개요
쿼리 실행 시간 및 비용 절약을 위해 일반적으로 BigQuery 성능 조정이 실행됩니다. 이 실습에서는 사용 사례에서 활용할 수 있는 여러 성능 최적화에 대해 살펴보겠습니다.
성능 조정은 개발 마지막 단계에서, 그리고 일반 쿼리에 시간이 너무 많이 소요되는 경우에만 실행해야 합니다. 테이블 레이아웃과 쿼리를 난독화하여 성능을 약간 향상시키는 것보다, 유연한 테이블 스키마와 읽기 쉽고 유지보수가 가능한 고급 쿼리를 활용하는 것이 훨씬 좋습니다.
너무 잦은 쿼리 수행으로 인해 조금이라도 개선하는 것이 유의미하여 쿼리 성능을 개선해야 하는 경우가 있습니다. 또한, 성능별 손익 균형 측면에 대해서도 알아두면 설계 대안을 선택하는 데 도움이 됩니다.
목표
이 실습에서는 BigQuery 실행 시간 및 비용을 절약하는 기술에 대해 다음과 같이 살펴보겠습니다.
- I/O 최소화
- 이전 쿼리의 결과 캐싱
- 효율적인 조인 실행
- 단일 작업자 과부하 피하기
- 근사 집계 함수 사용
설정 및 요건
각 실습에서는 정해진 기간 동안 새 Google Cloud 프로젝트와 리소스 집합이 무료로 제공됩니다.
-
시크릿 창을 사용하여 Qwiklabs에 로그인합니다.
-
실습 사용 가능 시간(예: 1:15:00)을 참고하여 해당 시간 내에 완료합니다.
일시중지 기능은 없습니다. 필요한 경우 다시 시작할 수 있지만 처음부터 시작해야 합니다.
-
준비가 되면 실습 시작을 클릭합니다.
-
실습 사용자 인증 정보(사용자 이름 및 비밀번호)를 기록해 두세요. Google Cloud Console에 로그인합니다.
-
Google Console 열기를 클릭합니다.
-
다른 계정 사용을 클릭한 다음, 안내 메시지에 이 실습에 대한 사용자 인증 정보를 복사하여 붙여넣습니다.
다른 사용자 인증 정보를 사용하는 경우 오류가 발생하거나 요금이 부과됩니다.
-
약관에 동의하고 리소스 복구 페이지를 건너뜁니다.
BigQuery 콘솔 열기
-
Google Cloud 콘솔의 탐색 메뉴에서 BigQuery를 클릭합니다.
Cloud 콘솔의 BigQuery에 오신 것을 환영합니다라는 대화상자가 열립니다. 이 대화상자에서는 빠른 시작 가이드 링크 및 UI 업데이트 목록을 확인할 수 있습니다.
-
완료를 클릭하여 대화상자를 닫습니다.
작업 1. I/O 최소화
세 열의 합계를 계산하는 쿼리는 두 열의 합계를 계산하는 쿼리보다 느리겠지만, 대부분 성능 차이는 추가로 계산해야 해서가 아니라 데이터를 더 많이 읽어야 해서 발생합니다. 따라서, 단순 쿼리의 오버헤드 대부분은 계산이 아닌 I/O에서 발생하는 것이기 때문에, 분산을 계산하려면 BigQuery에서 데이터의 합과 데이터의 제곱의 합, 두 가지를 모두 추적해야 하지만, 열 평균을 계산하는 쿼리와 데이터 분산을 계산하는 집계 메서드의 쿼리 속도는 거의 같습니다.
SELECT에서 효율적으로 작업
BigQuery는 열 파일 형식을 사용하기 때문에 SELECT에서 읽는 열이 적을수록 읽을 데이터의 양이 적어집니다. 특히, SELECT *를 수행하면 테이블에서 모든 행의 모든 열을 읽게 되어 매우 느려지고 효율성이 저하됩니다. 서브 쿼리에서 SELECT *를 사용하고 그때 외부 쿼리에서 몇몇 필드만 참조하는 경우는 예외입니다. 이 경우에는 BigQuery 옵티마이저의 스마트 기능이 꼭 필요한 열만 읽습니다.
-
BigQuery 편집기 창에서 다음 쿼리 실행:
SELECT
bike_id,
duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
ORDER BY
duration DESC
LIMIT
1
쿼리 결과 창에서, 쿼리가 약 1.2초 내에 완료되고 약 372MB의 데이터를 처리하는 것을 알 수 있습니다.
- BigQuery 편집기 창에서 다음 쿼리 실행:
SELECT
*
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
ORDER BY
duration DESC
LIMIT
1
쿼리 결과 창에서, 쿼리가 약 4.5초 내에 완료되고 약 2.6GB의 데이터를 처리하는 것을 알 수 있습니다. 훨씬 길군요!
테이블의 거의 모든 열이 필요한 경우, 필요 없는 열은 읽지 않도록 SELECT * EXCEPT를 사용할 수 있습니다.
참고: BigQuery에서는 쿼리 결과를 캐시하여 반복 쿼리 속도를 개선합니다. 이 캐시를 끄고 실제 쿼리 처리 성능을 확인하려면 더보기 > 쿼리 설정을 클릭하고 캐시 결과 사용을 선택 해제합니다. 저장을 클릭합니다.
읽는 데이터의 양 감소
쿼리를 조정할 때, 읽고 있는 데이터를 먼저 살펴 보고 이를 줄일 수 있는지 고려하는 게 중요합니다. 가장 일반적인 편도 대여 시간을 찾는다고 가정해 볼까요.
- BigQuery 편집기 창에서 다음 쿼리 실행:
SELECT
MIN(start_station_name) AS start_station_name,
MIN(end_station_name) AS end_station_name,
APPROX_QUANTILES(duration, 10)[OFFSET (5)] AS typical_duration,
COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
start_station_id != end_station_id
GROUP BY
start_station_id,
end_station_id
ORDER BY
num_trips DESC
LIMIT
10
쿼리는 다음과 같이 출력됩니다.

-
쿼리 결과 창에서 실행 세부정보 탭을 클릭합니다.
