GSP037

Descripción general
La API de Cloud Vision es un servicio basado en la nube que te permite analizar imágenes y extraer información. Se puede usar para detectar objetos, rostros y texto en imágenes. La API de Cloud Vision te permite comprender el contenido de una imagen a través del encapsulamiento de modelos de aprendizaje automático potentes en una API de REST sencilla.
En este lab, explorarás cómo enviar imágenes a la API de Cloud Vision y verás que detecta objetos, rostros y puntos de referencia.
Objetivos
En este lab, aprenderás a realizar las siguientes tareas:
- Crear una solicitud a la API de Cloud Vision y llamar a la API con
curl
- Usar los métodos de detección de etiquetas, rostros y puntos de referencia de la API
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs cuentan con un temporizador que no se puede pausar. El temporizador, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar. Se recomienda el navegador Chrome.
Nota: Usa una ventana del navegador privada o de incógnito (opción recomendada) para ejecutar el lab. Así evitarás conflictos entre tu cuenta personal y la cuenta de estudiante, lo que podría generar cargos adicionales en tu cuenta personal.
- Tiempo para completar el lab (recuerda que, una vez que comienzas un lab, no puedes pausarlo).
Nota: Usa solo la cuenta de estudiante para este lab. Si usas otra cuenta de Google Cloud, es posible que se apliquen cargos a esa cuenta.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haz clic en el botón Comenzar lab. Si debes pagar por el lab, se abrirá un diálogo para que selecciones la forma de pago.
A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón para abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debes usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordena las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta.
-
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}}
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}}
También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud.
Nota: Usar tu propia cuenta de Google Cloud para este lab podría generar cargos adicionales.
-
Haz clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.
Nota: Para acceder a los productos y servicios de Google Cloud, haz clic en el menú de navegación o escribe el nombre del servicio o producto en el campo Buscar.

Activa Cloud Shell
Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
-
Haz clic en Activar Cloud Shell  en la parte superior de la consola de Google Cloud.
en la parte superior de la consola de Google Cloud.
-
Haz clic para avanzar por las siguientes ventanas:
- Continúa en la ventana de información de Cloud Shell.
- Autoriza a Cloud Shell para que use tus credenciales para realizar llamadas a la API de Google Cloud.
Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu Project_ID, . El resultado contiene una línea que declara el Project_ID para esta sesión:
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
- Puedes solicitar el nombre de la cuenta activa con este comando (opcional):
gcloud auth list
- Haz clic en Autorizar.
Resultado:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Puedes solicitar el ID del proyecto con este comando (opcional):
gcloud config list project
Resultado:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Nota: Para obtener toda la documentación de gcloud, en Google Cloud, consulta la guía con la descripción general de gcloud CLI.
Tarea 1: Crea una clave de API
En esta tarea, generarás una clave de API para pasarla en la URL de tu solicitud como preparación para usar curl y enviar una solicitud a la API de Vision.
-
Para crear una clave de API, desde el menú de navegación, ve a APIs y servicios > Credenciales en la consola de Cloud.
-
Haz clic en Crear credenciales y selecciona Clave de API.
