GSP037

Informações gerais
A API Cloud Vision é um serviço baseado em nuvem que permite analisar imagens e extrair informações. Ela pode ser usada para detectar objetos, rostos e textos em imagens. A API Cloud Vision faz o encapsulamento de modelos avançados de machine learning em uma API REST simples, o que permite entender o conteúdo de imagens.
Neste laboratório, você vai aprender a enviar imagens para a API Cloud Vision e conferir como ela detecta objetos, rostos e pontos de referência.
Objetivos
Neste laboratório, você aprenderá a fazer o seguinte:
- Criar uma solicitação para a API Cloud Vision e chamar a API com
curl
- Usar os métodos de detecção facial, de rótulos e de pontos de referência da API
Configuração e requisitos
Antes de clicar no botão Começar o Laboratório
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é ativado quando você clica em Iniciar laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, e não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima (recomendado) ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório: não se esqueça que, depois de começar, não será possível pausar o laboratório.
Observação: use apenas a conta de estudante neste laboratório. Se usar outra conta do Google Cloud, você poderá receber cobranças nela.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar por ele, uma caixa de diálogo vai aparecer para você selecionar a forma de pagamento.
No painel Detalhes do Laboratório, à esquerda, você vai encontrar o seguinte:
- O botão Abrir Console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer Login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Username"}}}
Você também encontra o nome de usuário no painel Detalhes do Laboratório.
-
Clique em Próxima.
-
Copie a Senha abaixo e cole na caixa de diálogo de Olá.
{{{user_0.password | "Password"}}}
Você também encontra a senha no painel Detalhes do Laboratório.
-
Clique em Próxima.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.
Observação: para acessar os produtos e serviços do Google Cloud, clique no Menu de navegação ou digite o nome do serviço ou produto no campo Pesquisar.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
-
Clique em Ativar o Cloud Shell  na parte de cima do console do Google Cloud.
na parte de cima do console do Google Cloud.
-
Clique nas seguintes janelas:
- Continue na janela de informações do Cloud Shell.
- Autorize o Cloud Shell a usar suas credenciais para fazer chamadas de APIs do Google Cloud.
Depois de se conectar, você verá que sua conta já está autenticada e que o projeto está configurado com seu Project_ID, . A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
A gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
gcloud auth list
- Clique em Autorizar.
Saída:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (Opcional) É possível listar o ID do projeto usando este comando:
gcloud config list project
Saída:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Observação: consulte a documentação completa da gcloud no Google Cloud no guia de visão geral da gcloud CLI.
Tarefa 1: Criar uma chave de API
Nesta tarefa, você vai gerar uma chave de API para transmitir o URL da solicitação na preparação para usar curl para enviar uma solicitação à API Vision.
-
Para criar uma chave de API, acesse o Menu de navegação e selecione APIs e serviços > Credenciais no console do Cloud.
-
Clique em Criar credenciais e selecione Chave de API.
