체크포인트
Create a dataset
/ 25
Load Data to BigQuery Tables
/ 25
Explore and Investigate the Data with BigQuery
/ 10
Prepare Your Data
/ 10
Train an Unsupervised Model to Detect Anomalies
/ 10
Train a Supervised Machine Learning Model
/ 10
Predict Fraudulent Transactions on Test Data
/ 10
Google Cloud의 머신러닝으로 금융 거래 사기 감지
GSP774

개요
이 실습에서는 BigQuery ML을 사용하여 사기 분석을 위해 금융 거래 데이터를 탐색하고 특성 추출과 머신러닝 기술을 적용하여 허위 행위를 감지합니다.
공개 금융 거래 데이터가 사용됩니다. 데이터에는 다음 열이 포함됩니다.
- 거래 유형
- 이체 금액
- 송금 및 수취 계좌 ID
- 신규 및 기존 잔액
- 거래의 상대 시간(30일 기간의 시작을 기준으로 경과한 시간)
-
isfraud플래그
타겟 열 isfraud에는 사기 거래를 나타내는 라벨이 포함됩니다. 이러한 라벨을 사용하여 사기 감지를 위한 지도 모델을 학습시키고 비지도 모델을 적용하여 이상치를 감지합니다.
The data for this lab is from the Kaggle site. If you do not have a Kaggle account, it's free to create one.
학습할 내용:
- BigQuery로 데이터를 로드하고 탐색합니다.
- BigQuery에서 새 특성을 만듭니다.
- 이상 감지를 위한 비지도 모델을 빌드합니다.
- 사기 감지를 위한 지도 모델(로지스틱 회귀 및 부스팅된 트리 포함)을 빌드합니다.
- 모델을 평가 및 비교하고 가장 우수한 모델을 선택합니다.
- 선택한 모델을 사용하여 테스트 데이터에서 사기 가능성을 예측합니다.
이 실습에서는 특성 추출, 모델 개발, 평가, 예측을 위해 BigQuery 인터페이스를 사용합니다.
Participants that prefer Notebooks as the model development interface may choose to build models in AI Platform Notebooks instead of BigQuery ML. Then at the end of the lab, you can also complete the optional section. You can import open source libraries and create custom models or you can call BigQuery ML models within Notebooks using BigQuery magic commands.
If you want to train models in an automated way without any coding, you can use Google Cloud AutoML which builds models using state-of-the-art algorithms. The training process for AutoML would take almost 2 hours, that's why it is recommended to initiate it at the beginning of the lab, as soon as the data is prepared, so that you can see the results at the end. Check for the "Attention" phrase at the end of the data preparation step.
설정 및 요건
실습 시작 버튼을 클릭하기 전에
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머에는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지 표시됩니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 직접 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
- 표준 인터넷 브라우저 액세스 권한(Chrome 브라우저 권장)
- 실습을 완료하기에 충분한 시간---실습을 시작하고 나면 일시중지할 수 없습니다.
실습을 시작하고 Google Cloud 콘솔에 로그인하는 방법
-
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 팝업이 열립니다. 왼쪽에는 다음과 같은 항목이 포함된 실습 세부정보 패널이 있습니다.
- Google 콘솔 열기 버튼
- 남은 시간
- 이 실습에 사용해야 하는 임시 사용자 인증 정보
- 필요한 경우 실습 진행을 위한 기타 정보
-
Google 콘솔 열기를 클릭합니다. 실습에서 리소스가 가동된 후 로그인 페이지가 표시된 다른 탭이 열립니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
참고: 계정 선택 대화상자가 표시되면 다른 계정 사용을 클릭합니다. -
필요한 경우 실습 세부정보 패널에서 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다. 다음을 클릭합니다.
-
실습 세부정보 패널에서 비밀번호를 복사하여 시작 대화상자에 붙여넣습니다. 다음을 클릭합니다.
