Übersicht
Stellen Sie sich vor, Sie haben eine Taxiflotte in New York City und möchten in Echtzeit Einblick in den Betrieb erhalten. Dazu erstellen Sie eine Streamingdaten-Pipeline, um den Umsatz aus den Taxifahrten, die Fahrgastanzahl, den Fahrtenstatus und andere Aspekte zu erfassen. Die Ergebnisse visualisieren Sie anschließend übersichtlich in einem Verwaltungsdashboard.
Lernziele
Aufgaben in diesem Lab:
- Dataflow-Job aus einer Vorlage erstellen
- Dataflow-Pipeline in BigQuery streamen
- Dataflow-Pipeline in BigQuery überwachen
- Ergebnisse mit SQL analysieren
- Wichtige Messwerte in Looker Studio visualisieren
Einrichtung und Anforderungen
Für jedes Lab werden Ihnen ein neues Google Cloud-Projekt und die entsprechenden Ressourcen für eine bestimmte Zeit kostenlos zur Verfügung gestellt.
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Pop-up-Fenster geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können.
Auf der linken Seite befindet sich der Bereich Details zum Lab mit diesen Informationen:
- Schaltfläche Google Cloud Console öffnen
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite Anmelden geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden.
-
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}}
Sie finden den Nutzernamen auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}}
Sie finden das Passwort auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos.
Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen.
-
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.
Hinweis: Wenn Sie eine Liste der Google Cloud-Produkte und ‑Dienste aufrufen möchten, klicken Sie oben links auf das Navigationsmenü oder geben Sie den Namen des Produkts oder Dienstes in das Feld Suchen ein.

Google Cloud Shell aktivieren
Google Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud.
Mit Google Cloud Shell erhalten Sie Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen.
-
Klicken Sie in der Cloud Console in der rechten oberen Symbolleiste auf „Cloud Shell öffnen“.

-
Klicken Sie auf Weiter.
Die Bereitstellung und Verbindung mit der Umgebung dauert einen kleinen Moment. Wenn Sie verbunden sind, sind Sie auch bereits authentifiziert und das Projekt ist auf Ihre PROJECT_ID eingestellt. Beispiel:

gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
- Sie können den aktiven Kontonamen mit diesem Befehl auflisten:
gcloud auth list
Ausgabe:
Konten mit Anmeldedaten:
- @.com (aktiv)
Beispielausgabe:
Konten mit Anmeldedaten:
- google1623327_student@qwiklabs.net
- Sie können die Projekt-ID mit diesem Befehl auflisten:
gcloud config list project
Ausgabe:
[core]
Projekt =
Beispielausgabe:
[core]
Projekt = qwiklabs-gcp-44776a13dea667a6
Hinweis:
Die vollständige Dokumentation zu gcloud finden Sie in der Übersicht zur gcloud CLI.
Aufgabe 1: BigQuery-Dataset erstellen
In dieser Aufgabe erstellen Sie das Dataset taxirides. Sie haben zwei Möglichkeiten, dies zu tun: mit Google Cloud Shell oder der Google Cloud Console.
In diesem Lab arbeiten Sie mit einem Auszug aus dem öffentlichen Dataset der NYC Taxi & Limousine Commission. Eine kleine, kommagetrennte Datei wird verwendet, um regelmäßige Aktualisierungen von Taxidaten zu simulieren.
BigQuery ist ein serverloses Data Warehouse. Tabellen in BigQuery sind in Datasets organisiert. In diesem Lab werden Taxidaten aus einer eigenständigen Datei über Dataflow in BigQuery gespeichert. Mit dieser Konfiguration wird jede neue Datendatei, die in den Cloud Storage-Quell-Bucket hochgeladen wird, automatisch für das Laden verarbeitet.
Verwenden Sie eine der folgenden Optionen, um ein neues BigQuery-Dataset zu erstellen:
Option 1: Befehlszeilentool
- Führen Sie in Cloud Shell (
 ) den folgenden Befehl aus, um das Dataset
) den folgenden Befehl aus, um das Dataset taxirides zu erstellen.
bq --location={{{project_0.default_region|Region}}} mk taxirides
- Führen Sie diesen Befehl aus, um die Tabelle
taxirides.realtime (ein leeres Schema, in das später gestreamt wird) zu erstellen:
bq --location={{{project_0.default_region|Region}}} mk \
--time_partitioning_field timestamp \
--schema ride_id:string,point_idx:integer,latitude:float,longitude:float,\
timestamp:timestamp,meter_reading:float,meter_increment:float,ride_status:string,\
passenger_count:integer -t taxirides.realtime
Option 2: Benutzeroberfläche der BigQuery Console
Hinweis: Wenn Sie die Tabellen über die Befehlszeile erstellt haben, können Sie diese Schritte überspringen.
