チェックポイント
Create a new dataset
/ 20
Create a model and specify model options
/ 20
Evaluate classification model performance
/ 15
Improve model performance with Feature Engineering(Create second model)
/ 15
Improve model performance with Feature Engineering(Better predictive power)
/ 15
Predict which new visitors will come back and purchase
/ 15
BigQuery ML で分類モデルを使用して訪問者の購入を予測する
GSP229

概要
BigQuery は、Google が提供する低コスト、NoOps のフルマネージド分析データベースです。BigQuery では、インフラストラクチャを所有して管理したりデータベース管理者を置いたりすることなく、テラバイト単位の大規模なデータでクエリを実行できます。また、SQL が採用されており、従量課金制というメリットもあります。このような特徴を活かし、ユーザーは有用な情報を得るためのデータ分析に専念できます。
BigQuery の新しい機能である BigQuery 機械学習(BigQuery ML)を使用すれば、最小限のコーディングで ML モデルの作成、トレーニング、評価、予測が可能になります。
このラボでは、Google Merchandise Store の数百万件の Google アナリティクス レコードが BigQuery に読み込まれた特別な e コマース データセットを使用します。このデータを使用して一般的なクエリを実行し、企業が必要とする顧客の購買習慣に関する情報を取得します。
学習内容
このラボでは、次のタスクの実行方法について学びます。
- BigQuery を使用して一般公開データセットを見つける
- ecommerce データセットでクエリを実行して探索する
- バッチ予測に使用するトレーニングと評価のデータセットを作成する
- BigQuery ML に分類(ロジスティック回帰)モデルを作成する
- 機械学習モデルの性能を評価する
- 訪問者が購入を行う見込みを予測してランクを付ける
設定
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

BigQuery コンソールを開く
- Google Cloud コンソールで、ナビゲーション メニュー > [BigQuery] を選択します。
[Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスには、クイックスタート ガイドとリリースノートへのリンクが表示されます。
- [完了] をクリックします。
BigQuery コンソールが開きます。
コース用データセットにアクセスする
- [エクスプローラ] ペインで、[+追加] をクリックします。
[データを追加] ペインが開きます。
-
[その他のソース] の下で [名前を指定してプロジェクトにスターを付ける] をクリックします。
-
「
data-to-insights」と入力して、[スターを付ける] をクリックします。
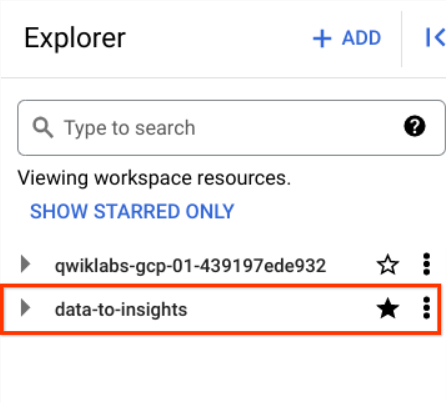
次の直接リンクをクリックし、一般公開の data-to-insights プロジェクトを表示します。
data-to-insights ecommerce データセットのフィールド定義については、こちらをご覧ください。このリンク先のページは、参照用に新しいタブで開いたままにしておきます。
[クエリ] タブをクリックし、[新しいタブ] を選択してクエリエディタを開きます。
タスク 1. e コマースデータを調べる
シナリオ: データ アナリスト チームが、e コマース ウェブサイトに関する Google アナリティクスのログを BigQuery にエクスポートし、e コマース訪問者のセッションの生データをすべて含むテーブルを作成して、データを調べられるようにしました。このデータを使用して、いくつかの質問に対する答えを見つけていきましょう。
質問: ウェブサイト訪問者の何パーセントが実際に購入に至りましたか。
- 次のクエリをコピーして、BigQuery エディタに貼り付けます。
- [実行] をクリックします。
結果: 2.69%
質問: 売り上げで上位 5 つの商品は何ですか。
- 前のクエリを消去し、エディタで以下のクエリを追加します。
- [実行] をクリックします。
結果:
|
行 |
v2ProductName |
v2ProductCategory |
units_sold |
revenue |
|
1 |
