

Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Explore the NYC Citi Bike Trips dataset
/ 20
Cleaned training data
/ 20
Training a Model
/ 20
Evaluate the time series model
/ 20
Make Predictions using the model
/ 20
BigQuery is Google's fully managed, NoOps, low cost analytics database. With BigQuery you can query terabytes and terabytes of data without having any infrastructure to manage, or needing a database administrator.
BigQuery Machine Learning (BQML) is a feature in BigQuery where data analysts can create, train, evaluate, and predict with machine learning models with minimal coding. Watch this BigQuery ML video to learn more.
In this lab, you will learn how to build a time series model to forecast the demand of multiple products using BigQuery ML. Using the NYC Citi Bike Trips public dataset, learn how to use historical data to forecast demand in the next 30 days. Imagine the bikes are retail items for sale, and the bike stations are stores.
Watch this video to understand some example use cases for demand forecasting.
In this lab, you learn to perform the following tasks:
NYC Citi Bike Trips dataset.Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources are made available to you.
This hands-on lab lets you do the lab activities in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
Click the Start Lab button. If you need to pay for the lab, a dialog opens for you to select your payment method. On the left is the Lab Details pane with the following:
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
If necessary, copy the Username below and paste it into the Sign in dialog.
You can also find the Username in the Lab Details pane.
Click Next.
Copy the Password below and paste it into the Welcome dialog.
You can also find the Password in the Lab Details pane.
Click Next.
Click through the subsequent pages:
After a few moments, the Google Cloud console opens in this tab.

The Welcome to BigQuery in the Cloud Console message box opens. This message box provides a link to the quickstart guide and the release notes.
The BigQuery console opens.
You will use the public dataset for NYC Bike Trips. This dataset can be accessed in Marketplace within the Google Cloud console. BigQuery makes it easy to access public datasets directly from the Explorer interface.