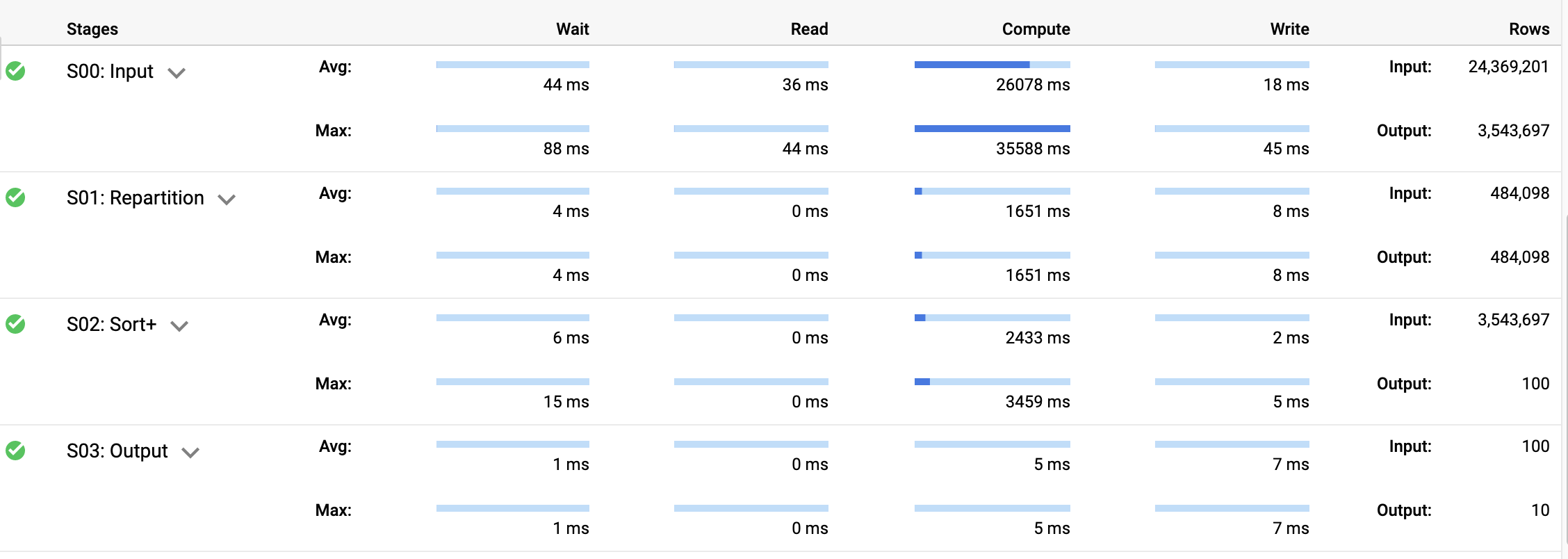
쿼리 세부정보를 통해 각 대여소 쌍의 근사 분위수에 대한 정렬에는 입력 단계에서 출력 다시 나누기가 필요하지만 대부분의 시간은 계산에 쓰인다는 것을 확인할 수 있습니다.
대여소 id보다는 대여소 이름을 사용해 필터링 및 그룹화를 하면 읽어야 할 열이 적어지므로 쿼리의 I/O 오버헤드를 줄일 수 있습니다.
- 다음 쿼리를 실행합니다.
SELECT
start_station_name,
end_station_name,
APPROX_QUANTILES(duration, 10)[OFFSET(5)] AS typical_duration,
COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
start_station_name != end_station_name
GROUP BY
start_station_name,
end_station_name
ORDER BY
num_trips DESC
LIMIT
10
위의 쿼리에서는 두 개의 id 열을 읽을 필요 없이 10.8초 내에 완료합니다. 이와 같은 속도 향상은 데이터를 더 적게 읽는 다운스트림 효과로 가능합니다.
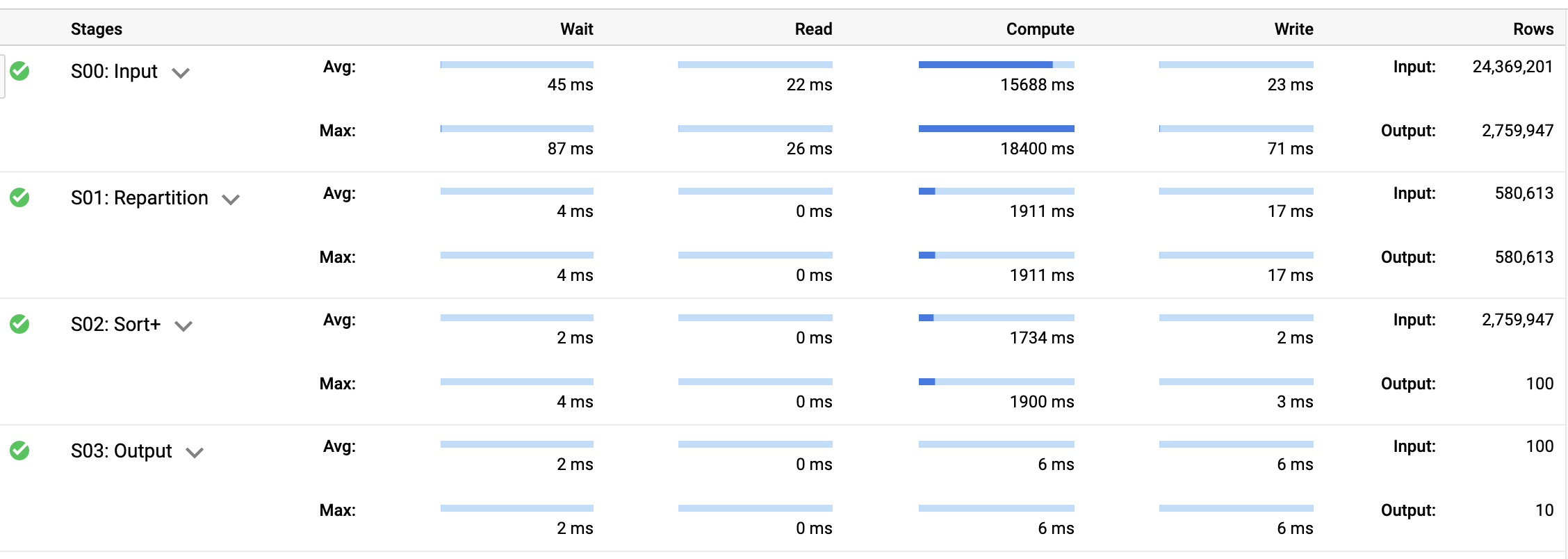
대여소 이름과 대여소 ID가 1:1 대응 관계이므로 쿼리 결과는 동일합니다.