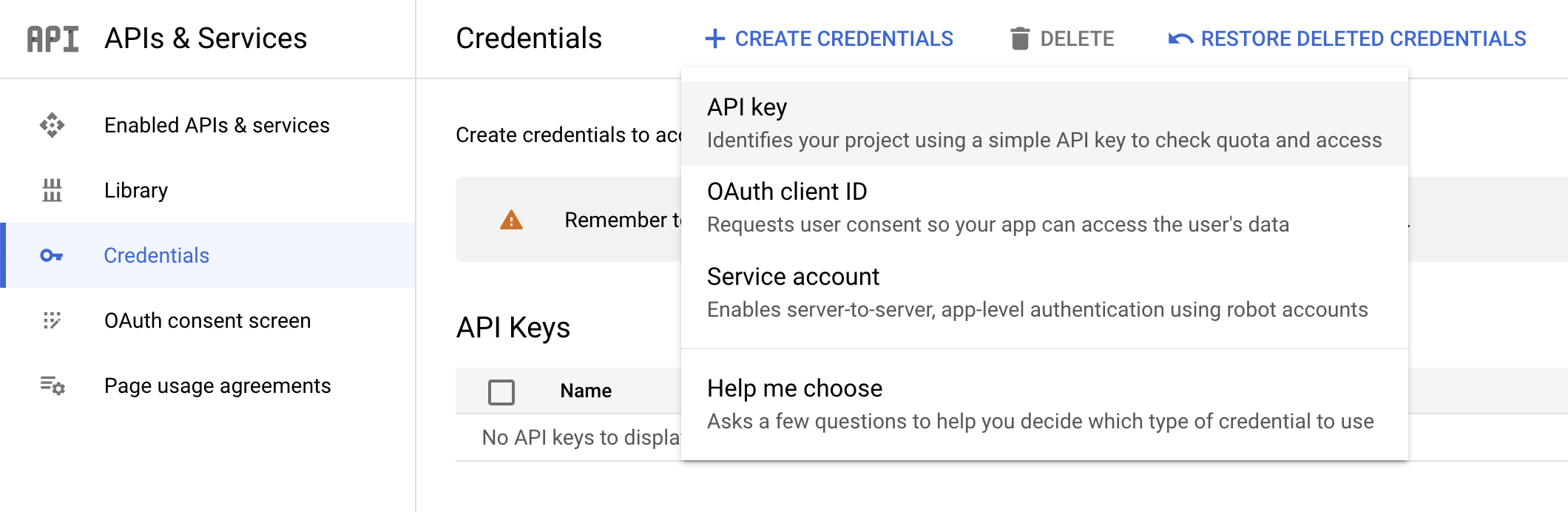
- Luego, copia la clave que acabas de generar y haz clic en Cerrar.
Haz clic en Revisar mi progreso para verificar tu progreso en el lab.
Crear una clave de API
Ahora, guárdala en una variable de entorno para no tener que ingresar el valor de la clave de API en cada solicitud.
- Actualiza el siguiente comando para reemplazar el texto del marcador de posición por la clave de API que copiaste y, luego, ejecuta el comando en Cloud Shell para establecer el valor como una variable de entorno:
export API_KEY=<YOUR_API_KEY>
Tarea 2: Sube una imagen a un bucket de Cloud Storage
Hay dos maneras de enviar una imagen a la API de Cloud Vision para que la detecte: enviar a la API una cadena de imagen codificada en base64 o pasarle a la API la URL de un archivo almacenado en Cloud Storage.
En este lab, se usa el enfoque de URL de Cloud Storage. El primer paso es crear un bucket de Cloud Storage para almacenar tus imágenes.
-
En el menú de navegación, selecciona Cloud Storage > Buckets. Junto a Buckets, haz clic en Crear.
-
Establece un nombre único para el bucket: -bucket.
-
Luego de hacerlo, haz clic en Elige cómo controlar el acceso a los objetos.
-
Desmarca la casilla de verificación Aplicar la prevención de acceso público a este bucket y selecciona el botón de selección Detallado.
Todos los otros parámetros de configuración de tu bucket pueden quedar con sus valores predeterminados.
- Haz clic en Crear.
Sube una imagen a tu bucket
- Haz clic con el botón derecho en la siguiente imagen de donas. Luego, haz clic en Guardar imagen como y guárdala en tu computadora como donuts.png.

- Ve al bucket que acabas de crear, haz clic en Subir > Subir archivos, selecciona donuts.png y, luego, haz clic en Abrir.