중요: 왼쪽 패널에 표시된 사용자 인증 정보를 사용해야 합니다. Google Cloud Skills Boost 사용자 인증 정보를 사용하지 마세요. 참고: 이 실습에 자신의 Google Cloud 계정을 사용하면 추가 요금이 발생할 수 있습니다. -
이후에 표시되는 페이지를 클릭하여 넘깁니다.
- 이용약관에 동의합니다.
- 임시 계정이므로 복구 옵션이나 2단계 인증을 추가하지 않습니다.
- 무료 평가판을 신청하지 않습니다.
잠시 후 Cloud 콘솔이 이 탭에서 열립니다.

Cloud Shell 활성화
Cloud Shell은 다양한 개발 도구가 탑재된 가상 머신으로, 5GB의 영구 홈 디렉터리를 제공하며 Google Cloud에서 실행됩니다. Cloud Shell을 사용하면 명령줄을 통해 Google Cloud 리소스에 액세스할 수 있습니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화
를 클릭합니다.
연결되면 사용자 인증이 이미 처리된 것이며 프로젝트가 PROJECT_ID로 설정됩니다. 출력에 이 세션의 PROJECT_ID를 선언하는 줄이 포함됩니다.
gcloud는 Google Cloud의 명령줄 도구입니다. Cloud Shell에 사전 설치되어 있으며 명령줄 자동 완성을 지원합니다.
- (선택사항) 다음 명령어를 사용하여 활성 계정 이름 목록을 표시할 수 있습니다.
-
승인을 클릭합니다.
-
다음과 비슷한 결과가 출력됩니다.
출력:
- (선택사항) 다음 명령어를 사용하여 프로젝트 ID 목록을 표시할 수 있습니다.
출력:
출력 예시:
gcloud 전체 문서는 Google Cloud에서 gcloud CLI 개요 가이드를 참조하세요.
작업 1. 실습용 데이터 파일 다운로드
- 다음을 실행하여 데이터 파일을 프로젝트에 다운로드합니다.
- 메시지가 표시되면 승인을 클릭합니다.
- zip 파일을 업로드한 후 다음
unzip명령어를 실행합니다.
파일 1개가 확장된 것을 확인할 수 있습니다.
- 나중에 이 파일을 더 쉽게 참조할 수 있도록 파일 이름의 환경 변수를 만듭니다.
- 다음을 실행하여 실습의 프로젝트 ID를 찾은 후 복사합니다.
- 프로젝트 ID의 환경 변수를 만들고 <project_id>를 복사한 프로젝트 ID로 바꿉니다.
- Cloud Shell에서 다음을 실행하여 이 실습의 테이블과 모델을 저장할
finance라는 BigQuery 데이터 세트를 만듭니다.
위 명령어를 성공적으로 실행하면 다음과 같은 결과가 출력됩니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 2. Cloud Storage에 데이터 세트 복사
- 다음을 실행하여 고유한 프로젝트 ID를 이름으로 사용하여 Cloud Storage 버킷을 만듭니다.
- csv 파일을 새로 만든 버킷에 복사합니다.
작업 3. BigQuery 테이블로 데이터 로드
BigQuery로 데이터를 로드하려면 BigQuery 사용자 인터페이스나 Cloud Shell의 명령어 터미널을 사용하면 됩니다. 아래 옵션 중 하나를 선택하여 데이터를 로드합니다.
옵션 1: 명령줄
- 다음 명령어를 실행하여
finance.fraud_data테이블로 데이터를 로드합니다.
--autodetect 옵션은 테이블의 스키마(변수 이름, 유형 등)를 자동으로 읽습니다.
옵션 2: BigQuery 사용자 인터페이스
Cloud 콘솔에서 BigQuery를 열어 Cloud Storage 버킷의 데이터를 로드할 수 있습니다.
- '탐색기' 섹션에서 프로젝트 ID 옆의 '노드 펼치기'를 클릭합니다.
