GSP246

總覽
BigQuery 是 Google 提供的全代管數據分析資料庫,不但免人工管理,而且價格低廉。您可以使用 BigQuery 查詢 TB 規模的資料,不必管理基礎架構,也不需要資料庫管理員。
BigQuery ML 讓資料分析師只需編寫少量程式碼,就能建立、訓練、評估機器學習模型,並將模型用於預測結果。
在本實驗室中,您將使用 BigQuery 公開資料集,運用當中數百萬筆的紐約市黃色計程車載客資料,在 BigQuery 建立機器學習模型。接著您將輸入指令,使用模型來預測計程車車資,並評估模型的預測成效。
實驗室內容
本實驗室將說明如何執行下列工作:
- 使用 BigQuery 尋找公開資料集
- 查詢及探索公開計程車資料集
- 建立訓練和評估資料集,供批次預測使用
- 在 BigQuery ML 建立預測 (線性迴歸) 模型
- 評估機器學習模型的成效
設定和需求
瞭解以下事項後,再點選「Start Lab」按鈕
請詳閱以下操作說明。實驗室活動會計時,且中途無法暫停。點選「Start Lab」後就會開始計時,顯示可使用 Google Cloud 資源的時間。
您將在真正的雲端環境完成實作實驗室活動,而不是模擬或示範環境。為此,我們會提供新的暫時憑證,供您在實驗室活動期間登入及存取 Google Cloud。
為了順利完成這個實驗室,請先確認:
- 可以使用標準的網際網路瀏覽器 (Chrome 瀏覽器為佳)。
注意事項:請使用無痕模式 (建議選項) 或私密瀏覽視窗執行此實驗室,這可以防止個人帳戶和學員帳戶之間的衝突,避免個人帳戶產生額外費用。
- 是時候完成實驗室活動了!別忘了,活動一旦開始將無法暫停。
注意事項:務必使用實驗室專用的學員帳戶。如果使用其他 Google Cloud 帳戶,可能會產生額外費用。
如何開始研究室及登入 Google Cloud 控制台
-
點選「Start Lab」按鈕。如果實驗室會產生費用,畫面上會出現選擇付款方式的對話方塊。左側的「Lab Details」窗格會顯示下列項目:
- 「Open Google Cloud console」按鈕
- 剩餘時間
- 必須在這個研究室中使用的臨時憑證
- 完成這個實驗室所需的其他資訊 (如有)
-
點選「Open Google Cloud console」;如果使用 Chrome 瀏覽器,也能按一下滑鼠右鍵,選取「在無痕視窗中開啟連結」。
接著,實驗室會啟動相關資源,並開啟另一個分頁,顯示「登入」頁面。
提示:您可以在不同的視窗中並排開啟分頁。
注意:如果頁面中顯示「選擇帳戶」對話方塊,請點選「使用其他帳戶」。
-
如有必要,請將下方的 Username 貼到「登入」對話方塊。
{{{user_0.username | "Username"}}}
您也可以在「Lab Details」窗格找到 Username。
-
點選「下一步」。
-
複製下方的 Password,並貼到「歡迎使用」對話方塊。
{{{user_0.password | "Password"}}}
您也可以在「Lab Details」窗格找到 Password。
-
點選「下一步」。
重要事項:請務必使用實驗室提供的憑證,而非自己的 Google Cloud 帳戶憑證。
注意:如果使用自己的 Google Cloud 帳戶來進行這個實驗室,可能會產生額外費用。
-
按過後續的所有頁面:
- 接受條款及細則。
- 由於這是臨時帳戶,請勿新增救援選項或雙重驗證機制。
- 請勿申請免費試用。
Google Cloud 控制台稍後會在這個分頁開啟。
注意:如要使用 Google Cloud 產品和服務,請點選「導覽選單」,或在「搜尋」欄位輸入服務或產品名稱。
開啟 BigQuery 控制台
- 在 Google Cloud 控制台中,依序選取「導覽選單」>「BigQuery」。
接著,畫面中會顯示「歡迎使用 Cloud 控制台中的 BigQuery」訊息方塊,當中會列出快速入門導覽課程指南的連結和版本資訊。
- 點選「完成」。
BigQuery 控制台會隨即開啟。
工作 1:探索紐約市計程車資料
問:2015 年黃色計程車每月載客次數是多少?
