



准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Deploy an application
/ 30
Create a logs-based metric
/ 30
Create an alerting policy
/ 40
Cloud Logging 及其配套工具 Cloud Monitoring 都是功能齐全的产品,并且都与 Google Kubernetes Engine 深度集成。本实验将通过常见的日志记录应用场景,教您了解 Cloud Logging 如何与 GKE 集群和应用配合使用,以及日志收集的一些最佳实践。
在本实验中,您将学习如何完成以下操作:
为了使用具体示例,您将对部署到 GKE 集群的示例微服务演示应用进行问题排查。在此演示应用中,有许多微服务,并且它们之间存在依赖关系。您将使用 loadgenerator 生成流量,然后使用 Logging、Monitoring 和 GKE 来发现错误(提醒/指标),使用 Logging 确定根本原因,最后使用 Logging 和 Monitoring 修复/确认问题已修复。
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。左侧是“实验详细信息”窗格,其中包含以下各项:
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:将这些标签页安排在不同的窗口中,并排显示。
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
您也可以在“实验详细信息”窗格中找到“用户名”。
点击下一步。
复制下面的密码,然后将其粘贴到欢迎对话框中。
您也可以在“实验详细信息”窗格中找到“密码”。
点击下一步。
继续在后续页面中点击以完成相应操作:
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
点击 Google Cloud 控制台顶部的激活 Cloud Shell 
在弹出的窗口中执行以下操作:
如果您连接成功,即表示您已通过身份验证,且项目 ID 会被设为您的 Project_ID
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
输出:
输出:
gcloud 的完整文档,请参阅 gcloud CLI 概览指南。
某些 Compute Engine 资源位于区域和可用区内。区域是指某个地理位置,您可以在其中运行自己的资源。每个区域包含一个或多个可用区。
在 Cloud 控制台中运行以下 gcloud 命令,设置实验的默认区域和可用区:
连接到一个 Google Kubernetes Engine 集群,并验证该集群已正确创建。
集群状态将显示为“正在预配”。
稍等片刻,再次运行上述命令,直到状态显示为“正在运行”。这可能需要几分钟时间。
验证名为 central 的集群已创建。
您还可以在 Cloud 控制台中监控进度,方法是依次前往导航菜单 > Kubernetes Engine > 集群。
输出:
输出的内容应如下所示:
接下来,将一个名为 Hipster Shop 的微服务应用部署到集群中,创建您可以监控的工作负载。
microservices-demo 目录:kubectl 安装应用:输出应类似以下内容:
点击“检查我的进度”,验证已完成以下目标:
确认信息将类似:
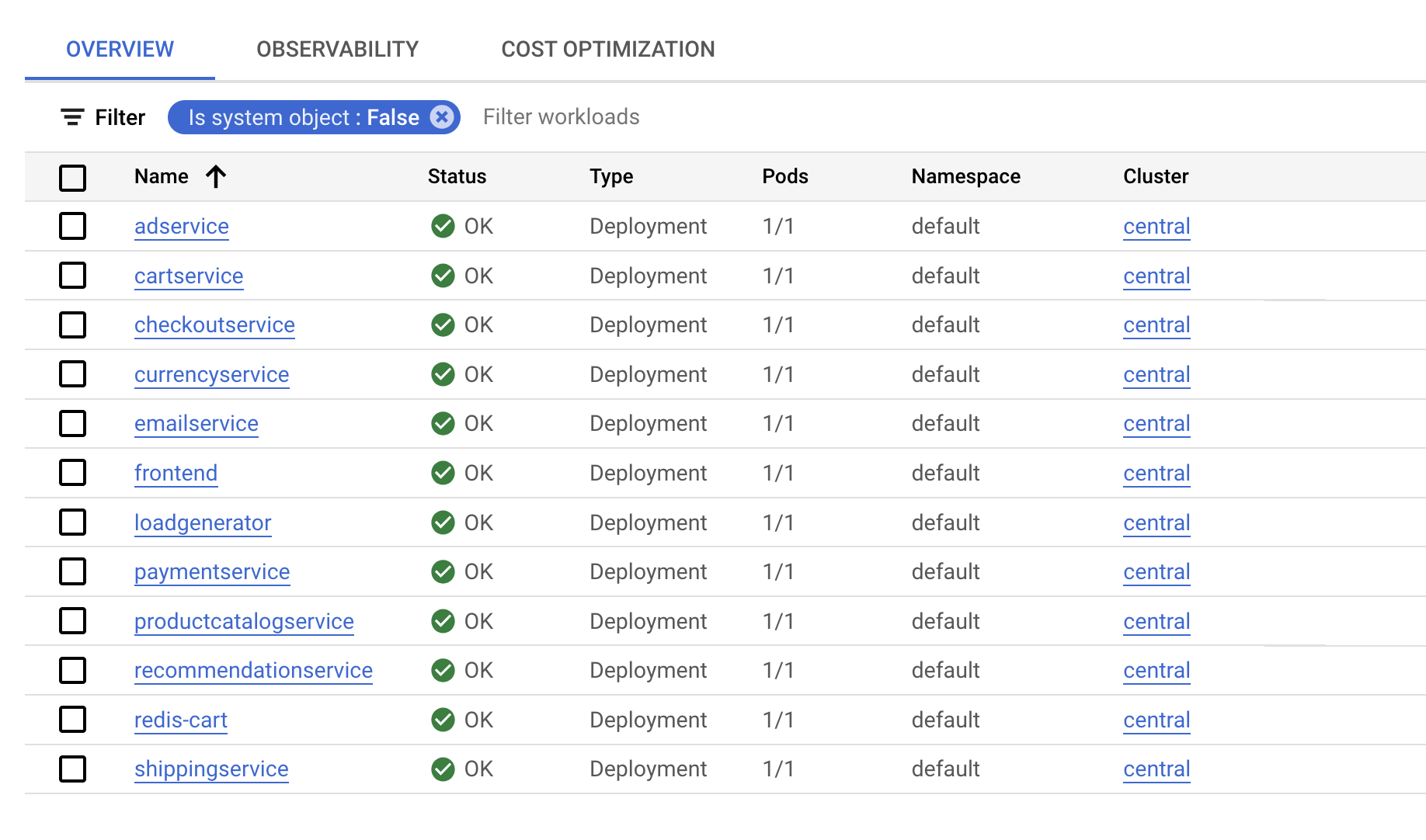