- finance 데이터 세트 옆의 작업 보기를 클릭한 다음 테이블 만들기를 클릭합니다.
-
'테이블 만들기' 팝업 창에서
Source를 Google Cloud Storage로 설정하고 Cloud Storage 버킷에서 원시 csv 파일을 선택합니다. -
테이블 이름으로 fraud_data를 입력하고 스키마에서 자동 감지 옵션을 선택하면 원시 파일의 첫 번째 줄에서 변수 이름을 자동으로 읽습니다.
-
테이블 만들기를 클릭합니다.
로드하는 데 1~2분 정도 걸릴 수 있습니다.
- 완료되면 BigQuery의 '탐색기' 패널 뷰에서 finance 데이터 세트를 클릭한 후 fraud_data 테이블을 찾아 메타데이터를 확인하고 테이블 데이터를 미리 봅니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 4. BigQuery를 사용하여 데이터 탐색 및 조사
아직 Cloud 콘솔에서 BigQuery를 열지 않았으면 지금 엽니다.
- 탐색 메뉴 > BigQuery를 클릭합니다.
다음으로 데이터를 더 잘 이해하고 머신러닝 모델에 맞게 준비하기 위해 데이터 탐색을 시작합니다.
-
쿼리 편집기에 다음 쿼리를 추가한 후 실행을 클릭하고 데이터를 탐색합니다.
-
새 쿼리 작성을 클릭하여 다음 쿼리를 시작합니다. 이렇게 하면 작업이 완료된 후 결과를 쉽게 비교할 수 있습니다.
- 거래 유형별 사기 거래 건수는 얼마나 되나요?
isFraud 열에서 1이 yes(예)임을 확인합니다.
- 다음을 실행하여 TRANSFER 및 CASH_OUT 거래 유형에 대한 허위 행위의 비율을 확인합니다(
isFraud개수 제공).
- 다음을 실행하여 상위 10개의 최대 거래 금액을 확인합니다.
잠시 멈춰 생각해 보기:
- 거래에 특이한 잔액이 있다는 사실을 발견했나요? 송금 계좌의 잔액이 0인 경우 어떻게 거래를 할 수 있나요? 송금 후 수취 계좌의 새 잔액이 0으로 유지되는 이유는 무엇인가요? 이러한 사례에 플래그를 지정하고 다음 단계에서 새로운 특성으로 추가하겠습니다.
- 데이터가 불균형하다고 생각하나요? 그렇다면 사기 거래 비율이 1%보다 훨씬 적나요?
isfraud수를 총 관찰 수로 나누면 사기 거래의 비율을 구할 수 있습니다.
다음 섹션에서는 이러한 질문을 처리하고 머신러닝 모델의 데이터를 개선하는 방법을 살펴보겠습니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 5. 데이터 준비
새로운 특성을 추가하고, 불필요한 거래 유형을 필터링하고, 언더샘플링 적용을 통해 타겟 변수 isFraud의 비율을 높여 모델링 데이터를 개선할 수 있습니다.
분석 단계의 결과에 따라 거래 유형 TRANSFER와 CASH_OUT만 분석하고 나머지는 필터링하면 됩니다. 기존 금액 값에서 새 변수를 계산할 수도 있습니다.
데이터 세트에는 매우 불균형한 사기 타겟이 포함되어 있습니다(원시 데이터의 사기 비율 = 0.0013%). 사기의 경우 이벤트가 드문 것이 일반적입니다. 머신러닝 알고리즘에서 허위 행위의 패턴을 더욱 명확하게 만들고 결과를 쉽게 해석할 수 있도록 데이터를 계층화하고 사기 플래그의 비율을 높여 보겠습니다.
- 다음 단계에서는 새 쿼리를 작성하고, 다음 코드를 추가하여 데이터에 새로운 특성을 추가하고, 불필요한 거래 유형을 필터링하고, 언더샘플링이 적용된 사기가 아닌 거래의 하위 집합을 선택합니다.
