GSP246

개요
BigQuery는 Google의 완전 관리형, 노옵스(NoOps), 저비용 분석 데이터베이스입니다. BigQuery를 사용하면 관리할 인프라나 데이터베이스 관리자가 없어도 테라바이트 단위의 데이터를 쿼리할 수 있습니다.
BigQuery ML을 사용하면 데이터 분석가가 최소한의 코딩만으로 머신러닝 모델을 만들고, 학습시키고, 평가하고, 예측할 수 있습니다.
이 실습에서는 BigQuery 공개 데이터 세트에서 제공되는 수백만 건의 뉴욕 옐로캡 택시 운행 데이터로 작업을 수행합니다. 이 데이터를 사용하여 BigQuery 내에서 머신러닝 모델을 만들어 모델 입력으로 주어진 택시 요금을 예측하고, 모델의 성능을 평가하며, 예측을 수행합니다.
학습할 내용
이 실습에서는 다음 작업을 수행하는 방법에 대해 알아봅니다.
- BigQuery를 사용하여 공개 데이터 세트 찾기
- 공개 택시 데이터 세트 쿼리 및 탐색
- 일괄 예측에 사용할 학습 및 평가 데이터 세트 만들기
- BigQuery ML에서 선형 회귀 예측 모델 만들기
- 머신러닝 모델의 성능 평가하기
설정 및 요건
실습 시작 버튼을 클릭하기 전에
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지를 표시합니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
- 표준 인터넷 브라우저 액세스 권한(Chrome 브라우저 권장)
참고: 이 실습을 실행하려면 시크릿 모드(권장) 또는 시크릿 브라우저 창을 사용하세요. 개인 계정과 학습자 계정 간의 충돌로 개인 계정에 추가 요금이 발생하는 일을 방지해 줍니다.
- 실습을 완료하기에 충분한 시간(실습을 시작하고 나면 일시중지할 수 없음)
참고: 이 실습에는 학습자 계정만 사용하세요. 다른 Google Cloud 계정을 사용하는 경우 해당 계정에 비용이 청구될 수 있습니다.
실습을 시작하고 Google Cloud 콘솔에 로그인하는 방법
-
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 대화상자가 열립니다.
왼쪽에는 다음과 같은 항목이 포함된 실습 세부정보 창이 있습니다.
- Google Cloud 콘솔 열기 버튼
- 남은 시간
- 이 실습에 사용해야 하는 임시 사용자 인증 정보
- 필요한 경우 실습 진행을 위한 기타 정보
-
Google Cloud 콘솔 열기를 클릭합니다(Chrome 브라우저를 실행 중인 경우 마우스 오른쪽 버튼으로 클릭하고 시크릿 창에서 링크 열기를 선택합니다).
실습에서 리소스가 가동되면 다른 탭이 열리고 로그인 페이지가 표시됩니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
참고: 계정 선택 대화상자가 표시되면 다른 계정 사용을 클릭합니다.
-
필요한 경우 아래의 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다.
{{{user_0.username | "Username"}}}
실습 세부정보 창에서도 사용자 이름을 확인할 수 있습니다.
-
다음을 클릭합니다.
-
아래의 비밀번호를 복사하여 시작하기 대화상자에 붙여넣습니다.
{{{user_0.password | "Password"}}}
실습 세부정보 창에서도 비밀번호를 확인할 수 있습니다.
-
다음을 클릭합니다.
중요: 실습에서 제공하는 사용자 인증 정보를 사용해야 합니다. Google Cloud 계정 사용자 인증 정보를 사용하지 마세요.
참고: 이 실습에 자신의 Google Cloud 계정을 사용하면 추가 요금이 발생할 수 있습니다.
-
이후에 표시되는 페이지를 클릭하여 넘깁니다.
- 이용약관에 동의합니다.
- 임시 계정이므로 복구 옵션이나 2단계 인증을 추가하지 않습니다.
- 무료 체험판을 신청하지 않습니다.
잠시 후 Google Cloud 콘솔이 이 탭에서 열립니다.