Under Additional Sources, select Public Datasets.
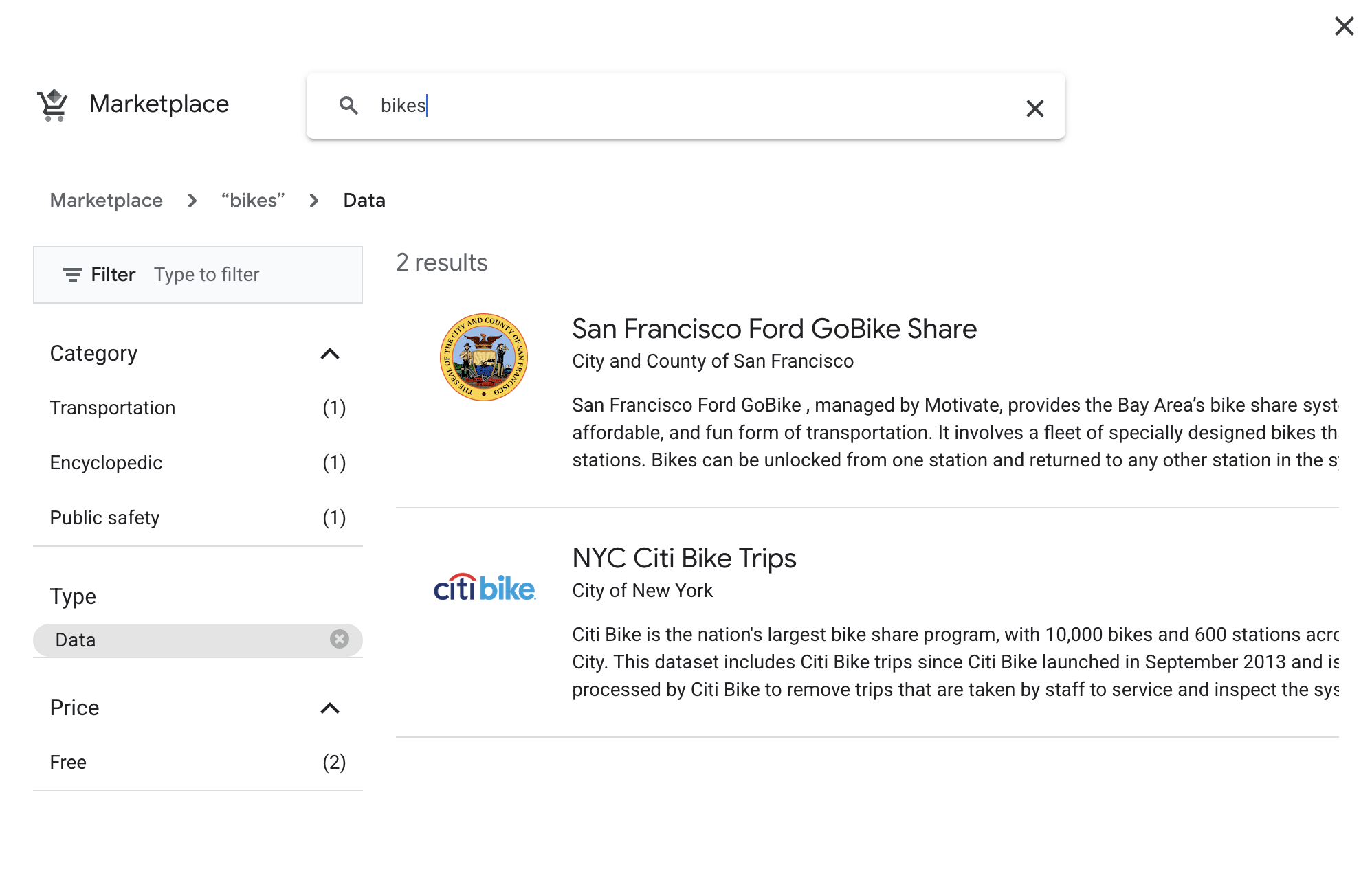
Search for "bikes" and click on the NYC Citi Bike Trips tile.
Question: Could you name some New York locations where you can hire bikes?
Next you'll make a query to answer that question.
| Row | bikeid | starttime | start_station_name | end_station_name |
|---|---|---|---|---|
| 1 | 18447 | 2013-09-16T19:22:43 | 9 Ave & W 22 St | W 27 St & 7 Ave |
| 2 | 22598 | 2015-12-30T13:02:38 | E 10 St & 5 Ave | W 11 St & 6 Ave |
| 3 | 28833 | 2017-09-02T16:27:37 | Washington Pl & Broadway | Lexington Ave & E 29 St |
| 4 | 21338 | 2017-11-15T06:57:09 | Hudson St & Reade St | Centre St & Chambers St |
| 5 | 19888 | 2013-11-07T15:12:07 | W 42 St & 8 Ave | W 56 St & 6 Ave |
This is a list of station locations in New York City where you can hire a bike. You now know how to query the Citi Bike trips dataset.
BigQuery is great for answering questions through data. Learning the query syntax will assist in providing insight through data.
Thinking about the query that was just run...
Try another type of query. In some instances, it may be useful to filter a dataset to present a more granular view.
In the following example, use BigQuery to implement a date range.
You should receive a result similar to the following:
| Row | start_date | start_station_id | total_trips |
|---|---|---|---|
| 1 | 2016-01-27 | 3119 | 15 |
| 2 | 2016-04-07 | 3140 | 83 |
| 3 | 2016-08-15 | 254 | 109 |
| 4 | 2016-05-10 | 116 | 217 |
| 5 | 2016-07-07 | 268 | 151 |
You now know how to filter query results by date range.
Building queries involves learning commands to manipulate the data. Based on the last query you can now group the trips by date and station name.
Click Check my progress to verify the objective.
From the last query run, you now have one row per date, per start_station, and the number of trips for that day. This data can be stored as a table or view.
In the next section you will create the following structure for your training data:
| Type | Name |
|---|---|
| Dataset | bqmlforecast |
| Table | training_data |
bqmlforecast.You now have a dataset in which to host your data.
Unfortunately you do not currently have any data created. Correct that by running a query and saving the results to a table.