Nest® Learning Thermostat 3rd Gen-USA - Stainless Steel |
Nest-USA |
17651 |
870976.95 |
|
2 |
Nest® Cam Outdoor Security Camera - USA |
Nest-USA |
16930 |
684034.55 |
|
3 |
Nest® Cam Indoor Security Camera - USA |
Nest-USA |
14155 |
548104.47 |
|
4 |
Nest® Protect Smoke + CO White Wired Alarm-USA |
Nest-USA |
6394 |
178937.6 |
|
5 |
Nest® Protect Smoke + CO White Battery Alarm-USA |
Nest-USA |
6340 |
178572.4 |
質問: ウェブサイトを再訪問して購入を行った人は何人ですか。
- 前のクエリを消去し、エディタで以下のクエリを追加します。
- [実行] をクリックします。
結果:
|
行 |
total_visitors |
will_buy_on_return_visit |
|
1 |
729848 |
0 |
|
2 |
11873 |
1 |
結果を分析すると、総訪問者の 1.6%(11,873 ÷ 741,721)がウェブサイトに戻ってきて、購入を行ったことがわかります。この人数には、最初の訪問で購入し、再度訪問してもう一度購入した人も含まれます。
質問: e コマースの利用者の多くが、閲覧するものの再訪問するまで購入しない理由は何ですか。
回答: 唯一の正解はありませんが、よくある理由のひとつは、最終的に購入を決定する前に、別の e コマースサイトと比較検討してから購入するから、というものです。これは、事前に入念な事前調査と比較が必要になる高額な商品(自動車など)の購入の際に顕著ですが、比較的程度は低いものの、このサイトの商品(T シャツやアクセサリーなど)の購入にも当てはまります。
オンライン マーケティング業界では今後、初回訪問で観察された特徴に基づいて将来購入に至るユーザーを識別し、マーケティング活動を行うことが、コンバージョン率を上げ、競合他社のサイトへのユーザー流出を抑える鍵となるでしょう。
タスク 2. 対象を特定する
ここからは、BigQuery で ML モデルを作成し、新しいユーザーが将来的に購入を行うかどうかを予測します。こうした高い価値を持つユーザーを識別することで、マーケティング チームがそれらのユーザーにターゲットを絞って特別プロモーションや広告キャンペーンを実施することが可能になり、それらのユーザーが自社の e コマースサイトを再度訪問するまでの間に他のサイトと比較していたとしても、コンバージョンにつなげやすくなります。
タスク 3. 特徴量を選択し、トレーニング データセットを作成する
Google アナリティクスでは、さまざまなディメンションを捉えてこの e コマース ウェブサイトのユーザー訪問が計測されます。フィールドの一覧を [UA] BigQuery Export スキーマのドキュメントで確認してからデモ データセットをプレビューし、ユーザーによるウェブサイト初回訪問のデータと、そのユーザーが戻ってきて購入を行うかどうかの関係を、ML モデルが理解するために役立つ特徴を見つけます。
次の 2 つのフィールドが分類モデルに適した入力であるかどうかをテストしましょう。
-
totals.bounces(訪問者がウェブサイトをすぐに離れたかどうか) -
totals.timeOnSite(訪問者がウェブサイトに留まった期間)
質問: 上記の 2 つのフィールドのみを使用することにはどんなリスクがありますか。
解答: ML の良し悪しは、提供されるトレーニング データにかかっています。入力した特徴とラベル(ここでは、訪問者が将来購入するかどうか)の関係をモデルに判断、学習させるための十分な情報が揃わない場合、精度の高いモデルを確立することはできません。これら 2 つのフィールドでモデルをトレーニングすることは出発点にはなりますが、精度の高いモデルを生成するために 2 つのフィールドだけで十分かどうかを見極める必要があります。
- BigQuery エディタで、次のクエリを実行します。
結果:
|
行 |
bounces |
time_on_site |
will_buy_on_return_visit |
|
1 |
0 |
15047 |
0 |
|
2 |
0 |
12136 |
0 |
|
3 |
0 |
11201 |
0 |
|
4 |
0 |
10046 |
0 |
|
5 |
0 |
9974 |
0 |
|
6 |
0 |
9564 |
0 |
|
7 |
0 |
9520 |
0 |
|
8 |
0 |
9275 |
1 |
|
9 |
0 |
9138 |
0 |
|
10 |
0 |
8872 |
0 |
質問: 入力特徴とラベルのフィールドはどれですか?
