O ajuste de desempenho do BigQuery serve para reduzir o tempo ou o custo da execução de consultas. Neste laboratório, veremos algumas otimizações de desempenho que podem funcionar no seu caso de uso.
Faça o ajuste apenas no final do estágio de desenvolvimento, se você observar que as consultas demoram demais. É muito melhor ter esquemas de tabelas flexíveis e consultas refinadas, legíveis e fáceis de manter do que ofuscar os layouts de tabelas e consultas para aumentar um pouco o desempenho.
Vão ocorrer situações em que você terá que melhorar o desempenho das consultas, talvez porque elas sejam realizadas tantas vezes que pequenas melhorias façam diferença. O conhecimento sobre os pontos fortes e fracos do desempenho também ajuda na escolha de designs alternativos.
Objetivos
Neste laboratório, você conhecerá estas técnicas para reduzir o tempo e o custo de execução do BigQuery:
Minimizar E/S
Armazenar o resultado de consultas anteriores em cache
Fazer mesclagens eficientes
Evitar sobrecarregar workers
Usar funções de agregação aproximadas
Configuração e requisitos
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
Faça login no Qwiklabs em uma janela anônima.
Confira o tempo de acesso do laboratório (por exemplo, 1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
Quando tudo estiver pronto, clique em Começar o laboratório.
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
Clique em Abrir Console do Google.
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
Aceite os termos e pule a página de recursos de recuperação.
Abra o console do BigQuery
No Console do Google Cloud, selecione Menu de navegação > BigQuery. Você verá a caixa de mensagem Olá! Este é o BigQuery no Console do Cloud. Ela tem um link para o guia de início rápido e lista as atualizações da IU.
Clique em Concluído.
Tarefa 1: minimizar E/S
Uma consulta que calcula a soma de três colunas é mais lenta do que a que calcula a soma de duas, mas a diferença principal no desempenho é a leitura de um volume maior de dados, não a adição. Portanto, uma consulta que calcula a média de uma coluna é quase tão rápida quanto outra que tem como método de agregação o cálculo da variância dos dados. Isso ocorre apesar de o BigQuery ter que controlar tanto a soma quanto a soma dos quadrados no cálculo da variância. O motivo é que o overhead de consultas simples é gerado pela E/S, não pela computação.
Use SELECT com consciência
O BigQuery usa formatos de arquivos baseados em colunas. Por isso, quanto menos colunas a operação SELECT ler, menos dados ela terá que consultar. Em especial, a operação SELECT * lê todas as colunas de todas as linhas na tabela, sendo bastante lenta e cara. A exceção é quando você usa uma função SELECT * em uma subconsulta e faz referência a alguns campos em uma consulta externa. O otimizador do BigQuery é inteligente e lê apenas as colunas que são absolutamente necessárias.
SELECT
bike_id,
duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
ORDER BY
duration DESC
LIMIT
1
Na janela Resultados da consulta, vemos que a consulta levou quase 1,2 segundo e processou cerca de 372 MB de dados.
Execute esta consulta na janela do editor do BigQuery:
SELECT
*
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
ORDER BY
duration DESC
LIMIT
1
Na janela Resultados da consulta, vemos que a consulta levou quase 4,5 segundos e processou cerca de 2,6 GB de dados. Muito mais tempo.
Caso você precise de quase todas as colunas de uma tabela, use SELECT * EXCEPT para ler só as necessárias.
Observação: o BigQuery armazena em cache os resultados das consultas para acelerar a repetição delas. Para desativar o cache e conferir o desempenho real do processamento das consultas, clique em Mais > Configurações de consulta e desmarque Usar resultados em cache. Clique em SALVAR.
Reduza os dados lidos
Ao ajustar uma consulta, é importante verificar se é possível reduzir a quantidade de dados que são lidos. Suponha que queremos saber a duração típica dos aluguéis de trajeto único mais comuns.
Execute a consulta abaixo na janela EDITOR do BigQuery:
SELECT
MIN(start_station_name) AS start_station_name,
MIN(end_station_name) AS end_station_name,
APPROX_QUANTILES(duration, 10)[OFFSET (5)] AS typical_duration,
COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
start_station_id != end_station_id
GROUP BY
start_station_id,
end_station_id
ORDER BY
num_trips DESC
LIMIT
10
A resposta da sua consulta será parecida com esta:
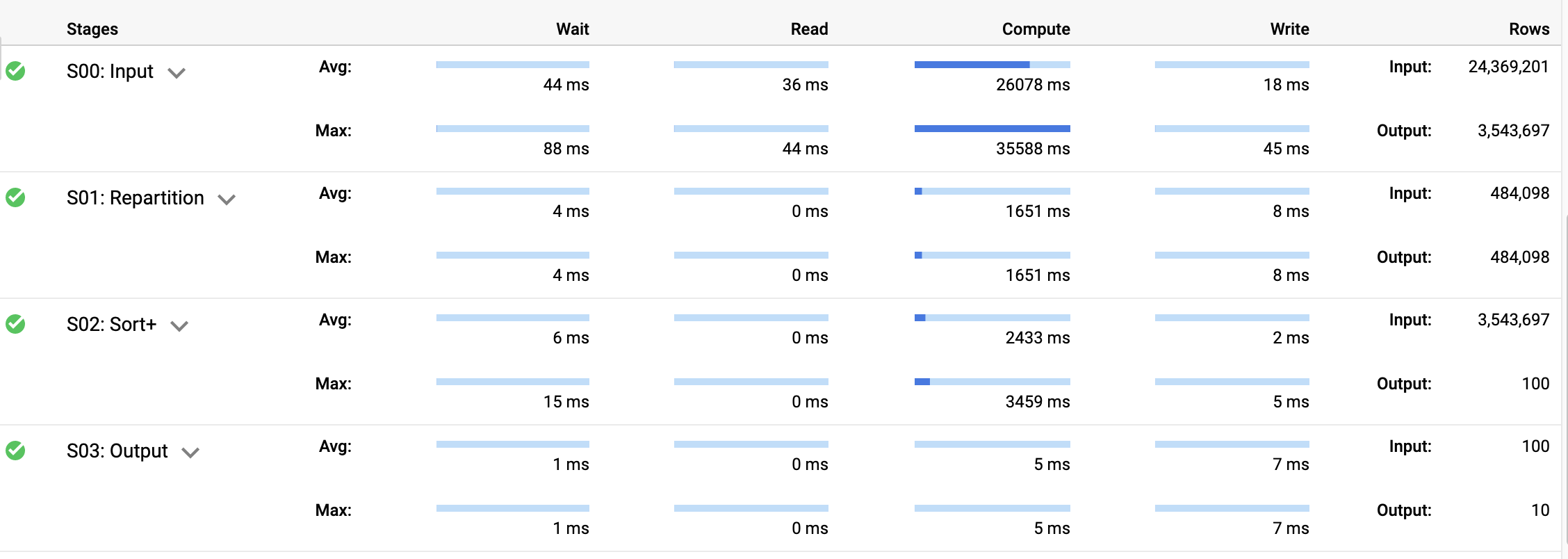
Clique na guia Detalhes da execução da janela Resultados da consulta.
