques que vous avez consultées sont des indicateurs utiles sur les performances du pipeline.
Data watermark lag (Retard de la marque de données) : âge (temps écoulé depuis l'horodatage de l'événement) de l'élément de données le plus récent entièrement traité par le pipeline.
Retard du système : délai d'attente maximal actuellement enregistré pour le traitement d'un élément de données, exprimé en secondes.
Tâche 12 : Créer des alertes
Si vous souhaitez être averti lorsqu'une métrique donnée franchit un seuil spécifié (par exemple, lorsque le retard du système du pipeline de flux de données de notre atelier dépasse une valeur prédéfinie), vous pouvez utiliser les mécanismes d'alerte de Monitoring.
Créer une alerte
Dans Cloud Monitoring, cliquez sur Alertes.
Cliquez sur + Créer une règle.
Cliquez sur le menu déroulant Sélectionner une métrique. Désactivez l'option Afficher uniquement les ressources et métriques actives.
Saisissez Job Dataflow sous "Filtrer par nom de ressource ou de métrique", puis cliquez sur Job Dataflow > Job. Sélectionnez Retard du système et cliquez sur Appliquer.
Cliquez sur Configurer un déclencheur.
Définissez la Position du seuil sur Au-dessus du seuil, la Valeur du seuil sur 5 et Options avancées > Fenêtre du nouveau test sur 1 min. Cliquez sur Suivant.
Ajouter une notification
Cliquez sur la flèche du menu déroulant à côté de Canaux de notification, puis sur Gérer les canaux de notification.
Une page Canaux de notification s'ouvre dans un nouvel onglet.
Faites défiler la page vers le bas, puis cliquez sur le bouton Ajouter associé à Adresse e-mail.
Dans la boîte de dialogue Créer un canal de messagerie, saisissez le nom d'utilisateur associé à l'atelier dans le champ Adresse e-mail, et spécifiez un Nom à afficher.
Remarque : Si vous saisissez votre propre adresse e-mail, vous risquez de recevoir des alertes jusqu'à la suppression de toutes les ressources du projet.
Cliquez sur Enregistrer.
Revenez à l'onglet Créer une règle d'alerte précédent.
Cliquez de nouveau sur Canaux de notification, puis sur l'icône Actualiser pour obtenir le nom à afficher que vous avez indiqué à l'étape précédente.
Sélectionnez ensuite votre nom à afficher, puis cliquez sur OK.
Dans le champ Nom de l'alerte, saisissez MyAlertPolicy.
Cliquez sur Suivant.
Examinez l'alerte et cliquez sur Créer une règle.
Afficher des événements
Dans l'onglet Cloud Monitoring, cliquez sur Alertes > Règles.
Chaque fois qu'une alerte est déclenchée par une condition de seuil de métrique, un incident et un événement correspondant sont créés dans Monitoring. Si vous avez spécifié un mécanisme de notification dans l'alerte (e-mail, SMS, bipeur, etc.), vous recevez également une notification.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer une alerte
Tâche 13 : Configurer des tableaux de bord
Vous pouvez créer facilement des tableaux de bord contenant les graphiques liés à Dataflow les plus pertinents à l'aide de la fonction correspondante de Cloud Monitoring.
Dans le volet de gauche, cliquez sur Tableaux de bord.
Cliquez sur + Créer un tableau de bord.
Dans le champ Nom du nouveau tableau de bord, saisissez Mon tableau de bord.
Cliquez sur Ajouter un widget, puis sur Graphique en courbes.
Cliquez sur le menu déroulant sous Ressource et métrique.
Sélectionnez Job Dataflow > Job > Retard du système et cliquez sur Appliquer.
Dans le panneau Filtres, cliquez sur + Ajouter un filtre.
Sélectionnez project_id dans le champ Étiquette, puis sélectionnez ou saisissez votre dans le champ Valeur.
Cliquez sur Appliquer.
Exemple :
Si vous le souhaitez, vous pouvez ajouter d'autres graphiques au tableau de bord, comme les taux de publication Pub/Sub sur le sujet ou les tâches d'abonnement en attente (qui sont un signal envoyé à l'autoscaler Dataflow).
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur Terminer l'atelier. Google Cloud Skills Boost supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez un nombre d'étoiles, saisissez un commentaire, puis cliquez sur Envoyer.
Le nombre d'étoiles correspond à votre degré de satisfaction :
1 étoile = très insatisfait(e)
2 étoiles = insatisfait(e)
3 étoiles = ni insatisfait(e), ni satisfait(e)
4 étoiles = satisfait(e)
5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez accéder à l'onglet Assistance.
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.
Les ateliers créent un projet Google Cloud et des ressources pour une durée déterminée.
Les ateliers doivent être effectués dans le délai imparti et ne peuvent pas être mis en pause. Si vous quittez l'atelier, vous devrez le recommencer depuis le début.
En haut à gauche de l'écran, cliquez sur Démarrer l'atelier pour commencer.
Utilisez la navigation privée
Copiez le nom d'utilisateur et le mot de passe fournis pour l'atelier
Cliquez sur Ouvrir la console en navigation privée
Connectez-vous à la console
Connectez-vous à l'aide des identifiants qui vous ont été attribués pour l'atelier. L'utilisation d'autres identifiants peut entraîner des erreurs ou des frais.
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer, car cela effacera votre travail et supprimera le projet.
Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible
Parfait !
Nous vous contacterons par e-mail s'il devient disponible
Un atelier à la fois
Confirmez pour mettre fin à tous les ateliers existants et démarrer celui-ci
Utilisez la navigation privée pour effectuer l'atelier
Ouvrez une fenêtre de navigateur en mode navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
Traitement des flux de données : Pipelines de flux de données
Durée :
1 min de configuration
·
Accessible pendant 90 min
·
Terminé après 90 min
 ), puis sélectionnez IAM et administration > IAM.
), puis sélectionnez IAM et administration > IAM.

 ) et sélectionnez Nouvelle connexion à l'instance "training-vm" dans le menu déroulant. Une nouvelle fenêtre de terminal s'ouvre.
) et sélectionnez Nouvelle connexion à l'instance "training-vm" dans le menu déroulant. Une nouvelle fenêtre de terminal s'ouvre.