En este lab, usarás Dataflow para recopilar eventos de tráfico a partir de datos simulados de un sensor de tráfico disponibles mediante Google Cloud Pub/Sub. Luego, los procesarás para obtener un promedio factible y almacenarás los datos sin procesar en BigQuery para su posterior análisis. Aprenderás a iniciar una canalización de Dataflow, supervisarla y, por último, optimizarla.
Nota: En el momento en que se redactó este documento, las canalizaciones de transmisión no se encontraban disponibles en el SDK de Dataflow para Python. Por lo tanto, los labs de transmisión están escritos en Java.
Objetivos
En este lab, realizarás las siguientes tareas:
Iniciar Dataflow y ejecutar un trabajo
Entender cómo fluyen los elementos de datos a través de las transformaciones de una canalización de Dataflow
Conectar Dataflow a Pub/Sub y BigQuery
Observar y entender cómo el ajuste de escala automático de Dataflow adapta los recursos informáticos para procesar datos de entrada de manera óptima
Aprender dónde encontrar información de registro creada por Dataflow
Explorar métricas y crear alertas y paneles con Cloud Monitoring
Configuración
En cada lab, recibirá un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
Accede a Qwiklabs desde una ventana de incógnito.
Ten en cuenta el tiempo de acceso del lab (por ejemplo, 1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesita, puede reiniciar el lab, pero deberá hacerlo desde el comienzo.
Cuando esté listo, haga clic en Comenzar lab.
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
Haga clic en Abrir Google Console.
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usa otras credenciales, se generarán errores o incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación.
Verifica los permisos del proyecto
Antes de comenzar a trabajar en Google Cloud, asegúrate de que tu proyecto tenga los permisos correctos en Identity and Access Management (IAM).
En la consola de Google Cloud, en el Menú de navegación (), selecciona IAM y administración > IAM.
Confirma que aparezca la cuenta de servicio predeterminada de Compute {número-del-proyecto}-compute@developer.gserviceaccount.com, y que tenga asignado el rol Editor. El prefijo de la cuenta es el número del proyecto, que puedes encontrar en el Menú de navegación > Descripción general de Cloud > Panel.
Nota: Si la cuenta no aparece en IAM o no tiene asignado el rol Editor, sigue los pasos que se indican a continuación para asignar el rol necesario.
En la consola de Google Cloud, en el Menú de navegación, haz clic en Descripción general de Cloud > Panel.
Copia el número del proyecto (p. ej., 729328892908).
En el Menú de navegación, selecciona IAM y administración > IAM.
En la parte superior de la tabla de funciones, debajo de Ver por principales, haz clic en Otorgar acceso.
Reemplaza {número-del-proyecto} por el número de tu proyecto.
En Rol, selecciona Proyecto (o Básico) > Editor.
Haz clic en Guardar.
Tarea 1. Preparación
Tendrás que ejecutar un simulador del sensor desde la VM de entrenamiento. En el Lab 1, configuraste manualmente los componentes de Pub/Sub. En este lab, varios de esos procesos son automáticos.
Abre la terminal SSH y conéctate a la VM de entrenamiento
En la consola, abre el Menú de navegación () y haz clic en Compute Engine > Instancias de VM.
Ubica la línea que tenga la instancia training-vm.
En el extremo derecho, en Conectar, haz clic en SSH para abrir una ventana de la terminal.
En este lab, ingresarás comandos de la CLI en training-vm.
Verifica que se haya completado la inicialización
La instancia training-vm está instalando software en segundo plano.
Revisa el contenido del directorio nuevo para verificar que la configuración esté completa.
ls /training
La configuración estará completa cuando el resultado de tu comando list (ls) aparezca como en la siguiente imagen. Si no aparece la lista completa, espera unos minutos y vuelve a intentarlo.
Nota: Es posible que todas las acciones en segundo plano tarden entre 2 y 3 minutos en completarse.
Descarga el repositorio de código
Luego, actualiza el repositorio de código para usar en este lab:
En la terminal SSH de training-vm, ingresa lo siguiente:
source /training/project_env.sh
Esta secuencia de comandos configura las variables de entorno DEVSHELL_PROJECT_ID y BUCKET.