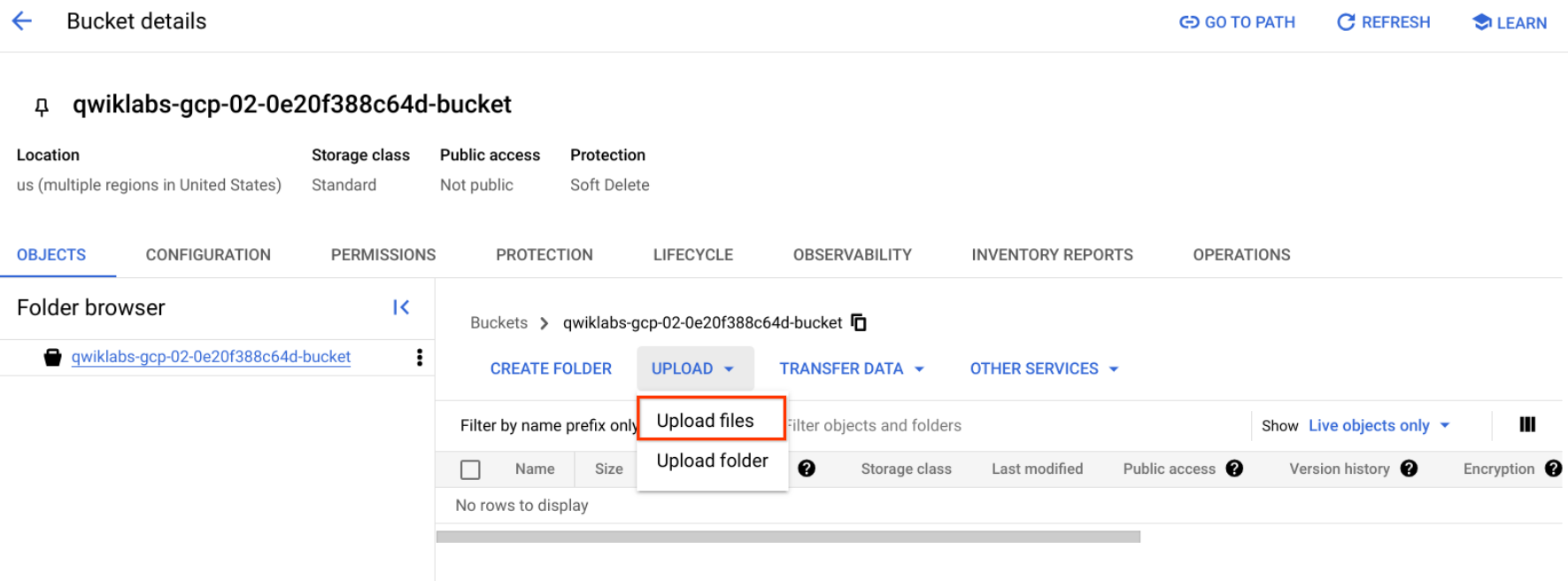
Deberías ver el archivo en tu bucket.
Ahora, debes hacer que esta imagen esté disponible al público.
- Haz clic en los 3 puntos de tu imagen y selecciona Acceso de edición.
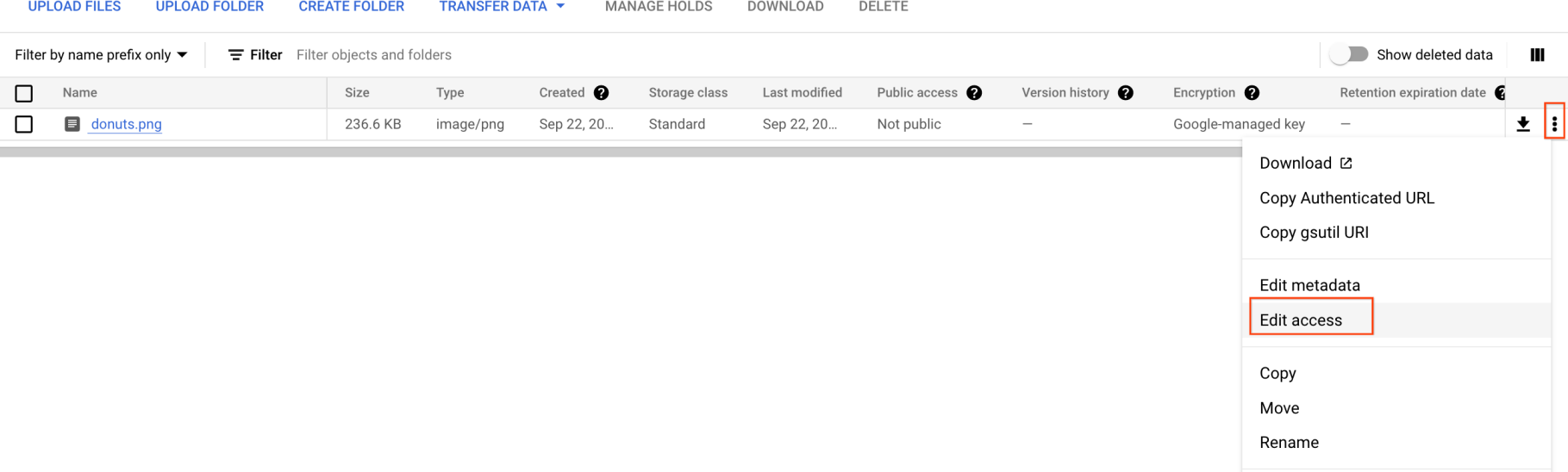
-
Haz clic en Agregar entrada y luego escribe lo siguiente:
-
Entidad: Pública
-
Nombre: allUsers
-
Acceso: Lector
-
Luego, haz clic en Guardar.
