


Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Creating Cloud Storage buckets
/ 20
Creating Cloud Pub/Sub topics
/ 20
Creating Cloud Storage notifications
/ 20
Create the BigQuery dataset and table
/ 10
Deploying the Cloud Run Functions
/ 20
Testing the flow
/ 10
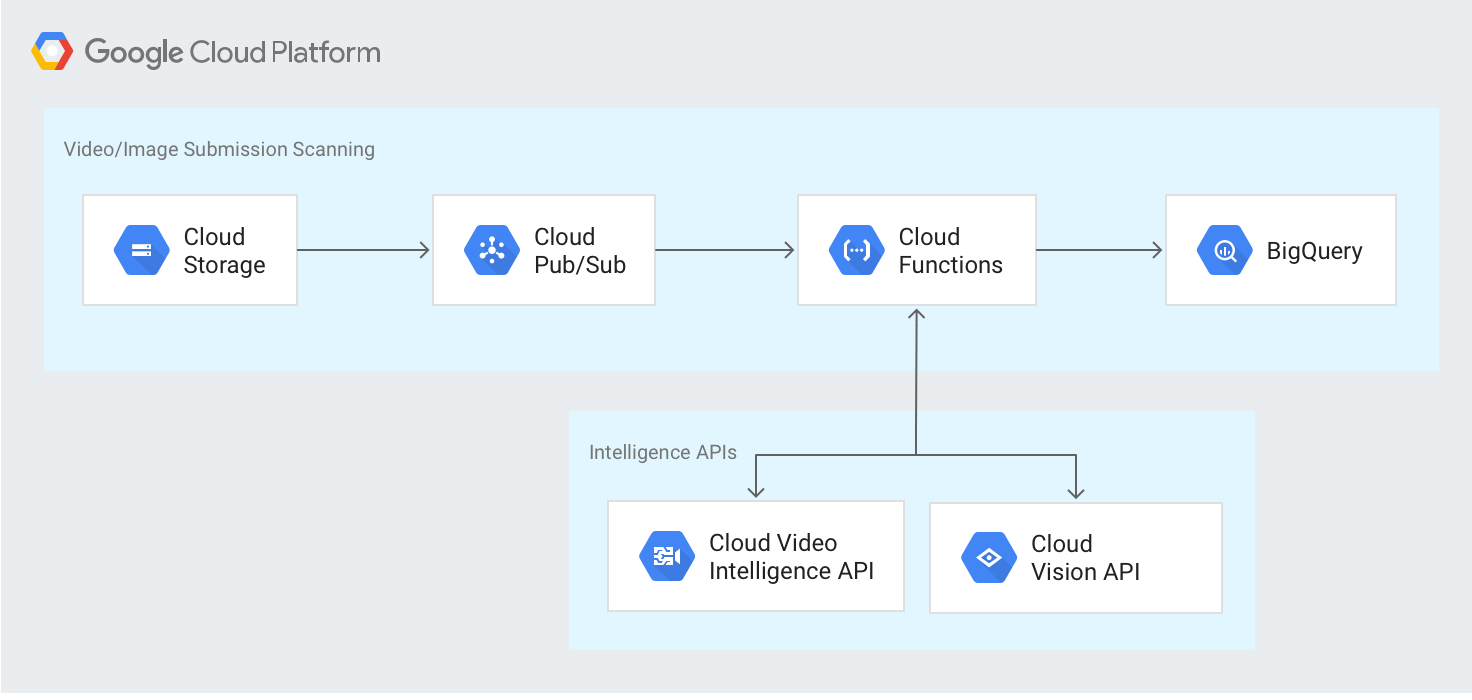
This lab will show you how to deploy a set of Cloud Run functions in order to process images and videos with the Cloud Vision API and Cloud Video Intelligence API.
Social marketing campaigns often invite consumers to submit user-generated images and videos. Campaigns that solicit videos and images often use them for contest submissions, product testimonials, or as user-generated content for public campaign websites. Processing these submissions at scale requires considerable resources.
The Cloud Video Intelligence and Cloud Vision APIs offer you a scalable and serverless way to implement intelligent image and video filtering, accelerating submission processing. If you use the safe-search feature in the Vision API solution and the explicit content detection feature in the Video Intelligence API, you can eliminate images and videos that are identified as unsafe or undesirable content before further processing.
You'll need image and video files that you can upload into the lab for analysis. Ideally they would be of different types - with people whose faces can be seen, no people, landscape, close-ups - so you can see how the image analysis treats the image. You can also just use a single image or video.
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources are made available to you.