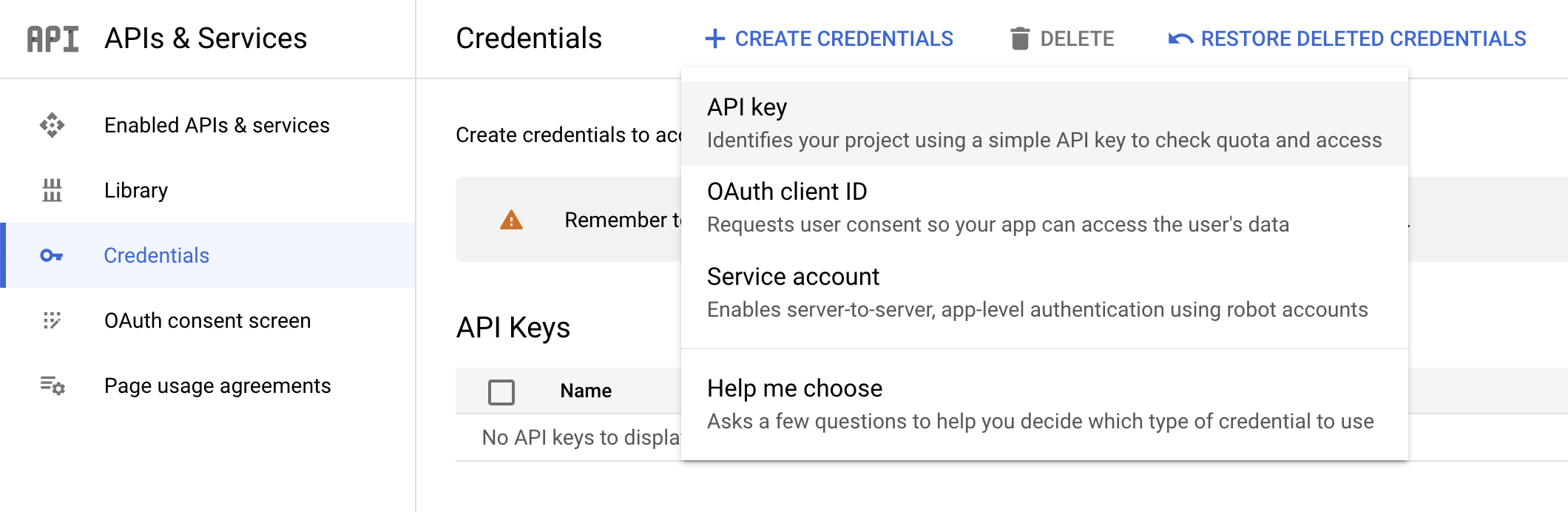
- Depois, copie a chave gerada e clique em Fechar.
Clique em Verificar meu progresso abaixo para conferir seu progresso no laboratório.
Crie uma chave de API
Em seguida, salve a chave em uma variável de ambiente para não precisar inserir o valor dela em cada solicitação.
- Atualize o comando a seguir para substituir o texto do marcador pela chave de API que você copiou e execute o comando no Cloud Shell para definir o valor como uma variável de ambiente:
export API_KEY=<YOUR_API_KEY>
Tarefa 2: Fazer upload de uma imagem em um bucket do Cloud Storage
Há duas maneiras de enviar uma imagem à API Cloud Vision para detecção: enviar uma string de imagem codificada em base64 ou transmitir o URL de um arquivo armazenado no Cloud Storage.
Este laboratório usa a abordagem de URL do Cloud Storage. A primeira etapa é criar um bucket do Cloud Storage para armazenar suas imagens.
-
No Menu de navegação, selecione Cloud Storage > Buckets. Ao lado de Buckets, clique em Criar.
-
Dê um nome exclusivo ao bucket: -bucket.
-
Após dar o nome ao bucket, clique em Escolher como controlar o acesso aos objetos.
-
Desmarque a caixa de seleção Aplicar a prevenção do acesso público neste bucket e selecione o botão de opção Detalhado.
Mantenha o padrão em todas as outras configurações do bucket.
- Clique em Criar.
Faça upload de uma imagem para o bucket
- Clique com o botão direito do mouse na imagem de donuts, depois em Salvar imagem como e salve no seu computador como donuts.png.

- Acesse o bucket que você criou, clique em Fazer upload > Fazer upload de arquivos, depois selecione donuts.png e clique em Abrir.