Haz clic en Revisar mi progreso para verificar el objetivo.
Descargar un repositorio de código
Tarea 2. Crea un conjunto de datos de BigQuery y un bucket de Cloud Storage
La canalización de Dataflow se creará luego y se escribirá en una tabla en el conjunto de datos de BigQuery.
Abra BigQuery en Console
En Google Cloud Console, seleccione el menú de navegación > BigQuery.
Se abrirá el cuadro de mensaje Te damos la bienvenida a BigQuery en Cloud Console, que contiene un vínculo a la guía de inicio rápido y enumera las actualizaciones de la IU.
Haga clic en Listo.
Crea un conjunto de datos de BigQuery
Para crear un conjunto de datos, haz clic en el ícono de Ver acciones junto con el ID del proyecto y selecciona Crear conjunto de datos.
A continuación, asigna el nombre demos al ID del conjunto de datos y deja todas las demás opciones con sus valores predeterminados. Luego, haz clic en Crear conjunto de datos.
Verifica el bucket de Cloud Storage
Ya debería existir un bucket con el mismo nombre que el ID del proyecto.
En el Menú de navegación () de la consola, haz clic en Cloud Storage > Buckets.
Observa los siguientes valores:
Propiedad
Valor
(escribe el valor o selecciona la opción como se especifica)
Nombre
Clase de almacenamiento predeterminada
Regional
Ubicación
Haz clic en Revisar mi progreso para verificar el objetivo.
Crea un conjunto de datos de BigQuery
Tarea 3. Simula los datos del sensor de tráfico en Pub/Sub
En la terminal SSH de training-vm, inicia el simulador del sensor. La secuencia de comandos lee los datos de muestra de un archivo CSV y los publica en Pub/Sub:
/training/sensor_magic.sh
Este comando enviará 1 hora de datos en 1 minuto. Deja que la secuencia de comandos continúe ejecutándose en la terminal actual.
Abre una segunda terminal SSH y conéctate a la VM de entrenamiento
En la esquina superior derecha de la terminal SSH de training-vm, haz clic en el botón con forma de engranaje () y selecciona Conexión nueva a training-vm en el menú desplegable. Se abrirá una nueva ventana de la terminal.
La nueva sesión de la terminal no tendrá las variables de entorno necesarias. Ejecuta el siguiente comando para configurarlas.
En la nueva terminal SSH de training-vm, ingresa lo siguiente:
source /training/project_env.sh
Haz clic en Revisar mi progreso para verificar el objetivo.
Simula los datos del sensor de tráfico en Pub/Sub.
Tarea 4. Inicia la canalización de Dataflow
Verifica que la API de Google Cloud Dataflow esté habilitada para este proyecto
Para asegurarte de que se establezcan las APIs y los permisos adecuados, ejecuta el siguiente bloque de código en Cloud Shell.
La secuencia de comandos requiere tres argumentos: project id, bucket name y classname.
Un cuarto argumento no obligatorio es options. El argumento options se explicará posteriormente en este lab.
ID del proyecto
bucket name
classname
<el archivo Java que ejecuta las agregaciones>
options
<opciones>
En el caso de classname, puedes elegir entre 4 archivos Java. Cada uno lee los datos de tráfico de Pub/Sub y ejecuta diferentes agregaciones o cálculos.
Ve al directorio de Java. Identifica el archivo fuente AverageSpeeds.java.
cd ~/training-data-analyst/courses/streaming/process/sandiego/src/main/java/com/google/cloud/training/dataanalyst/sandiego
cat AverageSpeeds.java
¿Qué hace la secuencia de comandos?
Cierra el archivo para continuar. Es conveniente que consultes este código fuente mientras ejecutas la aplicación. Para facilitar el acceso, deberás abrir una nueva pestaña del navegador y así ver el archivo AverageSpeeds.java en GitHub.
Copia y pega la siguiente URL en una pestaña del navegador para ver el código fuente en GitHub:
Deja abierta esta pestaña del navegador. Volverás a consultar el código fuente más adelante en este lab.