-
쿼리를 실행합니다.
-
20%의 무작위 표본을 선택하여 TEST 데이터 테이블을 만듭니다.
- 쿼리를 실행합니다.
이 데이터는 별도로 보관되며 학습에 포함되지 않습니다. 최종 단계에서 모델을 스코어링하는 데 사용할 것입니다.
BigQuery ML과 AutoML은 학습 및 검증 데이터 모두에 대한 오류율을 테스트하고 과적합을 방지하기 위해 머신러닝 알고리즘을 사용하는 동안 모델 데이터를 TRAIN과 VALIDATE로 자동 분할합니다.
- 다음을 실행하여 샘플 데이터를 생성합니다.
모델링을 위해 생성한 샘플 데이터에는 약 228,000행의 은행 거래가 포함되어 있습니다.
특히 AutoML 또는 AI Platform과 같은 서로 다른 환경의 모델을 비교하고 일관성을 유지하려는 경우 데이터 세트를 TRAIN/VALIDATE 및 TEST로 직접 분할할 수도 있습니다.
잠시 멈춰 생각해 보기:
- 데이터에 라벨이 지정된 사기 이벤트가 없는 문제는 어떻게 접근할 수 있을까요? 라벨이 지정된 거래가 없는 경우 비지도 모델링 기법을 사용하여 k-평균 클러스터링과 같은 데이터의 이상치를 분석할 수 있습니다. 다음 섹션에서는 이 방법을 직접 시도해 보겠습니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 6. 이상치를 감지하도록 비지도 모델 학습
비지도 방법은 데이터의 비정상적인 동작을 탐색하기 위해 사기 감지에 일반적으로 사용됩니다. 이는 사기를 나타내는 라벨이 없거나 이벤트 비율이 매우 낮고 발생 횟수로 인해 지도 모델을 빌드할 수 없는 경우에도 도움이 됩니다.
이 섹션에서는 k-평균 클러스터링 알고리즘을 사용하여 거래의 세그먼트를 만들고 각 세그먼트를 분석하고 이상치가 있는 세그먼트를 감지합니다.
- 새 쿼리를 작성하고 BigQuery에서 CREATE OR REPLACE MODEL 문을 포함한 아래 코드를 실행하고 model_type을
kmeans로 설정합니다.
그러면 fraud_data_model에서 선택한 변수를 사용하여 5개의 클러스터로 model_unsupervised라는 k-평균 모델이 만들어집니다.
모델이 학습을 마치면 재무 > 모델 아래에 해당 모델이 표시됩니다.
- model_unsupervised를 클릭한 다음 평가 탭을 클릭합니다.
k-평균 알고리즘은 centroid_id라는 출력 변수를 생성합니다. 각 거래는 centroid_id에 할당됩니다. 서로 유사하거나 더 가까운 거래는 알고리즘에 의해 동일한 클러스터에 할당됩니다.
데이비스-볼딘 지수는 클러스터가 얼마나 동질적인지를 나타냅니다. 값이 낮을수록 클러스터가 서로 더 멀리 떨어져 있으며, 이는 원하는 결과입니다.
숫자 특성은 '평가' 탭에서 각 중심(클러스터)의 막대 그래프와 함께 표시됩니다. 막대 옆의 숫자는 각 클러스터 내 변수의 평균 값을 나타냅니다. 가장 좋은 방법은 클러스터링을 위한 거리 계산에서 큰 숫자 또는 이상점의 영향을 피하기 위해 입력 변수를 표준화하거나 버킷으로 그룹화하는 것입니다. 이 실습에서는 편의상 이 연습에 원래 변수를 사용합니다.
입력으로 사용되는 범주형 변수는 별도로 표시됩니다. 아래의 각 세그먼트에서 TRANSFER 및 CASH_OUT 거래의 분포를 확인할 수 있습니다.
그래프는 모델에 따라 다르게 보일 수 있으므로 더 작은 세그먼트에 초점을 맞추고 분포를 해석해 보세요.
