Puntos de control
Scale Up Hello App
/ 30
Create node pool
/ 30
Managing a Regional Cluster
/ 20
Simulate Traffic
/ 20
Explora la optimización de costos para máquinas virtuales de GKE
GSP767

Descripción general
La infraestructura subyacente de un clúster de Google Kubernetes Engine se compone de nodos que son instancias individuales de VMs de procesamiento. En este lab, se muestra cómo la optimización de la infraestructura de tu clúster puede contribuir a que ahorres costos y generes una infraestructura eficaz para tus aplicaciones.
Aprenderás una estrategia para maximizar la utilización (y evitar la infrautilización) de tus recursos de infraestructura valiosos, a través de la selección de tipos de máquina con el tamaño adecuado para una carga de trabajo de ejemplo. Además del tipo de infraestructura que estás usando, la ubicación geográfica física de esa infraestructura también afecta el costo. En este ejercicio, explorarás la creación de una estrategia rentable para administrar clústeres regionales con mayor disponibilidad.
Actividades
- Examinar el uso de recursos de una implementación
- Escalar verticalmente una implementación
- Migrar tu carga de trabajo a un grupo de nodos con un tipo de máquina optimizado
- Explorar las opciones de ubicación de tu clúster
- Supervisar los registros de flujo entre Pods en zonas diferentes
- Trasladar un Pod con alto tráfico para minimizar los costos de tráfico entre zonas
Requisitos previos
- Tener conocimientos sobre máquinas virtuales puede ser útil.
Configuración
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Cómo iniciar su lab y acceder a la consola de Google Cloud
-
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, se encuentra el panel Detalles del lab que tiene estos elementos:
- El botón Abrir la consola de Google
- Tiempo restante
- Las credenciales temporales que debe usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haga clic en Abrir la consola de Google. El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordene las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ve el diálogo Elegir una cuenta, haga clic en Usar otra cuenta. -
Si es necesario, copie el nombre de usuario del panel Detalles del lab y péguelo en el cuadro de diálogo Acceder. Haga clic en Siguiente.
-
Copie la contraseña del panel Detalles del lab y péguela en el cuadro de diálogo de bienvenida. Haga clic en Siguiente.
Importante: Debe usar las credenciales del panel de la izquierda. No use sus credenciales de Google Cloud Skills Boost. Nota: Usar su propia Cuenta de Google podría generar cargos adicionales. -
Haga clic para avanzar por las páginas siguientes:
- Acepte los términos y condiciones.
- No agregue opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No se registre para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Cloud en esta pestaña.

Este lab genera un clúster pequeño que tú usarás. El aprovisionamiento del clúster demora entre 2 y 5 minutos.
Si presionaste el botón Comenzar lab y ves un mensaje azul en el que se indica que se están aprovisionando los recursos con un círculo giratorio, tu clúster todavía se está creando.