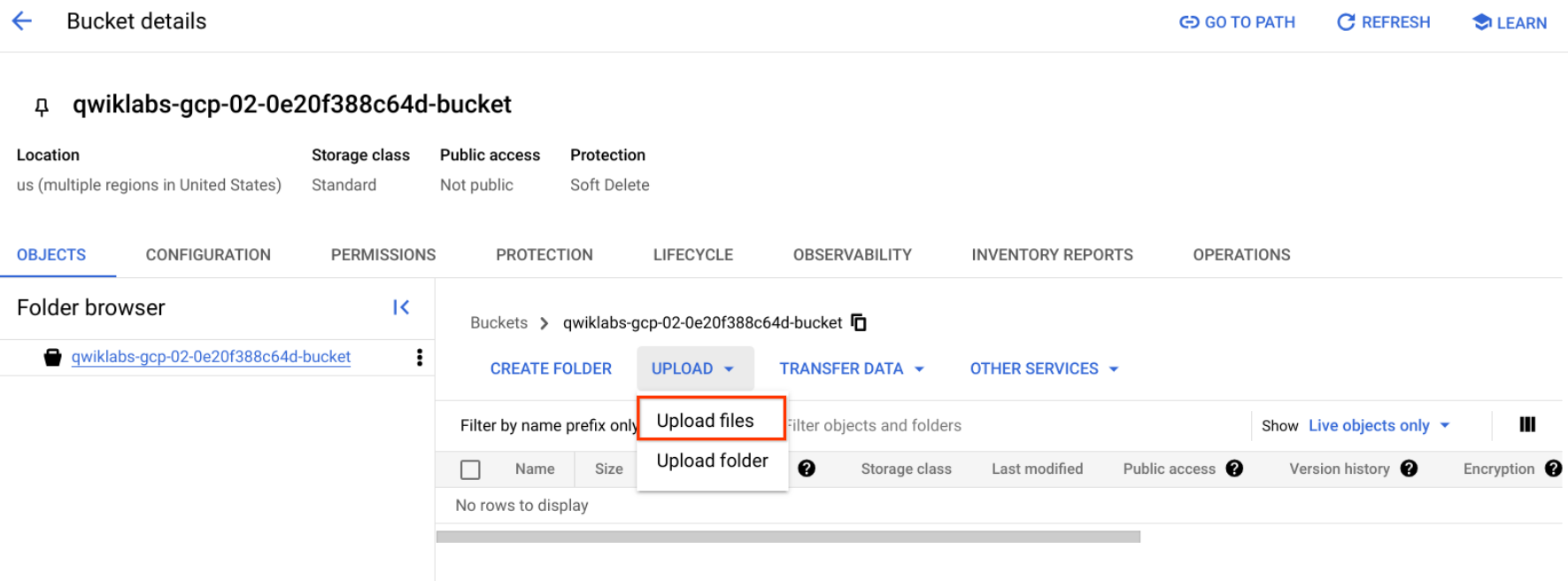
Você verá o arquivo no bucket.
Agora você precisa disponibilizar a imagem de maneira pública.
- Clique nos três pontos da imagem e selecione Editar acesso.
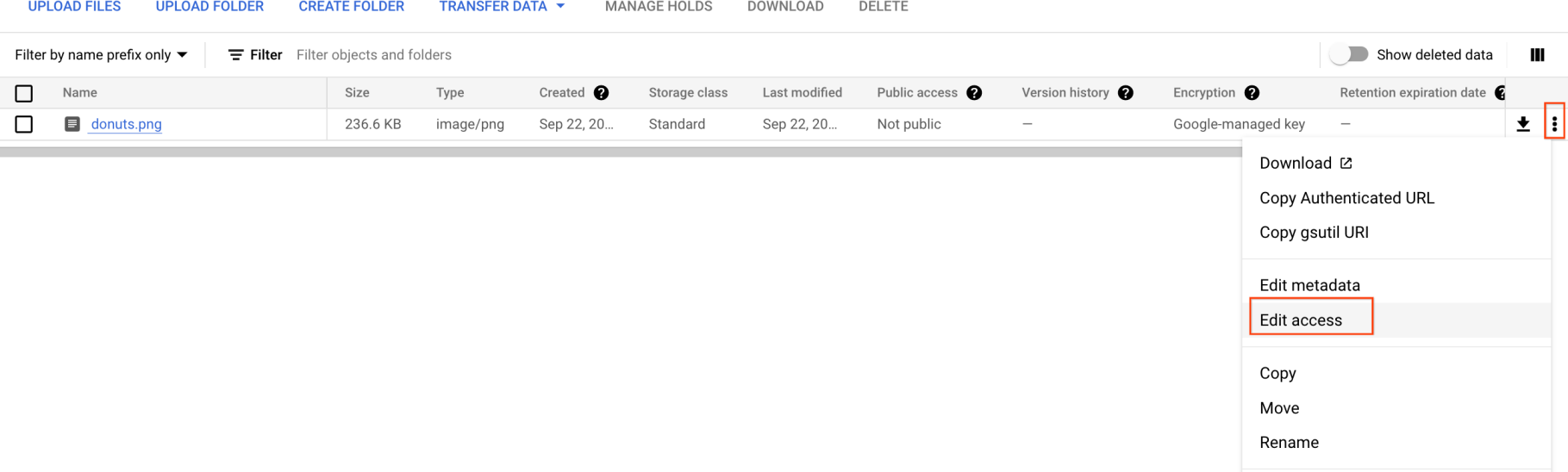
-
Clique em Adicionar entrada e digite o seguinte:
-
Entidade: Public
-
Nome: allUsers
-
Acesso: Reader
-
Em seguida, clique em Salvar.