This hands-on lab lets you do the lab activities in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
Click the Start Lab button. If you need to pay for the lab, a dialog opens for you to select your payment method. On the left is the Lab Details pane with the following:
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
If necessary, copy the Username below and paste it into the Sign in dialog.
You can also find the Username in the Lab Details pane.
Click Next.
Copy the Password below and paste it into the Welcome dialog.
You can also find the Password in the Lab Details pane.
Click Next.
Click through the subsequent pages:
After a few moments, the Google Cloud console opens in this tab.

Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud. Cloud Shell provides command-line access to your Google Cloud resources.
Click Activate Cloud Shell 
Click through the following windows:
When you are connected, you are already authenticated, and the project is set to your Project_ID,
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
Output:
Output:
gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
The following diagram outlines the high-level architecture:
Prepare for the lab by setting up some environment variables that you'll need in the lab.
-upload, -filtered, -flagged, and -staging to the project ID in order to create a set of globally unique and valid Cloud Storage bucket names that will be used by the lab to process and store the uploaded image and video files. You can override these values with any valid storage bucket names if you prefer.
Cloud Storage buckets provide a storage location for uploading your images and videos. Now you will create four different Cloud Storage buckets.
IV_BUCKET_NAME environment variable:FILTERED_BUCKET_NAME environment variable:FLAGGED_BUCKET_NAME environment variable:STAGING_BUCKET_NAME environment variable:You should see the names of the four storage buckets listed in the output. These will be be in the format [PROJECT-ID]-upload, -filtered, -flagged, and -staging.
Click Check my progress to verify the objective.
Cloud Pub/Sub topics is used for Cloud Storage notification messages and for messages between your Cloud Run functions. This lab has some of the topic names preset to specific defaults which are used in this section for the topic names.
config.json file that is downloaded later as part of the solution.upload_notification and save it in an environment variable since it will be used later:config.json file is visionapiservice:config.json file is videointelligenceservice:config.json file is bqinsert:You should see the names of the four topics listed in the output: upload_notification, visionapiservice, videointelligenceservice and bqinsert.
Click Check my progress to verify the objective.
You'll see this output, if the function succeeds:
Click Check my progress to verify the objective.
The code for the Cloud Run functions used in this lab are available in a public Cloud Storage bucket, defined in the index.js file.
You can examine the source in detail by opening index.js with the editor of your choice to see how each of the functions is implemented.
The results of the Vision and Video Intelligence APIs are stored in BigQuery. The demo solution used in this Qwiklab has default dataset and table names set to intelligentcontentfilter and filtered_content. You can change these values, but if you do you must also make those changes in the config.json file that is downloaded later as part of the solution.
The dataset name is set to intelligentcontentfilter to match the default value in the config.json file.
Now you'll create your BigQuery table from the schema file that is included with the lab. The dataset and table name is set to filtered_content to match the default values in the config.json file and the schema is defined in the file intelligent_content_bq_schema.json.
Resulting output should contain the following:
Click Check my progress to verify the objective.
Before you can deploy the Cloud Run functions defined in the source code, you must modify the config.json file to use your specific Cloud Storage buckets, Cloud Pub/Sub topic names, and BigQuery dataset ID and table name.
sed commands in the Google Cloud shell to make the changes for you:config.json file to replace the placeholders for [PROJECT-ID], [FLAGGED_BUCKET_NAME], [FILTERED_BUCKET_NAME], [DATASET_ID] and [TABLE_NAME] that you can see here with the appropriate values.[FLAGGED_BUCKET_NAME] and [FILTERED_BUCKET_NAME] here must not include the leading gs:// prefix.
The code for the Cloud Run functions used in this lab are available on GitHub, defined in the index.js file. You can examine the source in detail on Github to see how each of the functions is implemented. The deployments can each take a few minutes to complete.
Next you will deploy the GCStoPubsub Cloud Run Function, which contains the logic to receive a Cloud Storage notification message from Cloud Pub/Sub and forward the message to the appropriate function with another Cloud Pub/Sub message.
Type "n" if asked Bind the role to service account [GCStoPubsub]?
Type "Y" if asked Allow unauthenticated invocations of new function [GCStoPubsub]?
The command-line output is similar to the following for each of the four Cloud Run functions:
Deploy your visionAPI Cloud Run Function, which contains the logic to receive a message with Cloud Pub/Sub, call the Vision API, and forward the message to the insertIntoBigQuery Cloud Run Function with another Cloud Pub/Sub message. If you chose to use a different Vision API topic name then change that name here as well.