Ahora que el archivo está en tu bucket, está todo listo para que crees una solicitud a la API de Cloud Vision y pasarle la URL de esta foto de donas.
Haz clic en Revisar mi progreso para verificar tu progreso en el lab.
Subir una imagen a tu bucket
Tarea 3: Crea tu solicitud
Crea un archivo request.json en el directorio principal de Cloud Shell.
- Con el editor de código de Cloud Shell (haciendo clic en el ícono de lápiz en la cinta de Cloud Shell)

o con tu editor de línea de comandos preferido (nano, vim o emacs), crea un archivo request.json.
- Pega el siguiente código en el archivo
request.json:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}
-
Guarda el archivo.
Habilita Gemini Code Assist en el IDE de Cloud Shell
Puedes usar Gemini Code Assist en un entorno de desarrollo integrado (IDE) como Cloud Shell para recibir orientación sobre el código o resolver problemas con tu código. Antes de comenzar a usar Gemini Code Assist, debes habilitarlo.
- En Cloud Shell, habilita la API de Gemini for Google Cloud con el siguiente comando:
gcloud services enable cloudaicompanion.googleapis.com
- En la barra de herramientas de Cloud Shell, haz clic en Abrir editor.
Nota: Para abrir el editor de Cloud Shell, haz clic en Abrir editor en la barra de herramientas de Cloud Shell. Para cambiar entre Cloud Shell y el editor de código, haz clic en Abrir editor o Abrir terminal, según sea necesario.
-
En el panel izquierdo, haz clic en el ícono de Configuración y, luego, en la vista Configuración, busca Gemini Code Assist.
-
Busca la opción Geminicodeassist: Habilitar y asegúrate de que esté seleccionada. Luego, cierra la Configuración.
-
Haz clic en Cloud Code - Sin proyecto en la barra de estado, en la parte inferior de la pantalla.
-
Autoriza el complemento según las instrucciones. Si no se selecciona un proyecto automáticamente, haz clic en Seleccionar un proyecto de Google Cloud y elige .
-
Verifica que tu proyecto de Google Cloud () se muestre en el mensaje de la barra de estado de Cloud Code.
Tarea 4: Realiza la detección de etiquetas
La primera función de la API de Cloud Vision que explorarás es la detección de etiquetas. El método que usas devuelve una lista de etiquetas (palabras) de lo que hay en tu imagen.
