Points de contrôle
Create a dataset
/ 25
Load Data to BigQuery Tables
/ 25
Explore and Investigate the Data with BigQuery
/ 10
Prepare Your Data
/ 10
Train an Unsupervised Model to Detect Anomalies
/ 10
Train a Supervised Machine Learning Model
/ 10
Predict Fraudulent Transactions on Test Data
/ 10
Détecter la fraude dans les transactions financières à l'aide du machine learning sur Google Cloud
- GSP774
- Présentation
- Préparation
- Tâche 1 : Télécharger le fichier de données de l'atelier
- Tâche 2 : Copier l'ensemble de données dans Cloud Storage
- Tâche 3 : Charger les données dans des tables BigQuery
- Tâche 4 : Explorer et analyser les données avec BigQuery
- Tâche 5 : Préparer vos données
- Tâche 6 : Entraîner un modèle non supervisé pour détecter les anomalies
- Tâche 7 : Entraîner un modèle de machine learning supervisé
- Tâche 8 : Améliorer votre modèle
- Tâche 9 : Évaluer vos modèles de machine learning supervisé
- Tâche 10 : Prédire les transactions frauduleuses dans des données de test
- Félicitations !
GSP774

Présentation
Dans cet atelier, vous allez explorer les données de transactions financières pour analyser les fraudes, et appliquer des techniques d'ingénierie des caractéristiques et de machine learning pour détecter les activités frauduleuses à l'aide de BigQuery ML.
Vous utiliserez des données de transactions financières publiques. Ces données comportent les colonnes suivantes :
- Type de transaction
- Montant transféré
- ID des comptes de provenance et de destination
- Solde avant et après la transaction
- Durée relative de la transaction (c'est-à-dire le nombre d'heures écoulées depuis le début de la période de 30 jours)
- Option
isFraud
La colonne cible isFraud inclut les étiquettes pour les transactions frauduleuses. Vous utiliserez ces étiquettes pour entraîner des modèles supervisés destinés à la détection des fraudes et appliquerez des modèles non supervisés pour détecter les anomalies.
The data for this lab is from the Kaggle site. If you do not have a Kaggle account, it's free to create one.
Points abordés :
- Charger des données dans BigQuery et les explorer
- Créer des caractéristiques dans BigQuery
- Créer un modèle non supervisé pour la détection des anomalies
- Créer des modèles supervisés (avec régression logistique et arbre de décision à boosting) pour la détection des fraudes
- Évaluer et comparer les modèles, et sélectionner le champion
- Utiliser le modèle sélectionné pour prédire la probabilité de fraude dans les données de test
Dans cet atelier, vous allez utiliser l'interface de BigQuery pour l'ingénierie des caractéristiques, le développement du modèle, l'évaluation et la prédiction.
Participants that prefer Notebooks as the model development interface may choose to build models in AI Platform Notebooks instead of BigQuery ML. Then at the end of the lab, you can also complete the optional section. You can import open source libraries and create custom models or you can call BigQuery ML models within Notebooks using BigQuery magic commands.
If you want to train models in an automated way without any coding, you can use Google Cloud AutoML which builds models using state-of-the-art algorithms. The training process for AutoML would take almost 2 hours, that's why it is recommended to initiate it at the beginning of the lab, as soon as the data is prepared, so that you can see the results at the end. Check for the "Attention" phrase at the end of the data preparation step.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google. L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte. -
Si nécessaire, copiez le nom d'utilisateur inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue Se connecter. Cliquez sur Suivant.
-
Copiez le mot de passe inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue de bienvenue. Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis dans le panneau de gauche. Ne saisissez pas vos identifiants Google Cloud Skills Boost. Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés. -
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas aux essais offerts.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
- Cliquez sur Activer Cloud Shell
en haut de la console Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Le résultat contient une ligne qui déclare YOUR_PROJECT_ID (VOTRE_ID_PROJET) pour cette session :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
-
Cliquez sur Autoriser.
-
Vous devez à présent obtenir le résultat suivant :
Résultat :
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
Résultat :
Exemple de résultat :
gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Tâche 1 : Télécharger le fichier de données de l'atelier
- Exécutez la commande suivante pour télécharger le fichier de données dans votre projet :
- Cliquez sur Autoriser si vous y êtes invité.