Agora que o arquivo está no bucket, você pode criar uma solicitação para a API Cloud Vision transmitindo a ela o URL dessa imagem de donuts.
Clique em Verificar meu progresso abaixo para conferir seu progresso no laboratório.
Faça upload de uma imagem para o bucket
Tarefa 3: Criar a solicitação
Crie um arquivo request.json no diretório principal do Cloud Shell.
- Usando o editor de código do Cloud Shell (clicando no ícone de lápis na barra de opções do Cloud Shell)

ou seu editor de linha de comando preferido (nano, vim ou emacs), crie um arquivo request.json.
- Cole o código a seguir no arquivo
request.json:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}
-
Salve o arquivo.
Ativar o Gemini Code Assist no Cloud Shell IDE
Você pode usar o Gemini Code Assist em um ambiente de desenvolvimento integrado (IDE), como o Cloud Shell, para receber orientações sobre o código ou resolver problemas com ele. Antes de começar a usar o Gemini Code Assist, você precisa ativá-lo.
- No Cloud Shell, ative a API Gemini para Google Cloud com o seguinte comando:
gcloud services enable cloudaicompanion.googleapis.com
- Clique em Abrir editor na barra de ferramentas do Cloud Shell.
Observação: para abrir o editor do Cloud Shell, clique em Abrir editor na barra de ferramentas do Cloud Shell. Você pode alternar o Cloud Shell e o editor de código clicando em Abrir editor ou Abrir terminal, conforme necessário.
-
No painel à esquerda, clique no ícone Configurações e, na visualização Configurações, pesquise Gemini Code Assist.
-
Localize e verifique se a caixa de seleção Geminicodeassist: Ativar está marcada e feche as Configurações.
-
Clique em Cloud Code - Sem projeto na barra de status na parte de baixo da tela.
-
Autorize o plug-in conforme instruído. Se um projeto não for selecionado automaticamente, clique em Selecionar um projeto do Google Cloud e escolha .
-
Verifique se o projeto do Google Cloud () aparece na mensagem de status do Cloud Code na barra de status.
Tarefa 4: Realizar detecção de rótulos
O primeiro recurso da API Cloud Vision que você vai conhecer é a detecção de rótulos. O método que você usa retorna uma lista de rótulos (palavras) que descrevem o conteúdo da imagem.
