GSP246

Présentation
BigQuery est la base de données d'analyse NoOps, économique et entièrement gérée de Google. Grâce à BigQuery, vous pouvez interroger plusieurs téraoctets de données sans avoir à gérer d'infrastructure ni faire appel à un administrateur de base de données.
BigQuery ML permet aux analystes de données de créer, d'entraîner et d'évaluer des modèles de machine learning en vue de prédire des résultats, et ce avec très peu de code.
Dans cet atelier, vous allez travailler sur des millions de courses effectuées par les taxis jaunes new-yorkais, à partir d'un ensemble de données public BigQuery. Vous allez créer un modèle de machine learning dans BigQuery pour prédire le prix de la course à partir des données traitées par le modèle, puis évaluer les performances du modèle et réaliser des prédictions.
Points abordés
Dans cet atelier, vous allez apprendre à réaliser les opérations suivantes :
- Utiliser BigQuery pour rechercher des ensembles de données publics
- Interroger et examiner l'ensemble de données public relatif aux taxis
- Créer un ensemble de données d'entraînement et d'évaluation pour la prédiction par lots
- Créer un modèle de prévision (de type régression linéaire) dans BigQuery ML
- Évaluer les performances de votre modèle de machine learning
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Des identifiants temporaires vous sont fournis pour vous permettre de vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode incognito (recommandé) ou de navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Utilisez uniquement le compte de participant pour cet atelier. Si vous utilisez un autre compte Google Cloud, des frais peuvent être facturés à ce compte.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, une boîte de dialogue s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau "Détails concernant l'atelier", qui contient les éléments suivants :
- Le bouton "Ouvrir la console Google Cloud"
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page "Se connecter" dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour accéder aux produits et services Google Cloud, cliquez sur le menu de navigation ou saisissez le nom du service ou du produit dans le champ Recherche.

Ouvrir la console BigQuery
- Dans la console Google Cloud, sélectionnez le menu de navigation > BigQuery.
Le message Bienvenue sur BigQuery dans Cloud Console s'affiche. Il contient un lien vers le guide de démarrage rapide et les notes de version.
- Cliquez sur OK.
La console BigQuery s'ouvre.
Tâche 1 : Examiner les données relatives aux taxis new-yorkais
Question : Combien de courses les taxis jaunes ont-ils effectuées chaque mois en 2015 ?
- Copiez le code SQL suivant et collez-le dans l'éditeur de requête :
#standardSQL
SELECT
TIMESTAMP_TRUNC(pickup_datetime,
MONTH) month,
COUNT(*) trips
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
GROUP BY
1
ORDER BY
1
- Ensuite, cliquez sur Exécuter.
Vous devez obtenir le résultat suivant :
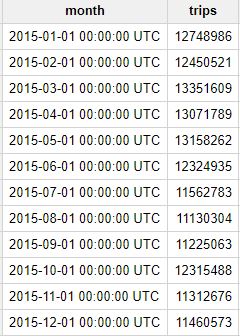
Comme vous pouvez le constater, en 2015, les taxis de New York ont effectué plus de 10 millions de courses chaque mois. Un chiffre considérable !
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
Calculer les courses effectuées chaque mois par les taxis jaunes en 2015
Question : Quelle était la vitesse moyenne des taxis jaunes en 2015 ?
- Remplacez la requête précédente par celle qui suit, puis cliquez sur Exécuter :
#standardSQL
SELECT
EXTRACT(HOUR
FROM
pickup_datetime) hour,
ROUND(AVG(trip_distance / TIMESTAMP_DIFF(dropoff_datetime,
pickup_datetime,
SECOND))*3600, 1) speed
FROM
`bigquery-public-data.new_york.tlc_yellow_trips_2015`
WHERE
trip_distance > 0
AND fare_amount/trip_distance BETWEEN 2
AND 10
AND dropoff_datetime > pickup_datetime
GROUP BY
1
ORDER BY
1
Vous devez obtenir le résultat suivant :

En journée, la vitesse moyenne est d'environ 18-19 km/h. Elle atteint 34 km/h à 5 h du matin, soit près du double. Cela semble logique, car la circulation est sans doute plus fluide à cette heure-là.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
Calculer la vitesse moyenne des taxis jaunes en 2015
Tâche 2 : Identifier un objectif
Vous allez maintenant créer un modèle de machine learning dans BigQuery afin de prédire le prix d'une course à New York en vous basant sur un ensemble de données contenant l'historique des courses et les informations associées. Cela peut s'avérer très utile en termes de planification des trajets, pour le chauffeur comme pour l'agence de taxis.