컴퓨팅 리소스가 많이 드는 계산 수 감소
데이터 세트에서 각 자전거의 총 주행거리를 찾고자 하는 경우를 가정해 봅시다.
- 한 가지 원시적인 방법은 각 자전거에 대해 대여 시 주행 거리를 찾아 그 합계를 구하는 것입니다.
WITH
trip_distance AS (
SELECT
bike_id,
ST_Distance(ST_GeogPoint(s.longitude,
s.latitude),
ST_GeogPoint(e.longitude,
e.latitude)) AS distance
FROM
`bigquery-public-data`.london_bicycles.cycle_hire,
`bigquery-public-data`.london_bicycles.cycle_stations s,
`bigquery-public-data`.london_bicycles.cycle_stations e
WHERE
start_station_id = s.id
AND end_station_id = e.id )
SELECT
bike_id,
SUM(distance)/1000 AS total_distance
FROM
trip_distance
GROUP BY
bike_id
ORDER BY
total_distance DESC
LIMIT
5
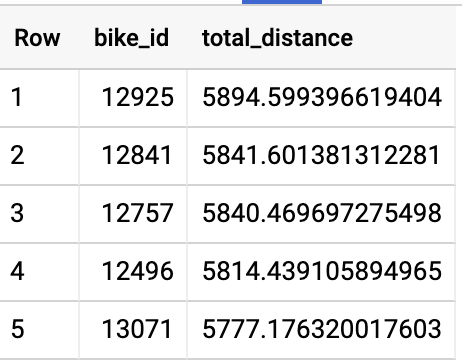
위의 쿼리 실행은 9.8초(슬롯 시간으로는 55초)가 소요되고 1.22MB의 데이터를 셔플합니다. 결과를 보면 일부 자전거는 6,000킬로미터 가까이 주행했습니다.
- 거리 계산은 부하가 많이 걸리는 작업이기 때문에 다음과 같이 대여소의 모든 쌍 사이의 거리를 미리 계산하는 경우
cycle_stations와 cycle_hire table을 조인하지 않아도 됩니다.
WITH
stations AS (
SELECT
s.id AS start_id,
e.id AS end_id,
ST_Distance(ST_GeogPoint(s.longitude,
s.latitude),
ST_GeogPoint(e.longitude,
e.latitude)) AS distance
FROM
`bigquery-public-data`.london_bicycles.cycle_stations s,
`bigquery-public-data`.london_bicycles.cycle_stations e ),
trip_distance AS (
SELECT
bike_id,
distance
FROM
`bigquery-public-data`.london_bicycles.cycle_hire,
stations
WHERE
start_station_id = start_id
AND end_station_id = end_id )
SELECT
bike_id,
SUM(distance)/1000 AS total_distance
FROM
trip_distance
GROUP BY
bike_id
ORDER BY
total_distance DESC
LIMIT
5
이 쿼리에서는 60만 번(이전 쿼리에서는 2천 4백만 번) 지리적 거리 계산을 합니다. 이제 33.05MB의 데이터를 셔플링하지만 슬롯 시간은 31.5초가 걸립니다(30% 속도 향상).
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
I/O 최소화
작업 2. 이전 쿼리 결과 캐시
BigQuery 서비스는 임시 테이블에 쿼리 결과를 자동으로 캐시합니다. 동일한 쿼리가 거의 24시간 내에 제출되면 다시 계산하지 않고 이 임시 테이블에서 결과를 제공합니다. 캐시된 결과는 굉장히 빠르고 요금이 청구되지 않습니다.
하지만 일부 주의사항이 있습니다. 쿼리 캐싱은 정확한 문자열 비교에 기반합니다. 따라서 공백만으로도 캐시 부적중 현상이 발생할 수 있습니다. 비확정적 행동을 보인다거나(CURRENT_TIMESTAMP 또는 RAND를 사용하는 경우), 쿼리되는 테이블 또는 뷰가 변경되거나(쿼리의 대상이 되는 열/행은 변경되지 않은 경우라도 해당), 테이블이 스트리밍 버퍼와 관련되거나(새로운 행이 없는 경우라도 해당), 쿼리가 DML 문 또는 쿼리 외부 데이터 소스를 사용하는 경우 쿼리는 절대 캐시되지 않습니다.
중간 결과를 캐시
임시 테이블 및 구체화된 뷰를 활용하면 I/O가 증가하더라도 전반적인 성능은 향상될 수 있습니다.
예를 들어, 여러 쿼리에서 두 대여소 간 평균 이동 시간을 찾는다고 가정해 봅시다. WITH 절(공통 테이블 표현식(CTE)이라고도 함)은 가독성을 높이지만 결과가 캐시되지 않기 때문에 쿼리 속도 또는 비용은 개선되지 않습니다. 뷰 및 서브 쿼리의 경우도 마찬가지입니다. WITH 절, 뷰, 서브 쿼리를 자주 사용하는 경우, 성능을 개선하는 방법 중 하나는 결과를 테이블(또는 구체화된 뷰)에 저장하는 것입니다.
먼저 BigQuery 프로젝트에서 EU 리전(자전거 데이터가 있는 곳)에 mydataset라는 데이터 세트를 만들어야 합니다.
-
탐색기 섹션 왼쪽 창에서, BigQuery 프로젝트(qwiklabs-gcp-xxxx) 가까이 있는 뷰 작업 아이콘(점 3개)을 클릭하고 데이터 세트 만들기를 선택합니다.
-
데이터 세트 만들기 대화상자에서 다음을 실행합니다.