Os detalhes indicam que a classificação (dos quantis aproximados de cada par de estações) exigiu a repartição das saídas do estágio de entrada, mas a maior parte do tempo foi gasta no cálculo.
Para reduzir o custo de E/S da consulta, podemos filtrar e agrupar usando os nomes das estações em vez dos IDs. Assim, teremos menos colunas para ler.
Execute esta consulta:
SELECT
start_station_name,
end_station_name,
APPROX_QUANTILES(duration, 10)[OFFSET(5)] AS typical_duration,
COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
start_station_name != end_station_name
GROUP BY
start_station_name,
end_station_name
ORDER BY
num_trips DESC
LIMIT
10
A consulta acima ignora a leitura das duas colunas de IDs e demora 10,8 segundos. Essa aceleração é causada pelos efeitos da redução da quantidade de dados lidos.
O resultado é o mesmo, porque há uma relação 1:1 entre os nomes e os IDs das estações.
Reduza o número de cálculos caros
Imagine que queremos descobrir qual é a distância total percorrida por cada bicicleta no conjunto de dados.
Uma forma simples de fazer isso seria descobrir a distância percorrida em cada deslocamento de uma bicicleta e somar os valores:
WITH
trip_distance AS (
SELECT
bike_id,
ST_Distance(ST_GeogPoint(s.longitude,
s.latitude),
ST_GeogPoint(e.longitude,
e.latitude)) AS distance
FROM
`bigquery-public-data`.london_bicycles.cycle_hire,
`bigquery-public-data`.london_bicycles.cycle_stations s,
`bigquery-public-data`.london_bicycles.cycle_stations e
WHERE
start_station_id = s.id
AND end_station_id = e.id )
SELECT
bike_id,
SUM(distance)/1000 AS total_distance
FROM
trip_distance
GROUP BY
bike_id
ORDER BY
total_distance DESC
LIMIT
5
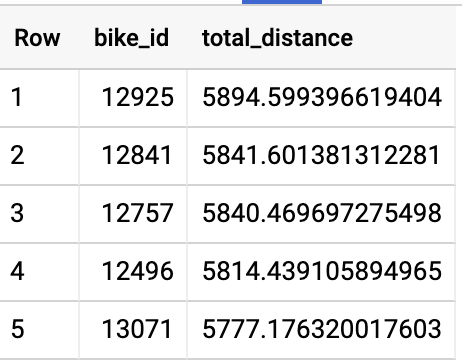
A consulta acima leva 9,8 segundos (55 segundos de tempo de slot) e faz o embaralhamento de 1,22 MB. O resultado é que algumas bicicletas percorreram quase 6 mil quilômetros.
O cálculo da distância é uma operação muito cara. Para evitar a mesclagem das tabelas cycle_stations e cycle_hire, podemos pré-calcular as distâncias entre todos os pares de estações:
WITH
stations AS (
SELECT
s.id AS start_id,
e.id AS end_id,
ST_Distance(ST_GeogPoint(s.longitude,
s.latitude),
ST_GeogPoint(e.longitude,
e.latitude)) AS distance
FROM
`bigquery-public-data`.london_bicycles.cycle_stations s,
`bigquery-public-data`.london_bicycles.cycle_stations e ),
trip_distance AS (
SELECT
bike_id,
distance
FROM
`bigquery-public-data`.london_bicycles.cycle_hire,
stations
WHERE
start_station_id = start_id
AND end_station_id = end_id )
SELECT
bike_id,
SUM(distance)/1000 AS total_distance
FROM
trip_distance
GROUP BY
bike_id
ORDER BY
total_distance DESC
LIMIT
5
Essa consulta só faz 600 mil cálculos de distância geográfica em comparação aos 24 milhões anteriores. Agora ela leva 31,5 segundos de tempo de slot (uma aceleração de 30%), apesar de embaralhar 33,05 MB de dados.
Clique em Verificar meu progresso para conferir o objetivo.
Minimizar E/S
Tarefa 2: armazenar em cache os resultados de consultas anteriores
O serviço do BigQuery armazena automaticamente os resultados das consultas anteriores em uma tabela temporária em cache. Se uma consulta idêntica for feita em um período de aproximadamente 24 horas, ele usará os resultados dessa tabela sem recalcular. Os resultados armazenados em cache são extremamente rápidos e não acarretam cobranças.