-
Klicken Sie in der Google Cloud Console im Navigationsmenü ( ) auf BigQuery.
) auf BigQuery.
-
Wenn das Willkommensdialogfeld angezeigt wird, klicken Sie auf Fertig.
-
Klicken Sie neben Ihrer Projekt-ID auf Aktionen ansehen ( ) und dann auf Dataset erstellen.
) und dann auf Dataset erstellen.
-
Geben Sie unter „Dataset-ID“ den Begriff taxirides ein.
-
Wählen Sie unter „Speicherort der Daten“ Folgendes aus:
{{{project_0.default_region|Region}}}
Klicken Sie dann auf Dataset erstellen.
-
Klicken Sie im Bereich „Explorer“ auf Knoten maximieren (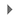 ), um das neue Dataset „taxirides“ aufzurufen.
), um das neue Dataset „taxirides“ aufzurufen.
-
Klicken Sie neben dem Dataset taxirides auf Aktionen ansehen () und dann auf Öffnen.
-
Klicken Sie auf Tabelle erstellen.
-
Geben Sie unter „Tabelle“ realtime ein.
-
Klicken Sie unter „Schema“ auf Als Text bearbeiten und fügen Sie Folgendes ein:
ride_id:string,
point_idx:integer,
latitude:float,
longitude:float,
timestamp:timestamp,
meter_reading:float,
meter_increment:float,
ride_status:string,
passenger_count:integer
-
Wählen Sie unter Partitions- und Clustereinstellungen die Option timestamp aus.
-
Klicken Sie auf Tabelle erstellen.
Aufgabe 2: Erforderliche Lab-Artefakte kopieren
In dieser Aufgabe verschieben Sie die benötigten Dateien in Ihr Projekt.
Mit Cloud Storage können Sie jederzeit beliebige Datenmengen weltweit speichern und abrufen. Sie können Cloud Storage für eine Reihe von Aufgaben verwenden, beispielsweise um Websiteinhalte bereitzustellen, Daten für die Archivierung und Notfallwiederherstellung zu speichern oder große Datenobjekte über direkte Downloads an Nutzer zu verteilen.
Beim Start des Labs wurde bereits ein Cloud Storage-Bucket für Sie erstellt.
- Führen Sie in Cloud Shell () die folgenden Befehle aus, um die für den Dataflow-Job benötigten Dateien zu verschieben:
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/schema.json gs://{{{project_0.project_id|Project_ID}}}-bucket/tmp/schema.json
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/transform.js gs://{{{project_0.project_id|Project_ID}}}-bucket/tmp/transform.js
gcloud storage cp gs://cloud-training/bdml/taxisrcdata/rt_taxidata.csv gs://{{{project_0.project_id|Project_ID}}}-bucket/tmp/rt_taxidata.csv
Aufgabe 3: Dataflow-Pipeline einrichten
In dieser Aufgabe richten Sie eine Streaming-Datenpipeline ein, um Dateien aus Ihrem Cloud Storage-Bucket zu lesen und Daten in BigQuery zu schreiben.
Dataflow bietet die Möglichkeit, serverlos Daten zu analysieren.
Verbindung zur Dataflow API neu starten
- Führen Sie in Cloud Shell die folgenden Befehle aus, um sicherzustellen, dass die Dataflow API in Ihrem Projekt aktiviert ist:
gcloud services disable dataflow.googleapis.com
gcloud services enable dataflow.googleapis.com
Neue Streamingpipeline erstellen
-
Klicken Sie in der Cloud Console im Navigationsmenü () auf Alle Produkte ansehen > Analytics > Dataflow.
-
Klicken Sie in der oberen Menüleiste auf Job aus Vorlage erstellen.
-
Geben Sie streaming-taxi-pipeline als Jobnamen für Ihren Dataflow-Job ein.