- 複製下列 SQL 程式碼,並貼入查詢編輯器:
#standardSQL
SELECT
TIMESTAMP_TRUNC(pickup_datetime,
MONTH) month,
COUNT(*) trips
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
GROUP BY
1
ORDER BY
1
- 然後點選「執行」。
畫面上會顯示下列結果:
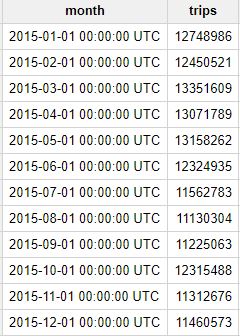
如資料表所示,2015 年紐約市計程車每月載客次數都超過 1,000 萬次,非常驚人!
測試已完成的工作
點選「Check my progress」確認工作已完成。如果順利完成,就會看見評估分數。
計算 2015 年黃色計程車每月載客次數
問:2015 年黃色計程車載客的平均車速是多少?
#standardSQL
SELECT
EXTRACT(HOUR
FROM
pickup_datetime) hour,
ROUND(AVG(trip_distance / TIMESTAMP_DIFF(dropoff_datetime,
pickup_datetime,
SECOND))*3600, 1) speed
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
WHERE
trip_distance > 0
AND fare_amount/trip_distance BETWEEN 2
AND 10
AND dropoff_datetime > pickup_datetime
GROUP BY
1
ORDER BY
1
畫面上會顯示下列結果:

白天的平均車速約為每小時 11 至 12 英里,但凌晨 5 點的平均車速為每小時 21 英里,幾乎是白天的兩倍。直觀來看,這很合理,因為凌晨 5 點的車流量可能較少。
測試已完成的工作
點選「Check my progress」確認工作已完成。如果順利完成,就會看見評估分數。
計算 2015 年黃色計程車載客的平均車速
工作 2:確定目標
接下來,您將使用歷來的載客資料集和資料,在 BigQuery 建立機器學習模型,預測紐約市計程車車資。對於乘客和計程車行來說,事先預測車資有助於規劃行程。
工作 3:選取特徵並建立訓練資料集
「紐約市黃色計程車」資料集是該市提供的公開資料集,已載入 BigQuery 供使用者運用。
請瀏覽完整欄位清單,然後預覽資料集,找出有參考價值的特徵,讓機器學習模型能理解歷來載客和車資資料之間的關係。
您的團隊決定將下列欄位做為車資預測模型的輸入資料,看看能否取得理想結果:
- 將查詢換成下列內容:
#standardSQL
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
請注意以上查詢中的幾個重點:
- 查詢的主要部分位於底部 (
SELECT * from taxitrips)。
-
taxitrips 會大量擷取 NYC 資料集內容,而 SELECT 包含用於訓練的特徵和標籤。
-
WHERE 會移除您不想用於訓練的資料。
- 同時
WHERE 也會納入取樣子句,只擷取第 1/1000 的資料。
- 查詢定義了一個名為
TRAIN 的變數,讓您能快速建構 EVAL 獨立資料集。
- 現在您充分瞭解這個查詢的目的了,請點選「執行」。
畫面上會顯示類似下方的結果:
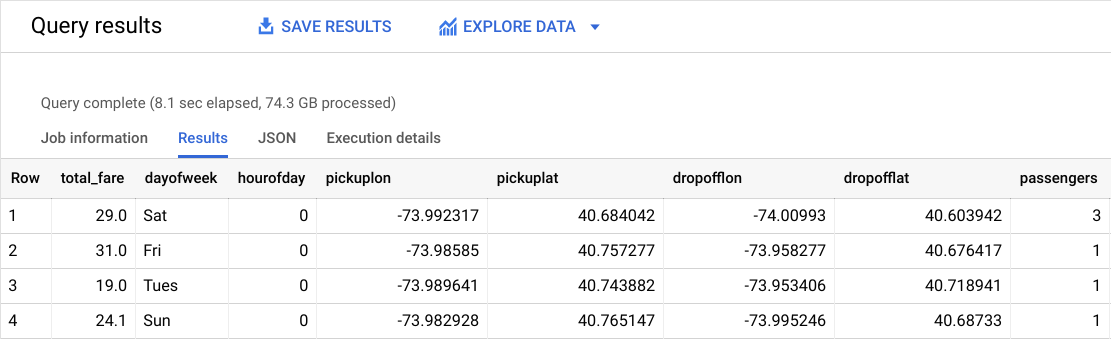
哪項元素是標籤 (正確答案)?