Mas você deve observar algumas ressalvas. O armazenamento em cache das consultas é baseado na comparação de strings exatas. Portanto, até mesmo espaços em branco podem causar uma ausência no cache. O armazenamento não ocorre nas seguintes situações: quando a consulta tem comportamento não determinístico (por exemplo, ela usa CURRENT_TIMESTAMP ou RAND); quando a tabela ou a visualização sendo consultada foi alterada (mesmo que as colunas ou linhas da consulta continuem iguais); quando a tabela está associada a um buffer de streaming (mesmo que não haja linhas novas); quando a consulta usa instruções DML ou lê fontes de dados externas.
Armazene em cache os resultados intermediários
É possível usar tabelas temporárias e visualizações materializadas para melhorar o desempenho geral às custas do aumento de E/S.
Por exemplo, suponha que algumas consultas comecem identificando a duração média dos deslocamentos entre duas estações. A cláusula WITH (também chamada de expressão de tabela comum) melhora a legibilidade, mas não melhora a velocidade nem o custo da consulta porque os resultados não são armazenados em cache. O mesmo vale para visualizações e subconsultas. Se você usa cláusulas WITH, visualizações ou subconsultas com frequência, talvez o armazenamento dos resultados em uma tabela (ou visualização materializada) melhore o desempenho.
Primeiro você tem que criar um conjunto de dados chamado mydataset na região EU (onde estão os dados sobre bicicletas) no seu projeto do BigQuery.
No painel esquerdo da seção Explorer, clique no ícone Ver ações (três pontos) próximo ao seu projeto do BigQuery (qwiklabs-gcp-xxxx) e selecione Criar conjunto de dados.
Na caixa de diálogo Criar conjunto de dados, siga estas instruções:
Defina o ID do conjunto de dados como mydataset.
Defina o Local dos dados como eu (multiple regions in European Union).
Deixe todas as outras opções com os valores padrão.
Para concluir, clique no botão azul CRIAR CONJUNTO DE DADOS.
Agora é possível executar esta consulta:
CREATE OR REPLACE TABLE
mydataset.typical_trip AS
SELECT
start_station_name,
end_station_name,
APPROX_QUANTILES(duration, 10)[OFFSET (5)] AS typical_duration,
COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
start_station_name,
end_station_name
Use a tabela criada para identificar os dias em que os deslocamentos de bicicleta são muito mais longos do que o normal:
SELECT
EXTRACT (DATE
FROM
start_date) AS trip_date,
APPROX_QUANTILES(duration / typical_duration, 10)[OFFSET(5)] AS ratio,
COUNT(*) AS num_trips_on_day
FROM
`bigquery-public-data`.london_bicycles.cycle_hire AS hire
JOIN
mydataset.typical_trip AS trip
ON
hire.start_station_name = trip.start_station_name
AND hire.end_station_name = trip.end_station_name
AND num_trips > 10
GROUP BY
trip_date
HAVING
num_trips_on_day > 10
ORDER BY
ratio DESC
LIMIT
10
Use a cláusula WITH para identificar os dias em que os deslocamentos de bicicleta são muito mais longos do que o normal:
WITH
typical_trip AS (
SELECT
start_station_name,
end_station_name,
APPROX_QUANTILES(duration, 10)[OFFSET (5)] AS typical_duration,
COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
start_station_name,
end_station_name )
SELECT
EXTRACT (DATE
FROM
start_date) AS trip_date,
APPROX_QUANTILES(duration / typical_duration, 10)[
OFFSET
(5)] AS ratio,
COUNT(*) AS num_trips_on_day
FROM
`bigquery-public-data`.london_bicycles.cycle_hire AS hire
JOIN
typical_trip AS trip
ON
hire.start_station_name = trip.start_station_name
AND hire.end_station_name = trip.end_station_name
AND num_trips > 10
GROUP BY
trip_date
HAVING
num_trips_on_day > 10
ORDER BY
ratio DESC
LIMIT
10
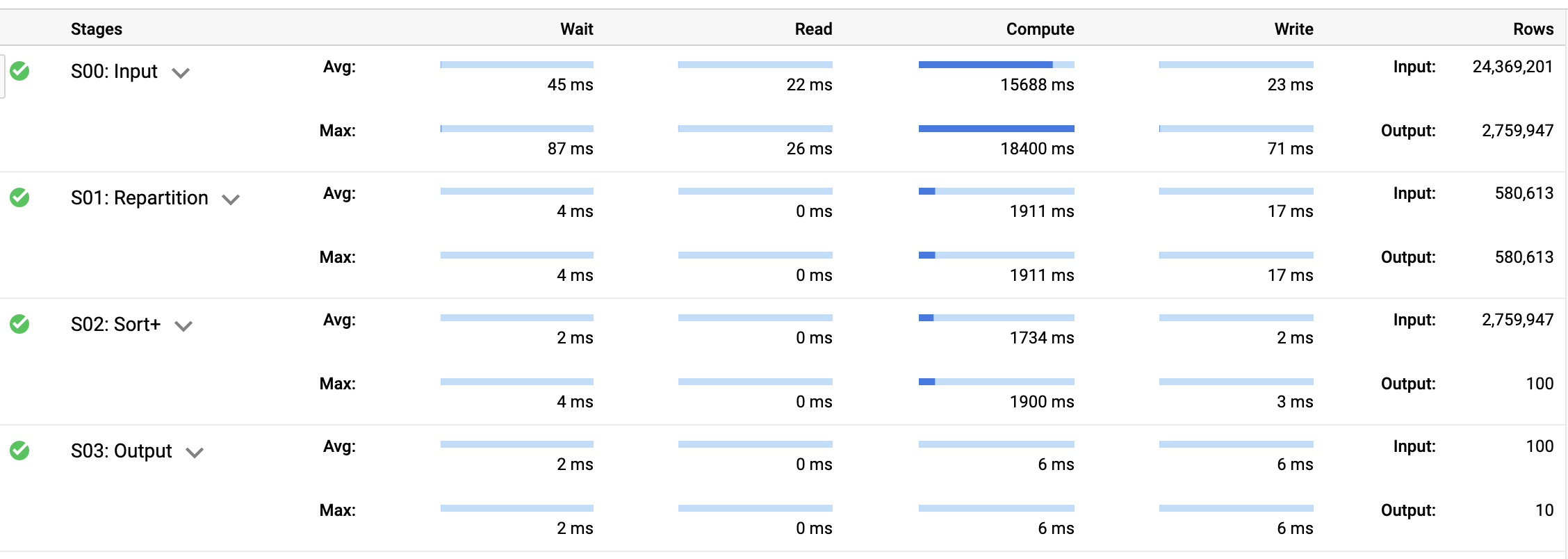
Observe que houve uma aceleração de cerca de 50%, porque não foi necessário calcular a duração média dos deslocamentos. As duas consultas mostram o mesmo resultado: os deslocamentos no Natal são mais longos do que o normal. A tabela mydataset.typical_trip não é atualizada quando são adicionados novos dados à tabela cycle_hire. Uma possível solução para esse problema de dados desatualizados é usar uma visualização materializada ou programar consultas para atualizar a tabela periodicamente. Meça o custo dessas atualizações para ver se a melhora no desempenho da consulta compensa o custo extra de manter atualizada a tabela ou a visualização materializada.