回答: 入力は、bounces と time_on_site です。ラベルは、will_buy_on_return_visit です。
質問: 訪問者の最初のセッションの後にわかる 2 つのフィールドはどれですか。
解答: bounces と time_on_site は、訪問者の最初のセッションの後に明らかになります。
質問: 後になるまで判明しないフィールドはどれですか?
解答: will_buy_on_return_visit は、初回の訪問後にはわかりません。繰り返しになりますが、ここでは、ウェブサイトに戻ってきて購入を行うユーザーのサブセットを予測します。予測時に将来のことはわからないため、新しい訪問者が後から戻ってきて購入を行うかどうかについて確かなことはいえません。ML モデルを構築する価値は、最初のセッションについて収集されたデータに基づいて、将来の購入の確率を予測できる点にあります。
質問: 最初のデータ結果から見て、time_on_site と bounces は、ユーザーが戻ってきて購入を行うかどうかを示す適切な指標だといえますか?
解答: モデルのトレーニングと評価を行う前に結論を出すのは早すぎるかもしれませんが、time_on_site の上位 10 項目を見ると、戻ってきて購入を行ったユーザーは 1 人だけでした。あまり確率は高くなさそうです。モデルの機能を検証してみましょう。
タスク 4. モデルを格納する BigQuery データセットを作成する
次に、新しい BigQuery データセットを作成し、ML モデルを格納します。
- 左側のペインで、[エクスプローラ] セクションのプロジェクト名(
qwiklabs-gcp-...で始まる)の横にある「アクションを表示」アイコンをクリックした後、[データセットを作成] をクリックします。
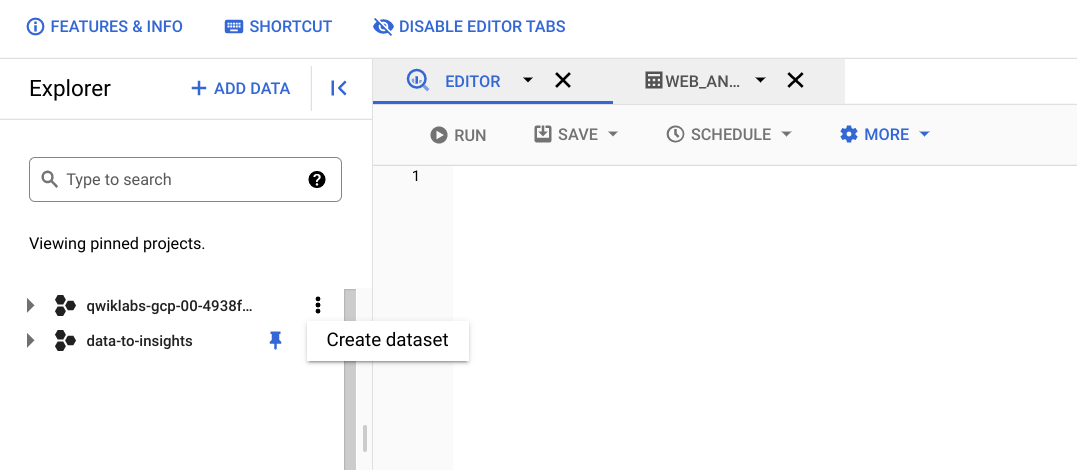
- [データセットを作成する] ダイアログで、次の操作を行います。
- [データセット ID] に「ecommerce」と入力します。
- その他の値はデフォルトのままにします。
- [データセットを作成] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 5. BigQuery ML モデルタイプを選択し、オプションを指定する
最初に使用する特徴を選択したので、ML モデルを BigQuery で作成する準備ができました。
モデルタイプは次の 2 つから選択します。
|
モデル |
モデルタイプ |
ラベルのデータ型 |
例 |
|
予測 |
linear_reg |
数値(通常は整数または浮動小数点数) |
過去の売り上げデータから翌年の売り上げを予測。 |
|
分類 |
logistic_reg |
0 または 1 のバイナリ分類 |
コンテキストに応じてメールを迷惑メールまたは迷惑メール以外に分類。 |
どちらのモデルタイプを選択すればいいでしょうか。
訪問者を「将来購入する」か「将来購入しない」にバケット化しているため、分類モデルで logistic_reg を使用します。
次のクエリはモデルを作成してモデルのオプションを指定します。
- このクエリを実行してモデルをトレーニングします。
- モデルのトレーニングが終わるのを待ちます(5~10 分)。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
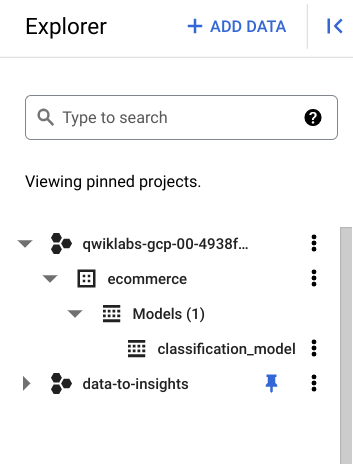
モデルのトレーニングが終わると、「このステートメントで新しいモデル qwiklabs-gcp-xxxxxxxxx:ecommerce.classification_model が作成されました」というメッセージが表示されます。
-
[モデルに移動] をクリックします。
-
ecommerce データセットの内容を確認し、classification_model が表示されていることを確かめます。
次に、未知の評価データに対するモデルの性能を評価します。
タスク 6. 分類モデルの性能を評価する
性能の基準を選択する
ML での分類では、偽陽性率(ユーザーが戻ってきて購入を行うと予測したものの、実際には購入しなかった)を最小限に抑え、真陽性率(ユーザーが戻ってきて購入を行うと予測し、実際に購入した)を最大限にすることを目指します。
この関係は次に示すような受信者操作特性(ROC)曲線で可視化できます。ここでは、曲線の下の面積(AUC)を最大限にすることが目標です。
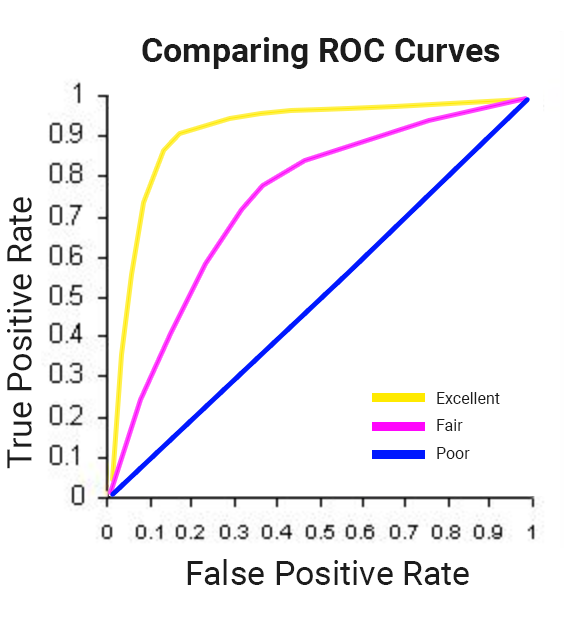
BigQuery ML の roc_auc は、トレーニング済みの ML モデルを評価する際にクエリ可能なフィールドです。
- トレーニングが完了したので、このクエリを実行して
ML.EVALUATEを使用するモデルの性能を評価します。
次のような結果が表示されます。
|
行 |
roc_auc |
model_quality |
|
1 |
0.7238561438561438 |
decent |
モデルを評価すると、roc_auc が 0.72 となります。これは、モデルが妥当(decent)なレベルではあるものの、予測力が特に優れているわけではないことを示しています。目標は、曲線の下の領域を可能な限り 1.0 に近づけることであるため、改善の余地はまだ残されています。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 7. 特徴量エンジニアリングでモデル性能を強化する
先にも少し触れましたが、訪問者の最初のセッションと再度訪問して購入を行う可能性の関係をモデルに理解させるうえで、役に立つデータセットの特徴は他にもたくさん存在します。
- 新しい特徴をいくつか追加し、
classification_model_2という名前の 2 番目の ML モデルを作成します。
- 初回訪問時に訪問者は購入手続きをどこまで進めていたか
- 訪問者はどこからアクセスしたか(トラフィック ソースがオーガニック検索、参照元サイトなど)
- デバイスのカテゴリ(モバイル、タブレット、パソコン)
- 地理情報(国)
- 「+」(クエリを新規作成)アイコンをクリックして、この 2 番目のモデルを作成します。
トレーニング データセットのクエリに追加された新しい重要な特徴は、各訪問者がセッションで到達した購入手続きの段階です。これは、フィールド hits.eCommerceAction.action_type に記録されます。フィールド定義でそのフィールドを検索すると、「6 = Completed Purchase」のフィールド マッピングが表示されます。
- 新しいモデルのトレーニングが終わるのを待ちます(5~10 分)。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
- この新しいモデルを評価し、より優れた予測力が備わっているかどうかを確認します。
出力:
|
行 |
roc_auc |
model_quality |
|
1 |
0.9094875124875125 |
good |
この新しいモデルでは、roc_auc が 0.91 となりました。これは、最初のモデルよりも著しく向上しています。
モデルをトレーニングしたので、今度は予測を行います。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 8. どの新しい訪問者が戻ってきて購入を行うかを予測する
次に、どの新しい訪問者がサイトに戻って購入を行うかを予測するためのクエリを作成します。
- 以下の予測クエリでは、改善された分類モデルを使用して、Google Merchandise Store への初めての訪問者が再訪問で購入を行う確率を予測します。
予測は、最後の 1 か月(12 か月中)のデータセットで行われます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
これで、モデルがこれらの 2017 年 7 月の e コマース セッションの予測を出力するようになりました。ここでは、新しく追加された 3 つのフィールドを確認できます。
- predicted_will_buy_on_return_visit: 訪問者が後で購入を行うことを、モデルが予測しているかどうか(1 = yes)