- En la terminal de Cloud Shell, ejecuta el siguiente comando
curl para llamar a la API de Cloud Vision y guardar la respuesta en el archivo label_detection.json:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY} -o label_detection.json && cat label_detection.json
Tu respuesta debería ser similar al siguiente ejemplo:
Resultado:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "Powdered sugar",
"score": 0.9861496,
"topicality": 0.9861496
},
{
"mid": "/m/01wydv",
"description": "Beignet",
"score": 0.9565117,
"topicality": 0.9565117
},
{
"mid": "/m/02wbm",
"description": "Food",
"score": 0.9424965,
"topicality": 0.9424965
},
{
"mid": "/m/0hnyx",
"description": "Pastry",
"score": 0.8173416,
"topicality": 0.8173416
},
{
"mid": "/m/02q08p0",
"description": "Dish",
"score": 0.8076026,
"topicality": 0.8076026
},
{
"mid": "/m/01ykh",
"description": "Cuisine",
"score": 0.79036003,
"topicality": 0.79036003
},
{
"mid": "/m/03nsjgy",
"description": "Kourabiedes",
"score": 0.77726763,
"topicality": 0.77726763
},
{
"mid": "/m/06gd3r",
"description": "Angel wings",
"score": 0.73792106,
"topicality": 0.73792106
},
{
"mid": "/m/06x4c",
"description": "Sugar",
"score": 0.71921736,
"topicality": 0.71921736
},
{
"mid": "/m/01zl9v",
"description": "Zeppole",
"score": 0.7111677,
"topicality": 0.7111677
}
]
}
]
}
La API pudo identificar el tipo específico de donas, con azúcar en polvo. Genial. Por cada etiqueta que la API de Vision encuentra, muestra lo siguiente:
-
description con el nombre del elemento.
-
score, un número entre 0 y 1 que indica qué tan seguro es que la descripción coincida con lo que está en la imagen.
- valor
mid que se asigna al mid del elemento en el Gráfico de conocimiento de Google. Puedes utilizar el mid cuando llamas a la API de Gráfico de conocimiento para obtener más información sobre el elemento.
- En el editor de Cloud Shell, ve a
label_detection.json. Esta acción habilita Gemini Code Assist, como lo indica la presencia del ícono  en la esquina superior derecha del editor.
en la esquina superior derecha del editor.
Para ayudarte a aumentar la productividad y, al mismo tiempo, minimizar el cambio de contexto, Gemini Code Assist proporciona acciones inteligentes potenciadas por IA directamente en tu editor de código. En esta sección, decides pedirle a Gemini Code Assist que te ayude a explicarle la respuesta de la Cloud Vision API a un miembro del equipo.
-
Haz clic en el ícono Gemini Code Assist: Smart Actions y selecciona Explicar esto.
-
Gemini Code Assist abre un panel de chat con la instrucción Explicar esto completada previamente. En el cuadro de texto intercalado del chat de Code Assist, reemplaza el prompt completado previamente por lo siguiente y haz clic en Enviar:
You are a Machine Learning Engineer at Cymbal AI. A new team member needs help understanding this Cloud Vision API response. Explain the label_detection.json file in detail. Break down its key components and their function within the JSON code.
For the suggested improvements, don't make any changes to the file's content.
Las explicaciones detalladas de la respuesta de la API de Cloud Vision en el código label_detection.json aparecen en el chat de Gemini Code Assist.
Tarea 5: Realiza la detección web
Además de obtener etiquetas sobre lo que hay en tu imagen, la API de Cloud Vision puede realizar búsquedas en Internet para obtener detalles adicionales sobre tu imagen. A través del método de detección de Web de la API, recibes mucha información interesante:
- Una lista de entidades encontradas en tu imagen según el contenido de páginas con imágenes similares
- URLs de imágenes que coinciden total o parcialmente y que fueron encontradas en la Web, junto con las URLs de dichas páginas
- URLs de imágenes similares, como realizar una búsqueda de imagen inversa
Para probar la detección de Web, usa la misma imagen de beignets y cambia una línea en el archivo request.json (también puedes aventurarte en lo desconocido y utilizar una imagen completamente diferente).
-
En el editor de Cloud Shell, navega a request.json y ábrelo en el mismo directorio.
-
Haz clic en el ícono Gemini Code Assist: Smart Actions en la barra de herramientas.
Además de proporcionar explicaciones detalladas del código, también puedes usar las funciones potenciadas por IA de Gemini Code Assist para realizar cambios en tu código directamente en tu editor de código. En esta instancia, decides dejar que Gemini Code Assist te ayude a editar el contenido del archivo request.json.
- Para editar el archivo
request.json, pega el siguiente prompt en el campo de texto intercalado de Gemini Code Assist que se abre desde la barra de herramientas.
In the request.json file, update the features list, change type from LABEL_DETECTION to WEB_DETECTION.