应用部署完成后,您还可以前往 Cloud 控制台查看状态。
在 Kubernetes Engine > 工作负载页面中,您会看到所有 Pod 均正常运行。
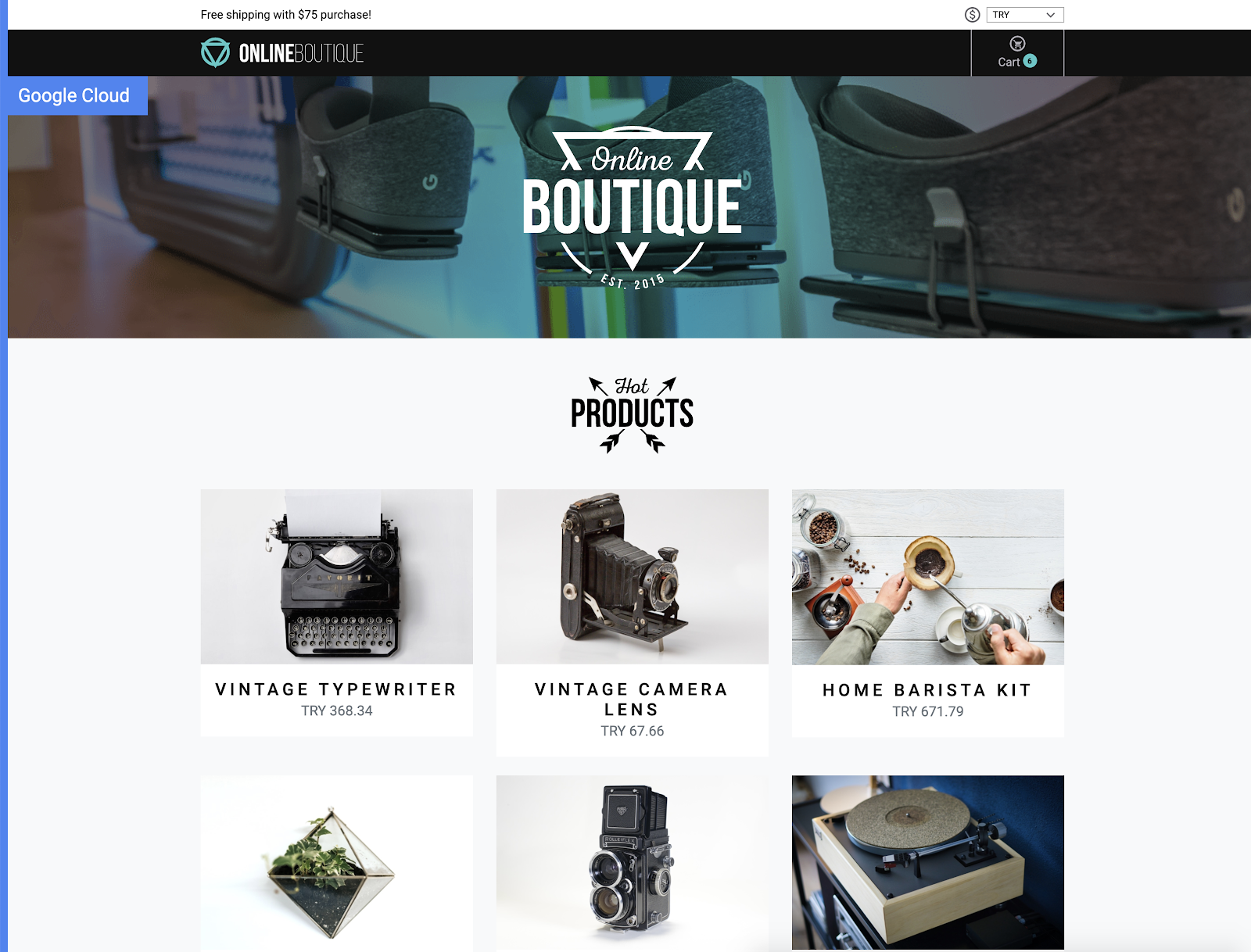
这应该会打开应用,您将看到如下所示的页面:
现在,您将配置 Cloud Logging 以创建基于日志的指标,这是 Cloud Monitoring 中根据日志条目创建的自定义指标。基于日志的指标非常适合统计日志条目的数量,以及跟踪日志中某个值的分布情况。在本例中,您将使用基于日志的指标来计算前端服务中的错误数。然后,您可以在信息中心和提醒中使用该指标。
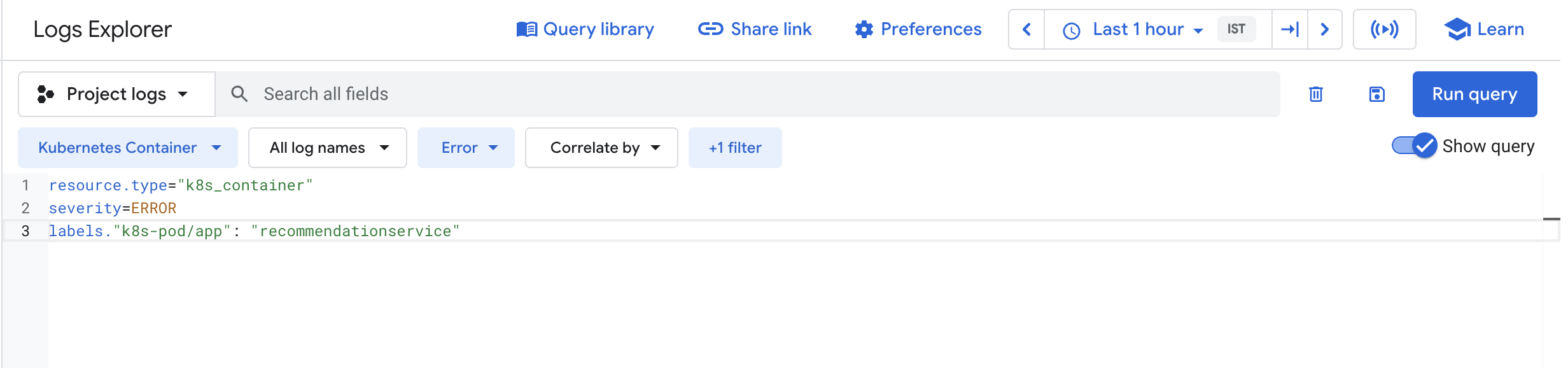
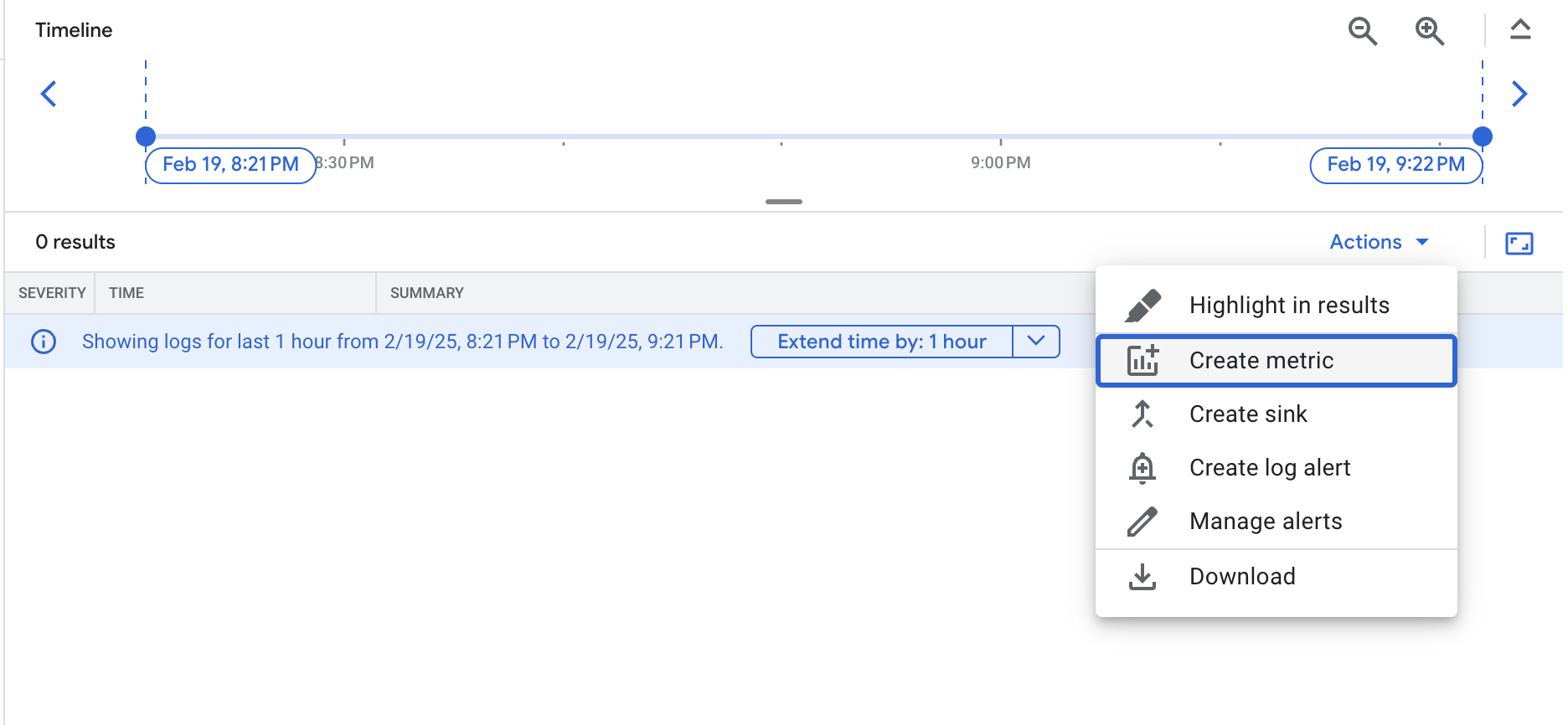
您使用的查询可让您找到前端 Pod 中的所有错误。不过,由于目前还没有错误,您现在应该看不到任何结果。
现在,您会看到该指标列在“基于日志的指标”页面上的“用户定义的指标”部分。
点击“检查我的进度”,验证已完成以下目标:
借助提醒,您可以及时得知云端应用中出现的问题,从而快速加以解决。现在,您将使用 Cloud Monitoring 来监控前端服务的可用性,方法是根据之前创建的基于日志的前端错误指标创建提醒政策。当满足提醒政策的条件时,Cloud Monitoring 会在 Cloud 控制台中创建并显示突发事件。
在导航菜单中,打开 Monitoring,然后点击提醒。
工作区创建完成后,点击顶部的创建政策。
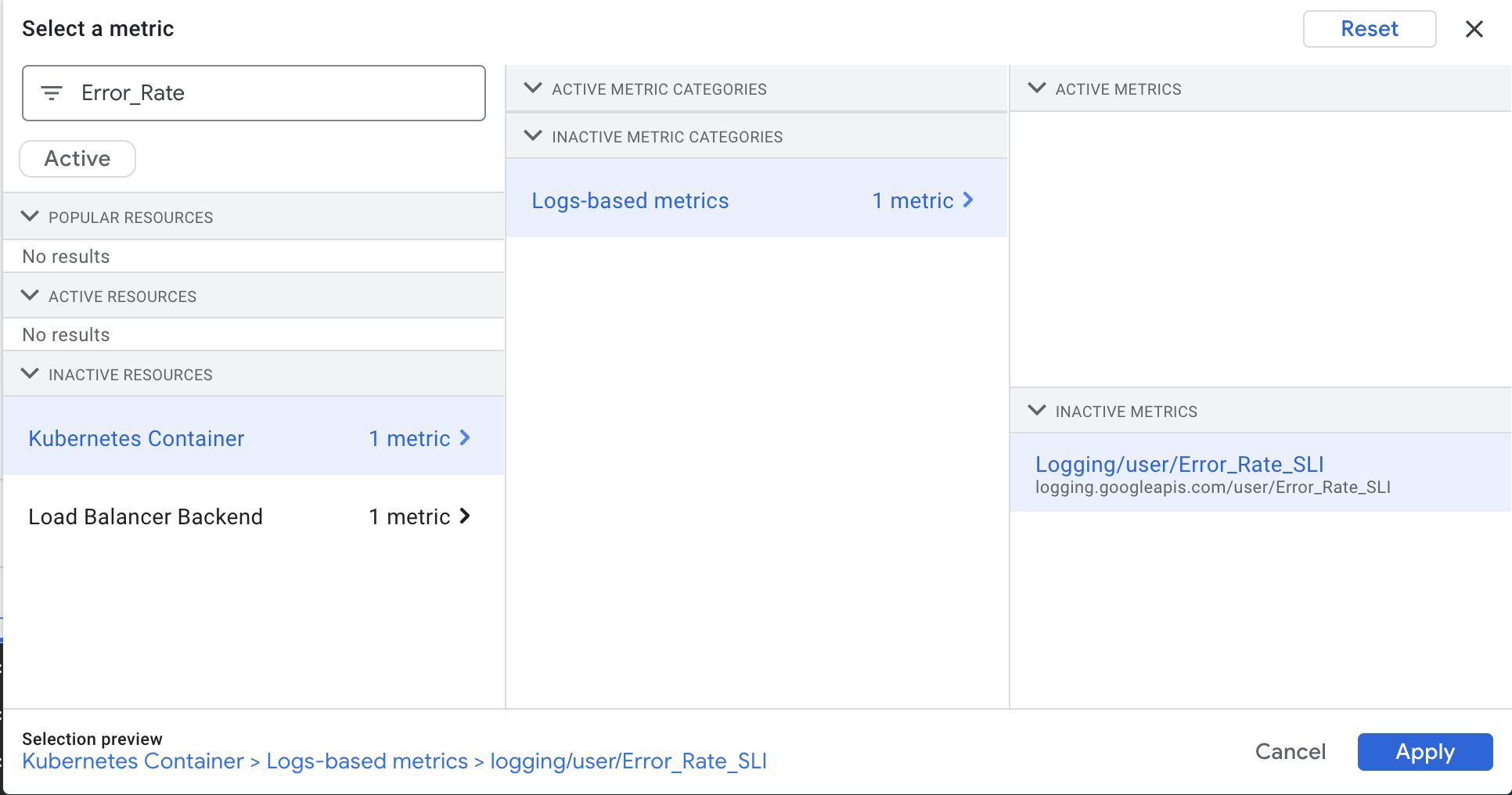
点击选择指标下拉菜单。取消选中活跃。
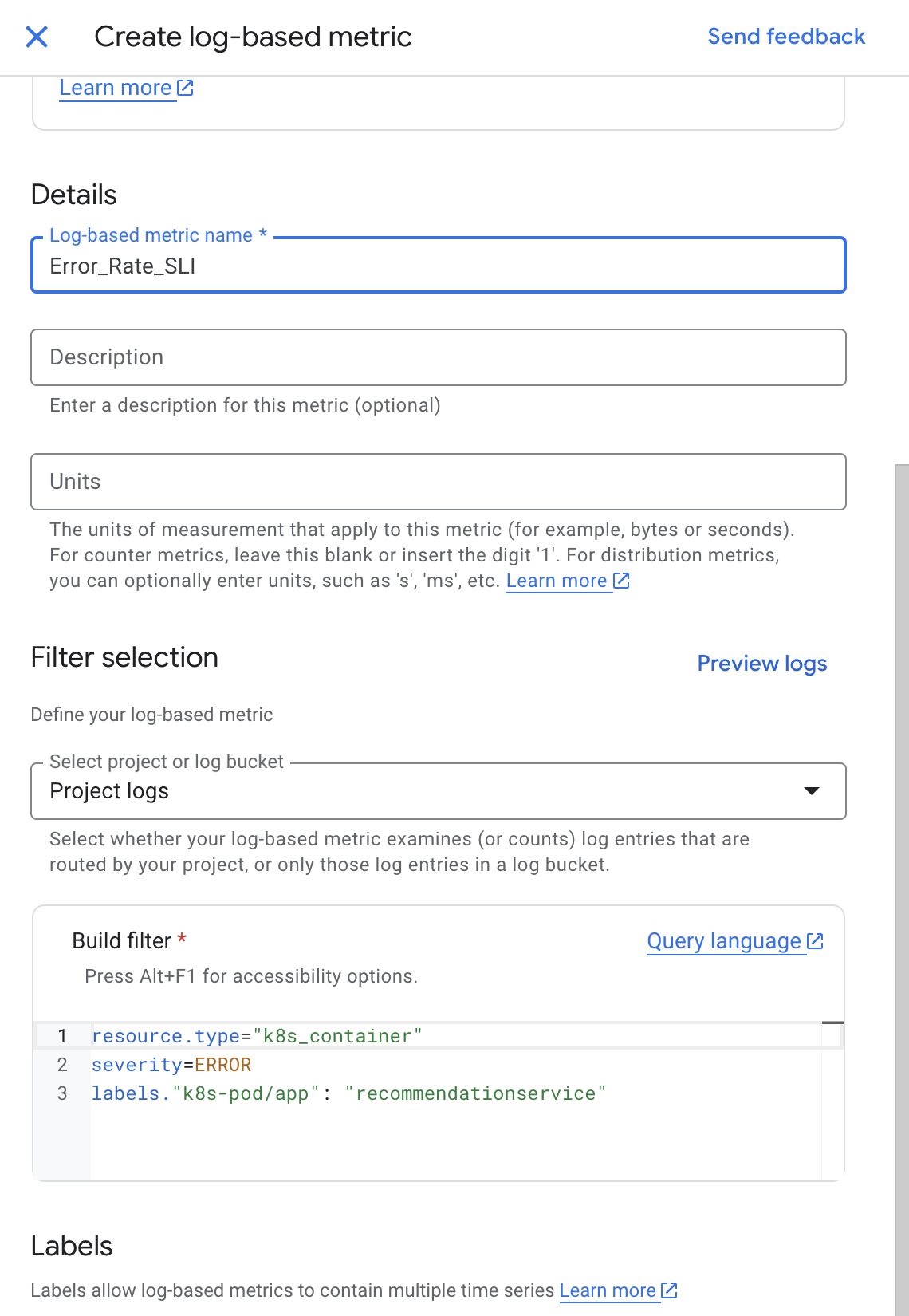