Acelere as consultas com o BI Engine
Se você acessa algumas tabelas com frequência ao lidar com Business Intelligence (BI), como painéis com agregações e filtros, use o BI Engine para agilizar suas consultas. Ele armazena automaticamente os dados relevantes na memória (colunas da tabela ou resultados derivados) e usa um processador de consultas especializado, adaptado para trabalhar principalmente com dados na memória. Você pode reservar a quantidade de memória (até 10 GB atualmente) que o BigQuery deve usar no cache no Admin Console do BigQuery, em BI Engine.
Reserve essa memória na mesma região do conjunto de dados que você consultará. O BigQuery começará a armazenar tabelas, partes de tabelas e agregações na memória e exibirá os resultados mais rapidamente.
Um caso de uso importante do BI Engine é para tabelas que são acessadas por ferramentas de painéis como o Google Data Studio. Com a alocação de memória para uma reserva do BI Engine, podemos deixar os painéis que dependem do back-end do BigQuery mais responsivos.
Clique em Verificar meu progresso para conferir o objetivo.
Armazenar em cache os resultados de consultas anteriores
Tarefa 3: mesclagens eficientes
A mesclagem de duas tabelas exige coordenação dos dados e está sujeita às limitações impostas pela largura de banda de comunicação entre os slots. Se for possível, evite fazer mesclagens ou reduza a quantidade de dados mesclados.
Desnormalização
Uma maneira de agilizar a leitura e evitar as mesclagens é parar de armazenar dados de forma eficiente e, em vez disso, adicionar cópias redundantes deles. O nome disso é desnormalização.
Logo, em vez de armazenar as latitudes e as longitudes das estações de bicicletas separadamente das informações de aluguel de bicicletas, podemos criar uma tabela desnormalizada:
CREATE OR REPLACE TABLE
mydataset.london_bicycles_denorm AS
SELECT
start_station_id,
s.latitude AS start_latitude,
s.longitude AS start_longitude,
end_station_id,
e.latitude AS end_latitude,
e.longitude AS end_longitude
FROM
`bigquery-public-data`.london_bicycles.cycle_hire AS h
JOIN
`bigquery-public-data`.london_bicycles.cycle_stations AS s
ON
h.start_station_id = s.id
JOIN
`bigquery-public-data`.london_bicycles.cycle_stations AS e
ON
h.end_station_id = e.id
As consultas posteriores não terão que fazer a mesclagem, porque a tabela vai conter as informações de localização necessárias para todos os deslocamentos. Nesse caso, você sacrifica o armazenamento e a quantidade de dados lidos para evitar o custo computacional da mesclagem. Talvez o custo de ler mais dados no disco supere o custo da mesclagem. Você precisa analisar se a desnormalização aumenta o desempenho.
Clique em Verificar meu progresso para conferir o objetivo.
Desnormalização
Evite mesclagens automáticas de tabelas grandes
A mesclagem automática ocorre quando uma tabela é mesclada consigo mesma. O BigQuery faz mesclagens automáticas, mas elas podem reduzir o desempenho se a tabela em questão for muito grande. Em muitos casos, você pode explorar recursos do SQL como a agregação e as funções de janela para evitar a mesclagem automática.
Vejamos um exemplo. Um dos conjuntos de dados públicos do BigQuery, da Administração da Previdência Social dos EUA, contém nomes de bebês.
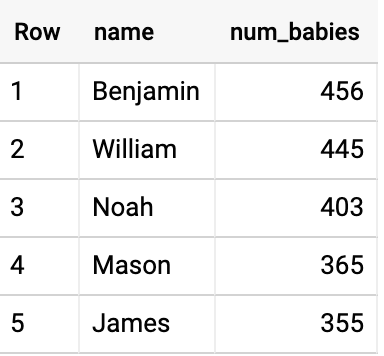
É possível consultar o conjunto de dados para identificar os nomes masculinos mais comuns em 2015 no estado de Massachusetts. Execute a consulta abaixo na região US: selecione a região em Mais > Configurações de consulta > Local de processamento.