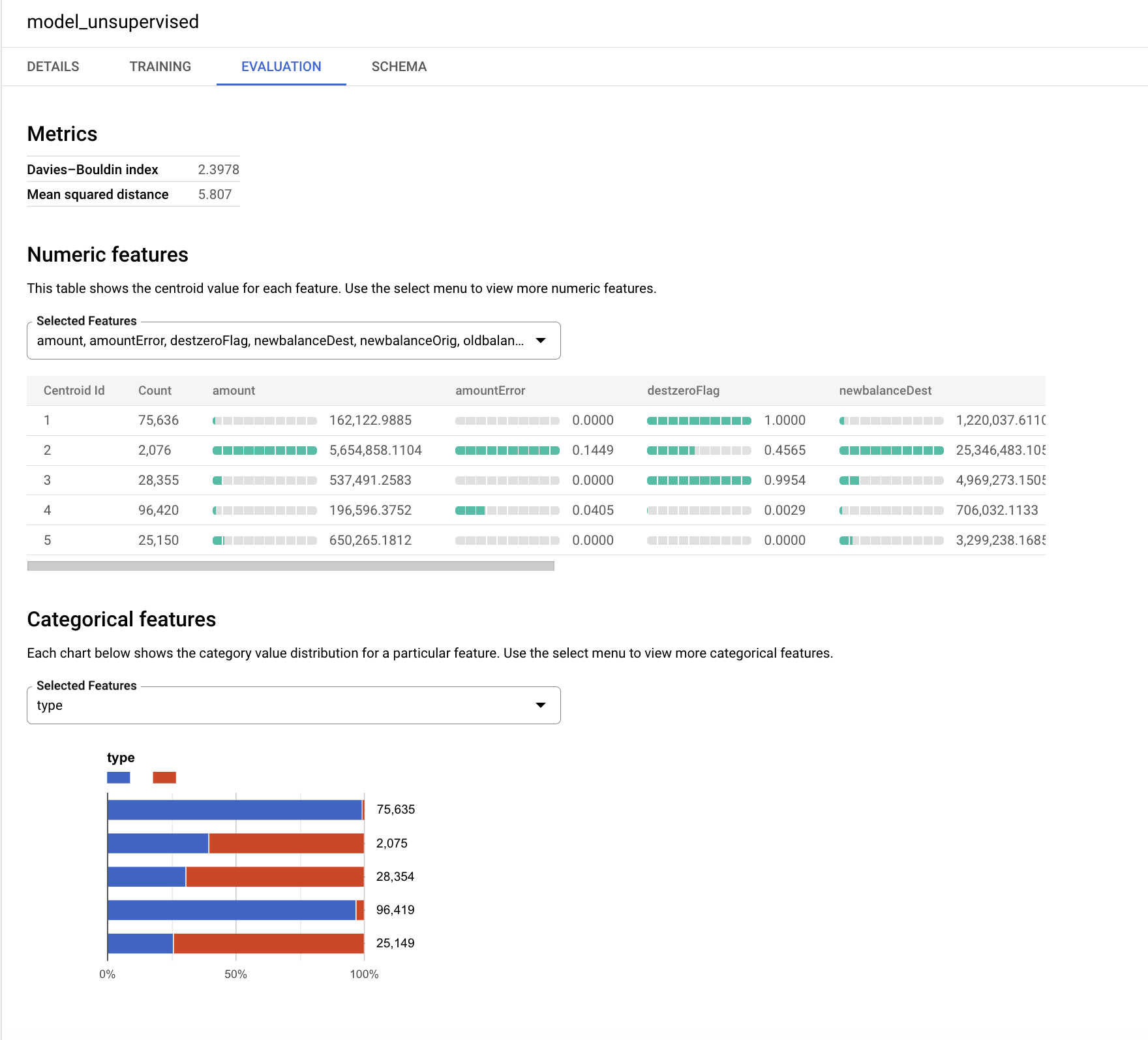
이 비지도 모델에서는 타겟 변수 isFraud가 사용되지 않았습니다. 이 연습에서는 프로파일링을 위해 해당 변수를 저장하고 이를 사용하여 각 클러스터 내의 허위 행위 분포를 탐색하는 것이 좋습니다.