在按资源和指标名称过滤字段中,输入 Error_Rate。
点击 Kubernetes 容器 > 基于日志的指标。选择 logging/user/Error_Rate_SLI,然后点击应用。
您的屏幕应如下所示:
将滚动窗口函数设置为速率。
点击下一步。
将 0.5 设置为阈值。
正如预期的那样,没有出现故障,您的应用达到了可用性服务等级目标 (SLO)。
再次点击下一步。
停用使用通知渠道。
提供提醒名称,例如 Error Rate SLI,然后点击下一步。
审核该提醒并点击创建政策。
点击“检查我的进度”,验证已完成以下目标:
现在,您将使用负载生成器为 Web 应用创建一些流量。由于此版本的应用中故意引入了一个 bug,因此达到一定流量时会触发错误。您将按照步骤找出并修复该 bug。
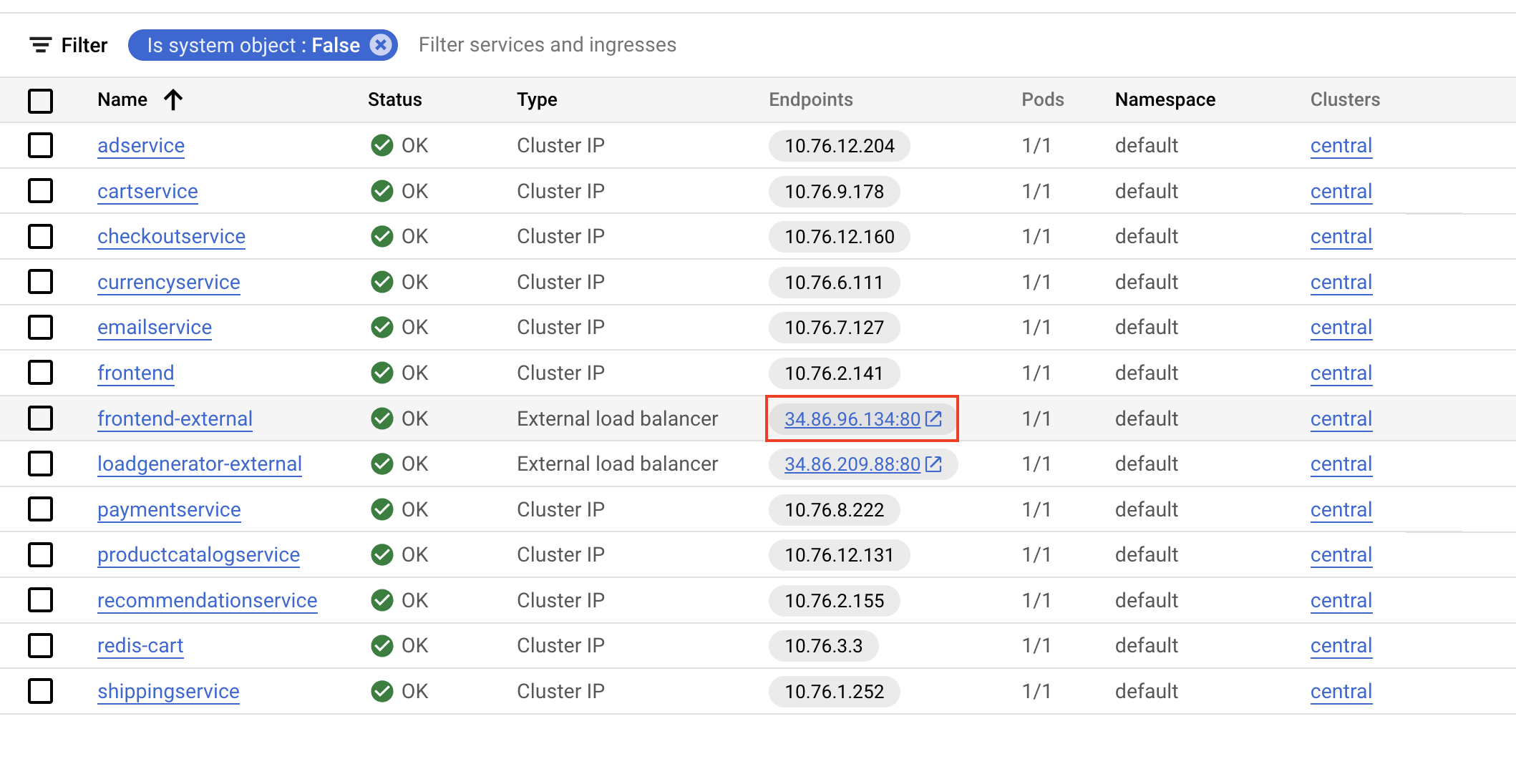
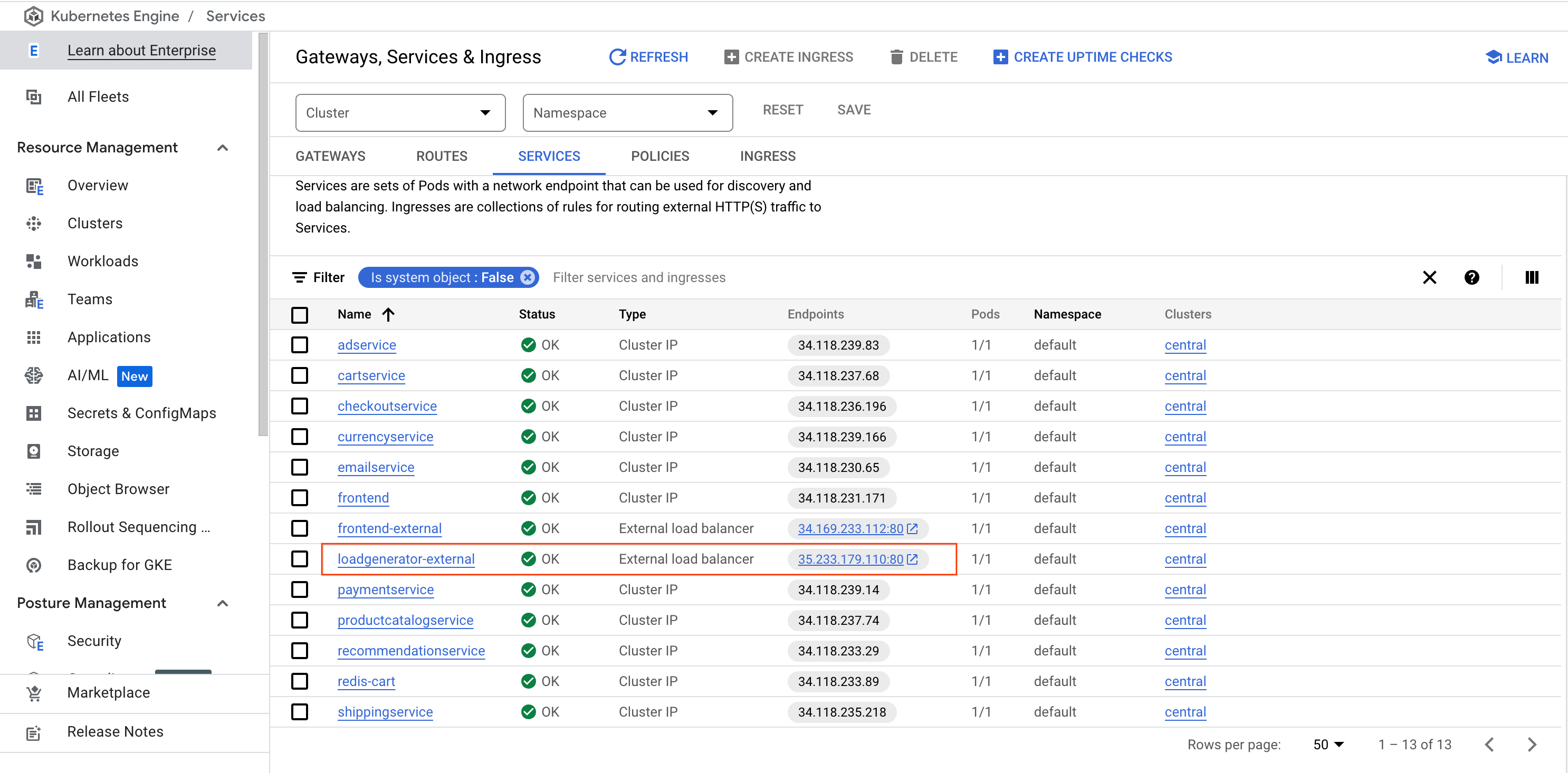
在导航菜单中,依次选择 Kubernetes Engine、网关、服务和入站流量,然后点击服务标签页。
找到 loadgenerator-external 服务,然后点击端点链接。
或者,您可以打开一个新的浏览器标签页或窗口,将 IP 复制/粘贴到网址字段中,例如:http://\[loadgenerator-external-ip\]
现在,您应该会看到 Locust 负载生成器页面:
Locust 是一款开源负载生成器,可用于对 Web 应用进行负载测试。它可以模拟一定数量的用户以特定速率同时访问某个应用端点。
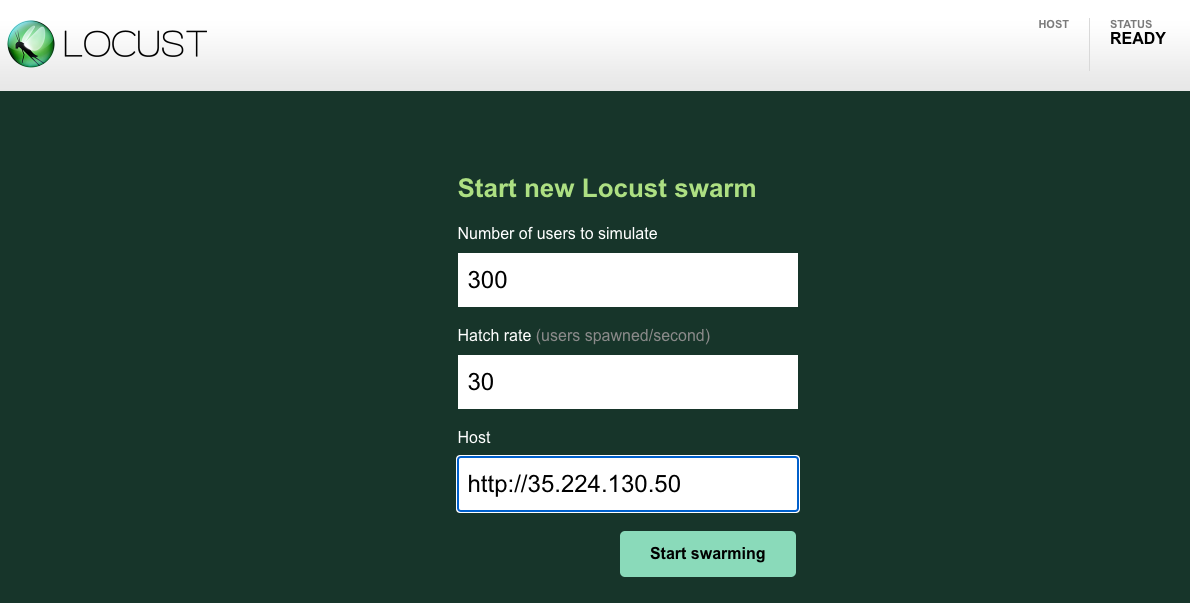
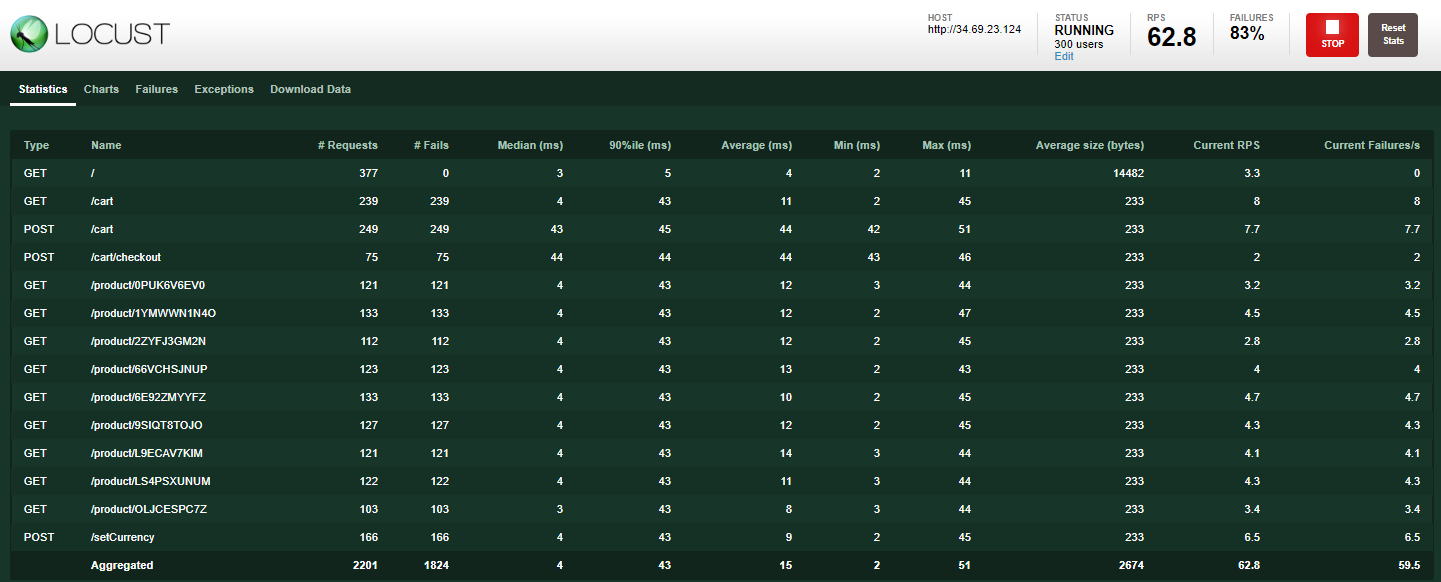