- Après avoir importé le fichier ZIP, exécutez la commande
unzip:
Le résultat indique qu'un fichier a été décompressé.
- Afin de faciliter les références ultérieures à ce fichier, créez une variable d'environnement pour le nom du fichier :
- Exécutez la commande suivante pour afficher l'ID du projet de votre atelier, puis copiez l'ID :
- Créez une variable d'environnement pour l'ID du projet et remplacez <project_id> par l'ID copié :
- Exécutez la commande suivante afin de créer un ensemble de données BigQuery appelé
financepour stocker les tables et les modèles de cet atelier dans Cloud Shell :
Si la commande s'exécute correctement, vous obtiendrez le résultat suivant :
Cliquez sur Vérifier ma progression pour valider l'objectif.
Tâche 2 : Copier l'ensemble de données dans Cloud Storage
- Exécutez la commande suivante pour créer un bucket Cloud Storage dont le nom sera l'ID unique de votre projet :
- Copiez votre fichier CSV dans ce nouveau bucket :
Tâche 3 : Charger les données dans des tables BigQuery
Pour charger vos données dans BigQuery, vous pouvez utiliser l'interface utilisateur de BigQuery ou le terminal de commande dans Cloud Shell. Choisissez l'une des options ci-dessous :
Option 1 : Ligne de commande
- Exécutez la commande suivante pour charger les données dans la table
finance.fraud_data:
L'option --autodetect lira automatiquement le schéma de la table (le nom et type des variables, etc.).
Option 2 : Interface utilisateur de BigQuery
Pour charger les données à partir de votre bucket Cloud Storage, ouvrez BigQuery dans la console Cloud.
- Dans la section "Explorateur", cliquez sur "Développer le nœud" à côté de l'ID de votre projet.
- Cliquez sur Afficher les actions à côté de l'ensemble de données finance, puis cliquez sur Créer une table.
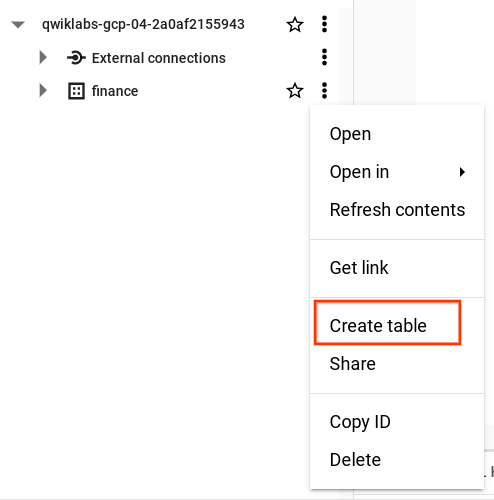
-
Dans la fenêtre pop-up "Créer une table", définissez
Sourcesur Google Cloud Storage et sélectionnez le fichier CSV brut dans votre bucket Cloud Storage. -
Saisissez fraud_data comme nom de table. Sous "Schéma", sélectionnez l'option Détection automatique pour que le nom des variables soit lu automatiquement à partir de la première ligne du fichier brut.
-
Cliquez sur Créer une table.
Le processus de chargement peut prendre une à deux minutes.
- Une fois le chargement terminé, dans le panneau "Explorateur" de BigQuery, cliquez sur l'ensemble de données finance et recherchez la table fraud_data afin de consulter les métadonnées et de prévisualiser les données de la table.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Tâche 4 : Explorer et analyser les données avec BigQuery
Si ce n'est pas encore fait, ouvrez BigQuery dans la console Cloud.
- Cliquez sur le menu de navigation > BigQuery.
Vous allez maintenant commencer à explorer les données afin de mieux les comprendre et de les préparer pour les modèles de machine learning.
-
Ajoutez les requêtes suivantes dans l'éditeur de requête, cliquez sur EXÉCUTER, puis explorez les données.
-
Cliquez sur SAISIR UNE NOUVELLE REQUÊTE pour lancer la suivante. Cela vous permettra de comparer facilement les résultats lorsque vous aurez terminé.
- Combien de transactions frauduleuses sont détectées pour chaque type de transaction ?
Dans la colonne isFraud, recherchez "1 = yes".