-
Para indicarle a Gemini Code Assist que modifique el código según corresponda, presiona INTRO.
-
Cuando se te solicite en la vista Gemini Diff, haz clic en Aceptar.
El contenido del archivo request.json ahora debería ser similar al siguiente:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}
- En la terminal de Cloud Shell, ejecuta el siguiente comando
curl para llamar a la API de Cloud Vision:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Analiza la respuesta, empezando por
webEntities. Estas son algunas de las entidades que mostró esta imagen:
{
"responses": [
{
"webDetection": {
"webEntities": [
{
"entityId": "/m/0z5n",
"score": 0.8868,
"description": "Application programming interface"
},
{
"entityId": "/m/07kg1sq",
"score": 0.3139,
"description": "Encapsulation"
},
{
"entityId": "/m/0105pbj4",
"score": 0.2713,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/01hyh_",
"score": 0.2594,
"description": "Machine learning"
},
...
]
Esta imagen se usó en muchas presentaciones en las APIs de Cloud ML, razón por la cual la API encontró las entidades “Aprendizaje automático” y “Google Cloud Platform”.
Si inspeccionas las URLs que se encuentran en fullMatchingImages, partialMatchingImages y pagesWithMatchingImages, notarás que muchas de las URLs apuntan al sitio de este lab (¡qué coincidencia!).
Supongamos que quieres encontrar otras imágenes de beignets, pero no exactamente las mismas. Aquí es donde resulta útil la parte visuallySimilarImages de la respuesta de la API. Estas son algunas de las imágenes visualmente similares que encontró:
"visuallySimilarImages": [
{
"url": "https://media.istockphoto.com/photos/cafe-du-monde-picture-id1063530570?k=6&m=1063530570&s=612x612&w=0&h=b74EYAjlfxMw8G-G_6BW-6ltP9Y2UFQ3TjZopN-pigI="
},
{
"url": "https://s3-media2.fl.yelpcdn.com/bphoto/oid0KchdCqlSqZzpznCEoA/o.jpg"
},
{
"url": "https://s3-media1.fl.yelpcdn.com/bphoto/mgAhrlLFvXe0IkT5UMOUlw/348s.jpg"
},
...
]
Puedes navegar a esas URLs para ver las imágenes similares:



Y, ahora, probablemente tengas muchas ganas de un beignet con azúcar en polvo (¡perdón!). Esto es parecido a buscar por una imagen en Google Imágenes.
Con Cloud Vision, puedes acceder a esta funcionalidad con una API de REST fácil de usar y, a su vez, integrarla a tus aplicaciones.
Tarea 6: Realiza la detección de rostros
A continuación, explora los métodos de detección de rostros de la API de Vision.
El método de detección de rostros muestra datos de rostros encontrados en una imagen, que incluyen las emociones de los rostros y su ubicación en la imagen.
Sube una imagen nueva
Para utilizar este método, deberás subir una imagen nueva con rostros al bucket de Cloud Storage.
- Haz clic con el botón derecho en la siguiente imagen. Luego, haz clic en Guardar imagen como y guárdala en tu computadora como selfie.png.

- Ahora, súbela a tu bucket de Cloud Storage del mismo modo en que lo hiciste antes y hazla pública.
Haz clic en Revisar mi progreso para verificar tu progreso en el lab.
Subir una imagen para la detección de rostro a tu bucket
Actualiza el archivo de solicitud
-
En el editor de Cloud Shell, navega a request.json en el mismo directorio.
-
Haz clic en el ícono Gemini Code Assist: Smart Actions en la barra de herramientas.
-
Para ayudarte a actualizar tu archivo request.json, pega el siguiente prompt en el campo de texto intercalado de Gemini Code Assist que se abre desde la barra de herramientas.
Update the JSON file request.json to achieve three specific changes:
* Update the gcsImageUri value from donuts.png to selfie.png.
* Replace the existing features array with two new feature types: FACE_DETECTION and LANDMARK_DETECTION.
* Don't want maxResults result.
-
Para indicarle a Gemini Code Assist que modifique el código según corresponda, presiona INTRO.