-
데이터 세트 ID를
mydataset로 설정합니다.
-
데이터 위치를
eu (multiple regions in European Union)로 설정합니다.
- 다른 옵션은 모두 기본값 그대로 둡니다.
- 완료하려면 파란색 데이터 세트 만들기 버튼을 클릭합니다.
- 이제 다음 쿼리를 실행할 수 있습니다.
CREATE OR REPLACE TABLE
mydataset.typical_trip AS
SELECT
start_station_name,
end_station_name,
APPROX_QUANTILES(duration, 10)[OFFSET (5)] AS typical_duration,
COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
start_station_name,
end_station_name
- 자전거 이동이 예외적으로 긴 경우, 일 수를 찾기 위해 만든 테이블을 다음과 같이 사용합니다.
SELECT
EXTRACT (DATE
FROM
start_date) AS trip_date,
APPROX_QUANTILES(duration / typical_duration, 10)[OFFSET(5)] AS ratio,
COUNT(*) AS num_trips_on_day
FROM
`bigquery-public-data`.london_bicycles.cycle_hire AS hire
JOIN
mydataset.typical_trip AS trip
ON
hire.start_station_name = trip.start_station_name
AND hire.end_station_name = trip.end_station_name
AND num_trips > 10
GROUP BY
trip_date
HAVING
num_trips_on_day > 10
ORDER BY
ratio DESC
LIMIT
10

- 자전거 이동이 예외적으로 긴 경우 다음과 같이 일 수를 찾는 WITH 절을 사용합니다.
WITH
typical_trip AS (
SELECT
start_station_name,
end_station_name,
APPROX_QUANTILES(duration, 10)[OFFSET (5)] AS typical_duration,
COUNT(duration) AS num_trips
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
GROUP BY
start_station_name,
end_station_name )
SELECT
EXTRACT (DATE
FROM
start_date) AS trip_date,
APPROX_QUANTILES(duration / typical_duration, 10)[
OFFSET
(5)] AS ratio,
COUNT(*) AS num_trips_on_day
FROM
`bigquery-public-data`.london_bicycles.cycle_hire AS hire
JOIN
typical_trip AS trip
ON
hire.start_station_name = trip.start_station_name
AND hire.end_station_name = trip.end_station_name
AND num_trips > 10
GROUP BY
trip_date
HAVING
num_trips_on_day > 10
ORDER BY
ratio DESC
LIMIT
10
평균 이동 시간의 계산을 하지 않아 속도가 약 50% 개선된 점에 주의하세요. 두 쿼리 모두 동일한 결과, 즉 크리스마스 이동 시간은 평소보다 더 오래 걸린다고 반환합니다. mydataset.typical_trip 테이블은 새 데이터가 cycle_hire 테이블에 추가되어도 새로고침되지 않습니다. 이 비활성 데이터 문제를 해결하는 한 가지 방법은 구체화된 뷰를 사용하거나 쿼리 일정을 예약하여 테이블을 주기적으로 업데이트하는 것입니다. 이러한 업데이트 비용을 측정하여, 쿼리 성능 개선이 테이블 유지나 구체화된 뷰 업데이트의 추가 비용을 상쇄하는지를 확인해야 합니다.
BI 엔진으로 쿼리 가속화
집계 및 필터가 있는 대시보드 등과 같이 비즈니스 인텔리전스(BI) 설정에서 자주 액세스하는 테이블이 있는 경우, 쿼리 속도를 높이는 방법으로 BI 엔진을 이용할 수 있습니다. 이를 통해 자동으로 메모리에 관련 데이터(테이블의 실제 열 또는 도출된 결과)를 저장하고 대부분의 인메모리 데이터 작업에 조정된 전용 쿼리 프로세서를 사용하게 됩니다. BI 엔진 하에서, BigQuery 관리 콘솔에서 캐시에 사용해야 하는 메모리의 양(현재 최대 10GB)을 예약할 수 있습니다.
쿼리하는 데이터 세트와 동일한 리전에 이 메모리를 예약해야 합니다. 그런 다음 BigQuery에서 메모리의 테이블, 테이블 일부, 집계를 캐시하기 시작하면 결과를 더 빨리 제공할 수 있습니다.
BI 엔진은 주로 Google 데이터 스튜디오 등의 대시보드 도구에서 액세스하는 테이블에 사용합니다. BI 엔진 예약에 메모리를 할당하면 BigQuery 백엔드에 의존하는 대시보드의 반응성을 훨씬 더 높일 수 있습니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
이전 쿼리 결과 캐시
작업 3. 효율적인 조인
두 개의 테이블을 조인하려면 데이터 조정이 필요하고 슬롯 간 통신 대역폭으로 인해 제약을 받게 됩니다. 가능하다면, 조인하지 않거나 조인할 데이터의 양을 줄이는 것이 좋습니다.
비정규화
읽기 성능을 개선하고 조인을 하지 않는 방법 중 하나는 데이터를 효율적으로 저장하는 것을 포기하고 대신에 데이터의 중복 사본을 추가하는 것입니다. 이를 비정규화라고 합니다.
-
따라서, 자전거 대여 정보에서 자전거 대여소의 위도와 경도를 별도로 저장하는 대신에, 비정규화 테이블을 다음과 같이 만들 수 있습니다.
CREATE OR REPLACE TABLE
mydataset.london_bicycles_denorm AS
SELECT
start_station_id,
s.latitude AS start_latitude,
s.longitude AS start_longitude,
end_station_id,
e.latitude AS end_latitude,
e.longitude AS end_longitude
FROM
`bigquery-public-data`.london_bicycles.cycle_hire AS h
JOIN
`bigquery-public-data`.london_bicycles.cycle_stations AS s
ON
h.start_station_id = s.id
JOIN
`bigquery-public-data`.london_bicycles.cycle_stations AS e
ON
h.end_station_id = e.id
그러면 테이블이 모든 이동에 대해 필요한 위치 정보를 포함하기 때문에 모든 후속 쿼리는 조인을 실행할 필요가 없습니다. 이 경우, 조인에 필요한 컴퓨팅 비용은 줄이고 저장용량과 보다 많은 데이터 읽기 비용을 늘린 것입니다. 디스크에서 더 많은 데이터를 읽는 비용이 조인의 비용보다 높을 수 있으므로, 비정규화 시행 시 성능이 개선되는지 측정해야 합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
비정규화
대규모 테이블의 자체 조인 피하기
자체 조인은 테이블이 자체적으로 조인될 경우에 발생합니다. BigQuery가 자체 조인을 지원하기는 하지만, 자체적으로 조인되는 테이블이 대용량인 경우 이를 통해 성능 저하가 일어날 수 있습니다. 많은 경우, 집계 및 윈도우 함수와 같은 SQL 기능을 활용하여 자체 조인을 피할 수 있습니다.