模拟 300 位用户以 30 的生成速率访问应用。Locust 将每秒添加 30 个用户,直到达到 300 个用户。
对于主机字段,您将使用 frontend-external。从“网关、服务和入站流量”页面复制网址,确保不包含端口。例如:
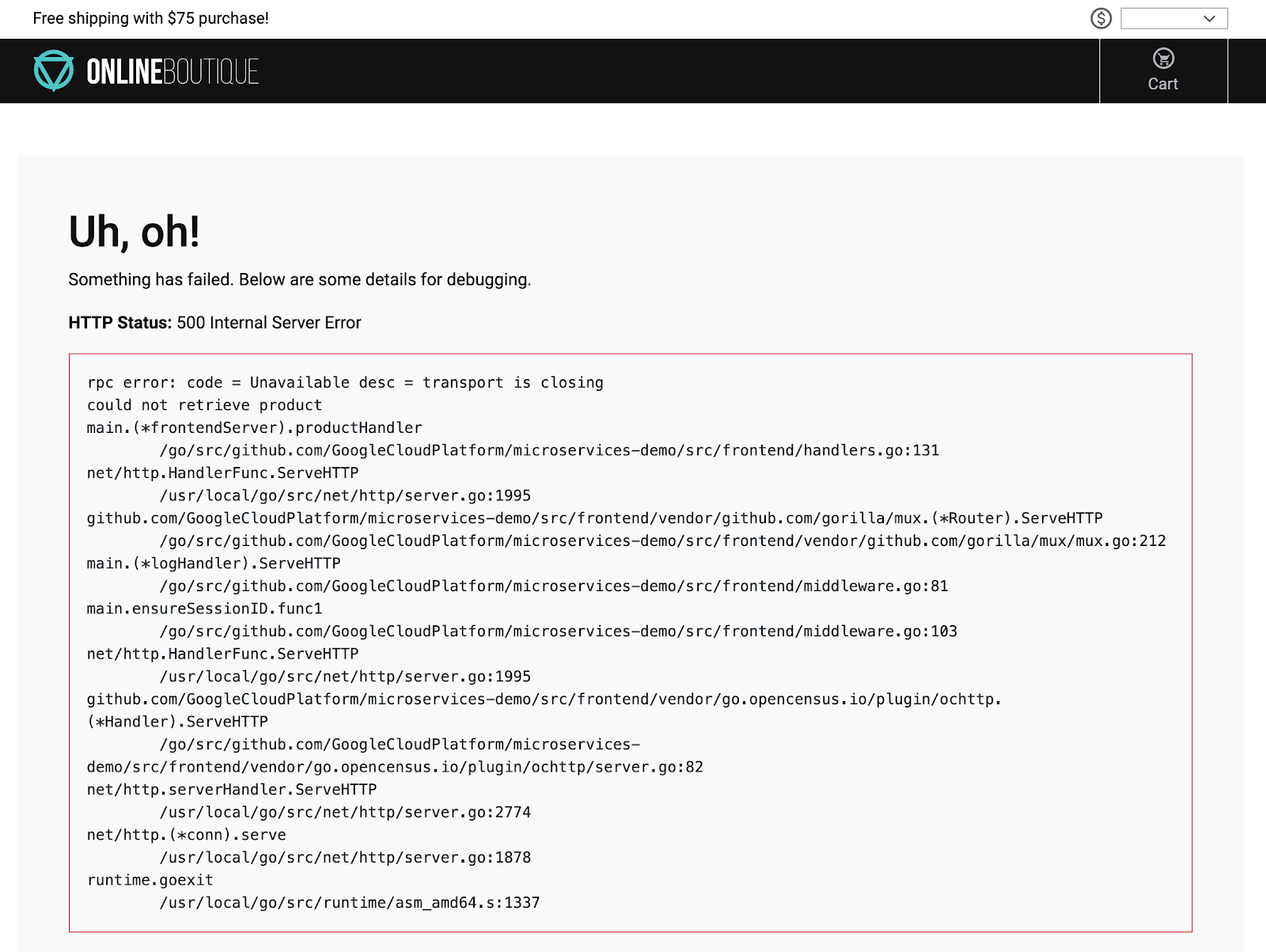
同时,如果您点击首页上的任何商品,要么速度明显很慢,要么会收到如下错误:
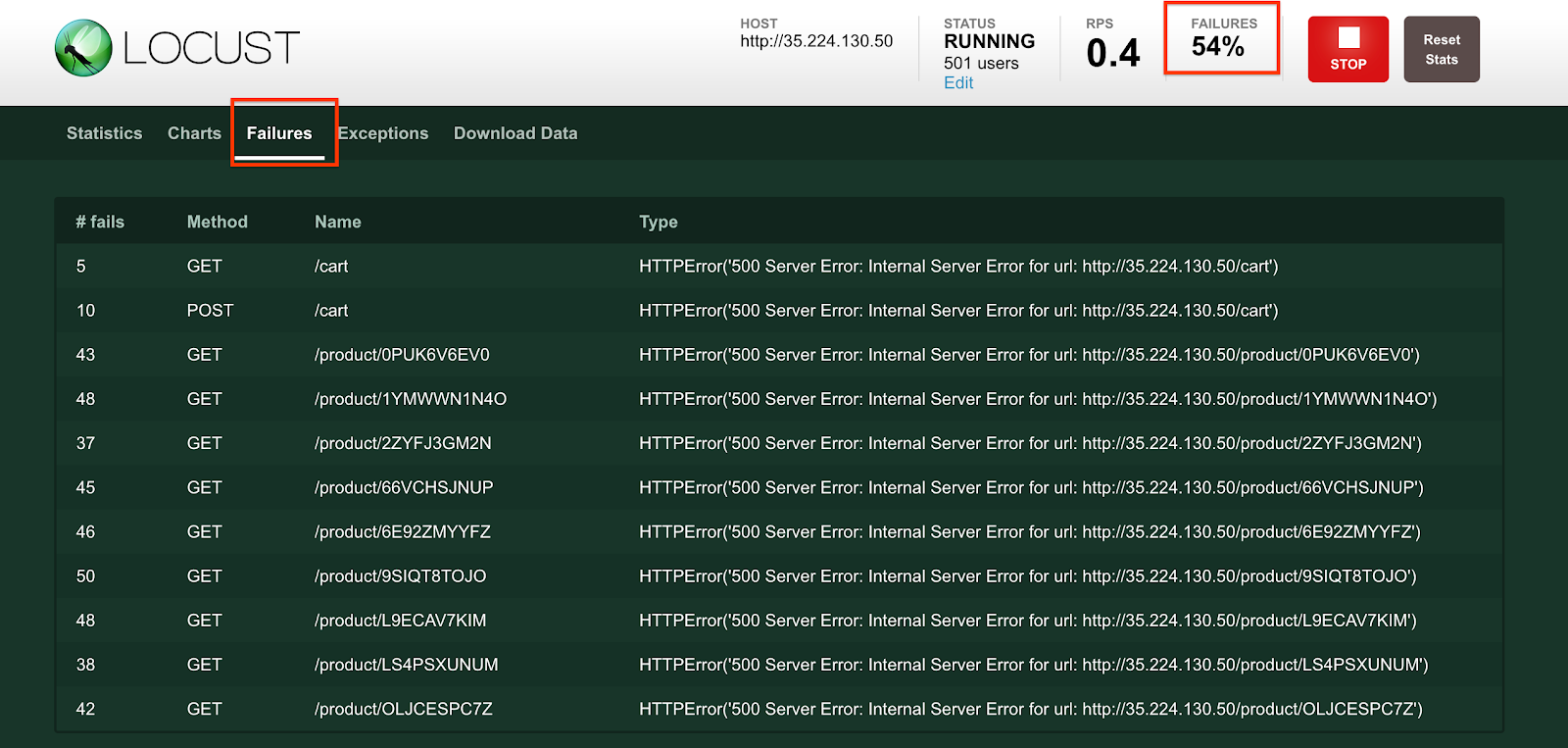
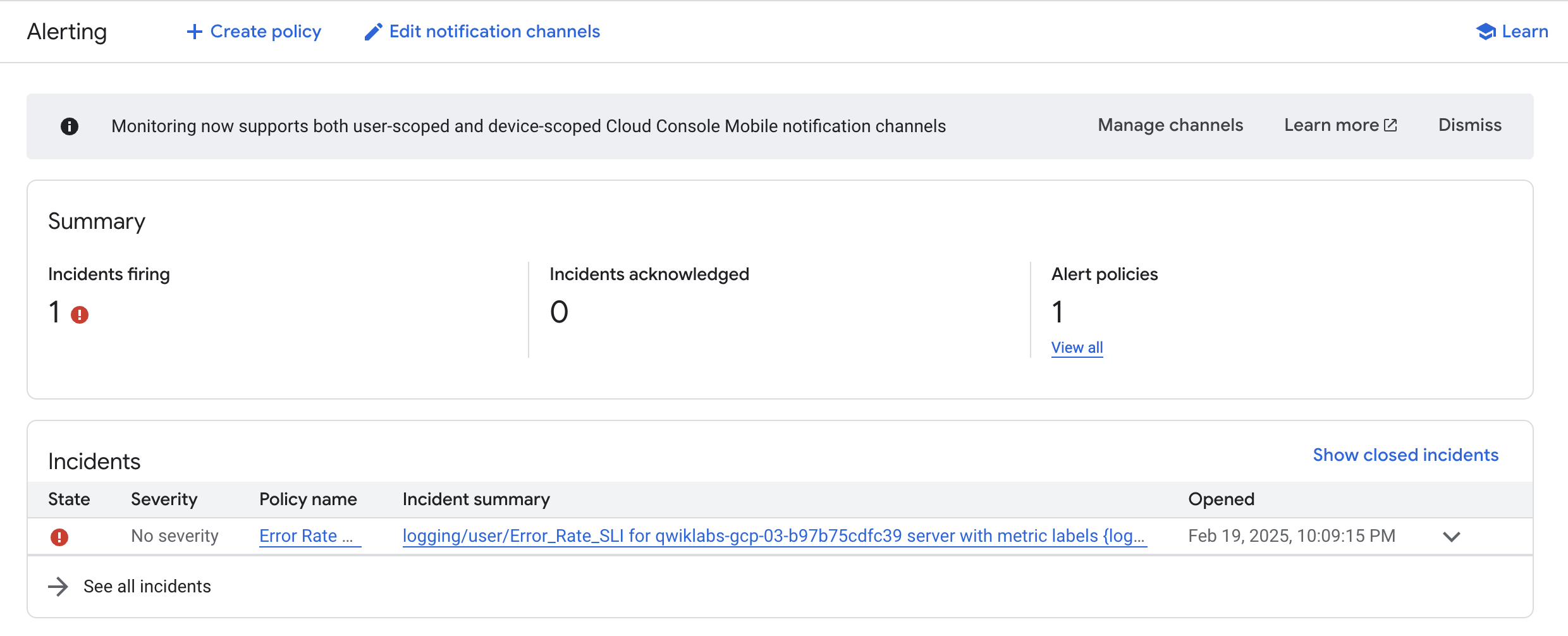
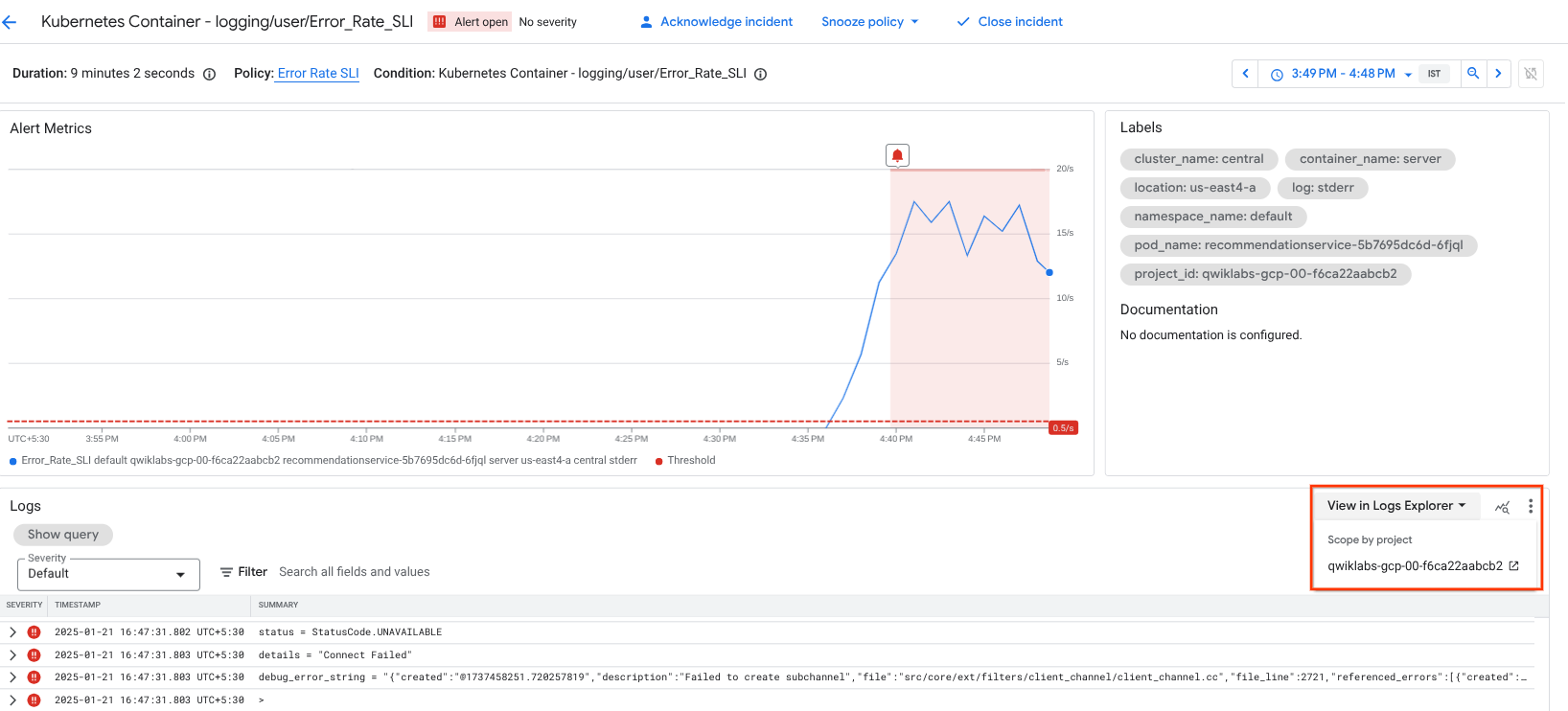
在控制台中,从导航菜单中依次点击 Monitoring 和提醒。您很快就会看到与 logging/user/Error_Rate_SLI 相关的突发事件。如果您没有立即看到突发事件,请等待一两分钟,然后刷新页面。提醒最多可能需要 5 分钟才会触发。
点击突发事件的链接:
您随即会进入详情页面。
或者,您可以点击“查询预览”字段以显示查询构建器,然后点击严重级别下拉菜单,将错误添加到查询中。点击添加按钮,然后点击运行查询。通过下拉菜单可以添加多个严重级别值。
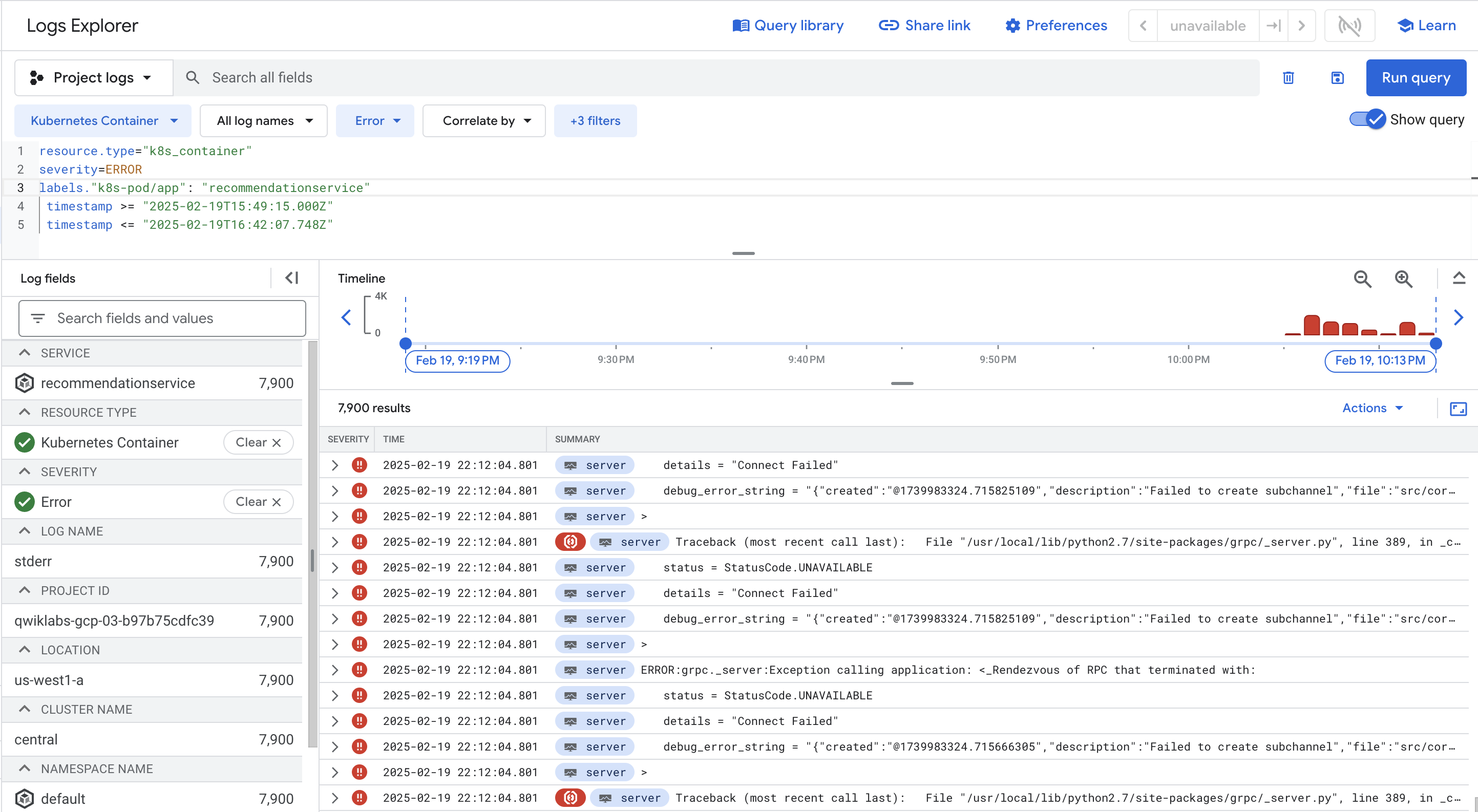
无论哪种方式,结果都是在查询中添加 severity=ERROR。完成此操作后,您应该会看到 recommendationservice Pod 的所有错误。
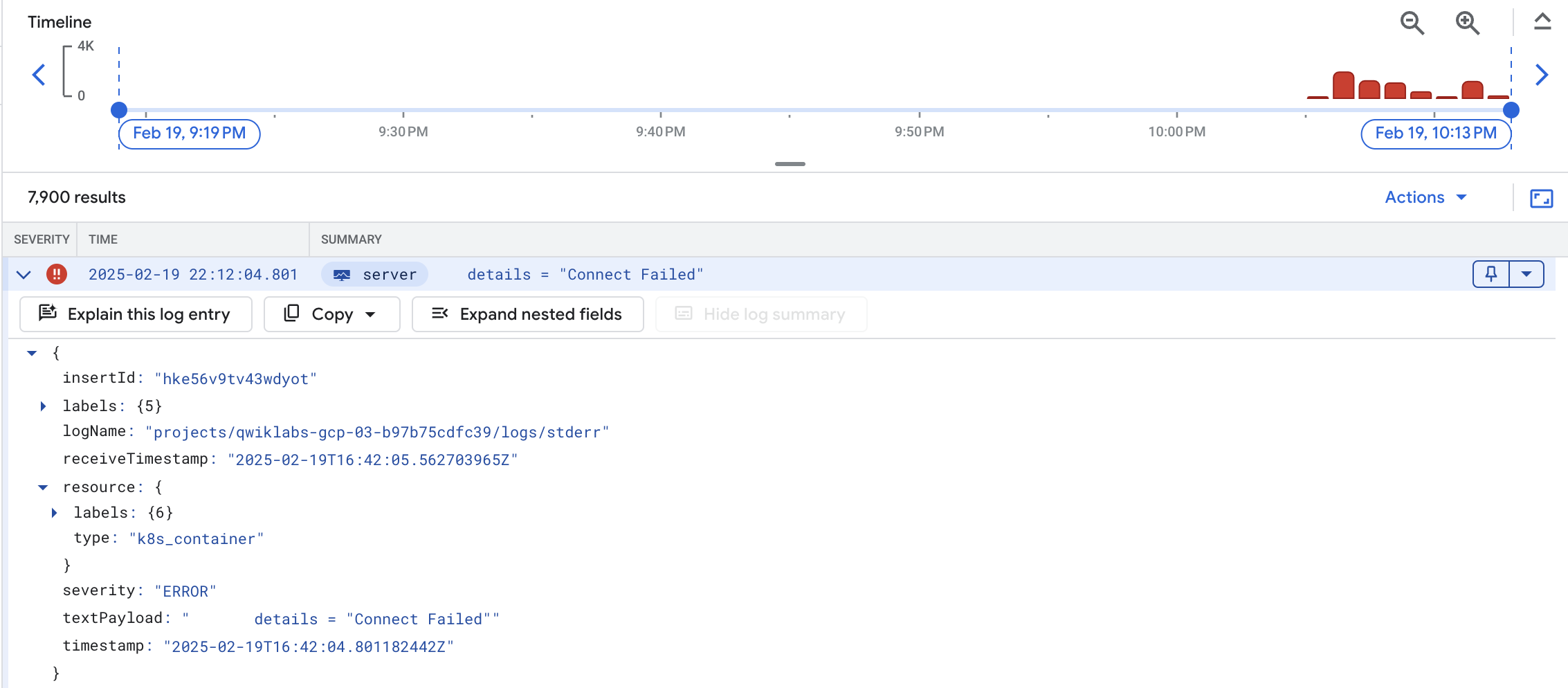
展开 textPayload。
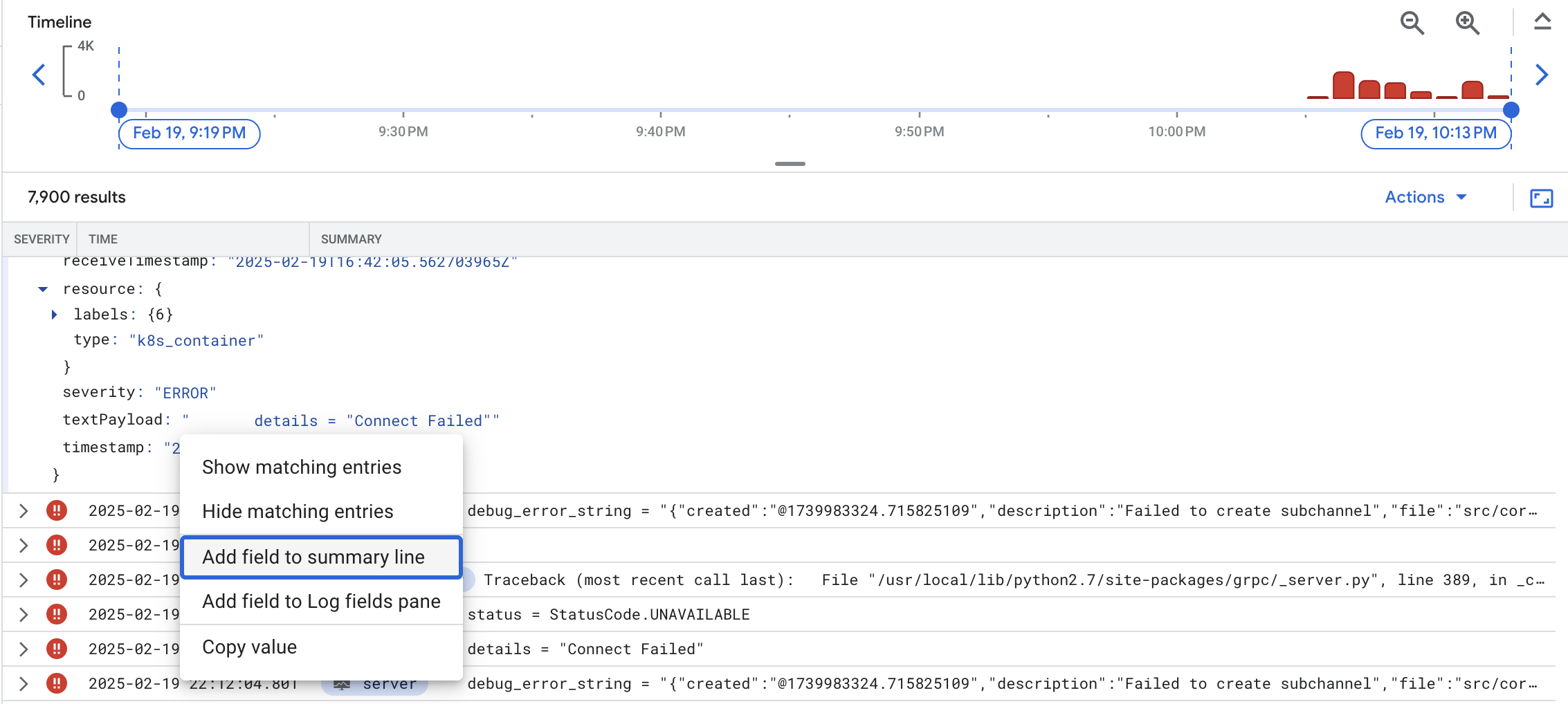
点击错误消息,然后选择向摘要行添加字段,将错误消息显示为摘要字段:
从那里,您可以确认 RecommendationService 服务确实存在许多错误。根据错误消息,RecommendationService 似乎无法连接到某些下游服务来获取商品或推荐。不过,我们仍然不清楚这些错误的根本原因。
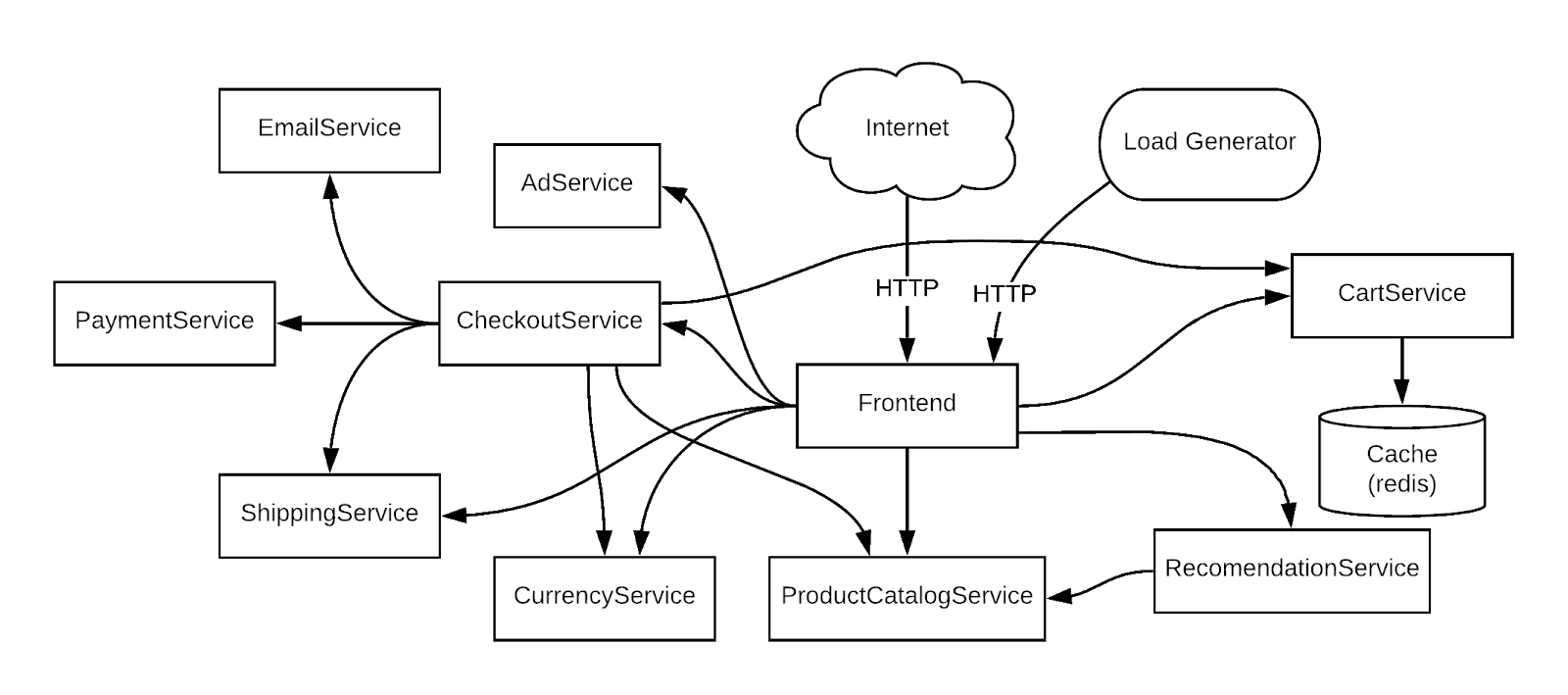
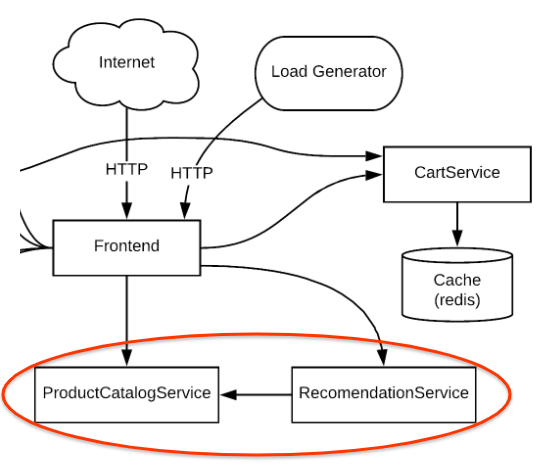
如果您重新查看架构图,会发现 RecommendationService 向 Frontend 服务提供建议列表。不过,Frontend 服务和 RecommendationService 都会调用 ProductCatalogService 来获取产品列表。
接下来,您将查看主要嫌疑对象 ProductCatalogService 的指标,以查找任何异常情况。无论如何,您都可以在日志中深入挖掘,以获得一些分析洞见。
首先,您可以在 Monitoring 控制台的 Kubernetes Engine 部分查看指标(导航菜单 > 监控> 信息中心 > GKE)。
查看工作负载部分。
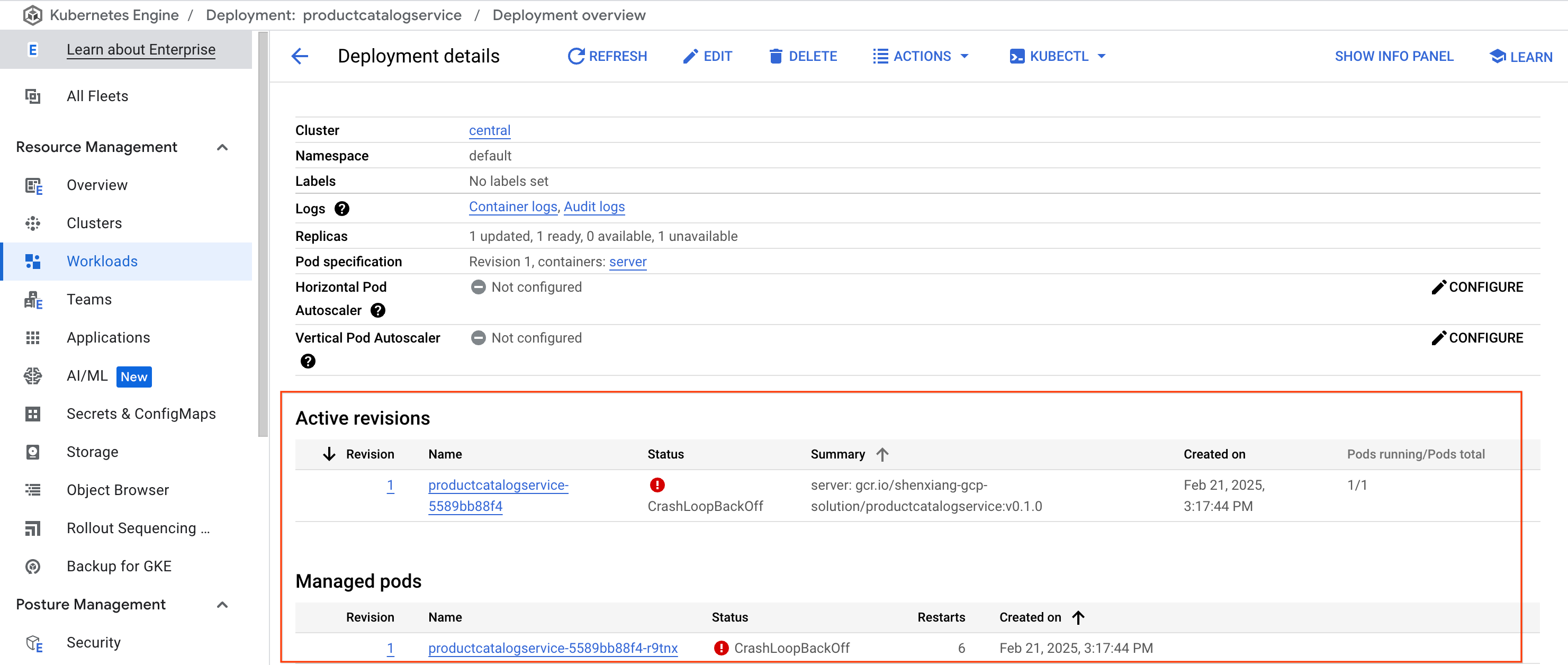
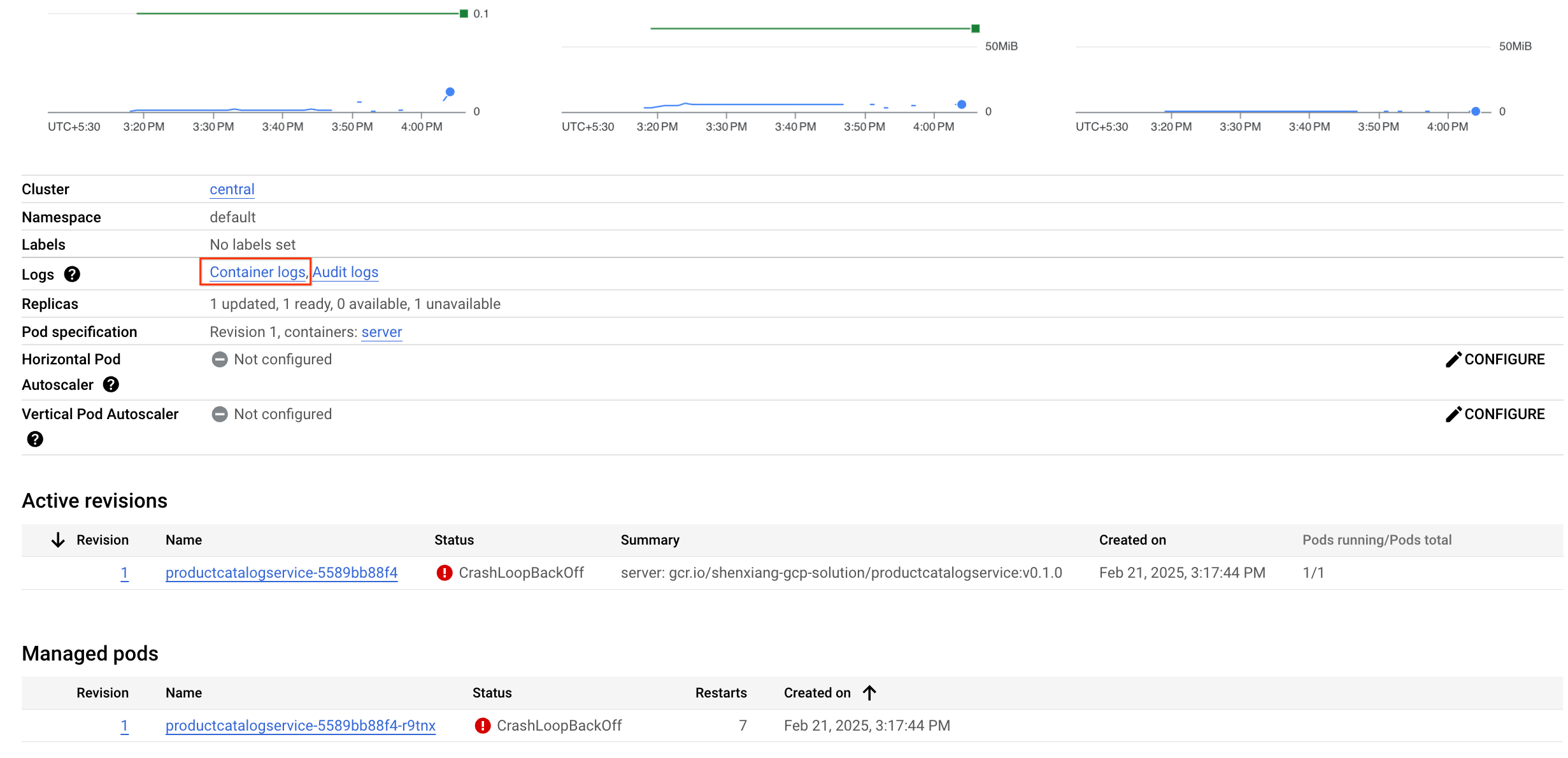
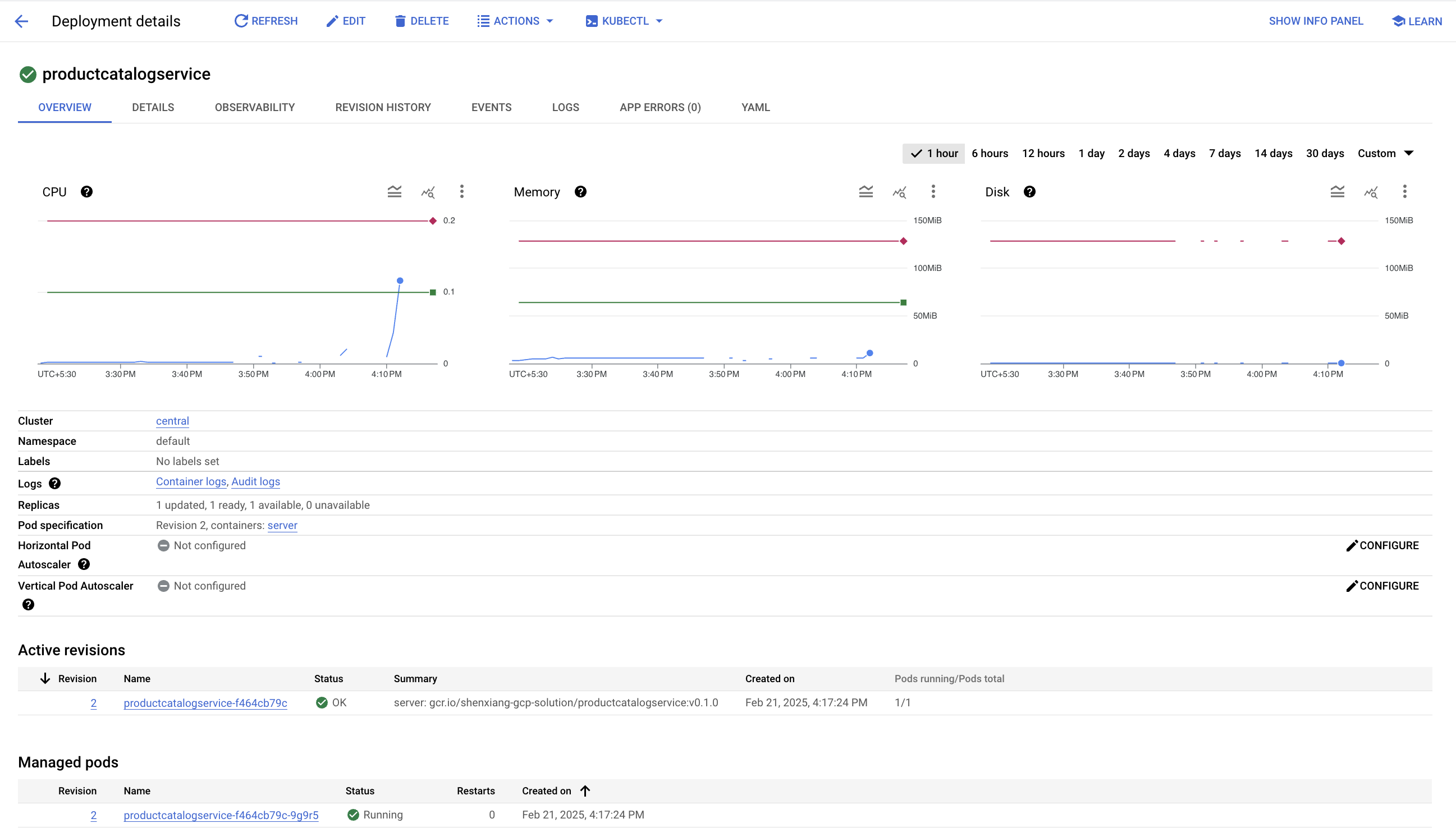
依次前往 Kubernetes Engine > 工作负载 > productcatalogservice。您可以看到,该服务的 Pod 不断崩溃并重新启动。
接下来,看看日志中是否有任何值得注意的内容。
您可以通过以下两种方式轻松获取容器日志:
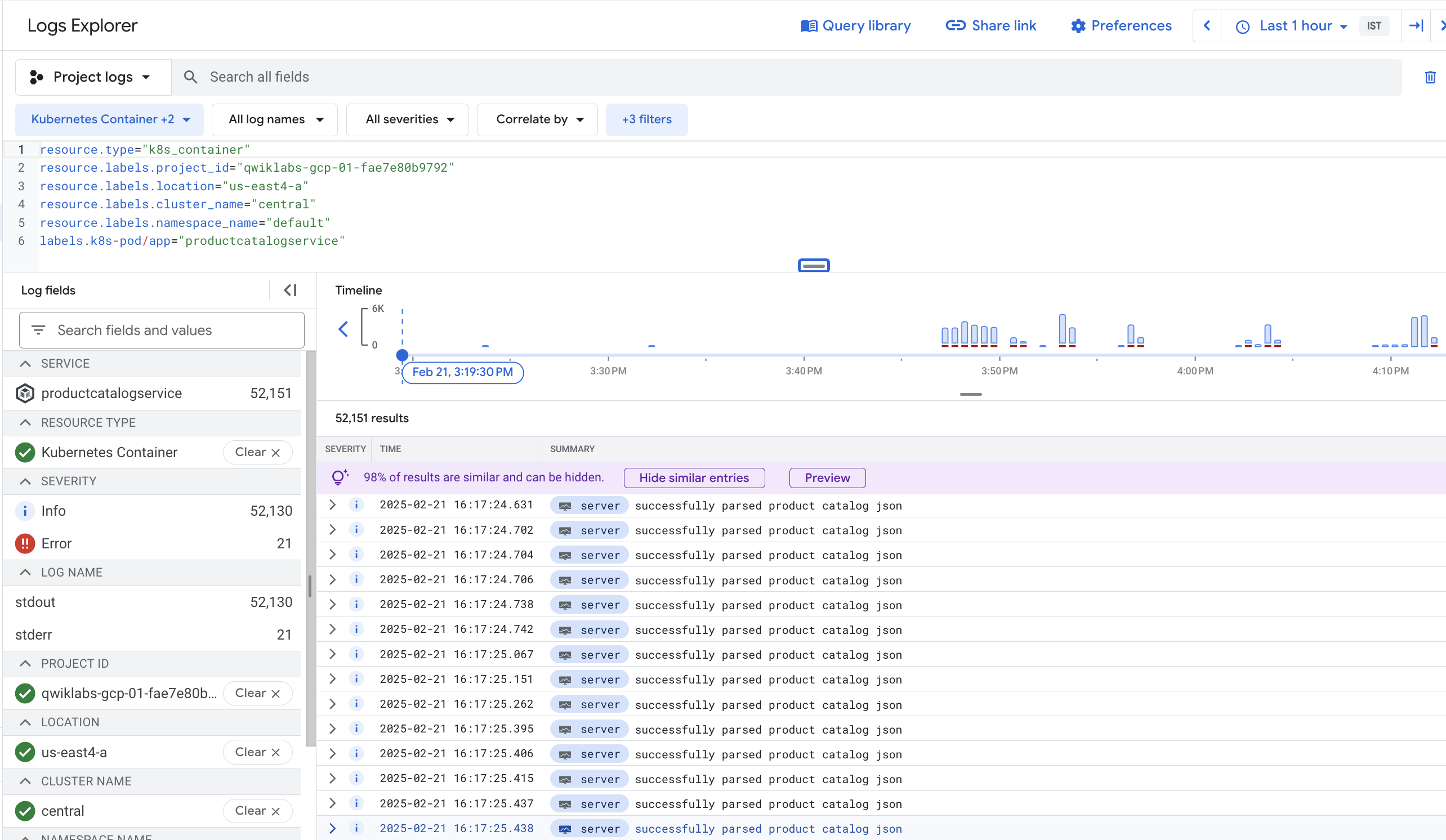