total_fare 是標籤 (預測目標)。這個欄位是根據 tolls_amount 和 fare_amount 建立。小費金額取決於乘客意願,因此可忽略不計,不提供給模型。
測試已完成的工作
點選「Check my progress」確認工作已完成。如果順利完成,就會看見評估分數。
將特定欄位做為車資預測模型的輸入資料,看看能否取得理想結果
工作 4:建立 BigQuery 資料集來儲存模型
在本節中,您將建立新的 BigQuery 資料表來儲存機器學習模型。
-
在左側的「Explorer」窗格中,依序點選專案 ID 旁的「查看動作」圖示和「建立資料集」。
-
在「建立資料集」對話方塊中,輸入下列資訊:
- 在「資料集 ID」部分,輸入 taxi。
- 在「位置類型」部分,選取「美國 (多個美國地區)」。
- 其他設定均保留預設值。
- 接著點選「建立資料集」。
測試已完成的工作
點選「Check my progress」確認工作已完成。如果順利完成,就會看見評估分數。
建立 BigQuery 資料集來儲存模型
工作 5:選取 BigQuery ML 模型類型,並指定選項
您已選取初始特徵,現在可以在 BigQuery 建立第一個機器學習模型。
有數種模型可選擇:
-
預測模型:使用線性迴歸 (linear_reg) 預測數值,例如下個月的銷售量。
-
二元/多類別分類模型:使用邏輯迴歸 (logistic_reg) 進行分類,例如將電子郵件分為垃圾郵件或非垃圾郵件。
-
k-means 分群模型:想透過非監督式學習探索內容時,就適合使用這個模型。
注意:機器學習技術還能用於其他多種模型,例如類神經網路和決策樹,TensorFlow 等程式庫可提供這些模型。目前 BQML 支援以上所列的三種模型,詳情請參閱 BQML 藍圖。
- 輸入下列查詢來建立模型,並指定模型選項:
CREATE or REPLACE MODEL taxi.taxifare_model
OPTIONS
(model_type='linear_reg', labels=['total_fare']) AS
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
-
接著點選「執行」來開始訓練模型。
-
等模型訓練完成 (5 至 10 分鐘)。
模型訓練完成後,畫面會顯示下列訊息:「This statement will create a new model named qwiklabs-gcp-03-xxxxxxxx:taxi.taxifare_model」,這表示模型訓練成功。
- 查看計程車資料集,確認已顯示「taxifare_model」。
接下來,您將使用新資料來評估模型成效。
測試已完成的工作
點選「Check my progress」確認工作已完成。如果順利完成,就會看見評估分數。
建立計程車車資模型
工作 6:評估分類模型的成效
選取成效條件
請使用均方根誤差 (RMSE) 等損失指標來評估線性迴歸模型的成效,並持續訓練及改進模型,直到得出最低 RMSE 為止。
在 BQML 評估訓練過的機器學習模型時,mean_squared_error 是可查詢的欄位,加入 SQRT() 即可得出 RMSE。
現在模型已訓練完成,您可以使用 ML.EVALUATE 執行下列查詢來評估模型成效。
- 複製下列指令並貼入查詢編輯器,然後點選「執行」:
#standardSQL
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
現在請根據不同的計程車載客資料組合,使用 params.EVAL 篩選條件來評估模型的成效。
- 在模型開始運作後,檢查輸出結果 (您模型的 RMSE 值將略有不同)。
|
Row
|
rmse
|
|
1
|
9.477056435999074
|
評估模型後,您得到的 RMSE 為 9.47。得到 RMSE 值 9.47 後,可比照 total_fare 的單位記為 +-$9.47 美元來進行評估。
如果將模型用於正式環境,這項損失指標值是可接受的嗎?這完全取決於您在開始訓練模型前設定的基準條件。設定基準,就是針對模型成效和準確率,確立可接受的最低門檻。
測試已完成的工作
點選「Check my progress」確認工作已完成。如果順利完成,就會看見評估分數。
評估分類模型的成效
工作 7:預測計程車車資
接下來請編寫查詢,使用新建立的模型進行預測。
#standardSQL
SELECT
*
FROM
ml.PREDICT(MODEL `taxi.taxifare_model`,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
));
您會看見模型預測的計程車車資,以及這些載客資料的實際車資和其他特徵。畫面上會顯示類似下方的結果:

測試已完成的工作
點選「Check my progress」確認工作已完成。如果順利完成,就會看見評估分數。