- Exécutez la commande suivante afin d'afficher la proportion d'activités frauduleuses pour les transactions de type TRANSFER et CASH_OUT (vous obtiendrez le nombre d'
isFraud) :
- Exécutez la commande suivante pour afficher les 10 montants de transaction les plus élevés :
PRENEZ LE TEMPS DE RÉFLÉCHIR :
- Certains soldes ont-ils attiré votre attention dans les transactions ? Comment peut-on effectuer une transaction à partir d'un compte dont le solde est nul ? Pourquoi le solde du compte de destination reste-t-il à zéro après le transfert d'argent ? Nous allons signaler ces cas et les ajouter en tant que nouvelles caractéristiques à la prochaine étape.
- Pensez-vous que les données sont déséquilibrées ? Oui, elles le sont. La proportion de transactions frauduleuses est considérablement inférieure à 1 %. En divisant le nombre d'occurrences d'
isFraudpar le nombre total d'observations, vous obtiendrez la proportion de transactions frauduleuses.
Dans la section suivante, nous verrons comment traiter ces questions et améliorer les données pour les modèles de machine learning.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Tâche 5 : Préparer vos données
Vous pouvez améliorer les données de modélisation en ajoutant de nouvelles caractéristiques, en filtrant les types de transactions non pertinents et en augmentant la proportion de la variable cible isFraud par le biais d'un sous-échantillonnage.
Les résultats produits par votre phase d'analyse indiquent que vous avez seulement besoin d'analyser les transactions de type TRANSFER et CASH_OUT et que vous pouvez filtrer le reste. Vous pouvez aussi calculer de nouvelles variables à partir des valeurs de montant existantes.
L'ensemble de données comporte une cible extrêmement déséquilibrée pour la fraude (dans les données brutes, le taux de fraude est de 0,0013 %). Les événements rares sont un cas classique dans le domaine de la fraude. Vous allez stratifier les données et augmenter la proportion de cas de fraude afin de rendre le schéma de comportement frauduleux plus évident pour les algorithmes de machine learning et de faciliter l'interprétation des résultats.
- Dans l'étape suivante, rédigez une nouvelle requête avec le code suivant pour ajouter de nouvelles caractéristiques aux données, filtrer les types de transactions non pertinents et sélectionner un sous-ensemble des transactions non frauduleuses en procédant à un sous-échantillonnage :
-
Exécutez la requête.
-
Créez une table de données TEST en sélectionnant aléatoirement un échantillon de 20 % :
- Exécutez la requête.
Ces données seront conservées séparément et ne seront pas incluses dans l'entraînement. Vous les utiliserez pour attribuer un score à votre modèle lors de l'étape finale.
BigQuery ML et AutoML partitionnent automatiquement les données du modèle entre TRAIN (entraînement) et VALIDATE (validation) lorsqu'ils utilisent des algorithmes de machine learning pour tester le taux d'erreur dans les données d'entraînement et dans les données de validation, afin d'éviter un surapprentissage.
- Exécutez la commande suivante pour créer les données échantillonnées :
Les données échantillonnées créées pour la modélisation comportent environ 228 000 lignes de transactions bancaires.
Vous pouvez aussi partitionner manuellement votre ensemble de données entre TRAIN/VALIDATE et TEST, en particulier lorsque vous avez besoin de cohérence pour comparer des modèles de différents environnements, comme AutoML ou AI Platform.
PRENEZ LE TEMPS DE RÉFLÉCHIR :
- Comment aborderiez-vous le problème si vous n'aviez pas d'événements de fraude étiquetés dans vos données ? Si les transactions ne sont pas étiquetées, vous pouvez utiliser des techniques de modélisation non supervisées, comme le clustering en k-moyennes, pour analyser les anomalies dans les données. Nous allons essayer cette méthode dans la prochaine section.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Tâche 6 : Entraîner un modèle non supervisé pour détecter les anomalies
Les méthodes non supervisées sont couramment utilisées pour la détection des fraudes afin d'explorer les comportements anormaux dans les données. Elles peuvent également être utiles lorsqu'il n'y a pas d'étiquettes pour signaler la fraude ou lorsque le taux d'événements est très faible et que le nombre d'occurrences ne permet pas de construire un modèle supervisé.