- No terminal do Cloud Shell, execute o seguinte comando
curl para chamar a API Cloud Vision e salvar a resposta no arquivo label_detection.json:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY} -o label_detection.json && cat label_detection.json
A resposta deverá ser semelhante a esta:
Saída:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "Powdered sugar",
"score": 0.9861496,
"topicality": 0.9861496
},
{
"mid": "/m/01wydv",
"description": "Beignet",
"score": 0.9565117,
"topicality": 0.9565117
},
{
"mid": "/m/02wbm",
"description": "Food",
"score": 0.9424965,
"topicality": 0.9424965
},
{
"mid": "/m/0hnyx",
"description": "Pastry",
"score": 0.8173416,
"topicality": 0.8173416
},
{
"mid": "/m/02q08p0",
"description": "Dish",
"score": 0.8076026,
"topicality": 0.8076026
},
{
"mid": "/m/01ykh",
"description": "Cuisine",
"score": 0.79036003,
"topicality": 0.79036003
},
{
"mid": "/m/03nsjgy",
"description": "Kourabiedes",
"score": 0.77726763,
"topicality": 0.77726763
},
{
"mid": "/m/06gd3r",
"description": "Angel wings",
"score": 0.73792106,
"topicality": 0.73792106
},
{
"mid": "/m/06x4c",
"description": "Sugar",
"score": 0.71921736,
"topicality": 0.71921736
},
{
"mid": "/m/01zl9v",
"description": "Zeppole",
"score": 0.7111677,
"topicality": 0.7111677
}
]
}
]
}
A API identificou o tipo específico dos donuts: com açúcar de confeiteiro. Ótimo! Para cada rótulo encontrado pela API Vision, são retornadas as seguintes informações:
-
description com o nome do item.
-
score, que consiste em um número de 0 a 1 que indica o nível de confiança na correspondência entre a descrição e o que está na imagem.
-
mid, que consiste no valor correspondente ao mid do item no Mapa de informações do Google. É possível usar mid ao chamar a API Knowledge Graph para receber mais informações sobre o item.
- No editor do Cloud Shell, navegue até
label_detection.json. Essa ação ativa o Gemini Code Assist, como indicado pela presença do ícone  no canto superior direito do editor.
no canto superior direito do editor.
Para aumentar a produtividade e minimizar a troca de contexto, o Gemini Code Assist oferece ações inteligentes com tecnologia de IA diretamente no editor de código. Nesta seção, você decide pedir ao Gemini Code Assist para explicar a resposta da API Cloud Vision a um membro da equipe.
-
Clique no ícone Gemini Code Assist: Ações Inteligentes e selecione Explique isto.
-
O Gemini Code Assist abre um painel de chat com o comando Explique isto preenchido. Na caixa de texto inline do chat do Code Assist, substitua o comando preenchido previamente pelo seguinte e clique em Enviar:
Você é engenheiro de machine learning na Cymbal AI. Um novo membro da equipe precisa de ajuda para entender essa resposta da API Cloud Vision. Explique o arquivo label_detection.json em detalhes. Analise os principais componentes e a função deles no código JSON.
Para as melhorias sugeridas, não faça alterações no conteúdo do arquivo.
Explicações detalhadas da resposta da API Cloud Vision no código label_detection.json aparecem no chat do Gemini Code Assist.
Tarefa 5: Realizar detecção na Web
Além de extrair rótulos da imagem, a API Cloud Vision também pesquisa mais detalhes sobre ela na Internet. Com o método WebDetection da API, você recebe muitos dados interessantes:
- Uma lista das entidades encontradas na imagem, com base no conteúdo de páginas com imagens semelhantes.
- URLs de imagens correspondentes (exatas e parciais) encontradas na Web, além dos URLs dessas páginas.
- URLs de imagens semelhantes, como na pesquisa reversa de imagens.
Para testar a detecção na Web, use a mesma imagem dos beignets e altere uma linha no arquivo request.json. Se quiser tentar algo novo, use uma imagem completamente diferente.
-
No editor do Cloud Shell, ainda no mesmo diretório, navegue até request.json e abra o arquivo.
-
Clique no ícone Gemini Code Assist: Ações Inteligentes na barra de ferramentas.
Além de fornecer explicações detalhadas do código, você também pode usar os recursos com tecnologia de IA do Gemini Code Assist para fazer alterações no código diretamente no editor. Nesse caso, você decide deixar o Gemini Code Assist ajudar a editar o conteúdo do arquivo request.json.
- Para editar o arquivo
request.json, cole o seguinte comando no campo de texto inline do Gemini Code Assist que aparece na barra de ferramentas.
No arquivo request.json, atualize a lista de recursos e mude o tipo de LABEL_DETECTION para WEB_DETECTION.
