Getting Started with Elasticsearch on Google Cloud
This lab was developed with our partner, Elastic. Your personal information may be shared with Elastic, the lab sponsor, if you have opted in to receive product updates, announcements, and offers in your Account Profile.
GSP817

Overview
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with a HTTP web interface and schema-free JSON documents.
In this lab you will focus on creating a simple Elasticsearch deployment, leveraging Google Cloud Platform. Once you have created your Elastic cluster you will explore a sample dataset and visualize the data in a dashboard.
Objectives
In this lab, you learn how to perform the following tasks:
- Create an Elasticsearch deployment on the Google Cloud Platform
- Explore data in Elastic through dashboards and more
Prerequisites
This is an introductory lab. No prior knowledge of Elastic and its various products and features are required, though basic system configuration, such as knowing how to run commands via. a Linux based command line, and editing text files using a Unix based text editor is advantageous, i.e. Vim.
Setup and requirements
Before you click the Start Lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- Access to a standard internet browser (Chrome browser recommended).
- Time to complete the lab---remember, once you start, you cannot pause a lab.
How to start your lab and sign in to the Google Cloud console
-
Click the Start Lab button. If you need to pay for the lab, a pop-up opens for you to select your payment method. On the left is the Lab Details panel with the following:
- The Open Google Cloud console button
- Time remaining
- The temporary credentials that you must use for this lab
- Other information, if needed, to step through this lab
-
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account. -
If necessary, copy the Username below and paste it into the Sign in dialog.
{{{user_0.username | "Username"}}} You can also find the Username in the Lab Details panel.
-