Tâche 3 : Sélectionner des caractéristiques et créer l'ensemble de données d'entraînement
L'ensemble de données concernant les taxis jaunes new-yorkais est un ensemble de données public fourni par la ville. Il a été chargé dans BigQuery afin que vous puissiez l'examiner.
Après avoir parcouru la liste complète des champs, prévisualisez l'ensemble de données pour identifier les caractéristiques utiles qui permettront à votre modèle de machine learning de déterminer le lien entre les données concernant l'historique des courses en taxi et le prix de la course.
Votre équipe veut savoir si les champs suivants conviennent pour établir le modèle de prévision du prix d'une course :
- Tarif des péages
- Prix de la course
- Heure de la journée
- Adresse de départ
- Adresse d'arrivée
- Nombre de passagers
- Remplacez la requête par celle-ci :
#standardSQL
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
Informations importantes concernant la requête :
- La partie principale de la requête se trouve à la fin : (
SELECT * from taxitrips).
- L'essentiel de l'extraction depuis l'ensemble de données relatif aux taxis new-yorkais s'effectue grâce à
taxitrips. La partie SELECT contient les caractéristiques d'entraînement et l'étiquette que vous avez définies.
- La partie
WHERE permet d'exclure certaines données de l'entraînement.
- La partie
WHERE inclut également une clause d'échantillonnage permettant de ne sélectionner que 1/1 000e des données.
- Définissez une variable nommée
TRAIN qui vous permettra de créer rapidement un ensemble EVAL indépendant.
- Maintenant que vous comprenez mieux l'objectif de cette requête, cliquez sur Exécuter.
Vous devriez obtenir un résultat semblable à celui-ci :
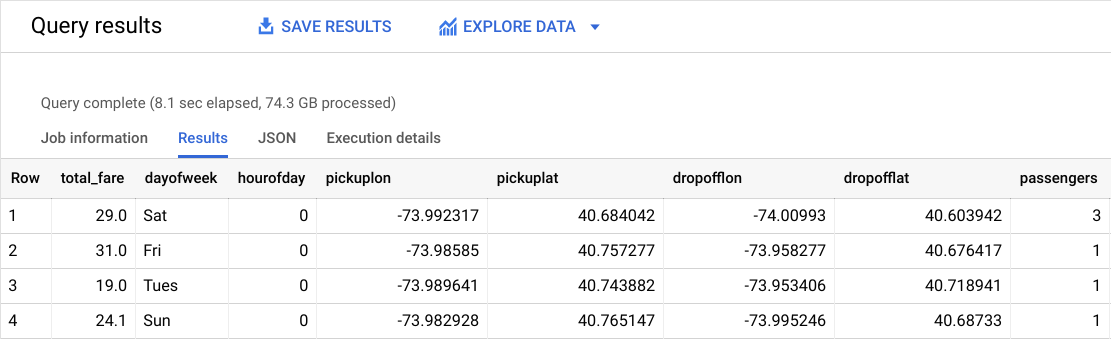
Quelle est l'étiquette (la réponse correcte) ?
total_fare (total de la course) est l'étiquette (ce que vous allez prédire). Ce champ découle de tolls_amount (tarif des péages) et de fare_amount (prix de la course). Vous pouvez donc ignorer les pourboires des clients dans le modèle étant donné qu'ils ne sont pas obligatoires.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
Tester si les champs conviennent pour établir le modèle de prévision du prix d'une course
Tâche 4 : Créer un ensemble de données BigQuery pour y stocker vos modèles
Dans cette section, vous allez créer un ensemble de données BigQuery dans lequel stocker vos modèles de ML.