예를 살펴보겠습니다. BigQuery 공개 데이터 세트 중 하나로 미국 사회보장국에서 발표하는 아기 이름 데이터 세트가 있습니다.
- 데이터 세트를 쿼리하여 2015년 매사추세츠 주에서 가장 흔한 남자 이름을 찾을 수 있습니다(더보기 > 쿼리 설정 > 처리 위치를 선택하여
US 리전에서 쿼리가 진행 중인지 확인).
SELECT
name,
number AS num_babies
FROM
`bigquery-public-data`.usa_names.usa_1910_current
WHERE
gender = 'M'
AND year = 2015
AND state = 'MA'
ORDER BY
num_babies DESC
LIMIT
5
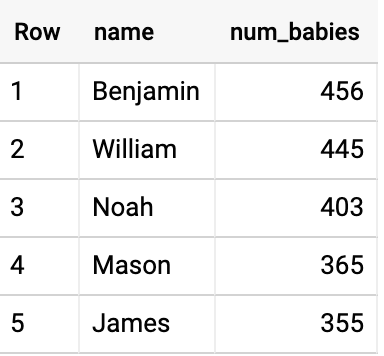
- 이와 유사하게, 데이터 세트를 쿼리하여 2015년 매사추세츠 주에서 가장 흔한 여자 이름을 다음과 같이 찾습니다.
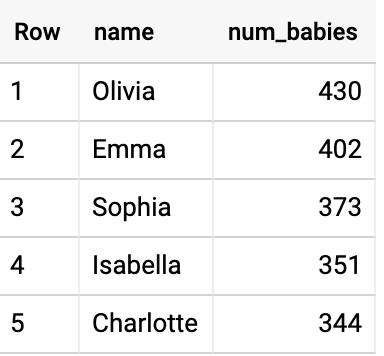
데이터 세트에서 해당 기간에 걸쳐 미국에서 가장 흔한 남자 이름과 여자 이름은 무엇일까요?
- 입력 테이블을 두 차례 읽고 자체 조인을 실행하는 간단한 방법으로 이 문제를 풀 수 있습니다.
WITH
male_babies AS (
SELECT
name,
number AS num_babies
FROM
`bigquery-public-data`.usa_names.usa_1910_current
WHERE
gender = 'M' ),
female_babies AS (
SELECT
name,
number AS num_babies
FROM
`bigquery-public-data`.usa_names.usa_1910_current
WHERE
gender = 'F' ),
both_genders AS (
SELECT
name,
SUM(m.num_babies) + SUM(f.num_babies) AS num_babies,
SUM(m.num_babies) / (SUM(m.num_babies) + SUM(f.num_babies)) AS frac_male
FROM
male_babies AS m
JOIN
female_babies AS f
USING
(name)
GROUP BY
name )
SELECT
*
FROM
both_genders
WHERE
frac_male BETWEEN 0.3
AND 0.7
ORDER BY
num_babies DESC
LIMIT
5
74초가 걸렸고 다음 결과가 산출되었습니다.
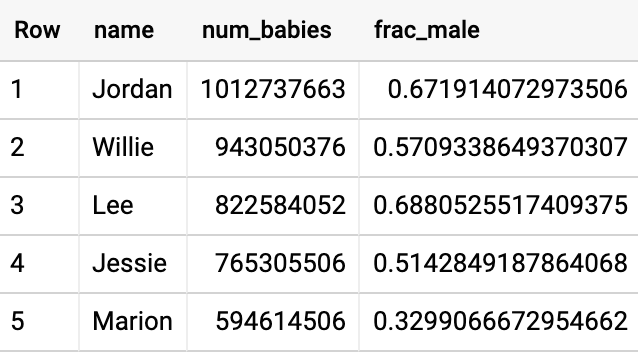
설상가상으로, 답 또한 틀립니다. Jordan이라는 이름은 멋진 이름이지만, 미국의 총인구는 3억 명이므로, Joardan이라는 아기가 9억 8천2백만 명 있을 수는 없습니다. 안타깝게도 자체 조인으로 인해 주와 연도 경계에 걸쳐 조인되었습니다.
- 더 빠르고 보다 고급스러운(그리고 정확하기까지 한) 솔루션은 쿼리를 리캐스팅하여 입력을 한 번만 읽고 자체 조인을 완전히 피하는 것입니다.
WITH
all_babies AS (
SELECT
name,
SUM(
IF
(gender = 'M',
number,
0)) AS male_babies,
SUM(
IF
(gender = 'F',
number,
0)) AS female_babies
FROM
`bigquery-public-data.usa_names.usa_1910_current`
GROUP BY
name ),
both_genders AS (
SELECT
name,
(male_babies + female_babies) AS num_babies,
SAFE_DIVIDE(male_babies,
male_babies + female_babies) AS frac_male
FROM
all_babies
WHERE
male_babies > 0
AND female_babies > 0 )
SELECT
*
FROM
both_genders
WHERE
frac_male BETWEEN 0.3
AND 0.7
ORDER BY
num_babies DESC
LIMIT
5
이 경우 2.4초밖에 걸리지 않습니다. 30배 빨라진 것이죠.
조인되는 데이터 줄이기
이름과 성별로 미리 데이터를 그룹핑하여 조인되는 데이터의 양을 줄이면 효율적인 조인으로 위의 쿼리를 실행할 수 있습니다.