-
Para pedir ao Gemini Code Assist que modifique o código de acordo com isso, pressione ENTER.
-
Quando solicitado na visualização Gemini Diff, clique em Aceitar.
O conteúdo do arquivo request.json agora deve ser semelhante ao seguinte:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}
- No terminal do Cloud Shell, execute o seguinte comando
curl para chamar a API Cloud Vision:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Analise os detalhes da resposta, começando com
webEntities. Veja algumas entidades retornadas por essa imagem:
{
"responses": [
{
"webDetection": {
"webEntities": [
{
"entityId": "/m/0z5n",
"score": 0.8868,
"description": "Application programming interface"
},
{
"entityId": "/m/07kg1sq",
"score": 0.3139,
"description": "Encapsulation"
},
{
"entityId": "/m/0105pbj4",
"score": 0.2713,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/01hyh_",
"score": 0.2594,
"description": "Machine learning"
},
...
]
Essa imagem foi usada em muitas apresentações sobre APIs de ML do Google Cloud. Foi por isso que a API encontrou as entidades "Machine learning" e "Google Cloud Platform".
Se você inspecionar os URLs em fullMatchingImages, partialMatchingImages e pagesWithMatchingImages, perceberá que muitos deles apontam para o site deste laboratório (super meta!).
Suponha que você queira encontrar outras imagens de beignets, mas não exatamente as mesmas. É aí que entra a parte visuallySimilarImages da resposta da API. Veja algumas das imagens visualmente semelhantes encontradas por ela:
"visuallySimilarImages": [
{
"url": "https://media.istockphoto.com/photos/cafe-du-monde-picture-id1063530570?k=6&m=1063530570&s=612x612&w=0&h=b74EYAjlfxMw8G-G_6BW-6ltP9Y2UFQ3TjZopN-pigI="
},
{
"url": "https://s3-media2.fl.yelpcdn.com/bphoto/oid0KchdCqlSqZzpznCEoA/o.jpg"
},
{
"url": "https://s3-media1.fl.yelpcdn.com/bphoto/mgAhrlLFvXe0IkT5UMOUlw/348s.jpg"
},
...
]
Você pode acessar esses URLs para ver as imagens parecidas:



Depois de todas essas imagens, você deve ter ficado com vontade de comer um beignet com açúcar de confeiteiro (foi mal)!. Esse processo é semelhante à pesquisa de uma imagem nas Imagens do Google.
No Cloud Vision, é possível acessar essa funcionalidade com uma API REST fácil de usar e integrá-la aos seus aplicativos.
Tarefa 6: Realizar detecção facial
Em seguida, conheça os métodos de detecção facial da API Vision.
O método de detecção de rosto retorna dados sobre os rostos encontrados, inclusive as emoções e o local da imagem.
Faça upload de uma nova imagem
Para usar esse método, faça upload de uma nova imagem com rostos no bucket do Cloud Storage.
- Clique com o botão direito do mouse na imagem abaixo. Em seguida, clique em Salvar imagem como e salve-a no seu computador como selfie.png.

- Agora, faça upload da imagem para o bucket do Cloud Storage da forma como fez antes e torne-a pública.
Clique em Verificar meu progresso abaixo para conferir seu progresso no laboratório.
Faça upload de uma imagem no bucket para realizar a detecção facial
Atualize o arquivo de solicitação
-
No editor do Cloud Shell, ainda no mesmo diretório, navegue até request.json.
-
Clique no ícone Gemini Code Assist: Ações Inteligentes na barra de ferramentas.
-
Para ajudar a atualizar o arquivo request.json, cole o seguinte comando no campo de texto inline do Gemini Code Assist que é aberto na barra de ferramentas:
Atualize o arquivo request.json para fazer três mudanças específicas:
* Atualize o valor de gcsImageUri de donuts.png para selfie.png.
* Substitua a matriz de recursos atual por dois novos tipos de recursos: FACE_DETECTION e LANDMARK_DETECTION.
* Não quero o resultado maxResults.