참고: Google Cloud 제품 및 서비스에 액세스하려면 탐색 메뉴를 클릭하거나 검색창에 제품 또는 서비스 이름을 입력합니다.

BigQuery 콘솔 열기
- Google Cloud 콘솔에서 탐색 메뉴 > BigQuery를 선택합니다.
Cloud 콘솔의 BigQuery에 오신 것을 환영합니다라는 메시지 상자가 열립니다. 이 메시지 상자에서는 빠른 시작 가이드 및 출시 노트로 연결되는 링크가 제공됩니다.
-
완료를 클릭합니다.
BigQuery 콘솔이 열립니다.
작업 1. 뉴욕시 택시 데이터 살펴보기
질문: 2015년 옐로캡 택시의 월별 운행 횟수는 모두 몇 번일까요?
- 다음 SQL 코드를 복사하여 쿼리 편집기에 붙여넣습니다.
#standardSQL
SELECT
TIMESTAMP_TRUNC(pickup_datetime,
MONTH) month,
COUNT(*) trips
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
GROUP BY
1
ORDER BY
1
- 그런 다음 실행을 클릭합니다.
다음과 같은 결과가 표시됩니다.
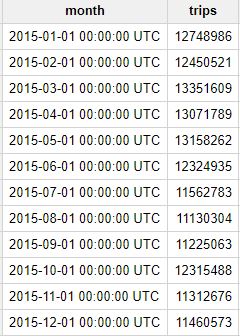
위의 결과에서 2015년 뉴욕시의 월별 택시 운행 횟수는 천만 회가 넘었음을 알 수 있습니다. 이는 상당한 규모입니다.
완료된 작업 테스트하기
내 진행 상황 확인하기를 클릭하여 실행한 작업을 확인합니다. 작업을 올바르게 완료하면 평가 점수가 부여됩니다.
2015년의 옐로캡 운행 횟수를 월별로 계산하기
질문: 2015년 옐로캡 택시의 평균 속도는 얼마인가요?
- 이전 쿼리를 다음으로 대체한 다음 쿼리를 실행합니다.
#standardSQL
SELECT
EXTRACT(HOUR
FROM
pickup_datetime) hour,
ROUND(AVG(trip_distance / TIMESTAMP_DIFF(dropoff_datetime,
pickup_datetime,
SECOND))*3600, 1) speed
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
WHERE
trip_distance > 0
AND fare_amount/trip_distance BETWEEN 2
AND 10
AND dropoff_datetime > pickup_datetime
GROUP BY
1
ORDER BY
1
다음과 같은 결과가 표시됩니다.

낮 동안 평균 속도는 약 11~12MPH이지만, 오전 5시 평균 속도는 거의 두 배인 21MPH를 기록했습니다. 직관적으로 바로 이해하실 수 있겠지만, 이는 새벽 5시에 도로의 교통량이 적을 가능성이 높기 때문입니다.
완료된 작업 테스트하기
내 진행 상황 확인하기를 클릭하여 실행한 작업을 확인합니다. 작업을 올바르게 완료하면 평가 점수가 부여됩니다.
2015년 옐로캡 택시 평균 운행 속도 계산하기
작업 2. 목표 파악하기
이제 BigQuery에서 머신러닝 모델을 만들어 주어진 과거 운행 데이터 세트와 운행 데이터를 바탕으로 뉴욕 옐로캡 택시 운행 요금을 예측하게 됩니다. 운행 전에 요금을 예측하면 승객과 택시 회사 양쪽 모두가 경로를 계획하는 데 매우 도움이 됩니다.
작업 3. 특성 선택 및 학습 데이터 세트 만들기
뉴욕시 옐로캡 데이터 세트는 시에서 제공하는 공개 데이터 세트이며, 사용자가 탐색할 수 있도록 BigQuery에 로드되어 있습니다.
전체 필드 목록을 둘러본 다음 데이터 세트 미리보기를 통해 과거 택시 운행 데이터와 운행 요금 간의 관계를 머신러닝 모델이 이해하는 데 도움이 되는 유용한 특성을 찾습니다.