Puedes comenzar a leer las siguientes instrucciones y explicaciones mientras esperas, pero los comandos de shell no funcionarán hasta que tus recursos terminen de aprovisionarse.
Tarea 1: Comprende los tipos de máquina de nodo
Descripción general
Un tipo de máquina es un conjunto de recursos de hardware virtualizados disponibles para una instancia de máquina virtual (VM) y que incluye el tamaño de la memoria del sistema, el recuento de CPUs virtuales (vCPU) y los límites del disco persistente. Los tipos de máquina se agrupan y seleccionan por familias para diferentes cargas de trabajo.
Cuando eliges un tipo de máquina para tu grupo de nodos, la familia de tipo de máquina de uso general ofrece, normalmente, la mejor proporción de precio y rendimiento para una variedad de cargas de trabajo. Los tipos de máquina de uso general se componen de las series N y E2:
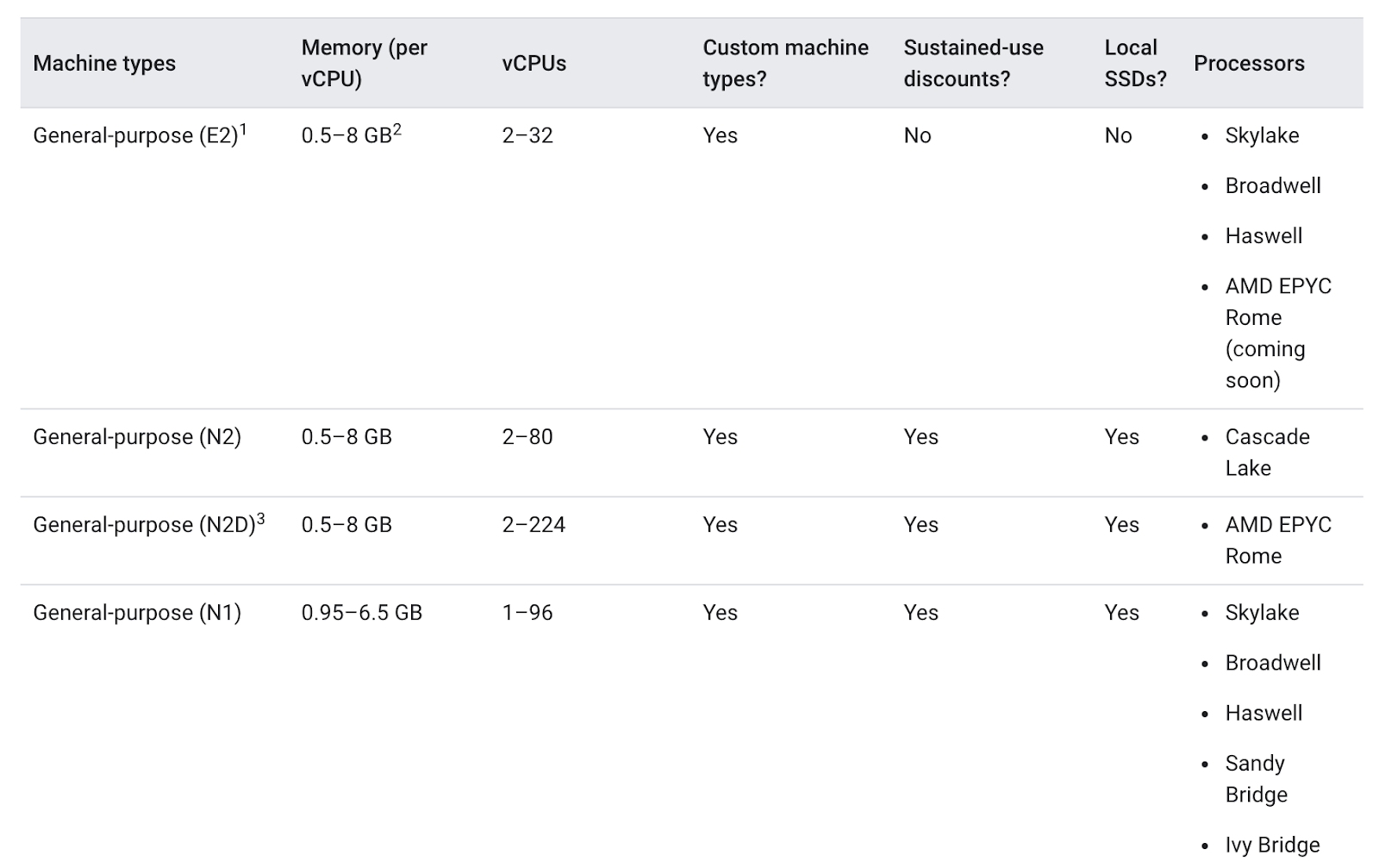
Las diferencias entre los tipos de máquina pueden ser una ventaja o una desventaja para tu app. En general, las E2 tienen un rendimiento parecido a las N1, pero están optimizadas en función del costo. Normalmente, utilizar solo el tipo de máquina E2 puede ser útil para ahorrar costos.
Sin embargo, con un clúster, es más importante que los recursos utilizados se optimicen según las necesidades de tu aplicación. Para aplicaciones o implementaciones más grandes que tengan que escalar en gran medida, puede ser más económico apilar tus cargas de trabajo en algunas máquinas optimizadas, en lugar de dividirlas en varias de uso general.
Para tomar una decisión, es importante comprender los detalles de tu aplicación. Si tu aplicación tiene requisitos específicos, puedes asegurarte de que las características del tipo de máquina sean adecuadas para esta.
En la siguiente sección, verás una app de demostración y la migrarás a un grupo de nodos con un tipo de máquina adecuado.
Tarea 2: Elige el tipo de máquina correcto para la app de Hello
Inspecciona los requisitos del clúster de demostración de Hello
Al inicio, tu lab generó un Clúster de demostración de Hello con dos nodos e2-medium (2 CPUs virtuales, 4 GB de memoria). Este clúster está implementando una réplica de una aplicación web simple llamada app de Hello, un servidor web escrito en Go que responde a todas las solicitudes con el mensaje “Hello, World!”.
- Cuando se complete el aprovisionamiento de tu lab, haz clic en el Menú de navegación de la consola de Cloud y, luego, en Kubernetes Engine.
-
En la ventana de Clústeres de Kubernetes, selecciona hello-demo-cluster.
-
En la siguiente ventana, selecciona la pestaña Nodos:
Ahora, deberías ver una lista de los nodos de tu clúster:

Observa la forma en que GKE ha utilizado los recursos de tu clúster. Puedes ver la cantidad de CPU y memoria que solicita cada nodo, además de la que podría asignar.
- Haz clic en el primer nodo de tu clúster.
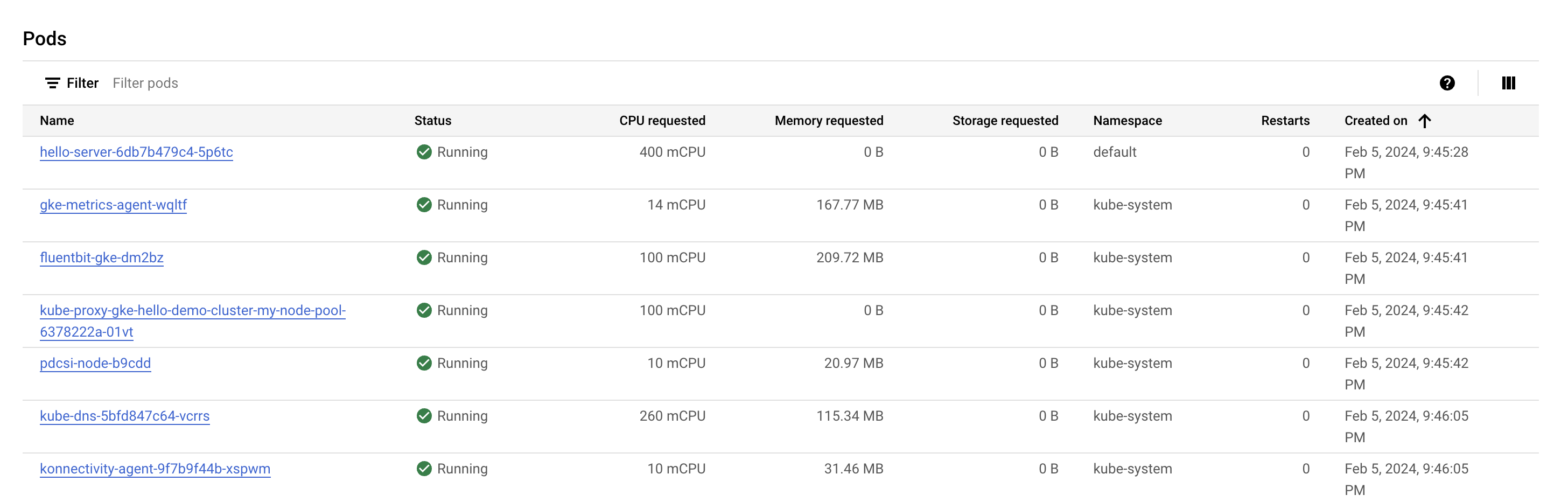
Observa la sección de Pods. Deberías ver tu Pod hello-server en el espacio de nombres predeterminado. Si no ves un Pod hello-server, vuelve y selecciona el segundo nodo de tu clúster.