預測計程車車資
工作 8:運用特徵工程提升模型成效
建構機器學習模型是不斷重複的程序。評估初始模型的成效後,通常需要回頭修剪特徵和資料列,看看模型是否因此改善。
篩選訓練資料集
現在請查看計程車車資的一般統計資料。
- 複製下列指令並貼入查詢編輯器,然後點選「執行」:
SELECT
COUNT(fare_amount) AS num_fares,
MIN(fare_amount) AS low_fare,
MAX(fare_amount) AS high_fare,
AVG(fare_amount) AS avg_fare,
STDDEV(fare_amount) AS stddev
FROM
`nyc-tlc.yellow.trips`
# 1,108,779,463 fares
畫面上會顯示類似下方的輸出內容:
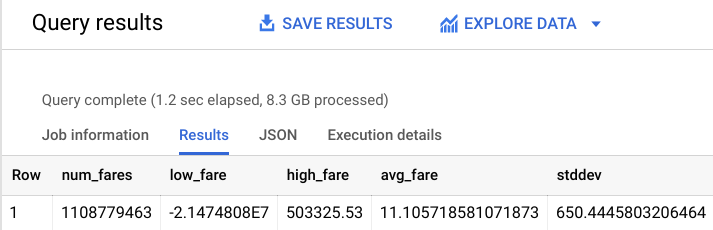
如您所見,資料集有一些異常的離群值,例如負車資或超過 $50,000 美元的車資。讓我們運用 BigQuery ML 相關專業知識,避免模型從這些離群值學習。
限制資料範圍,僅顯示介於 $$6 美元至 $$200 美元的車資資料。
- 複製下列指令並貼入查詢編輯器,然後點選「執行」:
SELECT
COUNT(fare_amount) AS num_fares,
MIN(fare_amount) AS low_fare,
MAX(fare_amount) AS high_fare,
AVG(fare_amount) AS avg_fare,
STDDEV(fare_amount) AS stddev
FROM
`nyc-tlc.yellow.trips`
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
# 843,834,902 fares
畫面上會顯示類似下方的輸出內容:
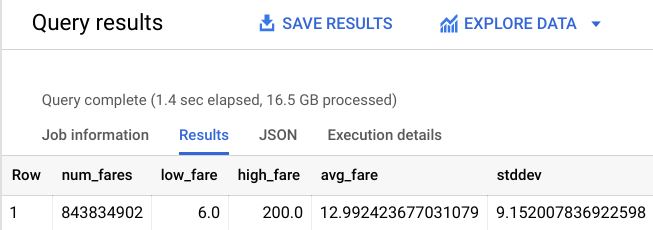
這樣合理多了。探索資料時,限制行車距離才能確實聚焦於紐約市的情形。
- 複製下列指令並貼入查詢編輯器,然後點選「執行」:
SELECT
COUNT(fare_amount) AS num_fares,
MIN(fare_amount) AS low_fare,
MAX(fare_amount) AS high_fare,
AVG(fare_amount) AS avg_fare,
STDDEV(fare_amount) AS stddev
FROM
`nyc-tlc.yellow.trips`
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
AND pickup_longitude > -75 #limiting of the distance the taxis travel out
AND pickup_longitude < -73
AND dropoff_longitude > -75
AND dropoff_longitude < -73
AND pickup_latitude > 40
AND pickup_latitude < 42
AND dropoff_latitude > 40
AND dropoff_latitude < 42
# 827,365,869 fares
畫面上會顯示類似下方的輸出內容:
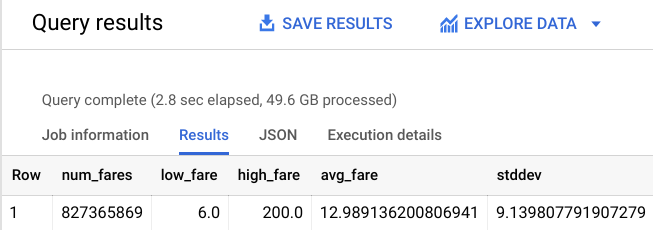
不過訓練資料集仍相當龐大,供新模型學習的載客資料超過 8 億筆。請新增下列限制並重新訓練模型,看看模型成效如何。
重新訓練模型
將新的線性迴歸模型命名為 taxi.taxifare_model_2,然後重新訓練模型來預測總車資。您會發現,這次的指令同時加入幾項特徵,來計算從上車到下車的歐幾里得距離 (直線距離)。
CREATE OR REPLACE MODEL taxi.taxifare_model_2
OPTIONS
(model_type='linear_reg', labels=['total_fare']) AS
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
SQRT(POW((pickup_longitude - dropoff_longitude),2) + POW(( pickup_latitude - dropoff_latitude), 2)) as dist, #Euclidean distance between pickup and drop off
SQRT(POW((pickup_longitude - dropoff_longitude),2)) as longitude, #Euclidean distance between pickup and drop off in longitude