Regresa a la terminal SSH de la instancia training_vm. Ejecuta los siguientes comandos para que la canalización de Dataflow lea de Pub/Sub y escribe en BigQuery:
cd ~/training-data-analyst/courses/streaming/process/sandiego
export REGION={{{project_0.startup_script.gcp_region|Lab GCP Region}}}
./run_oncloud.sh $DEVSHELL_PROJECT_ID $BUCKET AverageSpeeds
Esta secuencia de comandos usa Maven para crear una canalización de transmisión de Dataflow en Java.
Ejemplo de una ejecución exitosa:
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 45.542 s
[INFO] Finished at: 2018-06-08T16:51:30+00:00
[INFO] Final Memory: 56M/216M
[INFO] ------------------------------------------------------------------------
Tarea 5. Explora la canalización
Esta canalización de Dataflow lee los mensajes de un tema de Pub/Sub, analiza el JSON del mensaje de entrada, produce un resultado principal y escribe en BigQuery.
Regresa a la pestaña del navegador de la consola. En Menú de navegación (), haz clic en Dataflow y, luego, en tu trabajo para supervisar el progreso.
Ejemplo:
Nota: Si el trabajo de Dataflow falló, vuelve a ejecutar el comando ./run_oncloud.sh $DEVSHELL_PROJECT_ID $BUCKET AverageSpeeds.
Después de ejecutar la canalización, haz clic en el Menú de navegación () y, luego, en Pub/Sub > Temas.
Examina la línea Nombre del tema para sandiego.
Regresa al Menú de navegación () y haz clic en Dataflow y, luego, en tu trabajo.
Compara el código en la pestaña del navegador de GitHub, AverageSpeeds.java, y el gráfico de la canalización en la página de tu trabajo de Dataflow.
Busca el paso de canalización GetMessages en el gráfico y, luego, busca el código correspondiente en el archivo AverageSpeeds.java. Este es el paso de canalización que lee desde el tema de Pub/Sub. Crea una colección de strings que corresponde a mensajes de Pub/Sub leídos.
¿Puedes ver que se creó una suscripción?
¿Cómo extrae el código mensajes de Pub/Sub?
Busca el paso de canalización TimeWindow en el gráfico y en el código. En este paso de canalización, crearemos un período con una duración especificada en los parámetros de canalización (un período variable en este caso). Este período acumulará los datos de tráfico del paso anterior hasta el final del período y los transferirá a los siguientes pasos para realizar más transformaciones.
¿Cuál es el intervalo de este período?
¿Con qué frecuencia se crea un nuevo período?
Busca los pasos de canalización BySensor y AvgBySensor en el gráfico y, luego, busca el fragmento de código correspondiente en el archivo AverageSpeeds.java. BySensor agrupa todos los eventos en el período según el ID de cada sensor, mientras que AvgBySensor calculará la velocidad media para cada agrupación.
Busca el paso de canalización ToBQRow en el gráfico y en el código. En este paso, simplemente se crea una “fila” con el promedio calculado del paso anterior junto con la información del carril.
Nota: En la práctica, se podrían realizar otras acciones en el paso ToBQRow. Por ejemplo, se podría comparar el valor promedio calculado con un umbral predefinido y registrar los resultados de la comparación en Cloud Logging.
Busca BigQueryIO.Write en el gráfico de la canalización y en el código fuente. Este paso escribe la fila fuera de la canalización en una tabla de BigQuery. Debido a que elegimos la disposición de escritura WriteDisposition.WRITE_APPEND, se anexarán nuevos registros a la tabla.
Regresa a la pestaña de la IU web de BigQuery. Actualiza tu navegador.
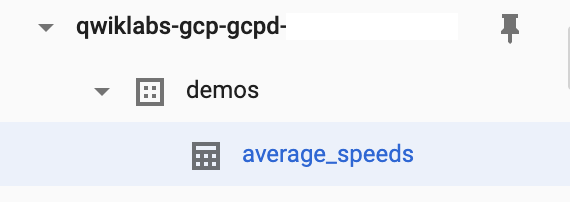
Busca el nombre de tu proyecto y el conjunto de datos (demos) que creaste. La flecha pequeña que se encuentra a la izquierda del nombre del conjunto de datos demos debería estar activada ahora. Haz clic en ella para revelar la tabla average_speeds.