Dans cette section, vous allez utiliser un algorithme de clustering en k-moyennes pour créer des segments de transactions, analyser chaque segment et détecter ceux qui comportent des anomalies.
- Rédigez une nouvelle requête et exécutez la commande ci-dessous dans BigQuery avec CREATE OR REPLACE MODEL, en définissant model_type sur
kmeans:
Cette opération créera un modèle en k-moyennes appelé model_unsupervised avec cinq clusters exploitant les variables sélectionnées dans fraud_data_model.
Une fois l'entraînement terminé, le modèle apparaîtra sous Finance > Modèles.
- Cliquez sur model_unsupervised, puis sur l'onglet ÉVALUATION.
L'algorithme k-moyennes crée une variable de sortie appelée centroid_id. Chaque transaction est associée à un centroid_id. Les transactions proches ou similaires sont affectées au même cluster par l'algorithme.
L'indice de Davies-Bouldin reflète le degré d'homogénéité des clusters. Une valeur plus faible indique des clusters plus distants les uns des autres. C'est le résultat que nous voulons obtenir dans notre cas.
Les caractéristiques numériques sont affichées sur des graphiques à barres pour chaque centroïde (cluster) dans l'onglet "Évaluation". Le nombre à côté des barres correspond à la valeur moyenne des variables dans chaque cluster. Il est recommandé de standardiser les variables d'entrée ou de les regrouper dans des buckets pour empêcher les grands nombres ou les anomalies d'affecter le calcul des distances lors du clustering. Par souci de simplicité, nous utilisons les variables d'origine pour cet exercice de l'atelier.
Les variables catégorielles utilisées comme entrée sont affichées séparément. Vous pouvez observer la distribution des transactions de type TRANSFER et CASH_OUT dans les différents segments ci-dessous.
Le graphique de votre modèle peut être différent. Examinez les plus petits segments et essayez d'interpréter leurs distributions.
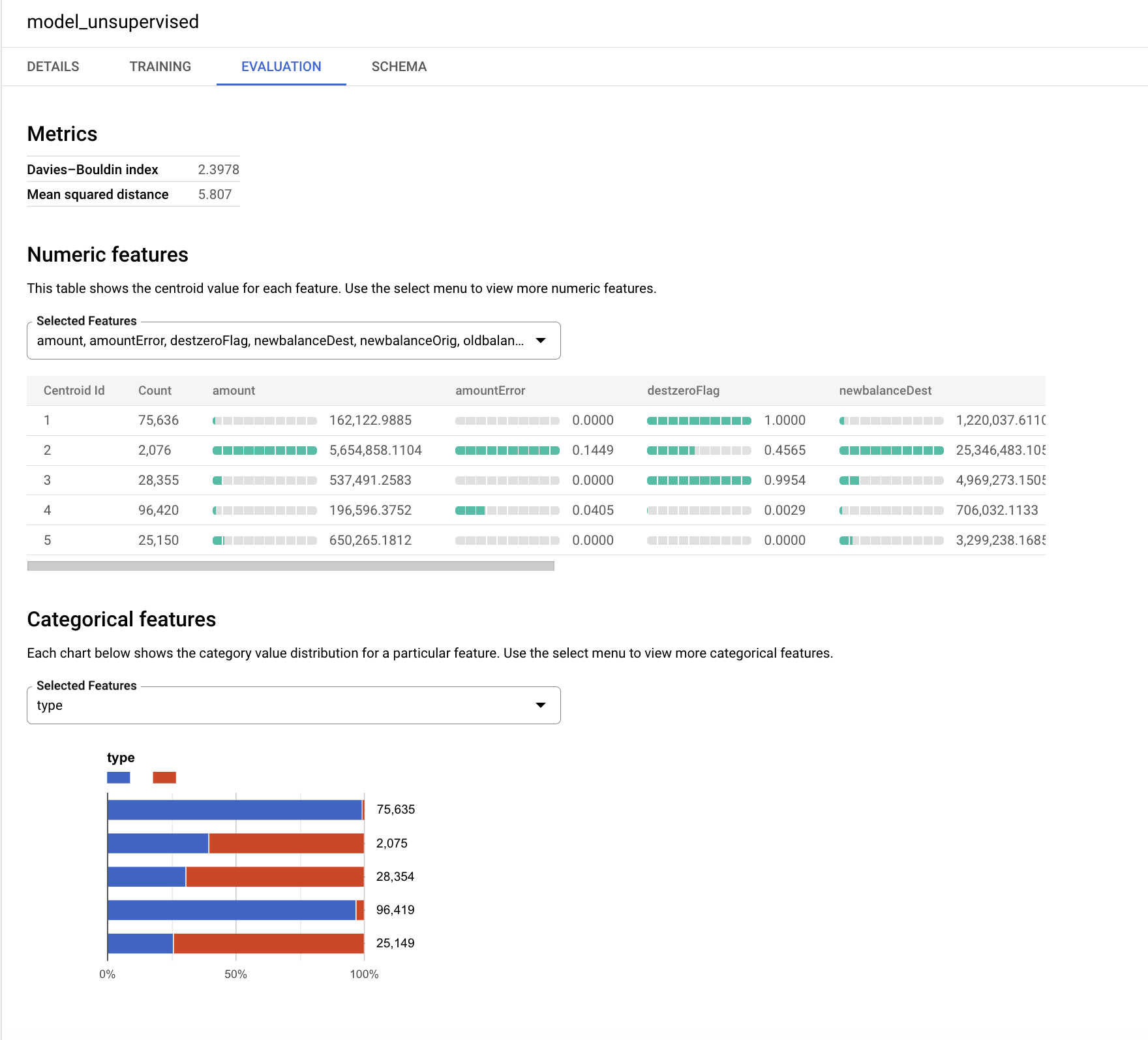
La variable cible isFraud n'a pas été utilisée dans ce modèle non supervisé. Dans cet exercice, il est préférable de conserver cette variable pour le profilage et de l'utiliser pour explorer la distribution des activités frauduleuses dans chaque cluster.