-
이 모델을 사용하여 테스트 데이터(
fraud_data_test)를 스코어링하고 각centroid_id에서 사기 이벤트 수를 확인하세요. 클러스터링 알고리즘은 동종 관찰 그룹을 생성합니다. 이 쿼리에서ML.PREDICT는 모델을 호출하고 테스트 데이터의 각 거래에 대해centroid_id를 생성합니다. -
새 쿼리에서 다음 코드를 실행합니다.
잠시 멈춰 생각해 보기:
- 어떤 클러스터가 가장 흥미롭다고 생각하시나요? 오류 양이 많은 작은 클러스터일 것입니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 7. 지도 머신러닝 모델 학습
이제 사기 거래 가능성을 예측하도록 BigQuery ML을 사용하여 지도 모델을 빌드할 준비가 되었습니다. 간단한 모델로 시작 - BigQuery ML을 사용하여 분류를 위한 바이너리 로지스틱 회귀 모델을 만듭니다. 이 모델은 거래가 사기일 가능성이 있는지를 예측하려고 시도합니다.
숫자가 아닌 모든(범주형) 변수에 대해 BigQuery ML은 자동으로 원-핫 인코딩 변환을 수행합니다. 이 변환은 변수의 각 고유한 값에 대해 별도의 특성을 생성합니다. 이 연습에서는 BigQuery ML이 자동으로 TYPE 변수에 대해 원-핫 인코딩을 수행합니다.
- 첫 번째 지도 모델을 만들려면 BigQuery에서 다음 SQL 문을 실행합니다.
준비되면 재무 > 모델 아래에 model_supervised_initial 테이블이 추가됩니다.