자체 조인 대신 윈도우 함수 사용하기
자전거 반납과 다시 대여되기까지의 시간, 즉 자전거가 대여소에 보관되는 시간을 파악한다고 해 봅시다. 이는 행 사이 의존적인 관계의 예입니다. 이를 해결하는 유일한 방법은 테이블을 자체 조인하여 이동의 end_date를 다음 이동의 start_date에 매칭시키는 것일 수 있습니다. 더보기 > 쿼리 설정 > 처리 위치를 선택하여 EU 리전에서 쿼리가 진행 중인지 확인하세요.
- 하지만 윈도우 함수를 사용하면 자체 조인을 하지 않아도 됩니다.
SELECT
bike_id,
start_date,
end_date,
TIMESTAMP_DIFF( start_date, LAG(end_date) OVER (PARTITION BY bike_id ORDER BY start_date), SECOND) AS time_at_station
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
LIMIT
5
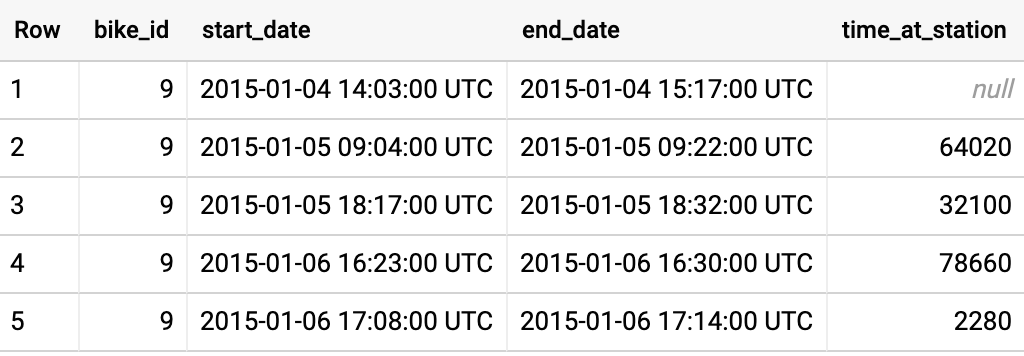
첫 번째 행은 이전 반납에 대한 타임스탬프가 없기 때문에 time_at_station의 값이 null입니다. 이후 time_at_station이 이전 반납과 현재 수령 간 차이를 추적합니다.
- 이를 이용해, 자전거가 대여소에서 사용되지 않고 보관되는 평균 시간을 계산하여, 이 측정치로 대여소의 순위를 지정할 수 있습니다.
WITH
unused AS (
SELECT
bike_id,
start_station_name,
start_date,
end_date,
TIMESTAMP_DIFF(start_date, LAG(end_date) OVER (PARTITION BY bike_id ORDER BY start_date), SECOND) AS time_at_station
FROM
`bigquery-public-data`.london_bicycles.cycle_hire )
SELECT
start_station_name,
AVG(time_at_station) AS unused_seconds
FROM
unused
GROUP BY
start_station_name
ORDER BY
unused_seconds ASC
LIMIT
5
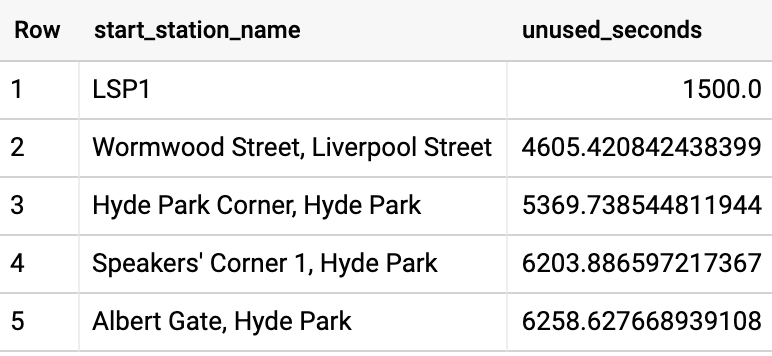
미리 계산된 값 조인
때로는 더 작은 테이블의 함수를 미리 계산하여, 미리 계산된 값으로 조인하는 것이 매번 부하가 높은 계산을 반복하는 것보다 유용할 수 있습니다.
예를 들어, 고객이 대여소 간 가장 빠른 속도로 자전거를 탄 대여소의 쌍을 찾는다고 해 봅시다. 고객이 이동한 속도(분/km)를 계산하려면 대여소 간 거리로 이동 시간을 나누어야 합니다.
- 이를 위해 다음과 같이 대여소 간 거리의 비정규화된 테이블을 만든 후 평균 속도를 계산할 수 있습니다.
WITH
denormalized_table AS (
SELECT
start_station_name,
end_station_name,
ST_DISTANCE(ST_GeogPoint(s1.longitude,
s1.latitude),
ST_GeogPoint(s2.longitude,
s2.latitude)) AS distance,
duration
FROM
`bigquery-public-data`.london_bicycles.cycle_hire AS h
JOIN
`bigquery-public-data`.london_bicycles.cycle_stations AS s1
ON
h.start_station_id = s1.id
JOIN
`bigquery-public-data`.london_bicycles.cycle_stations AS s2
ON
h.end_station_id = s2.id ),
durations AS (
SELECT
start_station_name,
end_station_name,
MIN(distance) AS distance,
AVG(duration) AS duration,
COUNT(*) AS num_rides
FROM
denormalized_table
WHERE
duration > 0
AND distance > 0
GROUP BY
start_station_name,
end_station_name
HAVING
num_rides > 100 )
SELECT
start_station_name,
end_station_name,
distance,
duration,
duration/distance AS pace
FROM
durations
ORDER BY
pace ASC
LIMIT
5
위의 쿼리는 지리정보 함수인 ST_DISTANCE를 cycle_hire 테이블에서 각 행마다 한 번씩 호출하여(2천 4백만 번) 14.7초가 소요되고 1.9GB의 데이터를 처리했습니다.