IN clause chooses just 5 of the stations to include in the model to reduce the size of the training data. Training a full model requires more time than is available for this lab. You can now use this query as the basis for training our model.
training_data .Click Check my progress to verify the objective.
The next query will use the training data to create a ML model. The model produced will enable you to perform demand forecasting.
ARIMA algorithm for time series forecasting.
Other algorithms are available and can be found in the BigQuery ML documentation.
When you train a time series model with BigQuery ML, multiple models/components are used in the model creation pipeline. ARIMA is one of the core algorithms available in BigQuery ML.
The components used are listed in roughly the order of the steps that are run:
HOLIDAY_REGION. With holiday effects enabled, spike and dip anomalies that appear during holidays will no longer be treated as anomalies. A full list of the holiday regions can be found in the HOLIDAY_REGION documentation.LOgical regrESSion (Loess STL) algorithm. Seasonality extrapolation using the double exponential smoothing (ETS) algorithm.Akaike information criterion (AIC).You can train a time series model to forecast a single item, or forecast multiple items at the same time (which is really convenient if you have thousands or millions of items to forecast).
To forecast multiple items at the same time, different pipelines are run in parallel.
In this example, since you are training the model on multiple stations in a single model creation statement, you will need to specify the parameter TIME_SERIES_ID_COL as start_station .