La tabla average_speeds tardará varios minutos en aparecer en BigQuery.
Ejemplo:
Haz clic en Revisar mi progreso para verificar el objetivo.
Inicia la canalización de Dataflow
Tarea 6. Determina los índices de capacidad de procesamiento
Una actividad que se practica comúnmente cuando se supervisa y se mejora una canalización de Dataflow es determinar cuántos elementos por segundo procesa la canalización, cuál es el retraso del sistema y cuántos datos se procesaron hasta el momento. En esta actividad, aprenderás dónde encontrar información sobre los elementos procesados y el tiempo en la consola de Cloud.
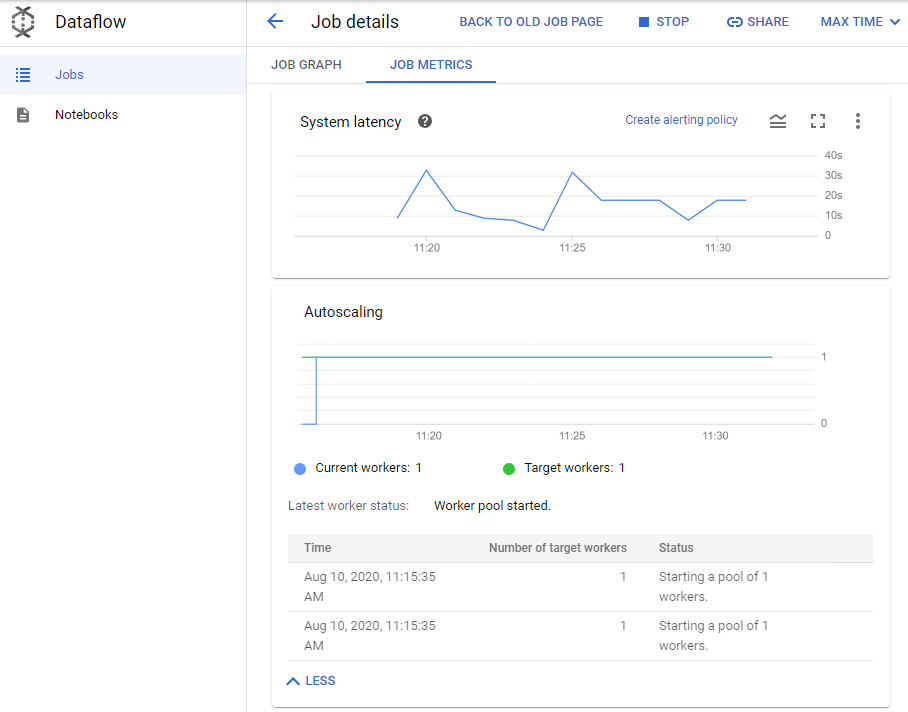
Regresa a la pestaña del navegador de la consola. En el Menú de navegación (), haz clic en Dataflow y, luego, en tu trabajo para supervisar el progreso (el nombre de la canalización será tu nombre de usuario).
Selecciona el nodo de canalización GetMessages en el grafo y consulta las métricas del paso que se encuentran a la derecha.
La métrica Retraso del sistema es importante para la canalización de datos de transmisión. Representa el tiempo que los datos esperan para que se procesen desde que “llegan” a la entrada del paso de transformación.
La métrica Elementos agregados en las colecciones de salida indica cuántos datos salieron en este paso (para el paso Read PubSub Msg de la canalización, también representa la cantidad de mensajes de Pub/Sub leídos desde el tema generado por el conector IO de Pub/Sub).
Selecciona el nodo de TimeWindow en el gráfico. Observa cómo la métrica Elementos agregados, en Colecciones de entrada del paso Time Window, coincide con la misma métrica en Colecciones de salida del paso anterior GetMessages.
Tarea 7. Revisa el resultado de BigQuery
Regresa a la IU web de BigQuery.
Nota: Es posible que los datos de transmisión y las tablas no se muestren de inmediato y que la función de versión preliminar no esté disponible para los datos que aún están en el búfer de transmisión. Si haces clic en Vista previa, verás el mensaje “This table has records in the streaming buffer that may not be visible in the preview”. Aún puedes ejecutar consultas para visualizar los datos.