-
Para pedir ao Gemini Code Assist que modifique o código de acordo com isso, pressione ENTER.
-
Quando solicitado na visualização Gemini Diff, clique em Aceitar.
Seu arquivo de solicitação atualizado deve ser semelhante ao seguinte:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}
Chame a API Vision e analise a resposta
- No terminal do Cloud Shell, execute o seguinte comando
curl para chamar a API Cloud Vision:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Observe o objeto
faceAnnotations na resposta. Veja que a API retorna um objeto para cada rosto encontrado na imagem (nesse caso são três). Esta é uma versão parcial da resposta:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "LIKELY",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}
-
boundingPoly informa as coordenadas X, Y ao redor do rosto na imagem.
-
fdBoundingPoly é uma caixa menor do que boundingPoly e que analisa apenas a pele do rosto.
-
landmarks é uma matriz de objetos para cada recurso facial, alguns que talvez você nem conheça. Ela informa o tipo de ponto de referência, junto com a posição 3D desse recurso (coordenadas X, Y, Z) onde a coordenada Z é a profundidade. Os demais valores dão mais detalhes sobre o rosto, incluindo a probabilidade de expressões de alegria, tristeza, raiva e surpresa.
A resposta que você recebeu é relacionada à pessoa que está de pé mais ao fundo da imagem. É possível notar que há uma expressão brincalhona, o que explica joyLikelihood como LIKELY.
Tarefa 7: Realizar anotação de pontos de referência
A detecção de pontos de referência consegue identificar lugares comuns (e desconhecidos também). Ela retorna o nome do ponto de referência, as coordenadas de latitude e longitude e o local onde esse ponto foi identificado na imagem.
Faça upload de uma nova imagem
Para usar esse método, faça upload de uma nova imagem no bucket do Cloud Storage.
- Clique com o botão direito do mouse na imagem abaixo. Em seguida, selecione Salvar imagem como e salve-a no seu computador como city.png.

Citação: Catedral de São Basílio, Moscou, Rússia (19 de dezembro de 2019) por Adrien Wodey no Unsplash, um repositório de mídia gratuito. Fonte: https://unsplash.com/photos/multicolored-dome-temple-yjyWCNx0J1U. O arquivo está licenciado sob a licença do Unsplash.
- Agora, faça upload da imagem para o bucket do Cloud Storage da forma como fez antes e torne-a pública.
Clique em Verificar meu progresso abaixo para conferir seu progresso no laboratório.
Faça upload de uma imagem no bucket para realizar a anotação de pontos de referência
Atualize o arquivo de solicitação
- Em seguida, atualize o arquivo
request.json com as informações abaixo. Elas incluem o URL da nova imagem e usam a detecção de pontos de referência.
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/city.png"
}
},
"features": [
{
"type": "LANDMARK_DETECTION",
"maxResults": 10
}
]
}
]
}
Chame a API Vision e analise a resposta
- No terminal do Cloud Shell, execute o seguinte comando
curl para chamar a API Cloud Vision:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Observe agora a parte
landmarkAnnotations da resposta:
"landmarkAnnotations": [
{
"mid": "/m/0hm_7",
"description": "Red Square",
"score": 0.8557956,
"boundingPoly": {
"vertices": [
{},
{
"x": 503
},
{
"x": 503,
"y": 650
},
{
"y": 650
}
]
},
"locations": [
{
"latLng": {
"latitude": 55.753930299999993,
"longitude": 37.620794999999994
}
...
A API Cloud Vision identificou o local em que a foto foi tirada e fornece as coordenadas do mapa para o local (Catedral de São Basílio na Praça Vermelha, Moscou, Rússia).
Os valores nessa resposta devem ser semelhantes à labelAnnotations citada anteriormente:
- O
mid do ponto de referência
- O nome (
description)
- Um
score de confiança
-
boundingPoly mostra a região na imagem onde o ponto de referência foi identificado.
- A chave
locations informa as coordenadas de latitude e longitude da imagem.
