




Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Launching cloud dataprep
/ 50
Publish to BigQuery
/ 50
This lab was developed with our partner, Trifacta. Your personal information may be shared with Trifacta, the lab sponsor, if you have opted-in to receive product updates, announcements, and offers in your Account Profile.
Dataprep by Trifacta is Google's self-service data preparation tool built in collaboration with Trifacta. In this lab you will learn some more advanced techniques with Dataprep.
Mount Rainier is one of the tallest active volcanoes in North America. Despite its high probability of eruption, every year thousands of people brave the elements to scale this 14,411 ft (4,392 m) peak. Using information collected from the National Park Services and National Oceanic and Atmospheric Administration (NOAA), you will take a look at how the weather affects the climbers on their expeditions.
In this lab, you will learn how to:
It is recommended that you take the Working with Google Cloud Dataprep lab before attempting this lab.
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources are made available to you.
This hands-on lab lets you do the lab activities in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
Click the Start Lab button. If you need to pay for the lab, a dialog opens for you to select your payment method. On the left is the Lab Details pane with the following:
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
If necessary, copy the Username below and paste it into the Sign in dialog.
You can also find the Username in the Lab Details pane.
Click Next.
Copy the Password below and paste it into the Welcome dialog.
You can also find the Password in the Lab Details pane.
Click Next.
Click through the subsequent pages:
After a few moments, the Google Cloud console opens in this tab.

In the Cloud Console go to the Navigation menu, and under Analytics select Dataprep.
To get into Cloud Dataprep, check that you agree to Google Dataprep Terms of Service, and then click Accept.
Click the checkbox and then click Agree and Continue when prompted to share account information with Trifacta.
Click Allow to give Trifacta access to your project.
Select your lab credentials to sign in and click Allow.
Check the box and click Accept to agree to Trifacta Terms of Service.
If prompted to use the default location for the storage bucket, click Continue.
Click Check my progress to verify the objective.
The data contains information from the National Park Service about Mount Rainier ascension attempts. The climb data is separated by year. There is also weather data from NOAA taken from the Mount Rainier Paradise Ranger station over the same period of time.
Click Create a new flow in the top right corner.
Click Untitled Flow and in the Rename dialog, for Flow Name, use Rainier Climbs.
Click OK.
Click on the (+) under Dataset to add a new source.
Click Import datasets and click the Cloud Storage browser on the left.
Navigate to the bucket with your Project ID.
You can see that this folder contains data from each year starting from 2006 to 2015. It also includes information on the weather forecast for the corresponding years. For this lab, you will use all the datasets.
You could individually bring in every single dataset and union them, but what happens when you get a new file with the latest years? You would have to add in another dataset and rebuild your union. What if you could avoid all of that work and just create a rule that will account for new files in the pipeline?
Dataset parameterization allows you to use patterns or variables to match multiple files when importing or publishing data.
Hover over one of the expedition datasets. On the right, an option to parameterize the dataset will appear. Click to Parameterize the import data.
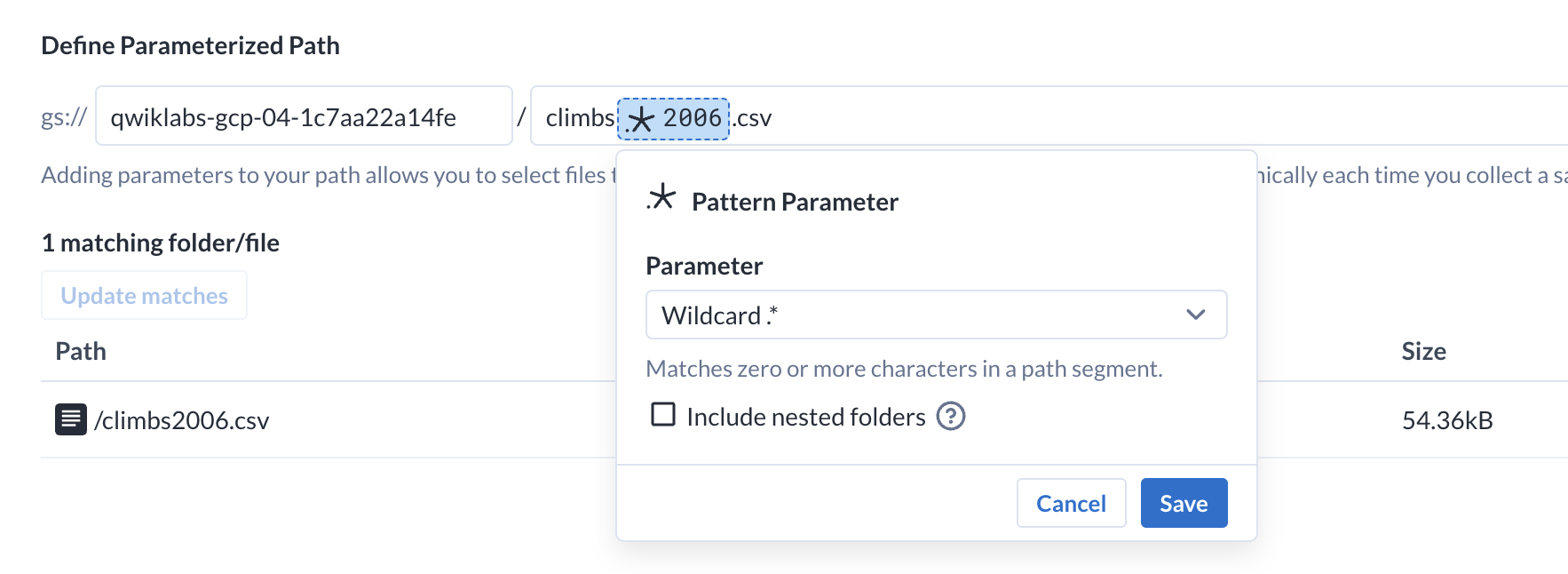
This will open the parameterization wizard. At first, it pre-populates the selection with the file path to the data you selected.
Select the portion of the path that you would like to parameterize. Notice that all of the climb data are named as "climbs", followed by the year. Highlight the year (2006) in the path.
Once some text is highlighted, you can see options to change the highlighted portion of the path into a parameter. Select the Add Pattern Parameter parameter.