Te darás cuenta de que el Pod hello-server solicita 400 mcpu. Además, deberías ver un conjunto de otros Pods de kube-system en ejecución. Estos se cargan para ayudar a habilitar servicios de clústeres de GKE, como la supervisión.
- Presiona el botón Atrás para volver a la página anterior de Nodos.
Notarás que se necesitan dos nodos e2-medium para ejecutar una réplica de Hello-App junto con los servicios esenciales de kube-system. Además, cuando usas la mayoría de los recursos de CPU del clúster, solo estás usando alrededor de un tercio de su memoria asignable.
Si las cargas de trabajo para esta aplicación fueran completamente estáticas, podrías crear un tipo de máquina con una forma personalizada que tenga la cantidad exacta y necesaria de CPU y memoria. Por consiguiente, esto ahorraría costos en la infraestructura general del clúster.
Sin embargo, los clústeres de GKE suelen ejecutar múltiples cargas de trabajo que, en general, necesitan escalar vertical y horizontalmente.
¿Qué pasaría si la app de Hello escalara verticalmente?
Activa Cloud Shell
Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
- Haz clic en Activar Cloud Shell
en la parte superior de la consola de Google Cloud.
Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu PROJECT_ID. El resultado contiene una línea que declara el PROJECT_ID para esta sesión:
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
- Puedes solicitar el nombre de la cuenta activa con este comando (opcional):
-
Haz clic en Autorizar.
-
Ahora, el resultado debería verse de la siguiente manera:
Resultado:
- Puedes solicitar el ID del proyecto con este comando (opcional):
Resultado:
Resultado de ejemplo:
gcloud, consulta la guía con la descripción general de gcloud CLI en Google Cloud.
Escala verticalmente la app de Hello
- Accede a las credenciales de tu clúster:
- Escala verticalmente tu
Hello-Server:
Haz clic en Revisar mi progreso para verificar la realización de la tarea indicada arriba.
- En la consola, selecciona Cargas de trabajo en el menú de Kubernetes Engine que se encuentra en el lado izquierdo.
Deberías ver el hello-server con el estado de error No tiene disponibilidad mínima:
- Haz clic en el mensaje de error para obtener detalles sobre el estado. Verás que la razón es
CPU insuficiente.
No es sorprendente. Si lo recuerdas, el clúster casi no tenía más recursos de CPU y tú solicitaste otros 400 mcpu con otra réplica de hello-server.
- Aumenta tu grupo de nodos para manejar la nueva solicitud:
-
Cuando se te solicite continuar, escribe
yy presionaIntro. -
En la consola, actualiza la página Cargas de trabajo hasta que veas que el estado de la carga de trabajo
hello-serverindique OK:

Examina tu clúster
Después de escalar verticalmente la carga de trabajo de forma correcta, regresa a la pestaña de nodos de tu clúster.
- Haz clic en hello-demo-cluster:

- Luego, haz clic en la pestaña Nodos.
El grupo de nodos más grande puede manejar la carga de trabajo más pesada, pero debes prestar atención a la forma en que se utilizan los recursos de tu infraestructura.

Aunque GKE usa los recursos de un clúster lo mejor que puede, aún es posible una optimización. Puedes ver que uno de tus nodos usa la mayoría de su memoria, pero dos de ellos tienen una cantidad considerable de memoria sin utilizar.
En este momento, si sigues escalando verticalmente la app, comenzarás a observar un patrón similar. Kubernetes trataría de encontrar un nodo para cada réplica nueva de la implementación de hello-server, fallaría y, luego, crearía un nodo nuevo con alrededor de 600 mcpu.
Un problema de empaquetado en contenedores
En un problema de este tipo, debes colocar elementos de varios volúmenes y formas en una cantidad finita de “discretizaciones” o contenedores de tamaño regular. Básicamente, el desafío es “acomodar” los elementos de la forma más eficiente posible para colocarlos en la menor cantidad de discretizaciones.
Esto es parecido al desafío que se presenta cuando tratas de optimizar clústeres de Kubernetes para las aplicaciones que ejecutan. Tienes una cantidad de aplicaciones, probablemente con diversos requisitos de recursos (es decir, memoria y CPU). Debes tratar de acomodarlas en los recursos de infraestructura que Kubernetes administra por ti (en los que quizá se encuentren la mayoría de los costos de tu clúster) de la forma más eficiente posible.
Tu clúster de demostración de Hello no realiza un empaquetado muy eficiente. Sería más rentable configurar Kubernetes para que use un tipo de máquina más adecuado para esta carga de trabajo.
Migra a un grupo de nodos optimizado
- Crea un nuevo grupo de nodos con un tipo de máquina más grande:
Haz clic en Revisar mi progreso para verificar la realización de la tarea indicada arriba.
Ahora, sigue estos pasos para migrar Pods al nuevo grupo de nodos:
-
Acordona el grupo de nodos existente: Esta operación marca los nodos en el grupo de nodos existente (
nodo) como no programables. Kubernetes deja de programar los Pods nuevos en estos nodos en el momento que los marcas como no programables. -
Vacía el grupo de nodos existente: Esta operación expulsa las cargas de trabajo que se ejecutan en los nodos del grupo de nodos existente (
nodo) con facilidad.