-
Cuando se te solicite en la vista Gemini Diff, haz clic en Aceptar.
Tu archivo de solicitud actualizado debería ser similar al siguiente:
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}
Llama a la API de Vision y analiza la respuesta
- En la terminal de Cloud Shell, ejecuta el siguiente comando
curl para llamar a la API de Cloud Vision:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Revisa el objeto
faceAnnotations en la respuesta. Notarás que la API muestra un objeto para cada rostro encontrado en la imagen (en este caso, tres). Aquí puedes ver una versión reducida de la respuesta:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "LIKELY",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}
-
boundingPoly te proporciona las coordenadas x,y alrededor del rostro en la imagen.
-
fdBoundingPoly es una caja más pequeña que boundingPoly y se enfoca en la parte de la piel del rostro.
-
landmarks es un arreglo de objetos para cada rasgo facial, algunos de los cuales puede que no conozcas. Esto nos indica el tipo de punto de referencia, junto con la posición 3D de ese rasgo (coordenadas x,y,z), en el que la coordenada z es la profundidad. Los valores restantes te proporcionan detalles sobre el rostro, incluida la probabilidad de alegría, tristeza, enojo y sorpresa.
La respuesta que estás leyendo es para la persona que se encuentra más atrás en la imagen: puedes ver que está haciendo una especie de gesto gracioso que explica la joyLikelihood de LIKELY.
Tarea 7: Realiza anotaciones de puntos de referencia
La detección de punto de referencia puede identificar puntos de referencia comunes (y desconocidos). Muestra el nombre del punto de referencia, las coordenadas de latitud y longitud, y la ubicación donde se identificó el punto de referencia en una imagen.
Sube una imagen nueva
Para utilizar este método, deberás subir una imagen nueva al bucket de Cloud Storage.
- Haz clic con el botón derecho en la siguiente imagen. Luego, haz clic en Guardar imagen como y guárdala en tu computadora como city.png.

Cita: Catedral de San Basilio, Moscú, Rusia (19 de diciembre de 2019), por Adrien Wodey en Unsplash, el repositorio de medios gratuito. Disponible en https://unsplash.com/photos/multicolored-dome-temple-yjyWCNx0J1U. Este archivo tiene la licencia de Unsplash.
- Ahora, súbela a tu bucket de Cloud Storage del mismo modo en que lo hiciste antes y hazla pública.
Haz clic en Revisar mi progreso para verificar tu progreso en el lab.
Subir una imagen para anotación de puntos de referencia a tu bucket
Actualiza el archivo de solicitud
- A continuación, actualiza tu archivo
request.json con la siguiente información, lo que incluye la URL de la nueva imagen, y utiliza la detección de puntos de referencia.
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://{{{project_0.project_id | PROJECT_ID}}}-bucket/city.png"
}
},
"features": [
{
"type": "LANDMARK_DETECTION",
"maxResults": 10
}
]
}
]
}
Llama a la API de Vision y analiza la respuesta
- En la terminal de Cloud Shell, ejecuta el siguiente comando
curl para llamar a la API de Cloud Vision:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Observa la parte
landmarkAnnotations de la respuesta:
"landmarkAnnotations": [
{
"mid": "/m/0hm_7",
"description": "Red Square",
"score": 0.8557956,
"boundingPoly": {
"vertices": [
{},
{
"x": 503
},
{
"x": 503,
"y": 650
},
{
"y": 650
}
]
},
"locations": [
{
"latLng": {
"latitude": 55.753930299999993,
"longitude": 37.620794999999994
}
...
La API de Cloud Vision pudo identificar dónde se tomó la fotografía y brinda coordenadas geográficas de la ubicación (Catedral de San Basilio en la Plaza Roja de Moscú, Rusia).
Los valores en esta respuesta deberían ser similares a la respuesta labelAnnotations anterior:
- el
mid del punto de referencia
- su nombre (
description)
- un
score de confianza
-
boundingPoly muestra la zona de la imagen donde se identificó el punto de referencia
- la clave
locations nos proporciona las coordenadas de latitud y longitud de la imagen
Tarea 8: Realiza la localización de objetos
La API de Vision puede detectar y extraer varios objetos en una imagen con la localización de objetos. La localización de objetos permite identificar varios objetos en una imagen y proporciona una LocalizedObjectAnnotation para cada objeto en ella. Cada LocalizedObjectAnnotation identifica la información sobre el objeto, su posición y los límites rectangulares para la región de la imagen que contiene el objeto.