팀에서 아래의 필드가 요금 예측 모델에 적합한 입력인지 테스트하기로 결정합니다.
- 통행 요금
- 요금
- 시간
- 승차 주소
- 하차 주소
- 승객 수
- 다음으로 쿼리를 대체합니다.
#standardSQL
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
이 쿼리와 관련해 다음 사항을 참고하세요.
- 쿼리의 주요 부분은 쿼리 하단(
SELECT * from taxitrips)에 있습니다.
-
taxitrips는 뉴욕시 데이터 세트에 대한 일괄 추출을 수행하며, SELECT에는 학습 특성 및 라벨이 포함되어 있습니다.
-
WHERE는 학습시키고 싶지 않은 데이터를 제거합니다.
-
WHERE에는 데이터의 1/1000만 가져오기 위한 샘플링 절 또한 포함되어 있습니다.
- 독립적인
EVAL 세트를 빠르게 빌드할 수 있도록 TRAIN이라는 변수를 정의합니다.
- 이 쿼리의 목적을 알아보았으니, 이제 실행을 클릭합니다.
다음과 비슷한 결과가 표시됩니다.
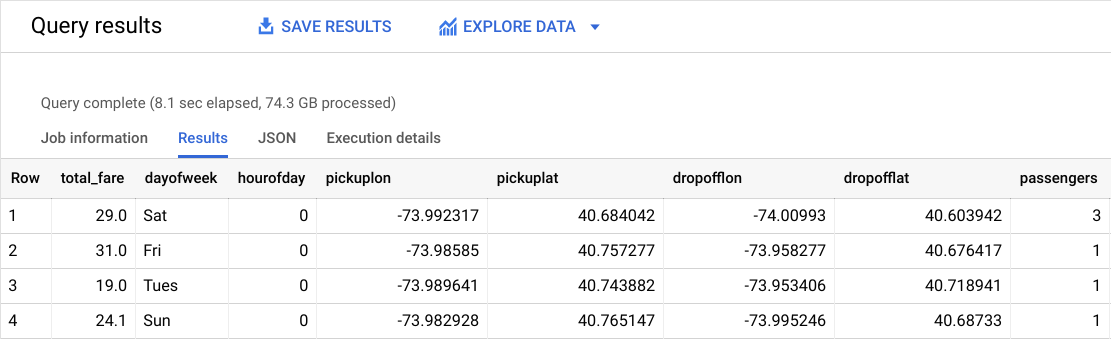
여기에서 라벨(정답)은 무엇인가요?
라벨(예측 대상)은 total_fare입니다. 이 필드는 tolls_amount 및 fare_amount를 바탕으로 생성됩니다. 고객이 지불하는 팁의 액수는 임의적이므로 모델에서 무시할 수 있습니다.
완료된 작업 테스트하기
내 진행 상황 확인하기를 클릭하여 실행한 작업을 확인합니다. 작업을 올바르게 완료하면 평가 점수가 부여됩니다.
필드가 요금 예측 모델에 적합한 입력인지 테스트하기
작업 4. 모델을 저장할 BigQuery 데이터 세트 만들기
이 섹션에서는 ML 모델을 저장할 새로운 BigQuery 데이터 세트를 만듭니다.
-
왼쪽 탐색기 패널에서 프로젝트 ID 옆에 있는 작업 보기 아이콘을 클릭한 다음, 데이터 세트 만들기를 클릭합니다.
-
데이터 세트 만들기 대화상자에서 다음을 입력합니다.
-
데이터 세트 ID에 taxi를 입력합니다.
-
위치 유형으로 us(미국 내 여러 리전)를 선택합니다.
- 다른 값은 기본값을 유지합니다.
-
데이터 세트 만들기를 클릭합니다.
완료된 작업 테스트하기
내 진행 상황 확인하기를 클릭하여 실행한 작업을 확인합니다. 작업을 올바르게 완료하면 평가 점수가 부여됩니다.
모델을 저장할 BigQuery 데이터 세트 만들기
작업 5. BigQuery ML 모델 유형 선택 및 옵션 지정
초기 특성을 선택했으므로 이제 BigQuery에서 첫 번째 ML 모델을 만들어 보도록 하겠습니다.