-
Wählen Sie unter Regionaler Endpunkt Folgendes aus:
{{{project_0.default_region|Region}}}
- Wählen Sie unter Dataflow-Vorlage die Vorlage Cloud Storage-Text für BigQuery (Stream) unter Daten kontinuierlich verarbeiten (Stream) aus.
Hinweis: Achten Sie darauf, dass Sie die Vorlagenoption auswählen, die mit den unten aufgeführten Parametern übereinstimmt.
- Fügen Sie unter Cloud Storage-Eingabedatei(en) Folgendes ein:
{{{project_0.project_id|Project_ID}}}-bucket/tmp/rt_taxidata.csv
- Fügen Sie unter Cloud Storage-Speicherort Ihrer BigQuery-Schemadatei im JSON-Format Folgendes ein:
{{{project_0.project_id|Project_ID}}}-bucket/tmp/schema.json
- Fügen Sie unter BigQuery-Ausgabetabelle Folgendes ein:
{{{project_0.project_id|Project_ID}}}:taxirides.realtime
- Fügen Sie unter Temporäres Verzeichnis für den BigQuery-Ladevorgang Folgendes ein:
{{{project_0.project_id|Project_ID}}}-bucket/tmp
-
Klicken Sie auf Erforderliche Parameter.
-
Fügen Sie unter Temporärer Speicherort (verwendet zum Schreiben temporärer Dateien) Folgendes ein:
{{{project_0.project_id|Project_ID}}}-bucket/tmp
- Fügen Sie unter JavaScript-UDF-Pfad in Cloud Storage Folgendes ein:
{{{project_0.project_id|Project_ID}}}-bucket/tmp/transform.js
- Fügen Sie unter JavaScript-UDF-Name Folgendes ein:
transform
-
Geben Sie unter Maximale Anzahl der Worker den Wert 2 ein.
-
Geben Sie unter Anzahl der Worker den Wert 1 ein.
-
Deaktivieren Sie das Kästchen Standardmaschinentyp verwenden.
-
Wählen Sie unter Für allgemeine Zwecke Folgendes aus:
Serie: E2
Maschinentyp: e2-medium (2 vCPUs, 4 GB Arbeitsspeicher)
- Klicken Sie auf Job ausführen.
Daraufhin wird ein neuer Streaming-Job gestartet. Sie können jetzt eine visuelle Darstellung der Datenpipeline sehen. Es dauert 3 bis 5 Minuten, bis die Daten in BigQuery übertragen werden.