Allow unauthenticated invocations of new function [GCStoPubsub]?.Deploy your videoIntelligenceAPI Cloud Run Function, which contains the logic to receive a message with Cloud Pub/Sub, call the Video Intelligence API, and forward the message to the insertIntoBigQuery Cloud Run Function with another Cloud Pub/Sub message. If you chose to use a different Video Intelligence API topic name then change that name here as well.
Allow unauthenticated invocations of new function [videoIntelligenceAPI]?
Deploy your insertIntoBigQuery Cloud Run Function, which contains the logic to receive a message with Cloud Pub/Sub and call the BigQuery API to insert the data into your BigQuery table. If you chose to use a different BigQuery topic name then change that name here as well.
Allow unauthenticated invocations of new function [insertIntoBigQuery]?
You should see the names of the four, Cloud Run functions listed in the output: GCStoPubsub, visionAPI, videoIntelligenceAPI and insertintobigquery.
Click Check my progress to verify the objective.
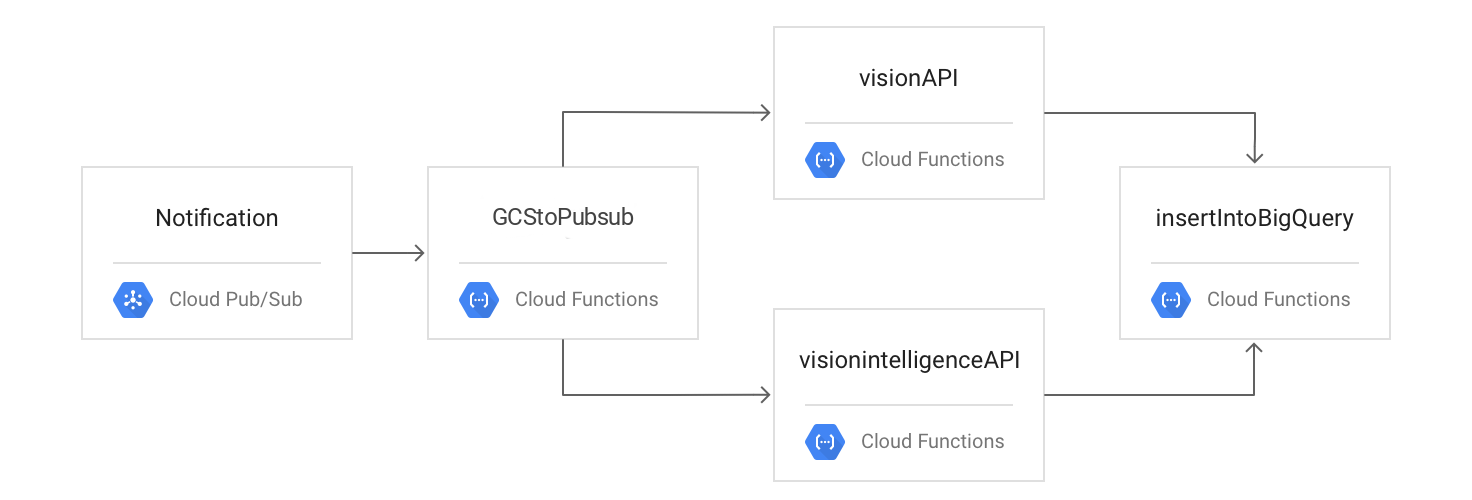
The following diagram outlines the processing flow:
You test the process by uploading your files to Cloud Storage, checking your logs, and viewing your results in BigQuery.
On the Navigation menu (
Click the name of the bucket with the -upload suffix and then click Upload > Upload Files.
Upload some image files and/or video files from your local machine.
Switch back to Cloud Shell to verify that your Cloud Run functions were triggered and ran successfully by viewing the Cloud Run functions logs captured in Cloud Logging.
GCStoPubsub:This command may take a minute or two to complete.
Resulting output:
You will also notice that your uploaded image has been moved to the next bucket as well.
insertIntoBigQuery:Resulting output:
To see your results in BigQuery, you'll create SQL commands to query BigQuery.
[PROJECT_ID], [DATASET_ID], and [TABLE_NAME] with your project ID, dataset ID, and BigQuery table name if you found out that variables created for above doesn't contain correct value:[PROJECT_ID]with your project ID:Resulting output:
Click Check my progress to verify the objective.
Congratulations! You have now successfully completed the Scanning User-Generated Content using the Cloud Video Intelligence and Cloud Vision APIs lab.
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated November 07, 2024
Lab Last Tested November 07, 2024
Copyright 2025 Google LLC. All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one