SELECT
name,
number AS num_babies
FROM
`bigquery-public-data`.usa_names.usa_1910_current
WHERE
gender = 'M'
AND year = 2015
AND state = 'MA'
ORDER BY
num_babies DESC
LIMIT
5
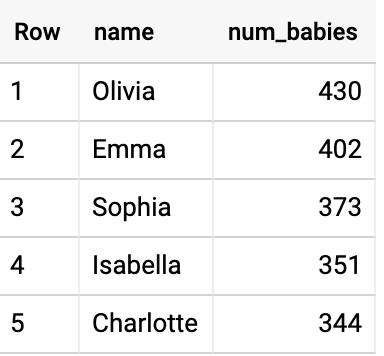
Da mesma forma, consulte o conjunto de dados para identificar os nomes femininos mais comuns em 2015 no estado de Massachusetts:
Quais são os nomes de bebês mais comuns no país ao longo dos anos?
Uma forma simples de resolver esse problema seria ler a tabela de entrada duas vezes e fazer uma mesclagem automática:
WITH
male_babies AS (
SELECT
name,
number AS num_babies
FROM
`bigquery-public-data`.usa_names.usa_1910_current
WHERE
gender = 'M' ),
female_babies AS (
SELECT
name,
number AS num_babies
FROM
`bigquery-public-data`.usa_names.usa_1910_current
WHERE
gender = 'F' ),
both_genders AS (
SELECT
name,
SUM(m.num_babies) + SUM(f.num_babies) AS num_babies,
SUM(m.num_babies) / (SUM(m.num_babies) + SUM(f.num_babies)) AS frac_male
FROM
male_babies AS m
JOIN
female_babies AS f
USING
(name)
GROUP BY
name )
SELECT
*
FROM
both_genders
WHERE
frac_male BETWEEN 0.3
AND 0.7
ORDER BY
num_babies DESC
LIMIT
5
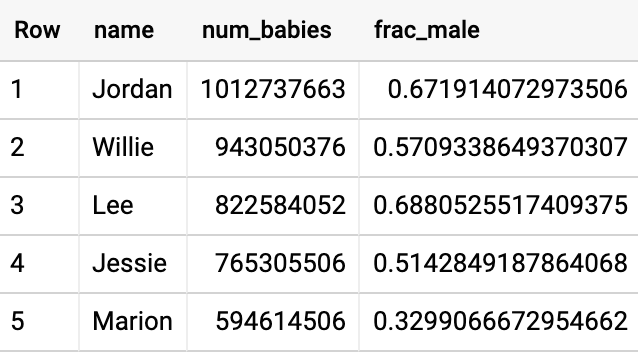
A consulta levou 74 segundos e teve o seguinte resultado:
Para piorar as coisas, a resposta está errada. Nós adoramos o nome Jordan, mas não é possível que 982 milhões de bebês tenham esse nome, já que a população americana é de apenas 300 milhões. A mesclagem automática atua entre os limites de estados e de anos.
Uma solução mais rápida, refinada e correta é recriar a consulta para ler a entrada só uma vez e evitar a mesclagem automática.
WITH
all_babies AS (
SELECT
name,
SUM(
IF
(gender = 'M',
number,
0)) AS male_babies,
SUM(
IF
(gender = 'F',
number,
0)) AS female_babies
FROM
`bigquery-public-data.usa_names.usa_1910_current`
GROUP BY
name ),
both_genders AS (
SELECT
name,
(male_babies + female_babies) AS num_babies,
SAFE_DIVIDE(male_babies,
male_babies + female_babies) AS frac_male
FROM
all_babies
WHERE
male_babies > 0
AND female_babies > 0 )
SELECT
*
FROM
both_genders
WHERE
frac_male BETWEEN 0.3
AND 0.7
ORDER BY
num_babies DESC
LIMIT
5
Essa consulta só levou 2,4 segundos, ou seja, ela foi 30 vezes mais rápida.
Reduza os dados mesclados
É possível fazer a consulta acima com uma mesclagem eficiente, contanto que você agrupe os dados por nome e sexo para reduzir a quantidade de dados mesclados:
Execute esta consulta:
WITH
all_names AS (
SELECT
name,
gender,
SUM(number) AS num_babies
FROM
`bigquery-public-data`.usa_names.usa_1910_current
GROUP BY
name,
gender ),
male_names AS (
SELECT
name,
num_babies
FROM
all_names
WHERE
gender = 'M' ),
female_names AS (
SELECT
name,
num_babies
FROM
all_names
WHERE
gender = 'F' ),
ratio AS (
SELECT
name,
(f.num_babies + m.num_babies) AS num_babies,
m.num_babies / (f.num_babies + m.num_babies) AS frac_male
FROM
male_names AS m
JOIN
female_names AS f
USING
(name) )
SELECT
*
FROM
ratio
WHERE
frac_male BETWEEN 0.3
AND 0.7
ORDER BY
num_babies DESC
LIMIT
5
O agrupamento antecipado eliminou os dados da consulta antes que ela executasse uma função JOIN. Dessa forma, o embaralhamento e outras operações complexas foram executados em uma quantidade muito menor de dados e mantiveram a eficiência. A consulta acima levou 2 segundos e retornou o resultado correto.
Use uma função de janela em vez de uma mesclagem automática
Suponha que você queira descobrir qual é a duração entre a devolução de uma bicicleta e o momento em que ela é alugada de novo, ou seja, o tempo que a bicicleta permanece na estação. Esse é um exemplo de uma relação dependente entre as linhas. Talvez pareça que a única forma de solucionar isso é mesclar a tabela consigo mesma, fazendo a correspondência do valor de end_date de um deslocamento ao valor de start_date do próximo deslocamento. Para confirmar que a consulta está sendo executada na região EU, selecione Mais > Configurações de consulta > Local de processamento.