Click Next.
-
Copy the Password below and paste it into the Welcome dialog.
{{{user_0.password | "Password"}}} You can also find the Password in the Lab Details panel.
-
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials. Note: Using your own Google Cloud account for this lab may incur extra charges. -
Click through the subsequent pages:
- Accept the terms and conditions.
- Do not add recovery options or two-factor authentication (because this is a temporary account).
- Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.

Activate Cloud Shell
Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud. Cloud Shell provides command-line access to your Google Cloud resources.
- Click Activate Cloud Shell
at the top of the Google Cloud console.
When you are connected, you are already authenticated, and the project is set to your Project_ID,
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
- (Optional) You can list the active account name with this command:
- Click Authorize.
Output:
- (Optional) You can list the project ID with this command:
Output:
gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
Task 1. Elastic - Set up trial account
1.1 Sign up for a free trial.
- Click Start free trial.
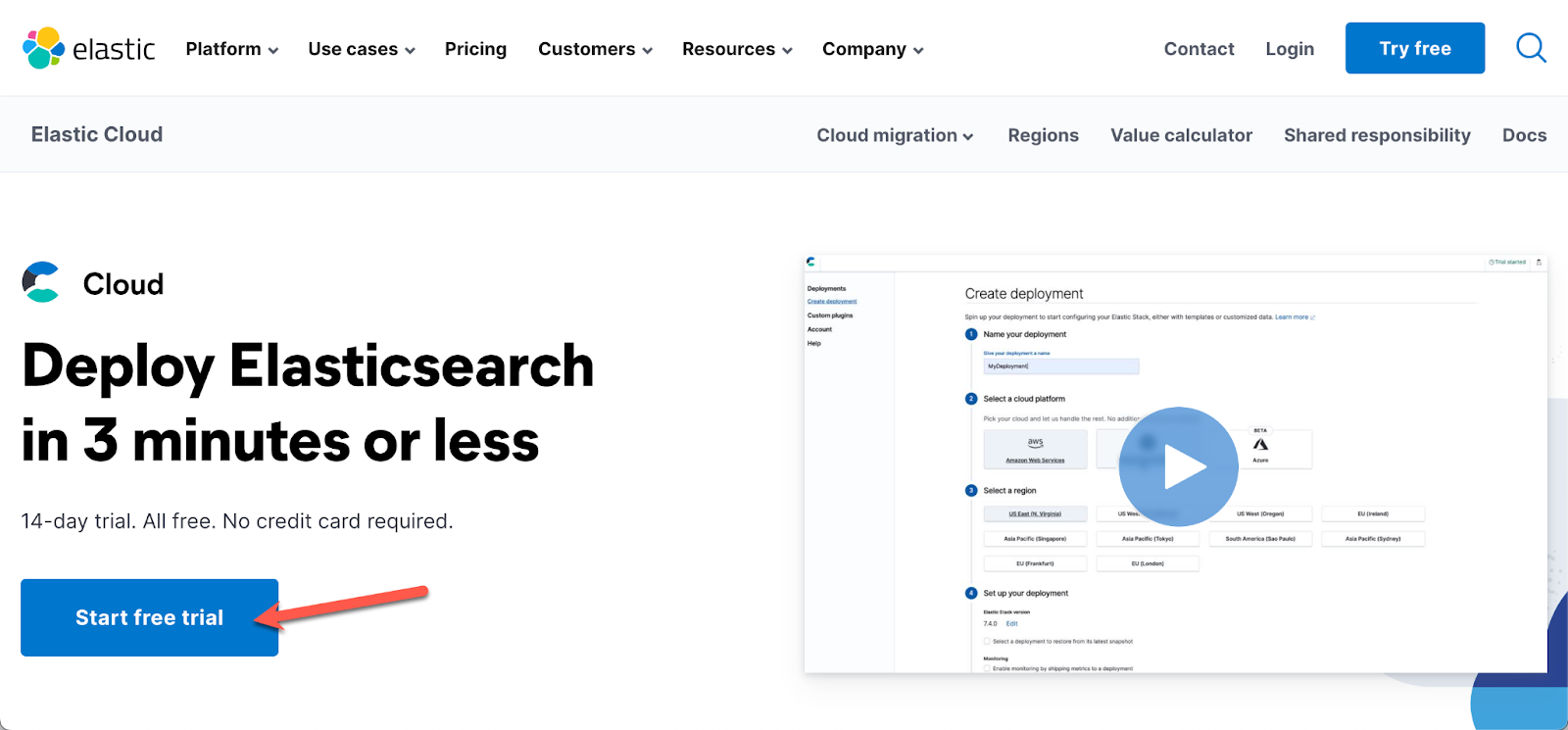
1.1 Sign up using your personal email and a unique password. Do NOT click the "sign up with Google" button, click sign up with Email:

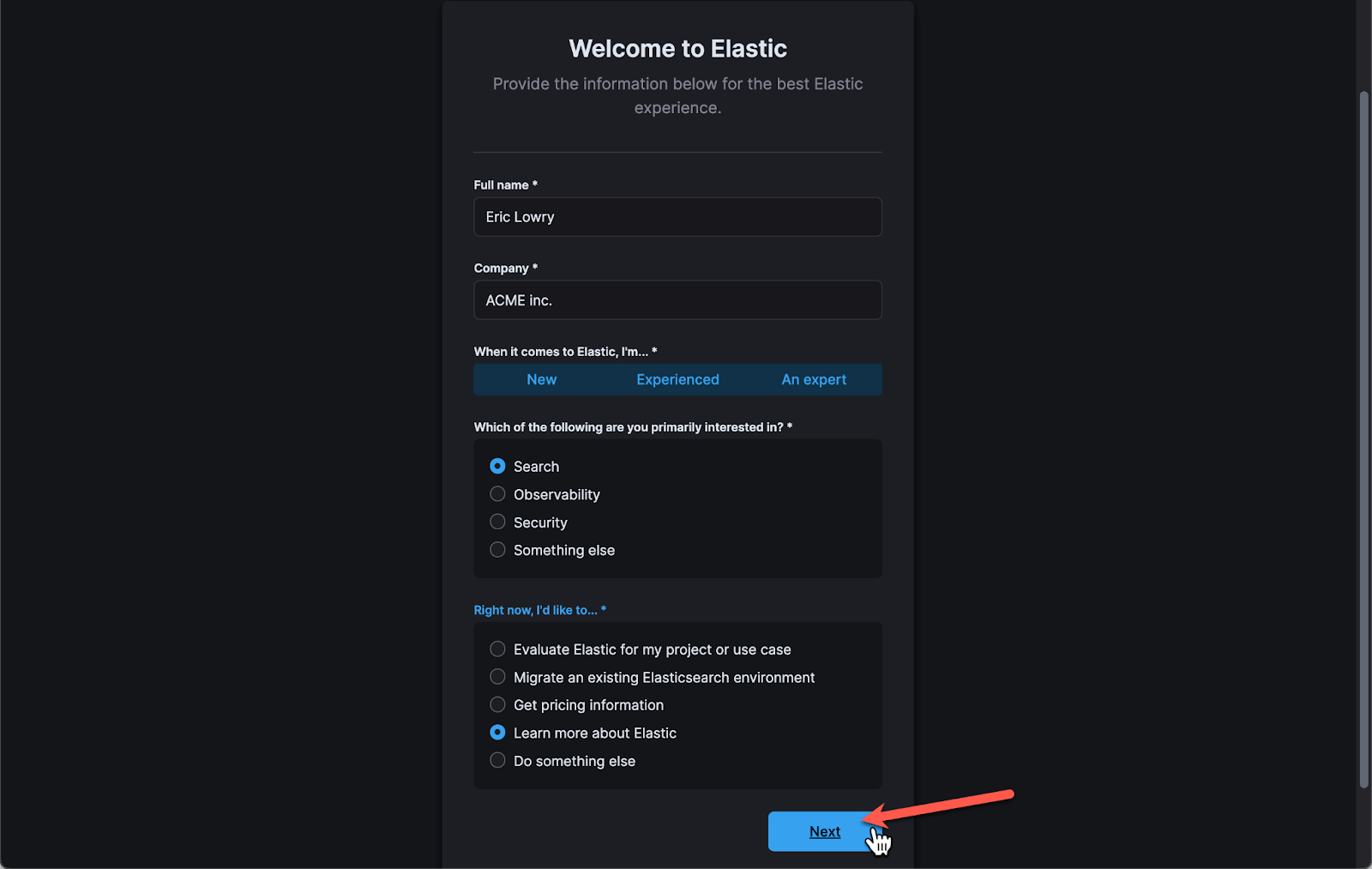
1.2 Enter some details about yourself and click Next.
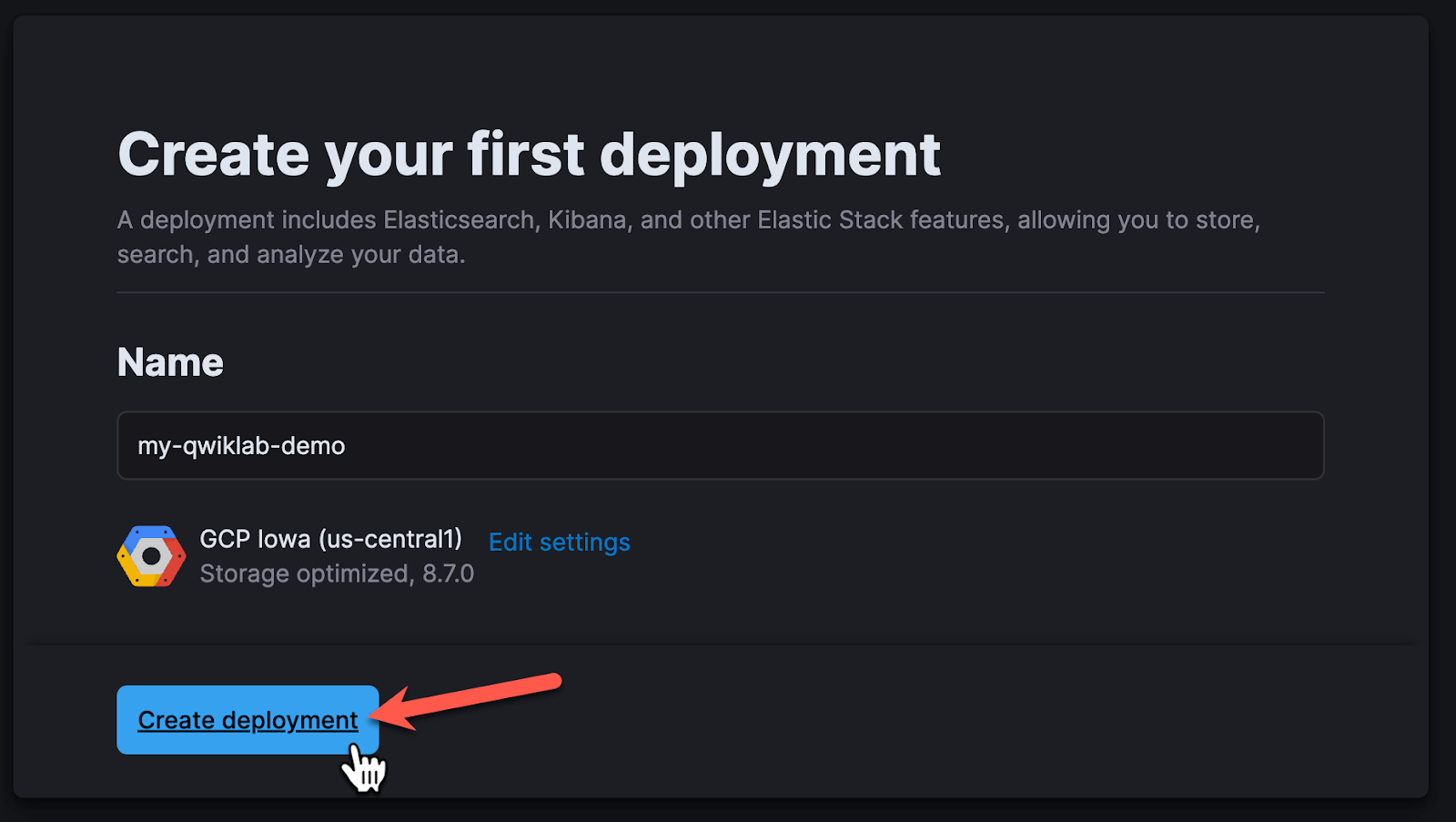
1.3 Provide a unique name to the deployment, and click Create Deployment.
1.4 Save your deployment Credentials, you may need it later.
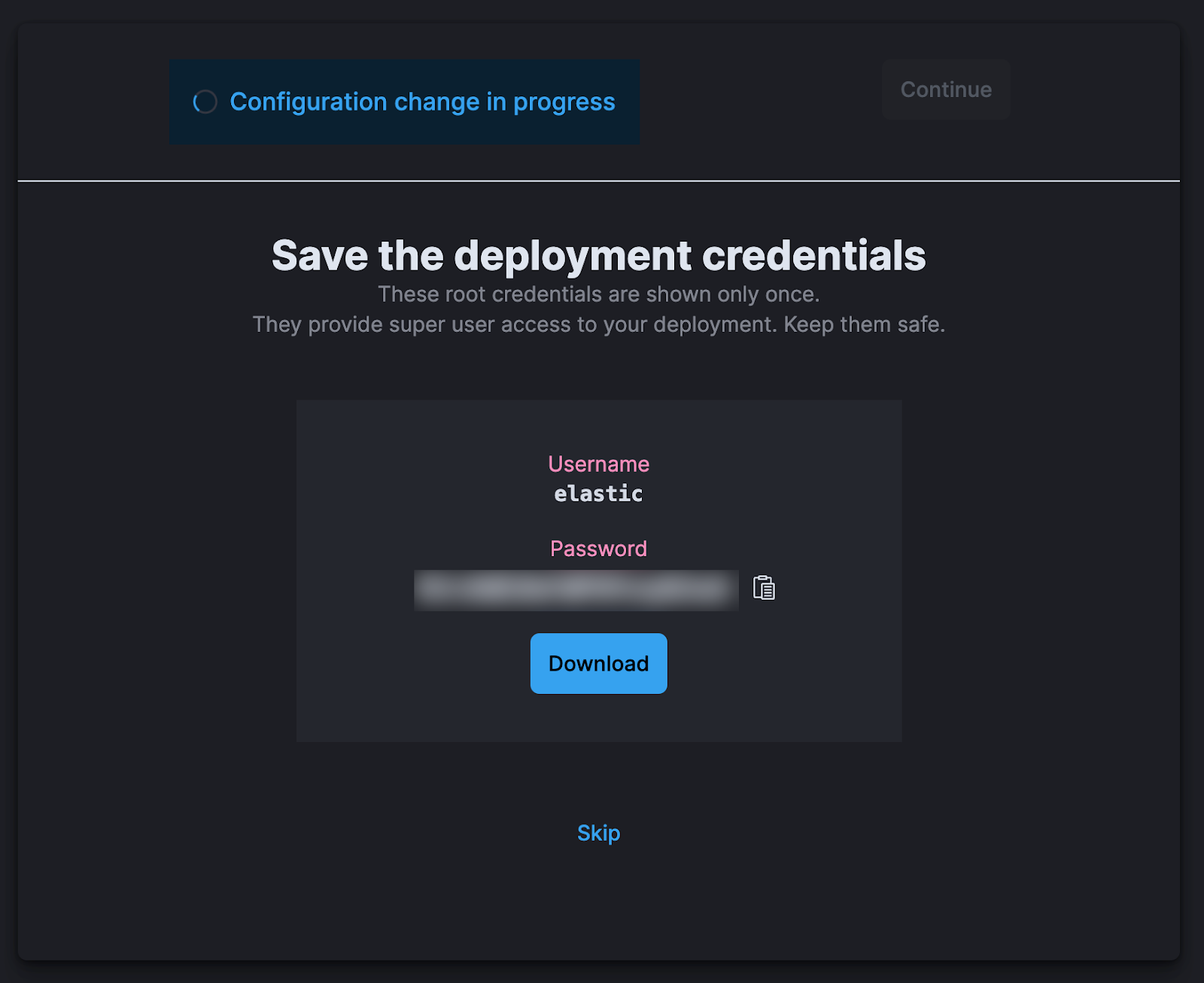
1.5 Click "Continue" to go to your elastic deployment.
Task 2. Elastic - Explore Sample Data
2.1 In the Elastic home page, select "Try Sample Data".
2.2 Select "Start exploring".
2.3 Select the use case that is the most relevant to you. The remainder of the lab will follow the "Observability → Log analytics" use case.