Choose Wildcard .* from the Parameter dropdown and click Save.
This parameter will match any files that begin with "climbs" and ends with ".csv". On the lower portion of the screen, you can see Dataprep update to reflect any files that match the parameter.
Click Create on the bottom right to create a dataset with this parameter. All of the matching files will be concatenated into one large dataset as input for your recipe.
Click Import & Add to Flow to add the sources.
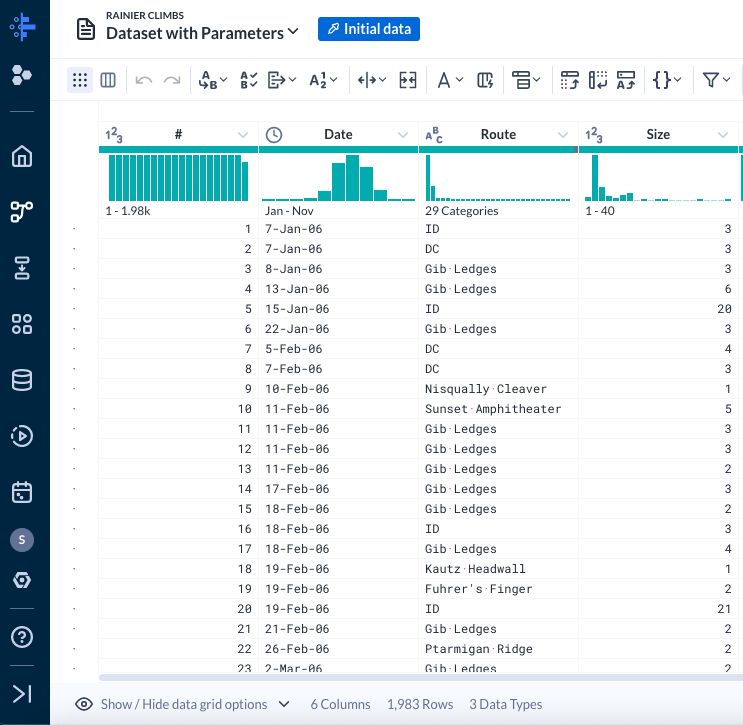
A new dataset called Dataset with Parameters is created and placed on the Flow View. A recipe and an output are created automatically for this dataset as well.
Double click on the recipe node to edit the Dataset with Parameters recipe.
When the dataset is first loaded, you may notice the dataset has 6 columns and only 1,983 rows.
That row count seems low for a span of 9 years. If you look at the Date column, you may notice in the histogram that it only contains values from 2006. Why is that?
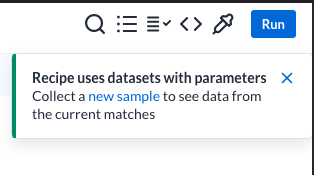
You may also have noticed the notification that showed up in the upper right.
Remember that in Dataprep, you are creating transformations on a sample of the dataset. In this case, it only loaded the first dataset of the parameterized input, just to give you a preview of the data.
Here you can see the current visible samples, as well as other available samples. You can also choose to collect a new sample at any point.
Under Collect new sample, select Random.
Choose Quick and click Collect to collect a new random sample. A random sample is a sampling technique in which each row has an equal probability of being chosen.
Dataprep is now preparing the new sample for you in the background. The progress can be seen in the panel.
Depending on the size and complexity of the sample, it may take a few minutes to collect. You can continue exploring and manipulating the data with the current sample while the new one collects.
While the sample collects in the background, you can take a brief look at your data. The climb data contains 6 columns:
# - An incrementing climb IDDate - The date of the climbRoute - The route takenSize - The size of the climbing partySummit - The number of people who summit the peakLeader Zip Code - The zip code of the leader of the climbing partyMake a note of the format of the Date column (7-Jan-06).
Make a note of the distribution of the Date column. (There are multiple climbing parties per day).
The standard BigQuery datetime format is yyyy-MM-ddTHH:mm:ss. Since the end goal is to publish this data to BigQuery, it is best to adhere to that format. Dataprep allows for easy manipulation of datetime columns.
Click the dropdown next to the Date column and select Format > Change datetime format > Date.
This will bring up the Date Format transform builder. Under output format, select the format, in this case, yyyy-MM-dd. Check the preview and then click Add.
To analyze how the weather affects the summit success rate, the weather data needs to be brought in. That weather data is in another dataset. While Dataprep collects your climb data sample, you can explore the weather dataset.