Hinweis: Falls der Dataflow-Job beim ersten Versuch fehlschlägt, erstellen Sie eine neue Jobvorlage mit einem neuen Jobnamen und führen Sie den Job erneut aus.
Aufgabe 4: Taxidaten mit BigQuery analysieren
In dieser Aufgabe analysieren Sie die Daten während des Streamings.
-
Klicken Sie in der Google Cloud Console im Navigationsmenü () auf BigQuery.
-
Wenn das Willkommensdialogfeld angezeigt wird, klicken Sie auf Fertig.
-
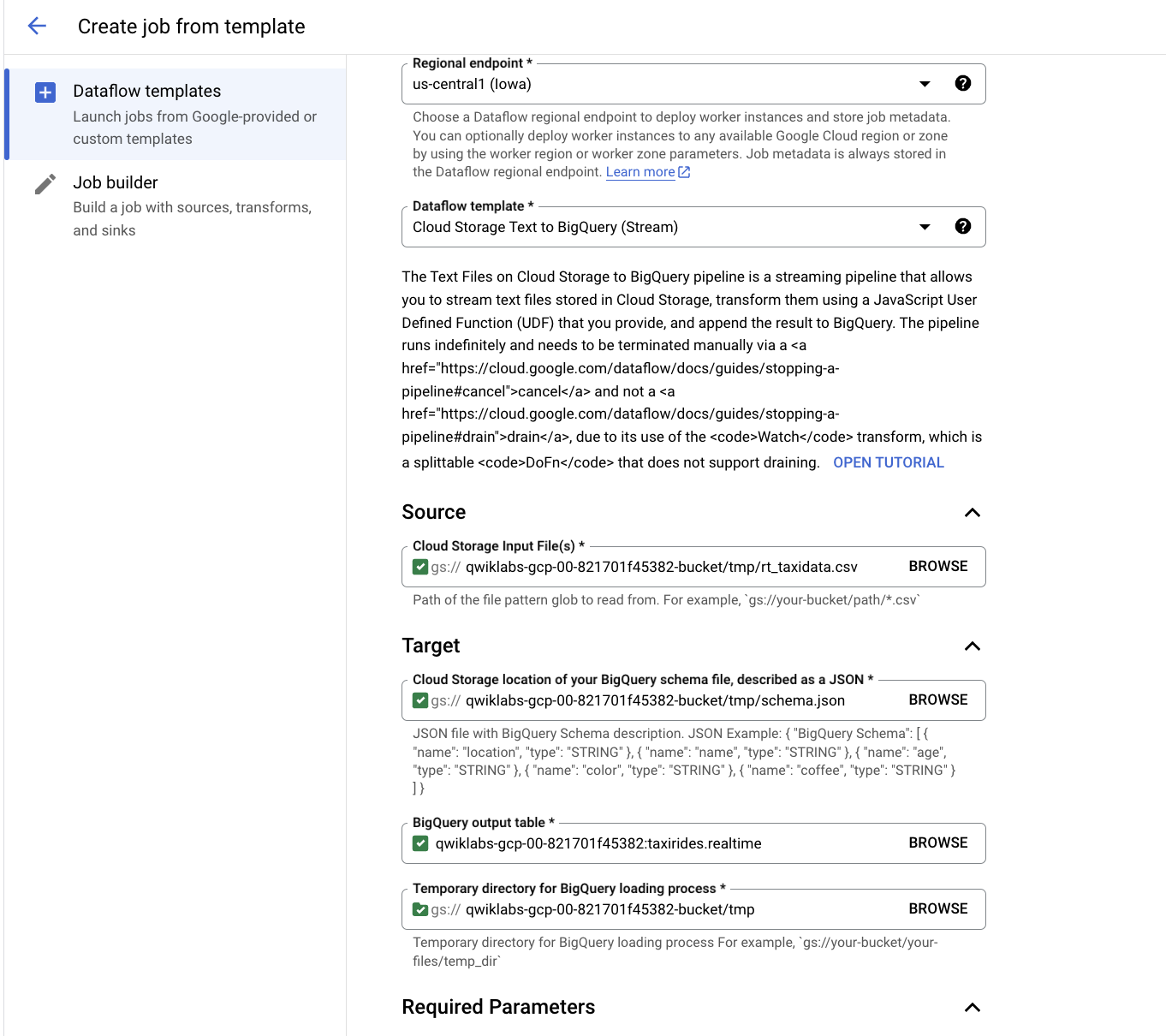
Geben Sie im Abfrageeditor Folgendes ein und klicken Sie auf Ausführen:
SELECT * FROM taxirides.realtime LIMIT 10
Hinweis: Wenn keine Datensätze zurückgegeben werden, warten Sie eine Minute und führen Sie die obige Abfrage noch einmal aus. Dataflow benötigt drei bis fünf Minuten, um den Stream einzurichten.
Ihre Ausgabe sieht in etwa so aus:
Aufgabe 5: Stream zur Berichterstellung aggregieren
In dieser Aufgabe berechnen Sie Aggregationen im Stream für die Berichterstellung.
-
Löschen Sie im Abfrageeditor die aktuelle Abfrage.
-
Kopieren Sie die folgende Abfrage und fügen Sie sie ein. Klicken Sie dann auf Ausführen:
WITH streaming_data AS (
SELECT
timestamp,
TIMESTAMP_TRUNC(timestamp, HOUR, 'UTC') AS hour,
TIMESTAMP_TRUNC(timestamp, MINUTE, 'UTC') AS minute,
TIMESTAMP_TRUNC(timestamp, SECOND, 'UTC') AS second,
ride_id,
latitude,
longitude,
meter_reading,
ride_status,
passenger_count
FROM
taxirides.realtime
ORDER BY timestamp DESC
LIMIT 1000
)
# calculate aggregations on stream for reporting:
SELECT
ROW_NUMBER() OVER() AS dashboard_sort,
minute,
COUNT(DISTINCT ride_id) AS total_rides,
SUM(meter_reading) AS total_revenue,
SUM(passenger_count) AS total_passengers
FROM streaming_data
GROUP BY minute, timestamp
Hinweis: Achten Sie darauf, dass Dataflow Daten in BigQuery registriert, bevor Sie mit der nächsten Aufgabe fortfahren.