En la ventana Editor de consultas, escribe (o copia y pega) la siguiente consulta Utiliza la siguiente búsqueda para observar el resultado del trabajo de Dataflow. Haz clic en Ejecutar.
SELECT *
FROM `demos.average_speeds`
ORDER BY timestamp DESC
LIMIT 100
Busca la última actualización de la tabla con el siguiente SQL:
SELECT
MAX(timestamp)
FROM
`demos.average_speeds`
A continuación, usa la función retroactiva de BigQuery para consultar el estado de la tabla en un momento anterior.
La siguiente consulta mostrará un subconjunto de filas de la tabla average_speeds que existía hace 10 minutos.
Si tu consulta solicita filas, pero la tabla no existía en ese punto de referencia en el tiempo, recibirás el siguiente mensaje de error:
Invalid snapshot time 1633691170651 for Table PROJECT:DATASET.TABLE__
Si encuentras este error, reduce el valor de minutos para limitar el permiso de la función retroactiva.
SELECT *
FROM `demos.average_speeds`
FOR SYSTEM_TIME AS OF TIMESTAMP_SUB(CURRENT_TIMESTAMP, INTERVAL 10 MINUTE)
ORDER BY timestamp DESC
LIMIT 100
Tarea 8. Observa y entiende el ajuste de escala automático
Observa cómo Dataflow ajusta la cantidad de trabajadores para procesar el trabajo pendiente de mensajes de Pub/Sub entrantes.
Regresa a la pestaña del navegador de la consola. En el Menú de navegación (), haz clic en Dataflow y, luego, en tu trabajo de canalización.
Examina el panel Métricas de trabajo de la derecha y revisa la sección Ajuste de escala automático. ¿Cuántos trabajadores se usan actualmente para procesar mensajes en el tema de Pub/Sub?
Haz clic en Más historial y revisa la cantidad de trabajadores utilizados en diferentes puntos durante la canalización.
Los datos del simulador del sensor de tráfico iniciado al comienzo del lab crean cientos de mensajes por segundo en el tema de Pub/Sub. Esto hará que Dataflow aumente la cantidad de trabajadores para mantener el retraso del sistema de la canalización en niveles óptimos.
Haz clic en Más historial. En Grupo de trabajadores, puedes ver cómo Dataflow cambió la cantidad de trabajadores. Observa la columna Estado, en la que se explica la razón del cambio.
Tarea 9. Actualiza la secuencia de comandos de la simulación de datos del sensor
Nota: El entorno de entrenamiento del lab tiene límites de cuota. Si la secuencia de comandos de la simulación de datos del sensor se ejecuta por demasiado tiempo, pasará el límite de cuota y generará la suspensión de las credenciales de la sesión.
Regresa a la terminal SSH de training_vm, en la que se ejecuta la secuencia de comandos de datos del sensor.
Si ves el mensaje INFO: Publishing, aún se está ejecutando la secuencia de comandos. Presiona CTRL + C para detenerla. A continuación, ejecuta el comando para iniciar la secuencia de comandos nuevamente.
cd ~/training-data-analyst/courses/streaming/publish
./send_sensor_data.py --speedFactor=60 --project $DEVSHELL_PROJECT_ID
Los pasos 3-8 solo son necesarios si no puedes usar CTRL + C para frenar la secuencia de comandos. Si la secuencia de comandos ha excedido el límite de cuota, verás mensajes de error repetidos que dirán “las credenciales no pudieron ser actualizadas” y CTRL + C no funcionará. En ese caso, simplemente cierra la terminal SSH y sigue los pasos 3-8 que se encuentran abajo.
Abre una nueva terminal SSH. Esta nueva sesión tendrá una cuota nueva.
En la consola, abre el Menú de navegación () y haz clic en Compute Engine > Instancias de VM.
Ubica la línea que tenga la instancia training-vm.
En el extremo derecho, en Conectar, haz clic en SSH para abrir una nueva ventana de terminal.