2.4 Expand one of the transactions to see the fields you have to work with.
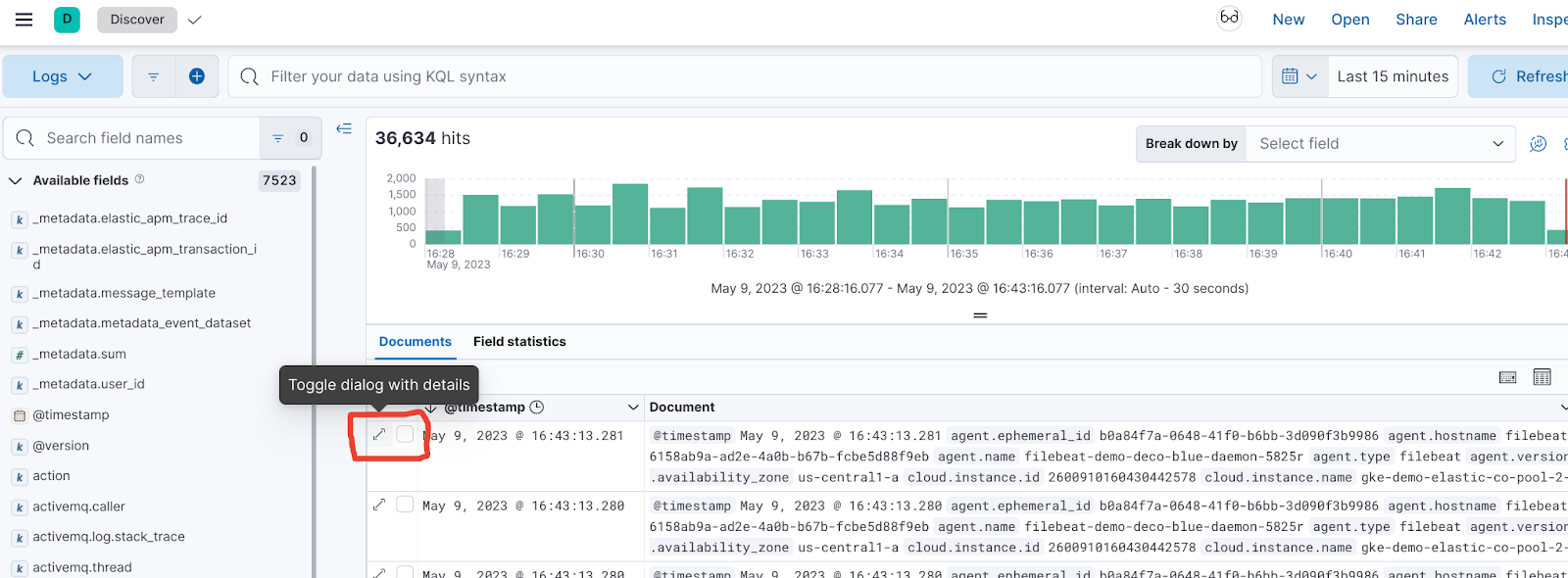
Task 3. Create a Simple Dashboard
3.1 Select the Analytics "Dashboard".
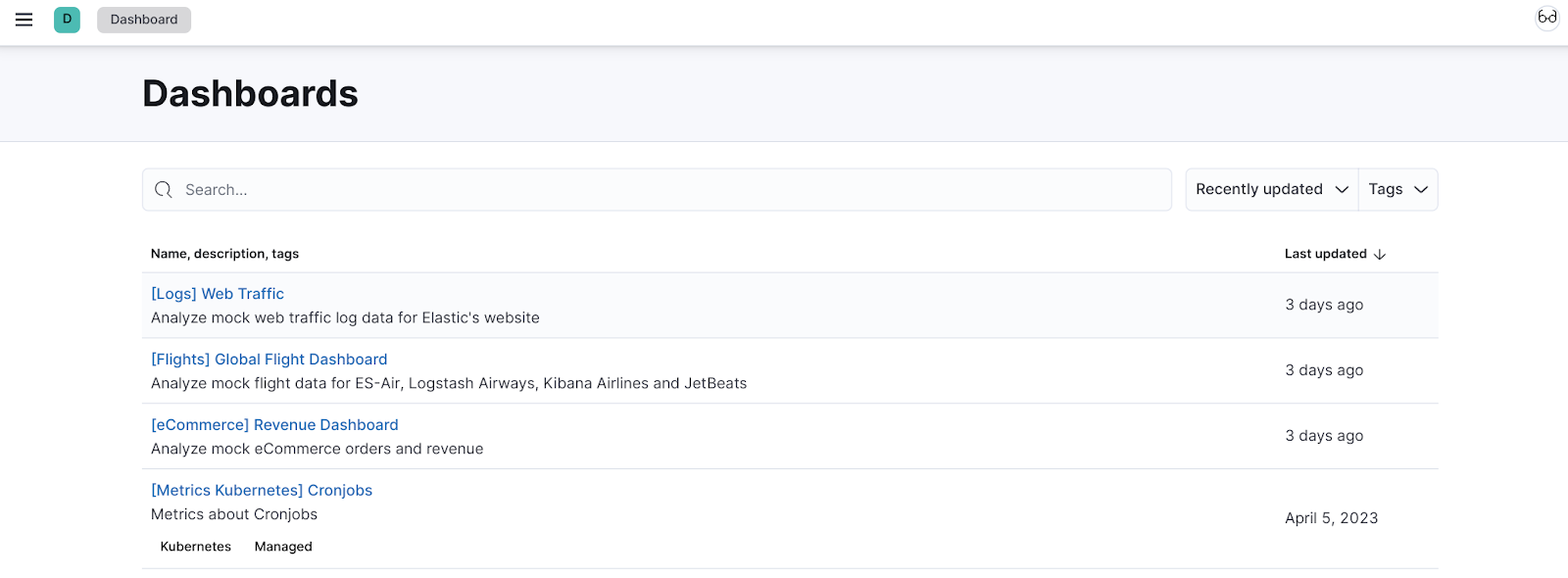
3.2 Select the Dashboard that is the most relevant to you. This lab will use the "[Logs] Web Traffic dashboard".
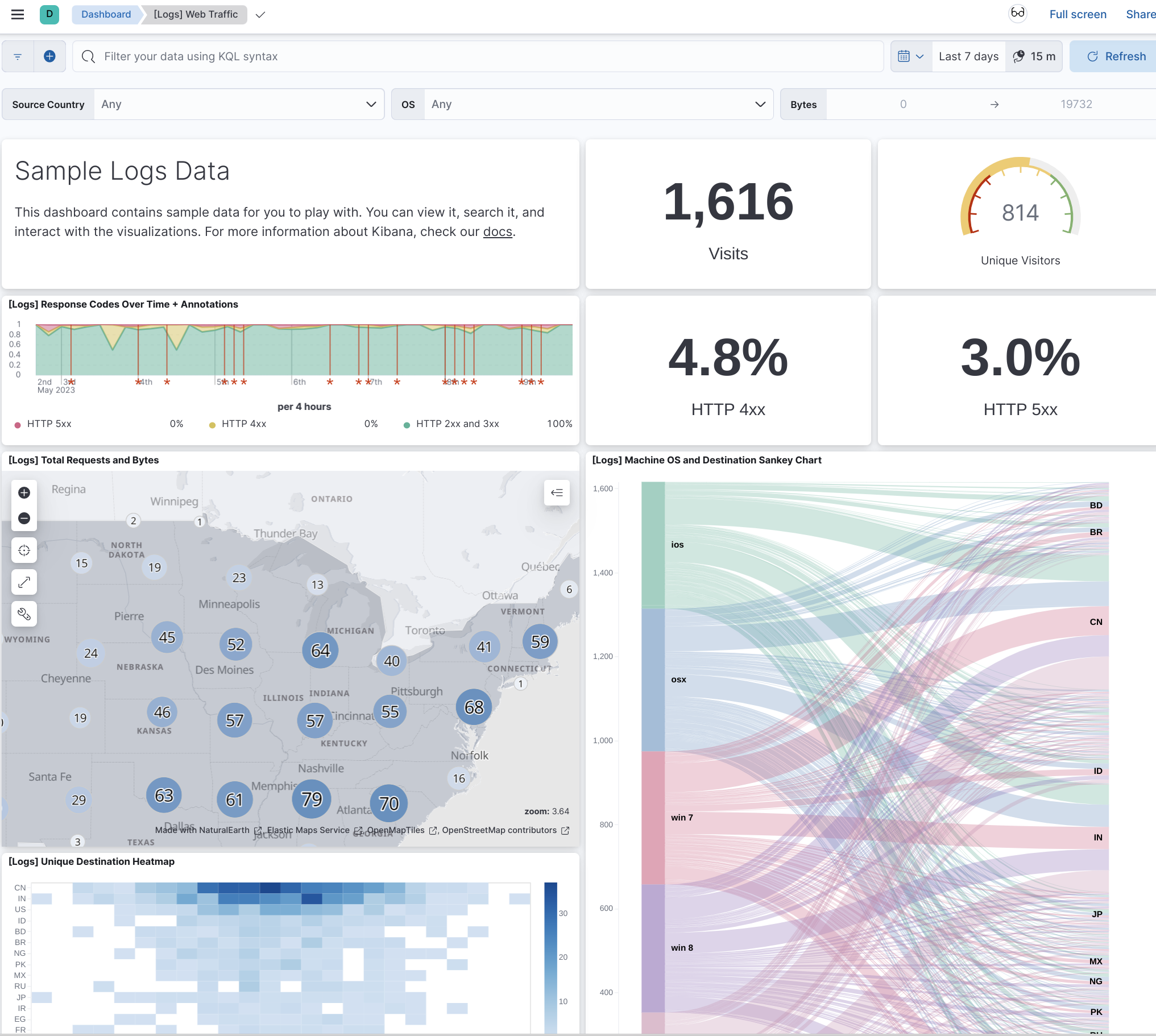
3.3 Explore the dashboard and customize it
Congratulations!
In this lab, you have created an Elasticsearch deployment on the Google Cloud Platform and explored data in Elastic through dashboards.
Next steps / Learn more
- Elastic on the Google Cloud Marketplace!
- Elastic Cloud offers a fully managed experience so that you can focus on your data instead of managing the cluster. You can check it out here and play with a free trial.
- Check out the Elastic Integrations page and see how easily you can stream in logs, metrics, traces, content, and more from your apps, endpoints, infrastructure, cloud, network, workplace tools, and every other common source in your ecosystem.
- Leverage the out-of-the-box solutions to give your Elastic project a jump start!
Google Cloud training and certification
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated October 11, 2023
Lab Last Tested October 11, 2023
Copyright 2024 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.