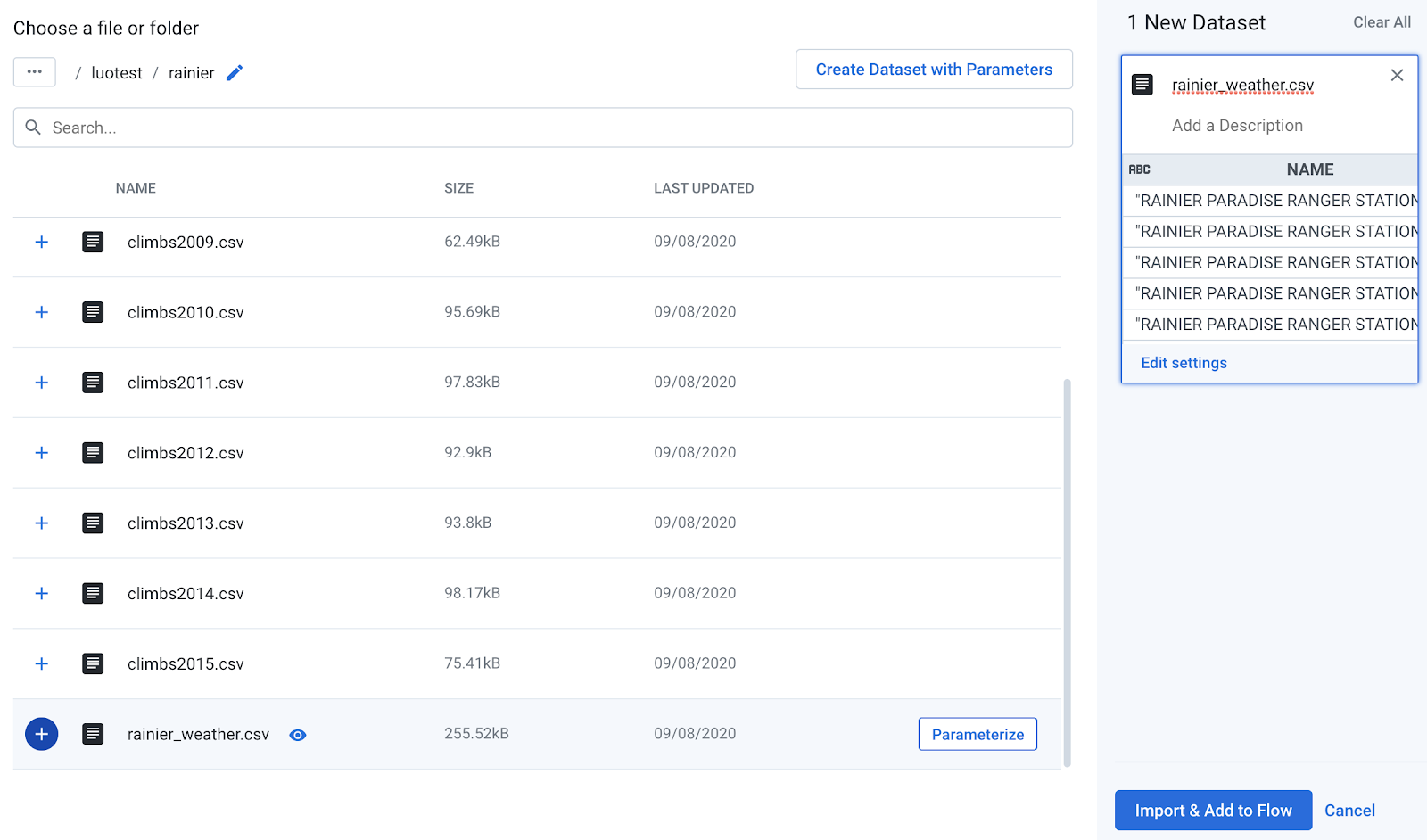
RAINIER CLIMBS.At the top right of the Flow View page, click the Add datasets button to add a new dataset to this flow.
Click Import datasets on the bottom left of the dialog.
rainier_weather.csv dataset.
A new node appears on the Flow canvas for the weather data. Click the plus (+) sign next to it and select Add new recipe.
Rename the Untitled recipe as rainier weather and double click the new recipe node to edit the recipe.
The weather data contains the following columns:
NAME - The name of the weather station that took the measurementsELEVATION - The elevation of the weather stationDATE - The date of forecastMultiday_precipitation_total - The total amount of rainfall across multiple days in inchesMultiday_snowfall_total - The total amount of snowfall across multiple days in inchesPrecipitation_inches - The inches of rainfall for that particular daySnowfall_inches - The inches of snow for that particular daySnow_depth - The depth of snow surrounding the station in inchesTemp_max - The forecasted high temperatureTemp_min - The forecasted low temperatureTemp_observed - The temperature observed at noonFog - (Boolean) for foggy weatherNote the format of the dates in this dataset: 2/22/06.
Looking across all of the columns, you can see that Dataprep tried to infer data types based on the most popular values in the columns. However, some of the inferred data types are not what is expected. For example, the majority of values in Snowfall_inches are integers, so the tool inferred the column type as integer, and marked any decimals as mismatched. With dirty data, often you will have to do additional exploration to truly understand what data type is appropriate for each column.
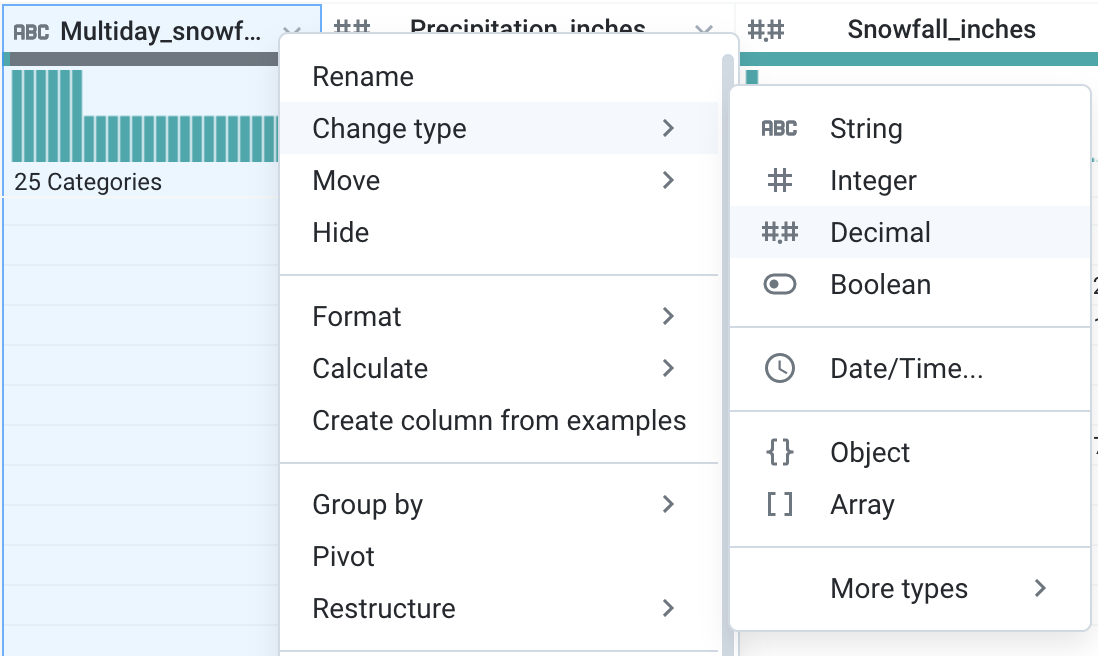
For the following columns, change the data type to decimal. Use the dropdown menu next to the column and select Change type > Decimal.
Multiday_precipitation_totalMultiday_snowfall_totalSnowfall_inchesNext, take a look at some of the missing values in this dataset. Click on the gray area of the data quality bar for Precipitation_inches. Doing so will cause Dataprep to suggest Transformations for the selected area. Additionally, it highlights the rows that are empty. Scroll through the dataset to see some of the highlighted rows.
