
![API の詳細([管理] と [この API を試す] という 2 つのボタンと、[API が有効] チェックマークを含む)](https://cdn.qwiklabs.com/FQ3J%2FqnmXCNrmY7IP3SMGX9uJYi2CBHeUH%2BmSS4g5GU%3D)
![[データセットを作成] がハイライト表示された [アクションを表示] メニュー](https://cdn.qwiklabs.com/%2F790WLV%2FFGhNI%2BECmQLOeuyp8C2hpyp6ml%2BZpzIJbVY%3D)
![[テーブルを作成] ページの [スキーマ] セクション内のフィールド リスト(article-text、category、confidence を含む)](https://cdn.qwiklabs.com/HQzXyjN0enWHFzlZwdKHUr397LLYhxBwg%2F1cBJ4Nqlc%3D)
![[新しいタブ] オプションがハイライト表示された [クエリ] プルダウン メニュー](https://cdn.qwiklabs.com/LnLtnteOXzBCBvJmleYX9WCe2Qv%2FK10MtH0Lud678ho%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create an API Key
/ 25
Create a request to Classify a news article
/ 25
Check the Entity Analysis response
/ 25
Create a new Dataset and table for categorized text data
/ 25
Cloud Natural Language API を使用すると、テキストからエンティティを抽出して感情分析や構文解析を行い、分析したテキストをカテゴリに分類できます。このラボでは、テキストの分類に注目します。700 以上のカテゴリが登録されたデータベースを使用するこの API 機能により、大規模なテキスト データセットの分類が容易になります。
このラボでは、次の方法について学びます。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン 
ウィンドウで次の操作を行います。
接続した時点で認証が完了しており、プロジェクトに各自の Project_ID、
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力:
gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
画面左上のナビゲーション メニュー(
[API とサービス] > [有効な API とサービス] を選択します。
次に、検索ボックスで「language」を検索します。
[Cloud Natural Language API] をクリックします。
API が有効になっていない場合は、[有効にする] ボタンが表示されます。
API が有効になると、次のような API の情報が表示されます。
curl を使用して Natural Language API にリクエストを送信するため、リクエスト URL に含める API キーを生成する必要があります。
API キーを作成するには、コンソールで、ナビゲーション メニュー > [API とサービス] > [認証情報] をクリックします。
[認証情報を作成] をクリックします。
プルダウン メニューで [API キー] を選択します。
次に、生成したキーをコピーして [閉じる] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
API キーが準備できたので、リクエストのたびに API キーの値を挿入しなくて済むよう、環境変数としてキーを保存します。
この後のステップを実行するために、プロビジョニングされているインスタンスに SSH で接続してください。
linux-instance が表示されます。[SSH] ボタンをクリックします。インタラクティブ シェルが表示されます。
コマンドラインで以下のコマンドを入力します。<YOUR_API_KEY> の部分は、先ほどコピーしたキーに置き換えてください。
Natural Language API の classifyText メソッドを使用すると、1 つの API 呼び出しでテキストデータをカテゴリに分類できます。このメソッドは、テキスト ドキュメントに適用されるコンテンツ カテゴリのリストを返します。