La localización de objetos identifica objetos importantes y menos destacados en una imagen.
La información del objeto se muestra solo en inglés. Cloud Translation puede traducir etiquetas en inglés a varios idiomas.
Para usar este método, utilizarás una imagen existente en Internet y actualizarás el archivo request.json.
Actualiza el archivo de solicitud
- Actualiza tu archivo
request.json con la siguiente información, que incluye la URL de la imagen nueva, y utiliza la localización de objetos.
{
"requests": [
{
"image": {
"source": {
"imageUri": "https://cloud.google.com/vision/docs/images/bicycle_example.png"
}
},
"features": [
{
"maxResults": 10,
"type": "OBJECT_LOCALIZATION"
}
]
}
]
}
Llama a la API de Vision y analiza la respuesta
- En la terminal de Cloud Shell, ejecuta el siguiente comando
curl para llamar a la API de Cloud Vision:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- Ahora, observa la parte
localizedObjectAnnotations de la respuesta:
{
"responses": [
{
"localizedObjectAnnotations": [
{
"mid": "/m/01bqk0",
"name": "Bicycle wheel",
"score": 0.89648587,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.32076266,
"y": 0.78941387
},
{
"x": 0.43812272,
"y": 0.78941387
},
{
"x": 0.43812272,
"y": 0.97331065
},
{
"x": 0.32076266,
"y": 0.97331065
}
]
}
},
{
"mid": "/m/0199g",
"name": "Bicycle",
"score": 0.886761,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.312,
"y": 0.6616471
},
{
"x": 0.638353,
"y": 0.6616471
},
{
"x": 0.638353,
"y": 0.9705882
},
{
"x": 0.312,
"y": 0.9705882
}
]
}
},
...
Como puedes ver, la API de Vision pudo decir que esta imagen contiene una bicicleta y una rueda de bicicleta. Los valores en esta respuesta deben verse similares a la respuesta de labelAnnotations anterior: el mid del objeto, su nombre (name), una score de confianza y el boundingPoly muestran la región en la imagen donde se identificó el objeto.
Además, el boundingPoly tiene una clave normalizedVertices, que te da las coordenadas del objeto en la imagen. Estas coordenadas están normalizadas en un rango de 0 a 1, en la que 0 representa la parte superior izquierda de la imagen y 1 representa la parte inferior derecha de la imagen.
Perfecto. Usaste de forma correcta la API de Vision para analizar una imagen y extraer información sobre los objetos en la imagen.
Tarea 9: Explora otros métodos de la API de Vision
Analizaste los métodos de localización de objetos, detección de puntos de referencia, rostros y etiquetas de la API de Vision, pero hay otros tres que no has explorado. Analiza el documento Method: images.annotate para conocer estos otros tres métodos:
-
Detección de logotipo: identifica logotipos comunes y su ubicación en la imagen.
-
Búsqueda segura: determina si una imagen incluye contenido explícito o no. Esto es útil para cualquier aplicación con contenido generado por usuarios. Puedes filtrar imágenes en función de cuatro factores: contenido adulto, médico, violento y falso.
-
Detección de texto: ejecuta el OCR para extraer texto de las imágenes. Este método incluso puede identificar el idioma del texto presente en una imagen.
¡Felicitaciones!
Aprendiste a analizar imágenes con la API de Vision. En este lab, pasaste a la API las URLs de Cloud Storage de diferentes imágenes y recuperaste las etiquetas, los rostros, los puntos de referencia y los objetos encontrados en la imagen. Además, puedes pasar a la API un valor de cadena válido codificado en base64, que es útil si deseas analizar una imagen almacenada en una base de datos o en la memoria.
Próximos pasos y más información
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 21 de agosto de 2025
Prueba más reciente del lab: 21 de agosto de 2025
Copyright 2025 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.