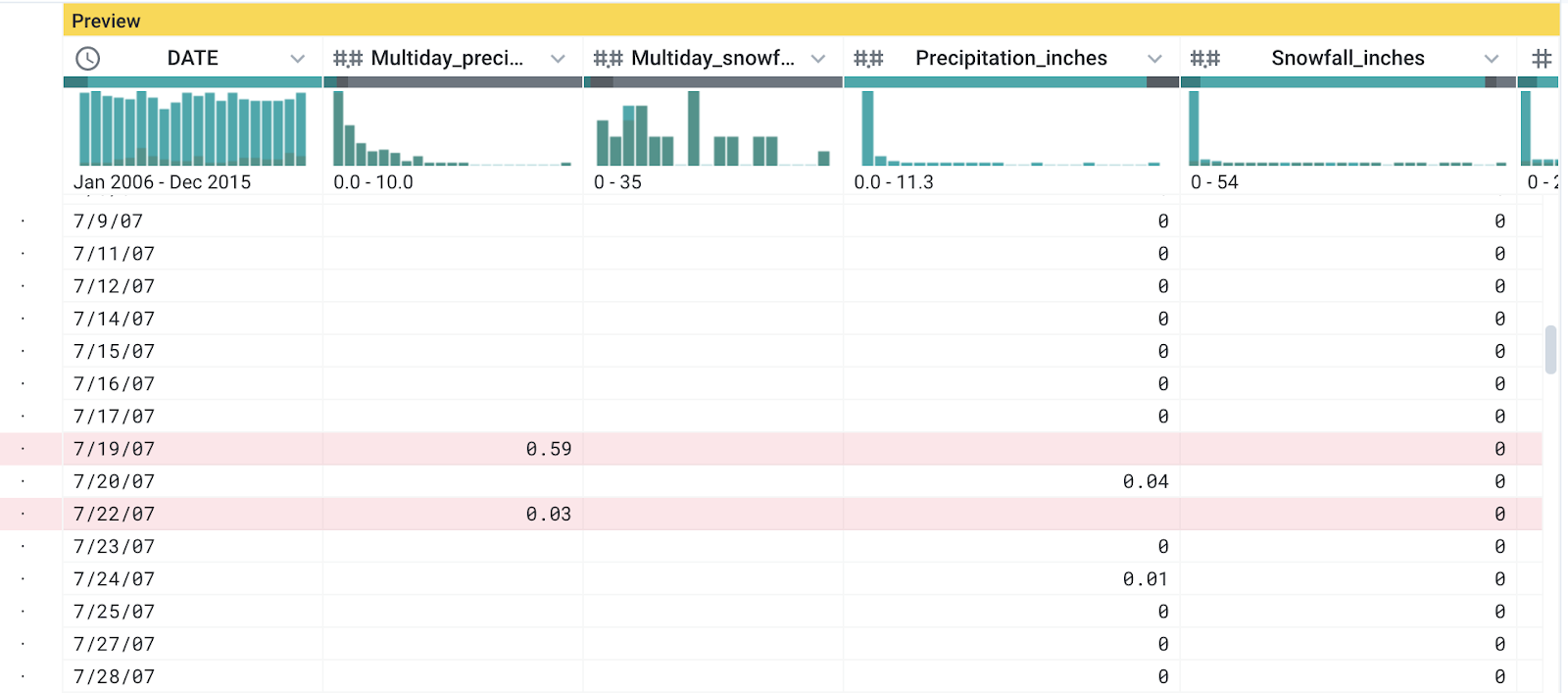
As you scroll down, you may notice that many of the empty rows in Precipitation_inches have valid values in the Multiday_precipitation_total column.
Not every row follows this pattern, but for the ones that do, it's also very likely that there is a gap in the date as well.
For example, you can see in this screenshot that the data for dates 7/18/07 and 7/21/07 are missing. It seems that for days of constant precipitation, the data is not recorded with daily granularity.
It's possible to fill in these dates and values using more complicated logic, but for now, you can coalesce the values in the multi-day and single day precipitation columns to get this dataset in shape to join with the climbs data.
Click on the column header of Multiday_precipitation_total to select the column.
Hold CTRL or CMD, and click on the header for Precipitation_inches to select 2 columns together.
From the suggestions, under Create a new column, choose the COALESCE([Multiday_precipitation_total,Precipitation_inches]) option and Add it.
The COALESCE function returns the first non-empty value found in the 2 columns, essentially merging the columns into a single column.
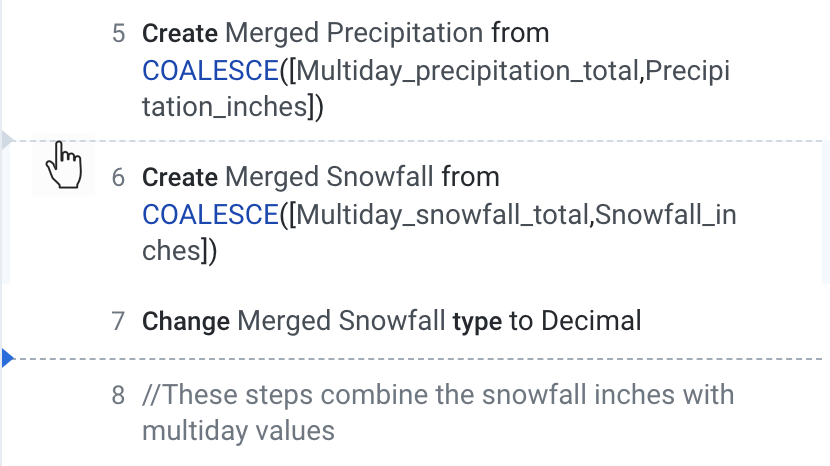
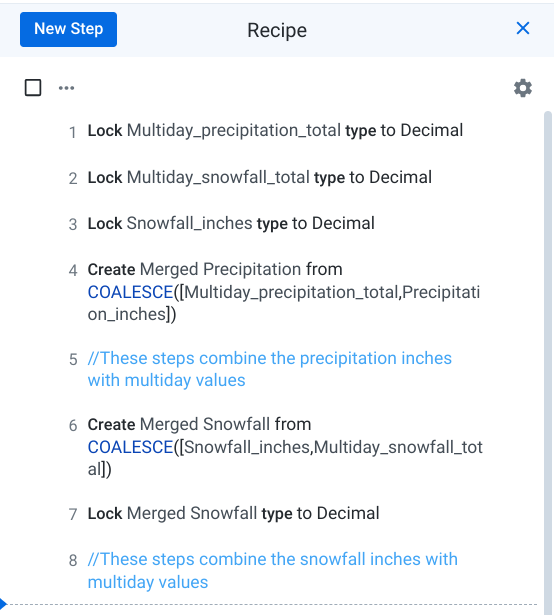
Edit the previous recipe step or add a new recipe step to rename the column to Merged Precipitation.