다음과 같은 몇 가지 모델 유형 중에서 선택할 수 있습니다.
- 다음 달 매출과 같은 숫자 값을 예측할 수 있는 선형 회귀(linear_reg)
- 이메일의 스팸 처리와 같이 바이너리 또는 멀티클래스로 분류할 수 있는 로지스틱 회귀(logistic_reg)
- 탐색을 위해 비지도 학습을 할 때 클러스터링을 지원하는 k-평균(kmeans)
참고: 그 밖에도 머신러닝에 사용할 수 있는 다양한 유형의 모델(예: 신경망, 결정 트리)이 있으며, TensorFlow와 같은 라이브러리를 통해 사용할 수 있습니다. 현재 BQML에서는 위에 나열된 세 모델을 지원합니다. 자세한 내용은 BQML 로드맵을 참고하세요.
- 다음 쿼리를 입력하여 모델을 만들고 모델 옵션을 지정합니다.
CREATE or REPLACE MODEL taxi.taxifare_model
OPTIONS
(model_type='linear_reg', labels=['total_fare']) AS
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
-
그런 다음 실행을 클릭하여 모델을 학습시킵니다.
-
모델이 학습을 마칠 때까지 기다립니다(5~10분).
모델 학습이 끝나면 '이 문으로 이름이 qwiklabs-gcp-03-xxxxxxxx:taxi.taxifare_model인 모델이 생성됩니다'라는 메시지가 표시되며, 이는 모델이 정상적으로 학습했음을 의미합니다.
- 택시 데이터 세트 내에 taxifare_model이 표시되어 있는지 확인합니다.
다음 단계에서는 입력되지 않은 새 평가 데이터를 기반으로 모델 성능을 평가하겠습니다.
완료된 작업 테스트하기
내 진행 상황 확인하기를 클릭하여 실행한 작업을 확인합니다. 작업을 올바르게 완료하면 평가 점수가 부여됩니다.
택시 요금 모델 만들기
작업 6. 분류 모델 성능 평가
성능 기준 선택
선형 회귀 모델의 경우 평균 제곱근 오차(RMSE)와 같은 손실 측정항목을 사용하는 것이 좋으며, RMSE가 가장 낮아질 때까지 계속해서 모델을 학습시키고 개선해야 합니다.
BQML에서 mean_squared_error는 학습시킨 ML 모델을 평가할 때 쿼리 가능한 필드입니다. SQRT()를 추가하여 RMSE를 가져옵니다.
이제 학습을 완료했으니, 이 쿼리를 사용할 때 모델이 어떤 성능을 내는지 ML.EVALUATE를 사용해 평가할 수 있습니다.
- 다음 명령어를 복사하여 쿼리 편집기에 붙여넣은 다음 실행을 클릭합니다.
#standardSQL
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
이제 params.EVAL 필터를 사용하여 다양한 택시 운행 데이터 세트에 대해 모델을 평가합니다.
- 모델이 실행된 후 모델 결과를 검토합니다(모델 RMSE 값은 약간 다를 수 있음).
|
행
|
rmse
|
|
1
|
9.477056435999074
|
모델을 평가하면 9.47의 RMSE가 반환됩니다. 평균 제곱 오차(RMSE)의 제곱근을 취했으므로 9.47 오류는 total_fare와 똑같은 단위에서 평가할 수 있습니다. 따라서 +-$9.47가 됩니다.
이 손실 측정항목이 모델을 프로덕션화하는 데 충분한지는 모델 학습이 시작되기 전에 설정되는 벤치마크 기준에 전적으로 달려 있습니다. 허용 가능한 모델 성능 및 정확도의 최소 수준은 벤치마킹에서 정합니다.
완료된 작업 테스트하기
내 진행 상황 확인하기를 클릭하여 실행한 작업을 확인합니다. 작업을 올바르게 완료하면 평가 점수가 부여됩니다.
분류 모델 성능 평가하기
작업 7. 택시 요금 예측하기
이제 새 모델을 사용하여 예측을 수행하기 위한 쿼리를 작성하겠습니다.