If you are only forecasting a single item, then you would not need to specify TIME_SERIES_ID_COL .
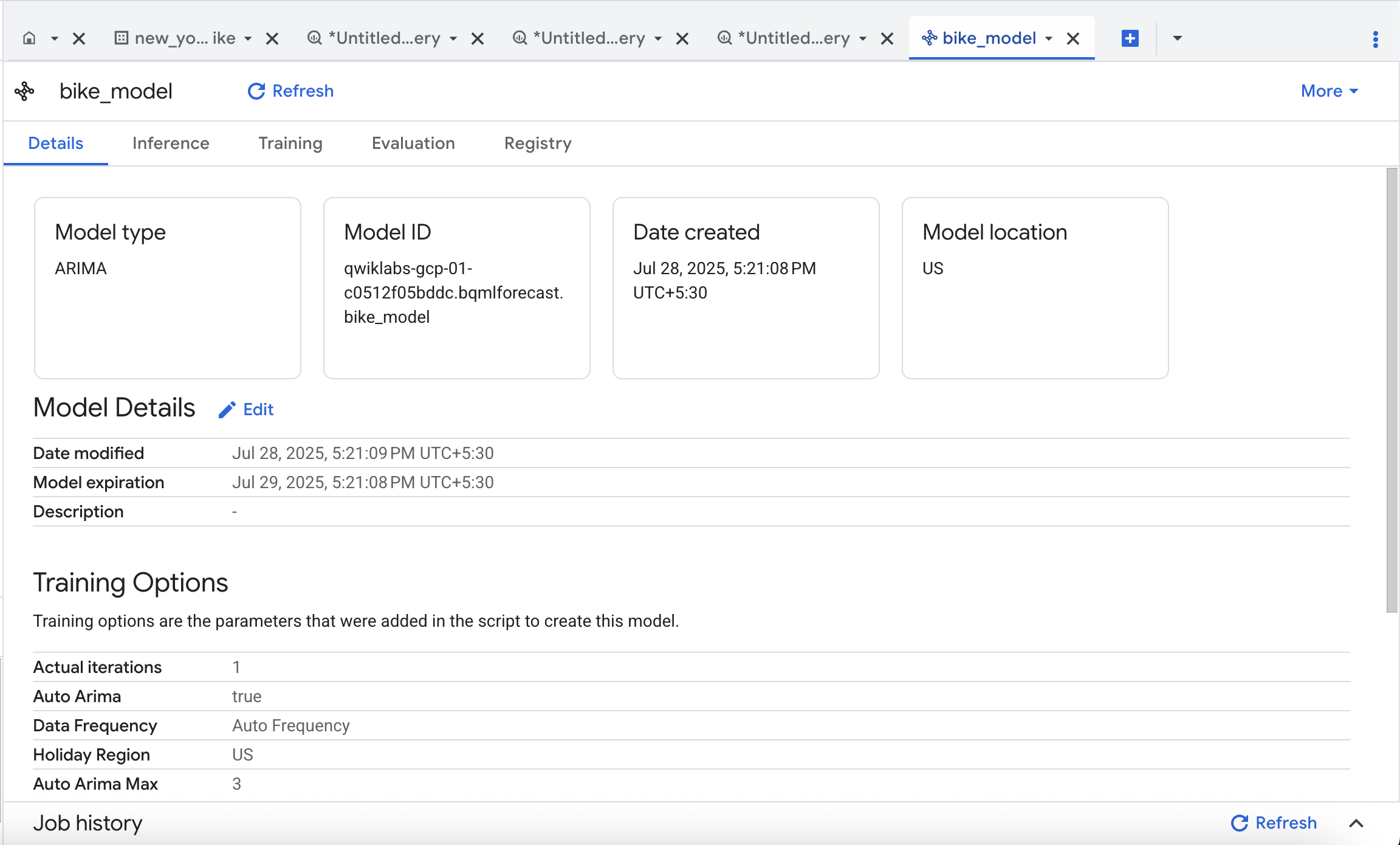
When you see a green check mark the model has successfully completed, and you can use it to perform a forecast!
If you are still waiting for your model to train, you can start watching this YouTube video that discusses building and deploying a demand forecasting solution just like this lab but with a different data set. Just remember to come back to your lab - remember, this lab is only available for a set amount of time!
Go to model in the results tab.Thinking about the query that was just run...
Click Check my progress to verify the objective.
Watch How time series models work in BigQuery ML to understand how time series models work in BigQuery ML.
The model produced can be queried. Based on the prior query you now have a new model available. You can use the ML.EVALUATE function (documentation) to see the evaluation metrics of all the created models (one per item):
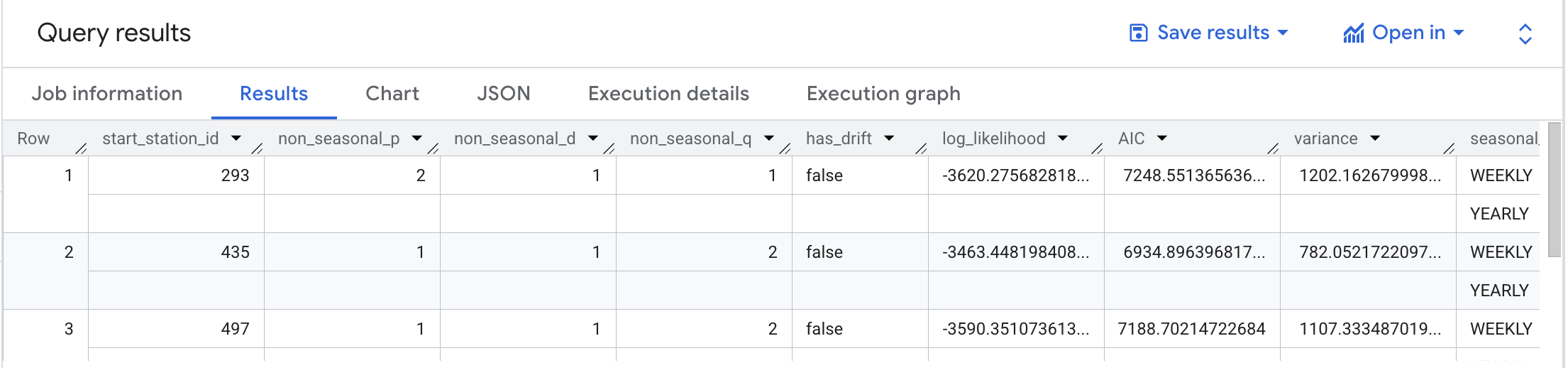
Running the above query should provide results similar to the image below:
There are five models trained, one for each of the stations in the training data.
non_seasonal_{p,d,q} and has_drift) define the ARIMA model.log_likelihood, AIC, and variance) are relevant to the ARIMA model fitting process.The fitting process determines the best ARIMA model by using the auto.ARIMA algorithm, one for each time series. Of these metrics, AIC is typically the go-to metric to evaluate how well a time series model fits the data while penalizing overly complex models.