Als Ergebnis erhalten Sie die minutengenauen Messwerte für jedes Taxiziel.
-
Klicken Sie auf Speichern > Abfrage speichern.
-
Geben Sie im Dialogfeld „Abfrage speichern“ im Feld Name den Namen Meine gespeicherte Abfrage ein.
-
Achten Sie darauf, dass die Region mit der Qwiklabs-Lab-Region übereinstimmt.
-
Klicken Sie auf Speichern.
Aufgabe 6: Dataflow-Job beenden
In dieser Aufgabe beenden Sie den Dataflow-Job, um Ressourcen für Ihr Projekt freizugeben.
-
Klicken Sie in der Cloud Console im Navigationsmenü () auf Alle Produkte ansehen > Analytics > Dataflow.
-
Klicken Sie auf streaming-taxi-pipeline oder den neuen Jobnamen.
-
Klicken Sie auf Beenden und wählen Sie Abbrechen > Job anhalten aus.
Aufgabe 7: Echtzeit-Dashboard erstellen
In dieser Aufgabe erstellen Sie ein Echtzeit-Dashboard, um die Daten zu visualisieren.
-
Klicken Sie in der Google Cloud Console im Navigationsmenü () auf BigQuery.
-
Maximieren Sie im Bereich „Explorer“ Ihre Projekt-ID.
-
Maximieren Sie den Bereich Abfragen und klicken Sie dann auf Meine gespeicherte Abfrage.
Ihre Abfrage wird in den Abfrageeditor geladen.
-
Klicken Sie auf Ausführen.
-
Klicken Sie im Abschnitt „Abfrageergebnisse“ auf Öffnen in > Looker Studio.
Looker Studio wird geöffnet. Klicken Sie auf Jetzt starten.
-
Klicken Sie im Looker Studio-Fenster auf das Balkendiagramm.
Der Bereich „Diagramm“ wird angezeigt.
-
Klicken Sie auf Diagramm hinzufügen und wählen Sie Kombinationsdiagramm aus.

-
Bewegen Sie im Bereich „Einrichtung“ unter „Datenbereichsdimension“ den Mauszeiger über minute (Date) und klicken Sie auf das X, um die Dimension zu entfernen.
-
Klicken Sie im Bereich „Daten“ auf dashboard_sort und ziehen Sie das Element zu Einrichtung > Datenbereichsdimension > Dimension hinzufügen.
-
Klicken Sie unter Einrichtung > Dimension auf minute und wählen Sie dann dashboard_sort aus.
-
Klicken Sie unter Einrichtung > Messwert auf dashboard_sort und wählen Sie dann total_rides aus.
-
Klicken Sie unter Einrichtung > Messwert auf Anzahl der Datensätze und wählen Sie dann total_passengers aus.
-
Klicken Sie unter Einrichtung > Messwert auf Messwert hinzufügen und wählen Sie dann total_revenue aus.
-
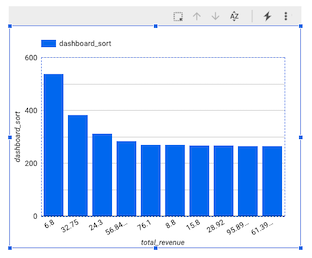
Klicken Sie unter Einrichtung > Sortieren auf total_rides und wählen Sie dann dashboard_sort aus.
-
Klicken Sie unter Einrichtung > Sortieren auf Aufsteigend.
Ihr Diagramm sollte in etwa so aussehen:
Hinweis: Die Visualisierung von Daten mit einem minutengenauen Detaillierungsgrad wird in Looker Studio zurzeit nicht als Zeitstempel unterstützt. Daher haben wir unsere eigene dashboard_sort-Dimension erstellt.
-
Wenn Sie mit dem Dashboard zufrieden sind und die Datenquelle speichern möchten, klicken Sie auf Speichern und freigeben.
-
Wenn Sie aufgefordert werden, die Kontoeinrichtung abzuschließen, geben Sie Ihr Land und die Unternehmensdetails ein, stimmen Sie den Nutzungsbedingungen zu und klicken Sie auf Weiter.
-
Wenn Sie gefragt werden, welche Updates Sie erhalten möchten, antworten Sie auf alle Fragen mit Nein und klicken Sie dann auf Weiter.