-
Attribuez un score aux données de test (
fraud_data_test) avec ce modèle et examinez le nombre d'événements de fraude dans chaquecentroid_id. Les algorithmes de clustering créent des groupes d'observations homogènes. Dans cette requête,ML.PREDICTva appeler le modèle et générer lecentroid_idpour chaque transaction dans les données de test. -
Exécutez la commande suivante dans une nouvelle requête :
PRENEZ LE TEMPS DE RÉFLÉCHIR :
- Selon vous, quel est le cluster le plus intéressant ? Réponse : les petits clusters avec un grand nombre d'erreurs.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Tâche 7 : Entraîner un modèle de machine learning supervisé
Vous êtes maintenant prêt à créer des modèles supervisés à l'aide de BigQuery ML afin de prédire la probabilité de transactions frauduleuses. Commencez par un modèle simple. Utilisez BigQuery ML pour créer un modèle de régression logistique binaire destiné à la classification. Ce modèle essaiera de prédire s'il est ou non probable que la transaction soit frauduleuse.
Pour toutes les variables non numériques (catégorielles), BigQuery ML effectue automatiquement une transformation d'encodage one-hot qui génère une caractéristique distincte pour chaque valeur unique dans la variable. Dans cet exercice, l'encodage one-hot va être automatiquement effectué par BigQuery ML pour la variable TYPE.
- Pour créer votre premier modèle supervisé, exécutez l'instruction SQL suivante dans BigQuery :
Une fois compilée, la table model_supervised_initial apparaîtra sous Finance > Modèles.
Lorsque le modèle sera créé, vous pourrez obtenir ses statistiques d'évaluation, d'entraînement et de métadonnées depuis l'UI de la console BigQuery.
- Dans le panneau de gauche, cliquez sur model_supervised_initial, puis sur les onglets Détails, Entraînement, Évaluation ou Schéma pour accéder aux informations correspondantes.
Dans l'onglet Évaluation, vous trouverez différentes métriques de performances spécifiques aux modèles de classification.