您再次进入 Logs Explorer 页面,现在页面上有一个预定义的查询,专门用于过滤您在 GKE 中查看的容器的日志。
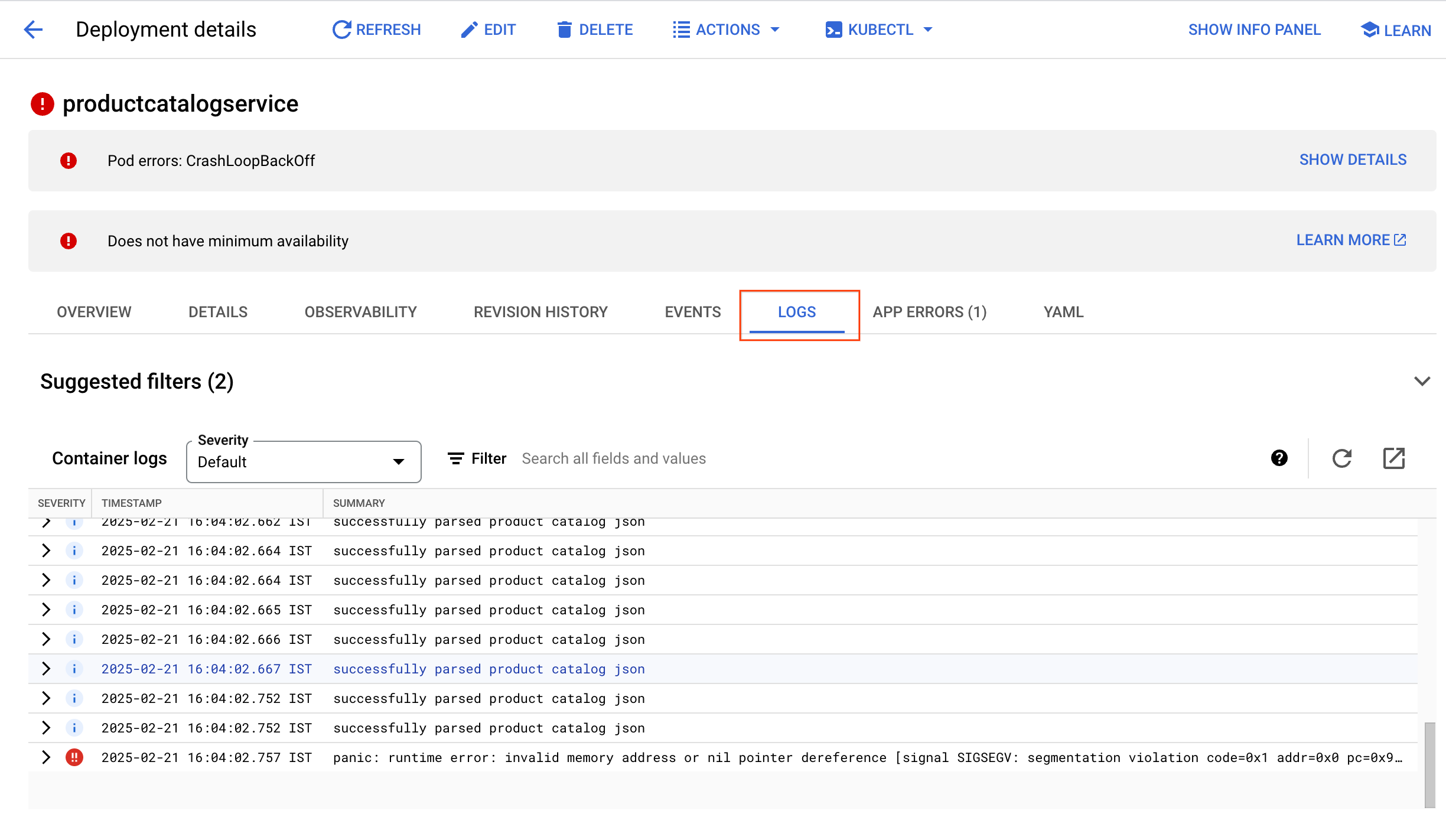
从日志查看器中,日志消息和直方图都显示容器在短时间内重复解析商品目录。这似乎非常低效。
在查询结果的底部,可能还会出现如下所示的运行时错误:
这可能实际上导致了 Pod 崩溃。
为了更好地了解原因,在代码中搜索日志消息。
输出应如下所示,其中包含源文件名和行号:
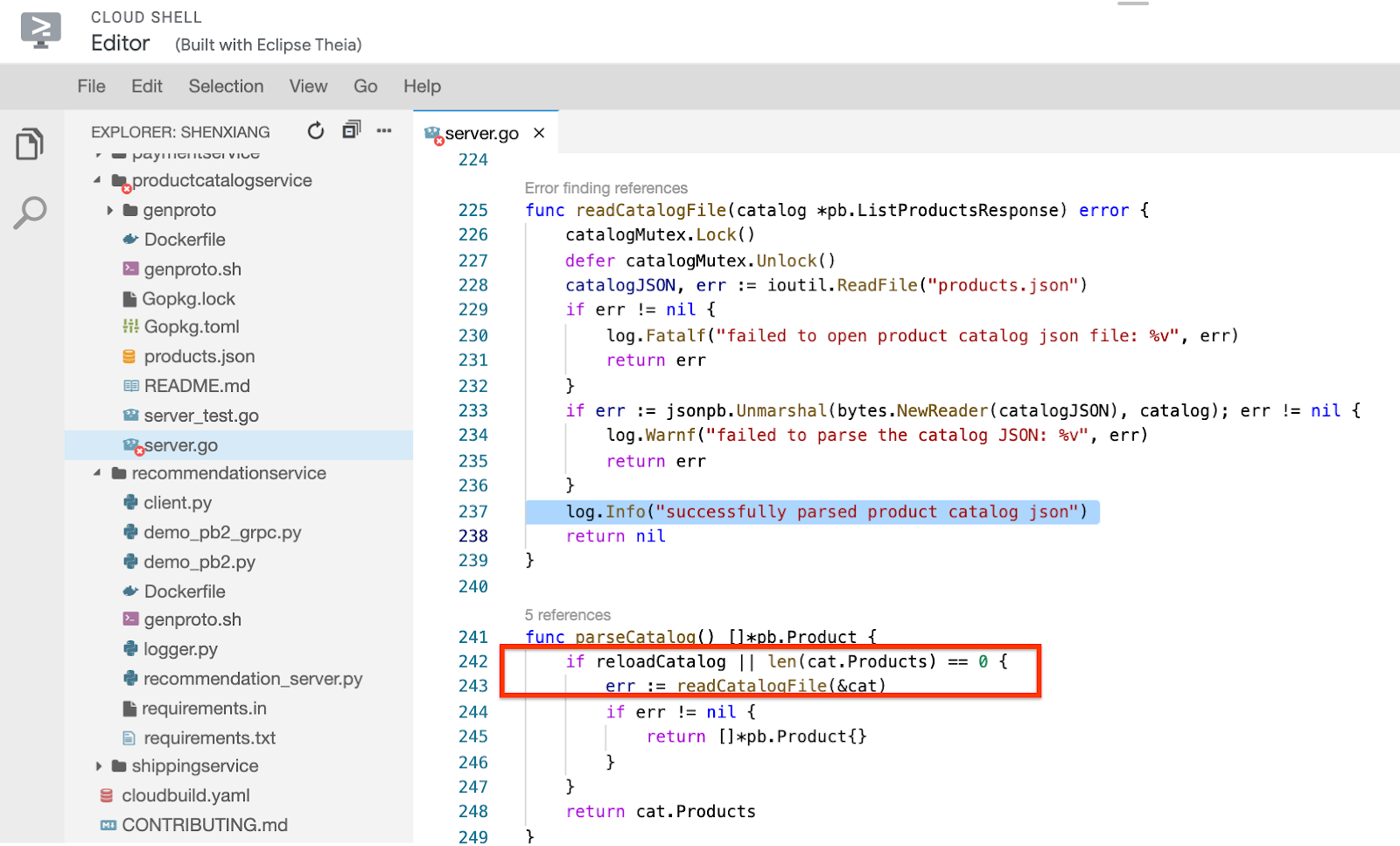
microservices-demo/src/productcatalogservice/server.go,向下滚动到第 237 行,您会发现 readCatalogFile 方法记录了以下消息:再仔细检查,你会发现,如果布尔值变量 reloadCatalog 为 true,则每次调用服务时,服务都会重新加载并解析产品目录,这似乎没有必要。
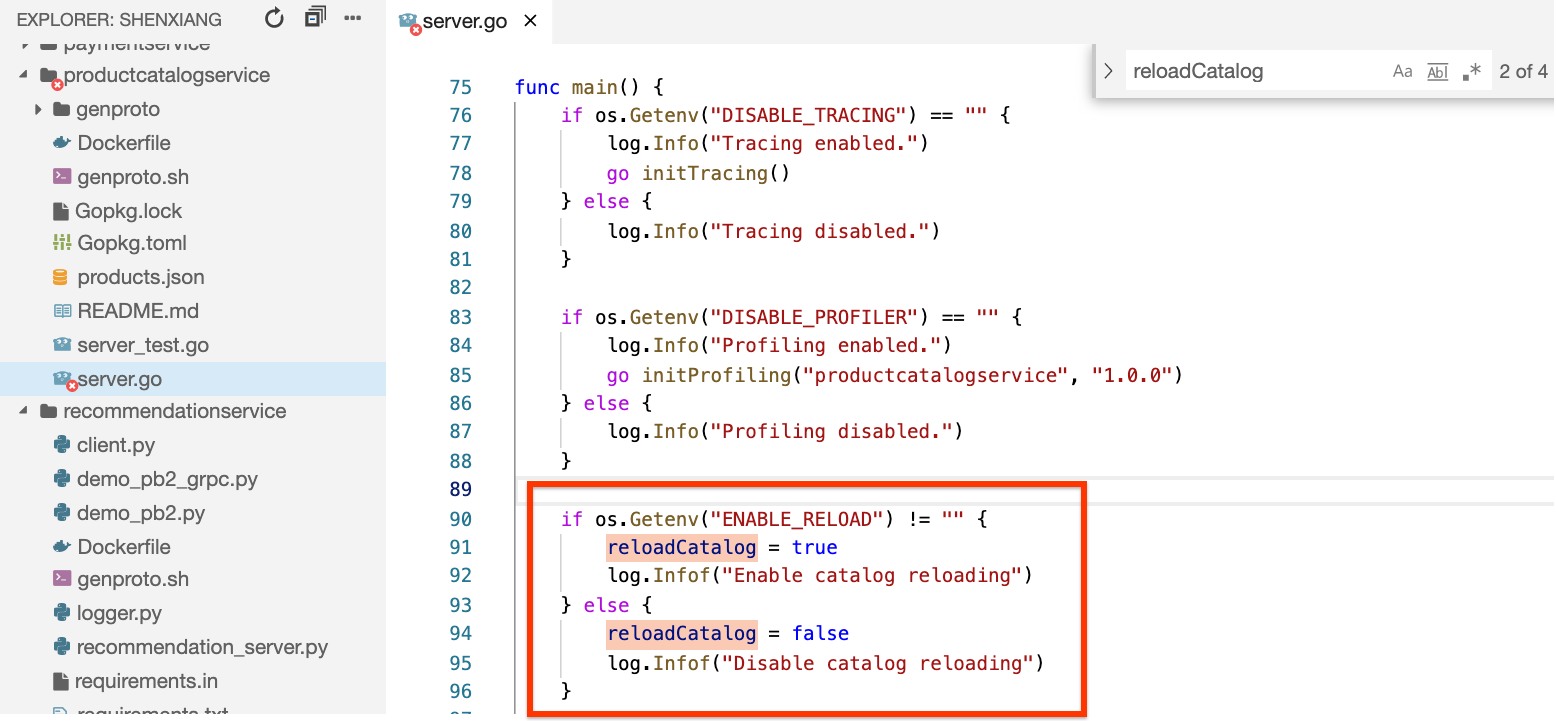
在代码中搜索 reloadCatalog 变量,您可以看到它由环境变量 ENABLE_RELOAD 控制,并为其状态写入一条日志消息。
将此消息添加到查询中,再次检查日志,确定是否存在任何相关条目。
这样,查询构建器中的完整查询如下:
至此,您可以确定前端错误是由于每次请求都加载目录而造成的开销所致。当您增加负载时,该开销导致服务失败并生成错误。
根据代码和日志中显示的内容,您可以尝试通过停用目录重新加载来修复此问题。现在,您将移除商品目录服务的 ENABLE_RELOAD 环境变量。完成变量更改后,您可以重新部署应用,验证更改是否解决了观察到的问题。