- 다음 명령어를 복사하여 쿼리 편집기에 붙여넣은 다음 실행을 클릭합니다.
#standardSQL
SELECT
*
FROM
ml.PREDICT(MODEL `taxi.taxifare_model`,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
));
그러면 택시 요금에 대한 모델의 예측과 함께 실제 요금, 운행과 관련된 기타 특성이 표시됩니다. 아래와 비슷한 결과가 나와야 합니다.

완료된 작업 테스트하기
내 진행 상황 확인하기를 클릭하여 실행한 작업을 확인합니다. 작업을 올바르게 완료하면 평가 점수가 부여됩니다.
택시 요금 예측하기
작업 8. 특성 추출을 통해 모델 개선하기
머신러닝 모델 빌드는 반복적인 프로세스입니다. 초기 모델 성능을 평가한 후에는 특성과 행을 가지치기하는 단계로 돌아가 모델 성능을 더 향상할 수 있는지 확인해야 할 때가 많습니다.
학습 데이터 세트 필터링하기
이제 택시 요금에 대한 일반적인 통계를 확인해 봅니다.
- 다음 명령어를 복사하여 쿼리 편집기에 붙여넣은 다음 실행을 클릭합니다.
SELECT
COUNT(fare_amount) AS num_fares,
MIN(fare_amount) AS low_fare,
MAX(fare_amount) AS high_fare,
AVG(fare_amount) AS avg_fare,
STDDEV(fare_amount) AS stddev
FROM
`nyc-tlc.yellow.trips`
# 1,108,779,463 fares
다음과 비슷한 출력이 표시됩니다.
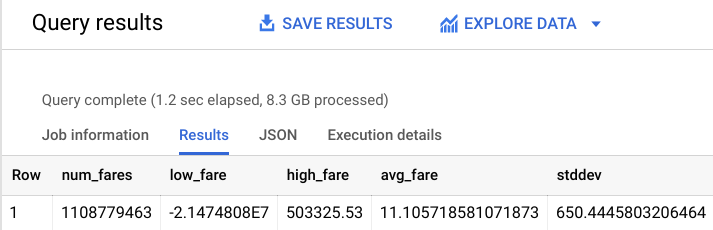
결과에서 볼 수 있듯이 이 데이터 세트에는 이해되지 않는 이상점이 몇 가지 있습니다($50,000가 넘거나 음수로 표시된 요금). 모델이 이해되지 않는 이상값을 학습하지 않도록 주제와 관련된 지식을 활용해 보겠습니다.
데이터를 $$6에서 $$200 사이의 요금으로만 제한합니다.
- 다음 명령어를 복사하여 쿼리 편집기에 붙여넣은 다음 실행을 클릭합니다.
SELECT
COUNT(fare_amount) AS num_fares,
MIN(fare_amount) AS low_fare,
MAX(fare_amount) AS high_fare,
AVG(fare_amount) AS avg_fare,
STDDEV(fare_amount) AS stddev
FROM
`nyc-tlc.yellow.trips`
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
# 843,834,902 fares
다음과 비슷한 출력이 표시됩니다.
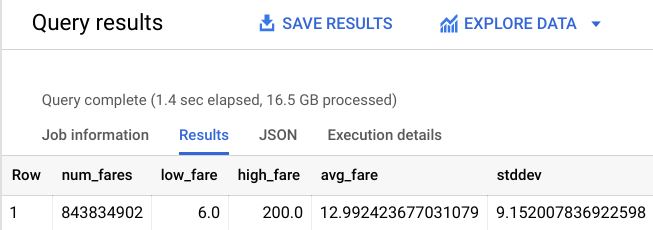
더 나은 결과가 표시되었습니다. 이와 동시에 이동 거리를 제한하여 뉴욕시에 집중해 보겠습니다.
- 다음 명령어를 복사하여 쿼리 편집기에 붙여넣은 다음 실행을 클릭합니다.