Evite a mesclagem automática usando uma função de janela:
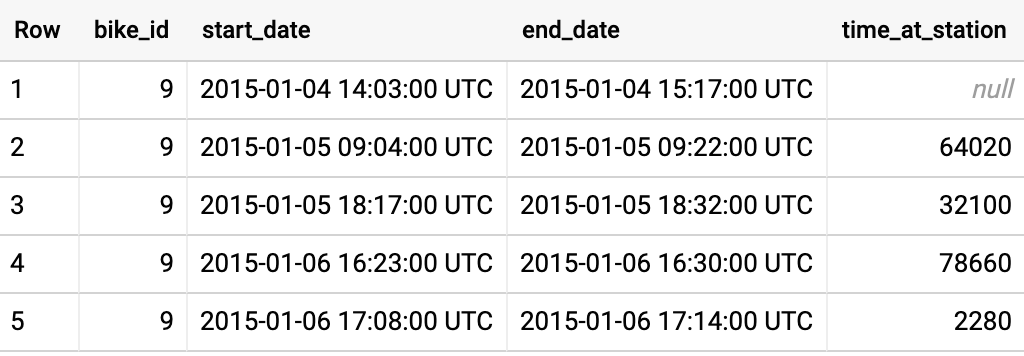
SELECT
bike_id,
start_date,
end_date,
TIMESTAMP_DIFF( start_date, LAG(end_date) OVER (PARTITION BY bike_id ORDER BY start_date), SECOND) AS time_at_station
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
LIMIT
5
A primeira linha tem null em time_at_station, porque não temos o carimbo de data/hora da devolução anterior. Depois disso, time_at_station indica a diferença entre a devolução anterior e a retirada atual.
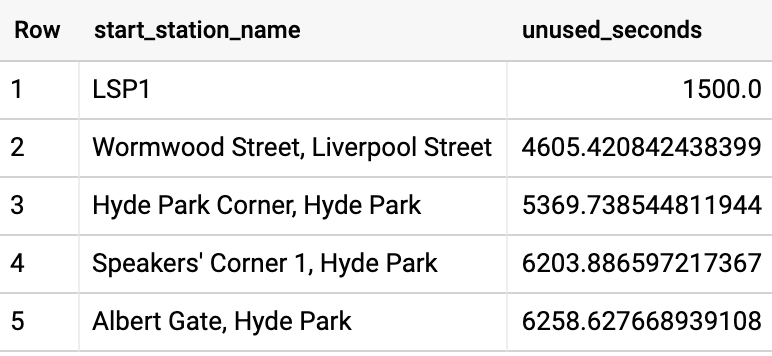
Com base nisso, podemos calcular o tempo médio em que a bicicleta fica sem uso em cada estação e classificar as estações por essa medida:
WITH
unused AS (
SELECT
bike_id,
start_station_name,
start_date,
end_date,
TIMESTAMP_DIFF(start_date, LAG(end_date) OVER (PARTITION BY bike_id ORDER BY start_date), SECOND) AS time_at_station
FROM
`bigquery-public-data`.london_bicycles.cycle_hire )
SELECT
start_station_name,
AVG(time_at_station) AS unused_seconds
FROM
unused
GROUP BY
start_station_name
ORDER BY
unused_seconds ASC
LIMIT
5
Faça mesclagens com valores pré-calculados
Às vezes, é melhor pré-calcular as funções em tabelas menores e depois fazer a mesclagem com esses valores, em vez de repetir um cálculo caro a cada vez.
Por exemplo, digamos que queremos descobrir qual é o par de estações entre as quais os clientes conseguem se deslocar mais rapidamente. Para calcular o ritmo de deslocamento (minutos por quilômetro), nós dividimos a duração do percurso pela distância entre as estações.
Seria possível criar uma tabela desnormalizada com as distâncias entre as estações, depois calcular o ritmo médio:
WITH
denormalized_table AS (
SELECT
start_station_name,
end_station_name,
ST_DISTANCE(ST_GeogPoint(s1.longitude,
s1.latitude),
ST_GeogPoint(s2.longitude,
s2.latitude)) AS distance,
duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire AS h
JOIN
`bigquery-public-data`.london_bicycles.cycle_stations AS s1
ON
h.start_station_id = s1.id
JOIN
`bigquery-public-data`.london_bicycles.cycle_stations AS s2
ON
h.end_station_id = s2.id ),
durations AS (
SELECT
start_station_name,
end_station_name,
MIN(distance) AS distance,
AVG(duration) AS duration,
COUNT(*) AS num_rides
FROM
denormalized_table
WHERE
duration > 0
AND distance > 0
GROUP BY
start_station_name,
end_station_name
HAVING
num_rides > 100 )
SELECT
start_station_name,
end_station_name,
distance,
duration,
duration/distance AS pace
FROM
durations
ORDER BY
pace ASC
LIMIT
5
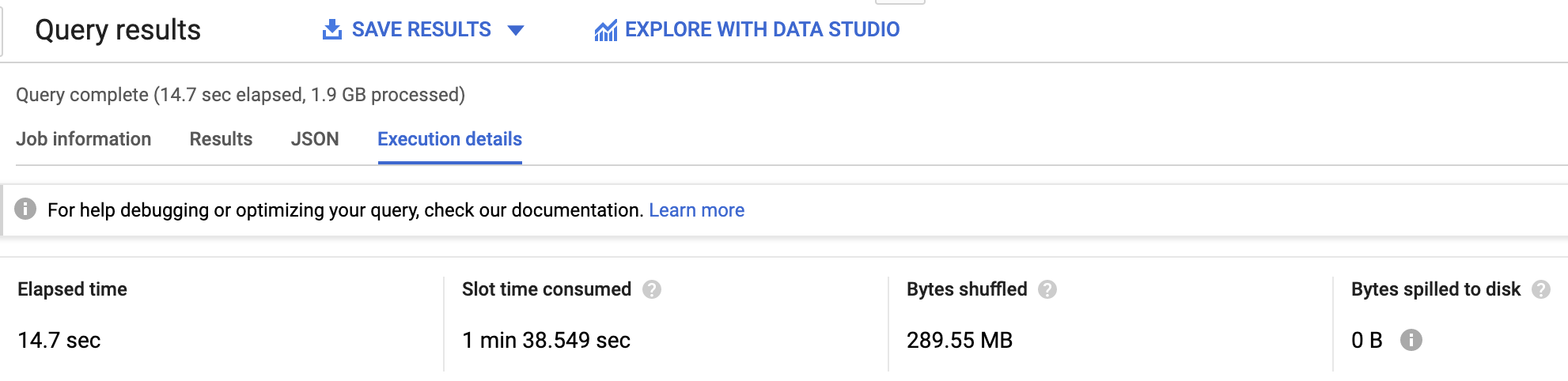
A consulta acima invoca a função geoespacial ST_DISTANCE uma vez para cada linha da tabela cycle_hire (24 milhões de vezes), dura 14,7 segundos e processa 1,9 GB.
