チェックポイント
Create an API Key
/ 40
Make an Entity Analysis Request
/ 30
Check the Entity Analysis response
/ 30
Natural Language API によるエンティティ感情分析
GSP038

概要
Cloud Natural Language API を使用すると、テキストからエンティティを抽出して感情分析や構文解析を行い、テキストをカテゴリに分類できます。
このラボでは、Natural Language API を使ってエンティティ、感情、構文を分析する方法について学びます。
学習内容
- Natural Language API リクエストを作成し、curl で API を呼び出す
- Natural Language API でテキストのエンティティ抽出と感情分析を行う
- Natural Language API でテキストを言語学的に分析する
- 別の言語のテキストを使って Natural Language API リクエストを作成する
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

タスク 1. API キーを作成する
curl を使用して Natural Language API にリクエストを送信するため、リクエスト URL に渡す API キーを生成する必要があります。
-
API キーを作成するには、Google Cloud コンソールのナビゲーション メニューで [API とサービス] > [認証情報] を選択します。
-
[認証情報を作成] をクリックし、[API キー] を選択します。
-
生成された API キーをコピーし、[閉じる] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
次のステップを実行するために、プロビジョニングされているインスタンスに SSH で接続してください。
-
ナビゲーション メニューの [Compute Engine] をクリックします。[VM インスタンス] の一覧に、プロビジョニングされた Linux インスタンス、
linux-instanceが表示されます。 -
[SSH] ボタンをクリックします。インタラクティブ シェルが表示されます。
-
コマンドラインで以下のコマンドを入力します。
<YOUR_API_KEY>の部分は、先ほどコピーしたキーに置き換えてください。
タスク 2. エンティティ分析リクエストを行う
最初に使用する Natural Language API メソッドは、analyzeEntities です。このメソッドを使用すると、API によってテキストからエンティティ(人、場所、イベントなど)が抽出されます。ここでは、次の文を使って Natural Language API のエンティティ分析を試してみます。
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
Natural Language API へのリクエストは、ファイル request.json で構築します。
- nano(コードエディタ)を使用してファイル
request.jsonを作成します。
-
request.jsonに次のコードを入力するか、コピーして貼り付けます。
- Ctrl+X キーで nano を終了したら、Y キーでファイルを保存し、Enter キーを押して確定します。
このリクエストでは、送信するテキストについての情報を Natural Language API に知らせます。サポートされている型の値は PLAIN_TEXT または HTML です。content には、分析のために Natural Language API に送信するテキストを指定します。
Natural Language API では、Cloud Storage に保存されているファイルをテキスト処理用に送信することもできます。Cloud Storage からファイルを送信する場合は、content を gcsContentUri に置き換えて、Cloud Storage に保存されているテキスト ファイルの URI の値を指定します。
encodingType は、テキストを処理するときに使用するテキスト エンコードの種類を API に指示します。API はこの情報を使って、特定のエンティティがテキストのどこに出現するかを調べます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 3. Natural Language API を呼び出す
- 次の
curlコマンドを実行して、リクエストの本文を、先ほど保存した API キー環境変数とともに Natural Language API に渡します(コマンドは 1 行で入力してください)。
- レスポンスを確認するために、次を実行します。
レスポンスの最初の部分は次のようになります。
このレスポンスには、各エンティティの type、ウィキペディアの関連ページの URL(存在する場合)、salience、テキスト内の場所を示すインデックスが含まれています。salience(顕著性)は、[0,1] の範囲の数値です。これは、そのエンティティがテキスト全体でどの程度重要かを表します。
Natural Language API では、同じエンティティの別の表現も認識されます。レスポンスの mentions のリストをご覧ください。「Joanne Rowling」、「Rowling」、「novelist」、「Robert Galbraith」がすべて同じものを指していることが API で認識されています。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 4. Natural Language API で感情分析を行う
Natural Language API では、エンティティの抽出に加えて、テキスト ブロックの感情分析を行うこともできます。次の JSON リクエストに含まれているパラメータは先ほどのリクエストと同じですが、今回は分析するテキストをより強い感情を含むものに変更します。
- nano を使用して
request.jsonのコードを次のように置き換えます。contentの部分は独自のテキストに置き換えてもかまいません。
-
Ctrl+X キーで nano を終了したら、Y キーでファイルを保存し、Enter キーを押して確定します。
-
次に、このリクエストを API の
analyzeSentimentエンドポイントに送信します。
レスポンスは次のようになります。
sentiment の値が 2 種類あることに注目してください。これは、ドキュメント全体の値と文単位の値です。sentiment メソッドは次の 2 つの値を返します。
-
score- -1.0~1.0 の数値です。その主張がどのくらいポジティブまたはネガティブかを示します。 -
magnitude- 0~無限大の数値です。その主張の中で表現されている感情の重みを表します。感情がポジティブがネガティブかは問いません。
重みの大きい主張を含むテキスト ブロックが長くなるほど magnitude の値が大きくなります。この例では、1 つ目の文の score はポジティブ(0.7)ですが、2 つ目の文の score はニュートラル(0.1)です。
タスク 5. エンティティ感情を分析する
Natural Language API では、テキスト ドキュメント全体の感情だけでなく、テキスト内のエンティティごとの感情を調べることもできます。今度は次の文を例として使用します。
I liked the sushi but the service was terrible.