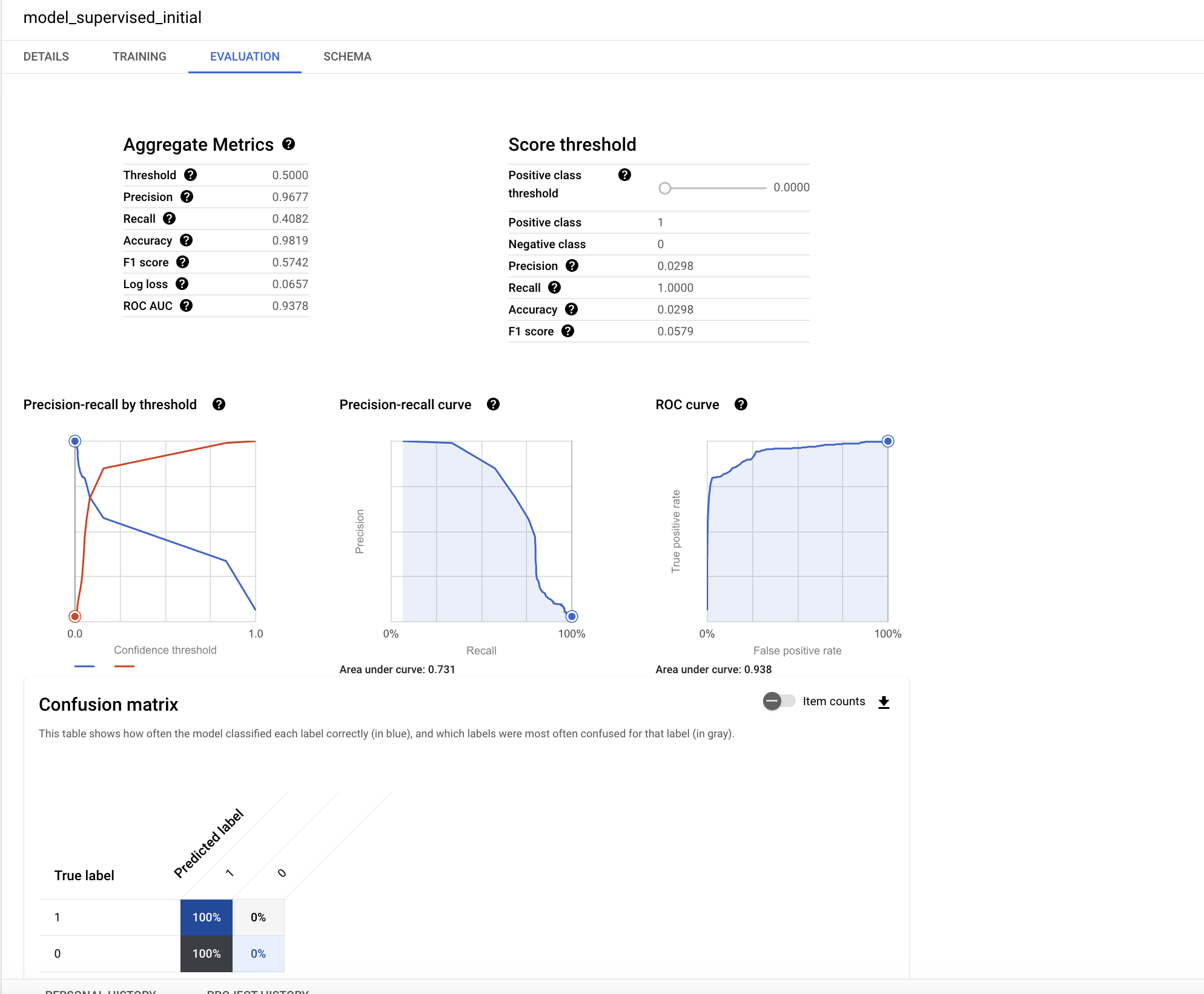
L'interprétation des performances d'un modèle fait partie des thématiques clés en machine learning. Étant donné que vous avez effectué une régression logistique, il est important de comprendre les principaux concepts ci-dessous :
- Précision : la précision correspond à la proportion de cas correctement identifiés comme positifs par le modèle.
- Rappel : le rappel correspond au nombre d'étiquettes identifiées correctement par le modèle parmi toutes les étiquettes positives possibles.
- Justesse : la justesse correspond à la proportion globale de prédictions correctes.
- Score F1 : le score F1 mesure la justesse du modèle et correspond à la moyenne harmonique de la précision et du rappel, avec une valeur entre 0 et 1. Un score plus élevé est considéré comme meilleur.