- Primero, acordona el grupo de nodos original:
- Luego, vacía el grupo:
En este punto, deberías ver que tus Pods se están ejecutando en el nuevo grupo de nodos, larger-pool:
- Cuando los Pods se hayan migrado, es seguro borrar el grupo de nodos antiguo:
- Cuando se te solicite continuar, escribe
yy presionaIntro.
Este proceso puede demorar alrededor de 2 minutos. Puedes leer la siguiente sección mientras esperas.
Análisis de costos
Ahora estás ejecutando la misma carga de trabajo que requería tres máquinas e2-medium en una máquina e2-standard-2.
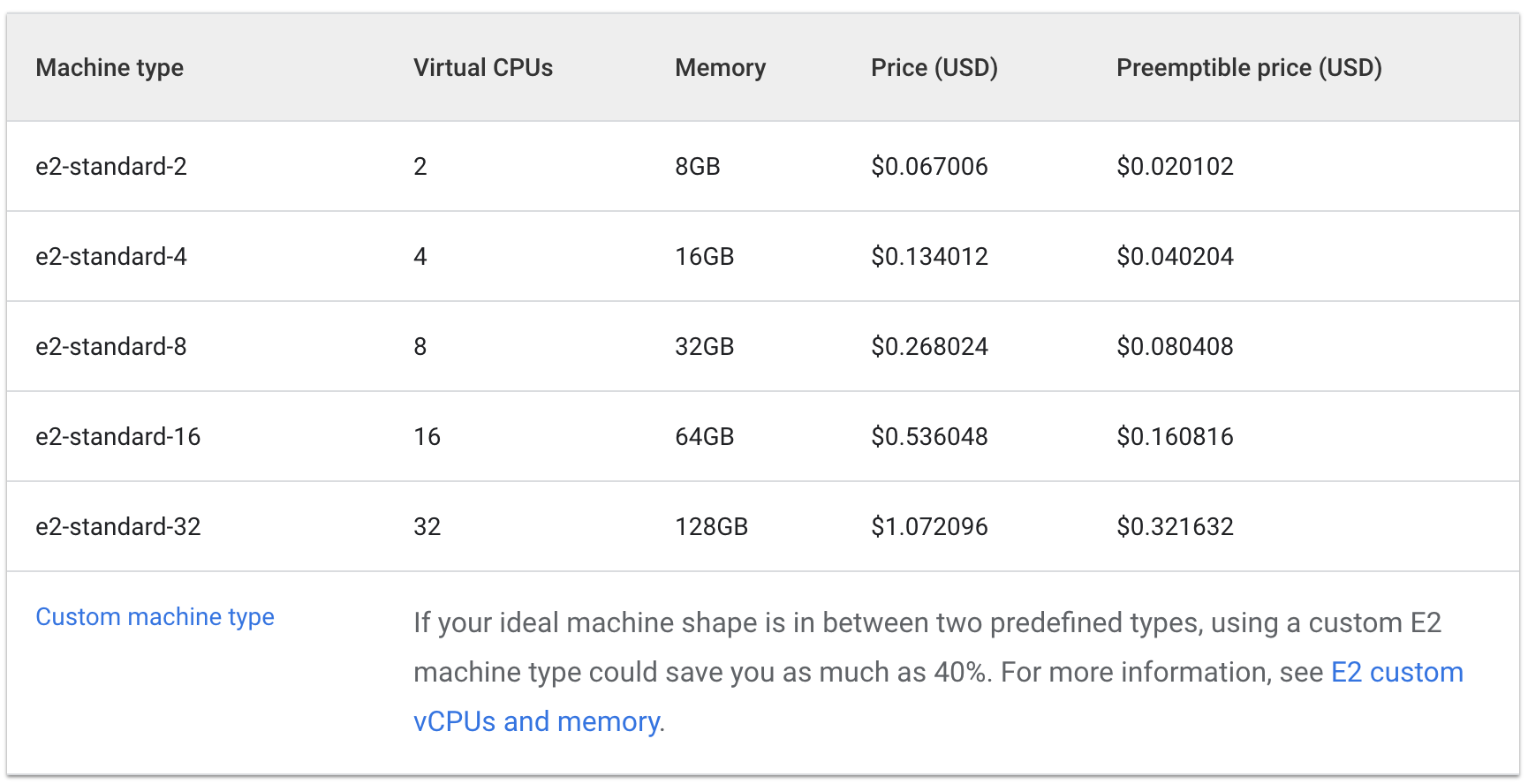
Observa el costo por hora cuando tiene una e2-estándar y tipos de máquina de núcleo compartido en funcionamiento:
Estándar:
Con núcleo compartido:
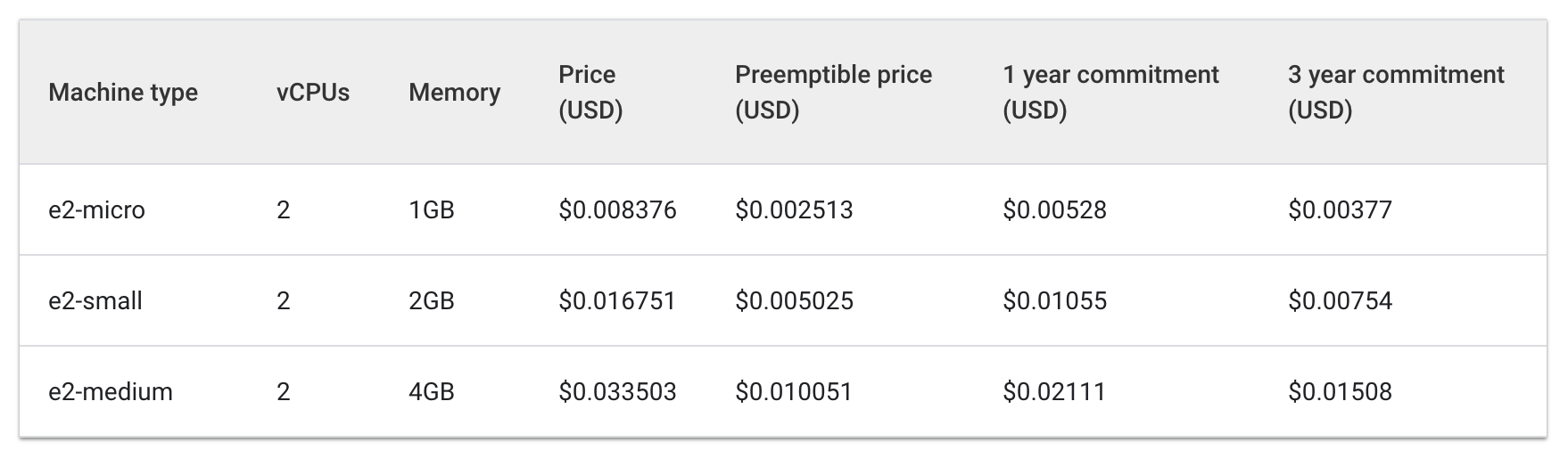
El costo de tres máquinas e2-medium sería de alrededor de $0.1 por hora, mientras que una e2-standard-2 costaría alrededor de $0.067 por hora.
Un ahorro de $0.04 por hora puede parecer insignificante, pero este costo se acumula durante el ciclo de vida de una aplicación en ejecución. De hecho, sería aún más visible a mayor escala. Dado que la máquina e2-standard-2 puede empaquetar tu carga de trabajo de forma más eficiente y hay menos espacio sin utilizar, el costo por escalar verticalmente se acumularía más despacio.
Un aspecto interesante es que e2-medium es un tipo de máquina de núcleo compartido que está diseñado para ser rentable con aplicaciones pequeñas y que usan pocos recursos. Sin embargo, para la carga de trabajo actual de Hello-App, verás que usar un grupo de nodos con un tipo de máquina más grande da como resultado una estrategia más rentable.
En la consola de Cloud, debes permanecer en la pestaña Nodos de tu clúster de hello-demo. Actualiza esta pestaña y examina los campos de CPU solicitada y CPU asignable para tu nodo de larger-pool.
Verás que es posible optimizarlo más. El nuevo nodo puede admitir otra réplica de tu carga de trabajo sin necesidad de aprovisionar otro nodo. Es más, podrías elegir un tipo de máquina de tamaño personalizado que se adapte a las necesidades de memoria y CPU de la aplicación, lo que ahorraría aún más recursos.
Debes tener en cuenta que estos precios tendrán variaciones dependiendo de la ubicación de tu clúster. La siguiente parte de este lab se trata de cómo seleccionar la mejor región y administrar un clúster regional.
Selecciona la ubicación adecuada para un clúster
Descripción general de regiones y zonas
Los recursos de Compute Engine, que se usan para los nodos de tu clúster, están alojados en múltiples ubicaciones en todo el mundo. Estas ubicaciones se componen de regiones y zonas. Una región es una ubicación geográfica específica donde puedes alojar recursos. Las regiones tienen tres o más zonas.
Los recursos que se ubican en una zona, como las instancias de máquina virtual o los discos persistentes zonales, se denominan recursos zonales. Otros recursos, como las direcciones IP externas estáticas, son regionales. Cualquier recurso de esa región puede usar los recursos regionales, sin importar la zona, mientras que, en el caso de los recursos zonales, solo los pueden usar otros recursos en la misma zona.
Cuando elijas una región o zona, es importante que consideres los siguientes aspectos:
- Manejo de fallas: Si los recursos para tu app solo están distribuidos en una zona que ya no está disponible, lo mismo sucederá con tu app. Para apps de mayor escala y demanda, una práctica recomendada es distribuir los recursos en múltiples zonas o regiones para manejar fallas.
- Disminución de la latencia de red: Para disminuir la latencia de red, te recomendamos elegir una región o zona que esté cerca de tu punto de servicio. Por ejemplo, si la mayoría de tus clientes están en la Costa Este de EE.UU., es conveniente que elijas una región y zona principales que estén cerca de esa área.
Prácticas recomendadas para clústeres
Los costos varían entre regiones en función de varios factores. Por ejemplo, los recursos en la región us-west2 suelen ser más caros que los de la región us-central1.
Cuando selecciones una región o zona para tu clúster, examina lo que hace tu aplicación. En un entorno de producción sensible a la latencia, es probable que colocar tu aplicación en una zona o región con menor latencia de red y mayor eficiencia te brinde la mejor proporción entre costo y rendimiento.
Sin embargo, puedes colocar un entorno de desarrollo que no es sensible a la latencia en una región más económica para reducir los costos.
Manejo de la disponibilidad de clústeres
Los tipos de clústeres disponibles en GKE son zonales (de una zona o de varias zonas) y regionales. En el sentido literal, un clúster de una sola zona será la opción menos costosa. Sin embargo, para la alta disponibilidad de tus aplicaciones, es mejor distribuir los recursos de infraestructura de tu clúster entre zonas.
En muchos casos, priorizar la disponibilidad a través de un clúster de varias zonas o regiones da como resultado la mejor arquitectura en cuanto a costo y rendimiento.
Tarea 3: Administra un clúster regional
Configuración
Administrar los recursos del clúster en múltiples zonas se vuelve un poco más complejo. Si no tienes cuidado, es posible que se acumulen costos adicionales por la comunicación interzonal innecesaria entre tus Pods.
En esta sección, observarás el tráfico de red de tu clúster y trasladarás dos Pods con alto tráfico entre ellos para que se encuentren en la misma zona.
- En la pestaña de Cloud Shell, crea un nuevo clúster regional (este comando tardará algunos minutos en completarse):
Para demostrar el tráfico entre los Pods y los nodos, crearás dos Pods en nodos independientes en tu clúster regional. Usaremos ping para generar tráfico de un Pod al otro, que luego podremos supervisar.
- Ejecuta este comando para crear un manifiesto en tu primer Pod:
- Crea el primer Pod en Kubernetes con el siguiente comando:
- Luego, ejecuta este comando para crear un manifiesto para tu segundo Pod:
- Crea el segundo Pod en Kubernetes:
Haz clic en Revisar mi progreso para verificar la realización de la tarea indicada arriba.
Los Pods que creaste usan el contenedor node-hello y dan como resultado el mensaje Hello Kubernetes cuando se solicita.
Si analizas el archivo pod-2.yaml que creaste, puedes observar que la Antiafinidad de Pods es una regla definida. Esto te permite garantizar que el Pod no está programado en el mismo nodo que pod-1. Para hacer esto, haz coincidir una expresión basada en la etiqueta security: demo de pod-1. Afinidad de Pods se usa para asegurar que los Pods están programados en el mismo nodo, mientras que Antiafinidad de Pods se usa para garantizar que no se programen los Pods en el mismo nodo.
En este caso, Antiafinidad de Pods se usa para ilustrar el tráfico entre nodos, pero el uso correcto de Antiafinidad de Pods y Afinidad de Pods puede ayudarte a utilizar aún mejor los recursos del clúster regional.
- Visualiza los Pods que creaste:
Verás que ambos Pods devuelven el estado En ejecución y tienen direcciones IP internas.
Sample output:
Toma nota de la dirección IP del pod-2. Utilizarás esa IP en el siguiente comando.
Simula tráfico
- Obtén una shell para tu contenedor
pod-1:
- En tu shell, envía una solicitud a
pod-2; reemplaza [POD-2-IP] con la dirección IP interna que se muestra parapod-2:
Ten en cuenta la latencia promedio que se necesita para hacer ping al pod-2 desde el pod-1.
Examina los registros de flujo
Después de que pod-1 haga ping con pod-2, puedes habilitar registros de flujo en la subred de la VPC en la que se creó el clúster para observar el tráfico.
- En la consola de Cloud, abre el Menú de navegación y selecciona Red de VPC en la sección Herramientas de redes.
- Localiza la subred
predeterminadaen la regióny haz clic en ella.
-
Haz clic en Editar en la parte superior de la pantalla.
-
Activa los Registros de flujo.
-
Luego, haz clic en Guardar.
-
A continuación, haz clic en Ver registros de flujo.
Ahora verás una lista de registros que muestran una gran cantidad de información en cualquier momento que algo se envió o recibió desde una de tus instancias.
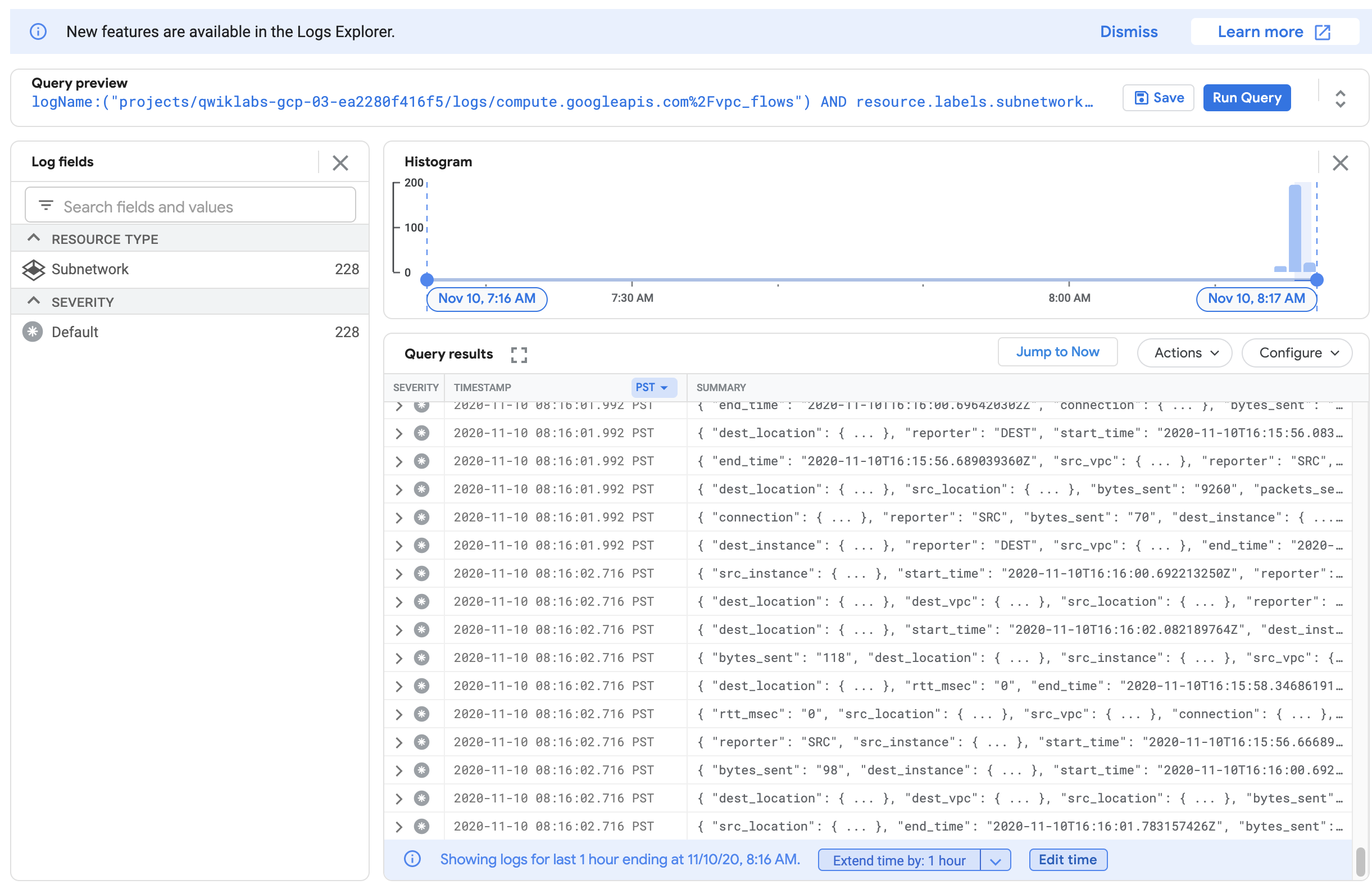
Si los registros no se generaron, reemplaza / antes de vpc_flows con %2F como se muestra en la captura de pantalla anterior.