En la terminal SSH de training-vm, ingresa lo siguiente para crear variables de entorno:
source /training/project_env.sh
Usa los siguientes comandos para iniciar una nueva simulación del sensor.
cd ~/training-data-analyst/courses/streaming/publish
./send_sensor_data.py --speedFactor=60 --project $DEVSHELL_PROJECT_ID
Tarea 10. Integración en Cloud Monitoring
La integración de Cloud Monitoring con Dataflow permite a los usuarios acceder a las métricas de trabajos de Dataflow, como Retraso del sistema (para trabajos de transmisión), Estado del trabajo (error o finalizado) y recuentos de elementos y usuarios, desde Cloud Monitoring.
Funciones de integración de Cloud Monitoring
Explora las métricas de Dataflow: Navega por las métricas de canalización disponibles de Dataflow y visualízalas en gráficos.
Algunas métricas comunes de Dataflow son las siguientes:
Métricas
Características
Estado del trabajo
Estado del trabajo (error, finalizado), informado como una enumeración cada 30 segundos y cuando se actualiza
Tiempo transcurrido
Tiempo transcurrido del trabajo (medido en segundos), informado cada 30 segundos
Retraso del sistema
Retraso máximo en toda la canalización, informado en segundos
Recuento actual de CPU virtuales
Cantidad actual de CPU virtuales utilizadas por trabajo y actualizadas cuando cambia un valor.
Recuento estimado de bytes
Cantidad de bytes procesados por PCollection
Organiza en gráficos las métricas de Dataflow en los paneles de Monitoring: Crea paneles y series temporales de gráficos a partir de métricas de Dataflow.
Configura alertas: Define umbrales para las métricas a nivel del grupo de trabajos o recursos y genera alertas cuando estas métricas alcancen valores específicos. Las alertas de Monitoring notifican varias condiciones, como una larga demora en el sistema de transmisión o trabajos fallidos.
Supervisa métricas definidas por el usuario: Además de sus propias métricas, Dataflow muestra métricas definidas por el usuario (agregadores de SDK) como contadores personalizados de Monitoring en la IU de Monitoring, disponibles para crear gráficos y alertas. Cualquier agregador definido en una canalización de Dataflow se informará a Monitoring como una métrica personalizada. Dataflow definirá una nueva métrica personalizada en nombre del usuario y le informará actualizaciones graduales a Monitoring cada 30 segundos aproximadamente.
Tarea 11. Explora las métricas
Cloud Monitoring es un servicio separado de Google Cloud. Por lo tanto, tendrás que realizar algunos ajustes para inicializar el servicio en tu cuenta de lab.
Cree un lugar de trabajo de Monitoring
Ahora configurará un lugar de trabajo de Monitoring vinculado a su proyecto de GCP de Qwiklabs. Siga estos pasos para crear una cuenta nueva que incluya una prueba gratuita de Monitoring.
En Google Cloud Platform Console, haga clic en Menú de navegación > Monitoring.
Espere a que se aprovisione su lugar de trabajo.
Cuando se abra el panel de Monitoring, su lugar de trabajo estará listo.
En el panel de la izquierda, haz clic en Explorador de métricas.
En Recursos & Métricas del Explorador de métricas, haz clic en Seleccionar una métrica.
Selecciona Dataflow Job > Job. Deberías ver una lista de métricas disponibles relacionadas con Dataflow. Selecciona Data watermark lag y haz clic en Aplicar.
Cloud Monitoring creará un gráfico en el lado derecho de la página.