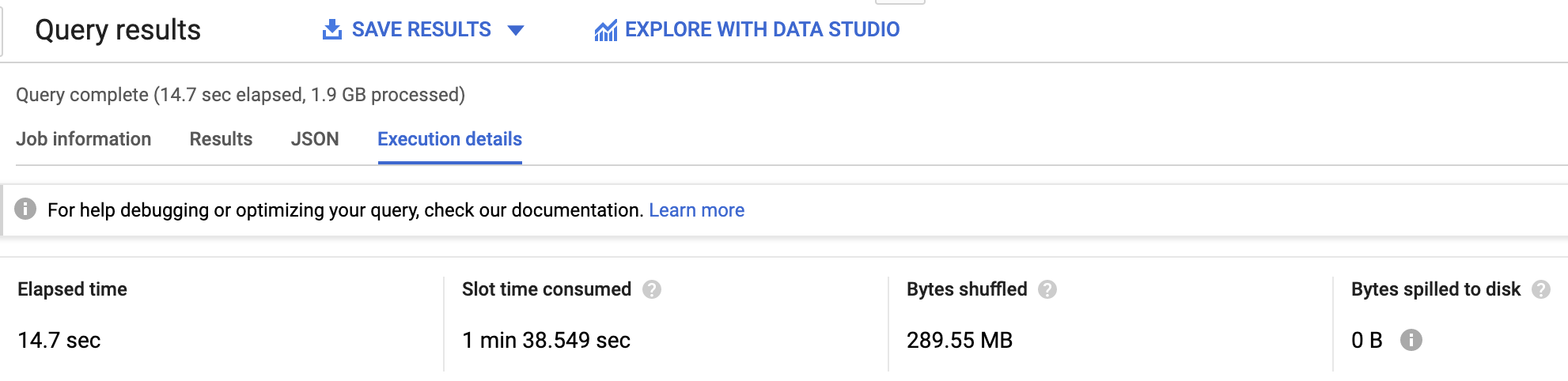
- 다른 방법으로
cycle_stations 테이블을 사용해 각 대여소 쌍 간 거리(자체 조인)를 미리 계산하고, 이를 좀 더 작은 크기의 테이블인 대여소 간 평균 시간 테이블과 조인합니다.
WITH
distances AS (
SELECT
a.id AS start_station_id,
a.name AS start_station_name,
b.id AS end_station_id,
b.name AS end_station_name,
ST_DISTANCE(ST_GeogPoint(a.longitude,
a.latitude),
ST_GeogPoint(b.longitude,
b.latitude)) AS distance
FROM
`bigquery-public-data`.london_bicycles.cycle_stations a
CROSS JOIN
`bigquery-public-data`.london_bicycles.cycle_stations b
WHERE
a.id != b.id ),
durations AS (
SELECT
start_station_id,
end_station_id,
AVG(duration) AS duration,
COUNT(*) AS num_rides
FROM
`bigquery-public-data`.london_bicycles.cycle_hire
WHERE
duration > 0
GROUP BY
start_station_id,
end_station_id
HAVING
num_rides > 100 )
SELECT
start_station_name,
end_station_name,
distance,
duration,
duration/distance AS pace
FROM
distances
JOIN
durations
USING
(start_station_id,
end_station_id)
ORDER BY
pace ASC
LIMIT
5
보다 효율적으로 조인하여 쿼리를 리캐스트하면 속도가 1.8배 증가하여 8.2초밖에 걸리지 않으며 554MB의 데이터를 처리하여 비용이 4배 가량 감소합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
조인
작업 4. 작업자 과부하 피하기
일부 작업(예: 정렬)은 단일 작업자에서 실행해야 합니다. 너무 많은 데이터를 정렬하면 작업자의 메모리가 과부하되어 '리소스 초과' 오류를 야기할 수 있습니다. 너무 많은 데이터로 작업자가 과부하되지 않도록 합니다. Google 데이터 센터의 하드웨어가 업그레이드되면, 이 맥락에서 '너무 많은'의 의미도 시간 경과에 따라 확장됩니다. 현재는 1GB에 해당하는 주문입니다.
큰 정렬 제한하기
- 대여된 자전거 전체에서 대여가 만료된 순서로 1, 2, 3과 같이 번호를 지정한다고 합시다. ROW_NUMBER() 함수를 사용하여 이를 실행할 수 있습니다.
SELECT
rental_id,
ROW_NUMBER() OVER(ORDER BY end_date) AS rental_number
FROM
`bigquery-public-data.london_bicycles.cycle_hire`
ORDER BY
rental_number ASC
LIMIT
5
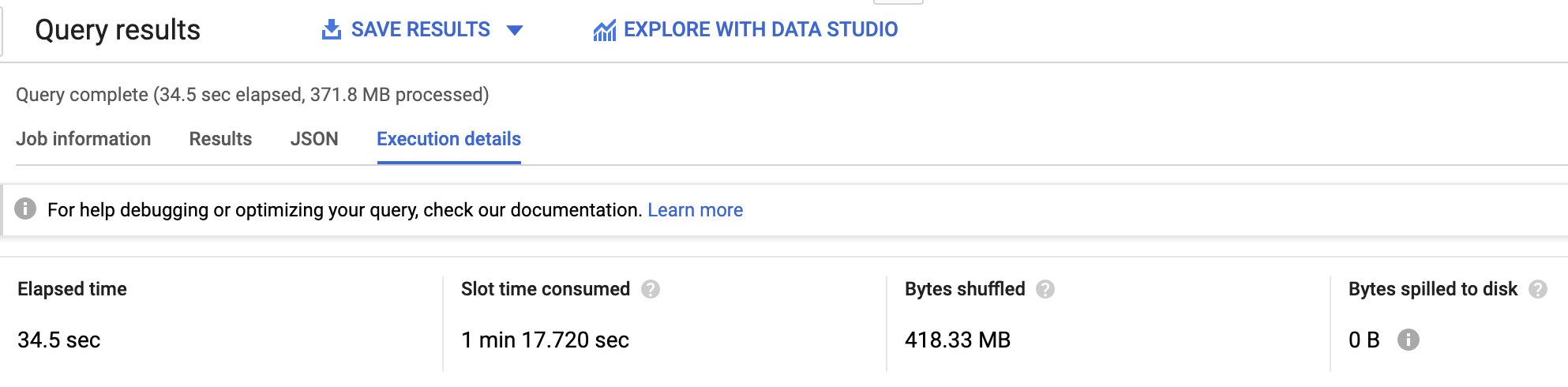
단 372MB의 데이터 처리에 34.5초가 걸립니다. 단일 작업자에서 런던의 자전거 데이터 세트 전체를 정렬해야 하기 때문이죠. 더 큰 데이터 세트를 처리했다면 해당 작업자에 과부하가 걸렸을 겁니다.