SQRT(POW((pickup_latitude - dropoff_latitude), 2)) as latitude, #Euclidean distance between pickup and drop off in latitude
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
AND pickup_longitude > -75 #limiting of the distance the taxis travel out
AND pickup_longitude < -73
AND dropoff_longitude > -75
AND dropoff_longitude < -73
AND pickup_latitude > 40
AND pickup_latitude < 42
AND dropoff_latitude > 40
AND dropoff_latitude < 42
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
模型可能需要幾分鐘才能重新訓練完成。在控制台中收到下列訊息後,即可前往下一個步驟:
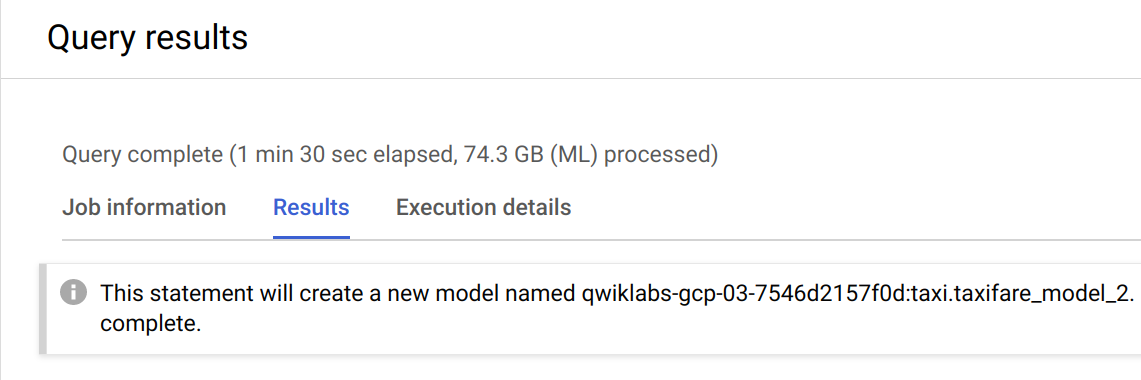
評估新模型的成效
新的線性迴歸模型已經過最佳化調整,現在請使用資料集進行評估,看看模型成效如何。
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model_2,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
SQRT(POW((pickup_longitude - dropoff_longitude),2) + POW(( pickup_latitude - dropoff_latitude), 2)) as dist, #Euclidean distance between pickup and drop off
SQRT(POW((pickup_longitude - dropoff_longitude),2)) as longitude, #Euclidean distance between pickup and drop off in longitude
SQRT(POW((pickup_latitude - dropoff_latitude), 2)) as latitude, #Euclidean distance between pickup and drop off in latitude
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
AND pickup_longitude > -75 #limiting of the distance the taxis travel out
AND pickup_longitude < -73
AND dropoff_longitude > -75
AND dropoff_longitude < -73
AND pickup_latitude > 40
AND pickup_latitude < 42
AND dropoff_latitude > 40
AND dropoff_latitude < 42
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
畫面上會顯示類似下方的輸出內容:
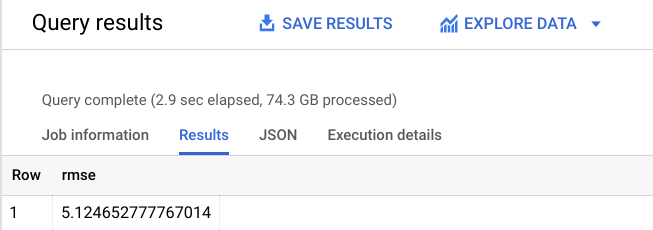
如您所見,RMSE 值大幅降至 +-$$5.12 美元,遠優於第一個模型的 +-$$9.47 美元。
RMSE 為預測誤差的標準差,由此可得知,重新訓練後的線性迴歸模型準確率明顯提高。
工作 9:隨堂測驗
下列選擇題可以加深您對本實驗室概念的理解,盡力回答即可。
工作 10:其他可探索的資料集
如想瞭解使用其他資料集建模的情形,比如預測芝加哥計程車車資,可以使用 bigquery-public-data 專案。
-
依序點選「+新增」>「依據名稱為專案加上星號」>「Enter Project Name」,然後輸入名稱 bigquery-public-data,即可開啟 bigquery-public-data 資料集。
-
點選「加上星號」。
bigquery-public-data 專案會列在「Explorer」專區。
恭喜!
您已成功在 BigQuery 建構機器學習模型,預測紐約市計程車車資。
後續行動/瞭解詳情
Google Cloud 教育訓練與認證
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2024 年 2 月 7 日
實驗室上次測試日期:2023 年 8 月 24 日
Copyright 2025 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。