返されるカテゴリの具体性には幅があり、/Computers & Electronics のように大まかなカテゴリもあれば、/Computers & Electronics/Programming/Java (Programming Language) のように非常に具体的なカテゴリもあります。700 以上あるカテゴリ候補の全リストはコンテンツ カテゴリ ページでご確認ください。
ここでは、最初に 1 つの記事を分類し、同じ手法で大規模なニュース コーパスを整理していく方法について説明します。
A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes.(タパス風スモーキー ロブスター サラダ。スペイン料理「タコのガリシア風」をヒントにしたこの一品には、タコは使いませんが、岩塩、オリーブオイル、ピメントン、ゆでたジャガイモを使います。)
request.json という名前のファイルを作成し、以下のコードを追加します。お好みのコマンドライン エディタ(nano、vim、emacs)を使用してファイルを作成してもかまいません。curl コマンドを使って Natural Language API の classifyText メソッドに送信します。レスポンスを確認します。
Speech API のリクエストを作成し、Speech API を呼び出すことができました。
result.json ファイルにレスポンスを保存します。このテキストに対し、次の 2 つのカテゴリが API から返されます。
/Food & Drink/Cooking & Recipes/Food & Drink/Food/Meat & Seafoodテキストには、これがレシピであることもシーフードが含まれることもはっきりとは書かれていませんが、この API を使えば分類できます。1 つの記事の分類からもこの機能の優れた点がわかりますが、本当の利点は、次のように大規模なテキストデータを扱うことで見えてきます。
BBC のニュース記事を集めたこちらの一般公開データセットを題材に、大量のテキストを含むデータセットを classifyText メソッドを使ってわかりやすく整理していきましょう。このデータセットには、2004 年から 2005 年までの 5 つの分野(ビジネス、エンターテイメント、政治、スポーツ、テクノロジー)の記事が 2,225 件含まれています。これらの記事の一部が、一般公開されている Cloud Storage バケットの中にあります。記事は 1 件ずつ 1 つの .txt ファイルになっています。
データを調べて Natural Language API に送信するために、Cloud Storage から各テキスト ファイルを読み取り、classifyText エンドポイントに送信し、その結果を BigQuery テーブルに保存する Python スクリプトを作成します。BigQuery は、大規模なデータセットの保存や分析を容易にする Google Cloud のビッグデータ ウェアハウス ツールです。
gsutil は Cloud Storage のコマンドライン インターフェースです)。次に、データを保存する BigQuery テーブルを作成します。
Natural Language API にテキストを送信する前に、各記事のテキストとカテゴリの保存場所を用意する必要があります。
コンソールのナビゲーション メニュー > [BigQuery] に移動します。
[完了] をクリックします。
データセットを作成するには、プロジェクト ID の横にある [アクションを表示] アイコンをクリックし、[データセットを作成] を選択します。
データセットの名前を「news_classification_dataset」にして、[データセットを作成] をクリックします。
テーブルを作成するには、news_classification_dataset の横にある [アクションを表示] アイコンをクリックして、[テーブルを作成] を選択します。
以下の設定で新しいテーブルを作成します。
[スキーマ] で、[フィールドを追加] をクリックして、次の 3 つのフィールドを追加します。
| フィールド名 | 種類 | モード |
|---|---|---|
article_text |
STRING | NULLABLE |
category |
STRING | NULLABLE |
confidence |
FLOAT | NULLABLE |
現在、テーブルは空の状態です。次のステップで、Cloud Storage から記事を読み取り、それを Natural Language API に送信して分類し、結果を BigQuery に保存していきます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