Esto puede ser un poco difícil de leer. Luego, exporta los registros a una tabla de BigQuery para que puedas consultar la información pertinente.
- Haz clic en Más acciones > Crear un receptor.
-
Asigna el nombre
FlowLogsSamplea tu receptor. -
Haz clic en Siguiente.
Destino del receptor
- En Seleccionar el servicio del receptor, selecciona Conjunto de datos de BigQuery.
- Para tu Conjunto de datos de BigQuery, selecciona Crear nuevo conjunto de datos de BigQuery.
- Nombra tu conjuntos de datos como 'us_flow_logs', y haz clic en CREAR CONJUNTO DE DATOS.
Todo lo demás puede permanecer sin modificaciones.
-
Haz clic en Crear un receptor.
-
Ahora, inspecciona el conjunto de datos que acabas de crear. En la consola de Cloud, en el Menú de navegación en la sección Analytics, haz clic en BigQuery.
-
Haz clic en Listo.
-
Selecciona el nombre de tu proyecto y, luego, selecciona us_flow_logs para ver la tabla que acabas de crear. Si no aparece una tabla, es posible que debas actualizar la sección hasta que se cree.
-
Haz clic en la tabla
compute_googleapis_com_vpc_flows_xxxen el conjunto de datoss_flow_logs.
-
Haz clic en Consultar > En una pestaña nueva.
-
En el Editor de BigQuery, pega lo siguiente entre
SELECCIONARyDESDE:
- Haz clic en Ejecutar.
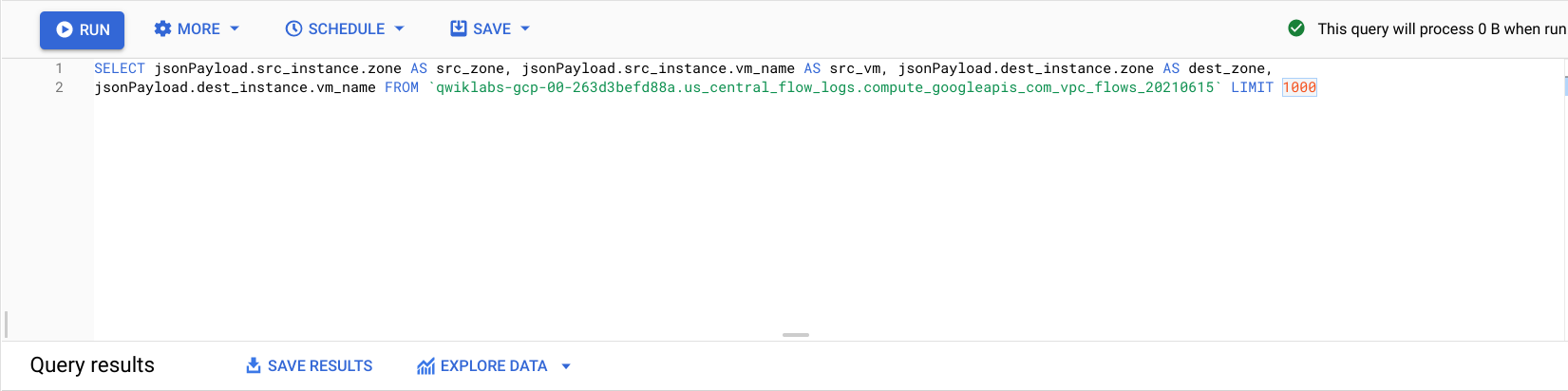
Verás los registros de flujo de antes, pero filtrados por zona de origen, vm de origen, zona de destino y vm de destino.
Ubica algunas filas en las que se realizan llamadas entre dos zonas diferentes en tu clúster regional-demo.

Si observas los registros de flujo, verás que hay tráfico frecuente entre distintas zonas.
Luego, moverás los Pods a la misma zona y observarás los beneficios.
Traslada un Pod con alto tráfico para minimizar los costos de tráfico entre zonas
-
En Cloud Shell, presiona Ctrl + C para cancelar el comando
ping. -
Escribe el comando
salirpara salir del shell delpod-1:
- Ejecuta este comando para editar el manifiesto del
pod-2:
Esto cambia tu regla de Antiafinidad de Pods a Afinidad de Pods mientras sigue utilizando la misma lógica. Ahora pod-2 se programará en el mismo nodo que pod-1.
- Borra el
pod-2en ejecución:
- Cuando borres el
pod-2, puedes volver a crearlo con el manifiesto que acabas de editar:
Haz clic en Revisar mi progreso para verificar la realización de la tarea indicada arriba.