Repeat the Coalesce step for the Snowfall_inches and Multiday_snowfall_total columns. Name the new column Merged Snowfall. Lastly, change the data type from the dropdown menu of the new column to decimal.
While Dataprep displays the transformations in easily readable natural language, if you don't work on a recipe for a long time or share the recipe with others, it may take some deciphering to figure out what the steps do. To help with reusability, you can add comments to your recipes to help annotate and describe your steps.
Describe the previous steps, ie. "These steps combine the snowfall inches with multi day values".
Click Add. Comments will show up in blue with two slashes in front. Comments steps do not change the data and are not executed during job runs.
Now that you know how to insert comments, it makes sense to go back and insert a similar comment next to the step that produced the merged precipitation column.
The Recipe View Line serves 2 purposes:
To set the RVL, simply hover in the space in between 2 steps. A gray dotted line will appear to indicate you are mousing over a RVL. Click to set the RVL to that step. The active RVL is indicated by a blue dotted line.
In this screenshot, the RVL is currently between steps 7 and 8.
Notice that, after you have set the RVL after step 5, the column Merged Snowfall no longer shows up in the grid. This is because the steps after the RVL are not displayed in the data grid, allowing you to quickly review the data after different transformations.
Add the comment "These steps combine the precipitation inches with multi day values" to the recipe.
Set the RVL back to the bottom of the recipe. Your recipe should now resemble the following:
By now, your random sample collection on the climb data should be finished.
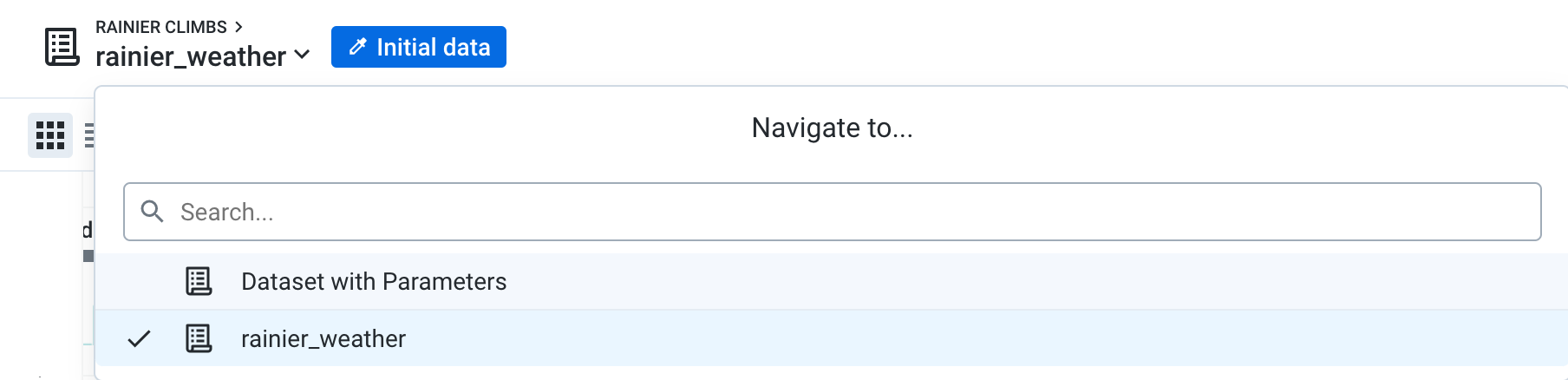
Quickly switch to the climb data by clicking on the dropdown next to the recipe name at the top.
Click on Dataset with Parameters to quickly switch to the other recipe in the flow.
Once the recipe is switched, click on Initial data again to open the Samples panel.
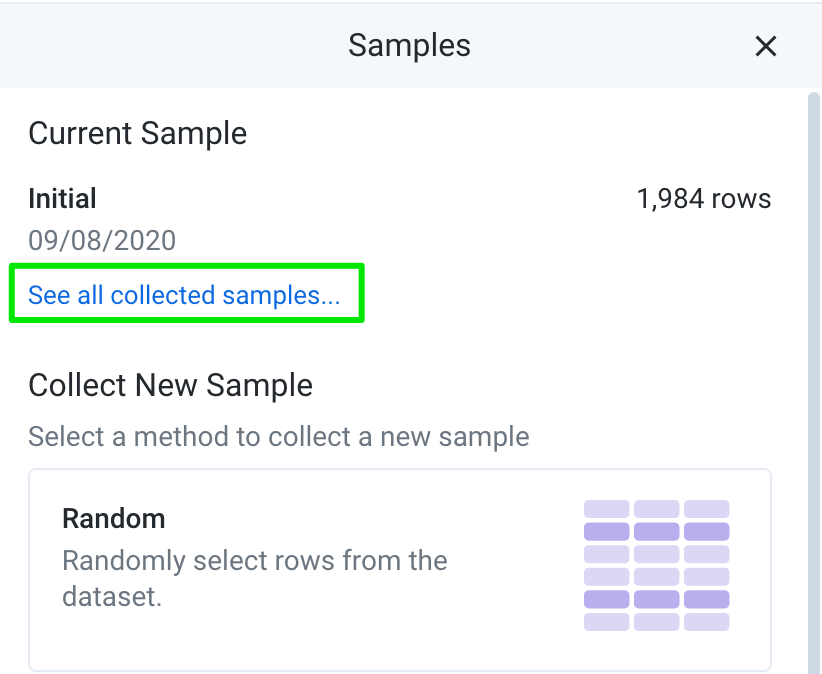
In the Samples panel, click on See all collected samples.
Under Available samples, you should see 2 options: Initial, which is currently selected, and Random. Click on Random to switch to that sample.