-
Dans le panneau Explorateur de gauche, cliquez sur l'icône Afficher les actions à côté de l'ID de votre projet, puis sur Créer un ensemble de données.
-
Dans la boîte de dialogue "Créer un ensemble de données", saisissez les valeurs suivantes :
- Dans le champ ID de l'ensemble de données, saisissez taxi.
- Pour Type d'emplacement, sélectionnez us (plusieurs régions aux États-Unis).
- Conservez les valeurs par défaut dans les autres champs.
- Cliquez ensuite sur Créer l'ensemble de données.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
Créer un ensemble de données BigQuery pour y stocker vos modèles
Tâche 5 : Sélectionner un type de modèle BigQuery ML et définir les options correspondantes
Maintenant que vous avez sélectionné les caractéristiques de base, vous pouvez créer votre premier modèle de ML dans BigQuery.
Vous avez le choix entre plusieurs types de modèles :
-
Prévision de valeurs numériques comme les ventes des mois à venir, grâce à une régression linéaire (linear_reg).
-
Classification binaire ou multiclasse comme les emails indésirables ou non, grâce à la régression logistique (logistic_reg).
-
Clustering en k-moyennes si vous souhaitez un apprentissage non supervisé pour l'exploration (k-moyennes).
Remarque : Il existe de nombreux autres types de modèles pour le machine learning (comme les réseaux de neurones et les arbres de décision). Ceux-ci sont disponibles dans des bibliothèques telles que TensorFlow. Pour l'instant, BQML n'accepte que les trois types mentionnés ci-dessus. Pour en savoir plus, suivez la feuille de route BQML.
- Saisissez la requête suivante pour créer un modèle et définir ses options :
CREATE or REPLACE MODEL taxi.taxifare_model
OPTIONS
(model_type='linear_reg', labels=['total_fare']) AS
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
-
Cliquez ensuite sur Exécuter pour entraîner le modèle.
-
Attendez que le modèle soit entraîné (cela prend entre 5 et 10 minutes).
Une fois votre modèle entraîné, le message suivant s'affiche : "This statement will create a new model named qwiklabs-gcp-03-xxxxxxxx:taxi.taxifare_model." (Cette instruction va créer un modèle nommé qwiklabs-gqwiklabs-gcp-03-xxxxxxxx:taxi.taxifare_model). Il indique que votre modèle a bien été entraîné.
- Vérifiez que le code taxifare_model apparaît bien dans l'ensemble de données portant sur les taxis.
L'étape suivante consiste à évaluer les performances du modèle à partir de nouvelles données d'évaluation.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
Créer un modèle "taxifare" (prix de la course)
Tâche 6 : Évaluer les performances du modèle de classification
Sélectionner vos critères de performance
Pour les modèles de régression linéaire, vous devez utiliser une statistique de perte, à savoir la racine carrée de l'erreur quadratique moyenne (RMSE, Root Mean Square Error). L'objectif est de continuer à entraîner le modèle et à l'améliorer de manière que ce chiffre soit le plus bas possible.
Dans BQML, mean_squared_error est un champ pouvant faire l'objet de requêtes lors de l'évaluation de votre modèle de ML entraîné. Ajoutez SQRT() pour obtenir la valeur RMSE.
Maintenant que l'entraînement est terminé, vous pouvez utiliser la fonction ML.EVALUATE pour évaluer les performances du modèle à l'aide de cette requête :
- Copiez le texte suivant et collez-le dans l'éditeur de requête, puis cliquez sur Exécuter :
#standardSQL
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
Vous évaluez désormais le modèle par rapport à différentes courses de taxi avec votre filtre params.EVAL.
- Examinez les résultats après l'exécution du modèle. Il est normal que la valeur RMSE varie légèrement.
|
Ligne
|
rmse
|
|
1
|
9,477056435999074
|
Suite à l'évaluation du modèle, vous obtenez une RMSE de 9,47. Depuis que nous avons pris la racine de l'erreur quadratique moyenne (RMSE), l'erreur de 9,47 peut être évaluée dans les mêmes unités que le total_fare ; elle est donc de +- 9,47 $.
Cette statistique de perte peut s'avérer acceptable ou non pour produire ensuite le modèle. Tout dépend des critères d'analyse comparative définis en amont de la phase d'entraînement qui permettent de fixer un niveau minimal acceptable en termes de performances et de justesse.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
Évaluer les performances du modèle de classification
Tâche 7 : Prédire le prix d'une course en taxi
Vous allez maintenant créer une requête afin de réaliser des prédictions à l'aide du nouveau modèle.
- Copiez le texte suivant et collez-le dans l'éditeur de requête, puis cliquez sur Exécuter :
#standardSQL
SELECT
*
FROM
ml.PREDICT(MODEL `taxi.taxifare_model`,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
));
Les prédictions concernant le prix des courses s'affichent désormais, avec les prix réels et d'autres caractéristiques liées à ces trajets. Vos résultats doivent ressembler à ce qui suit :

Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
Prédire le prix d'une course en taxi
Tâche 8 : Améliorer le modèle avec l'ingénierie des caractéristiques
La création de modèles de machine learning est un processus itératif. Une fois que nous avons évalué les performances de notre modèle initial, nous allons régulièrement revenir dessus pour apporter des modifications aux caractéristiques et aux lignes afin de tenter de l'optimiser.
Filtrer l'ensemble de données d'entraînement
Examinez à présent les statistiques communes des prix de courses en taxi.
- Copiez le texte suivant et collez-le dans l'éditeur de requête, puis cliquez sur Exécuter :
SELECT
COUNT(fare_amount) AS num_fares,
MIN(fare_amount) AS low_fare,
MAX(fare_amount) AS high_fare,
AVG(fare_amount) AS avg_fare,
STDDEV(fare_amount) AS stddev
FROM
`nyc-tlc.yellow.trips`
# 1,108,779,463 fares
Vous devez obtenir un résultat semblable à celui-ci :
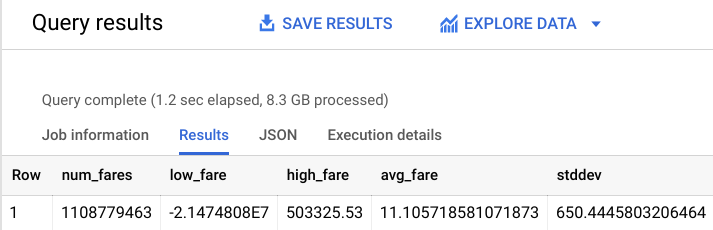
Comme vous le voyez, l'ensemble de données comporte certaines anomalies (courses aux montants négatifs ou supérieurs à 50 000 $). Appuyez-vous sur notre expertise en la matière pour éviter que le modèle ne les prenne en compte.
Vous allez restreindre les données aux tarifs compris entre 6 $ et 200 $.
- Copiez le texte suivant et collez-le dans l'éditeur de requête, puis cliquez sur Exécuter :
SELECT
COUNT(fare_amount) AS num_fares,
MIN(fare_amount) AS low_fare,
MAX(fare_amount) AS high_fare,
AVG(fare_amount) AS avg_fare,
STDDEV(fare_amount) AS stddev
FROM
`nyc-tlc.yellow.trips`
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
# 843,834,902 fares
Vous devez obtenir un résultat semblable à celui-ci :
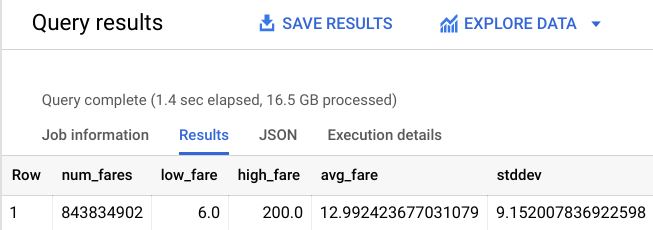
Voilà qui est un peu mieux. Pendant que vous y êtes, limitez la distance parcourue afin de vous concentrer sur la ville de New York.
- Copiez le texte suivant et collez-le dans l'éditeur de requête, puis cliquez sur Exécuter :
SELECT
COUNT(fare_amount) AS num_fares,
MIN(fare_amount) AS low_fare,
MAX(fare_amount) AS high_fare,
AVG(fare_amount) AS avg_fare,
STDDEV(fare_amount) AS stddev
FROM
`nyc-tlc.yellow.trips`
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
AND pickup_longitude > -75 #limiting of the distance the taxis travel out
AND pickup_longitude < -73
AND dropoff_longitude > -75
AND dropoff_longitude < -73
AND pickup_latitude > 40
AND pickup_latitude < 42
AND dropoff_latitude > 40
AND dropoff_latitude < 42
# 827,365,869 fares
Vous devez obtenir un résultat semblable à celui-ci :
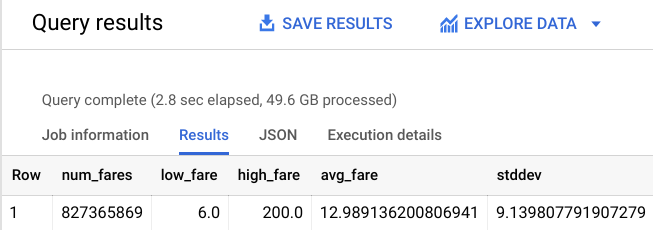
Vous disposez toujours d'un vaste ensemble de données d'entraînement du modèle, avec plus de 800 millions de trajets. Entraînez à nouveau le modèle avec ces nouvelles contraintes, et observez ses performances.
Recommencer l'entraînement du modèle
Appelez ce nouveau modèle taxi.taxifare_model_2 et entraînez à nouveau le modèle de régression linéaire pour prédire le total des courses. Vous remarquez que vous avez également ajouté quelques caractéristiques calculées pour la distance euclidienne (ligne droite) entre la prise en charge et le dépôt.
- Copiez le texte suivant et collez-le dans l'éditeur de requête, puis cliquez sur Exécuter :
CREATE OR REPLACE MODEL taxi.taxifare_model_2
OPTIONS
(model_type='linear_reg', labels=['total_fare']) AS
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
SQRT(POW((pickup_longitude - dropoff_longitude),2) + POW(( pickup_latitude - dropoff_latitude), 2)) as dist, #Euclidean distance between pickup and drop off
SQRT(POW((pickup_longitude - dropoff_longitude),2)) as longitude, #Euclidean distance between pickup and drop off in longitude
SQRT(POW((pickup_latitude - dropoff_latitude), 2)) as latitude, #Euclidean distance between pickup and drop off in latitude
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
AND pickup_longitude > -75 #limiting of the distance the taxis travel out
AND pickup_longitude < -73
AND dropoff_longitude > -75
AND dropoff_longitude < -73
AND pickup_latitude > 40
AND pickup_latitude < 42
AND dropoff_latitude > 40
AND dropoff_latitude < 42
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.TRAIN
)
SELECT *
FROM taxitrips
Le réentraînement du modèle peut prendre quelques minutes. Vous pouvez passer à l'étape suivante lorsque vous recevez le message suivant dans la console :
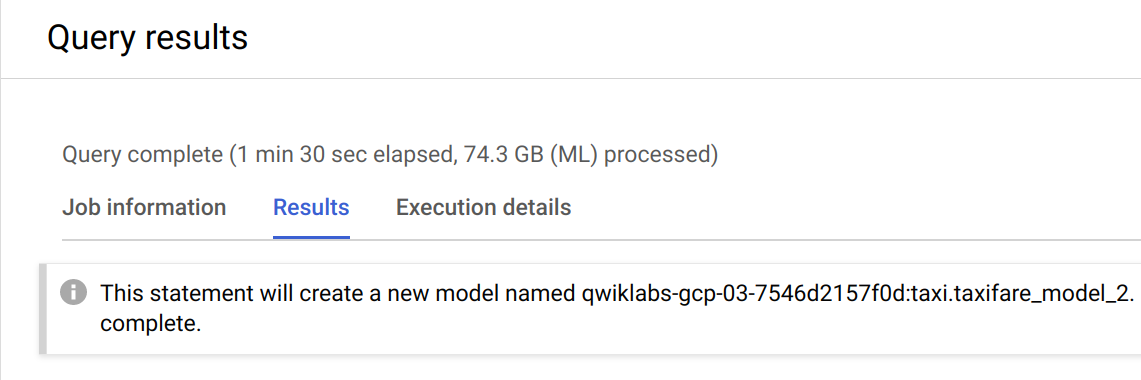
Évaluer le nouveau modèle
Maintenant que vous avez optimisé le modèle de régression linéaire, évaluez l'ensemble de données par rapport à ce modèle et observez ses performances.