Uma alternativa é usar a tabela cycle_stations para pré-calcular a distância entre cada par de estações (mesclagem automática) e depois mesclar o resultado com a tabela menor de duração média entre as estações:
WITH
distances AS (
SELECT
a.id AS start_station_id,
a.name AS start_station_name,
b.id AS end_station_id,
b.name AS end_station_name,
ST_DISTANCE(ST_GeogPoint(a.longitude,
a.latitude),
ST_GeogPoint(b.longitude,
b.latitude)) AS distance
FROM
`bigquery-public-data`.london_bicycles.cycle_stations a
CROSS JOIN
`bigquery-public-data`.london_bicycles.cycle_stations b
WHERE
a.id != b.id ),
durations AS (
SELECT
start_station_id,
end_station_id,
AVG(duration) AS duration,
COUNT(*) AS num_rides
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
duration > 0
GROUP BY
start_station_id,
end_station_id
HAVING
num_rides > 100 )
SELECT
start_station_name,
end_station_name,
distance,
duration,
duration/distance AS pace
FROM
distances
JOIN
durations
USING
(start_station_id,
end_station_id)
ORDER BY
pace ASC
LIMIT
5
A consulta recriada com as mesclagens mais eficientes leva só 8,2 segundos, é 1,8x mais rápida e processa apenas 554 MB, uma redução de quase quatro vezes no custo.
Clique em Verificar meu progresso para conferir o objetivo.
Mesclagens
Tarefa 4: evitar sobrecarregar workers
Algumas operações, como classificações, precisam ser realizadas em apenas um worker. O excesso de dados para classificar pode sobrecarregar a memória do worker e causar o erro "recursos excedidos". Evite sobrecarregar o worker com dados demais. Com os upgrades do hardware nos data centers do Google, a definição de "dados demais" aumenta com o tempo. Atualmente, esse limite é de aproximadamente 1 GB.
Limite grandes classificações
Imagine que queremos classificar os aluguéis em 1, 2, 3 etc., na ordem em que eles chegaram ao fim dos respectivos prazos. Podemos fazer isso usando a função ROW_NUMBER():
SELECT
rental_id,
ROW_NUMBER() OVER(ORDER BY end_date) AS rental_number
FROM
`bigquery-public-data.london_bicycles.cycle_hire`
ORDER BY
rental_number ASC
LIMIT
5
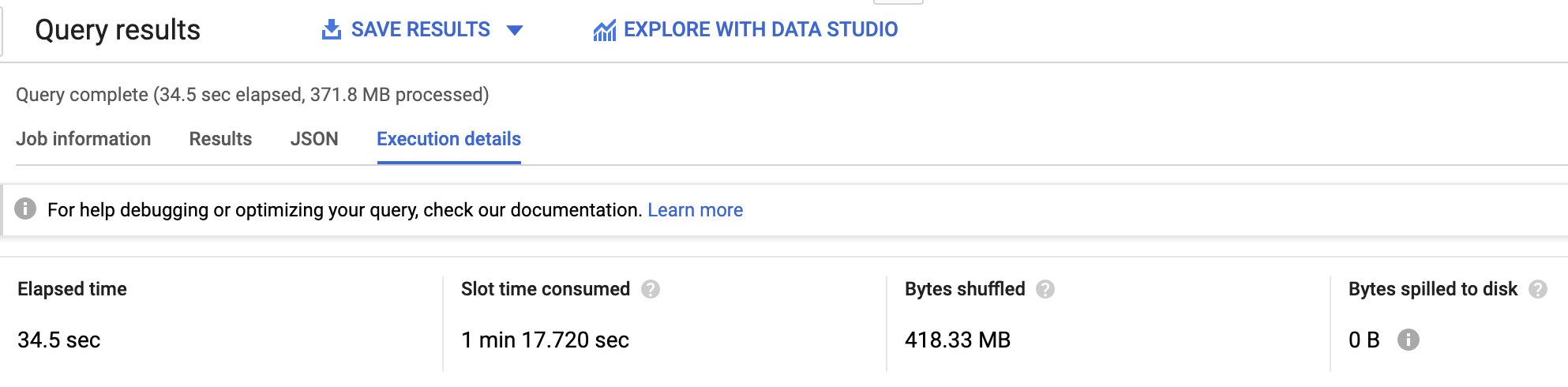
A consulta leva 34,5 segundos para processar apenas 372 MB, porque ela precisa classificar todo o conjunto de dados de bicicletas de Londres em um só worker. Se o conjunto de dados processado fosse maior, o worker ficaria sobrecarregado.
Vamos ver se é possível limitar e distribuir classificações grandes.