Tarefa 8: Realizar a localização de objetos
A API Vision pode detectar e extrair vários objetos de uma imagem com a localização de objetos. A localização de objetos identifica vários itens em uma imagem e fornece uma LocalizedObjectAnnotation para cada um deles. Cada LocalizedObjectAnnotation identifica informações sobre o objeto, como a posição e os limites retangulares dele para a região da imagem que contém o objeto.
A localização de objetos também identifica itens significativos e menos proeminentes em uma imagem.
As informações sobre o objeto são retornadas apenas em inglês. O Cloud Translation pode traduzir rótulos em inglês para vários idiomas diferentes.
Para usar esse método, escolha uma imagem existente na Internet e atualize o arquivo request.json.
Atualize o arquivo de solicitação
- Atualize o arquivo
request.json com as informações abaixo. Elas incluem o URL da nova imagem e usam a localização de objetos.
{
"requests": [
{
"image": {
"source": {
"imageUri": "https://cloud.google.com/vision/docs/images/bicycle_example.png"
}
},
"features": [
{
"maxResults": 10,
"type": "OBJECT_LOCALIZATION"
}
]
}
]
}
Chame a API Vision e analise a resposta
- No terminal do Cloud Shell, execute o seguinte comando
curl para chamar a API Cloud Vision:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Observe agora a parte
localizedObjectAnnotations da resposta:
{
"responses": [
{
"localizedObjectAnnotations": [
{
"mid": "/m/01bqk0",
"name": "Bicycle wheel",
"score": 0.89648587,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.32076266,
"y": 0.78941387
},
{
"x": 0.43812272,
"y": 0.78941387
},
{
"x": 0.43812272,
"y": 0.97331065
},
{
"x": 0.32076266,
"y": 0.97331065
}
]
}
},
{
"mid": "/m/0199g",
"name": "Bicycle",
"score": 0.886761,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.312,
"y": 0.6616471
},
{
"x": 0.638353,
"y": 0.6616471
},
{
"x": 0.638353,
"y": 0.9705882
},
{
"x": 0.312,
"y": 0.9705882
}
]
}
},
...
Observe que a API Vision conseguiu identificar que a imagem contém uma bicicleta e uma roda de bicicleta. Os valores na resposta devem ser semelhantes aos da resposta labelAnnotations acima: o mid do objeto, o nome dele (name), um score de confiança e o boundingPoly mostram a região da imagem em que o objeto foi identificado.
Além disso, boundingPoly tem uma chave normalizedVertices, que fornece as coordenadas do objeto na imagem. Essas coordenadas são normalizadas para um intervalo de 0 a 1, em que 0 representa a parte superior esquerda da imagem e 1 representa a parte inferior direita.
Ótimo. Você usou a API Vision para analisar uma imagem e extrair informações sobre os objetos que estão nela.
Tarefa 9: Explorar outros métodos da API Vision
Você acabou de aprender sobre os métodos de detecção facial, de rótulos e de pontos de referência da API Vision, mas ainda há três outros que você não conhece. Confira a documentação do método images.annotate para saber mais sobre os outros três métodos:
-
Detecção de logotipos: identifica logotipos comuns e os locais deles em uma imagem.
-
Detecção de pesquisa segura: determina se uma imagem contém conteúdo explícito. É útil para aplicativos com conteúdo gerado pelo usuário. É possível filtrar imagens com base em quatro fatores: conteúdo adulto, médico, violento e falso.
-
Detecção de texto: usa OCR para extrair textos de imagens. Esse método pode até mesmo identificar o idioma do texto presente em uma imagem.
Parabéns!
Você aprendeu a analisar imagens com a API Vision. Neste laboratório, você transmitiu à API o URL do Cloud Storage de diferentes imagens, e ela retornou os rótulos, rostos, pontos de referência e objetos encontrados nelas. Também é possível transmitir à API a string codificada em base64 de uma imagem, o que é útil quando ela está armazenada em um banco de dados ou na memória.
Próximas etapas / Saiba mais
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 21 de agosto de 2025
Laboratório testado em 21 de agosto de 2025
Copyright 2025 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.