Click Load. Once the sample is loaded, you should see:
Now that you have more rows of data, you can summarize the data to make downstream analysis easier. As you saw when you initially opened this dataset, the climbing dataset has multiple parties per day.
In the Row labels section, select the Date column.
Note how the grid changes to show you how the table will look.
SUM(Size) & SUM(Summit).The other columns (#* and *Leader Zip Code) will be dropped out as they are not necessary for the analysis.
Click Add to accept the aggregation. This pivot summarizes the total number of climbers who set off and summited on each day.
You can now calculate the overall success rate for any given day by dividing the sum_Summit by sum_Size. From the toolbar, click the Functions icon then select Math > DIVIDE.
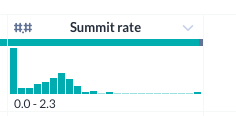
DIVIDE(sum_Summit, sum_Size) and name the new column Summit rate. Click Add.Depending on your sample, you may see that the histogram for the Summit rate shows values above 1.
This is odd, because a summit rate above 1 would mean that more people summited than ascended the mountain on a given day. This could indicate that people are camping on the mountain across multiple days or changing expedition groups, but it might skew some of your analysis if the success rate is over 100%. Next, you will create a condition to fix some of the issues.
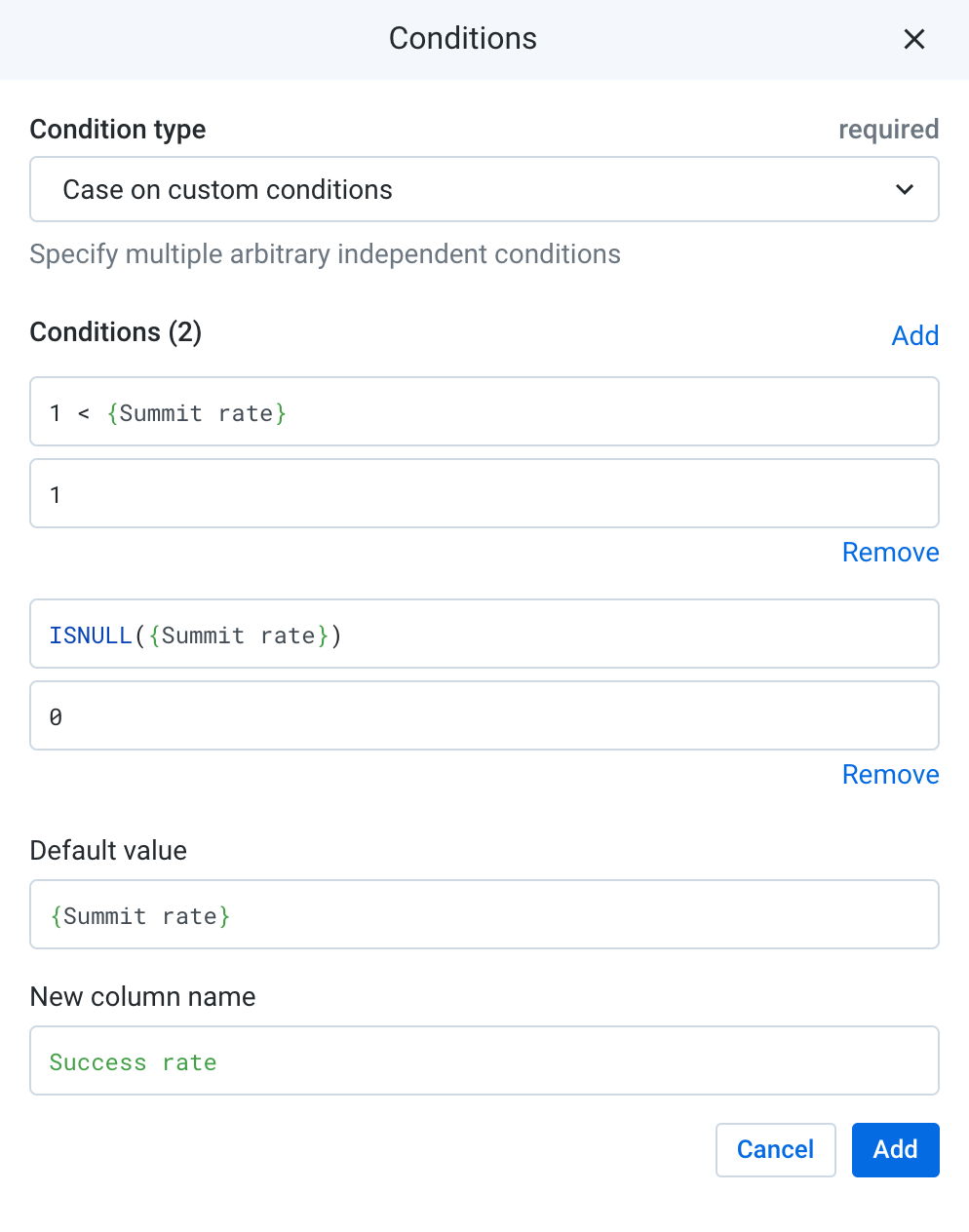
In the Conditions, the first box is the condition to evaluate and the second box is the value if the case is true. Enter 1 < {Summit rate} into the first box and 1 into the second box. This means, if the summit rate is over 1, then simply set it to 1. (The curly brackets { } around the column name is used to denote any columns with whitespaces)
You can add more cases by clicking on Add next to the Conditions argument.
New condition boxes appear. Enter ISNULL({Summit rate}) into the first box and 0 into the second box. For certain rows with sum_Size of 0, the previous calculation for Summit rate would have divided by 0 and produced a null, so just set that to 0.
For Default value, enter {Summit rate}. For any rows that do not evaluate true to the previous conditions, it simply fills in the existing value for Summit rate.
Name the new column "Success rate" and add the step to the recipe. Click Add. Your condition should resemble the following:
Now that you have the climbing data summarized to the day level, you are ready to join in the weather data.