- ROC-AUC : l'AUC correspond à l'aire sous la courbe ROC et vous informe sur la capacité de discrimination d'un classificateur binaire en fonction de différents seuils, avec une valeur entre 0 et 1. Une valeur plus élevée est considérée comme meilleure. Dans un modèle modéré, la valeur ROC attendue sera supérieure à 0,7.
Le graphique sur cette page Wikipédia explique bien les concepts de précision et de rappel.
La valeur ROC de ce modèle de régression est très élevée. Pour mieux comprendre la justesse, vous pouvez tester les résultats à différents seuils de probabilité.
Examinez les caractéristiques les plus influentes dans le modèle.
- Exécutez la requête suivante pour vérifier l'importance des caractéristiques :
Les pondérations sont standardisées avec l'option standardize, ce qui permet d'effacer l'impact de l'amplitude des variables. Les pondérations les plus élevées sont aussi les plus importantes. Le signe de la pondération indique sa direction, selon sa relation directe ou inverse avec la cible.
PRENEZ LE TEMPS DE RÉFLÉCHIR :
- Laquelle de ces deux variables vous semble la plus importante ? Les variables
oldbalanceOrigettypesont les plus importantes.

Cliquez sur Vérifier ma progression pour valider l'objectif.
Tâche 8 : Améliorer votre modèle
Passons à un exercice amusant : vous allez créer un autre modèle, puis entraîner vos deux modèles afin d'en améliorer la justesse.
- Exécutez la commande suivante pour créer un modèle à boosting de gradient :
Vous allez maintenant comparer vos deux modèles et choisir le meilleur.
Tâche 9 : Évaluer vos modèles de machine learning supervisé
Améliorez le modèle de régression logistique existant en lui ajoutant de nouvelles variables.
Après avoir créé le modèle, vous pouvez utiliser la fonction ML.EVALUATE pour évaluer les performances du classificateur. La fonction ML.EVALUATE compare le résultat ou les valeurs prédites aux données réelles.
- Exécutez les requêtes suivantes dans l'ordre afin d'ajouter les résultats provenant des deux modèles dans une même table et de sélectionner le modèle champion pour l'attribution de scores aux nouvelles données.
PRENEZ LE TEMPS DE RÉFLÉCHIR :
- Lequel de vos modèles offre les meilleures performances ? Au début, vous avez exécuté un modèle de régression. Ensuite, vous lui avez ajouté des variables supplémentaires, puis entraîné un nouveau modèle en vous servant de la régression (le modèle supervisé). Pour terminer, vous avez utilisé un second modèle supervisé avec un arbre de décision à boosting. La comparaison des tables de performances montre que le modèle avec arbre de décision à boosting est meilleur. L'ajout de caractéristiques nouvelles et supplémentaires a eu pour effet d'améliorer la justesse.
Tâche 10 : Prédire les transactions frauduleuses dans des données de test
La dernière étape en machine learning consiste à utiliser le modèle champion pour prédire des résultats sur de nouveaux ensembles de données.
Les algorithmes de machine learning dans BigQuery ML créent une variable imbriquée appelée predicted_<target_name\>_probs. Cette variable inclut les scores de probabilité pour la décision du modèle. Dans le cas présent, la décision du modèle désigne une transaction comme légitime ou frauduleuse.
- Exécutez la requête suivante dans BigQuery pour afficher la prédiction de transactions frauduleuses sur les données de test créée au début de cet atelier. L'instruction WHERE ci-dessous vous permet d'obtenir la liste des transactions avec les scores de probabilité les plus élevés :
PRENEZ LE TEMPS DE RÉFLÉCHIR :
- Quelle est la proportion d'activités frauduleuses dans l'ensemble de transactions faisant l'objet de prédictions ? Moins de 3 %.
- De combien a augmenté le taux d'événements dans l'ensemble de lignes faisant l'objet de prédictions, comparé aux données de test globales ? De plus de 95 %.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Félicitations !
Étapes suivantes
- Pour en savoir plus sur le machine learning, suivez le cours d'initiation sur le site Google Developers.
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière modification du manuel : 12 octobre 2023
Dernier test de l'atelier : 12 octobre 2023
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.