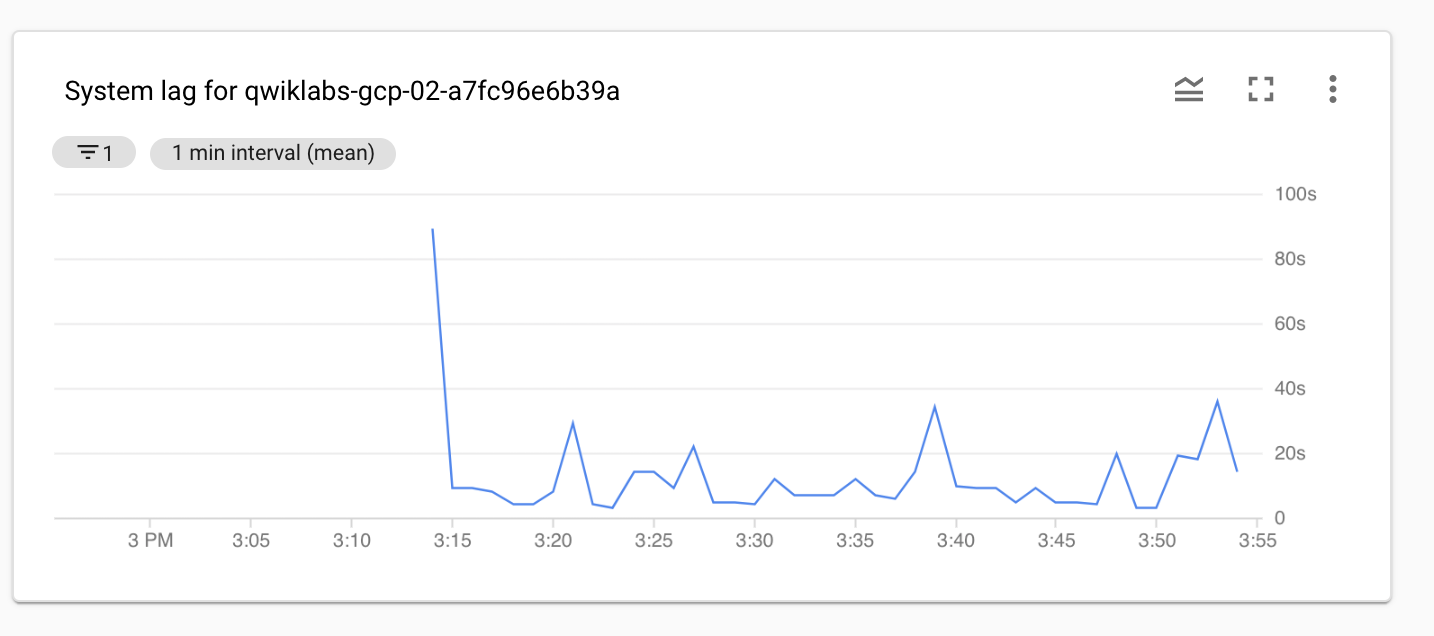
Haz clic en Restablecer para quitar la métrica Data watermark lag. Selecciona una nueva métrica de Dataflow, Retraso del sistema.
Nota: Las métricas que proporciona Dataflow a Monitoring se enumeran en la documentación de métricas de Google Cloud. Puedes buscar Dataflow en la página. Las métricas observadas son indicadores útiles del rendimiento de la canalización.
Retraso de la marca de agua de los datos: Es la edad (el tiempo transcurrido desde la marca de tiempo del evento) del elemento más reciente de datos procesados por completo por la canalización.
Retraso del sistema: Es la duración máxima actual en segundos que un elemento de datos ha esperado el procesamiento.
Tarea 12. Crea alertas
Si quieres recibir notificaciones cuando cierta métrica cruce un umbral específico (por ejemplo, cuando Retraso del sistema de la canalización de datos de este lab aumente por encima del valor predefinido), puedes utilizar mecanismos de Alerta de Monitoring.
Crea una alerta
En Cloud Monitoring, haz clic en Alertas.
Haz clic en + Crear política.
Haz clic en el menú desplegable Seleccionar una métrica. Inhabilita la opción Mostrar solo recursos y métricas activos.
Escribe Trabajo de Dataflow en Filtrar por nombre de recurso o métrica y haz clic en Trabajo de Dataflow > Trabajo. Selecciona Retraso del sistema y haz clic en Aplicar.
Haz clic en Configurar activador.
Establece el campo Posición del umbral en Por encima del umbral, Valor del umbral en 5 y Opciones avanzadas > Ventana para volver a probar en 1 min. Luego, haz clic en Siguiente.
Agrega una notificación
Haz clic en la flecha hacia abajo del menú desplegable junto a Canales de notificaciones y, luego, en Administrar canales de notificaciones.
Se abrirá la página Canales de notificaciones en una pestaña nueva.
Desplázate hacia abajo por la página y haz clic en Agregar nuevo para Correo electrónico.