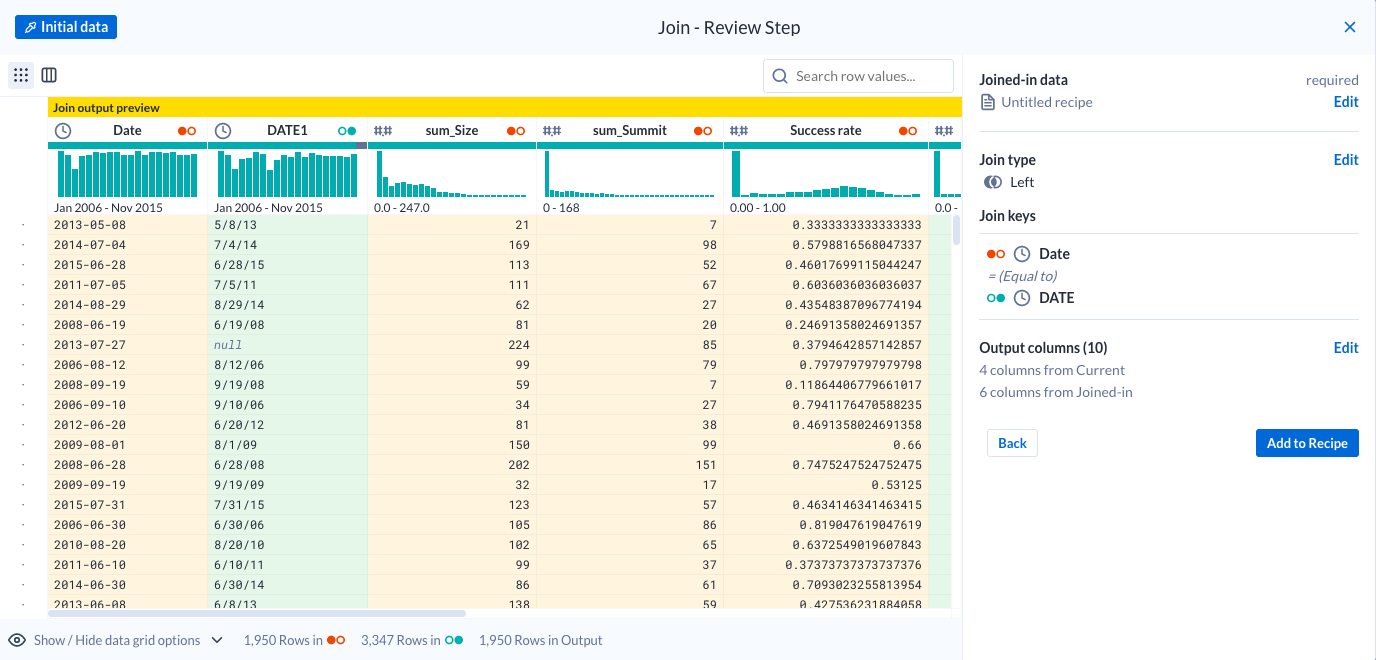
Select the weather dataset to join and click Accept.
Change the Join type to Left.
Edit the Join key to match the Date column = DATE column.
In the preview, notice that Dataprep is able to join on a datetime column that is not in the exact same format.
Also note that because a left join is selected, some rows do not have any matches. (Depending on your sample, the percentage of unmatched rows will vary.)
Click Next to select the output columns. Keep the following columns, the rest will be dropped automatically after the join.
DateDATEsum_Sizesum_SummitSuccess rateMerged PrecipitationMerged SnowfallSnow_depthTemp_observedFogClick Review. The join should look something like this:
Click Add to recipe.
Now that the join is added, you can see that there is weather data missing for some days so you won't be able to use them in your analysis. You can choose to delete the rows where DATE1 is missing or keep them in the dataset.
Now that you have joined the data, you can publish the results to BigQuery.
Click the Run button to create an output.
In the Publishing Actions section, Dataprep will create a CSV file by default. Hover over the action and click the Edit button to change the publishing destination to BigQuery instead.
Choose BigQuery from the list of systems on the left.
Choose the Dataprep database and click Create a new table on the right.
Based on the column names you created, you should see an error message on the top.
This is indicating that BigQuery cannot take column names with spaces in it and your dataset has a few of these.
Click Cancel to exit the Publishing action dialog, and Cancel again to exit the Run Job dialog. Open up the Dataset with Parameter recipe again.
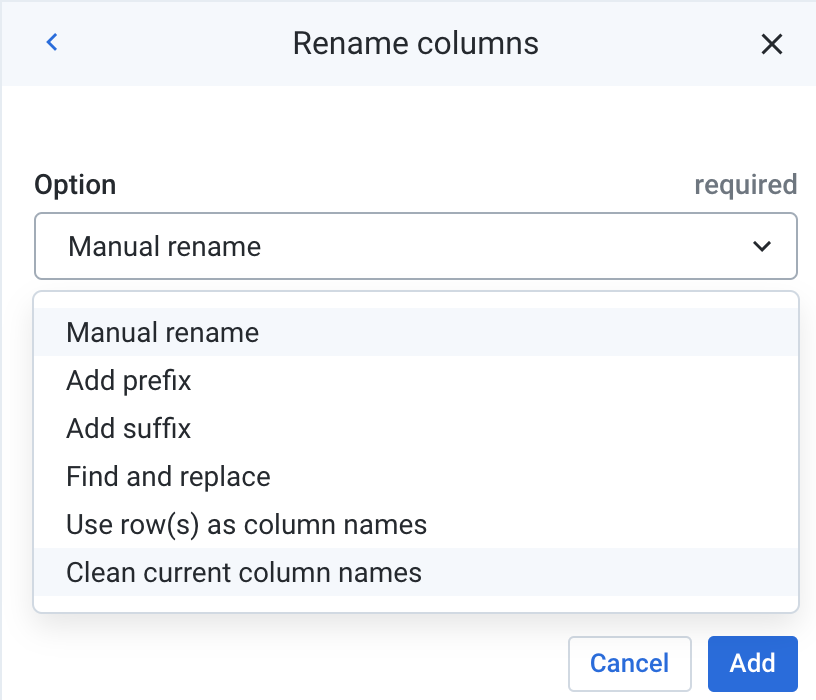
Dataprep can quickly fix up issues with column names by removing all special characters. Click on the chevron next to any column and choose Rename.
Under the Option dropdown, choose Clean current column names. Notice how the preview affects all columns and has replaced any spaces with underscores. Click Add.
Now that the column names are fixed, repeat Steps 1-4 and create a new table called RainierLab. Choose Truncate the table every run and Update the destination.