-
Wenn das Fenster Vor dem Speichern Datenzugriff prüfen angezeigt wird, klicken Sie auf Bestätigen und speichern.
-
Wenn Sie aufgefordert werden, ein Konto auszuwählen, wählen Sie Ihr Teilnehmerkonto aus.
-
Bei jedem Aufruf des Dashboards werden jetzt die neuesten Transaktionen berücksichtigt. Klicken Sie auf Weitere Optionen ( ) und dann auf Daten aktualisieren, um es selbst auszuprobieren.
) und dann auf Daten aktualisieren, um es selbst auszuprobieren.
Aufgabe 8: Zeitreihen-Dashboard erstellen
In dieser Aufgabe erstellen Sie ein Zeitreihendiagramm.
-
Klicken Sie auf diesen Link, um Looker Studio in einem neuen Browsertab zu öffnen.
-
Klicken Sie auf der Seite Berichte im Abschnitt Mit einer Vorlage beginnen auf die Vorlage [+] Leerer Bericht.
-
Ein neuer, leerer Bericht wird geöffnet und Sie sehen das Fenster Daten zum Bericht hinzufügen.
-
Wählen Sie in der Liste mit den Google-Connectors die Kachel für BigQuery aus.
-
Klicken Sie auf Benutzerdefinierte Abfrage und wählen Sie Ihre Projekt-ID aus. Sie sollte das folgende Format haben: qwiklabs-gcp-xxxxxxx.
-
Fügen Sie unter „Benutzerdefinierte Abfrage eingeben“ die folgende Abfrage ein:
SELECT
*
FROM
taxirides.realtime
WHERE
ride_status='enroute'
-
Klicken Sie auf Hinzufügen > Zum Bericht hinzufügen.
Ein neuer unbenannter Bericht wird angezeigt. Es kann bis zu einer Minute dauern, bis die Aktualisierung des Bildschirms abgeschlossen ist.
Zeitreihendiagramm erstellen
-
Klicken Sie im Bereich Daten auf Feld hinzufügen > Berechnetes Feld hinzufügen.
-
Klicken Sie links oben auf Alle Felder.
-
Ändern Sie den Feldtyp timestamp in Datum und Uhrzeit > Datum Stunde Minute (JJJJMMTThhmm).
-
Klicken Sie im Dialogfeld „Zeitstempel ändern“ auf Weiter und dann auf Fertig.
-
Klicken Sie im Menü oben auf Diagramm hinzufügen.
-
Wählen Sie Zeitreihendiagramm aus.

-
Platzieren Sie das Diagramm links unten im leeren Bereich.
-
Klicken Sie unter Einrichtung > Dimension auf timestamp (Date) und wählen Sie dann timestamp aus.
-
Klicken Sie unter Einrichtung > Dimension auf timestamp und wählen Sie dann calendar aus.

-
Wählen Sie im Feld Datentyp die Option Datum und Uhrzeit > Datum Stunde Minute aus.
-
Klicken Sie auf eine Stelle außerhalb des Dialogfelds, um es zu schließen. Sie müssen keinen Namen hinzufügen.
-
Klicken Sie unter Einrichtung > Messwert auf Anzahl der Datensätze und wählen Sie dann Zählerstand aus.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
In diesem Lab haben Sie Dataflow verwendet, um Daten über eine Pipeline in BigQuery zu streamen.
Lab beenden
Wenn Sie das Lab abgeschlossen haben, klicken Sie auf Lab beenden. Google Cloud Skills Boost entfernt daraufhin die von Ihnen genutzten Ressourcen und bereinigt das Konto.
Anschließend erhalten Sie die Möglichkeit, das Lab zu bewerten. Wählen Sie die entsprechende Anzahl von Sternen aus, schreiben Sie einen Kommentar und klicken Sie anschließend auf Senden.
Die Anzahl der Sterne hat folgende Bedeutung:
- 1 Stern = Sehr unzufrieden
- 2 Sterne = Unzufrieden
- 3 Sterne = Neutral
- 4 Sterne = Zufrieden
- 5 Sterne = Sehr zufrieden
Wenn Sie kein Feedback geben möchten, können Sie das Dialogfeld einfach schließen.
Verwenden Sie für Feedback, Vorschläge oder Korrekturen den Tab Support.
© 2024 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.