SELECT
COUNT(fare_amount) AS num_fares,
MIN(fare_amount) AS low_fare,
MAX(fare_amount) AS high_fare,
AVG(fare_amount) AS avg_fare,
STDDEV(fare_amount) AS stddev
FROM
`nyc-tlc.yellow.trips`
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
AND pickup_longitude > -75 #limiting of the distance the taxis travel out
AND pickup_longitude < -73
AND dropoff_longitude > -75
AND dropoff_longitude < -73
AND pickup_latitude > 40
AND pickup_latitude < 42
AND dropoff_latitude > 40
AND dropoff_latitude < 42
# 827,365,869 fares
다음과 비슷한 출력이 표시됩니다.
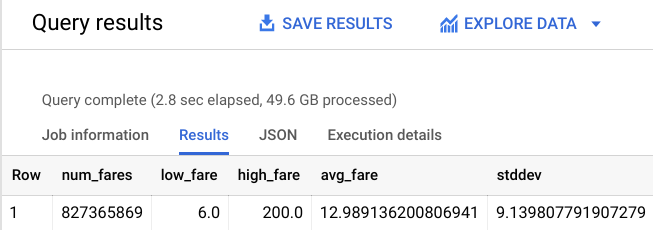
아직 새 모델에게 8억 건 이상의 택시 운행을 담은 대규모 학습 데이터 세트를 학습시키는 작업이 남아 있습니다. 위의 새로운 제약조건으로 모델을 다시 학습시킨 다음 성능이 어떤지 확인해 보겠습니다.
모델 재학습하기
새 모델 Taxifare_model_2를 호출하고 선형 회귀 모델을 다시 학습하여 전체 요금을 예측합니다. 승하차 지점 사이의 유클리드 거리(직선)를 계산한 특성도 몇 가지 추가되었습니다.
- 다음 명령어를 복사하여 쿼리 편집기에 붙여넣은 다음 실행을 클릭합니다.
CREATE OR REPLACE MODEL taxi.taxifare_model_2
OPTIONS
(model_type='linear_reg', labels=['total_fare']) AS
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
SQRT(POW((pickup_longitude - dropoff_longitude),2) + POW(( pickup_latitude - dropoff_latitude), 2)) as dist, #Euclidean distance between pickup and drop off
SQRT(POW((pickup_longitude - dropoff_longitude),2)) as longitude, #Euclidean distance between pickup and drop off in longitude
SQRT(POW((pickup_latitude - dropoff_latitude), 2)) as latitude, #Euclidean distance between pickup and drop off in latitude
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
AND pickup_longitude > -75 #limiting of the distance the taxis travel out
AND pickup_longitude < -73
AND dropoff_longitude > -75
AND dropoff_longitude < -73
AND pickup_latitude > 40
AND pickup_latitude < 42
AND dropoff_latitude > 40
AND dropoff_latitude < 42
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
모델이 재학습하는 데는 몇 분 정도 소요될 수 있습니다. 콘솔에 다음 메시지가 나타나면 다음 단계로 넘어가도 된다는 의미입니다.
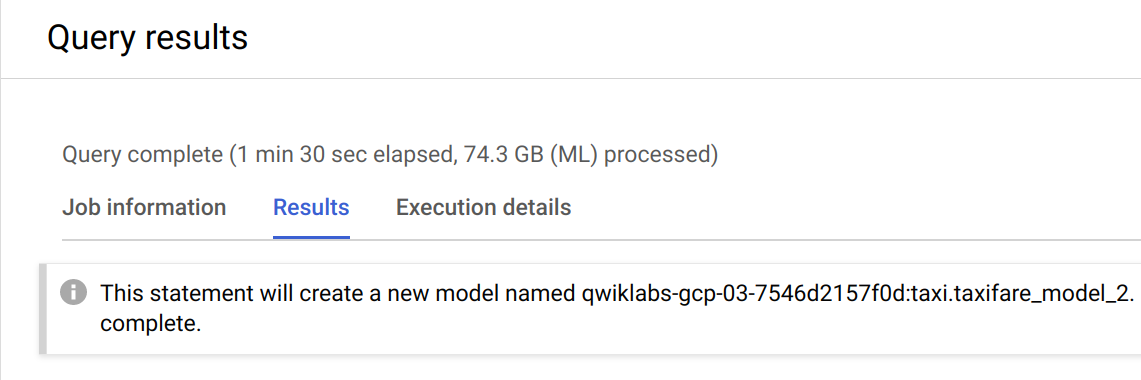
새로운 모델 평가하기
선형 회귀 모델이 최적화되었으니 이를 사용하여 데이터 세트를 평가하고 성능을 확인해 보겠습니다.