Click Run. This can take several minutes.
Click Check my progress to verify the objective.
Once the job is finished, build a quick visualization of the data.
Return to the Cloud Console and from the Navigation menu select BigQuery. If prompted click Done.
In the SQL query editor, run the following query:
Once the results are returned, click the Explore Data dropdown and select Explore with Looker Studio. This will open Data Studio in another tab.
Accept all the agreements for Data Studio.
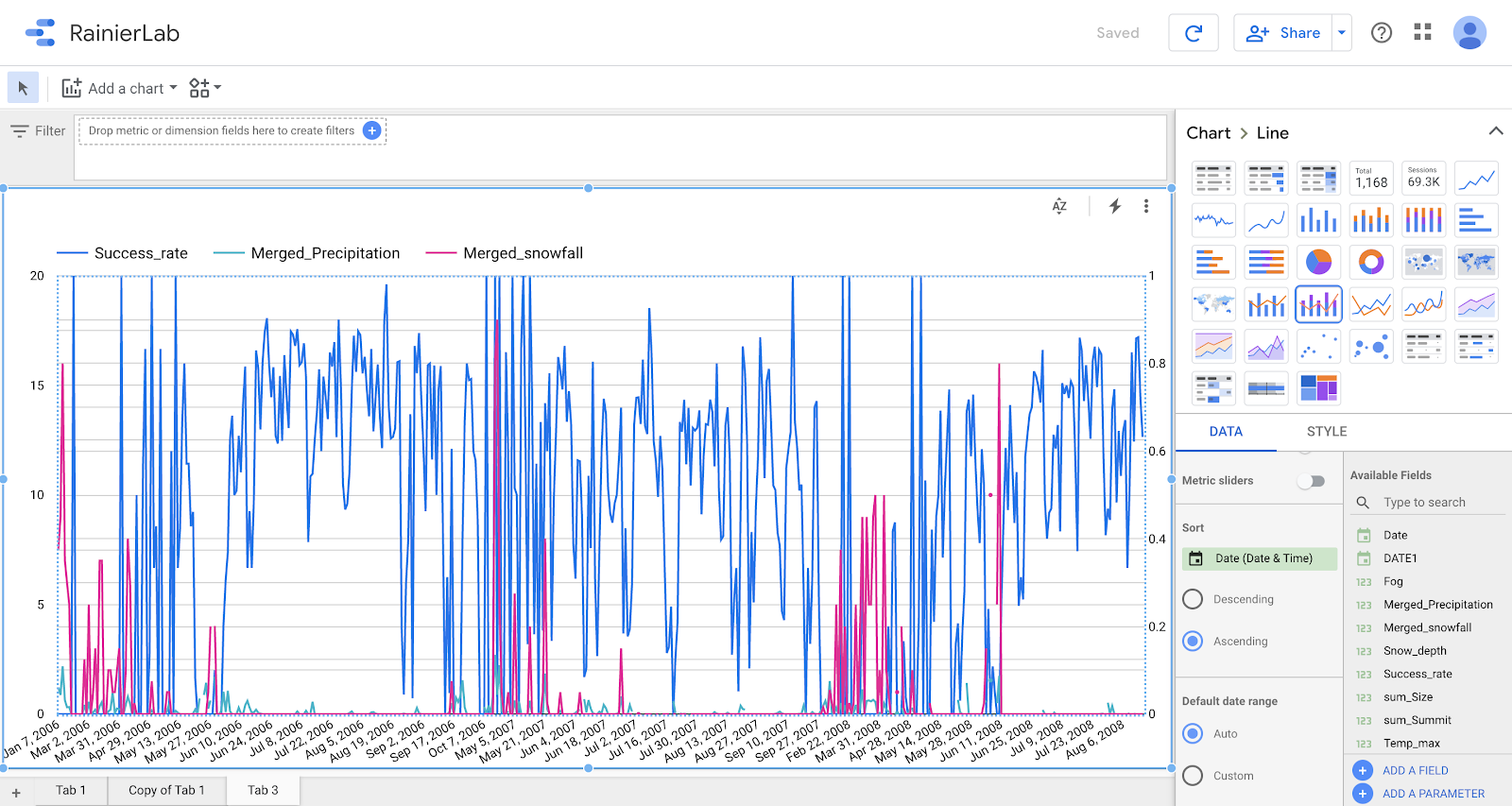
Now you can build a simple visualization. Click Add a chart and choose Line > Stacked Combo chart.
In the Setup tab on the right, keep Date Range Dimension as Date (Date) and Dimension as Date.
Toggle Optional metrics. Drag Success_rate, Merged_Precipitation, and Merged_Snowfall from the Available Fields to the Metric section. Remove the other metrics and position your Success_rate metric above the others.
Lastly, sort by Date ascending. Your configuration should resemble the following:
You can play around with the other style settings to whatever suits your taste.
Based on the graph, what can you conclude about the relation of summit success relative to precipitation and snowfall?
In your own Dataprep project, all of the flows are saved and can be reused. However, for Qwiklabs, these projects are temporary and deleted after the lab. Dataprep allows you to export your flows to use with version control systems, or import them into another environment or share them with colleagues. To save your work for the next lab, you can export the flow you created.
Return to the Rainier Climb Flow View.
On the top right, open the More Menu (...) and select Export.
flow_Rainier_Climbs.zip. You can use this file in the next lab if you so choose.In this lab, you got hands-on experience with Dataprep by creating parameterized datasets, leveraging new samples, and creating conditional cases and aggregations. You also manipulated datetimes, cleaned headers to publish to BigQuery, and visualized your results in Data Studio.
Explore Dataprep Professional Edition with a free 30-day trial available. Please make sure to sign out from your temporary Qwiklabs account and re-sign with your Google Cloud valid email. Advanced features, such as additional connectivity, pipeline orchestration, and adaptive data quality are also available in the Premium edition that you can explore in the Google Cloud Marketplace.
Read the how-to guides to learn how to discover, cleanse, and enhance data with Google Dataprep.
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated December 27, 2024
Lab Last Tested December 27, 2024
Copyright 2025 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.



This content is not currently available
We will notify you via email when it becomes available

Great!
We will contact you via email if it becomes available

One lab at a time
Confirm to end all existing labs and start this one