如果 Cloud Shell 终端已关闭,点击打开终端按钮以返回该终端。
运行以下命令:
输出将显示清单文件中环境变量的行号:
您会注意到,只有 productcatalogservice 得到配置。其他服务保持不变。
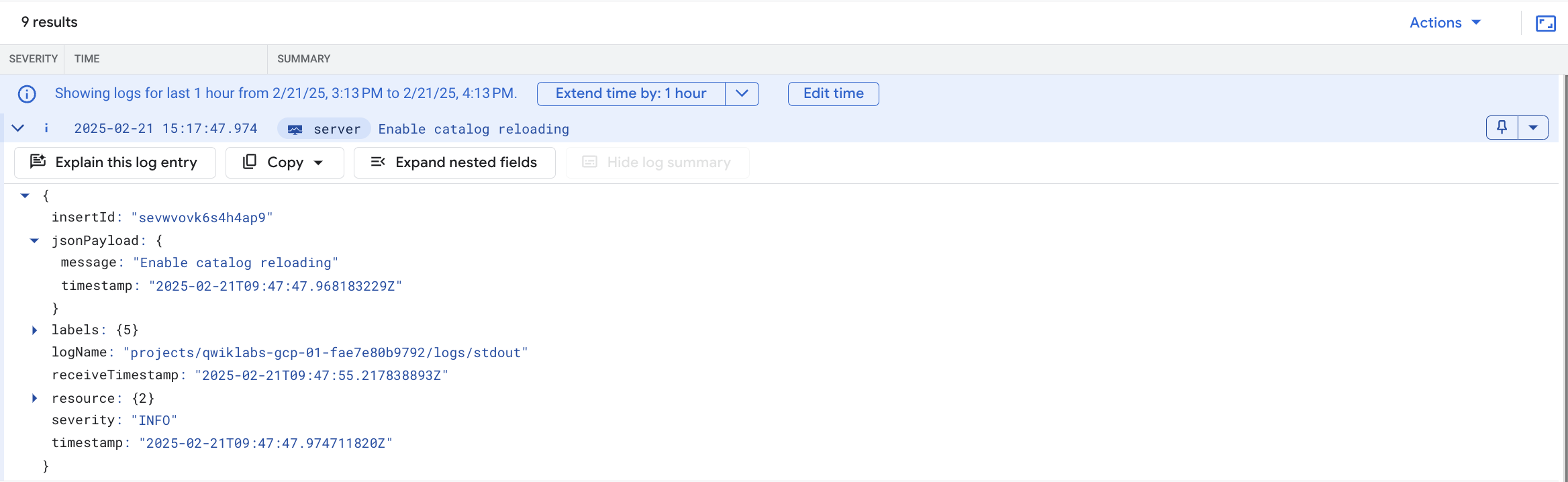
successfully parsing the catalog json 消息已消失:如果您返回到 Web 应用网址并点击首页上的商品,会发现响应速度也快了很多,并且不会遇到任何 HTTP 错误。
返回负载生成器,点击右上角的重置统计信息按钮。失败百分比已重置,您应该不会再看到它增加。
上述所有检查都表明问题已得到解决。如果您仍然看到 500 错误,请再等待几分钟,然后再次点击产品。
您使用 Cloud Logging 和 Cloud Monitoring 在故意包含配置错误的微服务演示应用版本中找到了一个错误。这与您在生产环境中缩小 GKE 应用问题范围时使用的故障排除流程类似。
首先,您将应用部署到 GKE,然后为前端错误设置了指标和提醒。接下来,您生成了负载,然后注意到提醒被触发。根据提醒,您使用 Cloud Logging 将问题范围缩小到特定服务。然后,您使用 Cloud Monitoring 和 GKE 界面查看了 GKE 服务的指标。为了解决此问题,您将更新后的配置部署到 GKE,并确认该修复解决了日志中的错误。
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2025 年 2 月 21 日
上次测试实验的时间:2025 年 2 月 21 日
版权所有 2025 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验