De fato, é possível extrair a data dos aluguéis, depois classificar os deslocamentos em cada dia:
WITH
rentals_on_day AS (
SELECT
rental_id,
end_date,
EXTRACT(DATE
FROM
end_date) AS rental_date
FROM
`bigquery-public-data.london_bicycles.cycle_hire` )
SELECT
rental_id,
rental_date,
ROW_NUMBER() OVER(PARTITION BY rental_date ORDER BY end_date) AS rental_number_on_day
FROM
rentals_on_day
ORDER BY
rental_date ASC,
rental_number_on_day ASC
LIMIT
5
Isso leva 15,1 segundos (ou seja, a metade do tempo), porque é possível fazer a classificação dos dados de um dia por vez.
Clique em Verificar meu progresso para conferir o objetivo.
Evitar sobrecarregar workers
Desvio de dados
O mesmo problema de sobrecarregar um worker (neste caso, a memória dele) pode acontecer em operações ARRAY_AGG com GROUP BY caso uma das chaves seja muito mais comum do que as outras.
A consulta abaixo é concluída com êxito porque há mais de três milhões de repositórios do GitHub, e os commits estão bem distribuídos entre eles. Execute a consulta no centro de processamento US:
SELECT
repo_name,
ARRAY_AGG(STRUCT(author,
committer,
subject,
message,
trailer,
difference,
encoding)
ORDER BY
author.date.seconds)
FROM
`bigquery-public-data.github_repos.commits`,
UNNEST(repo_name) AS repo_name
GROUP BY
repo_name
Observação: essa consulta será realizada, mas poderá levar mais de 15 minutos. Se você já entendeu a consulta, prossiga com o laboratório.
Como a maioria das pessoas que usam o GitHub reside em poucos fusos horários, não é possível fazer agrupamentos com base nessa informação. Solicitamos que apenas um worker classifique uma parte significativa de 750 GB de dados:
SELECT
author.tz_offset,
ARRAY_AGG(STRUCT(author,
committer,
subject,
message,
trailer,
difference,
encoding)
ORDER BY
author.date.seconds)
FROM
`bigquery-public-data.github_repos.commits`
GROUP BY
author.tz_offset
Para classificar todos os dados, use chaves mais granulares (por exemplo, distribua os dados do grupo por mais workers) e agregue os resultados que corresponderem à chave desejada.
Por exemplo, em vez de agrupar só pelo fuso horário, é possível agrupar por timezone e repo_name e agregar entre os repositórios para ver a resposta real de cada fuso horário:
SELECT
repo_name,
author.tz_offset,
ARRAY_AGG(STRUCT(author,
committer,
subject,
message,
trailer,
difference,
encoding)
ORDER BY
author.date.seconds)
FROM
`bigquery-public-data.github_repos.commits`,
UNNEST(repo_name) AS repo_name
GROUP BY
repo_name,
author.tz_offset
Essa consulta será realizada, mas poderá levar mais de 15 minutos para ser concluída. Se você já entendeu a consulta, prossiga com o laboratório.
Tarefa 5: usar funções de agregação aproximadas
O BigQuery gera aproximações rápidas das funções de agregação, com baixo uso de memória. Em vez de usar COUNT(DISTINCT …), podemos usar APPROX_COUNT_DISTINCT em grandes fluxos de dados quando uma pequena incerteza estatística no resultado é tolerável.
Faça uma aproximação da contagem
Podemos usar esta consulta para descobrir o número de repositórios exclusivos do GitHub:
SELECT
COUNT(DISTINCT repo_name) AS num_repos
FROM
`bigquery-public-data`.github_repos.commits,
UNNEST(repo_name) AS repo_name
A consulta acima leva 8,3 segundos para calcular o resultado correto, 3.347.770.
Se for usada a função de aproximação:
SELECT
APPROX_COUNT_DISTINCT(repo_name) AS num_repos
FROM
`bigquery-public-data`.github_repos.commits,
UNNEST(repo_name) AS repo_name
Isso vai levar 3,9 segundos (ou seja, a metade do tempo), gerando um resultado aproximado de 3.399.473, que é 1,5% maior do que a resposta correta.
O algoritmo de aproximação é muito mais eficiente do que o algoritmo exato apenas em conjuntos de dados grandes. Recomendamos usá-lo apenas quando erros de cerca de 1% forem toleráveis. Antes de usar a função de aproximação, avalie-a no seu caso de uso.
Outras funções de aproximação disponíveis são APPROX_QUANTILES para calcular percentis, APPROX_TOP_COUNT para identificar os elementos superiores e APPROX_TOP_SUM para calcular os elementos superiores com base na soma de um elemento.
Clique em Verificar meu progresso para conferir o objetivo.
Usar funções de agregação aproximadas
Parabéns!
Você aprendeu algumas técnicas para melhorar o desempenho das suas consultas. Quando pensar em usar essas técnicas, lembre-se da frase do lendário cientista da computação Donald Knuth: "A otimização prematura é a raiz de todo mal".
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.
Os laboratórios criam um projeto e recursos do Google Cloud por um período fixo
Os laboratórios têm um limite de tempo e não têm o recurso de pausa. Se você encerrar o laboratório, vai precisar recomeçar do início.
No canto superior esquerdo da tela, clique em Começar o laboratório
Usar a navegação anônima
Copie o nome de usuário e a senha fornecidos para o laboratório
Clique em Abrir console no modo anônimo
Fazer login no console
Faça login usando suas credenciais do laboratório. Usar outras credenciais pode causar erros ou gerar cobranças.
Aceite os termos e pule a página de recursos de recuperação
Não clique em Terminar o laboratório a menos que você tenha concluído ou queira recomeçar, porque isso vai apagar seu trabalho e remover o projeto
Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível
Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível
Um laboratório por vez
Confirme para encerrar todos os laboratórios atuais e iniciar este
Use a navegação anônima para executar o laboratório
Para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
Neste laboratório, veremos algumas técnicas para reduzir o tempo e o custo de execução de consultas no BigQuery.
Duração:
Configuração: 0 minutos
·
Tempo de acesso: 60 minutos
·
Tempo para conclusão: 60 minutos