- predicted_will_buy_on_return_visit_probs.label: yes / no のバイナリ分類器
- predicted_will_buy_on_return_visit.probs.prob: 予測に対するモデルの信頼度(1 = 100%)
![[クエリ結果] タブのページ](https://cdn.qwiklabs.com/ZAZ7QE8T%2FZP0WsX8AH6kam6Amgoh76i0cVKWvv4Z6tA%3D)
タスク 9. 結果の分析とその他の情報
結果
- 初回訪問者(予測された確率によって降順で並べ替え)の上位 6% のうち、6% 以上が再訪問時に購入を行いました。
- これらのユーザーは、再訪問で購入に至った初回訪問者全体の 50% 近くに相当します。
- 全体として、初回訪問者の 0.7% しか再訪問で購入しませんでした。
- 初回訪問者の上位 6% にターゲットを絞ると、マーケティング ROI は、全員をターゲットにした場合に比べて 9 倍も向上します。
追加情報
ヒント: 新しいデータで既存のモデルの再トレーニングを行う場合、warm_start = true をモデルのオプションに追加するとトレーニング時間を短縮できます。特徴の列を変更することはできません(変更すると、新しいモデルが必要になります)。
roc_auc は、モデル評価で使用できるパフォーマンス指標のひとつにすぎません。他にも accuracy、precision、recall を使用できます。どのパフォーマンス指標を使用するかは、全体の目標にもとづいて決める必要があります。
探索できるその他のデータセット
タクシー運賃を予測するなど、他のデータセットでモデルの構築を試してみる場合は、bigquery-public-data プロジェクトを利用できます。
- bigquery-public-data データセットを開くには、[+追加] をクリックします。[その他のソース] の下で [名前を指定してプロジェクトにスターを付ける] をクリックします。
-
bigquery-public-data名を記述します。 - [スターを付ける] をクリックします。
bigquery-public-data プロジェクトが [エクスプローラ] セクションに表示されます。
タスク 10. 理解度テスト
クイズに挑戦して Google Cloud Platform に関する知識をチェックしましょう
お疲れさまでした
e コマースの訪問者を分類する ML モデルを BigQuery で無事構築できました。
クエストを完了する
このセルフペース ラボは、「BigQuery for Machine Learning」と「Applying BigQuery ML's Classification, Regression, and Demand Forecasting for Retail Applications」クエストの一部です。クエストとは学習プログラムを構成する一連のラボのことで、完了すると成果が認められてバッジが贈られます。バッジは公開して、オンライン レジュメやソーシャル メディア アカウントにリンクできます。このラボの修了後、このラボが含まれるクエストに登録すれば、すぐにクレジットを受け取ることができます。受講可能なすべてのクエストについては、Google Cloud Skills Boost カタログをご覧ください。
次のラボを受講する
次のステップと詳細情報
- すでに Google アナリティクス アカウントをお持ちで、BigQuery で独自のデータセットをクエリするには、アナリティクスのヘルプページから BigQuery Export の設定に関するこちらのガイドの手順に沿って操作を行います。
- BigQuery ページでクエリを作成するリソースについては、クエリ構文リファレンスをご覧ください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 10 月 9 日
ラボの最終テスト日: 2023 年 10 月 9 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。