この場合、先ほどのように文全体の感情スコアを取得してもあまり役に立ちません。これがレストランのレビューで、同じレストランのレビューが何百件もあった場合、求められる情報は、それらのレビューで何が気に入られていて、何が気に入られていないかです。Natural Language API にはこのような場合のために、テキスト内の各エンティティに対する感情を調べられる analyzeEntitySentiment というメソッドが用意されています。さっそく試してみましょう。
- nano を使用して
request.jsonを以下のように更新します。
-
Ctrl+X キーで nano を終了したら、Y キーでファイルを保存し、Enter キーを押して確定します。
-
次に、以下の curl コマンドを使用して
analyzeEntitySentimentエンドポイントを呼び出します。
レスポンスには 2 つのエンティティ オブジェクトが含まれています。1 つは「sushi」、もう 1 つは「service」です。この JSON レスポンス全体は以下のとおりです。
「sushi」の score はニュートラルの 0 で、「service」の score は -0.7 になっています。分析がうまくいったようです。また、sentiment オブジェクトがエンティティごとに 2 つ返されていますが、これは特定の出現箇所の値と、エンティティ全体の集計値を表しています。これらの言葉が複数回出てきた場合は、それぞれに別の score と magnitude の値が返されます。
タスク 6. 構文と品詞を分析する
Natural Language API のもう 1 つのメソッドである構文解析では、言語学的な観点からテキストをさらに詳しく調べることができます。analyzeSyntax は言語情報を抽出し、指定されたテキストを一連の文とトークン(通常は単語の境界)に分解して、それらのトークンをさらに分析できるようにします。テキスト内の各単語について、その単語の品詞(名詞、動詞、形容詞など)と、文中の他の単語との関係(主動詞か修飾語かなど)を調べることができます。
簡単な文で試してみましょう。次の JSON リクエストは、先ほどのものとよく似ていますが、features キーが追加されています。これにより、構文アノテーションを行うことが API に伝えられます。
- nano を使用して
request.jsonを次の内容に置き換えます。
-
Ctrl+X キーで nano を終了したら、Y キーでファイルを保存し、Enter キーを押して確定します。
-
次に、API の
analyzeSyntaxメソッドを呼び出します。
レスポンスでは、次のようなオブジェクトが文中のトークンごとに返されます。
レスポンスを細かく見てみましょう。
-
partOfSpeechは、「Joanne」が名詞であることを示しています。 -
dependencyEdgeには、このテキストの係り受け解析ツリーを作成するためのデータが含まれています。係り受け解析ツリーとは、文中の単語が互いにどのように関連しているかを示す図です。たとえば、上の文の係り受け解析ツリーは次のようになります。
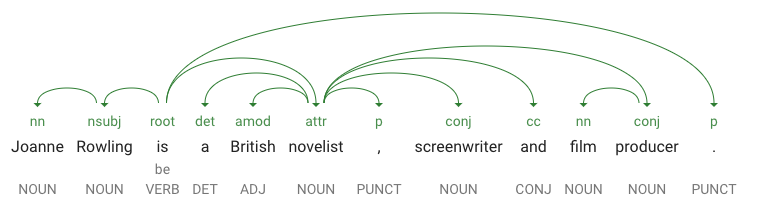
-
headTokenIndexは、「Joanne」に向かう曲線を持つトークンのインデックスです。文中の各トークンは、配列内の単語と考えることができます。 - 「Joanne」の
headTokenIndexの値 1 は「Rowling」を指しており、「Joanne」は係り受け解析ツリーでこの単語に結び付けられます。label の値NM(Noun Compound Modifier(複合名詞の修飾子)の略)は「Joanne」の文中の役割を表しており、「Joanne」はこの文の主語である「Rowling」を修飾しています。 -
lemmaはその単語の正規形です。たとえば、run、runs、ran、running の lemma はすべて run です。lemma の値は、大きなテキスト ブロックで単語の出現回数の推移を追跡するのに便利です。
タスク 7. 多言語自然言語処理
Natural Language API は英語以外の言語もサポートしています(サポート対象言語の一覧については、言語サポートをご覧ください)。
-
request.jsonのコードを次のように変更して、日本語の文で試してみましょう。
- Ctrl+X キーで nano を終了したら、Y キーでファイルを保存し、Enter キーを押して確定します。
テキストの言語を指定していないことに注目してください。言語は API によって自動的に検出されます。
- 次に、これを
analyzeEntitiesエンドポイントに送信します。
次のようなレスポンスが返されます。
ウィキペディアの URL も日本語版のページになっています。
お疲れさまでした
ここでは、Cloud Natural Language API によるテキスト分析の方法を学ぶために、エンティティ抽出、感情分析、構文アノテーションを行いました。具体的な内容は次のとおりです。
- Natural Language API リクエストを作成し、curl で API を呼び出す
- Natural Language API でテキストのエンティティ抽出と感情分析を行う
- テキストを言語学的に分析して係り受け解析ツリーを作成する
- 日本語のテキストを使って Natural Language API リクエストを作成する
クエストを完了する
このセルフペース ラボは、「Intro to ML: Language Processing」クエストと「Language, Speech, Text & Translation with Google Cloud APIs」クエストの一部です。クエストとは学習プログラムを構成する一連のラボのことで、完了すると成果が認められて上のようなバッジが贈られます。バッジは公開して、オンライン レジュメやソーシャル メディア アカウントにリンクできます。このラボの修了後、このラボが含まれるクエストに登録すれば、すぐにクレジットを受け取ることができます。受講可能なその他のクエストもご確認ください。
次のラボを受講する
ML API に関する別のラボ(Vertex AI Workbench ノートブック: Qwik Start など)、または以下のいずれかをお試しください。
次のステップ
- Natural Language API のチュートリアル ドキュメントを確認する
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 9 月 19 日
ラボの最終テスト日: 2023 年 10 月 13 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。