모델이 생성되면 BigQuery 콘솔 UI에서 모델 메타데이터, 학습, 평가 통계를 가져올 수 있습니다.
- 왼쪽 패널에서 model_supervised_initial을 클릭하고 세부정보, 학습, 평가 또는 스키마 탭을 클릭하여 자세한 정보를 확인합니다.
평가 탭에서 분류 모델과 관련된 다양한 성능 측정항목을 찾을 수 있습니다.
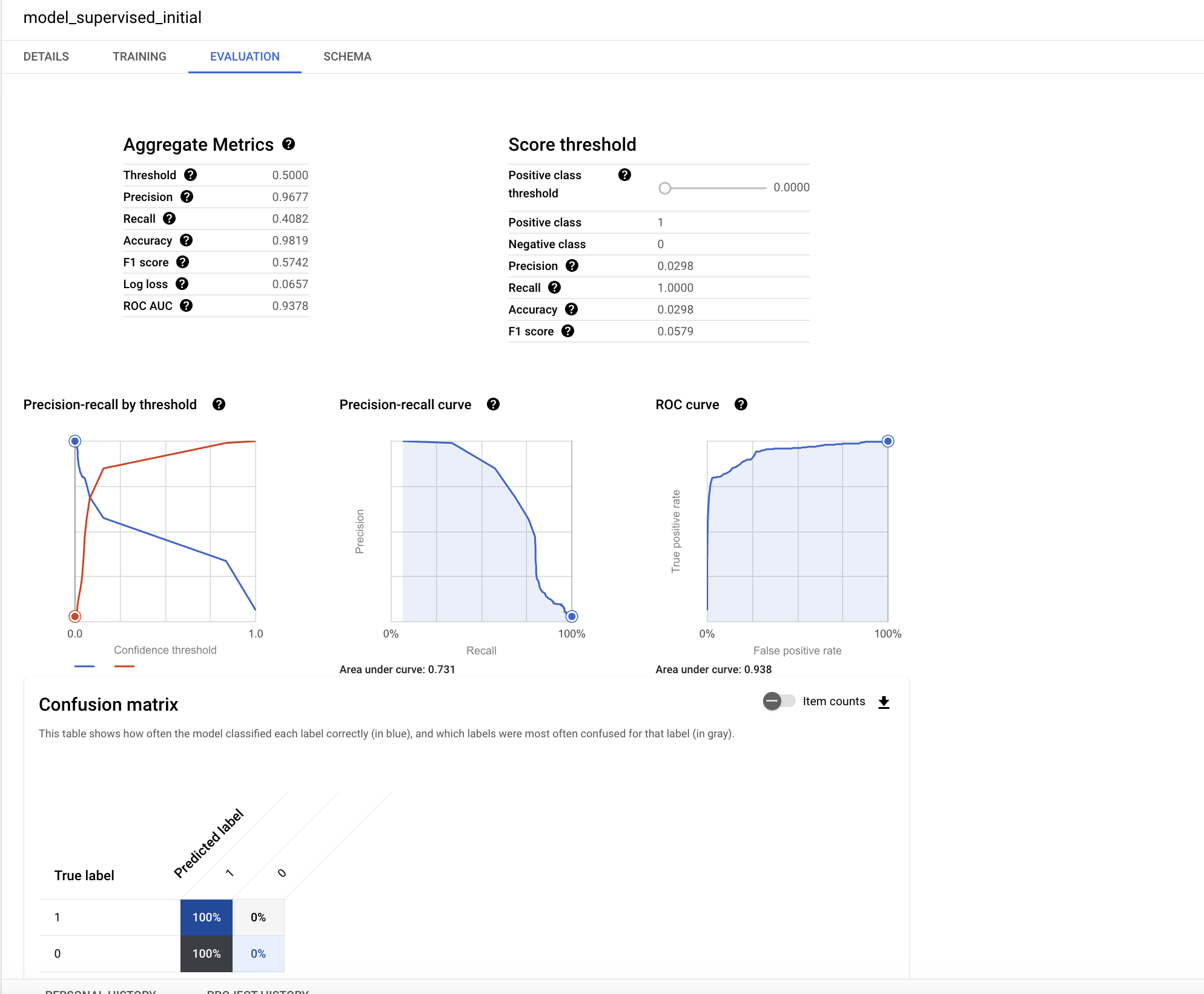
모델 성능에 대한 이해는 머신러닝에서 가장 중요한 부분입니다. 분류를 위해 로지스틱 회귀를 수행했으므로 다음 주요 개념을 이해하면 도움이 됩니다.
- 정밀도: 정밀도는 모델에서 정확히 맞추었던 양성 사례의 선택 비율을 식별합니다.
- 재현율: 가능한 모든 실제 양성 라벨 중 모델이 정확히 식별한 라벨 수를 나타내는 측정항목입니다.
- 정확성: 정확성은 전체 예측 중 정확한 예측의 비율입니다.
- f1 점수: 모델 정확성을 나타내는 척도입니다. f1 점수는 정밀도와 재현율의 조화 평균으로, 0에서 1 사이의 값을 가지며 높을수록 좋습니다.
- roc, auc: ROC 곡선 아래 영역입니다. 서로 다른 임곗값을 고려하여 바이너리 분류기의 식별 기능에 대한 정보를 제공하고 0과 1 사이의 값을 가지며 높을수록 좋습니다. 중간 모델의 경우 ROC 값이 0.7보다 클 것으로 예상됩니다.
이 Wikipedia 페이지의 그래프는 정밀도와 재현율의 개념을 잘 설명합니다.
이 회귀 모델의 ROC 값은 매우 높습니다. 다양한 확률 임곗값에 대한 결과를 테스트하여 정확성을 더 잘 파악할 수 있습니다.