- 다음 명령어를 복사하여 쿼리 편집기에 붙여넣은 다음 실행을 클릭합니다.
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model_2,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
SQRT(POW((pickup_longitude - dropoff_longitude),2) + POW(( pickup_latitude - dropoff_latitude), 2)) as dist, #Euclidean distance between pickup and drop off
SQRT(POW((pickup_longitude - dropoff_longitude),2)) as longitude, #Euclidean distance between pickup and drop off in longitude
SQRT(POW((pickup_latitude - dropoff_latitude), 2)) as latitude, #Euclidean distance between pickup and drop off in latitude
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
AND pickup_longitude > -75 #limiting of the distance the taxis travel out
AND pickup_longitude < -73
AND dropoff_longitude > -75
AND dropoff_longitude < -73
AND pickup_latitude > 40
AND pickup_latitude < 42
AND dropoff_latitude > 40
AND dropoff_latitude < 42
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
다음과 비슷한 출력이 표시됩니다.
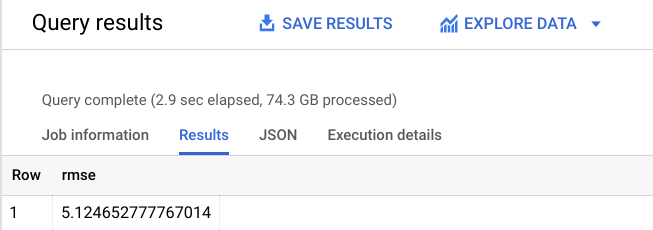
위에서 볼 수 있듯이 RMSE가 +-$$5.12로 감소했습니다. 이는 첫 번째 모델이 출력했던 +-$$9.47보다 훨씬 형상된 결과입니다.
RMSE는 예측 오류의 표준 편차를 정의하므로, 모델이 선형 회귀를 재학습하여 정확도를 개선했음을 알 수 있습니다.
작업 9. 배운 내용 테스트하기
아래에는 이 실습에서 배운 내용을 복습하기 위한 객관식 테스트가 나와 있습니다. 최선을 다해 풀어보세요.
작업 10. 살펴볼 다른 데이터 세트
시카고의 택시 운행 요금 예측하기와 같이 다른 데이터 세트에 대한 모델링을 알아보고 싶다면 bigquery-public-data 프로젝트를 사용하면 됩니다.
-
bigquery-public-data 데이터 세트를 열려면 +추가 > 이름으로 프로젝트에 별표표시 > 프로젝트 이름 입력를 클릭한 다음 bigquery-public-data라는 이름을 입력합니다.
-
별표를 클릭합니다.
탐색기 섹션에 bigquery-public-data 프로젝트가 표시됩니다.
수고하셨습니다
BigQuery에서 머신러닝 모델을 빌드하여 뉴욕시 택시 요금을 예측해 보았습니다.
다음 단계/더 학습하기
Google Cloud 교육 및 자격증
Google Cloud 기술을 최대한 활용하는 데 도움이 됩니다. Google 강의에는 빠른 습득과 지속적인 학습을 지원하는 기술적인 지식과 권장사항이 포함되어 있습니다. 기초에서 고급까지 수준별 학습을 제공하며 바쁜 일정에 알맞은 주문형, 실시간, 가상 옵션이 포함되어 있습니다. 인증은 Google Cloud 기술에 대한 역량과 전문성을 검증하고 입증하는 데 도움이 됩니다.
설명서 최종 업데이트: 2024년 2월 7일
실습 최종 테스트: 2023년 8월 24일
Copyright 2025 Google LLC. All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.