En el cuadro de diálogo Crear un canal de correo electrónico, ingresa el nombre de usuario de lab como el campo Dirección de correo electrónico y un nombre visible.
Nota: Si ingresas tu propia dirección de correo electrónico, es posible que recibas alertas hasta que se borren todos los recursos del proyecto.
Haz clic en Guardar.
Regresa a la pestaña anterior, Crear política de alertas.
Vuelve a hacer clic en Canales de notificaciones y luego en el ícono de actualización para que se muestre el nombre visible que mencionaste en el paso anterior.
Ahora, selecciona tu nombre visible y haz clic en Aceptar.
Establece el Nombre de la alerta como MyAlertPolicy.
Haz clic en Siguiente.
Revisa la alerta y haz clic en Crear política.
Ver eventos
En la pestaña Cloud Monitoring, haz clic en Alertas > Políticas.
Cada vez que se activa una alerta por la condición Límite de métrica, se crea un incidente y su correspondiente evento en Monitoring. Si especificaste un mecanismo de notificación en la alerta (correo electrónico, SMS, localizador, etc.), también recibirás una notificación.
Haz clic en Revisar mi progreso para verificar el objetivo.
Crea una alerta
Tarea 13. Configura paneles
Puedes crear paneles fácilmente con los gráficos de Dataflow más relevantes con los paneles de Cloud Monitoring.
En el panel izquierdo, haz clic en Paneles.
Haz clic en + Crear panel.
En Nombre del panel nuevo, escribe Mi panel.
Haz clic en Agregar widget, luego, en Gráfico de líneas.
Haz clic en el cuadro despegable debajo de Recurso y métrica.
Selecciona Trabajo de Dataflow > Trabajo > Retraso del sistema y haz clic en Aplicar.
En el panel Filtros, haz clic en + Agregar filtro.
Selecciona project_id en el campo Etiqueta, luego selecciona o escribe tu en el campo de Valor.
Haz clic en Aplicar.
Ejemplo:
Si quieres, puedes agregar más gráficos al panel, por ejemplo, índices de publicación de Pub/Sub sobre el tema o tareas pendientes de la suscripción (que es un indicador para el ajuste del escalador automático de Dataflow).
Finalice su lab
Cuando haya completado el lab, haga clic en Finalizar lab. Google Cloud Skills Boost quitará los recursos que usó y limpiará la cuenta.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
1 estrella = Muy insatisfecho
2 estrellas = Insatisfecho
3 estrellas = Neutral
4 estrellas = Satisfecho
5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
Copyright 2020 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.
Los labs crean un proyecto de Google Cloud y recursos por un tiempo determinado
.
Los labs tienen un límite de tiempo y no tienen la función de pausa. Si finalizas el lab, deberás reiniciarlo desde el principio.
En la parte superior izquierda de la pantalla, haz clic en Comenzar lab para empezar
Usa la navegación privada
Copia el nombre de usuario y la contraseña proporcionados para el lab
Haz clic en Abrir la consola en modo privado
Accede a la consola
Accede con tus credenciales del lab. Si usas otras credenciales, se generarán errores o se incurrirá en cargos.
Acepta las condiciones y omite la página de recursos de recuperación
No hagas clic en Finalizar lab, a menos que lo hayas terminado o quieras reiniciarlo, ya que se borrará tu trabajo y se quitará el proyecto
Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible
¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible
Un lab a la vez
Confirma para finalizar todos los labs existentes y comenzar este
Usa la navegación privada para ejecutar el lab
Usa una ventana de navegación privada o de Incógnito para ejecutar el lab. Así
evitarás cualquier conflicto entre tu cuenta personal y la cuenta
de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
Procesamiento de datos de transmisión: Canalizaciones de datos de transmisión
Duración:
1 min de configuración
·
Acceso por 90 min
·
90 min para completar
 ), selecciona IAM y administración > IAM.
), selecciona IAM y administración > IAM.

 ) y selecciona Conexión nueva a training-vm en el menú desplegable. Se abrirá una nueva ventana de la terminal.
) y selecciona Conexión nueva a training-vm en el menú desplegable. Se abrirá una nueva ventana de la terminal.