대규모 정렬을 제한하고 이를 배포할 수 있는지 여부를 고려하는 것이 좋습니다.
- 실제로 대여에서 날짜를 추출한 후에 각 날짜 내에서 이동을 정렬할 수 있습니다.
WITH
rentals_on_day AS (
SELECT
rental_id,
end_date,
EXTRACT(DATE
FROM
end_date) AS rental_date
FROM
`bigquery-public-data.london_bicycles.cycle_hire` )
SELECT
rental_id,
rental_date,
ROW_NUMBER() OVER(PARTITION BY rental_date ORDER BY end_date) AS rental_number_on_day
FROM
rentals_on_day
ORDER BY
rental_date ASC,
rental_number_on_day ASC
LIMIT
5
정렬이 한 번에 하루치 데이터에 대해 실행되므로 15.1초(속도 2배 증가)가 소요됩니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업자 과부하 피하기
데이터 편향
작업자 과부하(이 경우에는 작업자 메모리 부하)와 같은 동일한 문제는 GROUP BY로 ARRAY_AGG를 실행할 때 키 중 하나가 다른 키보다 훨씬 더 빈도가 높은 경우 발생할 수 있습니다.
- 300만 개가 넘는 GitHub 저장소가 있고 여기에 커밋이 잘 배포되어 있기 때문에, 이 쿼리는 성공적으로 실행됩니다(
US 처리 센터에서 해당 쿼리를 실행해야 함).
SELECT
repo_name,
ARRAY_AGG(STRUCT(author,
committer,
subject,
message,
trailer,
difference,
encoding)
ORDER BY
author.date.seconds)
FROM
`bigquery-public-data.github_repos.commits`,
UNNEST(repo_name) AS repo_name
GROUP BY
repo_name
참고: 이 쿼리가 성공적으로 실행되기는 하지만 시간이 15분 정도 더 소요될 수 있습니다. 쿼리를 이해한 경우 실습에서 다음으로 이동하세요.
- GitHub를 사용하는 대부분의 사람들은 일부 시간대에만 살고 있으므로 시간대로 그룹화하면 실패합니다. 따라서 750GB 중 상당량을 정렬하도록 단일 작업자에게 요청 중입니다.
SELECT
author.tz_offset,
ARRAY_AGG(STRUCT(author,
committer,
subject,
message,
trailer,
difference,
encoding)
ORDER BY
author.date.seconds)
FROM
`bigquery-public-data.github_repos.commits`
GROUP BY
author.tz_offset

모든 데이터를 정렬할 것을 요청한다면, 보다 세분화된 키를 사용, 즉 그룹의 데이터를 보다 많은 작업자에 배포하고, 그 다음 원하는 키에 해당하는 결과를 집계합니다.
- 예를 들어, 시간대에 따라 그룹화하지 않고,
timezone 및 repo_name으로 그룹화한 다음 모든 저장소에서 집계하여 각 시간대의 답을 실제로 얻을 수 있습니다.
SELECT
repo_name,
author.tz_offset,
ARRAY_AGG(STRUCT(author,
committer,
subject,
message,
trailer,
difference,
encoding)
ORDER BY
author.date.seconds)
FROM
`bigquery-public-data.github_repos.commits`,
UNNEST(repo_name) AS repo_name
GROUP BY
repo_name,
author.tz_offset
이 쿼리가 성공적으로 실행되기는 하지만 시간이 15분 정도 더 소요될 수 있습니다. 쿼리를 이해한 경우 실습에서 다음으로 이동하세요.
작업 5. 근사 집계 함수
BigQuery는 빠르고 메모리 사용률이 낮은 근사 집계 함수를 제공합니다. 결과에서 약간의 통계적 불확실성이 허용되는 경우, COUNT(DISTINCT …)를 사용하는 대신, 대용량 데이터 스트림에서 APPROX_COUNT_DISTINCT를 사용할 수 있습니다.
근사 수
- 다음을 사용하여 고유한 GitHub 저장소 수를 찾을 수 있습니다.
SELECT
COUNT(DISTINCT repo_name) AS num_repos
FROM
`bigquery-public-data`.github_repos.commits,
UNNEST(repo_name) AS repo_name
위의 쿼리는 3,347,770개의 정확한 결과를 계산하는 데 8.3초가 소요되었습니다.
- 근사 함수 사용:
SELECT
APPROX_COUNT_DISTINCT(repo_name) AS num_repos
FROM
`bigquery-public-data`.github_repos.commits,
UNNEST(repo_name) AS repo_name
3.9초가 소요(속도 2배 증가)되고 3399473개의 근사 결과를 반환하여 정확한 응답보다 1.5% 과대추정했습니다.
근사 알고리즘은 정확한 알고리즘보다 대용량 데이터 세트에서만 훨씬 효율적이며 약 1%의 오류가 허용가능한 사용 사례에 추천합니다. 근사 함수를 사용하기 전에, 사용 사례를 측정하세요!
기타 사용 가능한 근사 함수에는 백분위수를 계산하는 APPROX_QUANTILES, 최상위 요소를 찾는 APPROX_TOP_COUNT, 요소 합계에 기반하여 최상위 요소를 계산하는 APPROX_TOP_SUM이 있습니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
근사 집계 함수
수고하셨습니다.
쿼리 성능을 개선할 수 있는 다양한 기술을 학습했습니다. 이 기법을 고려하면서, '성급한 최적화는 모든 악의 뿌리'라는 전설적인 컴퓨터 과학자 도널드 커누스의 말을 기억하세요.
다음 단계/더 학습하기
Copyright 2020 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.