- Copiez le texte suivant et collez-le dans l'éditeur de requête, puis cliquez sur Exécuter :
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model_2,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
SQRT(POW((pickup_longitude - dropoff_longitude),2) + POW(( pickup_latitude - dropoff_latitude), 2)) as dist, #Euclidean distance between pickup and drop off
SQRT(POW((pickup_longitude - dropoff_longitude),2)) as longitude, #Euclidean distance between pickup and drop off in longitude
SQRT(POW((pickup_latitude - dropoff_latitude), 2)) as latitude, #Euclidean distance between pickup and drop off in latitude
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE trip_distance > 0 AND fare_amount BETWEEN 6 and 200
AND pickup_longitude > -75 #limiting of the distance the taxis travel out
AND pickup_longitude < -73
AND dropoff_longitude > -75
AND dropoff_longitude < -73
AND pickup_latitude > 40
AND pickup_latitude < 42
AND dropoff_latitude > 40
AND dropoff_latitude < 42
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
Vous devez obtenir un résultat semblable à celui-ci :
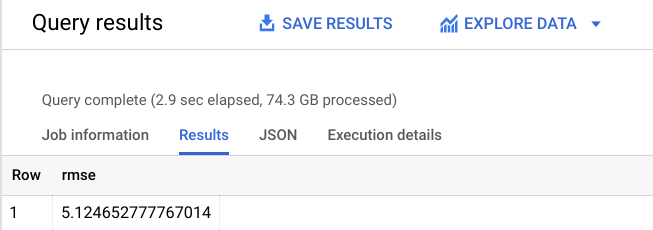
Comme vous pouvez le constater, la RMSE avoisine +-5,12 $, ce qui est nettement mieux que les +-9,47 $ obtenus pour votre premier modèle.
Dans la mesure où la RMSE définit l'écart-type des erreurs de prédiction, nous constatons que le réentraînement de la régression linéaire a considérablement accru la précision de notre modèle.
Tâche 9 : Tester vos connaissances
Voici quelques questions à choix multiples qui vous permettront de mieux maîtriser les concepts abordés lors de cet atelier. Répondez-y du mieux que vous le pouvez.
Tâche 10 : Autres ensembles de données à explorer
Vous pouvez utiliser le projet bigquery-public-data si vous souhaitez découvrir la modélisation d'autres ensembles de données, par exemple pour prédire le tarif de courses en taxi à Chicago.
-
Pour ouvrir l'ensemble de données bigquery-public-data, cliquez sur + Ajouter > Ajouter un projet aux favoris en saisissant son nom > Saisir le nom du projet, puis saisissez le nom bigquery-public-data.
-
Cliquez sur Ajouter aux favoris.
Le projet bigquery-public-data apparaît désormais dans la section "Explorateur".
Félicitations !
Vous avez créé un modèle de machine learning dans BigQuery permettant de prédire le prix d'une course en taxi à New York.
Étapes suivantes et informations supplémentaires
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 7 février 2024
Dernier test de l'atelier : 24 août 2023
Copyright 2025 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.