Finally, the seasonal_periods detected for the five stations are defined as WEEKLY and YEARLY.
Try another question:
Click Check my progress to verify the objective.
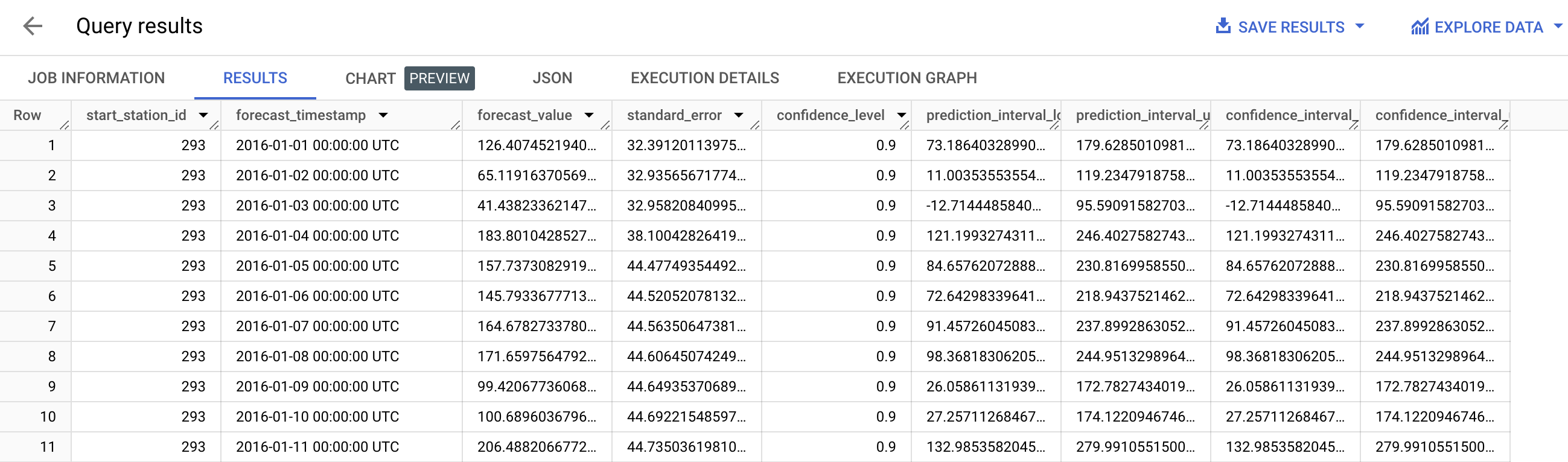
Make predictions using ML.FORECAST (syntax documentation), which forecasts the next n values, as set in horizon.
You can also change the confidence_level, the percentage that the forecasted values fall within the prediction interval.
The code below shows a forecast horizon of "30", which means to make predictions on the next 30 days, since the training data was daily.
This will show results similar to below:
prediction_interval, given the confidence_level.
As you may notice that the SQL script uses DECLARE and EXECUTE IMMEDIATE to help parameterize the inputs for horizon and confidence_level.
As these HORIZON and CONFIDENCE_LEVEL variables make it easier to adjust the values later, this can improve code readability and maintainability.
Learn more about how this syntax works from the Query syntax reference.
Thinking about the query that was just run...
In addition to the above, BigQuery ML also supports scheduled queries. To learn more about scheduled queries, watch Scheduling and automating model retaining with scheduled queries.
Click Check my progress to verify the objective.
You can use the link below to bring in the bigquery-public-data to your own project if you want to explore modeling on other datasets, like forecasting fares for Chicago taxi trips:
You've successfully built a ML model in BigQuery to perform demand forecasting.
To learn more about this subject from developer advocate Polong Lin see:
Here is another example of how to use demand forecasting:
Learn more about the tools used in this lab:
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated August 21, 2025
Lab Last Tested August 21, 2025
Copyright 2025 Google LLC. All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one