- Visualiza los Pods que creaste y asegúrate de que tengan el estado
En ejecución:
En el resultado, puedes ver que pod-1 y pod-2 ahora se están ejecutando en el mismo nodo.
Toma nota de la dirección IP del pod-2. Utilizarás esa IP en el siguiente comando.
- Obtén una shell para tu contenedor
pod-1:
- En tu shell, envía una solicitud a
pod-2; reemplaza [POD-2-IP] con la dirección IP interna que se muestra parapod-2del comando anterior:
Notarás que el tiempo de ping promedio entre estos Pods ahora es más rápido.
En este punto, puedes volver a tu conjunto de datos de BigQuery de registros de flujo y comprobar los registros recientes para verificar que no haya más comunicaciones interzonales no deseadas.
Análisis de costos
Observa los Precios de salida de VM a VM dentro de Google Cloud:
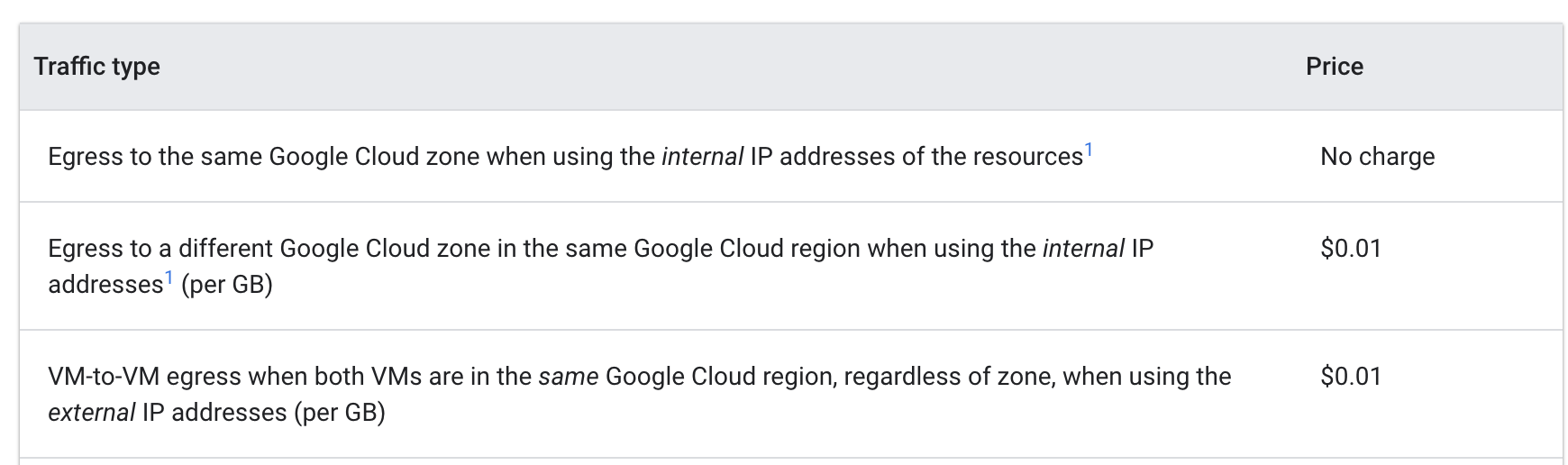
Cuando los Pods se hacían ping entre ellos desde diferentes zonas, el costo era de $0.01 por GB. Aunque parezca una cifra pequeña, se puede acumular muy rápido en un clúster de mayor escala con múltiples servicios que hacen llamadas frecuentes entre zonas.
Cuando trasladaste los Pods a la misma zona, el ping dejó de tener costo.
¡Felicitaciones!
Exploraste la optimización de costos para máquinas virtuales que son parte de un clúster de GKE. Primero, migraste una carga de trabajo a un grupo de nodos con un tipo de máquina más adecuado. Luego de comprender las ventajas y desventajas de las diferentes regiones, trasladaste un Pod con alto tráfico dentro de un clúster regional para que siempre se encuentre en la misma zona que el Pod con el que se estaba comunicando.
Este lab te presentó herramientas y estrategias rentables para las VMs de GKE; si deseas optimizar tus máquinas virtuales, primero debes comprender tu aplicación y sus necesidades. Conocer los tipos de cargas de trabajo que ejecutarás y estimar las demandas de tu aplicación casi siempre afectará la elección del tipo de máquina y la ubicación que serán más eficaces para las máquinas virtuales en tu clúster de GKE.
La utilización eficiente de la infraestructura de tu clúster será muy útil para optimizar tus costos.
Finaliza tu Quest
Este lab de autoaprendizaje forma parte de la Quest Optimize Costs for Google Kubernetes Engine. Una Quest es una serie de labs relacionados que forman una ruta de aprendizaje. Si completas esta Quest, obtendrás una insignia como reconocimiento por tu logro. Puedes hacer públicas tus insignias y agregar vínculos a ellas en tu currículum en línea o en tus cuentas de redes sociales.
Inscríbete en esta Quest y obtén un crédito inmediato de realización.
Consulta el catálogo de Google Cloud Skills Boost para ver todas las Quests disponibles.
Realiza tu próximo lab
Continúa tu Quest con Optimiza los costos de Google Kubernetes Engine o consulta estas sugerencias:
- Administra un clúster de múltiples usuarios de GKE con espacios de nombres
- Optimiza cargas de trabajo de GKE
Próximos pasos y más información
- Documentos de tipos de máquina
- Prácticas recomendadas para ejecutar aplicaciones de Kubernetes con optimización de costos en GKE: Elige el tipo de máquina correcto
- Prácticas recomendadas para ejecutar aplicaciones de Kubernetes con optimización de costos en GKE: Selecciona la región adecuada
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Actualización más reciente del manual: 20 de septiembre de 2023
Prueba más reciente del lab: 20 de septiembre de 2023 ![[/fragments/copyright]]