이제 모델에서 가장 영향력 있는 특성을 살펴봅니다.
- 다음 쿼리를 실행하여 특성의 중요도를 확인합니다.
가중치는 표준화 옵션을 사용하여 변수 척도의 영향을 제거하기 위해 표준화됩니다. 가중치가 클수록 더 중요합니다. 가중치의 부호는 타겟과의 직접 또는 반비례 관계에 따라 방향을 나타냅니다.
잠시 멈춰 생각해 보기:
- 가장 중요해 보이는 두 가지 변수는 무엇인가요?
oldbalanceOrig와type이 가장 중요한 변수입니다.

내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 8. 모델 개선
이제 재미있는 연습을 해보세요. 새 모델을 만들고 두 모델을 학습시켜 정확성을 높입니다.
- 다음을 실행하여 새로운 경사 부스트 모델을 만듭니다.
다음으로 만든 2개의 모델을 비교하고 가장 좋은 모델을 선택합니다.
작업 9. 지도 머신러닝 모델 평가
새 변수를 추가하여 기존 로지스틱 회귀 모델을 개선하세요.
모델을 만든 후 ML.EVALUATE 함수를 사용하여 분류기의 성능을 평가할 수 있습니다. ML.EVALUATE 함수는 실제 데이터를 기준으로 결과 또는 예측값을 평가합니다.
- 다음 쿼리를 실행하여 두 모델의 결과를 단일 테이블에 추가하고 새 데이터를 스코어링하는 데 사용할 챔피언 모델을 선택합니다.
잠시 멈춰 생각해 보기:
- 어느 모델의 성능이 가장 우수한가요? 처음에는 회귀 모델을 실행했습니다. 그런 다음 더 많은 변수를 추가하고 회귀를 사용하여 새 모델을 학습시켰습니다(지도 모델). 마지막으로 두 번째 지도 모델로 부스팅된 트리를 사용했습니다. 성능 테이블 비교 시 부스팅된 트리 모델의 성능이 더 좋습니다. 새로운 특성을 더 추가하여 모델의 정확성이 향상되었습니다.
작업 10. 테스트 데이터에 대한 사기 거래 예측
머신러닝의 마지막 단계는 가장 성능이 우수한 모델을 사용하여 새로운 데이터 세트에 대한 결과를 예측하는 것입니다.
BQML의 머신러닝 알고리즘은 predicted_<target_name\>_probs라는 중첩 변수를 만듭니다. 이 변수는 모델 결정을 위한 확률 점수를 포함합니다. 모델 결정은 사기 또는 진짜입니다.
- BigQuery에서 다음 쿼리를 실행하여 실습 시작 시 만든 테스트 데이터에 대한 사기 거래 예측을 확인합니다. 아래 WHERE 문은 확률 점수가 가장 높은 거래를 가져옵니다.
잠시 멈춰 생각해 보기:
- 예측된 거래 세트에서 허위 행위의 비율은 얼마인가요? 3% 미만
- 전체 테스트 데이터와 비교하여 예측된 행 집합에서 이벤트 비율이 얼마나 증가했나요? 95% 초과
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
수고하셨습니다
다음 단계
- Google Developers 단기집중과정에서 머신러닝에 대해 자세히 알아보세요.
Google Cloud 교육 및 자격증
Google Cloud 기술을 최대한 활용하는 데 도움이 됩니다. Google 강의에는 빠른 습득과 지속적인 학습을 지원하는 기술적인 지식과 권장사항이 포함되어 있습니다. 기초에서 고급까지 수준별 학습을 제공하며 바쁜 일정에 알맞은 주문형, 실시간, 가상 옵션이 포함되어 있습니다. 인증은 Google Cloud 기술에 대한 역량과 전문성을 검증하고 입증하는 데 도움이 됩니다.
설명서 최종 업데이트: 2023년 10월 12일
실습 최종 테스트: 2023년 10월 12일
Copyright 2024 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.