この後のステップを実行するために、Cloud Shell に接続してください。プロンプトが表示されたら、[続行] をクリックします。
ニュースデータを Natural Language API に送信するスクリプトを作成する前に、サービス アカウントを作成する必要があります。このアカウントは、Python スクリプトから Natural Language API と BigQuery に対して認証を行う際に使用されます。
これで、Natural Language API にテキストデータを送信する準備が整いました。
さまざまなクラウド クライアント ライブラリが存在し、どの言語でも同じことができます。
classify-text.py という名前のファイルを作成し、ファイルの中に次のコードをコピーします。お好みのコマンドライン エディタ(nano、vim、emacs)を使用してファイルを作成してもかまいません。これで、記事を分類して BigQuery にインポートする準備が整いました。
スクリプトが完了するまで 2 分ほどかかりますので、その間に処理内容について説明します。
現在、Google Cloud の Python クライアント ライブラリを使用して、Cloud Storage、Natural Language API、BigQuery にアクセスしています。まず、サービスごとにクライアントが作成され、BigQuery テーブルへの参照が作成されます。一般公開されているバケットに含まれる各 BBC データセット ファイルへの参照は、files です。ファイルが確認され、記事が文字列としてダウンロードされます。それぞれの記事は、classify_text 関数の Natural Language API に送信されます。Natural Language API からカテゴリが返されたすべての記事について、記事とそのカテゴリデータが rows_for_bq リストに保存されます。各記事の分類が完了すると、insert_rows() によって BigQuery にデータが挿入されます。
スクリプトの実行が完了したら、記事データが BigQuery に保存されたことを確認します。
article_data テーブルに移動して、[クエリ] をクリックし、テーブルに対してクエリを実行します。クエリが完了すると、データが表示されます。
カテゴリ列には、Natural Language API から記事に対して返された最初のカテゴリの名前が含まれており、confidence には、API による記事の分類の信頼度を示す 0〜1 の値が含まれています。
次のステップでは、データに対してより複雑なクエリを実行する方法について説明します。
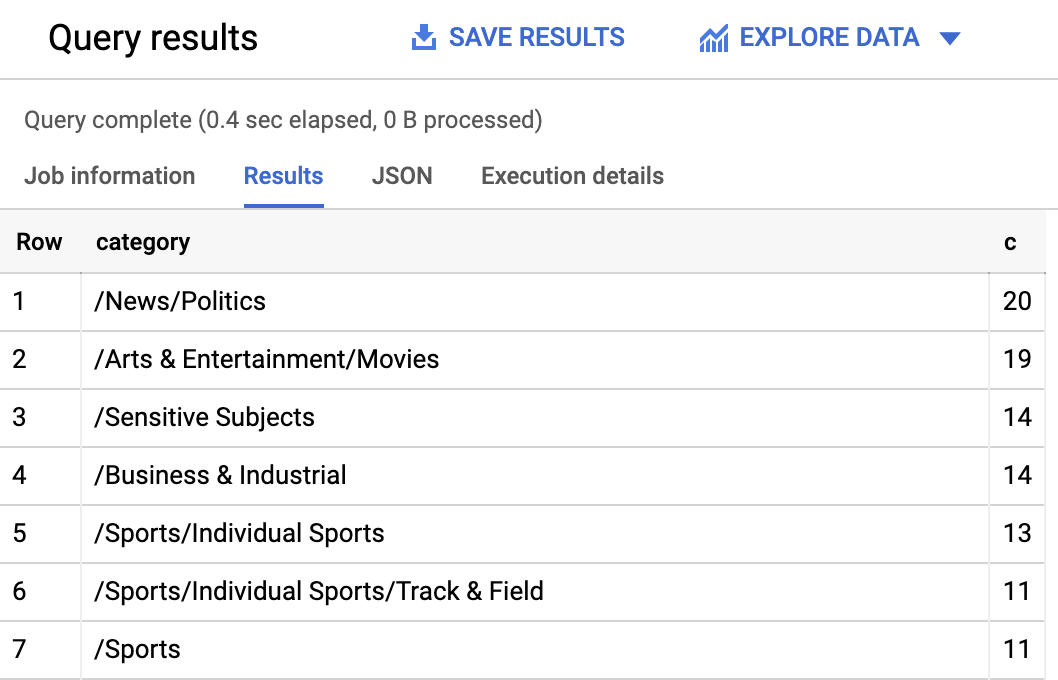
まず、データセットで最も多かったカテゴリを確認します。
BigQuery コンソールで、[+ SQL クエリ] をクリックします。
次のクエリを入力します。
クエリの結果として、次のような内容が表示されます。
/Arts & Entertainment/Music & Audio/Classical Music のように漠然としたカテゴリが返された記事を見つけたい場合は、次のようなクエリを使用します。
また、クエリを次のようにすると、Natural language API から返された信頼スコアが 90% を超えている記事のみを取得することができます。
その他のクエリ方法の詳細については、BigQuery のドキュメントをご確認ください。BigQuery は多数の可視化ツールとも統合されています。分類したニュースデータを可視化したい場合は、BigQuery の Looker Studio をご参照ください。
このラボでは、Natural Language API のテキスト分類メソッドを使ってニュース記事を分類する方法を学習しました。最初に 1 つの記事を分類する方法を学び、その後、大規模なニュース データセットを NL API で分類して BigQuery で分析する方法を学びました。また、BigQuery テーブルを作成し、データに対してクエリを実行する方法についても学びました。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2025 年 3 月 21 日
ラボの最終テスト日: 2025 年 3 月 21 日
Copyright 2025 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください